Analiza kategorijalnih podataka 1.Uvod Statistička analiza sa kojom smo se upoznali u toku školovanja uglavnom se bavila analizom numeričkih registrovanih podataka. Međutim, ekspanzija razvoja metoda za analiziranje kategorijalnih (atributivnih) podataka koja je započela 1960. godine, nastavila se ubrzano narednih godina. U našem seminarskom, upoznaćemo se sa raspodelama i metodama zaključivanja (izvođenja) za kategorijalne podatke. Za većinu metoda objašnjavajuća (nezavisna) promenljiva može biti kvalitativna ili kvantitativna. Za analizu kategorijalnih podataka najčešće koristimo tabele kontigencije, koje je uveo Karl Pearson 1904. godine, iako to nije jedini pristup. Na razvoj novih metoda uticala je rastuća dostupnost skupa podataka kategorijalnog tipa u društvenim, biomedicinskim naukama kao i u javnom zdravstvu, ljudskoj genetici, ekologiji, obrazovanju, marketingu i industrijskoj kontroli kvaliteta. Metode usmerene na obradu neprekidnih podataka dostigle su visok nivo početkom 20 veka, dok su statističke metode za kategorijalne podatke značajno kasnile za njima. Uprkos uticajnom radu Karla Pearsona oko 1900. godine jako mali je bio napredak modela za kategorijalne podatke sve do 1960-tih godina. Osnovni pojmovi Skup svih elemenata na kojima se proučava neka pojava naziva se statistički skup, populacija ili osnovni skup. Broj elemenata u populaciji naziva se obim populacije i obeležava se sa N. Osobine po kojima se elementi populacije razlikuju nazivaju se statistička obeležja ili kratko obeležja. Ako je E={e i } i∈I populacija, obeležje je preslikavanje X : E→S, gde je S skup vrednosti obeležja. U zavisnosti od skupa S, obeležja mogu biti numerička (kvantitativna) i atributivna (kategorijalna). Atributivna obeležja su na primer: boja kose, stručna sprema, pol... Obeležje odgovara pojmu slučajne promenljive u teoriji verovatnoće. Osnovni zadatak statistike je određivanje raspodele posmatranog obeležja. Kod ovih obeležja, da bi se 1
Transcript
Analiza kategorijalnih podataka
1.Uvod
Statistička analiza sa kojom smo se upoznali u toku školovanja uglavnom se bavila analizom numeričkih registrovanih podataka. Međutim, ekspanzija razvoja metoda za analiziranje kategorijalnih (atributivnih) podataka koja je započela 1960. godine, nastavila se ubrzano narednih godina. U našem seminarskom, upoznaćemo se sa raspodelama i metodama zaključivanja (izvođenja) za kategorijalne podatke. Za većinu metoda objašnjavajuća (nezavisna) promenljiva može biti kvalitativna ili kvantitativna. Za analizu kategorijalnih podataka najčešće koristimo tabele kontigencije, koje je uveo Karl Pearson 1904. godine, iako to nije jedini pristup. Na razvoj novih metoda uticala je rastuća dostupnost skupa podataka kategorijalnog tipa u društvenim, biomedicinskim naukama kao i u javnom zdravstvu, ljudskoj genetici, ekologiji, obrazovanju, marketingu i industrijskoj kontroli kvaliteta.
Metode usmerene na obradu neprekidnih podataka dostigle su visok nivo početkom 20 veka, dok su statističke metode za kategorijalne podatke značajno kasnile za njima. Uprkos uticajnom radu Karla Pearsona oko 1900. godine jako mali je bio napredak modela za kategorijalne podatke sve do 1960-tih godina.
Osnovni pojmovi
Skup svih elemenata na kojima se proučava neka pojava naziva se statistički skup, populacija ili osnovni skup. Broj elemenata u populaciji naziva se obim populacije i obeležava se sa N . Osobine po kojima se elementi populacije razlikuju nazivaju se statistička obeležja ili kratko obeležja. Ako je E={e i}i∈I populacija, obeležje je preslikavanje X :E→S, gde je S skup vrednosti obeležja. U zavisnosti od skupa S, obeležja mogu biti numerička (kvantitativna) i atributivna (kategorijalna). Atributivna obeležja su na primer: boja kose, stručna sprema, pol... Obeležje odgovara pojmu slučajne promenljive u teoriji verovatnoće. Osnovni zadatak statistike je određivanje raspodele posmatranog obeležja. Kod ovih obeležja, da bi se potpuno odredila raspodela, potrebno je odrediti vrednost odgovarajućih parametara. Međutim, u nekim slučajevima nije poznat ni tip raspodele, kao na primer kod produktivnosti radnika ili broja položenih ispita studenata na nekom fakultetu. U slučaju da se ispituje cela populacija, određivanje raspodele se svodi na registrovanje vrednosti obeležja na svim elementima populacije.
1
Analiza kategorijalnih podataka
2.Kategorijalne promenljive
Većina statističkih analiza razlikuje odgovorne (zavisne) i objašnjavajuće (nezavisne) promenljive. Recimo, regresijski modeli pokazuju kako vrednost odgovorne promenljive zavisi od vrednosti objašnjavajućih promenljivih (prodajna cena kuće - kvadratura, lokacija...). Mi se fokusiramo na metode za kategorijalne odgovorne promenljive.
Kategorijalna promenljiva ima skalu merenja koja se sastoji od skupa kategorija. Na primer, politička filozofija se često deli na liberalnu, umerenu i konzervativnu. Dijagnoze koje se odnose na karcinom dojke bazirane na rezultatima mamografije koriste kategorije normalan, benigni, verovatno benigni, sumnjiv i maligni.
Razvoj metoda kategorijalnih promenljivih podstaknut je istraživačkim studijama koje se sprovode u društvenim i biomedicinskim naukama, međutim nisu ograničene samo na ove oblasti. Kategorijalne skale se upotrebljavaju u društvenim naukama za merenje stavova i mišljenja. Kategorijalne skale u biomedicinskim naukama mere ishode kao što su uspeh medicinskog tretmana. Često se javljaju u naukama koje proučavaju ponašanje (kao što je tip mentalnih bolesti: šizofrenija, depresija i neuroza), genetici (tip alela koje je potomak nasledio), zoologiji (omiljena hrana aligatora: riba, bezkičmenjaci, reptili...), obrazovanje (npr. odgovori studenata na ispitno pitanje tipa tačno/ netačno) i marketingu (preferencije potrošača ). S obzirom na različite vrste kategorijalnih podataka, u nastavku dajemo njihovu klasifikaciju.
Skale merenja
Skala merenja promenljive određuje koja statistička metoda je odgovarajuća.
Nominalna skala je najjednostavnija i najmanje informativna od svih, a prilikom merenja obeležja uključuje samo imenovanje, kategorizaciju ili klasifikaciju mogućih vrednosti obeležja . Promenljive koje koriste ovu skalu imaju kategorije bez prirodnog poretka. Primer je omiljena vrsta muzike: klasična, kantri, folk, džez, ... Za nominalne promenljive poredak kategorija je nebitan. Statistička analiza ne zavisi od tog poretka.
Ordinalna skala je sledeći nivo merenja i uključuje rangiranje mogućih vrednosti obeležja. Među vrednostima obeležja koja se može meriti ordinalnom skalom postoji prirodan poredak, pa se mogu upoređivati. Promenljive koje koriste ovu skalu imaju uređene kategorije, ali je razlika između kategorija nepoznata. Primeri su socijalna klasa (niža, srednja, viša), stanje pacijenta (dobro, srednje, ozbiljno i kritično), stručna sprema zaposlenih (osnovna, srednja,...). Možemo reći da jedan zaposleni ima višu stručnu spremu od drugog, ali ne možemo govoriti ni o apsolutnoj ni o relativnoj veličini ovih razlika.
Intervalna skala merenja je na najvišem nivou. Promenljive koje koriste ovu skalu imaju numeričke razlike između neke dve vrednosti. Na primer, temperatura, koeficijent inteligencije, broj cipela, krvni pritisak, dužina zatvorske kazne, godišnji prihod, ...
2
Analiza kategorijalnih podataka
Način na koji se promenljiva meri određuje njenu klasifikaciju. Na primer, visoko obrazovanje je nominalna promenljiva ako se meri kao državna škola ili privatna škola; ordinalna ako se meri kao osnovne akademske studije, master studije ili doktorske studije; dok je intervalna promenljiva ukoliko se meri kao broj godina studiranja pri tome koristeći brojeve 0,1,2,...
U hijerarhiji merenja, intervalne promenljive su na najvišem nivou, zatim ordinalne, i na samom kraju nominalne. Merenje na višoj skali se može transformisati u skalu nižeg nivoa, ali ne i obrnuto.
