46
Data Mining

Data Mining

Unsupervised Paradigm
M. Brescia - Data Mining - lezione 5 2
An unsupervised machine learning model will try to fit its parameters so as to best summarize
regularities found in the data.
supervised algorithms try to
minimize the error in classifying
observations or approximating
a non-linear function.
Unsupervised learning models
don't have such gain, because
there are no outcomes or target
labels.
Unsupervised algorithms try to
create clusters of data that are
inherently similar.

Unsupervised Process
M. Brescia - Data Mining - lezione 5 3
Differently from supervised algorithms, which aim at minimizing the prediction error,
unsupervised algorithms try to create groups or subsets of the data, in which points belonging
to a cluster are as similar to each other as possible, by making the difference between the
clusters as high as possible.
Another main difference is that in an unsupervised problem, the concept of training set does
not apply in the same way as with supervised learners. Typically we have a data set that is
used to find the relationships in the data that buckets them in different clusters.
1. Pre-processing of data. As with
supervised learners, this step includes
selection of features to feed into the
algorithm, by also scaling them to build a
suitable training data set;
2. Execution of model training. We run the
unsupervised algorithm on the scaled data
set to get groups of like observations;
3. Validation. After clustering the data, we
need to verify whether it cleanly
separated the data in significant ways.
This includes calculating a set of statistics
on the resulting outcomes, as well as
analysis based on domain knowledge.

The core business of unsupervised ML
M. Brescia - Data Mining - lezione 5 4
From a ML perspective clusters correspond to hidden patterns, the search for clusters is
unsupervised learning, and the resulting system could represent a data concept in the KDD
(Knowledge Discovery in Databases).
From a practical perspective clustering plays an outstanding role in DM applications such as
scientific data exploration, information retrieval and text mining, spatial database
applications, Web analysis, Customer Relationships Management (CRM), marketing, medical
diagnostics, computational biology, and many others
Data mining on MDS adds to clustering the complications of very large data sets with very
many attributes of different types (high dimensionality). This imposes unique computational
requirements on relevant clustering algorithms.
What are the properties of clustering algorithms we are concerned with in DM?
These properties include:
• Type of attributes that the algorithm can
handle;
• Scalability to large data sets;
• Ability to work with high dimensional
data (multi-D parameter space, multi-
wavelength, multi-epoch etc…);
• Ability to find clusters of irregular shape;
• Handling outliers;
• Time complexity (when there is no
confusion, we use the term complexity);
• Data order dependency;

Clustering general notation
M. Brescia - Data Mining - lezione 5 5
To fix the context and to clarify prolific terminology, we consider a dataset X consisting of data
points (or synonymously, objects, instances, cases, patterns, tuples, transactions):
( )
(feature) attribute
N:1i
space parameter
,...,1
lil
idii
Ax
A
Axxx
∈=
∈=Such point-by-attribute data format conceptually corresponds
to a N x d matrix.
The ultimate goal of clustering is to assign points to a finite system of k subsets, clusters. Usually
subsets do not intersect (this assumption is sometimes violated), and their union is equal to a
full dataset with possible exception of outliers:
Φ=⋅⋅⋅⋅⋅⋅⋅⋅⋅= 211 , jjoutliersk CCCCCX

Unsupervised Methods (UM) are applied without any a priori knowledge…
They cluster the data relying on their intrinsic statistical properties. The
understanding only takes place through labeling (very limited Knowledge Base).
“a blind man in a dark room - looking for a black cat - which may be not there”
Charles Bowen
to be honest it is full of cats, the problem is to find the cat interesting us…
Unsupervised Methods:
• need little or none a-priori knowledge;
• do not reproduce biases present in the
KB;
• require more complex error evaluation
(through complex statistics);
• are computationally intensive;
• are not user friendly (… more an art than
a science; i.e. lot of experience required)
M. Brescia - Data Mining – PRISMA - 2014
Machine Learning - Unsupervised

Train Set
Analysis of results Clustering
Clusters
Machine Learning - Unsupervised
The World
M. Brescia - Data Mining – PRISMA - 2014

