Asymptotic Properties of White’s Test for Heteroskedasticity and the Jarque-Bera Test for Normality Carlos Caceres Nuffield College, University of Oxford Bent Nielsen Nuffield College, University of Oxford March 2006 Abstract The aim of this paper is to analyse the asymptotic properties of White’s test for heteroskedasticity and those of the Jarque-Bera test for normality from a time series perspective. For this purpose, we study the characteristics of these tests when applied to a first order autoregressive model with independent, identically and normally distributed errors. It will be proved here that White’s test for het- eroskedasticity is theoretically valid, and thus certainly applicable, in both the case of a stationary autoregressive process and in that of an autoregressive process with a unit root (i.e. a marginally stable autoregressive process or random walk). However, it will be shown that White’s test for heteroskedasticity is not valid when applied to an explosive autoregressive process. On the other hand, it is proved here that the Jarque-Bera test for normality is parameter independent. This means that this normality test can be applied to any first order autoregres- sive process, regardless of whether the latter contain a stationary, a unit or an explosive root. i
Transcript
Asymptotic Properties of White’s Test forHeteroskedasticity and the Jarque-Bera Test for
Normality
Carlos CaceresNuffield College, University of Oxford
Bent NielsenNuffield College, University of Oxford
March 2006
Abstract
The aim of this paper is to analyse the asymptotic properties of White’s test
for heteroskedasticity and those of the Jarque-Bera test for normality from a time
series perspective. For this purpose, we study the characteristics of these tests
when applied to a first order autoregressive model with independent, identically
and normally distributed errors. It will be proved here that White’s test for het-
eroskedasticity is theoretically valid, and thus certainly applicable, in both the
case of a stationary autoregressive process and in that of an autoregressive process
with a unit root (i.e. a marginally stable autoregressive process or random walk).
However, it will be shown that White’s test for heteroskedasticity is not valid
when applied to an explosive autoregressive process. On the other hand, it is
proved here that the Jarque-Bera test for normality is parameter independent.
This means that this normality test can be applied to any first order autoregres-
sive process, regardless of whether the latter contain a stationary, a unit or an
In Halbert White’s words (1980), the presence of heteroskedasticity in an otherwiseproperly specified linear model leads to consistent but inefficient parameter estimatesand faulty inference when testing statistical hypotheses. In other words, heteroskedas-ticity represents a serious problem in statistics and has to be taken into considerationwhen performing any econometric application that could be affected by the latter.Therefore, many statisticians have put a lot of effort into the elaboration of diagnostictests enabling accurate detection of heteroskedasticity.
In particular, a widely and commonly used test for heteroskedasticity is that pro-posed by White himself (1980). Nowadays, several econometrics software packages,such as PCGive, Stata and EViews, include this test - or an adaptation of it - amongsttheir key features. Nonetheless, White seems to have proposed this test without havinghad time series applications directly in mind. He only considered the case where theregressors were a sequence of independent random variables. Thus this test was prob-ably inspired by cross-section data analysis instead. The same applies to Amemiya’swork (1977) whose results also assumed the absence of lagged dependent variables.
In fact, only few results are available regarding the theoretical validity of White’stest for heteroskedasticity in a model including lagged endogenous variables. Kelejian(1982) only proved that the test is applicable in the stable (stationary) case, but didnot consider a more general case. A similar result was presented by Godfrey and Orme(1994). In addition the latter argue that White’s test is ineffective in the presenceof omitted variables. Doornik (1996) suggested that under simplifying assumptionsKelejian’s result reduces to a multivariate extension of White’s test. He seemed toassert the legitimacy of the latter but did not explicitly specify any restriction on theparameters of interest. This also applies to the paper by Ali and Giaccotto (1984).Wooldridge (1999) mentioned that this and other heteroskedasticity tests have not yetbeen truly analysed in the unit root case for which the use of the Functional CentralLimit Theorem would be required.
Another important mis-specification test is the normality test due to Jarque andBera (1980). Many econometric models and results are based on the fact that somevariables follow a normal distribution. In particular the maximum likelihood estimatorcoincides with the OLS estimator when normality is assumed. Thus the importance ofhaving a theoretical test for normality that can be used in time series analysis.
In the case of the Jarque-Bera test for normality, some studies in the past haveanalysed its validity when dealing with stationary autoregressive processes. Notablythe contribution of Lutkepohl and Shneider (1989). Other authors have expanded thisissue to accommodate for more general models. Kilian and Demiroglu (2000) proved thevalidity of the Jarque-Bera’s normality test for Vector-Error Correction (VEC) modelsand for unrestricted Vector Autoregression (VAR) models with possibly integrated orcointegrated variables. Yet, theoretical results regarding the validity of the Jarque-Beratest for normality in the general case are not available.
In this paper, the asymptotic properties of White’s test for heteroskedasticity andthat of the Jarque-Bera test for normality are analysed from a time series econometrics
1
perspective. Unfortunately, it is found that the validity of White’s test for heteroskedas-ticity depends upon the value of the parameters of interest. In more concrete words,this test may work well for some values of these parameters and yet it may not workfor others. It will be shown here that White’s test for heteroskedasticity is indeed validin the unit root case, but no longer valid in the explosive case.
This is a significant theoretical result. It implies that in order to do statisticalinference on the parameters of interest we need to know if heteroskedasticity is presentin the model. But, to test for heteroskedasticity we need to know the value of theseparameters! As a consequence, any applied statistician should not use this test unlesshe/she is completely certain of dealing with data from a stationary or marginally stableprocess.
It is important to mention that this drawback is not a general feature of all mis-specification tests. Remarkably, the results obtained here regarding White’s heteroskedas-ticity test are, for instance, in contrast to the theoretical outcome obtained also in thispaper for the Jarque-Bera normality test. The latter is in fact valid in all three, station-ary, unit root and explosive cases. Another example would be the findings of Nielsen(2001) regarding the tests for lag length. Nielsen proved that the methods used fororder determination in general vector autoregressions are valid regardless of the valuesof the characteristic roots. In other words, the validity of these lag length tests doesnot depend upon the values of the parameters of interest. Again, this is not the casein White’s heteroskedasticity test.
Before presenting White’s test for heteroskedasticity and the Jarque-Bera’s test fornormality in a formal way, some notation should be introduced.
1.1 Notation
The following notation is used throughout this paper:
N0 denotes the set of all positive integers (including zero)
N denotes the set of all strictly positive integers
Z denotes the set of all integers
R denotes the set of all real numbers
∀n ∈ N, [[1, n]] = [1, n] ∩ N
Rn×n denotes the field of square matrices of dimension n and with general term in R
Rn denotes the set of vectors of dimension n and with all terms in R
∀M ∈ Rn×n and ∀V ∈ Rn, MT and V T denote the transpose of M and V respectively
2
i.i.d. stands for independent and identically distributed
Having introduced the above notation, we are now in the position to formally presentWhite’s test for heteroskedasticity in a time series context.
1.2 White’s test for Heteroskedasticity
As we said earlier, our workhorse in this paper is a first order autoregressive model (orAR(1) model). Thus, lets start by defining the latter in a more formal way.
Let (X0, X1, ..., XT ) be a one-dimensional time series satisfying the first order au-toregressive equation:
Xt = αXt−1 + εt for t = 1, ..., T (1)
where (εt) is a sequence of i.i.d. normally distributed random shocks and α ∈ Rrepresents the parameter of interest (i.e. the parameter space).
In order to test for heteroskedasticity in the AR(1) model presented above, White’sidea is basically equivalent to the use of the following auxiliary model :
ε̂t2 = β0 + β1Xt−1 + β2X
2t−1 + ut for t = 1, ..., T (2)
where (ε̂t) are the least square residuals from regression (1).In this sense, one needs to consider the constant-adjusted squared multiple correla-
tion coefficient R2 from the regression exhibited in equation (2). This is given by:
R2 = S−100 .S01.S
−111 .S10 (3)
Where:S00 ∈ R and S00 = 1
T
∑Tt=1 R2
0t
S10 ∈ R2 and S10 = 1T
∑Tt=1 R0t.R1t
S01 ∈ R2 and S01 = ST10
S11 ∈ R2×2 and S11 = 1T
∑Tt=1 R1t.R
T1t
And:
R0t ∈ R and R0t = (ε̂2t − ε̂2)
R1t ∈ R2 and R1t =
Xt−1 −X
X2t−1 −X2
where the ‘bar’ over a random variable denotes the sample mean of that random vari-able, i.e. X = 1
T
∑Tt=1 Xt−1 or the second sample moment in the case of ε̂2 = 1
T
∑Tt=1 ε̂t
2
3
and X2 = 1T
∑Tt=1 X2
t−1.