Kvantitativno – kvalitativna podela
Nominalne promenljive spadaju u kvalitativne, jer određuju kategorije koje se razlikuju po kvalitetu. Intervalne promenljive su kvantitativne, jer različiti nivoi imaju različite količine određene karakteristike. Položaj ordinalnih promenljivih u kvantitativno – kvalitativnoj podeli je pomalo nejasan. Statističari ih često posmatraju kao kvalitativne, koristeći metode za nominalne promenljive. Međutim, u mnogim aspektima ordinalne promenljive sličnije su intervalnim nego nominalnim promenljivama. One poseduju značajne kvantitativne odlike: svaka kategorija ima veću ili manju zastupljenost karakteristike u odnosu na drugu kategoriju; i mada se ne može tačno odrediti, uglavnom postoji neprekidna promenljiva kao podloga.
Analitičari često koriste kvantitativnu prirodu ordinalne promenljive, dodeljujući numeričke vrednosti kategorijama, ili prihvataju neprekidnu raspodelu kao podlogu. Time je obezbeđen veći broj metoda za obradu podataka koje možemo da koristimo.
3
Analiza kategorijalnih podataka
3.Raspodele kategorijalnih podatakaKod modela sa neprekidnim promenljivama centralno mesto zauzima normalna raspodela. U našem seminarskom opisujemo ključne raspodele za kategorijalne promenljive: binomnu, multinomnu i Poasonovu raspodelu.
Binomna raspodela
Pretpostavimo da neki eksperiment ponavljamo n puta, a ishod tog eksperimenta prima samo dve vrednosti: uspešan i neuspešan, što označavamo sa 1 i 0. Niz dobijenih vrednosti za ishod zapisujemo kao x1, x2 ,…, xn i smatramo da su sva ponavljanja nezavisna i identična.
Ishod i – tog eksperimenta je slučajna promenljiva X i , i=1,2 ,…,n. Pretpostavili smo da su sve promenljive nezavisne, sa istom raspodelom, i pri tome je P (X i=1 )=p verovatnoća da ishod bude uspešan, a P (X i=0 )=1−p verovatnoća da ishod bude neuspešan.
Ukupan broj uspešnih ishoda je nova slučajna promenljiva X=∑i=1
n
X i koja ima binomnu
raspodelu sa parametrima n i p, u oznaci X :B(n , p).
Verovatnoća da promenljiva X primi vrednost k je:
pk=(nk) pk (1− p)n−k , k=0,1,…n
gde je binomni koeficijent (nk)= n !k ! (n−k )! .
Očekivanje i disperzija za slučajnu promenljivu X i su:
E (X i )=p D ( X i )=p (1− p ) .
Očekivanje i disperzija za slučajnu promenljivu X=∑i=1
n
X i su:
E (X )=np D (X )=np (1−p ) .
Multinomna raspodela
Neka ispitivanja mogu imati više od dva moguća ishoda. Pretpostavimo da svaki od n nezavisnih, identičnih eksperimenata može imati ishod u bilo kojoj od c kategorija. Ako eksperiment i ima ishod u kategoriji j onda je x ij=1, a inače je x ij=0. Tada
x i=( xi 1 , x i2 ,…,x ic) predstavlja multinomni eksperiment, gde je ∑j
x ij=1. Na primer,
(0,0,1,0 ) predstavlja ishod u trećoj od četiri moguće kategorije. Zapažamo da je x ic suvišno, jer je linearno zavisno od ostalih.
4
Analiza kategorijalnih podataka
Neka je k j=∑i
x ij broj eksperimenata koji imaju ishod u kategoriji j. Kažemo da vrednosti
(k 1 , k2 ,…,kc) imaju multinomnu raspodelu. Neka p j=P(X ij=1) označava verovatnoću ishoda u kategoriji j za svaki eksperiment. Multinomna funkcija verovatnoće je:
pk1 , k2,… ,kc=( n !
k1! k2!…kc ! ) p1k1 p2k2…pck c .
Binomna raspodela je specijalan slučaj multinomne raspodele kada je c=2.
Poasonova raspodela
Vrednosti podataka ponekad nisu rezultat fiksnog broja eksperimenata. Na primer, ako je x broj smrtnih ishoda usled saobraćajnih udesa tokom jedne sedmice, ne postoji fiksno gornje ograničenje n za x. Kako x mora biti nenegativan ceo broj, njegova vrednost treba da se raspodeli na tom opsegu. Najjednostavnija takva raspodela je Poasonova. Da slučajna promenljiva X ima Poasonovu raspodelu zapisujemo X :P(λ). Verovatnoće u ovoj raspodeli zavise od jednog parametra λ, na sledeći način:
pk=λk
k !e− λ , k=0,1,2 ,…
Poasonova raspodela koristi se za vrednosti događaja koji su slučajni u vremenu ili mestu, kada su ishodi u odvojenim periodima ili mestima nezavisni. Takođe se primenjuje kao aproksimacija za binomnu raspodelu kada je broj ponavljanja n veliki, a verovatnoća p mala, pri čemu je λ=np.
Osnovna karakteristika Poasonove raspodele jeste jednakost očekivanja i disperzije, odnosno
E ( X )=D ( X )=λ .
5
Analiza kategorijalnih podataka
4.Tabele kontigencijeZa pojedinačnu promenljivu kategorijalnog tipa, možemo da sumiramo podatke prebrojavajući učestalost za svaku kategoriju. Proporcija uzorka za proizvoljnu kategoriju ocenjuje nam odgovarajuću verovatnoću.
Neka su date dve kategorijalne promenljive, označene sa X i Y . Pretpostavimo da je I broj kategorija za X , a J broj kategorija za Y . U tabelarnom prikazu imamo I vrsta i J kolona koja odgovaraju kategorijama, dok polja tabele odgovaraju mogućim ishodima. Tabele ovog tipa koje prikazuju frekvencije kombinacija ishoda se nazivaju tabele kontigencije. Naziv je uveo Karl Pearson 1904. godine, a nazivaju se i tabelama unakrsne klasifikacije. Tabele kontigencije sa I vrsta i J kolona zovu se I × J tabele.
Zajedničke, marginalne i uslovne verovatnoće
Verovatnoće koje upisujemo u tabele kontigencije mogu biti zajedničke, marginalne ili uslovne. Pretpostavimo da pratimo dve kategorijalne promenljive X i Y na proizvoljnom subjektu iz populacije. Neka je pij=P(X=i ,Y= j) zajednička verovatnoća da par (X ,Y ) upadne u polje i-te vrste i j-te kolone. Verovatnoće {pij } formiraju zajedničku raspodelu za
X i Y . Važi uslov ∑i , j
pij=1.
Marginalne raspodele dobijaju se sumiranjem po vrstama ili kolonama zajedničkih verovatnoća. Označavaćemo ih sa {pi+¿}¿ ukoliko smo sumirali po vrstama i {p+ j} ukoliko smo sumirali po kolonama. Preciznije
pi+¿=∑
j=1
J
pij p+ j=∑i=1
I
pij . ¿
Svaka marginalna raspodela se odnosi na pojedinačne kategorije promenljivih.
Koristimo sličnu notaciju za konkretan uzorak. Na primer, { p̂ij } označava učestalost za polje u i-toj vrsti i j-toj koloni kod uzoračke zajedničke raspodele. Označavaćemo broj pojavljivanja u tom polju sa {nij}. Marginalna pojavljivanja su sume broja pojavljivanja u određenoj vrsti {ni+¿}¿ ili koloni {n+ j }, a ukupan obim uzorka je n=∑
i , jnij. Sada dobijamo izraz za učestalost
p̂ij=nij
n.
6
Analiza kategorijalnih podataka
U mnogim tabelama kontigencije, jedna promenljiva (recimo promenljiva po kolonama Y ) je odgovorna (zavisna), a druga (promenljiva po vrstama X ) je objašnjavajuća (nezavisna) promenljiva. Tada je pogodno konstuisati zasebnu raspodelu za Y za svaku kategoriju od X . Takva raspodela se sastoji od uslovnih verovatnoća za Y u zavisnosti od X i naziva se uslovna raspodela.
Primer 1 U tabeli 1 klasifikovan je uzorak iz jednog američkog istraživanja o povezanosti pola i verovanja u zagrobni život. Za ženske osobe u uzorku, na primer 509 je izjavilo da veruje u zagrobni život a 116 da ne veruje ili nema mišljenje o toj temi. Sada se pitamo da li postoji povezanost između pola i njihovih mišljenja.
Verovanje u zagrobni životPol Da Ne ili neodlučeno
Žene 509 116Muškarci 398 104
Tabela 1
S obzirom da se radi o promenljivama kategorijalnog tipa, primenićemo gore izložene metode i oznake. Ukupan obim uzorka je n=1127. Naša tabela sada izgleda ovako
Verovanje u zagrobni životPol Da Ne ili neodlučeno Ukupno
Žene n11=509 n12=116 n1+¿=625 ¿
Muškarci n21=398 n22=104 n2+¿=502¿
Ukupno n+1=907 n+2=220 n=1127
Tabela 2
U tabeli 2 verovanje u zagrobni život je odgovorna promenljiva, a pol je objašnjavajuća promenljiva. Dakle, tražimo uslovne raspodele za verovanje u zagrobni život, ukoliko nam je
dat pol. Za žene, učestalost potvrdnog odgovora je 509625
=0.81, a učestalost negativnog
odgovora je 116625
=0.19. Učestalosti (0.81 ,0.19) formiraju uzoračku uslovnu raspodelu. Za
muškarce, ta raspodela je (0.79,0 .21).