Train Set
Clustering
New Knowledge
Clusters Analysis of results
Analysis of results Analysis of results
Machine Learning - Unsupervised
The World
M. Brescia - Data Mining – PRISMA - 2014

main clustering rules: COMPETITIVE
M. Brescia - Data Mining - lezione 5 9
La regola primaria è l’apprendimento competitivo (Competitive Learning)
Architettura a strati con neuroni completamente connessi tra loro (strati input e output).
Ogni neurone compete con gli altri, cercando di guadagnarsi il diritto di «rappresentare» una
tipologia di pattern e inviando segnali inibitori ai neuroni limitrofi (strategia Winner Takes All)
Alla fine del processo di training auto-organizzante, lo strato output avrà una serie di regioni
intorno ai neuroni vincenti (Best Matching Units) corrispondenti ai clusters individuati nei dati
input.
La rete così formata è capace di catturare le regolarità statistiche della sequenza di pattern
presentati : Kohonen Self Organizing Maps (T. Kohonen, 1990)
Prima del
training Strato di Input
Strato di outputVicinato BMU
BMU
Dopo il
training

main clustering rules: HEBBIAN
M. Brescia - Data Mining - lezione 5 10
In 1949, Donald Hebb proposed one of the key ideas in biological learning, commonly known
as Hebb’s Law. Hebb’s Law states that if neuron i is near enough to excite neuron j and
repeatedly participates in its activation, the synaptic connection between these two neurons
is strengthened and neuron j becomes more sensitive to stimuli from neuron i.
Hebb’s Law can be represented in the form of two rules:
1. If two neurons on either side of a connection are activated synchronously, then the
weight of that connection is increased.
2. If two neurons on either side of a connection are activated asynchronously, then the
weight of that connection is decreased.
Hebb’s Law provides the basis for learning without a teacher. Learning here is a local
phenomenon occurring without feedback from the environment.
i j
I n
p u
t
S i g
n a
l s
O u
t p
u t
S i g
n a
l s

Hebbian rule
M. Brescia - Data Mining - lezione 5 11
we can represent Hebb’s Law as follows:
where a is the learning rate parameter. This equation is referred to as the activity
product rule
)()()( pxpypw ijij =∆ a
Hebbian learning implies that weights can only increase. To resolve this problem, we might
impose a limit on the growth of synaptic weights. It can be done by introducing a non-linear
forgetting factor into Hebb’s Law:
where ϕ is the forgetting factor.
Forgetting factor usually falls in the interval between 0 and 1, typically between 0.01 and
0.1, to allow only a little “forgetting” while limiting the weight growth.
)()()()()( pwpypxpypw ijjijij ϕ−α=∆

Hebbian Learning algorithm
M. Brescia - Data Mining - lezione 5 12
Step 1: Initialisation.
Set initial synaptic weights and thresholds to small random values, in an interval [0, 1 ].
Step 2:Activation.
Compute the neuron output at iteration p
where n is the number of neuron inputs, and θj is the threshold value of neuron j.
j
n
iijij pwpxpy θ−=∑
=1)()()(
Step 3: Learning.
Update the weights in the network:
where ∆wij(p) is the weight correction at iteration p.
The weight correction is determined by the generalized activity product rule:
Step 4: Iteration.
Increase iteration p by one, go back to Step 2.
)()()1( pwpwpw ijijij ∆+=+
][ )()()()( pwpxpypw ijijij −λϕ=∆

Summary: Competitive vs Hebbian
M. Brescia - Data Mining - lezione 5 13
In Hebbian learning, several output neurons can be activated simultaneously,
In competitive learning, only a single output neuron is active at any time. Neurons compete
among themselves to be activated. The output neuron that wins the “competition” is called
the winner-takes-all neuron.
Inputlayer
x1
x2
Outputlayer
y
y2
1
y3 i j
I n
p u
t S
ig n
a l
s
O u
t p
u t
S ig
n a
l s
HebbianCompetitive
)()()()()( pwpypxpypw ijjijij ϕ−α=∆
Λ∉
Λ∈−=∆
)(,0
)(,)()(
][pj
pjpwxpw
j
jijiij

