SCIENCE CHINA Mathematics . ARTICLES . April 2012 Vol. 55 No. 4: 787–804 doi: 10.1007/s11425-011-4352-0 c Science China Press and Springer-Verlag Berlin Heidelberg 2012 math.scichina.com www.springerlink.com Checking for normality in linear mixed models WU Ping 1, ∗ , ZHU LiXing 2,3 & FANG Yun 4 1 School of Finance and Statistics, East China Normal University, Shanghai 200241, China; 2 School of Statistics and Mathematics, Yunnan University of Finance and Economics, Yunnan 650221, China; 3 The Department of Mathematics, Hong Kong Baptist University, Hong Kong 999077, China; 4 Mathematics and Science College, Shanghai Normal University, Shanghai 200234, China Email: [email protected], [email protected], kellyfang0221@gmail.com Received August 20, 2010; accepted May 22, 2011; published online January 9, 2012 Abstract Linear mixed models are popularly used to fit continuous longitudinal data, and the random effects are commonly assumed to have normal distribution. However, this assumption needs to be tested so that further analysis can be proceeded well. In this paper, we consider the Baringhaus-Henze-Epps-Pulley (BHEP) tests, which are based on an empirical characteristic function. Differing from their case, we consider the normality checking for the random effects which are unobservable and the test should be based on their predictors. The test is consistent against global alternatives, and is sensitive to the local alternatives converging to the null at a certain rate arbitrarily close to 1/ √ n where n is sample size. Furthermore, to overcome the problem that the limiting null distribution of the test is not tractable, we suggest a new method: use a conditional Monte Carlo test (CMCT) to approximate the null distribution, and then to simulate p-values. The test is compared with existing methods, the power is examined, and several examples are applied to illustrate the usefulness of our test in the analysis of longitudinal data. Keywords linear mixed models, estimated best linear unbiased predictors, BHEP tests, conditional Monte Carlo test MSC(2010) 62G10, 62E20 Citation: Wu P, Zhu L X, Fang Y. Checking for normality in linear mixed models. Sci China Math, 2012, 55(4): 787–804, doi: 10.1007/s11425-011-4352-0 1 Introduction To analyze continuous longitudinal data, linear mixed models have been applied frequently. A commonly used assumption is that the random effects as well as the error terms follow normal distributions, or more generally, parametric distributions, see, e.g., [7, 8, 14]. The importance of the normality of random effects has been extensively investigated in the literature, please see [10, 16, 17, 22, 25, 26]. Testing normality for mixed models has attracted much attention from statisticians, for example [2, 11]. Since the random effects are not observable, the distributional properties of the predicted random effects, say the estimated best linear unbiased predictions (EBLUPs) become critical inferring tools. [15] proposed using weighted normal plots by comparing the expected and the empirical cumulative func- tions of the standardized linear combination of EBLUPs to check various departures from the normality assumption. For one-level random effects, [21] extended the pointwise result of [15] to a result for a weighted empirical process, and constructed a test that is based on the difference between a weighted empirical distribution function of the standardized EBLUPs and its expectation. Inspired by [21], [28] ∗ Corresponding author
1School of Finance and Statistics, East China Normal University, Shanghai 200241, China;2School of Statistics and Mathematics, Yunnan University of Finance and Economics, Yunnan 650221, China;
3The Department of Mathematics, Hong Kong Baptist University, Hong Kong 999077, China;4Mathematics and Science College, Shanghai Normal University, Shanghai 200234, China
where V and Ω are defined in Section 2, G0(t) and K0(s, t) are defined as above, and where a(t; θ0) =
limn→∞ n−1∑n
i=1 ai(t, θ0) provided that the limit exists and ai(t, θ0) is the derivative of Eθ(cos(t′ui) +
sin(t′ui)) evaluated at θ = θ0.
By Theorem 3.1 and the continuous mapping theorem, we have the following corollary.
Corollary 3.1. Under the conditions of Theorem 3.1, we have that n∫t∈Rq G
2n(t)ϕγ(t)dt converges in
distribution to∫t∈Rq G
20(t)ϕγ(t)dt.