Nezavisnost kategorijalnih promenljivih
Dve promenljive su statistički nezavisne ako su uslovne raspodele za Y dobijene na osnovu populacije identične za sve kategorije od X . Kada su dve promenljive nezavisne, verovatnoća pojedinačnog ishoda u koloni j ne zavisi od vrste u kojoj se nalazi. Verovanje u zagrobni život iz prethodnog primera bilo bi nezavisno od pola, da je stvarna verovatnoća verovanja u zagrobni život bila 0.8 i za muškarce i za žene.
7
Analiza kategorijalnih podataka
Kada su obe promenljive odgovorne, možemo opisati njihovu povezanost preko zajedničke raspodele, preko uslovne raspodele od Y za dato X ili preko uslovne raspodele od X za dato Y . Statistička nezavisnost je ekvivalenta sa osobinom da su sve zajedničke verovatnoće jednake proizvodu marginalnih
pij=pi+¿ p+ j ,i=1,2 ,… ,I , j=1,2 ,…, J .¿
Binomno, multinomno i Poasonovo uzorkovanje
Raspodele verovatnoća ranije uvedene možemo primeniti na polja tabela kontigencije. Na primer, Poasonovo uzorkovanje tretira vrednosti u poljima kao nezavisne slučajne promenljive sa Poasonovom raspodelom. Tada je slučajna promenljiva koja odgovara polju i× j, definisana sa X ij :P (λij ). Zajednička verovatnoća za potencijalne ishode {nij} je proizvod Poasonovih verovatnoća P(X ij=nij), odnosno
∏i∏
j
λijnij
nij !e− λij .
Takođe smo definisali binomnu i multinomnu raspodelu. Kod slučajnih uzoraka i eksperimenata, često je razumno koristiti neku od ovih raspodela za tabelu kontigencije. Kada se vrste u tabelama kontigencije odnose na različite grupe, veličine tih grupa su obično fiksirane. Primer za to je podela celog uzorka na dve polovine nad kojima će se vršiti različiti eksperimenti. Kada su marginalne sume za kategorije od X fiksirane a ne slučajne, zajednička raspodela za X i Y nema mnogo smisla, ali zato uslovna raspodela od Y za svako moguće X ima. Kada imamo dve kategorije za Y , možemo koristiti binomnu raspodelu za uzorak u svakoj vrsti, gde je broj ponavljanja fiksirana suma po vrsti. U slučaju da imamo više od dve kategorije za Y , koristimo multinomnu raspodelu. Ovaj princip možemo koristiti i kada odgovorna i objašnjavajuća promenljiva zamene mesta.
Vratimo se na kratko na naš primer. Kako je verovanje u zagrobni život odgovorna promenljiva, možemo posmatrati rezultate za žene kao binomno uzorkovanje sa mogućim ishodima ‘da’ i ‘ne’, a za muškarce takođe kao binomno uzorkovanje, ali nezavisno od rezultata za žene. Da smo imali više ponuđenih odgovora, koristili bismo multinomno uzorkovanje.
Vrste istraživanja
Koristeći sledeći primer, objasnićemo razlike između pojedinih vrsta istraživanja.
Primer 2 U tabeli 3 dati su rezultati jednog od prvih istraživanja veze između karcinoma pluća i pušenja, sprovedena od strane Ričarda Dola i Bredforda Hila. U 20 bolnica u Londonu, pacijenti primljeni sa rakom pluća ispitivani su o svojim pušačkim navikama proteklih godina. Za svakog od 709 pacijenata sa rakom, istraživači su ispitivali i pušačke navike pacijenata bez karcinoma, istog pola i približno istih godina.
U prvoj koloni, 709 pacijenata predstavlja obolele od karcinoma pluća, a u drugoj koloni, 709 pacijenata predstavlja kontrolnu grupu. Za pušača smo smatrali osobu koja je pušila barem jednu cigaretu dnevno bar godinu dana.
Uobičajeno je da pojava karcinoma pluća bude zavisna promenljiva, a pušačke navike ljudi bude objašnjavajuća promenljiva. U ovom istraživanju, marginalna raspodela za karcinom pluća je fiksirana izborom uzorka. Samim tim, poenta je uočiti da li je osoba ikad bila pušač ili ne.
Istraživanja koja koriste retrospektivni model zovu se case – control istraživanja i uobičajena su u zdravstvu. Videli smo da je u ovom istraživanju, za svakog obolelog pronađen jedan odgovarajući kontrolni slučaj i time su dobijeni uzorci istog tipa. Međutim, uzorci kod ove vrste istraživanja mogu biti potpuno nezavisni. Jedno takvo case – control istraživanje karcinoma i pušenja je uzorkovalo subjekte šaljući pisma lekarima koji su umirali od neke vrste kancera tokom 1950 ili 1951. godine, a rezultati su unakrsno klasifikovani prema tipu karcinoma i pušačkim navikama ispitanika.
Ako bismo želeli da uporedimo odnos obolelih i neobolelih od karcinoma pluća za pušače i nepušače, bile bi nam potrebne uslovne raspodele karcinoma pluća uz dati pušački status. Kako ovo istraživanje ne obezbeđuje takve raspodele, željeni odnos ostaje nepoznat. Umesto toga, case – control istraživanja nam daju suprotne odnose, to jest uslovne raspodele za pušačke navike ako nam je dat status pacijenta. U tabeli odnos za obolele koji su pušači je 688709
=0.97, a za kontrolne slučajeve taj odnos je 650709
=0.917.
Nasuprot ovakvom modelu, možemo posmatrati prospektivan model koji se bazira na budućnosti. Takvo bi bilo istraživanje koje uzorkuje subjekte iz populacije tinejdžera i onda 60 godina kasnije meri odnos nastanka karcinoma pluća pušača i nepušača. Postoje dve vrste prospektivnih istraživanja. Prva vrsta su klinički eksperimenti koji bi slučajno rasporedili subjekte u grupe pušača i nepušača. Druga vrsta su kohortna istraživanja (cohort studies) i u tom slučaju subjekti sami odlučuju da li će pušiti ili ne, a istraživanje prati kod koga od njih se vremenom razvio karcinom.
Sledeći pristup je unakrsno – podeljeni model, koji uzorkuje subjekte i istovremeno ih klasifikuje na obe promenljive.
Case – control, kohortno i unakrsno – podeljena istraživanja nazivaju se posmatračkim istraživanjima. Ta istraživanja jednostavno opažaju ko je izabrao koju grupu i kakav je krajnji ishod. Nasuprot tome, klinički eksperimenti spadaju u eksperimentalna istraživanja. U tom
9
Analiza kategorijalnih podataka
slučaju istraživač ima kontrolu nad izborom tretmana za subjekte. Ovakva istraživanja koriste slučajnost da bi približno izbalansirala grupe.
Posmatračka istraživanja su uobičajena, ali imaju više potencijala za pristrasnost ka određenim tipovima.
5. Upoređivanje proporcija u tabelama 2×2
Odgovorna promenljiva sa dve kategorije naziva se binarna promenljiva. Na primer, verovanje u zagrobni život je binarna promenljiva kada se izražava kategorijama (da, ne). Mnoge studije upoređuju dve grupe na osnovu binarnih odgovora Y . Podaci se prikazuju u tabelama kontigencije dimenzije 2×2, gde su vrste grupe koje se ispituju, a kolone su kategorije od Y . U nastavku uvodimo parametre za poređenje dve grupe sa binarnim odgovorima.
Razlika proporcije
Nadovezujući se na binomnu raspodelu definisanu ranije, označićemo kategorije ishoda sa ‘uspeh’ i ‘neuspeh’. Za subjekte u prvoj vrsti, neka p1 označava verovatnoću uspeha, a 1−p1 verovatnoću neuspeha. Za subjekte u drugoj vrsti, neka p2 označava verovatnoću uspeha. Ovo su uslovne verovatnoće.
Razlika proporcija je veličina koja upoređuje verovatnoće uspeha za dve vrste i izračunava se p1−p2. Ovakva razlika je u intervalu od −1 do +1. Jednaka je nuli kada su verovatnoće jednake, odnosno p1=p2 i tada je ishod nezavisan od podele grupa. Slično, za dati uzorak možemo računati uzoračke proporcije uspeha, označene sa p̂1 i p̂2. Uzoračka razlika p̂1− p̂2 ocenjuje nam razliku proporcija p1−p2.
Kada su obe promenljive odgovorne, uslovne raspodele se primenjuju u bilo kom smeru, pa umesto dve vrste možemo porediti dve kolone.