Full Taxonomy of Clustering models
M. Brescia - Data Mining - lezione 5 14
• Hierarchical Methods
• Agglomerative Algorithms
• Divisive Algorithms
• Partitioning Methods
• Relocation Algorithms
• Probabilistic Clustering
• K-medoids Methods
• K-means Methods
• Density-Based Algorithms
• Density-Based Connectivity Clustering
• Density Functions Clustering
• Grid-Based Methods
• Methods Based on Co-Occurrence of Categorical Data
• Clustering Algorithms Used in Machine Learning
• Artificial Neural Networks, Fuzzy and Hybrid Systems
• Evolutionary Methods
• Constraint-Based Clustering
• Algorithms For High Dimensional and Scalable Data
• Subspace Clustering
• Projection Techniques
• Co-Clustering Techniques
brescia_clusteringSurvey_DAME-NA-PRE-0031.pdf
In the following we will
shortly discuss among them…

Metriche per clustering
M. Brescia - Data Mining - lezione 5 15
��� � � ∑ min � � � � , ������������� � ������������������������ù������!�"#$ �, � � min�, � � , ������������� � ���������������������������%�� � �����%�
"&$ �, � � max�. � � , ������������� � ��������������������������!����� � �����%�
Siano dati:*+, *, %��������������∙ ���!�.��������/ � ������������� � �������������������������!"/ �, � ������������� � �������������������������! +, , ��!������������������������������
*.� � 1 �1 2 �34∈67 , ��������������������8 �&9 � � ∑ 34:6;74 <7 , ������������� � �������������������������"&9 �, � � *.+ � *., , ������������� � ��������������������������=> � � ∑ � � �, �? � � � 1 , ������������� � ������������������!����"=> �, � � ∑ � � �, �? + , , ������������� � ������������������!����

Metriche per clustering
M. Brescia - Data Mining - lezione 5 16
La selezione di uno di questo metodi dipende dal campo di applicazione. Molti di questi
infatti risultano inadeguati in talune situazioni.
Le distanze basate invece sulla media sono computazionalmente costose da calcolare su
dataset di grandi dimensioni.
La distanza basata sul criterio del complete-linkage (o massima distanza euclidea tra due
cluster, basata sui due oggetti dei rispettivi cluster più lontani tra loro), sebbene utilizzata i
molti algoritmi di tipo agglomerativo, richiede, per agire in maniera ottimale, cluster molto
compatti e ben separati, condizione che raramente è riscontrabile nei casi reali.
Le distanze basate sul vicino più prossimo e sul criterio del single-linkage (o minima distanza
euclidea tra due cluster, basata sui due oggetti dei rispettivi cluster più vicini tra loro), sono
eccessivamente sensibili al rumore ed agli outliers. Anche un solo punto è infatti in grado di
influenzare notevolmente il calcolo.
��� � � ∑ min � � � � , ������������� � ������������������������ù������!�"#$ �, � � min�, � � , ������������� � ���������������������������%�� � �����%�
"&$ �, � � max�. � � , ������������� � ��������������������������!����� � �����%�

Main Clustering Taxonomy
M. Brescia - Data Mining - lezione 5 17
Hierarchical
Build clusters
gradually (as they
grow up)
Partitioning
Learn clusters directly
Relocation
Try to discover clusters by iteratively
relocating points between subsets
Density-based
Try to discover dense connected
components of data, which are flexible
in terms of their shape
Probabilistic, K-means
Concentrate on how well points fit into
their clusters and tend to build
clusters of proper convex shapes

Hierarchical Clustering
M. Brescia - Data Mining - lezione 5 18
Il clustering gerarchico consiste in una sequenza di partizionamenti organizzati in una
struttura di tipo gerarchico nota come dendogramma. Questo tipo di clustering ha il
vantaggio di non dover specificare a priori il numero di cluster, tuttavia la complessità è
maggiore: tipicamente O(N2).
A seconda dell’approccio seguito, gli algoritmi di clustering gerarchico possono essere
classificati in:
Algoritmi agglomerativi: seguono una strategia bottom-up, operando come segue:
Assegnazione di ogni pattern al proprio cluster;
Calcolo delle distanze tra tutti i cluster;
Unione dei due cluster più vicini tra loro;
Torna al passo 2 finché non è rimasto un solo cluster
o il minimo numero possibile di clusters.
Algoritmi divisivi: seguono una strategia top-down che opera analogamente a quanto
descritto precedentemente, sebbene si parta da un unico cluster contenente tutti i punti,
per poi dividerli finché ogni cluster non sia composto dal minimo numero di punti, come
mostrato.Gli algoritmi di clustering gerarchico non forniscono un
clustering unico. Infatti, a seconda di dove venga “tagliato”
il dendogramma, verrà prodotto un clustering differente.