Therefore, the main components of the significant statistic S00, S10 and S11 presentedabove can be decomposed in the following way:
S00 = 1T
∑Tt=1(ε̂
2t − ε̂2)
2
= 1T
∑Tt=1 ε̂4
t −(
1T
∑Tt=1 ε̂2
t
)2
S10 = 1T
∑Tt=1(ε̂
2t − ε̂2) ·
(Xt−1 −XX2
t−1 −X2
)
=
1T
∑Tt=1(ε̂
2t − ε̂2)(Xt−1 −X)
1T
∑Tt=1(ε̂
2t − ε̂2)(X
2t−1 −X2)
And:
S11 = 1T
∑Tt=1
(Xt−1 −XX2
t−1 −X2
)·(
Xt−1 −XX2
t−1 −X2
)T
=
1T
∑Tt=1(Xt−1 −X)2 1
T
∑Tt=1(Xt−1 −X)(X2
t−1 −X2)
1T
∑Tt=1(Xt−1 −X)(X2
t−1 −X2)1T
∑Tt=1(X
2t−1 −X2)
2
=
1T
∑Tt=1 X2
t−1 −X2 1
T
∑Tt=1 X3
t−1 −X ·X2
1T
∑Tt=1 X3
t−1 −X ·X21T
∑Tt=1 X4
t−1 −X2
2
And, assuming that model (1) is true we have ε̂t = εt − (α̂− α)Xt−1, with (α̂− α)given by:
(α̂− α) =1T
∑Tt=1 Xt−1εt
1T
∑Tt=1 X2
t−1
(4)
Hence the above expressions for S00, S10 and S11 can be further expanded using thebinomial rule to obtain:
4
S00 =(
1T
∑Tt=1 ε4
t
)− 4(α̂− α)
(1T
∑Tt=1 Xt−1ε
3t
)+ 6(α̂− α)2
(1T
∑Tt=1 X2
t−1ε2t
)
−4(α̂− α)3(
1T
∑Tt=1 X3
t−1εt
)+ (α̂− α)4
(1T
∑Tt=1 X4
t−1
)
−(
1T
∑Tt=1 ε2
t − ( 1T
PTt=1 Xt−1εt)2
1T
PTt=1 X2
t−1
)2
(5)
S10 =
1T
∑Tt=1(Xt−1 −X)(ε2
t − 1) + (α̂− α)2(
1T
∑Tt=1 X3
t−1
)
1T
∑Tt=1(X
2t−1 −X2)(ε
2t − 1) + (α̂− α)2
(1T
∑Tt=1 X4
t−1
)
−2(α̂− α)(
1T
∑Tt=1 X2
t−1εt
)− (α̂− α)2X.X2 + 2(α̂− α)
(XT
∑Tt=1 Xt−1εt
)
−2(α̂− α)(
1T
∑Tt=1 X3
t−1εt
)− (α̂− α)2X
2
2 + 2(α̂− α)(
X2
T
∑Tt=1 Xt−1εt
)
(6)And:
S11 =
1T
∑Tt=1 X2
t−1 −X2 1
T
∑Tt=1 X3
t−1 −X ·X2
1T
∑Tt=1 X3
t−1 −X ·X21T
∑Tt=1 X4
t−1 −X2
2
(7)
Note that despite the presence of several terms in the expanded form of componentsS00 and S10, it will be shown that only few of these terms play and important role inthe asymptotic distribution of S00 and S10 (i.e. many of these terms become negligibleas T increases). In fact, it will be shown that a key feature of the explosive case is thatterms that would have been otherwise negligible will in that case have an effect uponthe asymptotic distribution of S10 and thus upon that of TR2.
Finally, under the null (i.e. β1 = β2 = 0), White’s test for heteroskedasticity shouldprovide the following result:
TR2 d−→ χ2(2) (8)
In other words, if the null hypothesis is true, and thus heteroskedasticity is rejected,then the TR2 above should have a chi-square as a limiting distribution.
It is worthwhile mentioning here that several different significant statistics havebeen analysed in the time series literature. Most statisticians and econometricians havebeen particularly concerned with the asymptotic properties of the estimators of theparameter α (i.e. Maximum Likelihood Estimator (MLE), Least Squares Estimator).These are driven by:
5
√T (α̂− α) =
1√T
∑Tt=1 Xt−1εt
1T
∑Tt=1 X2
t−1
for which the asymptotic results in the stationary case are universally known and are adirect consequences of the Law of Large Numbers (LLN) for serially dependent processesand the Central Limit Theorem (CLT) for martingale differences (c.f. Hamilton (1994),Nielsen (2004) among others). Nonetheless, the asymptotic properties of these estima-tors have been largely studied for unstable autoregressive processes as well. Notably,the contributions of Rubin (1950), Anderson (1959), Lai and Wei (1983), Chan andWei (1988), Jeganathan (1988) and Nielsen (2005).
On the other hand, it can be seen upon examination of the components S00, S10 andS11 presented in equations (5), (6) and (7) that a particular feature of the significantstatistic of White’s test is the presence of higher powers, for instance:
∑Tt=1 X4
t−1,∑Tt=1 X3
t−1,∑T
t=1 X3t−1εt and
∑Tt=1 X2
t−1(ε2t − 1) among others. These kinds of terms
have not been analysed in the general case in the literature. More precisely, most of thetechniques used in this paper are known but have not been applied to this particularproblem before. This represents a key attribute of the analysis presented here, bothfor White’s test for heteroskedasticity and for the Jarque-Bera normality test to bepresented in the next sub-section.
1.3 Jarque-Bera’s test for Normality
Consider again the one-dimensional time series satisfying the first order autoregressiveequation (1). And provided that this is the true model the residuals are given byε̂t = εt − (α̂− α)Xt−1, with (α̂− α) defined as in equation (4).
The Jarque-Bera normality test is based on the idea of analyzing the asymptoticproperties of the following two statistics:
K̂23 =
1T
∑Tt=1(ε̂t − ε̂)3
[1T
∑Tt=1(ε̂t − ε̂)2
]3/2=
S3
S23/2
(9)
And,
K̂24 =
1T
∑Tt=1(ε̂t − ε̂)4
[1T
∑Tt=1(ε̂t − ε̂)2
]2 − 3 =S4 − 3S2
2
S22 (10)
Where:
6
S2 = 1T
∑Tt=1(ε̂t − ε̂)2
= 1T
∑Tt=1 ε̂2
t −(
1T
∑Tt=1 ε̂t
)2
S3 = 1T
∑Tt=1(ε̂t − ε̂)3
= 1T
∑Tt=1 ε̂3
t − 3(
1T
∑Tt=1 ε̂2
t
)(1T
∑Tt=1 ε̂t
)+ 2
(1T
∑Tt=1 ε̂t
)3
S4 = 1T
∑Tt=1(ε̂t − ε̂)4
And
S4 − 3S22 = 1
T
∑Tt=1 ε̂4
t − 4(
1T
∑Tt=1 ε̂t
)(1T
∑Tt=1 ε̂3
t
)+ 12
(1T
∑Tt=1 ε̂2
t
)(1T
∑Tt=1 ε̂t
)2
−6(
1T
∑Tt=1 ε̂t
)4
− 3(
1T
∑Tt=1 ε̂2
t
)2
Then, under the null (i.e. the εt’s are normally distributed) we have the followingresults:
TK̂2
3
6
d−→ χ2(1)
TK̂2
4
24
d−→ χ2(1)
T(
K̂23
6+
K̂24
24
)d−→ χ2
(2)
This means that when we fail to reject the null hypothesis of normality, the abovethree statistics should have a chi-square as limiting distribution.
Now, as mentioned previously, it will be shown in this paper that White’s methodfor testing for heteroskedasticity works well in the stationary and unit root cases, butnot in the general case. Here the general case denotes all three stationary, unit root andexplosive cases together. Additionally, it will be proved that the Jarque-Bera normalitytest works well in all three cases. Thus this paper is organised in the following way:the validity of White’s test for Heteroskedasticity and that of the Jarque-Bera test forNormality will be analsed when dealing with a marginally stable process (i.e. unitroot case). This is going to be shown explicitly in Theorems 2.1 and 2.2 in section 2.Then, Theorem 3.1 in section 3 will reveal that White’s test for heteroskedasticity is not
7
valid in the explosive case. Whilst, Theorem 3.1 will demonstrate that the Jarque-Beranormality test is nevertheless valid in the explosive case.
Following the outline just described, it is worth emphasizing here that for each of thetwo cases studied in this paper (i.e. unit root and explosive cases) a different distributiontheory is required. The stationary case (as shown by previous authors) is based onthe application of the Law of Large Numbers (LLN) and the Central limit Theorem(CLT) to stationary ergodic (mixing) autoregressive processes and ergodic martingaledifferences respectively. In the unit root case, Theorems 2.1 and 2.2 are consequencesof the Functional Central Limit Theorem (FCLT), the Continuous Mapping Theoremand a result provided by Ibragimov and Phillips (2004). Last but not least, Theorems3.1 and 3.2 which represent the main results in the explosive case are based on adifferent theory from the previous two. As pointed out by Nielsen (2005), this theoryis based on the use of strong consistency arguments rather than weak consistency andweak convergence arguments used in non-explosive time series. Furthermore, it will bepointed out that the order of magnitude of the process (Xt)t∈N varies according to thecase under consideration (i.e. according to the values of the parameter α).
Before proceeding to the presentation of the mentioned theorems, it is importantat this point to introduce the main assumptions that are used in the rest of the paperunless stated otherwise.
1.4 Assumptions
Throughout the entire paper, the following two assumption are used:
Assumption 1.1. (εt)t is a sequence of i.i.d. normally distributed random variableswith mean zero and variance one.
Assumption 1.2. X0 = 0
Note that assumption 1.1 could be modified so that ‘variance equal to one’ couldbe replaced by ‘constant variance σ2’. This is due to the scale invariance property ofthis particular problem and simplifies the presentation thereafter. In other words, thedistribution of the significant statistic TR2 is unaffected when the variance σ2 is scaledto one.