3.2 Power study
In this section, we investigate the power properties of Tn,γ . Let a triangular array (Yn1, Xn1, Zn1, ln1), . . . ,
(Ynn, Xnn, Znn, lnn), n � q+1, follow (1) but the random effects have the Lebesgue density, for 0 � α �1/2,
fn(b) = ϕ(b;D)(1 + n−αh(b)), (12)
where ϕ(·;D) is the density of Nq(0, D) and h(·) is a bounded measurable function such that
∫
b∈Rq
h(b)ϕ(b;D)db = 0.
Here n is assumed to be large enough to guarantee that fn(·) is nonnegative.In what follows, we write Vi = σ2Ili + ZniDZ ′
ni, Wi = DZ ′niV
−1i ZniD, un(θ) = n−1
∑ni=1 uni(θ),
Sn(θ) = n−1∑n
i=1(uni(θ)− un(θ))(uni(θ)− un(θ))′, and Uni(θ) = S
−1/2n (uni(θ)− un(θ)), where uni(θ) =
W−1/2i DZ ′
niV−1i (Yni − Xniβ). Here uni is not the same as that defined in Subsection 3.1. Moreover,
Qi(Yi −Xiβ, θ) in (4) is replaced by Qni(Yni −Xniβ, θ).
The following theorem states that our test is able to detect alternatives which converge to the normal
distribution at the rate n−1/2, irrespective of the underlying dimension q of the random effects.
Theorem 3.2. If the random effects have the density function (12), then when α = 1/2, n1/2Gn(t)
converges in distribution to a zero mean Gaussian process G(t)+C(t) in C(Rq), where the shift function
C(t) is defined in (A13) in the Appendix. In addition, n∫t∈Rq G
2n(t)ϕγ(t)dt converges in distribution to∫
t∈Rq (G(t) + C(t))2ϕγ(t)dt. When α < 1/2 in (12), Tn,γ converges in probability to infinity.
Remark 3.1. From Theorem 3.2, we know that the new test is consistent against all global alternatives
(corresponding to α = 0) and can detect the local alternative converging to the null at up to the parametric
rate n−1/2 corresponding to 0 < α � 1/2.
Note that the asymptotic distribution of Tn,γ depends on the unknown parameter θ, even in the limit.
Then we propose a Monte Carlo approximation to simulate the critical values in the following section.
792 Wu P et al. Sci China Math April 2012 Vol. 55 No. 4
4 A conditional Monte Carlo test
The idea is simple and the procedure is easy to implement. We describe its algorithm as follows with
some notations that are defined in the appendix. Let Y ∗i = V
−1/2i0 (Yi −Xiβ0) (i = 1, . . . , n). Referring
to [26], (3) and (5), we have
∂Li(θ0)
∂β= X ′
iV−1/2i0 Y ∗
i ,
∂Li(θ0)
∂σ2= −1
2tr(V −1
i0 ) +1
2Y ∗′i V −1
i0 Y ∗i ,
∂Li(θ)
∂δj= −1
2tr
(V −1i0 Zi
∂D
∂δjZ ′i
)+
1
2Y ∗′
V−1/2i0 Zi
∂D
∂δjZ ′iV
−1/2i0 Y ∗,
and then,
Qi(Y∗i ; θ0) =
(∂Li(θ0)
∂σ2,∂Li(θ)
∂δ1, . . . ,
∂Li(θ)
∂δk,∂Li(θ0)
∂β′
)′, i = 1, . . . , n,
where tr(·) is denoted for trace. On the other hand, (7) implies that u0i = ui(θ0) = W−1/2i0 D0Z
′iV
−1/2i0 Y ∗
i .