Hierarchical Clustering
M. Brescia - Data Mining - lezione 5 19
Sequenza di partizionamenti organizzati in una struttura di tipo gerarchico
(bottom-up o top-down)
Agglomerative Divisive
Complessità O( N2 )
Non può incorporare conoscenza a priori di forma e grandezza dei cluster
Non è permesso approccio fuzzy, poiché non contempla intersezione fra clustersallo stesso livello di gerarchia
Esempio di
Clustering
gerarchico con
approccio
top-down
Dendogramma
relativo
Esempio di
Clustering
gerarchico
con approccio
Bottom-up

Partitional Clustering
M. Brescia - Data Mining - lezione 5 20
1
Appartengono a questa categoria tutti quegli algoritmi che partizionano i dati, operando
nel seguente modo:
1 Calcolo del numero di cluster;
2 Inizializzazione dei centri dei cluster;
3 Partizionamento dei dati in base ai centri calcolati ed alle relative distanze;
4 Aggiornamento dei centri dei cluster;
5 Se il partizionamento è cambiato e non è stato raggiunto un criterio d’arresto, torna al
punto 3.
Risulta evidente che in questo tipo di approccio il numero di cluster deve essere specificato
a priori o selezionato dinamicamente cercando di minimizzare una qualche misura di
validità.
Una soluzione ampiamente adottata è per esempio quella di minimizzare la distanza intra-
cluster e contemporaneamente massimizzare quella inter-cluster.
Tipicamente la complessità degli algoritmi appartenenti a tale categoria è O(N), dove N è il
numero di pattern input.
Partitional Clustering
M. Brescia - Data Mining - lezione 5 21
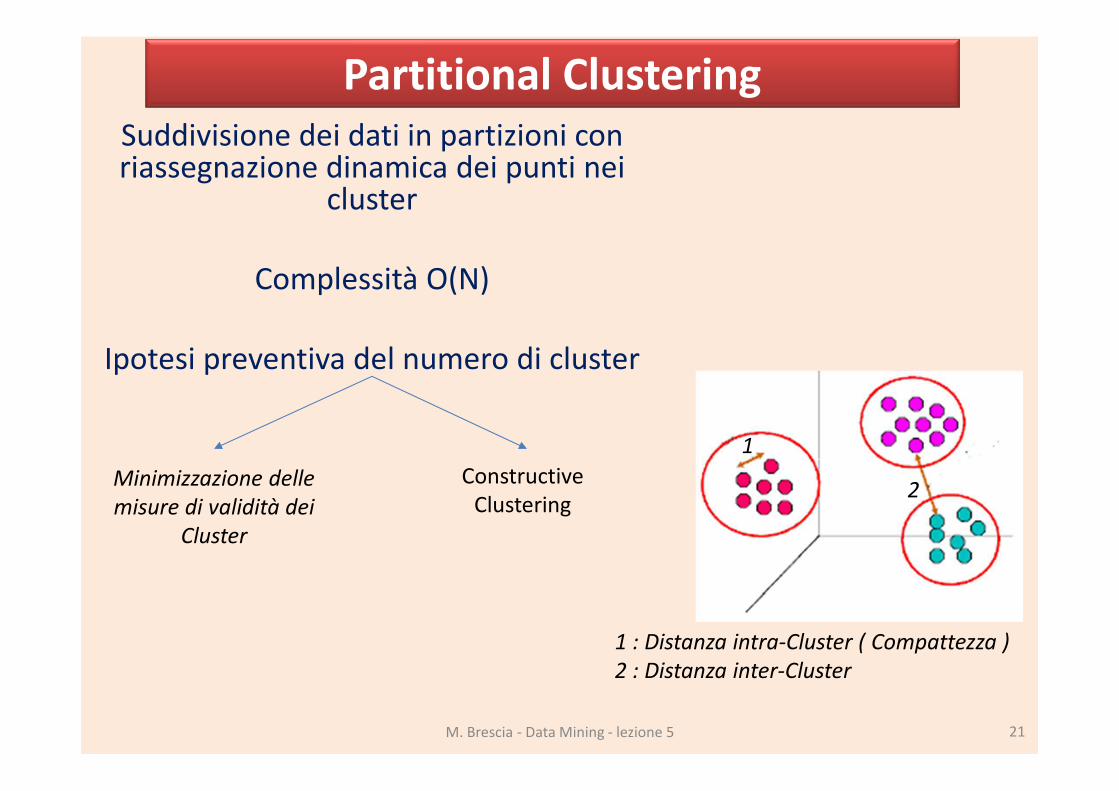
Suddivisione dei dati in partizioni con riassegnazione dinamica dei punti nei
cluster
Complessità O(N)
Ipotesi preventiva del numero di cluster
1 : Distanza intra-Cluster ( Compattezza )
2 : Distanza inter-Cluster
Minimizzazione delle
misure di validità dei
Cluster
Constructive
Clustering
1
2

