86
BIG DATA en Sciences et Industries de l’Environnement Franc ¸ois Royer www.datasio.com 21 mars 2012 FR — Big Data Congress, Paris 2012 — 1/23

BIG DATAen Sciences et Industries de l’Environnement
Francois Royer
www.datasio.com
21 mars 2012
FR — Big Data Congress, Paris 2012 — 1/23

Transport terrestre
Transport aerien
Tracabilite
Telemetrie - Argos
Oceanographie
Imagerie satellite
FR — Big Data Congress, Paris 2012 — 2/23

Points cles
Vers une Science ultra-empirique?
Big Data pour la Recherche et l’Industrie : mode d’emploi
Hadoop et les donnees geographiques et temporelles
FR — Big Data Congress, Paris 2012 — 3/23

Points cles
Vers une Science ultra-empirique?
Big Data pour la Recherche et l’Industrie : mode d’emploi
Hadoop et les donnees geographiques et temporelles
FR — Big Data Congress, Paris 2012 — 4/23

L’ere du ”Data Scientist”L’accumulation exponentielle de donnees transforme la demarche d’analyse
1960E. Wigner, ”The Unreasonable Effectiveness ofMathematics in the Natural Sciences,” Comm. Pure andApplied Mathematics, vol. 13, no. 1, pp. 1–14.
2009A. Halevy, P. Norvig, F. Pereira, ”The UnreasonableEffectiveness of Data,” IEEE Intelligent Systems, vol. 24,no. 2, pp. 8-12.
FR — Big Data Congress, Paris 2012 — 5/23

L’ere du ”Data Scientist”L’accumulation exponentielle de donnees transforme la demarche d’analyse
1960E. Wigner, ”The Unreasonable Effectiveness ofMathematics in the Natural Sciences,” Comm. Pure andApplied Mathematics, vol. 13, no. 1, pp. 1–14.
2009A. Halevy, P. Norvig, F. Pereira, ”The UnreasonableEffectiveness of Data,” IEEE Intelligent Systems, vol. 24,no. 2, pp. 8-12.
FR — Big Data Congress, Paris 2012 — 5/23

“ All models are wrong,but some are useful. ” George Box
FR — Big Data Congress, Paris 2012 — 6/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Data Scientist= nouveau metier?
Ce qui ne change pasI Le besoin en competences statistiques
(Bayesiennes, frequentistes etc...)I La demarche de questionnement et de critiqueI Les protocoles de collecte de donnees
Ce qui changeI Le stockage et le traitement de donneesI L’interaction entre modelisateurs, ingenieurs
systemes et bases de donnees et ... le client
FR — Big Data Congress, Paris 2012 — 7/23

Points cles
Vers une Science ultra-empirique?
Big Data pour la Recherche et l’Industrie : mode d’emploi
Hadoop et les donnees geographiques et temporelles
FR — Big Data Congress, Paris 2012 — 8/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

DefinitionI Big Data = gros volume (> 10 TB)
I Imagerie satellite 1-10 GB/jourI Systemes geolocalises (vehicules, personnes) 100
MB/jourI Modeles meteo 100 GB/jourI Simulateurs (traffic routier etc...) 100 GB/run
I Big Data + Big ProcessI Donnees pre-traitees (GPS) Cout d’analyse -I Aggregation, contextualisation Cout d’analyse +I Appels BD Cout d’analyse +++I Calculs en cascade Cout d’analyse +++
FR — Big Data Congress, Paris 2012 — 9/23

Diagnostic Big DataDocteur, ais-je un probleme Big Data?
Oui, si :I Vous avez un reseau d’observation autonome
(capteurs meteo, RFID, GPS, balises Argos,smartphones, telemetres, instruments sursatellites...)
I Vos donnees dependent d’une communauted’utilisateurs ou d’individus instrumentes (etude de lamobilite humaine, ecologie terrestre et marine etc... )
I Votre budget, programme de recherche ou businessplan prevoit de ”mesurer d’abord, traiter ensuite”
I Ces systemes de collecte produisent des flots dedonnees plus vite que vous ne pouvez les traiter
FR — Big Data Congress, Paris 2012 — 10/23

Diagnostic Big DataDocteur, ais-je un probleme Big Data?
Oui, si :I Vous avez un reseau d’observation autonome
(capteurs meteo, RFID, GPS, balises Argos,smartphones, telemetres, instruments sursatellites...)
I Vos donnees dependent d’une communauted’utilisateurs ou d’individus instrumentes (etude de lamobilite humaine, ecologie terrestre et marine etc... )
I Votre budget, programme de recherche ou businessplan prevoit de ”mesurer d’abord, traiter ensuite”
I Ces systemes de collecte produisent des flots dedonnees plus vite que vous ne pouvez les traiter
FR — Big Data Congress, Paris 2012 — 10/23