Relativan rizik
Razlika između dve proporcije obično je važnija ukoliko su obe proporcije blizu 0 ili 1, nego kada su u sredini opsega. Pretpostavimo da poredimo dejstvo dva različita leka na grupi pacijenata i beležimo učestalost neželjenog dejstva. U tom slučaju, razlika između 0.010 i 0.001 ista je kao razlika između 0.410 i 0.401, i iznosi 0.009. Prva razlika je mnogo značajnija, jer pokazuje da je 10 puta više pacijenata imalo neželjenu reakciju na prvi lek, nego na drugi. U takvim slučajevima, odnos proporcija bolje opisuje situaciju. Za tabele 2×2, relativan rizik je odnos
p1p2
.
10
Analiza kategorijalnih podataka
Relativni rizik može biti bilo koji nenegativan realan broj. Za gore date proporcije 0.010 i
0.001, relativan rizik je 0.0100.001
=10, dok je za druge dve proporcije 0.410 i 0.401, relativni rizik
je 0.4100.401
=1.02. Relativni rizik koji je jednak 1 dešava se kada je p1=p2, to jest kada je ishod
nezavisan od grupe.
Odnos verovatnoća neuspeha, 1−p11−p2
, uzima različitu vrednost naspram odnosa verovatnoća
uspeha. Kada jedan od mogućih ishoda ima malu verovatnoću, obično se računa odnos verovatnoća za taj ishod. Odnos šansi
Za verovatnoću uspeha p, šansa se definiše kao
Ω= p1−p
.
Šanse su nenegativne vrednosti, sa Ω>1 kada je uspeh verovatniji od neuspeha. Na primer,
neka je p=0.75, onda je Ω=0.750.25
=3, odnosno uspeh je tri puta verovatniji od neuspeha i
očekujemo oko tri uspeha za svaki neuspeh. Kada je Ω=13 , neuspeh je tri puta verovatniji od
uspeha. Obrnuto je
p= ΩΩ+1
.
Osvrnimo se ponovo na naše tabele kontigencije 2×2. Unutar i-te vrste, šanse za uspeh
umesto neuspeha su Ωi=pi
1− pi. Količnik šansi Ω1 i Ω2 u dve vrste izračunava se na sledeći
način
θ=Ω1
Ω2=
p11−p1p21−p2
i naziva se odnos šansi.
Za zajedničke raspodele sa verovatnoćama u poljima {pij }, ekvivalenta definicija za šansu u i-
toj vrsti je Ωi=pi1
pi2, i=1,2. Tada je odnos šansi
11
Analiza kategorijalnih podataka
θ=
p11p12p21p22
=p11 p22p12 p21
.
Drugi naziv za odnos šansi θ je odnos unakrsnog proizvoda, zbog toga što je jednak odnosu proizvoda verovatnoća iz dijagonalno suprotnih polja.
Osobine odnosa šansi
Odnos šansi može biti jednak bilo kom nenegativnom broju. Uslov Ω1=Ω2 odnosno θ=1 odgovara nezavisnosti promenljivih X i Y . Što se vrednosti za θ više udaljavaju od 1, povezanost među promenljivama je jača. Dve vrednosti predstavljaju istu povezanost, ali u suprotnom smeru, kada je jedna recipročna vrednost druge. Za θ∈(1 ,∞), uspeh je verovatniji za subjekte u prvoj vrsti, nego za subjekte u drugoj vrsti, pa sledi p1> p2. Na primer, kada je θ=4, šanse za uspeh u prvoj vrsti jednake su četvorostrukoj vrednosti šansi druge vrste. To ne znači da je verovatnoća p1=4 p2, nego se to interpretira kao relativni rizik u vrednosti 4. Za θ∈(0,1), verovatnoće su p1< p2. Kada se u nekom polju javi verovatnoća u vrednosti 0, θ je jednaka 0 ili ∞.
U primeni je češći izraz log θ. U ovom slučaju, nezavisnost je predstavljena sa 0 ( log1=0). Logaritamska vrednost odnosa šansi je simetrično raspoređena oko nule. Dve vrednosti za log θ koje su jednake, ali različitog znaka, na primer log 4=1.39 i log 0.25=−1.39, predstavljaju jednak intenzitet povezanosti.
Odnos šansi ne menja vrednost kada kolone i vrste zamene mesta, što vidimo iz simetričnosti izraza θ. Da bismo koristili θ, nije potrebno da neku promenljivu proglasimo za odgovornu.
Mada smo odnos šansi ranije definisali preko šansi po vrstama, to možemo uraditi i preko kolona. Sa zajedničkom raspodelom, uslovne raspodele postoje u proizvoljnom smeru i važi
Odnos šansi jednako je validan za prospektivne, retrospektivne i unakrsno – podeljene modele uzorkovanja. Uzorački odnos šansi procenjuje isti parametar u svakom od tih slučajeva.
Za vrednosti u poljima {nij }, uzorački odnos šansi je
θ̂=n11n22n12n21
.
12
Analiza kategorijalnih podataka
Ovaj količnik se ne menja kada se vrednosti u nekoj vrsti ili koloni pomnože ne nula konstantom. Odatle sledi da uzorački odnos šansi izračunava istu karakteristiku iz marginalnih kategorija promenljive, čak i kada je uzorak neproporcionalno velik ili mali.
Vratimo se na primer verovanja u zagrobni život. Od ranije znamo da je p̂1=0.81, a p̂2=0.79.
Verovanje u zagrobni životPol Da Ne ili neodlučeno
Žene n11=509 n12=116Muškarci n21=398 n22=104
Tabela 4
Sada računamo veličine koje smo definisali u ovom odeljku. Uzoračka razlika proporcija je
p̂1− p̂2=0.02. Relativan rizik za ovakav uzorak je p̂1p̂2
=0.810.79
=1.025, što nam pokazuje da je
proporcija žena koje veruju u zagrobni život 1.025 puta veća od proporcije muškaraca istog
verovanja. Šansa uspeha za žene je Ω1=0.811−0.81
=4.263, a šansa uspeha za muškarca je
Ω2=0.791−0.79
=3.762. Odnos šansi je θ̂=n11n22n12n21
=509∗104116∗398
=1.147 . Šansa za verovanje u
zagrobni život za žene je 1.147 puta šansi za muškarce.
Primer 3 Sledeća tabela je kreirana na osnovu istraživačkog izveštaja i predstavlja vezu između upotrebe aspirina i infarkta miokarda. Naime, istraživanje je sprovedeno da bi se utvrdila povezanost smrtnosti izazvane kardiovaskularnim oboljenjima i redovnog uzimanja aspirina. Ispitanici su dobili tabletu aspirina ili placebo, ali oni nisu znali koju tabletu od ove dve dobijaju. Tokom petogodišnjeg istraživanja, od ukupno 11 034 ispitanika koji su uzimali placebo, njih 18 je imalo fatalne srčane udare, dok je od 11 037 ispitanika koji su uzimali aspirin, njih 5 imalo fatalne srčane udare.
Infarkt miokardaNapad sa fatalnim
ishodomNapad bez fatalnog
ishodaBez napada
Placebo 18 171 10 845Aspirin 5 99 10 933
Tabela 5
Kako tabela razlikuje napade sa fatalnim i nefatalnim ishodom, mi ćemo sada kombinovati ove ishode. Od 11 034 ispitanika koji su uzimali placebo, njih 189 dobilo je srčani infarkt, a to
je odnos p1=18911034
=0.0171. Od 11 037 ispitanika koji su uzimali aspirin, njih 104 je imalo
infarkt. Taj odnos je p2=10411037
=0.0094 . Uzoračka razlika proporcija je
13
Analiza kategorijalnih podataka
0.0171−0.0094=0.0077. Relativni rizik je 0.01710.0094
=1.82. Odnos onih koji su imali infarkt, a
uzimali su placebo, 1.82 puta je veći od odnosa onih koji su imali infarkt, a uzimali su aspirin.
Uzorački odnos šansi je θ̂=189∗10933104∗10845
=1.83. Šansa infarkta za one koji su uzimali placebo
je 1.83 puta šanse onih koji su uzimali aspirin. Case – control istraživanje i odnos šansi
Sa retrospektivnim modelom uzorkovanja, kao što su case – control istraživanja, moguće je izračunati uslovne verovatnoće P (X=i|Y = j ). Uglavnom nije moguće izračunati verovatnoću P (Y= j|X=i ) koja nas stvarno interesuje, razliku proporcija ili relativni rizik za taj ishod. Međutim, moguće je izračunati odnos šansi, jer je on određen uslovnim verovatnoćama u proizvoljnom smeru.
Vratimo se na primer kako pušačke navike ljudi utiču na nastanak karcinoma pluća. Na osnovu tabele, već smo izračunali verovatnoće da je subjekat pušač, ako znamo da li subjekat ima karcinom pluća. Te verovatnoće su 0.97 i 0.917, redom za obolele i kontrolne pacijente.
Karcinom plućaPušač Oboleli Kontrolni pacijenti
Da 688 650Ne 21 59
Ukupno 709 709
Tabela 6
Nije moguće izračunati verovatnoću karcinoma pluća ako je zadato da li je subjekat pušač ili nije, i ako nam je to od daleko većeg značaja. Odatle, nije moguće izračunati razlike ili odnose verovatnoća za karcinom pluća. Razlika proporcija i relativni rizik su ograničeni na poređenja verovatnoća o statusu pušenja. Međutim, možemo izračunati odnos šansi
0.970.030.9170.083
=0.080510.02751
=3.