Denote u0i = u0i(Y∗i ). From (5), (A9), and (A10), thus, we have
Gn(t) =1
n
n∑
i=1
[cos(t′u0i(Y
∗i )) + sin(t′u0i(Y
∗i ))− exp
{− ‖t‖2
2
}
+
{1
2(t′u0i(Y
∗i ))
2 − ‖t‖22
− t′u0i(Y∗i )
}exp
{− ‖t‖2
2
}]
+ a′(t; θ0)Ω−10
1
n
n∑
i=1
Qi(Y∗i ; θ0) + op(n
−1/2).
Under the normality hypothesis, Y ∗i is standard multivariate normal. Therefore, we can propose a
conditional Monte Carlo test (CMCT) procedure to approximate the null distribution of the test. The
procedure is as follows:
Step 1. Generate m sets of Y0n = (Y01, . . . , Y0n), say Y(j)0n , j = 1, . . . ,m. Here Y01, . . . , Y0n are
mutually independent and obey standard normal distributions N (0, Il1), . . . ,N (0, Iln) respectively. That
is, Y01, . . . , Y0n has the same distribution as Y ∗1 , . . . , Y
∗n .
Step 2. Denote the Monte Carlo counterpart of the statistic Gn(t) by
Gn(Y0n, t) =1
n
n∑
i=1
[cos(t′u0i(Y0i)) + sin(t′u0i(Y0i))− exp
{− ‖t‖2
2
}
+
{1
2(t′u0i(Y0i))
2 − ‖t‖22
− t′u0i(Y0i)
}exp
{− ‖t‖2
2
}]
+1
n
n∑
i=1
a′i(t; θ)Ω−1 1
n
n∑
i=1
Qi(Y0i; θ), (13)
and the resulting test statistic
Tn,γ(Y0n) = n
∫
Rq
G2n(Y0n, t)ϕγ(t)dt. (14)
Compute m values of Tn,γ(Y0n), say Tn,γ(Y(j)0n ), j = 1, . . . ,m. Here the ai(·)s are defined in the proof of
Theorem 3.1.
Step 3. Compute the 1− α quartile of the Tn,γ(Y(j)0n )s as the α-level critical value for Tn,γ , or the
estimated p-values:
pn = k/(m+ 1),
where k = #{Tn,γ(Y(j)0n ) � T 0
n,γ , j = 0, 1, . . . ,m} with T(0)n,γ = Tn,γ .
The validity of the CMCT is justified by the following theorem.
Wu P et al. Sci China Math April 2012 Vol. 55 No. 4 793
Theorem 4.1. Assume that the conditions in Theorem 3.1 hold. When the random effects have
the density function (12) for almost all sequences of {(Xi, Zi, li, Yi)}∞i=1, the conditional distribution of
Tn,γ(Y0n) converges to the limiting null distribution of Tn,γ.
This conclusion means the CMCT is consistent and therefore asymptotically valid. Furthermore as
h(·) = 0 corresponds to the null hypothesis and h(·) �= 0 to the local alternative, the conclusion indicates
that the critical values determined by the CMCT, under local alternatives, equals approximately the ones
under the null hypothesis. Hence the critical values remain unaffected in the large sample sense by the
underlying distribution of the random effects with small perturbations from the normality hypothesis.
For a global alternative, that is α = 0, Tn,γ(Y0n) has a finite limit while Tn,γ goes to infinity. Therefore
the test is consistent.
5 Simulation studies and applications
5.1 Simulation studies
In order to examine the power performance of our test, a set of simulations is carried out. In all of the
simulations, the sample sizes n = 50, 100 are both considered, and the number of replications m is 1000
to simulate p-values. We conduct the simulation studies in three cases.
Case I. We first repeat parts of the simulation studies of [21] and [28] in the case of one-level
random effects. Following them, the null distribution of the random effect bi is standard normal, li ∼Poisson(5) + 1, and the true value of β is (0, 10, 12)′ which are assigned randomly to units. We choose
the random effects distribution as N (0, 1), 0.46t(2), or Γ(1, 1), exactly the same as those used by [28].