Crisp/Fuzzy Partitional Clustering
M. Brescia - Data Mining - lezione 5 22
Crisp Clustering: appartenenza totale o nulla
Fuzzy Clustering: Appartenenza di un pattern ad un
cluster può variare in maniera continua tra 0 e 1
Matrice di Appartenenza U = {µji}, µji ϵ [0,1]
Vincolo :
Generazione di Cluster Sovrapposti
(ammessi nel caso fuzzy)

Density-based Clustering
M. Brescia - Data Mining - lezione 5 23
Density-based methods are basically less sensitive to outliers and can discover clusters of
irregular shapes. They usually work with low-dimensional data of numerical attributes, known
as spatial data. Spatial objects could include not only points, but also extended objects.
Raggruppamenti in base
a parametri di densità
Complessità O( N2 )

Clustering with Machine Learning
M. Brescia - Data Mining - lezione 5 24
Machine Learning for
Clustering
topology-based
Neural Gas
Evolutionary Methods
genetic algorithms
ANN, Fuzzy, Hybrid systems
K-means, ART, SOM, VQ etc…
Hybrid (Soft Computing)
LVQ, MLC, NG-CHL, RBF-NDR

Self Organizing Maps
M. Brescia - Data Mining - lezione 5 25
Strato di Input
Strato di KohonenVicinato BMU
BMUFunzione a Mexican Hat
Struttura classica dell’ apprendimento competitivo
Funzione di vicinato determina range aggiornamento pesi
Attivazione decresce secondo la funzione a Mexican Hat
Legge di Kohonen per l’aggiornamento dei pesi:

SOM Algorithm
M. Brescia - Data Mining - lezione 5 26
1. @AB
CDE� valori di inizializzazione piccoli e casuali ordinati sulla griglia, dove � � 1… �, G �
1…�
2. Seleziona pattern di neuroni di input HI � HJI, HK
I, … , HLI
3. " � C"N, … , "$E vettore delle distanze tra il pattern in input ed i pesi dei neuroni dove
OA � LAPQCHI, @AQE� LAPQ HI, @B
Q � ∑ CHBI �@AB
QEKL
BRJ
4. Seleziona il BMU index tale che STUVWXYZ[ � \AICOE
5. Aggiorna i pesi nel modo seguente: @ABQ]J
� @ABQ^ ∆@AB
Q
6. Torna al passo 2 finché non è raggiunto un criterio di arresto
@ABQ]J
� @ABQ^ ∆@AB
Q� `@AB
CQE� aQb
c W, TUVWXYZ[ C[dX �eWd
c E
f, è il fattore di rapidità dell’algoritmo. In genere questo valore può essere costante in t, oppure assumere
valori che decrescono progressivamente. In generale valori elevati permettono un apprendimento elevato
ma al tempo stesso rischioso a causa dell’elevata dimensione che caratterizza il passo dell’apprendimento.
Lineare;
Esponenziale: f, � fgexpC�,
jE decresce nel tempo, basandosi anche su k, un parametro che non
varia durante l’esecuzione dell’algoritmo, in genere dipendente dal massimo numero di iterazioni
che si vuole eseguire;