Iako je istraživanje bilo retrospektivno, možemo interpretirati dobijeni rezultat u smeru koji nas interesuje. Izračunata šansa karcinoma pluća kod pušača je 3 puta veća nego kod nepušača.
Veza između odnosa šansi i relativnog rizika
14
Analiza kategorijalnih podataka
Iz prethodnih definicija, izvodimo sledeći zaključak
odnos šansi=relativanrizik∗( 1−p21−p1 ) .
Ove dve veličine imaju približne vrednosti ako su verovatnoće ishoda koji nas interesuje blizu nule za obe grupe. Sličnost smo videli u primeru sa aspirinom i srčanim infarktom, gde je proporcija infarkta bila manja od 0.02 za svaku grupu. Relativni rizik je iznosio 1.82, a odnos šansi je bio 1.83.
Kod case – control istraživanja, nije moguće direktno izračunati relativan rizik, pa za male verovatnoće uspeha koristimo odnos šansi da ga približno odredimo. U primeru pušačkih navika ljudi i karcinoma pluća, ako je verovatnoća karcinoma mala za obe grupe, 3 je gruba ocena i relativnog rizika. Smatramo da pušači imaju oko 3 puta veću relativnu učestalost karcinoma pluća od nepušača.
6. Parcijalne povezanosti u tabelama kontigencije 2×2
Važna komponenta većine istraživanja, posebno posmatračkih, jeste izbor kontrolnih promenljivih. Pri analizi efekata promenljive X na promenljivu Y , potrebno je kontrolisanje bilo koje nezavisne promenljive koja bi mogla da utiče na tu vezu. Ovo uključuje korišćenje određenih mehanizama koji omogućuju da ta nezavisna promenljiva ostane po strani. U suprotnom, efekat koji X ima na Y može zapravo da oslikava efekat te mešovite promenljive i na X i na Y . U tom slučaju, veza između X i Y ostaje nejasna. Eksperimentalna istraživanja mogu da uklone ovakvo mešanje sa strane slučajnim izborom subjekata za X , ali kao što smo videli to nije moguće sa posmatračkim istraživanjem.
Pretpostavimo da analiziramo efekte pasivnog pušenja, kada imamo situaciju da nepušač živi sa pušačem. Da bismo utvrdili da li je pasivno pušenje povezano sa karcinomom pluća, unakrsno – podeljeno istraživanje moglo bi da upoređuje pojavu karcinoma pluća među nepušačima čiji supružnici puše i nepušačima čiji supružnici ne puše. Istraživanje treba da pokuša da kontroliše starost, socijalno – ekonomski status, ili druge faktore koji mogu da utiču na pušenje supružnika i na razvoj karcinoma pluća. U suprotnom, rezultati će imati ograničenu korisnost. Ako bi supružnici nepušača bili u tom istraživanju uglavnom mlađi od supružnika pušača, na niži odnos slučajeva karcinoma među supružnicima nepušača može da utiče njihov niži prosečan broj godina starosti. Po je posledica činjenice da mlađi ljudi ređe oboljevaju od karcinoma pluća.
15
Analiza kategorijalnih podataka
U ovom delu našeg seminarskog, analiziraćemo vezu između kategorijalnih promenljivih X i Y , pri čemu ćemo kontrolisati samo jednu promenljivu Z, zbog jednostavnosti.
Parcijalne tabele
Kontrolisaćemo uticaj promenljive Z tako što ćemo proučavati odnos između X i Y na fiksiranim nivoima za Z. Kada iz tabele kontigencije koja sadrži sve tri promenljive, izdvojimo delove u kojima je Z fiksirano, dobijamo parcijalne tabele. Tabela kontigencije 2×2 dobijena kombinovanjem parcijalnih tabela, naziva se XY marginalna tabela. Vrednost svakog polja u marginalnoj tabeli je suma vrednosti istog polja parcijalne tabele. Marginalna tabela ne kontroliše Z, već je ignoriše i ne sadrži informacije o Z. Ona predstavlja tablični odnos promenljivih X i Y , ali može da oslikava efekte Z na X i Y .
Povezivanje u parcijalnim tabelama, naziva se uslovna povezanost, zato što posmatra efekte X na Y , u zavisnosti od fiksiranog Z na nekom nivou. Uslovne povezanosti u parcijalnim tabelama mogu se potpuno razlikovati od povezanosti u marginalnim tabelama. Može biti pogrešno analizirati samo marginalne tabele, što će biti ilustrovano u sledećem primeru.
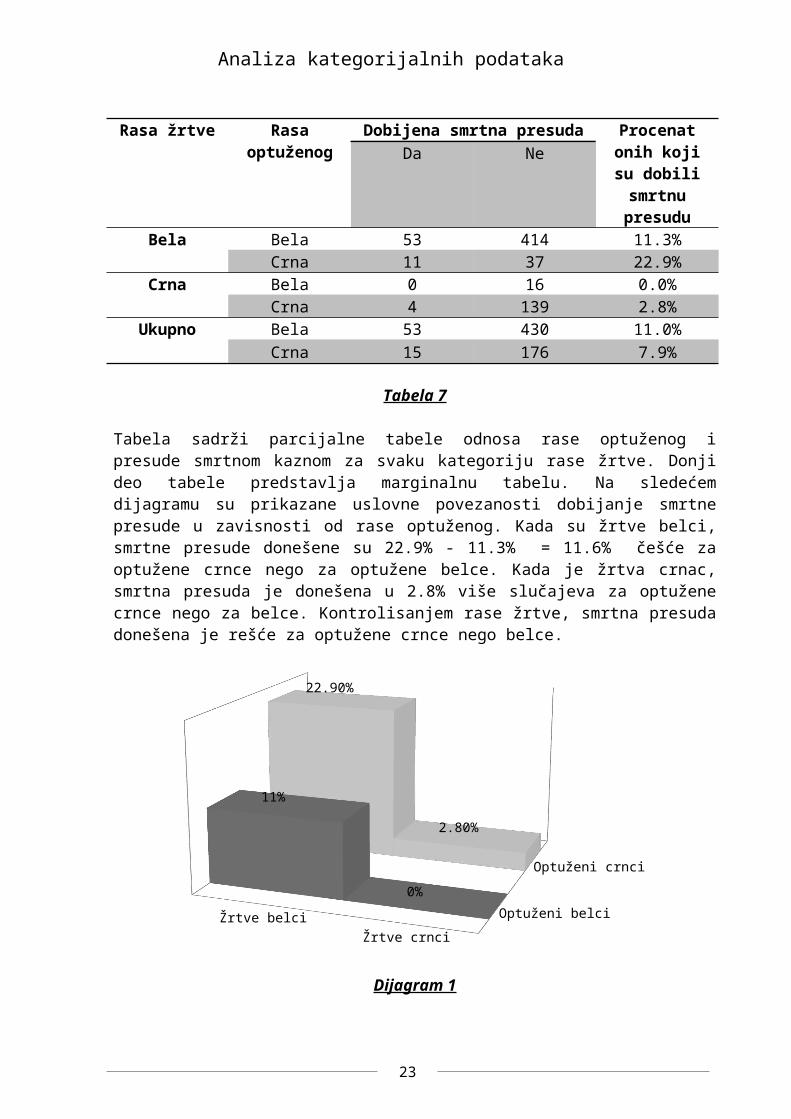
Primer 4 U sledećoj tabeli se istražuje efekat rasnih karakteristika na dobijanje smrtne presude za izvršeno ubistvo. Tabela sadrži 674 subjekta optuženih za učešće u slučajevima višestrukih ubistava. Promenljive koje posmatramo su:
Y – smrtna presuda (sa kategorijama da i ne), X – rasa optuženog (sa kategorijama bela i crna), Z – rasa žrtve (sa kategorijama bela i crna).
Rasa žrtve Rasa optuženog Dobijena smrtna presuda Procenat onih koji su dobili
smrtnu presuduDa Ne
Bela Bela 53 414 11.3%Crna 11 37 22.9%
Crna Bela 0 16 0.0%Crna 4 139 2.8%
Ukupno Bela 53 430 11.0%Crna 15 176 7.9%
Tabela 7
Tabela sadrži parcijalne tabele odnosa rase optuženog i presude smrtnom kaznom za svaku kategoriju rase žrtve. Donji deo tabele predstavlja marginalnu tabelu. Na sledećem dijagramu su prikazane uslovne povezanosti dobijanje smrtne presude u zavisnosti od rase optuženog. Kada su žrtve belci, smrtne presude donešene su 22.9% - 11.3% = 11.6% češće za optužene crnce nego za optužene belce. Kada je žrtva crnac, smrtna presuda je donešena
16
Analiza kategorijalnih podataka
u 2.8% više slučajeva za optužene crnce nego za belce. Kontrolisanjem rase žrtve, smrtna presuda donešena je rešće za optužene crnce nego belce.
