Page 1
CMPEN 411VLSI Digital Circuits
Spring 2011
Lecture 20: Multiplier Design
Sp11 CMPEN 411 L20 S.1
Lecture 20: Multiplier Design
[Adapted from Rabaey’s Digital Integrated Circuits, Second Edition, ©2003 J. Rabaey, A. Chandrakasan, B. Nikolic]
Page 2
Review: Basic Building Blocks
� Datapath
� Execution units
- Adder, multiplier, divider, shifter, etc.
� Register file and pipeline registers
� Multiplexers, decoders
� Control
Sp11 CMPEN 411 L20 S.2
� Finite state machines (PLA, ROM, random logic)
� Interconnect
� Switches, arbiters, buses
� Memory
� Caches (SRAMs), TLBs, DRAMs, buffers
Page 3
The Binary Multiplication
x
Multiplicand
Multiplier
1 0 1 0 1 0
1 0 1 0 1 0
1 0 1 1
Sp11 CMPEN 411 L20 S.3
+
Partial products
Result
1 0 1 0 1 0
1 1 1 0 0 1 1 1 0
0 0 0 0 0 0
1 0 1 0 1 0
Page 4
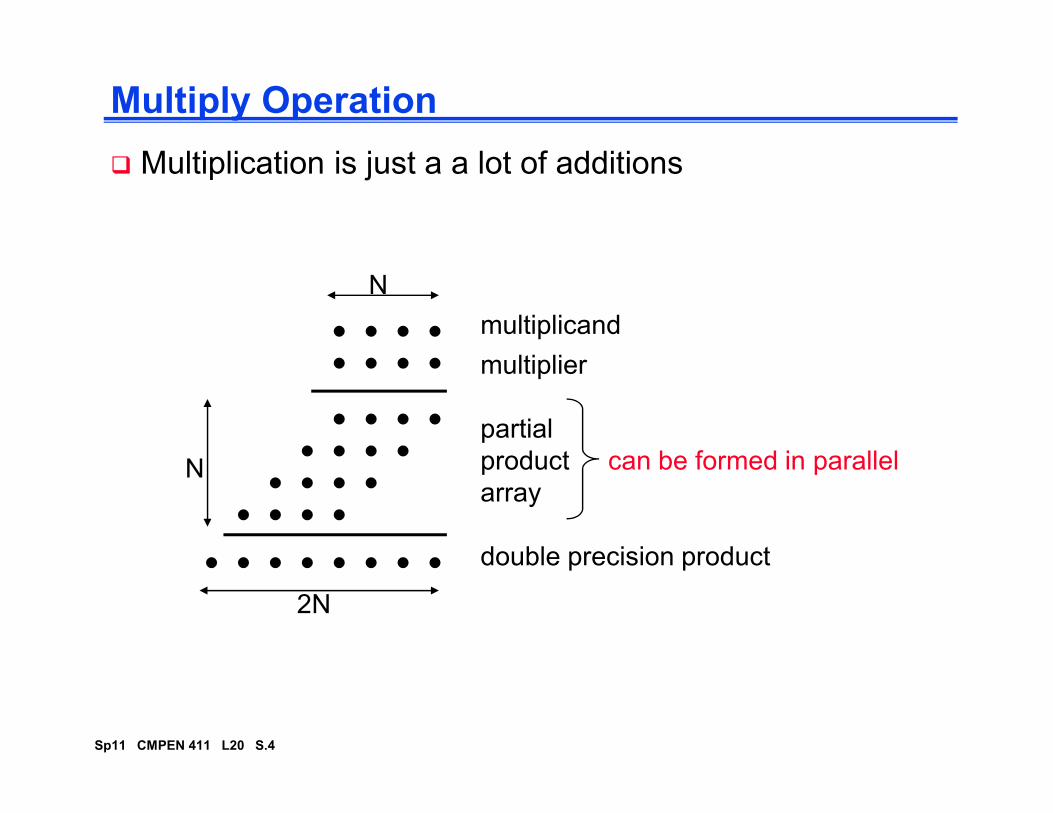
Multiply Operation
� Multiplication is just a a lot of additions
multiplicand
multiplier
N
Sp11 CMPEN 411 L20 S.4
partial
product
array
double precision product
2N
N can be formed in parallel
Page 5
Multiplication Approaches
� Right shift and add
� Partial product array rows are accumulated from top to bottom on an N-bit adder
- After each addition, right shift (by one bit) the accumulated partial product to align it with the next row to add
� Time for N bits Tserial_mult = O(N Tadder) = O(N2) for a RCA
� Making it faster
� Use a faster adder
Sp11 CMPEN 411 L20 S.5
� Use a faster adder
� Use higher radix (e.g., base 4) multiplication – O(N/2 Tadder)
- Use multiplier recoding to simplify multiple formation (booth)
� Form the partial product array in parallel and add it in parallel
� Making it smaller (i.e., slower)
� Use serial-parallel mult
� Use an array multiplier
- Very regular structure with only short wires to nearest neighbor cells. Thus, very simple and efficient layout in VLSI Can be easily and efficiently pipelined
Page 6
Serial-parallel multiplier structure
Sp11 CMPEN 411 L20 S.6
Page 7
The Array Multiplier
Y0
Y1
X3 X2 X1 X0
X3