SOM Algorithm
M. Brescia - Data Mining - lezione 5 27
ΛC,E è la funzione di vicinanza. Dati due indici dei pesi dei neuroni �Ne�m la funzione restituisce il fattore
vicinanza 0 o Λ p iN, im o 1. Il suo compito è quello di simulare la diffusione dell’apprendimento ai
neuroni vicini del BMU, simulando il comportamento già descritto. Il modello non specifica rigide direttive
per la sua realizzazione e le soluzioni sono dunque molteplici, a seconda del tipo di aggiornamento del
vicinato richiesto. Le varianti più note sono:
@ABQ]J � @ABQ ^ ∆@ABQ � `@ABCQE � aQb c W, TUVWXYZ[ C[dX �eWdc E
Bubble: la funzione restituisce 1 o 0 a seconda se ci si trovi entro il raggio del BMU:
b Q AJ, AK � qJ, ArLstAL AJ, AK u tD, vwPv con LstALCAJ, AKE = distanza in step lungo la griglia;
Gaussian: la funzione restituisce valori compresi tra 0 e 1 che si distribuiscono intorno al BMU come una
comune gaussiana. Nel caso venga usata questa tipologia di soluzione, la funzione necessita di ulteriori
parametri per la modellazione della forma della gaussiana. In tal caso potremmo calcolare:
b Q AJ, AK � Z[x � LstAL AJ,AKKyQK con yQ � yDZ[xC� QzE , funzione decrescente nel tempo con
andamento esponenziale. Come k, anche {g è un parametro costante pre-calcolato;
Cutted-Gaussian: un mix fra i due precedenti che, entro un certo raggio, restituisce un valore gaussiano;
ma al di fuori del raggio restituisce valore zero.

Example
M. Brescia - Data Mining - lezione 5 28
Bubble
Gaussian

Example: initial random weights
M. Brescia - Data Mining - lezione 5 29
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
W(2
,j)
W(1,j)

Example: after 100 iterations
M. Brescia - Data Mining - lezione 5 30
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1
W(2
,j)
W(1,j)

Example: after 1000 iterations
M. Brescia - Data Mining - lezione 5 31
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1
W(2
,j)
W(1,j)

Example: after 10.000 iterations
M. Brescia - Data Mining - lezione 5 32
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1
W(2
,j)
W(1,j)

Example of SOM algorithm
M. Brescia - Data Mining - lezione 5 33

Example of SOM algorithm
M. Brescia - Data Mining - lezione 5 34

Example of SOM algorithm
M. Brescia - Data Mining - lezione 5 35

SOM visualization: U-Matrix
M. Brescia - Data Mining - lezione 5 36
La U-Matrix (Unified Distance Matrix) è lo standard per la valutazione e l’interpretazione di
una SOM. Durante l’addestramento della rete i pesi dei neuroni sono calcolati in maniera tale
che elementi vicini tra loro sulla mappa siano anche vicini nello spazio dei pesi. In questo
modo lo strato di Kohonen è in grado di rappresentare, rispettando la topologia, dati multi-
dimensionali su una mappa di due o tre dimensioni.
Siano
Ad ogni nodo dello strato di Kohonen verrà assegnato un valore secondo la seguente
formula: |}vAs}Q I � 2 @ I ,@C\E\∈~~CIE
�, ������������!���� � , �����!�������������������������!����� � , ���������������������������������� � ,�C!E , �����������������������������������������������!��9���,C�E, ������C����E����������������

SOM visualization: U-Matrix
M. Brescia - Data Mining - lezione 5 37
Il valore così calcolato diventa identificativo della distanza di un nodo da tutti i suoi vicini più
prossimi ed è visualizzabile utilizzando una heat map in cui colori chiari rappresentano
neuroni vicini tra loro nello spazio dei pesi, viceversa colori scuri rappresentano neuroni
lontani tra loro.
Tipicamente si usa rappresentare la mappa con una scala di grigi. Per aumentare
ulteriormente il grado di interpretabilità della U-Matrix si sovrappone ad ogni nodo BMU di
qualche pattern un colore che ne identifichi il cluster di appartenenza. Ovviamente, i nodi,
su cui non è sovrapposto alcun quadratino colorato, non sono mai risultati BMU di qualche
pattern input.