Additionally, it is worth mentioning that most of the results presented in this paperstill hold if we further relax assumption 1.1. Notably if i.i.d.-ness is replaced by letting(εt)t∈N be a martingale difference sequence with respect to an increasing sequence ofσ-fields (Ft)t∈N (where Ft denotes the so called natural filtration). This is due to thefact that (as mentioned earlier) most of the theorems used here: Law of Large Num-bers, CLT’s, Functional CLT’s (FCLT’s), etc, are applicable to martingale differences.However, the fact that White’s test for heteroskedasticity is not valid in the explosivecase using assumption 1.1 is a sufficient condition to prove that this test is not generallyvalid when (εt)t∈N is a martingale difference sequence. Thus assumption 1.1 is appositehere.
8
Assumption 1.2 is used for simplicity only. The latter could be effectively replacedby the assumption that X0 is fixed and the main results would be unchanged. Howeverthe presentation would become more cumbersome due to the extra term. It is thereforeconvenient to use assumption 1.2 henceforth. This means that (Xt) is taken to be anautoregressive model without an intercept.
9
2 Unit Root Case: |α| = 1
The characteristics of this test for heteroskedasticity have been considered previously bya number of researchers in the stationary case. Kelejian (1982) has shown that White’stest for heteroskedasticity is valid in this case using a stationary p-dimensional vectorautoregressive process (a VAR(1) model). A similar result was presented by Godfreyand Orme (1994).
In this section, the asymptotic properties of White’s test for heteroskedasticity inthe unit root (or marginally stable) case are analysed. Therefore the findings presentedin this section are ground-breaking in the sense that, as mentioned by Wooldridge(1999), the properties of White’s test have not been studied formally in the unit rootcase before.
One of the main results of this section, which is the validity of White’s test forheteroskedasticity when applied to a first order autoregressive process with a unit root(i.e. a random walk), is presented in the following theorem:
Theorem 2.1. Let R2 be defined as in equation (3). If assumptions 1.1 and 1.2 aresatisfied and if |α| = 1, then
TR2 d−→ χ2(2) (11)
The second main result of this section is that of the validity of the Jarque-Beranormality test when dealing with a first order autoregressive process with a unit rootas in the previous theorem. This point is presented in the following theorem:
Theorem 2.2. Let K̂23 and K̂2
4 be defined as in equation (3). If assumptions 1.1 and1.2 are satisfied and if |α| = 1, then
TK̂2
3
6
d−→ χ2(1) , T
K̂24
24
d−→ χ2(1) and T
(K̂2
3
6+
K̂24
24
)d−→ χ2
(2) (12)
In order to establish the proofs for the above theorems, the following three lemmasare required.
Lemma 2.1. Let (εt)t∈N be a sequence of i.i.d. random variables satisfying assumption1.1. Therefore, on the space D[0, 1] of right continuous functions with left limits, wehave:
1√
T
[T ·]∑t=1
εt,1√T
[T ·]∑t=1
(ε2t − 1)
d−→ (B1·, B2·) (13)
Also: 1√
T
[T ·]∑t=1
(ε2t − 1),
1√T
[T ·]∑t=1
ε3t
d−→ (B2·, B3·) (14)
10
where B1·, B2· and B3· are three Brownian motions, and B2· is independent of both B1·and B3·.
The above lemma is a consequence of the Functional Central Limit Theorem (FCLT)for martingale difference sequence. This theorem can be found in Nielsen (2004).
Proof of lemma 2.1. :Let (εt)t∈N be a sequence of i.i.d. normally distributed random variables with mean
zero and variance one. Also, let (ut)t∈N be a sequence of i.i.d. random variables withmean zero and variance K2
0 (K0 constant). Let us define S2T =
∑Tt=1 E [u2
t ] = T ·K20 .
Note that (ut)t∈N can in turn be equal to the sequences (εt)t∈N, (ε2t − 1)t∈N and
(ε3t )t∈N. In that case (ut)t∈N is clearly a martingale difference and satisfies the following
three conditions:
i)∑T
t=1u2
t
S2T
= 1K2
0
1T
∑Tt=1 u2
tP−→ 1
ii) maxt∈[[1,T ]]
∣∣∣ ut
ST
∣∣∣ = 1K0
1√T
maxt∈[[1,T ]] |ut| P−→ 0 since ut = Op(1)
iii)∑[Tr]
t=1 E(
u2t
S2T
)= 1
T
∑[Tr]t=1
E(u2t)
K20
= [Tr]T
= Tr−frac(Tr)T
−→r
where ∀(T, r) ∈ R+× [0, 1], [Tr] is the integer value of Tr and frac(Tr) is the mantissaof Tr defined as frac(Tr) = Tr − [Tr]. Therefore, from the functional central limittheorem on the space D[0, 1] of right continuous functions with left limits (or CadLagfunctions), we have:
1
ST
[T ·]∑t=1
ut =1
K20
1√T
[T ·]∑t=1
utd−→ B· (15)
where B· is a Brownian motion.Now, setting (ut)t∈N equal to the sequences (εt)t∈N, (ε2
t − 1)t∈N and (ε3t )t∈N respec-
tively and using the result presented in (15) we obtain that:
1√T
[T.]∑t=1
εtd−→ B1. (16)
1√T
[T.]∑t=1
(ε2t − 1)
d−→ B2. (17)
1√T
[T.]∑t=1
ε3t
d−→ B3. (18)
11
where B1., B2. and B3. are three Brownian motions.Having stated the three individual marginal results presented in equations (16), (17)
and (18) we can provide a stronger result by combining the latter. In fact, the processes(εt)t∈N and (ε2
t − 1)t∈N are uncorrelated. Likewise the processes (ε2t − 1)t∈N and (ε3
t )t∈Nare also uncorrelated. In other words:
cov[εt, (ε
2t − 1)
]= cov
[ε3
t , (ε2t − 1)
]= 0
Hence, using the result presented by Helland (1982, Theorem 3.3) based on theCramer-Wold device, we conclude that:
1√
T
[T ·]∑t=1
εt,1√T
[T ·]∑t=1
(ε2t − 1)
d−→ (B1·, B2·)
Similarly:
1√
T
[T ·]∑t=1
(ε2t − 1),
1√T
[T ·]∑t=1
ε3t
d−→ (B2·, B3·)
where B1u, B2u and B3u are three Brownian motions. B2u is independent of both B1u
andB3u. This concludes the proof of Lemma 2.1.
Lemma 2.2. Let (Xt)t∈N be the process satisfying equation (1). If assumptions 1.1 and1.2 are satisfied and if |α| = 1, then ∀k ∈ [[1, 4]],
1
T
T∑t=1
(Xt−1√
T
)kd−→
∫ 1
0
Bk1u du (19)
where B1u represents the standard Brownian motion.
The above lemma is simply a corollary of Lemma 2.1 and its proof makes use of theContinuous Mapping Theorem which can also be found in Nielsen (2004).
Proof of lemma 2.2. :Let (εt)t∈N be a sequence of i.i.d. normally distributed random variables with mean
zero and variance one and let (XT .)T∈N be a sequence of random elements taking valuesin D[0, 1] defined as:
∀u ∈ [0, 1], XT (u) =1√T
[Tu]∑t=1
εt
Also, let f : R→R be a continuous function and B1(u) = B1u denotes a standard
12
Brownian motion. And we have already shown in equation (16) that:
XT (u) =1√T
[Tu]∑t=1
εtd−→ B1u (20)
Let G : D[0, 1] → R be the function defined by:
∀Z(·) ∈ D[0, 1], G(Z(·)
)=
∫ 1
0
f (Zu) du
G is a continuous mapping as the composed of the continuous mappings: f : R → Rabove and x 7→ ∫ 1
0xu du . Therefore, applying the Continuous Mapping Theorem to
the result presented in equation (20) we obtain that:
G (XT (u))d−→ G (B1u)
In other words, we obtain that:
1
T
T∑t=1
f
(Xt−1√
T
)d−→
∫ 1
0
f (B1u) du
The proof of Lemma 2.2 is completed by choosing the continuous function f : R→ Rsuch that:
∀(x, k) ∈ R× [[1, 4]], f(x) = xk
Lemma 2.3. Let (εt)t∈N be a sequence of i.i.d. random variables satisfying assumption1.1 and let (Xt)t∈N be the autoregressive process satisfying equation (1) and X0 = 0. If|α| = 1, then
∀k ∈ [[1, 3]], 1√T
∑Tt=1
(Xt−1√
T
)k
εtd−→ ∫ 1
0Bk
1u dB1u
∀k ∈ [[1, 2]], 1√T
∑Tt=1
(Xt−1√
T
)k
(ε2t − 1)
d−→ ∫ 1
0Bk
1u dB2u
And: 1√T
∑Tt=1
(Xt−1√
T
)ε3
td−→ ∫ 1
0B1u dB3u
where B1u, B2u and B3u are three Brownian motions as in Lemma 2.1.
Proof of lemma 2.3. :Lemma 2.3 is an immediate consequence of Theorem 0.3 presented by Caceres and
Nielsen (2006).
13
Additionally, a second consequence of Caceres and Nielsen’s Theorem 0.3 is thatthe convergence results in Lemma 2.2 and Lemma 2.3 also hold jointly.