Diagnostic Big DataDocteur, ais-je un probleme Big Data?
Oui, si :I Vous avez un reseau d’observation autonome
(capteurs meteo, RFID, GPS, balises Argos,smartphones, telemetres, instruments sursatellites...)
I Vos donnees dependent d’une communauted’utilisateurs ou d’individus instrumentes (etude de lamobilite humaine, ecologie terrestre et marine etc... )
I Votre budget, programme de recherche ou businessplan prevoit de ”mesurer d’abord, traiter ensuite”
I Ces systemes de collecte produisent des flots dedonnees plus vite que vous ne pouvez les traiter
FR — Big Data Congress, Paris 2012 — 10/23

Diagnostic Big DataDocteur, ais-je un probleme Big Data?
Oui, si :I Vous avez un reseau d’observation autonome
(capteurs meteo, RFID, GPS, balises Argos,smartphones, telemetres, instruments sursatellites...)
I Vos donnees dependent d’une communauted’utilisateurs ou d’individus instrumentes (etude de lamobilite humaine, ecologie terrestre et marine etc... )
I Votre budget, programme de recherche ou businessplan prevoit de ”mesurer d’abord, traiter ensuite”
I Ces systemes de collecte produisent des flots dedonnees plus vite que vous ne pouvez les traiter
FR — Big Data Congress, Paris 2012 — 10/23

Diagnostic Big DataDocteur, ais-je un probleme Big Data?
Oui, si :I Vous avez un reseau d’observation autonome
(capteurs meteo, RFID, GPS, balises Argos,smartphones, telemetres, instruments sursatellites...)
I Vos donnees dependent d’une communauted’utilisateurs ou d’individus instrumentes (etude de lamobilite humaine, ecologie terrestre et marine etc... )
I Votre budget, programme de recherche ou businessplan prevoit de ”mesurer d’abord, traiter ensuite”
I Ces systemes de collecte produisent des flots dedonnees plus vite que vous ne pouvez les traiter
FR — Big Data Congress, Paris 2012 — 10/23

Diagnostic Big DataC’est grave, Docteur?
“ Tout ira bien,je vais vous prescrire du DevOps et des calculsdistribues. ”
FR — Big Data Congress, Paris 2012 — 11/23

Solutions Big Data
FR — Big Data Congress, Paris 2012 — 12/23
Solutions Big Data
Dev
FR — Big Data Congress, Paris 2012 — 12/23
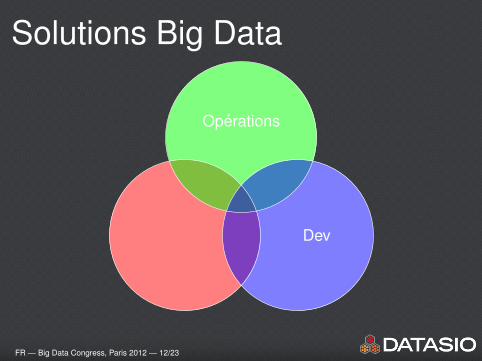
Solutions Big Data
Operations
Dev
FR — Big Data Congress, Paris 2012 — 12/23

Solutions Big Data
QA
Operations
Dev
FR — Big Data Congress, Paris 2012 — 12/23
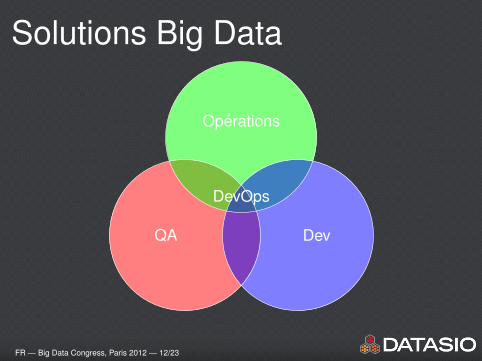
Solutions Big Data
QA
Operations
Dev
DevOps
FR — Big Data Congress, Paris 2012 — 12/23

Solutions Big Data
HierI Noeuds de
stockageperipheriques
I Stockage surplusieurs niveaux”chaud”/”froid”
I Supercalculateurau centre
I Data -> Code
FR — Big Data Congress, Paris 2012 — 13/23

Solutions Big Data
HierI Noeuds de
stockageperipheriques
I Stockage surplusieurs niveaux”chaud”/”froid”
I Supercalculateurau centre
I Data -> Code
FR — Big Data Congress, Paris 2012 — 13/23