Case II. We then compare our approach to the order selection (OS) tests in [2]. We follow the model
in Section 6.3 of [2] to generate data. The true value of β is set to be (1, 2)′. li is fixed to be 3. The first
column of coefficient matrix Xi for β is 1 with the second column generated from Uniform (0, 10). The
distribution of the error is normal with mean 0 and variance 0.3. The one-level random effect is either
generated from N (0, 0.1), t(1) or a mixture normal distribution: with probability 0.1, an N (−4, 0.1)
distribution and with probability 0.9 an N (4, 0.1) distribution, just as that used by [2].
Case III. We also conduct simulation studies when the random effects are two-dimensional. In this
case, we also use li and β that are the same as that of one-level random effects in Case I. We generate
the covariates zi from a normal distribution
N(0,
(1 0.5
0.5 1
)).
Since unstructured covariation matrix D is usually used, we consider that the null hypothesis is the
two-dimensional normal distribution with 0 mean and unstructured covariation, and one alternative is a
two-dimensional t distribution with a correlation matrixDt = ( 10.8
0.81 ) and 2 degree of freedom denoted by
t(Dt, 2), and another one is a two-dimensional independent gamma distribution with marginal distribution
Γ(1, 1), which is denoted by Γ2(1, 1) for notational simplicity.
To illustrate the dependence of the power of our test Tn,γ on the parameter γ, Figures 1–6 exhibit plots
of the empirical power (based on 1000 CMCT) for one-level and two-level random effects as a function
of γ under different alternatives when the samples sizes n = 50, 100 and nominal levels α = 0.05, 0.1, so
that we can suggest a value of γ for practical use.
From Figures 1–6, we can see that power curves get up quickly in all the plots when γ is very small.
However, the curves in Figures 3 and 4 keep flat after a rising stage, while other plots tell us that the
power declines after a peak. It is observed that different patterns of power curves are exhibited with
different alternative distributions. Similar findings were also exhibited in [9]. But (see [9]) we have no
theoretical explanation for these behaviors of power against tuning parameter γ up to now. More research
in the future is necessary to understand dependence of power on the parameter γ. By Figures 1–6, we
can observe that the power of Tn,γ is relatively high when γ is close to 0.6. Then, we report the estimated
794 Wu P et al. Sci China Math April 2012 Vol. 55 No. 4
0 2 4 6 8 10 12 14 16 18 200
10
20
30
40
50
60
70
80Power (n = 50)
α = 0.10α = 0.05
0 2 4 6 8 10 12 14 16 18 2010
20
30
40
50
60
70
80
90
100Power (n = 100)
α = 0.10α = 0.05
γ γ
Pow
er
Pow
er
Figure 1 Power of the test statistic Tn,γ versus γ for bi ∼ 0.46t(2) and sample sizes n = 50 and n = 100.
0 2 4 6 8 10 12 14 16 18 200
10
20
30
40
50
60
70
80
90Power (n = 50)
0 2 4 6 8 10 12 14 16 18 200
10
20
30
40
50
60
70
80
90
100 Power (n = 100)
α = 0.10α = 0.05
α = 0.10α = 0.05
γ γ
Pow
er
Pow
er
Figure 2 Power of the test statistics Tn,γ versus γ for bi ∼ Γ(1, 1) and sample sizes n = 50 and n = 100.
0 2 4 6 8 10 12 14 16 18 200
102030405060708090
100110
Power (n = 50)
0 2 4 6 8 10 12 14 16 18 200
102030405060708090
100110
Power (n = 100)
α = 0.10α = 0.05 α = 0.10
α = 0.05
γ γ
Pow
er
Pow
er
Figure 3 Power of the test statistics Tn,γ versus γ for bi ∼ t(1) and sample sizes n = 50 and n = 100.