Another important point to mention regarding these two lemmas above is theweights imposed to each sum. These clearly differ from the stationary case whereall sums are equally weighted (by a 1
Tcoefficient for the convergence in probability and
a 1√T
coefficient for the convergence in distribution). However, in the unit root case apolynomial weight is in order.
Now, having established Lemmas 2.2 and 2.3, we are in the position of formallypresenting the proofs of Theorem 2.1 and Theorem 2.2.
Proof of theorem 2.1. :Lets consider R2 defined in equation (3) as R2 = S−1
00 .S01.S−111 .S10. However, here
we use the fact that R2 can also be written in the following way:
where AT is a positive-definite diagonal matrix defined by:
AT =
T− 12 0
0 T−1
(22)
Note that the component S00 remains unchanged by the transformation presentedin equation (21), and it expanded form is given as in equation (5). However, the termsS∗10 and S∗11 above are now given by:
S∗10 =
T− 3
2
∑Tt=1(Xt−1 −X)(ε2
t − 1) + (α̂− α)2(T− 3
2
∑Tt=1 X3
t−1
)
T−2∑T
t=1(X2t−1 −X2)(ε
2t − 1) + (α̂− α)2
(T−2
∑Tt=1 X4
t−1
)
−2(α̂− α)(T− 3
2
∑Tt=1 X2
t−1εt
)− (α̂− α)2 X.X2√
T+ 2(α̂− α)
(T− 3
2 X ·∑Tt=1 Xt−1εt
)
−2(α̂− α)(T−2
∑Tt=1 X3
t−1εt
)− (α̂− α)2 X
22
T+ 2(α̂− α)
(T−2X2 ·
∑Tt=1 Xt−1εt
)
S∗11 =
T−2∑T
t=1(Xt−1 −X)2 T− 52
∑Tt=1(Xt−1 −X)(X2
t−1 −X2)
T− 52
∑Tt=1(Xt−1 −X)(X2
t−1 −X2) T−3∑T
t=1(X2t−1 −X2)
2
First of all, using the results from Lemmas 2.2 and 2.3 presented above for α = 1,we obtain that:
T (α̂− α) =1T
∑Tt=1 Xt−1εt
1T 2
∑Tt=1 X2
t−1
= Op(1)
14
Now, applying Lemma 2.2 to each of the terms of S∗11 presented above we obtainthe following result:
S∗11d−→
∫ 1
0B1u.G1u du
∫ 1
0B2
1u.G1u du
∫ 1
0B1u.G2u du
∫ 1
0B2
1u.G2u du
=
∫ 1
0
[G1u
G2u
]·[
G1u
G2u
]T
du (23)
where B1u represents the standard Brownian motion and G1u and G2u are given by:
G1u = B1u −∫ 1
0
B1v dv
G2u = B21u −
∫ 1
0
B21v dv
Similarly, we can apply both Lemma 2.2 and Lemma 2.3 to each of the terms of S00
and S∗10 to obtain the following results:
S00 =1
T
T∑t=1
ε4t −
(1
T
T∑t=1
ε2t
)2
+ op(1)P−→ 2 (24)
√T · S∗10 =
T−1∑T
t=1(Xt−1 −X)(ε2t − 1) + op(1)
T− 32
∑Tt=1(X
2t−1 −X2)(ε
2t − 1) + op(1)
(25)
Furthermore, we have that:
√T · S∗10
d−→[ ∫ 1
0G1u dB2u∫ 1
0G2u dB2u
]=
∫ 1
0
[G1u
G2u
]dB2u (26)
Finally, combining the three results presented in equations (23), (24) and (26) weobtain that the convergence of TR2 = T.S−1
00 .S∗01.S∗−111 .S∗10 is given by:
TR2 d−→∫ 1
0
dB2u√2
[G1u
G2u
]T
·(∫ 1
0
[G1u
G2u
]·[
G1u
G2u
]T
du
)−1
·∫ 1
0
[G1u
G2u
]dB2u√
2
Furthermore, based on Johansen’s (1996, chapter 13) exposition, we find that, con-
ditioning on the vector Gu = [G1u, G2u ]T , the integral∫ 1
01√2( dB2u)G
Tu is Gaussian:
N
[(00
),
(∫ 1
0
Gu ·GTu du
)]
because we have that Gu and B2u are independent (from the independence of B1u andB2u). Therefore we conclude that:
15
TR2 d−→ χ2(2) (27)
conditionally on Gu.But since the conditional distribution of TR2 does not depend on Gu, the above
result also holds marginally. This completes the proof of Theorem 2.1.
Proof of theorem 2.2. :Lets consider again the terms K̂2
3 and K̂24 defined in equations (9) and (10). Then,
using once more the results presented in Lemma 2.2 and Lemma 2.3, for α = 1, com-bined with the LLN and the Lindberg-Levy CLT, we obtain that:
T (α̂− α) =1T
∑Tt=1 Xt−1εt
1T 2
∑Tt=1 X2
t−1
= Op(1)
S2 =1
T
T∑t=1
ε2t + Op
(1
T
)P−→ 1 (28)
S22 =
(1
T
T∑t=1
ε2t
)2
+ Op
(1
T
)P−→ 1 (29)
√TS3 =
1√T
T∑t=1
(ε3
t − 3εt
)+ op(1)
d−→ N(0, 6) (30)
And
√T
(S4 − 3S2
2)
=1√T
T∑t=1
(ε4
t − 6ε2t + 3
) d−→ N(0, 24) (31)
Therefore, combining the above results we now obtain that:
TK̂2
3
6=
1
S23
(√TS3√6
)2
d−→ χ2(1) (32)
TK̂2
4
24=
1
S24
(√T
[S4 − 3S2
2]
√24
)2
d−→ χ2(1) (33)
Furthermore, let Zt = 1√6(ε3
t − 3εt) and Z ′t = 1√
24(ε4
t − 6ε2t + 3). Then, we have:
E(Zt) = 0, E(Z ′t) = 0, var(Zt) = 0, var(Z ′
t) = 0 and cov(Zt, Z′t) = 0
And, from the Lindberg-Levy CLT we obtain that:
16
1√T
T∑t=1
[Zt
Z ′t
]d−→ N
[(00
),
(1 00 1
)](34)
Thus, from the above results and using the Kramer-Wold device, we conclude that:
T
(K̂2
3
6+
K̂24
24
)d−→ χ2
(2) (35)
This completes the proof.
Hence, the results presented in this section prove that White’s test for heteroskedas-ticity is valid in the unit root case. This also proves the validity of the Jarque-Beranormality test in the same case. In other words, both tests are applicable to a marginallystable first order autoregressive process or random walk.
This is quite an important and innovative result since several commonly encoun-tered processes in economics, finance, biology and thermodynamics are believed to berepresented by random walks. Based on the findings presented here, such processes canbe submitted legitimately and accurately to these diagnostic tests.
17
3 Explosive Case: |α| > 1
In this section, the asymptotic properties of White’s test for heteroskedasticity and thatof the Jarque-Bera test for normality in the explosive case are examined.
The main result is presented in the following theorem, which states that White’s testfor heteroskedasticity is not valid when applied to a first order autoregressive processwith an explosive root.
Theorem 3.1. Let R2 be defined as in equation (3). If assumptions 1.1 and 1.2 aresatisfied and if |α| > 1, then it is not true that
TR2 d−→ χ2(2) (36)
Similarly, the corresponding result for the Jarque-Bera normality test when dealingwith an explosive autoregressive process is presented in the following theorem.
Theorem 3.2. Let K̂23 and K̂2
4 be defined as in equation (3). If assumptions 1.1 and1.2 are satisfied and if |α| > 1, then
TK̂2
3
6
d−→ χ2(1) , T
K̂24
24
d−→ χ2(1) and T
(K̂2
3
6+
K̂24
24
)d−→ χ2
(2) (37)
Following again the structure of the previous section, we are going to introduce thenext two Lemmas which are essential for the proof of Theorem 3.1. Nevertheless, it isimportant to mention at this point that the standard Law of Large Numbers (LLN’s),the Central Limit Theorems (CLT’s) and/or the Functional CLT’s (FCLT’s) do notapply in this case and a different asymptotic theory is therefore required.
Lemma 3.1. Let (Xt)t∈N be the process defined by equation (1). If assumptions 1.1 and1.2 are satisfied and if |α| > 1, then ∀k ∈ [[1, 4]],
∣∣∣∣∣T∑
t=1
Xkt−1
∣∣∣∣∣a.s.= O
(|α|kT)
(38)
And: ∣∣∣∣∣α−kT
T∑t=1
Xkt−1 − F(k)
∣∣∣∣∣a.s.−→ 0 (39)
Where:
F(k) =∞∑i=2
α−kiZk And: Z = α ·∞∑
j=1
α−jεj
It is worth mentioning here that the weights used for the almost sure (a.s.) con-vergence in the explosive case clearly differ from those used in the stationary and
18
unit root cases. Additionally, as proved by e.g. Lai and Wei (1983), the order ofthe process itself is given by: |XT | a.s.
= O(|α|T ). This is quite interesting as the term|∑T
t=1 Xt−1| a.s.= O(|α|T ) as well. This refers to the fact that the sum of exponentials
gives an exponential.