Indici di qualità della SOM
M. Brescia - Data Mining - lezione 5 38
Per valutare la qualità di una mappa ottenuta come primo stadio di un processo di
clustering, ci si può domandare:
i. Qual è il grado di continuità della mappa topologica?
ii. Qual è la risoluzione della mappa?
iii. La topologia della mappa riflette la probabilità di distribuzione dello spazio dei dati?
Per quanto concerne il terzo punto, in letteratura sono presenti diversi esempi di SOM con
struttura incrementale in grado di preservare la topologia dello spazio dei dati (vedremo il
modello E-SOM).
La quantificazione delle prime due proprietà può essere invece ottenuta tramite il calcolo
dell’errore di quantizzazione e dell’errore topografico.
I risultati di un clustering possono anche essere valutati tramite l’utilizzo dell’indice statistico
di Davies-Bouldin (DB), nonché di indici di valutazione facilmente derivabili avendo una base
di conoscenza a priori sul dataset, rispettivamente Indice di Accuratezza (ICA) e Completezza
(ICC) di clustering

Errore di quantizzazione
M. Brescia - Data Mining - lezione 5 39
L’errore di quantizzazione viene utilizzato per calcolare la similarità tra i pattern assegnati al
medesimo BMU. Di seguito è mostrata la formula per il calcolo del suddetto errore.
�� � J~∑ @��|A � HA~ARJdove����� � ��������������������9#�/� BMU
� ��!�����������������!���%������������� � �9#�/���������������������������������������������La formula corrisponde alla media delle distanze di ogni pattern dal vettore dei pesi del BMU
che lo identifica.

Errore topografico
M. Brescia - Data Mining - lezione 5 40
L’errore topografico viene utilizzato per calcolare la dissimilarità tra i pattern assegnati a
BMU differenti. Anche per questo errore di seguito viene fornita la formula.
�� � J~∑ � @A~Adove
� ��!�����������������!���%������������� � � q1, �������!��������������������9#�/������������������������0, �����!����La formula corrisponde quindi alla media del numero di volte in cui, per uno stesso
pattern, primo e secondo BMU non sono adiacenti sulla griglia dello strato di Kohonen.
Per primo e secondo BMU si intende in termini di vicinato (vettore dei pesi) rispetto al
pattern di riferimento nella mappa di Kohonen.

Indice di Davies-Bouldin
M. Brescia - Data Mining - lezione 5 41
Tale indice misura il rapporto tra la distribuzione intra-cluster e le distanze inter-cluster,
misurate a partire dai centroidi.
La distribuzione interna del cluster Ci può essere espresso come segue:�A,� � J�A ∑ HA � � � J/�HA∈�A , A � J…�dove *� denota il numero di vettori in input assegnati al suddetto cluster; xi e z
rappresentano rispettivamente un vettore di input del �9#�/� cluster e il centroide del cluster
stesso; q è un valore assoluto; K rappresenta il numero totale di cluster.
Successivamente la distanza tra due cluster Ci e Cj può essere scritta come:LAB,Q � �A � �B Q � ∑ �PA � �PB QOPRJ J/Qdove zi e zj rappresentano rispettivamente i centroide del �9#�/� e G9#�/� cluster; zsi e zsj
denotano il valore assoluto della differenza tra I vettori zi e zj calcolata sulla dimensione s; D
è il numero di dimensioni dei vettori in input; t è un valore assoluto.
L’indice di Davies-Bouldin (DB) può quindi essere espresso dalla seguente equazione:O� � J�∑ ��[B,B?A �A,�]�B,�LAB,Q�ARJDalla formula risulta evidente che a valori bassi del suddetto indice corrisponde un
clustering migliore.

Indici di Accuratezza e completezza
M. Brescia - Data Mining - lezione 5 42
Si assuma di avere a disposizione le seguenti quantità:
*, � ��!������������������� *& � ��!��������������������� *� � ��!���������������%�����In particolare, definiremo due cluster teorici disgiunti se l’intersezione delle label attribuite
dal clustering (cioè calcolate) nei due cluster risulta l’insieme vuoto.
Indice di Accuratezza di Clustering (ICA o Index of Clustering Accuracy):
��� � ~��:~�Q~��]~�QIndice di Completezza di Clustering (ICC o Index of Clustering Completeness):
��� � J � ~�L~�Q