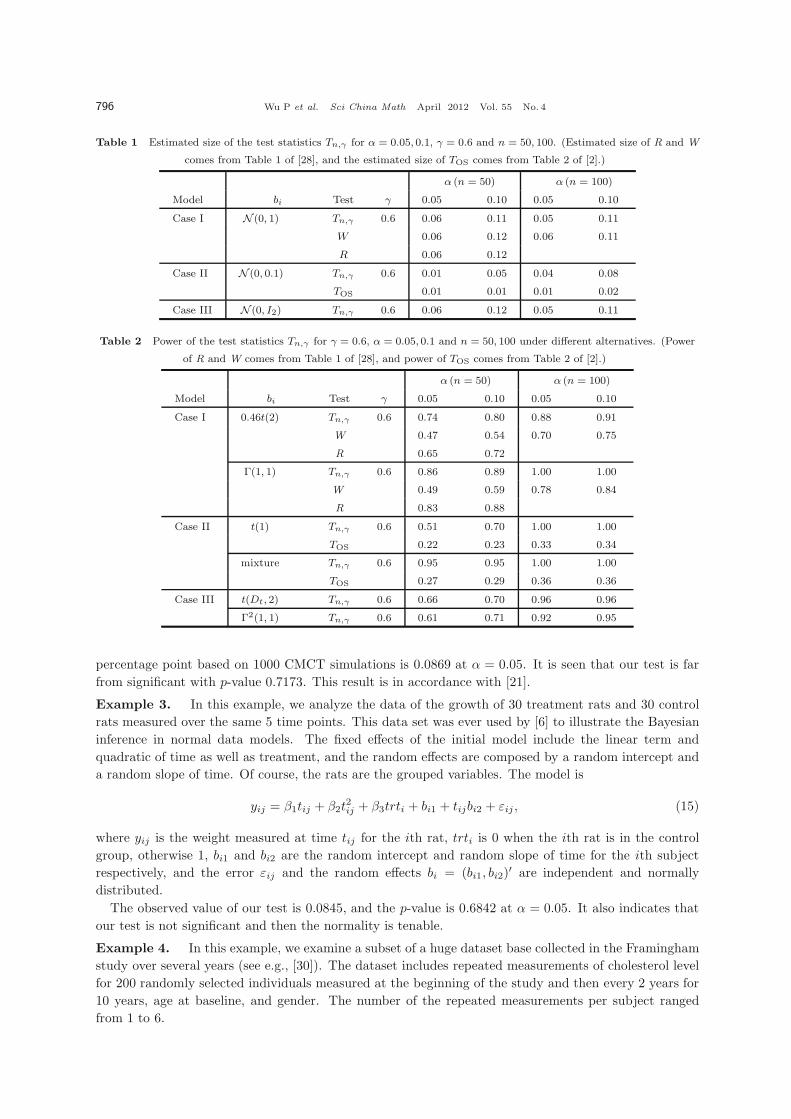
size in Table 1 under normality, and the power under different alternatives in Table 2 for γ = 0.6. To make
a comparison with R, W , TOS that were suggested by [2, 21, 28], we have cited part of their simulation
results in Table 1 [28] and Table 2 [2].
From Table 1, we can see that our test can in most cases maintain the significance level. For the
power, Table 2 shows that Tn,γ outperforms R, W and TOS in all of the cases. In conclusion, the limited
simulations suggest that the new test with γ = 0.6 is recommendable.
5.2 Applications
In this section, we apply our test to four data sets to illustrate further. From the simulation studies, the
Wu P et al. Sci China Math April 2012 Vol. 55 No. 4 795
0 2 4 6 8 10 12 14 16 18 200
102030405060708090
100110
Power (n = 50)
2 4 6 8 10 12 14 16 18 200
102030405060708090
100110
Power (n = 50)
0
α = 0.10α = 0.05
α = 0.10α = 0.05
γ γ
Pow
er
Pow
er
Figure 4 Power of the test statistics Tn,γ versus γ for bi ∼Mixnorm and sample sizes n = 50 and n = 100.
0 1 2 3 4 5 6 7 8 9 1010
20
30
40
50
60
70
80Power (n = 50)
0 1 2 3 4 5 6 7 8 9 1030
40
50
60
70
80
90
100Power (n = 100)
α = 0.10α = 0.05
α = 0.10α = 0.05
Pow
er
Pow
er
γ γ
Figure 5 Power of the test statistics Tn,γ versus γ for bi ∼ t(Dt, 2) and sample sizes n = 50 and n = 100.