Proof of lemma 3.1. :In order to prove Lemma 3.1 we follow Anderson (1959) in that he defines a random
variable Zt such that:
∀t ∈ N, Zt = α ·t−1∑j=1
α−jεj
In other words:∀t ∈ N, Xt−1 = α(t−2) · Zt
Additionally, let the Z, F(k,T ) and F(k) be defined by:
Z = α ·∑∞j=1 α−jεj
F(k,T ) =∑T
i=2 α−kiZkT
F(k) =∑∞
i=2 α−kiZk
From the martingale convergence theorem and the Marcinkiewicz-Zygmund result(Lai and Wei, 1983): ZT
a.s.−→ Z. Now,
∣∣∣∣∣α−kT
T∑t=1
Xkt−1 − F(k,T )
∣∣∣∣∣ =
∣∣∣∣∣α−kT
T∑t=2
[α(t−2)Zt
]k − F(k,T )
∣∣∣∣∣
=
∣∣∣∣∣α−2k
T∑t=2
α−k(T−t)Zkt −
T∑i=2
α−kiZkT
∣∣∣∣∣
=
∣∣∣∣∣α−2k
T∑i=2
α−ki+2kZkT−i+2 −
T∑i=2
α−kiZkT
∣∣∣∣∣
=
∣∣∣∣∣T∑
i=2
α−ki(Zk
T−i+2 − ZkT
)∣∣∣∣∣
And, using the triangular inequality:
∣∣∣∣∣α−kT
T∑t=1
Xkt−1 − F(k,T )
∣∣∣∣∣ ≤T∑
i=2
|α|−ki∣∣Zk
T−i+2 − ZkT
∣∣
≤T∑
i=2
|α|−ki |ZT−i+2 − ZT | ·∣∣∣∣∣k−1∑j=0
ZjT−i+2 · Zk−1−j
T
∣∣∣∣∣
19
And we know that (Zn)n∈N0 is a converging sequence (Zn−→Z), therefore this can bealso written as:
then, ∀j ∈ N0, |Zj| < K0 = max(c′, c + |Z|)V So, now we can write:
∣∣∣∣∣α−kT
T∑t=1
Xkt−1 − F(k,T )
∣∣∣∣∣
≤T∑
i=2
|α|−ki |ZT−i+2 − ZT | ·∣∣∣∣∣k−1∑j=0
ZjT−i+2 · Zk−1−j
T
∣∣∣∣∣
≤T−n0∑i=2
|α|−ki |(ZT−i+2 − Z)− (ZT − Z)| ·∣∣∣∣∣k−1∑j=0
ZjT−i+2 · Zk−1−j
T
∣∣∣∣∣
+T∑
i=T−n0+1
|α|−ki |ZT−i+2 − ZT | ·∣∣∣∣∣k−1∑j=0
ZjT−i+2 · Zk−1−j
T
∣∣∣∣∣
≤T−n0∑i=2
|α|−ki2c ·∣∣∣∣∣k−1∑j=0
Kk−10
∣∣∣∣∣ +T∑
i=T−n0+1
|α|−ki2K0 ·∣∣∣∣∣k−1∑j=0
Kk−10
∣∣∣∣∣
≤ 2c ·∣∣∣∣∣k−1∑j=0
Kk−10
∣∣∣∣∣ ·T−n0∑i=2
|α|−ki + 2K0 ·∣∣∣∣∣k−1∑j=0
Kk−10
∣∣∣∣∣ ·T∑
i=T−n0+1
|α|−ki
≤ 2c ·∣∣∣∣∣k−1∑j=0
Kk−10
∣∣∣∣∣ ·∞∑i=2
|α|−ki + o(1)
and c can be taken to be as small as possible and the rest are simply constants. Thus,
∣∣∣∣∣α−kT
T∑t=1
Xkt−1 − F(k,T )
∣∣∣∣∣a.s.−→ 0 (40)
Now, consider:
20
∣∣F(k) − F(k,T )
∣∣ =
∣∣∣∣∣T∑
i=2
α−kiZkT −
∞∑i=2
α−kiZk
∣∣∣∣∣
=
∣∣∣∣∣T∑
i=2
α−kiZkT −
T∑i=2
α−kiZk −∞∑
i=T+1
α−kiZk
∣∣∣∣∣
=
∣∣∣∣∣T∑
i=2
α−ki(Zk
T − Zk)−
∞∑i=T+1
α−kiZk
∣∣∣∣∣
And, using the triangular inequality:
∣∣F(k) − F(k,T )
∣∣ =
∣∣∣∣∣T∑
i=2
α−kiZkT −
∞∑i=2
α−kiZk
∣∣∣∣∣
≤T∑
i=2
|α|−ki∣∣Zk
T − Zk∣∣ +
∞∑i=T+1
|α|−ki|Z|k
≤∣∣Zk
T − Zk∣∣ ·
T∑i=2
|α|−ki + |Z|k |α|2k
|α|k − 1
∣∣αk∣∣−T
≤∣∣Zk
T − Zk∣∣ ·
∞∑i=2
|α|−ki + o(1)
and: ∣∣ZkT − Zk
∣∣ a.s.−→ 0
Hence: ∣∣F(k) − F(k,T )
∣∣ a.s.−→ 0 (41)
Finally, combining the results presented in equations (40) and (41) we obtain:
∣∣∣∣∣α−kT
T∑t=1
Xkt−1 − F(k)
∣∣∣∣∣a.s.−→ 0 (42)
where:
F(k) =∞∑i=2
α−kiZk (43)
Therefore this concludes with the proof of Lemma 3.1 by simply letting k to takevalues in [[1, 4]] accordingly.
Note that another proof for the above result, in the case where k = 1, was providedby Nielsen (2005). He also presents a proof for the case k = 2 following the lines of Laiand Wei (1983). The above exposition is a generalisation of these results where k cantake any value in the integer interval [[1,4]]. In fact the proof presented above is still
21
valid for any positive finite integer k.
Lemma 3.2. Let (εt)t∈N be a sequence of i.i.d. random variables satisfying assumption1.1 and let (Xt)t∈N be the autoregressive process defined by equation (1) and X0 = 0. If|α| > 1, then
∀k ∈ [[1, 3]], α−kT∑T
t=1 Xkt−1εt
a.s.−→ α−2k Zk · Y1k
∀k ∈ [[1, 2]], α−kT∑T
t=1 Xkt−1(ε
2t − 1)
a.s.−→ α−2k Zk · Y2k
And: α−T∑T
t=1 Xt−1ε3t
a.s.−→ α−2 Z · Y31
where Z is defined as in Lemma 3.1 and ∀k ∈ [[1, 3]], Y1k, Y2k, Y31 are random variablesdefined by:
Y1k = limT→∞[∑T
j=1 αk(j−T ) · εj
]
Y2k = limT→∞[∑T
j=1 αk(j−T ) · (ε2j − 1)
]
Y31 = limT→∞[∑T
j=1 α(j−T ) · ε3j
]
Proof of lemma 3.2. :Let (εt)t∈N be a sequence of i.i.d. random variables satisfying assumption 1.1 and
let (ut)t∈N be a sequence of i.i.d. random variables satisfying the following assumptions:
i) E(ut) = 0
ii) E(u2t ) = K2
1 i.e. a positive constant
iii) E(ut · us) = 0 for all t 6= s
Note that all three processes (εt)t∈N, (ε2t − 1)t∈N and (ε3
t )t∈N satisfy the above threeconditions and can therefore replace (ut)t∈N in what follows.