Žrtve belciŽrtve crnci
Optuženi belci
Optuženi crnci
11%
0%
22.90%
2.80%
Dijagram 1
Marginalna tabela nastala je sumiranjem iznosa u poljima za dve kategorije rasa žrtava, tj. kombinacijom dve parcijalne tabele. Povrh svega, 11% optuženih belaca i 7.9% optuženih crnaca dobili su smrtnu presudu. Zanemarujući rasu žrtve, smrtna presuda donešena je ređe kada je optuženi crnac, nego kada je optuženi belac.
Zašto se povezanost toliko menja kada ignorišemo rasu žrtve? Ovo se odnosi na prirodu povezanosti između rase žrtve i svih ostalih promenljivih. Prvo, povezanost između rase žrtve i rase optuženih je ekstremno jaka. Marginalna tabela koja se odnosi na ove promenljive ima
odnos šansi 467∗14348∗16
=87.0. Tabelu smo dobili iz prethodne sabiranjem svih presuda.
Rasa žrtve Rasa optuženogBela Crna
Bela 467 48Crna 16 143
Tabela 8
Drugo, Tabela 7 pokazuje da bez obzira na rasu optuženog, smrtna presuda je verovatnija kada su žrtve belci. Dakle, belci su skloniji ubijanju belaca, i ubijanjem belaca verovatnija je smrtna presuda.
Rezultat da marginalna povezanost može da ima suprotan smer od svake uslovne povezanosti naziva se Simpsonov paradoks. On je primenljiv na kvantitativne podjednako kao i na kvalitativne promenljive. Statističari ga obično koriste da bi izbegli uzročni efekat na povezanosti promenljive X sa Y . Na primer, kada su doktori počeli da primećuju veliki odnos
17
Analiza kategorijalnih podataka
šansi između pušenja i karcinoma pluća, neki statističari su upozorili da možda postoje neke promenljive (kao što je genetski faktor), takve da bi povezanost nestala pod odgovarajućom kontrolom. Sa druge strane, pokazano je da sa veoma snažnom povezanošću X i Y , mora postojati i veoma snažna povezanost između kontrolne promenljive Z i promenljivih X i Y , da bi došlo do promene usled kontrolisanja.
Uslovni i marginalni odnos šansi
Marginalnu i uslovnu povezanost možemo opisati preko odnosa šansi, što ćemo pokazati u tabeli kontigencije 2×2×K , gde K označava broj kategorija kontrolne promenljive Z. Neka su {μijk } očekivane frekvencije polja za neki model uzorkovanja, kao što je binomno, multinomno ili Poasonovo uzorkovanje.
U okviru fiksirane kategorije k od Z, odnos šansi je
θXY (k )=μ11k μ22kμ12 k μ21k
.
On opisuje uslovnu povezanost u parcijalnoj tabeli k . Odnosi šansi za K parcijalnih tabela nazivaju se XY uslovni odnosi šansi. Mogu se potpuno razlikovati od marginalnih odnosa šansi. Marginalne tabele XY imaju očekivane frekvencije {μij+¿=∑
kμijk }¿, pa je XY marginalni
odnos šansi dat sa
θXY=μ11+¿
μ22+¿
μ12+¿ μ21+¿ .¿¿¿¿
Na osnovu uzorka, ocenjujemo ove vrednosti zamenjujući očekivane frekvencije vrednostima polja iz tabele.Vratimo se na prethodni primer, koji opisuje povezanost rase optuženog i smrtne presude. U prvoj parcijalnoj tabeli, rasa žrtve je bela i važi
θ̂XY (1)=53∗37414∗11
=0.43 .
Uzoračka šansa za optužene belce koji su dobili smrtnu kaznu je 43% uzoračke šanse za optužene crnce. U drugoj parcijalnoj tabeli, rasa žrtve je crna i odnos šansi je
θ̂XY (2)=0∗13916∗4
=0 ,
pošto smrtna presuda nikada nije donešena optuženom belcu čija je žrtva bio crnac.
Za izračunavanje marginalnog odnosa šansi koristimo marginalnu tabelu unutar Tabele 7, i tada je
18
Analiza kategorijalnih podataka
θ̂XY=53∗176430∗15
=1.45 .
Uzoračka šansa smrtne presude je 1.45 puta veća za optužene belce nego za crnce, iako su unutar kategorija rase žrtava ti odnosi bili manji za optužene belce. Ova razlika u povezanosti posle kontrole rase žrtava ilustruje Simpsonov paradoks.
Marginalne nasuprot uslovnim nezavisnostima
Neka su promenljive X ,Y i Z zadate pomoću tabele kontigencije 2×2×K , kao i do sada. Ako su X i Y nezavisne u parcijalnoj tabeli k , kažemo da su one uslovno nezavisne na k – tom nivou promenljive Z. Ukoliko to važi za svako k , onda su promenljive X i Y uslovno nezavisne za zadato Z. Ukoliko postoji nezavisnost u marginalnoj tabeli, promenljive su i marginalno nezavisne.
Primer 5 U sledećoj tabeli prikazane su reakcije pacijenata u dve bolnice u zavisnosti od terapije koju su dobijali. Označićemo:
Y – reakcija (uspešna i neuspešna), X – terapija (A i B), Z – bolnica (1 i 2).
Bolnica Terapija ReakcijaUspešna Neuspešna
1 A 18 12B 12 8
2 A 2 8B 8 32
Ukupno A 20 20B 20 40
Tabela 9
Uslovni XY odnosi šansi iznose
θXY (1)=18∗812∗12
=1 iθXY (2)=2∗328∗8
=1.
Za zadatu bolnicu, reakcija i terapija su uslovno nezavisne promenljive. Marginalna tabela kombinuje tabele dve bolnice. Njen odnos šansi iznosi
θXY=20∗4020∗20
=2 ,
pa promenljive nisu marginalno nezavisne.
19
Analiza kategorijalnih podataka
Ako zanemarimo bolnicu, zbog čega je šansa uspeha terapije A dvostruka šansa uspeha terapije B? Uslovni XZ i YZ odnosi šansi nam daju odgovor. Odnos šansi između Z i neke od promenljivih X i Y , za svaku fiksiranu kategoriju druge promenljive iznosi 6. To znači da su uslovne šanse za zadatu reakciju primanja terapije A u klinici 1 šest puta veće od onih u klinici 2, i uslovne šanse za zadatu terapiju uspeha reakcije u klinici 1 su šest puta veće od onih u klinici 2.
Klinika 1 češće koristi terapiju A, takođe klinika 1 ima više uspešnih terapija. Na primer, ako su pacijenti u klinici 1 mlađi i boljeg zdravstvenog stanja od onih u klinici 2, moguće je da su oni imali bolji odnos uspeha bez obzira na terapiju koju su primili.
Homogene povezanosti
Tabela kontigencije 2×2×K ima homogenu XY povezanost kada je
θXY (1)=θXY (2)=…=θ XY (K ).
Tada je efekat promenljive X na Y isti za svaku kategoriju promenljive Z. Uslovna nezavisnost promenljivih X i Y je specijalan slučaj u kom je svako θXY (k)=1.
Kada je povezanost XY homogena, homogenost važi i za ostale povezanosti. Na primer, uslovni odnos šansi između dve kategorije promenljive X i dve kategorije promenljive Z je jednak za svaku kategoriju promenljive Y . Za odnos šansi, homogena povezanost je simetrično svojstvo. Primenjuje se na svaki par promenljivih posmatranih kroz kategorije treće promenljive. Kada se to dogodi, kažemo da nema interakcije dve promenljive u njihovom uticaju na preostalu promenljivu.
Kada interakcija postoji, uslovni odnos šansi za bilo koji par promenljivih se menja po kategorijama treće promenljive. Za
X – pušenje (da i ne), Y – karcinom pluća (da i ne), Z – uzrast (<45; 45-65; >65),
pretpostavimo da je θXY (1)=1.2, θXY (2)=3.9 i θXY (3)=8.8. Tada pušenje ima slabiji efekat na karcinom pluća kod mlađih ljudi, ali se efekat intenzivno povećava sa starošću. Godine starosti tada nazivamo modifikatorom efekta, jer je efekat pušenja modifikovan u zavisnosti od te vrednosti.
20
Analiza kategorijalnih podataka
7. Uopšteni linearni modelUopšteni linearni modeli, u oznaci GLM (Generalized Linear Models), uključuju model regresije i model ANOVA za neprekidne i diskretne podatke. Međutim, mi ćemo se fokusirati na GLM modele za kategorijalne i druge diskretne promenljive sa binarnim vrednostima.
GLM modeli se sastoje od tri komponente:1) Komponenta slučajnosti – poistovećujemo je sa zavisnom slučajnom promenljivom Y
i pretpostavljamo da nam je poznata njena funkcija verovatnoće,2) Komponenta sistematičnosti – poistovećujemo je sa nezavisnom slučajnom
promenljivom X datog modela,3) Funkcija veze – označava funkciju očekivane vrednosti za Y , koja povezuje model
GLM sa nezavisnom promenljivom X preko linearne forme jednačine predviđanja.