0 1 2 3 4 5 6 7 8 9 1010
20
30
40
50
60
70
80Power (n = 50)
0 1 2 3 4 5 6 7 8 9 1020
30
40
50
60
70
80
90
100 Power (n = 100)
α = 0.10α = 0.05
α = 0.10α = 0.05
Pow
er
Pow
er
γ γ
Figure 6 Power of the test statistics Tn,γ versus γ for bi ∼ Γ2(1, 1) and sample sizes n = 50 and n = 100.
weight parameter is chosen to be γ = 0.6.
Example 1. We first apply our test to the data from an experiment investigating the enzyme activity
in rye bread dough. In this dataset, there are 602 observations and n = 56 groups of size 8− 12. See [4].
The observed value of our goodness-of-fit test statistics is 0.1117, and the estimated percentage point
based on 1000 CMCT simulations is 0.087 at α = 0.05. Our test is significant with a p-value of 0.018.
Ritz’s test is also highly significant (p < 0.005) but Waagepetersen’s is not (p = 0.3).
Example 2. We now consider the data set used in Example 2 of [21]. That is a part of a larger growth
study measuring the weight of chickens. There are 2017 observations and n = 169 groups of size 4− 44.
See [21] for details. The observed value of our goodness-of-fit test statistic is 0.0094, and the estimated
796 Wu P et al. Sci China Math April 2012 Vol. 55 No. 4
Table 1 Estimated size of the test statistics Tn,γ for α = 0.05, 0.1, γ = 0.6 and n = 50, 100. (Estimated size of R and W
comes from Table 1 of [28], and the estimated size of TOS comes from Table 2 of [2].)
α (n = 50) α (n = 100)
Model bi Test γ 0.05 0.10 0.05 0.10
Case I N (0, 1) Tn,γ 0.6 0.06 0.11 0.05 0.11
W 0.06 0.12 0.06 0.11
R 0.06 0.12
Case II N (0, 0.1) Tn,γ 0.6 0.01 0.05 0.04 0.08
TOS 0.01 0.01 0.01 0.02
Case III N (0, I2) Tn,γ 0.6 0.06 0.12 0.05 0.11
Table 2 Power of the test statistics Tn,γ for γ = 0.6, α = 0.05, 0.1 and n = 50, 100 under different alternatives. (Power
of R and W comes from Table 1 of [28], and power of TOS comes from Table 2 of [2].)
α (n = 50) α (n = 100)
Model bi Test γ 0.05 0.10 0.05 0.10
Case I 0.46t(2) Tn,γ 0.6 0.74 0.80 0.88 0.91
W 0.47 0.54 0.70 0.75
R 0.65 0.72
Γ(1, 1) Tn,γ 0.6 0.86 0.89 1.00 1.00
W 0.49 0.59 0.78 0.84
R 0.83 0.88
Case II t(1) Tn,γ 0.6 0.51 0.70 1.00 1.00
TOS 0.22 0.23 0.33 0.34
mixture Tn,γ 0.6 0.95 0.95 1.00 1.00
TOS 0.27 0.29 0.36 0.36
Case III t(Dt, 2) Tn,γ 0.6 0.66 0.70 0.96 0.96
Γ2(1, 1) Tn,γ 0.6 0.61 0.71 0.92 0.95
percentage point based on 1000 CMCT simulations is 0.0869 at α = 0.05. It is seen that our test is far
from significant with p-value 0.7173. This result is in accordance with [21].
Example 3. In this example, we analyze the data of the growth of 30 treatment rats and 30 control
rats measured over the same 5 time points. This data set was ever used by [6] to illustrate the Bayesian
inference in normal data models. The fixed effects of the initial model include the linear term and
quadratic of time as well as treatment, and the random effects are composed by a random intercept and
a random slope of time. Of course, the rats are the grouped variables. The model is