Again, following Anderson’s (1959) notation, let:
ZT = α ·∑T−1j=1 α−j · εj = α−(T−2) ·XT−1
Z = α ·∑∞j=1 α−j · εj
Yu1,T =∑T
i=1 α(i−T ) · ui
22
Consider:
T∑t=1
α(2−T )Xt−1ut =T∑
t=1
α(2−T+t−2)ut · α−t+2Xt−1
=T∑
t=1
α−T+tut · Zt
=T∑
t=1
α−T+tut · [(Zt − ZT ) + ZT ]
= ZT · Yu1,T +T∑
t=1
α−T+tut · (Zt − ZT )
= ZT · Yu1,T +T−1∑j=1
α−juT−j · (ZT−j − ZT )
Therefore:
E
∣∣∣∣∣T∑
t=1
α(2−T )Xt−1ut − ZT · Yu1,T
∣∣∣∣∣ = E
∣∣∣∣∣T−1∑j=1
α−juT−j · (ZT−j − ZT )
∣∣∣∣∣
≤T−1∑j=1
∣∣α−j∣∣ E |uT−j · (ZT−j − ZT )|
≤T−1∑j=1
∣∣α−j∣∣ · [E(u2
T−j) · E[(ZT−j − ZT )2
]] 12
≤T−1∑j=1
∣∣α−j∣∣ · |K1| ·
[E
[(ZT−j − ZT )2
]] 12
And:
E[(ZT−j − ZT )2
]= α−2(T−2) ·
[α2j − 1
α2 − 1
](44)
Then,
23
E
∣∣∣∣∣T∑
t=1
α(2−T )Xt−1ut − ZT · Yu1,T
∣∣∣∣∣ ≤T−1∑j=1
∣∣α−j∣∣ · |K1| · α−(T−2) ·
[α2j − 1
α2 − 1
] 12
≤ |K1| ·T−1∑j=1
|α|−(T−2)
√α2 − 1
·∣∣1− α−2j
∣∣ 12
≤ |K1| ·T−1∑j=1
|α|−(T−2)
√α2 − 1
≤ |K1| · |α|√α2 − 1
· (T − 1)
|α|T−1
a.s.−→ 0
Hence,
E
∣∣∣∣∣T∑
t=1
α(2−T )Xt−1ut − ZT · Yu1,T
∣∣∣∣∣a.s.−→ 0
Thus, using Anderson’s theorems 2.3, 2.4 and 2.6 (Anderson, 1959) given that (ut)t∈Nis i.i.d we can say that (Yu1,T , ZT ) has a limiting distribution given by (Yu1, Z). Fur-thermore:
α−(T−2)
T∑t=1
Xt−1uta.s.−→ Z · Yu1
In other words, we obtain three of the results presented in Lemma 3.2 by simply lettingthe process (ut)t∈N to be equal to processes (εt)t∈N, (ε2
t − 1)t∈N and (ε3t )t∈N respectively:
α−T∑T
t=1 Xt−1 · εta.s.−→ α−2 Z · Y11
α−T∑T
t=1 Xt−1 · (ε2t − 1)
a.s.−→ α−2 Z · Y21
α−T∑T
t=1 Xt−1 · ε3t
a.s.−→ α−2 Z · Y31
Where:Y11 = limT→∞
[∑Tj=1 α(j−T ) · εj
]
Y21 = limT→∞[∑T
j=1 α(j−T ) · (ε2j − 1)
]
Y31 = limT→∞[∑T
j=1 α(j−T ) · ε3j
]
Note that a similar result corresponding to the case ut = εt above was presentedby Jeganathan (1988). In fact he included a result regarding the joint convergence of(α−2T
∑Tt=1 X2
t−1, α−T
∑Tt=1 Xt−1εt). The exposition presented here is therefore a gen-
24
eralisation of that result where (ut)t∈N can be any i.i.d. process satisfying the requiredthree conditions.
The other proofs for the other terms presented in Lemma 3.2 are also based on thetechnique presented above. These go as follows:
Lets consider ZT and Z as presented above. Lets also define Yu2,T by:
Yu2,T =T∑
i=1
α2(i−T ) · ui
Now, consider:
T∑t=1
α2(2−T )X2t−1ut =
T∑t=1
α2(2−T+t−2)ut · α−2(t−2)X2t−1
=T∑
t=1
α2(t−T )ut · Z2t
=T∑
t=1
α2(t−T )ut ·[(Z2
t − Z2T ) + Z2
T
]
= Z2T · Yu2,T +
T∑t=1
α2(t−T )ut · (Z2t − Z2
T )
= Z2T · Yu2,T +
T−1∑j=1
α−2juT−j · (Z2T−j − Z2
T )
Therefore:
E
∣∣∣∣∣T∑
t=1
α2(2−T )X2t−1ut − Z2
T · Yu2,T
∣∣∣∣∣ = E
∣∣∣∣∣T−1∑j=1
α−2juT−j · (Z2T−j − Z2
T )
∣∣∣∣∣
≤T−1∑j=1
∣∣α−2j∣∣ E
∣∣uT−j · (Z2T−j − Z2
T )∣∣
≤T−1∑j=1
∣∣α−2j∣∣ · [E(u2
T−j) · E[(Z2
T−j − Z2T )2
]] 12
≤T−1∑j=1
∣∣α−2j∣∣ · |K1| ·
[E
[(Z2
T−j − Z2T )2
]] 12
And:
E[(Z2
T−j − Z2T )2
]=
α8 · α−2T
(α2 − 1)2
(α2j − 1
) · (4α−2 − 3α−2T − α−2(T−j))
(45)
25
Then,
E
∣∣∣∣∣T∑
t=1
α(2−T )Xt−1ut − ZT · Yu1,T
∣∣∣∣∣
≤T−1∑j=1
|K1| · |α|−2j · α4 · |α|−T
(α2 − 1)· (α2j − 1
) 12 · (4α−2 − 3α−2T − α−2(T−j)
) 12
≤T−1∑j=1
|K1| · |α|−j · 2α4 · |α|−(T+1)
(α2 − 1)· (1− α−2j
) 12 ·
(1− 3
4α−2(T−1) − 1
4α−2(T−j−1)
) 12
≤T−1∑j=1
|K1| · 2α4 · |α|−(T+1)
(α2 − 1)
≤ 2 · |K1| · α2
(α2 − 1)· (T − 1)
|α|T−1
a.s.−→ 0
Hence,
E
∣∣∣∣∣T∑
t=1
α−2(T−2)X2t−1ut − Z2
T · Yu2,T
∣∣∣∣∣a.s.−→ 0
Thus, using Anderson’s theorems 2.3, 2.4 and 2.6 (Anderson, 1959) given that (ut)t∈Nis i.i.d we can say that (Yu2,T , ZT ) has a limiting distribution given by (Yu2, Z). Fur-thermore:
α−2(T−2)
T∑t=1
X2t−1ut
a.s.−→ Z2 · Yu2
In other words, we obtain two other results presented in Lemma 3.2:
α−2T∑T
t=1 X2t−1 · εt
a.s.−→ α−4 Z2 · Y12
α−2T∑T
t=1 X2t−1 · (ε2
t − 1)a.s.−→ α−4 Z2 · Y22
where:Y12 = limT→∞
[∑Tj=1 α2(j−T ) · εj
]
Y22 = limT→∞[∑T
j=1 α2(j−T ) · (ε2j − 1)
]
The last result presented in Lemma 3.2 is proved in exactly the same way, and wetherefore obtain:
α−3T∑T
t=1 X3t−1 · εt
a.s.−→ α−6 Z3 · Y13
where:
26
Y13 = limT→∞[∑T
j=1 α3(j−T ) · εj
]
This completes the proof of Lemma 3.2
Having established the above two lemmas, we can now state the following Theoremregarding the asymptotic distribution of TR2 in the explosive case.
Theorem 3.3. Let R2 be defined as in equation (3). If assumptions 1.1 and 1.2 aresatisfied and if |α| > 1, then
TR2 d−→ Y T∗ · Λ−1
z · Y∗ (46)
Where Y∗ ∈ R2 is given by:
Y∗ =
1α2 Z · Y21 + (α−1)(α+1)2
α3(α2+α+1)Z · Y 2
11 − 2(α2−1)α4 Z · Y11 · Y12
1α4 Z
2 · Y22 + (α2−1)α4(α2+1)
Z2 · Y 211 − 2(α2−1)
α6 Z2 · Y11 · Y13
(47)
and Λz ∈ R2×2 is given by:
Λz =
2z2
α2(α2−1)2z3
α3(α3−1)
2z3
α3(α3−1)2z4
α4(α4−1)
(48)
where ∀(i, j) ∈ [[1, 2]]× [[1, 3]], Yij and Z given as in Lemma 3.2.
Proof of theorem 3.3. :Lets consider once more the constant-adjusted squared correlation coefficient R2
Therefore the terms S∗10 and S∗11 in equation (49) are given by:
27
√TS∗10 =
α−T
∑Tt=1(Xt−1 −X)(ε2
t − 1) + (α̂− α)2(α−T
∑Tt=1 X3
t−1
)
α−2T∑T
t=1(X2t−1 −X2)(ε
2t − 1) + (α̂− α)2
(α−2T
∑Tt=1 X4
t−1
)
−2(α̂− α)(α−T
∑Tt=1 X2
t−1εt
)− (α̂− α)2 T
αT X.X2 + 2(α̂− α)(
XαT
∑Tt=1 Xt−1εt
)
−2(α̂− α)(α−2T
∑Tt=1 X3
t−1εt
)− (α̂− α)2 T
α2T X2
2 + 2(α̂− α)(
X2
α2T
∑Tt=1 Xt−1εt
)
S∗11 =
α−2T∑T
t=1 X2t−1 − T ·X2
α2T α−3T∑T
t=1 X3t−1 − T
α3T X.X2
α−3T∑T
t=1 X3t−1 − T
α3T X.X2 α−4T∑T
t=1 X4t−1 − T ·X2
2
α4T
Note that the term S00 remains unchanged after this transformation and it expandedform was presented in equation (5). Now applying Lemma 3.1 to the different terms ofS∗11 presented above we get:
S∗11 =
α−2T∑T
t=1 X2t−1 + o(1) α−3T
∑Tt=1 X3
t−1 + o(1)
α−3T∑T
t=1 X3t−1 + o(1) α−4T
∑Tt=1 X4
t−1 + o(1)
a.s.−→
F(2) F(3)
F(3) F(4)
=
1
2Λz
(51)
where:
∀k ∈ [[2, 4]], F(k) =∞∑i=2
α−kiZk And: Z = α ·∞∑
j=1
α−jεj
Similarly, combining both Lemma 3.1 and Lemma 3.2 we obtain the correspondingresults for S00 and S∗10:
S00 =1
T
T∑t=1
ε4t −
(1
T
T∑t=1
ε2t
)2
+ o(1)a.s.−→ 2 (52)
√T · S∗10 =
1αT
∑Tt=1 Xt−1(ε
2t − 1) + (α̂− α)2
(1
αT
∑Tt=1 X3
t−1
)− 2(α̂− α)2
(1
αT
∑Tt=1 X2
t−1εt
)+ o(1)
1α2T
∑Tt=1 X2
t−1(ε2t − 1) + (α̂− α)2
(1
α2T
∑Tt=1 X4
t−1
)− 2(α̂− α)2
(1
α2T
∑Tt=1 X3
t−1εt
)+ o(1)
28
(53)
Furthermore, we obtain that:
√T · S∗10
a.s.−→
α−2Z · Y21 + α−4 Z2·[Y11]2·F(3)
[F(2)]2 − 2α−6 Z3·Y11·Y12
F(2)
α−4Z2 · Y22 + α−4 Z2·[Y11]2·F(4)
[F(2)]2 − 2α−8 Z4·Y11·Y13
F(2)
= Y∗ (54)
where Y11, Y12, Y13, Y21 and Y22 are defined as in Lemma 3.2. Anderson’s (1959)theorem 2.6 implies that the distributions of Z and Y11 are normal with mean zero and
variance(
α2
α2−1
). These two variables have zero correlation and are in fact independent.