Solutions Big Data
HierI Noeuds de
stockageperipheriques
I Stockage surplusieurs niveaux”chaud”/”froid”
I Supercalculateurau centre
I Data -> Code
FR — Big Data Congress, Paris 2012 — 13/23
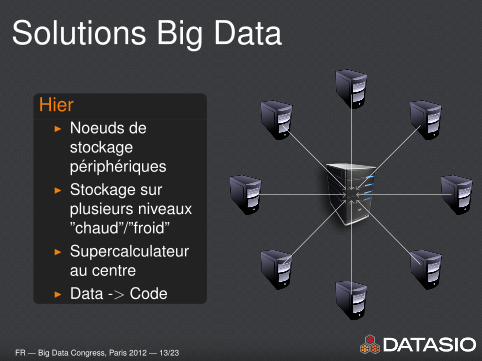
Solutions Big Data
HierI Noeuds de
stockageperipheriques
I Stockage surplusieurs niveaux”chaud”/”froid”
I Supercalculateurau centre
I Data -> Code
FR — Big Data Congress, Paris 2012 — 13/23

Solutions Big Data
Aujourd’huiI Noeuds de stockage sur meme reseau GBI Materiel milieu de gamme (100 - 1000 CPUs)I Systeme de fichiers distribues (DFS)I Gestion des jobs et donnees par des Master NodesI Code -> Data
FR — Big Data Congress, Paris 2012 — 14/23

Solutions Big Data
Aujourd’huiI Noeuds de stockage sur meme reseau GBI Materiel milieu de gamme (100 - 1000 CPUs)I Systeme de fichiers distribues (DFS)I Gestion des jobs et donnees par des Master NodesI Code -> Data
FR — Big Data Congress, Paris 2012 — 14/23

Solutions Big Data
Aujourd’huiI Noeuds de stockage sur meme reseau GBI Materiel milieu de gamme (100 - 1000 CPUs)I Systeme de fichiers distribues (DFS)I Gestion des jobs et donnees par des Master NodesI Code -> Data
FR — Big Data Congress, Paris 2012 — 14/23

Solutions Big Data
Aujourd’huiI Noeuds de stockage sur meme reseau GBI Materiel milieu de gamme (100 - 1000 CPUs)I Systeme de fichiers distribues (DFS)I Gestion des jobs et donnees par des Master NodesI Code -> Data
FR — Big Data Congress, Paris 2012 — 14/23

Solutions Big Data
Aujourd’huiI Noeuds de stockage sur meme reseau GBI Materiel milieu de gamme (100 - 1000 CPUs)I Systeme de fichiers distribues (DFS)I Gestion des jobs et donnees par des Master NodesI Code -> Data
FR — Big Data Congress, Paris 2012 — 14/23

Solutions Big Data
Aujourd’huiI Noeuds de stockage sur meme reseau GBI Materiel milieu de gamme (100 - 1000 CPUs)I Systeme de fichiers distribues (DFS)I Gestion des jobs et donnees par des Master NodesI Code -> Data
FR — Big Data Congress, Paris 2012 — 14/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Open source (fondation Apache, ouvert par Yahoo)I Projet en maturation, communaute activeI Parallelisation de taches et donnees robusteI Standard de facto en analyse de donnees massivesI Bonne interoperabilite avec les data warehouse et
BDs existantes (ETL, Hive, Sqoop)I Offres commerciales (support, packaging,
integration: IBM, Cloudera, AWS...)
FR — Big Data Congress, Paris 2012 — 15/23

Solutions Big Data
Pourquoi Hadoop?I Difficile a ”tuner” pour des jobs complexesI Encore confidentiel en France (cf. groupe Hadoop
France sur LinkedIn)I Difficile de formuler certains algorithmes sous forme
map-reduceI Embauche et formation de developpeurs et analystesI Autres alternatives disponibles (BSP, Storm, Disco...)
FR — Big Data Congress, Paris 2012 — 16/23

Solutions Big Data
Pourquoi Hadoop?I Difficile a ”tuner” pour des jobs complexesI Encore confidentiel en France (cf. groupe Hadoop
France sur LinkedIn)I Difficile de formuler certains algorithmes sous forme
map-reduceI Embauche et formation de developpeurs et analystesI Autres alternatives disponibles (BSP, Storm, Disco...)
FR — Big Data Congress, Paris 2012 — 16/23

Solutions Big Data
Pourquoi Hadoop?I Difficile a ”tuner” pour des jobs complexesI Encore confidentiel en France (cf. groupe Hadoop
France sur LinkedIn)I Difficile de formuler certains algorithmes sous forme
map-reduceI Embauche et formation de developpeurs et analystesI Autres alternatives disponibles (BSP, Storm, Disco...)
FR — Big Data Congress, Paris 2012 — 16/23