Indici di Accuratezza e completezza
M. Brescia - Data Mining - lezione 5 43
Tali indici devono permettere di valutare il clustering in presenza di outliers, cioè di oggetti
peculiari nello spazio dei parametri, così come in dati distribuiti in modo non lineare, per i
quali gruppi di dati distanti, ma appartenenti alla stessa categoria, possono essere
erroneamente attribuiti a categorie distinte (cluster disgiunti).
Naturalmente, per costruzione, il calcolo di tali indici presuppone che l’esito del training di
un modello su un dataset possa essere confrontato con una base di conoscenza a priori sul
numero e attribuzione dei cluster teorici per il dataset.
Come si evince dalle equazioni precedenti, i due indici restituiscono valori compresi tra 0 e 1
(ICA in [0, 1[ e ICC in [0, 1]).
La qualità di un esperimento di clustering ha un’elevata accuratezza quando l’indice ICA è
pari a zero. In tal caso infatti il numero di cluster calcolati sul dataset corrisponde al numero
di cluster attesi. Quanto più il numero di cluster calcolati diverge, in più o in meno, dal
numero di cluster attesi, tanto più vicino a 1 tenderà l’indice ICA.
L’elevata completezza di clustering, ossia la congruenza tra numero di cluster calcolati e
numero di cluster disgiunti, è garantita quando l’indice ICC è pari a zero.

Riepilogo indici di qualità clustering
M. Brescia - Data Mining - lezione 5 44
Indice di Davies-Bouldin
Rapporto tra distanza intra-cluster ed inter-cluster
Errore di quantizzazione
Similarità degli input assegnati al medesimo BMU
Errore topografico
Dissimilarità degli input assegnati a BMU differenti
Indice di accuratezza
Rapporto tra cluster attesi ed individuati
Indice di completezza
Disgiunzione dei cluster
Distanza intra-clusterDistanza inter-cluster

Two-stage clustering
M. Brescia - Data Mining - lezione 5 45
Lo scopo dell’attuazione di un metodo di clustering a due stadi è quello di superare i
principali problemi di cui sono afflitti i metodi convenzionali, come la sensibilità ai prototipi
iniziali (proto-cluster) e la difficoltà di determinare un appropriato numero di cluster attesi.
L’approccio maggiormente utilizzato è la combinazione di una tecnica di clustering
gerarchico o una SOM, seguita da una tecnica di clustering partizionale.
La funzione della SOM al primo stadio è quella di identificare un numero iniziale di cluster e
relativi centroidi, superando, di fatto, i problemi precedentemente descritti. Nel secondo
stadio invece, una tecnica di clustering partizionale assegnerà in maniera definitiva un
cluster per ogni pattern.
Il vantaggio principale risiede nel fatto che il secondo stadio viene applicato a partire dai
nodi (proto-cluster) dello strato di Kohonen, che generalmente sono in numero inferiore ai
pattern input.
Tale tecnica si traduce quindi in un notevole vantaggio dal punto di vista computazionale. In
tal caso però potrebbe essere necessaria la scelta di un numero di cluster attesi (clustering
partizionale).

References
M. Brescia - Data Mining - lezione 5 46
Du, K.L., 2010. Clustering: A neural network approach. Neural Networks, Elsevier, Vol. 23, 89-
107
Tomenko, V., 2011. Online dimensionality reduction using competitive learning and Radial
Basis Function network. Neural Networks, Elsevier, Vol. 24, 501-511
Review on Clustering on DAME site: brescia_clusteringSurvey_DAME-NA-PRE-0031.pdf
Kohonen, T., 1990. The self-organizing map. Proceedings of IEEE, 78, 14641480
Kohonen, T., 1982. Self-organized formation of topologically correct feature
maps. Biological Cybernetics, 43:59-69
Hartigan, J. A.; Wong, M. A. (1979) “A K-means clustering algorithm,” Applied Statistics, 28,
100–108
Yager, R. R., & Filev, D. (1994). Approximate clustering via the mountain method. IEEE
Transactions on Systems Man and Cybernetics, 24(8), 12791284
Grossberg, S. (1976). Adaptive pattern classification and universal recording: I. Parallel
development and coding of neural feature detectors; II. Feedback, expectation, olfaction, and
illusions. Biological Cybernetics, 23, 121134. 187202
Martinetz, T. M., Berkovich, S. G., & Schulten, K. J. (1993). Neural-gas network for vector
quantization and its application to time-series predictions. IEEE Transactions on Neural
Networks, 4(4), 558569

