Komponenta slučajnosti
Kao što smo rekli, komponenta slučajnosti za GLM model se identifikuje sa zavisnom promenljivom Y i prihvata njenu funkciju verovatnoće. Označimo realizacije za Y sa (Y 1 ,Y 2 ,…,Y n). Standardan model GLM posmatra Y 1 ,Y 2 ,…,Y n kao nezavisne.
U mnogim primenama, zapažanja Y su binarna, označimo ih kao ‘uspeh’ i ’neuspeh’. Uopšteno, svako Y i označava broj uspeha od određenog fiksiranog broja pokušaja. U svakom slučaju, pretpostavljamo binomnu raspodelu za Y . U praksi, sva zapažanja su podaci dobijeni
21
Analiza kategorijalnih podataka
prebrojavanjem. Tada možemo pretpostaviti funkciju verovatnoće za Y koja važi za sve nenegativne cele brojeve, kao što je Poasonova ili negativna binomna raspodela. Ako su zapažanja neprekidna, kao što je težina subjekta o studiji efekta dijete, možemo pretpostaviti normalnu raspodelu za Y .
Komponenta sistematičnosti
Komponentu sistematičnosti u GLM modelu poistovećujemo sa nezavisnim promenljivama. Odnosno, komponenta sistematičnosti određuje promenljive {x j} u sledećoj formuli
α+β1 x1+…+βk xk .
Linearna kombinacija nezavisnih promenljivih se naziva linearno predviđanje. Međutim, promenljive {x j} ne moraju biti linearno nezavisne, tj. može biti da je x3=x1x2 i time dozvoljavamo interakciju između x1 i x2 u efektima koje imaju na Y . (GLM model koristi oznaku x umesto X , da bi naglasio da posmatra vrednosti x radije kao fiksirane nego kao slučajne promenljive.)
Funkcija veze
Označimo očekivanu vrednost Y sa μ=E(Y ). Treća komponenta GLM modela, funkcija veze, definiše funkciju g(∙) koja povezuje μ sa linearnim predviđanjem
g ( μ )=α+β1x1+…+βk xk .
Funkcija g(∙) povezuje komponentu slučajnosti i sistematičnosti.
Najjednostavnija funkcija veze dobija se kada je funkcija veze očekivanja upravo očekivanje promenljive Y, odnosno važi g (μ )=μ, i nazivamo je veza identiteta. Dobijamo jednačinu oblika
μ=α+β1 x1+…+ βk xk .
Druge funkcije veze dozvoljavaju nelinearnost μ u odnosu na predviđanje. Na primer, funkcija veze g (μ )= log (μ) modelira logaritamsko očekivanje. Funkcija logaritma se primenjuje na pozitivne brojeve, stoga logaritamska funkcija veze je prikladna kada očekivanje μ ne može biti negativno, kao što je prebrojavanje podataka. GLM model koji koristi logaritamsku funkciju veze se zove loglinearan model, i ima sledeću formu
log ( μ )=α+β1 x1+…+ βk xk .
Funkcija veze g (μ )= log [ μ1−μ ]modelira logaritam šansi i koristi se kada je μ∈(0,1) i naziva
se logit veza. GLM model koji koristi logit vezu zove se logistički model regresije.
22
Analiza kategorijalnih podataka
Svaka potencijalna raspodela verovatnoća za Y ima jednu specijalnu funkciju očekivanja koja se zove prirodni parametar. Za normalnu raspodelu, prirodni parametar samo očekivanje. Za binomnu raspodelu, prirodni parameter je logit verovatnoće uspeha. Funkcija veze koja koristi prirodni parametar kao npr. g ( μ ) u GL modelu, zove se kanonička veza. Iako su druge funkcije veze moguće, u praksi je najčešća kanonička veza.
Uobičajeni regresioni modeli za neprekidne zavisne promenljive su posebni slučajevi GL modela. Oni pretpostavljaju da Y ima normalnu raspodelu i modeliraju očekivanje direktno iz veze identiteta g ( μ )=μ. GLM sprovodi uopštavanje obične regresije na dva načina: Prvi, dozvoljavamo da Y ima i neku drugu raspodelu osim normalne. Drugi, dozvoljava modeliranje funkcije očekivanja. Oba uopštenja su značajna za kategorijalne podatke. U suštini, GL model ujedinjuje razne statističke modele.
8. Uopšteni linearni model za binarne promenljiveMnoge kategorijalne zavisne promenljive imaju samo dve kategorije, na primer da li ste se danas vozili javnim prevozom (da, ne). Neka Y predstavlja binarnu zavisnu promenljivu, a njene ishode označimo sa 1 (uspeh) i 0 (neuspeh). Raspodela Y je definisana verovatnoćama P (Y=1 )=p uspeha i P (Y=0 )=1−p neuspeha. Sledi E (Y )=p. Za n nezavisnih eksperimenata, broj uspeha ima binomnu raspodelu sa parametrima n i p.
U nastavku se bavimo GLM modelom ako imamo binarnu zavisnu promenljivu. Iako model GLM podržava višestrukost nezavisnih promenljivih, radi jednostavnosti pretpostavljamo samo jednu nezavisnu promenljivu. Kako p zavisi od promene x, u daljem radu označavaćemo p sa p(x ).
Linearni model verovatnoće
U običnoj regresiji, μ=E(Y ) je linearna funkcija od x. Za binarnu zavisnu promenljivu, model je
p ( x )=α+ βx .
Ova jednačina se zove i linearni model verovatnoće, jer se verovatnoća uspeha menja linearno u zavisnosti od x. Parametar β predstavlja promenu verovatnoće za jediničnu promenu x. Ovo je GLM model sa binarnom slučajnom promenljivom i funkcijom veze
23
Analiza kategorijalnih podataka
identiteta. Iako je veoma jednostavan, linearni model verovatnoće ima nedostatak. Kako znamo da verovatnoća uzima vrednosti u intervalu [0,1], ovako definisan linearni model verovatnoće može primiti vrednost bilo kog realnog broja. Ovaj problem prevazilazimo modifikovanjem promenljive x, odnosno ograničavajući njen opseg. Ako imamo uzorak, linearni model verovatnoće se zapisuje na sledeći način
p̂ ( x )=α̂+ β̂ x ,
a ocene parametara dobijamo metodom maksimalne verodostojnosti. Ako zanemarimo binarnost zavisne promenljive i posmatramo običnu regresiju, ocene parametara dobijamo metodom najmanjih kvadrata.
Primer 6 U ovom primeru proučavamo povezanost između hrkanja i srčanih oboljenja. Istraživanje je sprovedeno na 2484 subjekata, i u narednoj tabeli prikazana je klasifikacija subjekata u zavisnosti od njihovog nivoa hrkanja.
Hrkanje Srčano oboljenje Linearno fitovanjeDa Ne
Nikad 24 1355 0.017Ponekad 35 603 0.057
Skoro svake noći 21 192 0.096Svake noći 30 224 0.116
Tabela 10Linearni model verovatnoće nam prikazuje verovatnoću srčanog oboljenja p̂(x ) kao linearnu funkciju hrkanja x. Nivoi hrkanja predstavljaju nezavisne binarne promenljive. Neka vrednosti (0,2,4,5) označavaju nivo hrkanja. Ako ocenjujemo parametre α i β preko metode maksimalne verodostojnosti, dobijamo sledeću ocenu linearnog modela verovatnoće
p̂=0.0172+0.0198 x .
Na primer, za ljude koji nemaju problema sa hrkanjem (x=0), ocenjena verovatnoća srčanog oboljenja je p̂=0.0172+0.0198∗0=0.0172. Procenjene vrednosti za E(Y ) zovu se fitovane vrednosti (fitted values).
Interpretacija ovog modela je krajnje jednostavna. Ocenjena verovatnoća srčanog oboljenja za ljude koji nemaju problema sa hrkanjem je 0.0172, i ona raste kako se nivo hrkanja povećava. Najveća ocenjena verovatnoća srčanog oboljenja je za ljude koji hrču svaku noć i iznosi 0.116.
Logistički model regresije
Odnosi između p(x ) i x obično je nelinearan. Ista promena za x može imati manji uticaj ako je verovatnoća p(x ) blizu 0 i 1, nego kada je u sredini intervala. Na primer, pri kupovini automobila, moramo da biramo između novog i polovnog. Neka je p(x ) verovatnoća za kupovinu novog automobila kada je godišnji prihod porodice jednak x. Povećanje od 10 000
24
Analiza kategorijalnih podataka
porodičnog prihoda imaće manji efekat kada je x=1000000 (p(x ) je blizu 1), nego za x=50000.
U praksi, p(x ) često neprekidno raste ili opada sa porastom x. Krive oblika kao na Slici 1, su često dobar pokazatelj ove veze.
Slika 1
Najznačajnija matematička funkcija ovog oblika data je sa
p ( x )= eα+βx
1+eα+βx .