Solutions Big Data
Pourquoi Hadoop?I Difficile a ”tuner” pour des jobs complexesI Encore confidentiel en France (cf. groupe Hadoop
France sur LinkedIn)I Difficile de formuler certains algorithmes sous forme
map-reduceI Embauche et formation de developpeurs et analystesI Autres alternatives disponibles (BSP, Storm, Disco...)
FR — Big Data Congress, Paris 2012 — 16/23

Solutions Big Data
Pourquoi Hadoop?I Difficile a ”tuner” pour des jobs complexesI Encore confidentiel en France (cf. groupe Hadoop
France sur LinkedIn)I Difficile de formuler certains algorithmes sous forme
map-reduceI Embauche et formation de developpeurs et analystesI Autres alternatives disponibles (BSP, Storm, Disco...)
FR — Big Data Congress, Paris 2012 — 16/23

Solutions Big Data
Pourquoi Hadoop?I Difficile a ”tuner” pour des jobs complexesI Encore confidentiel en France (cf. groupe Hadoop
France sur LinkedIn)I Difficile de formuler certains algorithmes sous forme
map-reduceI Embauche et formation de developpeurs et analystesI Autres alternatives disponibles (BSP, Storm, Disco...)
FR — Big Data Congress, Paris 2012 — 16/23

Solutions Big Data
FR — Big Data Congress, Paris 2012 — 17/23

Solutions Big Data
HDFS
FR — Big Data Congress, Paris 2012 — 17/23

Solutions Big Data
HDFS
Map Reduce
FR — Big Data Congress, Paris 2012 — 17/23

Solutions Big Data
HDFS
Map Reduce HBase
FR — Big Data Congress, Paris 2012 — 17/23

Solutions Big Data
HDFS
Map Reduce HBase
Hive
FR — Big Data Congress, Paris 2012 — 17/23

Solutions Big Data
HDFS
Map Reduce HBase
Hive Pig
FR — Big Data Congress, Paris 2012 — 17/23

Solutions Big Data
HDFS
Map Reduce HBase
Hive Pig Mahout
FR — Big Data Congress, Paris 2012 — 17/23
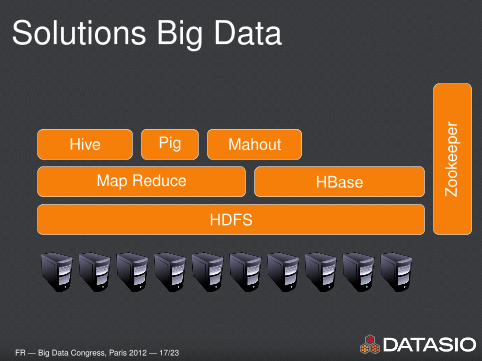
Solutions Big Data
HDFS
Map Reduce HBase
Hive Pig Mahout
Zook
eepe
r
FR — Big Data Congress, Paris 2012 — 17/23

Points cles
Vers une Science ultra-empirique?
Big Data pour la Recherche et l’Industrie : mode d’emploi
Hadoop et les donnees geographiques et temporelles
FR — Big Data Congress, Paris 2012 — 18/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytou Hadoop et les donnees geographiques et temporelles
BesoinI retraitement et fouille de donnees historiques
(geographiques et series temporelles)I Accelerer la decouverte d’anomalies et l’extraction de
valeur ajoutee
ProblematiqueI Donnees tres structurees - solution competitive?I Donnees correlees = pb du traitement independant?I Donnees stockees en fichiers binaires - distribution?I Algorithmes metier a reutiliser - interface Java?
FR — Big Data Congress, Paris 2012 — 19/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytTraitement d’images
I Extraction + tiling + renderingI Calculs massivement paralleles = gain de temps +++
FR — Big Data Congress, Paris 2012 — 20/23

Hadoop-xytGeolocalisation de vehicules
FR — Big Data Congress, Paris 2012 — 21/23

Transport terrestre
Transport aerien
Tracabilite
Telemetrie - Argos
Oceanographie
Imagerie satellite
FR — Big Data Congress, Paris 2012 — 22/23

DatasioWe are Data Scientists
Data Mining · Prototypage · Algorithmie ·Detection d’anomalies · Prediction · MachineLearning · Spatial data · Time series
Francois [email protected]
www.datasio.com
FR — Big Data Congress, Paris 2012 — 23/23






![RECRUITING TRENDS 2011 SUISSE - uni-bamberg.de...RECRUITING TRENDS 2011 SUISSE Bamberg et Francfort sur le Main, avril 2012 [Une étude empirique des 500 plus grandes entreprises suisses]](https://static.documents.pub/doc/80x56/5f25c64192bc6638b37354ad/recruiting-trends-2011-suisse-uni-recruiting-trends-2011-suisse-bamberg-et.jpg)