Furthermore, the same theorem implies that Y12 and Y13 have normal distributions
with mean zero and variances(
α4
α4−1
)and
(α6
α6−1
)respectively. Y12 and Y13 are both
independent of Z.Simplifying the above expression of Y∗ according to the definition of F(k) given by
equation (43), we obtain that:
Y∗ =
1α2 Z · Y21 + (α−1)(α+1)2
α3(α2+α+1)Z · Y 2
11 − 2(α2−1)α4 Z · Y11 · Y12
1α4 Z
2 · Y22 + (α2−1)α4(α2+1)
Z2 · Y 211 − 2(α2−1)
α6 Z2 · Y11 · Y13
(55)
Finally, combining the results presented in equations (51), (52) and (54), we concludethat:
TR2 = S−100 .S∗01.S
∗−111 .S∗10
d−→ Y T∗ · Λ−1
z · Y∗ (56)
This terminates the proof of Theorem 3.3.
At this point a few remarks are in order. First of all, as mentioned in the introduc-tion, several terms of the components S00 and S10 (equivalently S∗10) are asymptoticallynegligible (i.e. these become negligible as T increases). In the case of S00, whose ex-panded form is presented in equation (5), all the terms disappear asymptotically exceptfor the two terms 1
T
∑Tt=1 ε2
t and 1T
∑Tt=1 ε4
t . Furthermore, and more importantly, thisis true in all three stationary, unit root and explosive cases. In fact, the asymptoticdistribution of S00 is the same in all three cases and is independent of the value of theparameter α.
On the other hand, the asymptotic results obtained for S10 are very different in theexplosive case and in the non-explosive cases (i.e. |α| ≤ 1). Precisely, it has been shownin the previous two sections that all the terms in S10 are asymptotically negligible when|α| ≤ 1 except for the two terms
∑Tt=1(Xt−1−X)(ε2
t −1) and∑T
t=1(X2t−1−X2)(ε
2t −1).
In other words, these two are the leading terms of S10 in both the stationary and
29
the unit root cases. These results are explicitly presented in equations (??) and (25)respectively. However in the explosive case, as shown by equation (53) in the aboveproof, several other terms in S∗10 do not become negligible when T increases, and thusplay an important role in the asymptotic distribution of TR2.
Finally, the proof of Theorem 3.1 is presented below.
Proof of theorem 3.1. :
To begin with, recall that from Theorem 3.3 we have that TR2 d−→ Y T∗ · Λ−1
z · Y∗.However, note that it would be quite difficult to determine explicitly the distributionof Y∗ given by equation (55) and therefore that of (Y T
∗ · Λ−1z · Y∗) as well.
Nevertheless, it is important to mention at this point that a necessary condition forTR2 = T.S−1
00 .S∗01.S∗−111 .S∗10 to converge to a χ2 is that the moments of (Y T
∗ · Λ−1z · Y∗)
must be the same as those of the χ2 distribution. In particular, the first moment of aχ2 with k degrees of freedom is equal to k. In this case k = 2. Therefore, a sufficientcondition for (Y T
∗ · Λ−1z · Y∗) not to have a χ2 distribution is that its first moment is
different than 2 for all α ∈ R such that |α| > 1.In fact (Y T
∗ · Λ−1z · Y∗) can be written as:
Y T∗ · Λ−1
z · Y∗ =1
2
X∗ · Z
X∗∗ · Z2
T
·
z2
α2(α2−1)z3
α3(α3−1)
z3
α3(α3−1)z4
α4(α4−1)
−1
·
X∗ · Z
X∗∗ · Z2
(57)
where X∗ and X∗∗ are given by:
X∗ =1
α2Y21 +
(α− 1)(α + 1)2
α3(α2 + α + 1)Y 2
11 − 2(α2 − 1)
α4Y11 · Y12
X∗∗ =1
α4Y22 +
(α2 − 1)
α4(α2 + 1)Y 2
11 − 2(α2 − 1)
α6Y11 · Y13
Thus (Y T∗ · Λ−1
z · Y∗) becomes:
Y T∗ · Λ−1
z · Y∗ =∆
2
[X2∗
α4(α4 − 1)− 2 ·X∗ ·X∗∗
α3(α3 − 1)+
X2∗∗
α2(α2 − 1)
](58)
where ∆ = α4(α − 1)(α2 − 1)(α2 + α + 1)2(α3 + α2 + α + 1). Note that Z does notappear in the simplified expression of (Y T
∗ · Λ−1z · Y∗) presented in equation (58) above.
Additionally, we have that the first moment of (Y T∗ · Λ−1
z · Y∗) is given by:
E[Y T∗ · Λ−1
z · Y∗]
=3α8 + 3α5 + 8α4 + 5α3 + 16α2 + 5
2(α2 + 1)(α2 − α + 1)(α4 + α3 + α2 + α + 1)(59)
which is different than 2 for |α| > 1.
30
−15 −10 −5 0 5 10 150
0.5
1
1.5
2
2.5
3
α
Y*T⋅ Λ
z−1 ⋅ Y
*
Figure 1: E[Y T∗ · Λ−1
z · Y∗]
as a function of α
Therefore, (Y T∗ · Λ−1
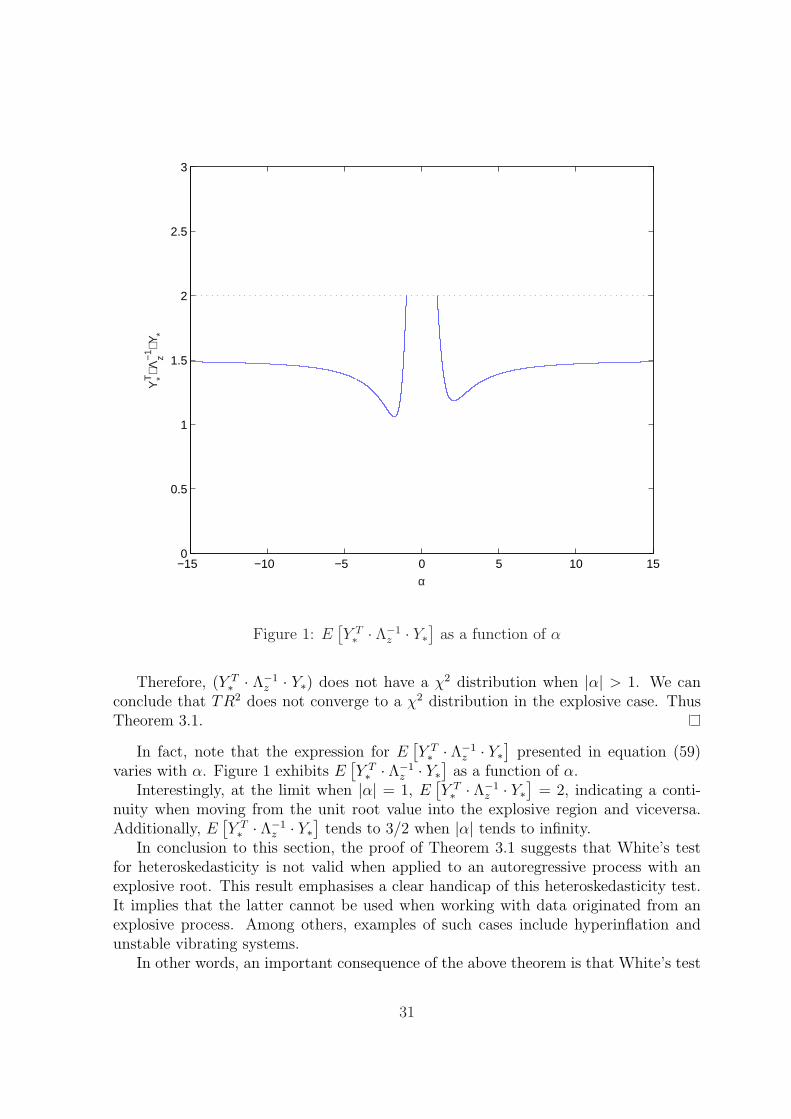
z · Y∗) does not have a χ2 distribution when |α| > 1. We canconclude that TR2 does not converge to a χ2 distribution in the explosive case. ThusTheorem 3.1.