To je funkcija logističke regresije. Odgovarajući model logističke regresije ima formu
log( p ( x )1−p ( x ) )=α+βx ,
i predstavlja specijalan slučaj GLM modela. Komponenta slučajnosti za ishode (uspeh i neuspeh) ima binomnu raspodelu. Funkcija veze je logit funkcija
logit ( p )=log( p1−p
) .
Modeli logističke regresije se često nazivaju logit modeli. Kako je verovatnoća p(x ) u intervalu [0,1], logit funkcija može uzeti vrednost bilo kog realnog broja. Realni brojevi su takođe potencijalni domen za linearna predviđanja (kao što su α+βx) koja čine komponentu sistematičnost modela GLM. Zato ovaj model nema problem sa strukturom kakav je imao linearni model verovatnoće.
25
Analiza kategorijalnih podataka
Parametar β u logit jednačini određuje stopu rasta krive prikazane na Slici 1. Kada je β>0, p(x ) raste kako x raste; kada je β<0, p(x ) opada kako x raste. Od |β| zavisi koliko će kriva biti strma. Za β=0, dobijamo horizontalnu pravu liniju.
Vratimo se na primer o povezanosti hrkanja i srčanih oboljenja. Metodom maksimalne verodostojnosti dobijamo ocene parametara α i β, a zatim i logistički regresioni model
logit [ p̂ ( x ) ]=−3.87+0.4 x .
Vrednosti za logit fitovanje date su u tabeli u zavisnosti od nivoa hrkanja.
Hrkanje Srčano oboljenje Logit fitovanjeDa Ne
Nikad 24 1355 0.021Ponekad 35 603 0.044
Skoro svake noći 21 192 0.093Svake noći 30 224 0.132
Tabela 11
Kako je β̂=0.4>0, procenjena verovatnoća srčanog oboljenja raste sa porastom nivoa hrkanja. Rezultati logističkog fitovanja su slični rezultatima linearnog, zbog uskog opsega verovatnoća.
Probit model regresije
Još jedan model koji daje krive oblika kao na Slici 1, je probit model. Funkcija veze za ovaj model, takozvana probit veza, transformiše verovatnoće u Z-vrednosti iz standardne normalne raspodele. Probit model dat je izrazom
probit [ p ( x ) ]=α+ βx .
Probit funkcija veze primenjena na p(x ) daje standardnu normalnu Z-vrednost za koju je levi rep verovatnoće jednak p(x ). Na primer, probit (0.05 )=−1.645, jer je 5% standardne normalne raspodele levo od −1.645. Isto tako, probit (0.5 )=0, probit (0.95 )=1.645, i probit (0.975 )=1.96.
U primeru povezanosti hrkanja i srčanih oboljenja, pomoću metode maksimalne verodostojnosti ocenili smo parametre α i β, i formirali probit model
probit [ p̂ ( x ) ]=−2.061+0.188 x .
Za nivo hrkanja x=0, probit funkcija je jednaka −2.061+0.188 (0 )=−2.06. Fitovana verovatnoća p̂(0) je verovantoća za levi rep standardne normalne raspodele za z=−2.06, što je jednako 0.02. Na isti način dobijamo ostale fitovane vrednosti prikazane u tabeli.
26
Analiza kategorijalnih podataka
Hrkanje Srčano oboljenje Probit fitovanjeDa Ne
Nikad 24 1355 0.020Ponekad 35 603 0.046
Skoro svake noći 21 192 0.095Svake noći 30 224 0.132
Tabela 12
Fitovane vrednosti dobijene pomoću probit modela slične su vrednostima dobijenim pomoću linearnog modela verovatnoće i modela logističke regresije. U praksi, probit i logit modeli daju slično fitovanje. Ako logistički model regresije daje dobro fitovanje, tada će i probit model dati dobra fitovanja i obrnuto.
9.Uopšteni linearni model za podatke dobijene prebrojavanjemMnoge diskretne zavisne promenljive imaju prebrojavanja kao moguće ishode. Na primer, na uzorku studenata, brojimo žurke koje je svaki od njih posetio prethodnog meseca. Prebrojavanja smo takođe koristili u tabelama kontigencije za kategorijalne promenljive. U ovom delu uvodimo GLM modele za takve podatke.
Najjednostavniji GLM modeli za podatke dobijene prebrojavanjem pretpostavljaju Poasonovu raspodelu komponente slučajnosti. Kao i podaci dobijeni prebrojavanjem, Poasonove slučajne promenljive uzimaju nenegativne celobrojne vrednosti. Znamo od ranije da Poasonova raspodela zavisi od jednog parametra μ>0 i važi
E (Y )=Var (Y )=μ .
Iz tog razloga, kada su vrednosti u proseku veće, one i više variraju.
Poasonova regresija
Sada ćemo se baviti Poasonovim GLM modelima za podatke dobijene prebrojavanjem, ako imamo jednu diskretnu zavisnu promenljivu.
27
Analiza kategorijalnih podataka
Poasonova raspodela ima pozitivno očekivanje. GLM model za Poasonovo očekivanje može da koristi vezu identiteta, ali je uobičajeno da se modelira pomoću logaritma očekivanja. Kao i linearno predviđanje, logaritam očekivanja može uzeti proizvoljnu realnu vrednost. Poasonov loglinearan model je GLM model koji pretpostavlja Poasonovu raspodelu za promenljivu Y i koristi logaritamsku funkciju veze.
Ako imamo jednu nezavisnu promenljivu x, Poasonov loglinearan model ima sledeću formu
log μ=α+βx .
Očekivanje zadovoljava eksponencijalnu vezu
μ=eα+βx=eα ¿
Jedinično povećanje za x ima sledeći uticaj: Očekivanje od Y za x+1 jednako je očekivanju od Y za x pomnoženim sa eβ. Ako je β=0, onda je eβ=e0=1 i faktor kojim množimo je 1. U tom slučaju, očekivanje za Y ne zavisi od x. Ako je β>0, tada je eβ>1, i očekivanje od Y se povećava kako x raste. Ako je β<0, očekivanje opada kako x raste.
Negativna binomna regresija
Negativna binomna je još jedna raspodela koja se bavi nenegativnim celim brojevima. Za razliku od Poasonove, ona ima dodatni parametar koji dozvoljava da disperzija bude veća od očekivanja, i važi
E (Y )=μ ,Var (Y )=μ+D μ2 .
Parametar D je nenegativan i naziva se parametar disperzije. Kada D→0, Var (Y )→μ i negativna binomna raspodela teži Poasonovoj. Što se parametar D više udaljava od 0, raspodela se više razlikuje od Poasonove.
Negativni binomni GLM model za podatke dobijene prebrojavanjem izražava očekivanje μ preko nezavisnih promenljivih. Najčešće se koristi logaritamska funkcija veze, kao u Poasonovim loglinearnim modelima, ali ponekad je adekvatnija veza identiteta. Uglavnom se uzima da je parametar disperzije D konstantan za sva linearna predviđanja. Ocenjena vrednost za D sumira sve efekte prekoračenja disperzije koju smo imali u Poasonovom GLM modelu.
28
Analiza kategorijalnih podataka
10. Statističko zaključivanje i provera modelaZa većinu GLM modela, ocenjivanje parametara metodom maksimalne verodostojnosti je veoma složeno. Taj metod nije jedini kojim se mogu oceniti parametri. Zaključivanje pomoću Wald – ove statistike je najjednostavnije, mada nije pouzdano kao metod maksimalne verodostojnosti.
Zaključivanje o parametrima modela
Wald – ov 95% interval poverenja za parametar β je β̂ ±1.96 (SE), gde je SE standardna greška za β̂. Za testiranje hipoteze H 0 : β=0, Wald – ova test statistika je
Z= β̂SE
i ona ima približno standardnu normalnu raspodelu kada je β=0. Ekvivalentno, Z2 ima približno χ2 raspodelu sa jednim stepenom slobode.
Vratimo se na primer povezanosti hrkanja sa srčanim oboljenjem. Model maksimalne verodostojnosti dao nam je ocenu p̂=0.0172+0.0198 x, gde je efekat hrkanja bio β̂=0.0198 sa standardnom greškom SE=0.0028. Testiraćemo hipotezu H 0 : β=0 protiv alternativne H 1: β≠0 Wald – ovom test statistikom
29
Analiza kategorijalnih podataka
z= β̂SE
=0.01980.0028
=7.1
za koju znamo da ima standardnu normalnu raspodelu. Ekvivalentno, ako posmatramo z2=50.4, onda je naša raspodela χ2 sa jednim stepenom slobode. Ovo nam obezbeđuje jak dokaz pozitivnog efekta hrkanja na verovatnoću srčanog oboljenja (pvrednost<0.0001).
Literatura1. Alan Agresti: An introduction to categorical data analysis; A John Wiley & Sons, inc.,
Publication; 20072. Alan Agresti: Categorical data analysis; A John Wiley & Sons, inc., Publication; 20023. Diplomski rad, Dejana Govedarica: Analiza kategorijalnih podataka4. Bayo Lawal: Categorical data analysis with SAS and SPSS applications; Lawrence