In fact, note that the expression for E[Y T∗ · Λ−1
z · Y∗]
presented in equation (59)varies with α. Figure 1 exhibits E
[Y T∗ · Λ−1
z · Y∗]
as a function of α.Interestingly, at the limit when |α| = 1, E
[Y T∗ · Λ−1
z · Y∗]
= 2, indicating a conti-nuity when moving from the unit root value into the explosive region and viceversa.Additionally, E
[Y T∗ · Λ−1
z · Y∗]
tends to 3/2 when |α| tends to infinity.In conclusion to this section, the proof of Theorem 3.1 suggests that White’s test
for heteroskedasticity is not valid when applied to an autoregressive process with anexplosive root. This result emphasises a clear handicap of this heteroskedasticity test.It implies that the latter cannot be used when working with data originated from anexplosive process. Among others, examples of such cases include hyperinflation andunstable vibrating systems.
In other words, an important consequence of the above theorem is that White’s test
31
for heteroskedasticity is parameter dependent. It is not valid in the general case, andtherefore, only applicable for a certain range of values of the parameter α (i.e. valid for|α| ≤ 1).
We now proceed to the proof of the result concerning the validity of the Jarque-Beranormality test in the explosive case.
Proof of theorem 3.2. :In a similar way to the proof of Theorem 2.2, but applying this time the results
presented in Lemmas 3.1 and 3.2, we obtain that:
αT (α̂− α) =α−T
∑Tt=1 Xt−1εt
α−2T∑T
t=1 X2t−1
= Op(1)
S2 =1
T
T∑t=1
ε2t + Op
(1
T
)P−→ 1 (60)
S22 =
(1
T
T∑t=1
ε2t
)2
+ Op
(1
T
)P−→ 1 (61)
√TS3 =
1√T
T∑t=1
(ε3
t − 3εt
)+ op(1)
d−→ N(0, 6) (62)
And
√T
(S4 − 3S2
2)
=1√T
T∑t=1
(ε4
t − 6ε2t + 3
) d−→ N(0, 24) (63)
Therefore, combining the above results we now obtain that:
TK̂2
3
6=
1
S23
(√TS3√6
)2
d−→ χ2(1) (64)
TK̂2
4
24=
1
S24
(√T
[S4 − 3S2
2]
√24
)2
d−→ χ2(1) (65)
And, following the same argument as in the proof of Theorem 2.2 we show that theabove two convergence results also hold jointly, that is:
T
(K̂2
3
6+
K̂24
24
)d−→ χ2
(2) (66)
which concludes the proof of Theorem 3.2.
The above result proves that the Jarque-Bera normality test is thus theoretically
32
valid in the general case. That is all three, the stationary, the unit root and the explosivecase.
This is also a very important result, in the sense that it comes as a relief giventhat this normality test is widely used in various standard statistical and econometricsoftware packages. Therefore, this paper shows that such test can be used when dealingwith a first order autoregressive processes without the need to worry about the valueof the root present in that model.
33
4 Conclusion
The objective of this paper was to analyse the asymptotic properties of White’s testfor heteroskedasticity and that of the Jarque-Bera test for normality from a time seriesperspective. In particular, we were interested in studying whether these tests are validin the general case when applied to a first order autoregressive process such as (Xt)t∈N0
defined in equation (1).In fact, it has been shown that the validity of White’s test for heteroskedasticity
is parameter dependent. In other words, the latter is valid for some values of theparameter of interest α but it is not valid for others. It has been proved in Section2 that this test works well in the unit root case (when |α| = 1). The validity of thistest in the stationary case (when |α| < 1) was already established by several authors(c.f. Kelejian (1982), Godfrey and Orme (1994) among others). Nevertheless, section3 proved that this test is not valid in the explosive case (when |α| > 1).
This is a very important theoretical result. It implies that in order to do statisticalinference on the parameter α we need to know if heteroskedasticity is present in themodel. But, to test for heteroskedasticity we need to know the value of α! Paraphras-ing, this means that any applied statistician should not use this test unless he/she isabsolutely sure of dealing with data from a stationary or marginally stable process.
Regarding the Jarque-Bera normality test, it was proved that this test is theoreti-cally valid in the general case when applied to a first order autoregressive process. Thismeans that the Jarque-Bera test for normality can be used when dealing with a firstorder autoregressive process independently of whether the latter contains a stationary,an unit or an explosive root.
It is worthwhile mentioning that the results presented in this paper are based ona purely theoretical framework. This applies in particular to the results obtained forWhite’s test for heteroskedasticity. In order to know in practice how different the distri-bution of the sufficient statistic TR2 in the explosive case is from that of a chi-squareddistribution, some computer simulations could be very valuable. From a practical pointof view, this test for heteroskedasticity could still be applicable for a certain range ofvalues of the parameter α that could be less restrictive than the theoretical one. Thisis certainly an area that needs further investigation.
Alternatively, a new heteroskedasticity test could be designed altogether. Thisshould essentially have solid basis upon the corresponding probability and measuretheory. Ideally, a heteroskedasticity test should not be parameter dependent. Also itshould be applicable to a multivariate model (i.e. VAR(k) models), and furthermore,should be able to accommodate for different types of deterministic terms in the model.
34
References
[1] Ali, M.M. and Giaccotto, C. (1984). A study of several new and existing testsfor heteroscedasticity in the general linear model. Journal of Econometrics 26,355-373.
[2] Amemiya, T. (1977). A note on a heteroskedasticity model. Journal of Economet-rics 6, 365-370.
[3] Anderson, T.W. (1959). On asymptotic distributions of estimates of parameters ofstochastic difference equations. Annals of Mathematical Statistics 30, 676-687.
[4] Caceres, C. and Nielsen, B. (2006). Limiting Distributions of Non-StationaryProcesses. Working paper, Nuffield College, Oxford.
[5] Chan, N.H. and Wei, C.Z. (1988). Limiting Distributions of Least Squares Esti-mates of Unstable Autoregressive Processes. Annals of Statistics 16, 367-401.
[6] Doornik, J.A. (1996). Testing Vector Autocorrelation and Heteroscedasticity inDynamic Models. Econometric Society 7th World Congress, Tokyo.
[7] Godfrey, L.G. and Orme, C.D. (1994). The sensitivity of some general checks toomitted variables in the linear model. International Economic Review 35, 489-506.
[8] Hamilton, J.D. (1994). Time Series Analysis. Princeton University Press.
[9] Helland, I. S. (1982). Central Limit Theorems for Martingales with Discrete orContinuous Time. Scandinavian Journal of Statistics 9, 79-94.
[10] Ibragimov, R. and Phillips, P.C.B. (2004). Regression Asymptotics Using Martin-gale Convergence Methods. Cowles Foundation Discussion paper No. 1473.
[11] Jarque, C.M. and Bera, A.K. (1980). Efficient tests for normality, homoscedasticityand serial independence of regression residuals. Economic Letters 6, 255-259.
[12] Jeganathan, P. (1988). On the strong approximation of the distributions of esti-mators in linear stochastic models, I and II: stationary and explosive AR models.Annals of Statistics 16, 1283-1314.
[13] Johansen, S. (1996). Likelihood-based inference in cointegrated vector autoregressivemodels, 2nd print, Oxford University Press.
[14] Kelejian, H.H. (1982). An Extension of a Standard Test for Heteroskedasticity toa System Framework. Journal of Econometrics 20, 325-333.
[15] Kilian, L. and Demiroglu, U. (2000). Residual-Based Tests for Normality in Au-toregressions: Asymptotic Theory and Simulation Evidence. Journal of Businessand Economic Statistics 18, 40-50.
35
[16] Lai, T.L. and Wei, C.Z. (1983). Asymptotic properties of general autoregressivemodels and strong consistency of least-squares estimates of their parameters. Jour-nal of Multivariate Analysis 13, 1-23.
[17] Lai, T.L. and Wei, C.Z. (1985). Asymptotic properties of multivariate weightedsums with applications to stochastic regression in linear dynamic systems. In P.R.Krishnaiah, ed., Multivariate Analysis VI, Elsevier Science Publishers, 375-393.
[18] Lutkepohl, H. and Schneider, W. (1989). Testing for Nonnormality of Autoregres-sive Time Series. computational Statistics Quarterly 2, 151-168.
[19] Nielsen, B. (2001). Order determination in general vector autoregressions. Discus-sion paper, Nuffield College, Oxford.
[20] Nielsen, B. (2004). Unit Roots. Advanced Econometrics lecture notes, MPhil inEconomics, Oxford University.
[21] Nielsen, B. (2005). Strong consistency results for least squares estimators in generalvector autoregressions with deterministic terms. Econometric Theory.
[22] Rubin, H. (1950). Consistency of maximum-likelihood estimates in the explosivecase. Statistical Inference in Dynamic Economic Models (ed. T.C. Koopmans),356-364, New York: Wiley.
[23] White, H. (1980). A Heteroskedastic-Consistent Covariance Matrix and a DirectTest for Heteroskedasticity. Econometrica 48, 817-838.
[24] White, J. (1958). The Limimiting Distribution of the Serial Correlation Coefficientin the Explosive Case. Annals of Mathematical Statistics 29, 1188-1197.
[25] Wooldridge, J.M. (1999). Asymptotic properties of some specification tests in linearmodels with integrated processes. In R.F. Engle and H. White, Cointegration,Causality and Forecasting: Festschrift in Honour of Clive W.J.Granger. OxfordUniversity Press.