HA
X2
FA
X1
FA
X0
HA
Y2X3 X2 X1 X0Z1
Z0
Sp11 CMPEN 411 L20 S.7
FA FA FA HA
Z3Z6Z7 Z5 Z4
Y3X3
FA
X2
FA
X1
FA
X0
HA
Z2
Page 8
The MxN Array Multiplier— Critical Path
HA FA FA HA
HAFAFAFA Critical Path 1
Sp11 CMPEN 411 L20 S.8
FAFA FA HA
Critical Path 2
Critical Path 1 & 2
Page 9
Carry-Save Multiplier
HA HA HA HA
FAFAFAHA
FAHA FA FA
Sp11 CMPEN 411 L20 S.9
FAHA FA HA
Vector Merging Adder
Page 10
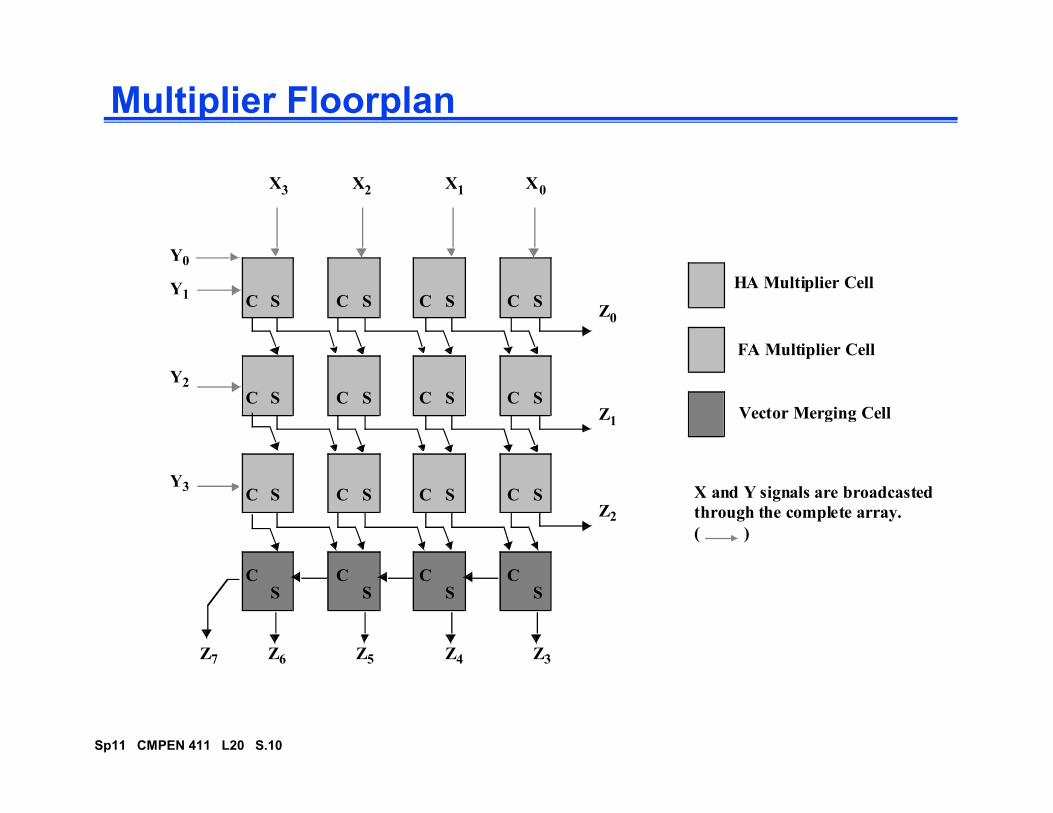
Multiplier Floorplan
SCSCSCSC
SCSCSCSC
Z0
Z
X0X1X2X3
Y1
Y2
Y0
Vector Merging Cell
HA Multiplier Cell
FA Multiplier Cell
Sp11 CMPEN 411 L20 S.10
SCSCSCSC
SCSCSCSC
SC
SC
SC
SC
Z1
Z2
Z3Z4Z5Z6Z7
Y3
Vector Merging Cell
X and Y signals are broadcasted
through the complete array.
( )
Page 11
Booth multiplier
� Encoding scheme to reduce number of stages in multiplication.
� Performs two bits of multiplication at once—requires half the stages.
� Each stage is slightly more complex than simple multiplier, but adder/subtracter is almost as small/fast as adder.
Sp11 CMPEN 411 L20 S.11
adder.
Page 12
Booth encoding
� Two’s-complement form of multiplier:
� y = -2nyn + 2n-1yn-1 + 2n-2yn-2 + ... (first bit is the sign bit)
(example, y=18=010010 y= -18 = 101110 )
� Rewrite using 2a = 2a+1 - 2a:
� y = 2n(yn-1-yn) + 2n-1(yn-2 -yn-1) + 2n-2(yn-3 -yn-2) + ...
� Consider first two terms: by looking at three bits of y, we
Sp11 CMPEN 411 L20 S.12
� Consider first two terms: by looking at three bits of y, we can determine whether to add x, 2x to partial product.
Page 13
Booth actions
yi yi-1 yi-2 increment
0 0 0 0
� y = 2n(yn-1-yn) + 2n-1(yn-2 -yn-1) + 2n-2(yn-3 -yn-2) + ...
� Consider first two terms: by looking at three bits of y, we can determine whether to add x, 2x to partial product.
Sp11 CMPEN 411 L20 S.13
0 0 1 x
0 1 0 x
0 1 1 2x
1 0 0 -2x
1 0 1 -x
1 1 0 -x
1 1 1 0
Page 14
Booth example
� x = 1001 (910), y = 0111 (710).
� P0 = 00000000
� y3y2y1=011 y1y0y-1=11(0)
� y1y0y-1 = 110, P1 = P0 - (1001) = 11110111
� x shift left for 2 bits to be 100100
Sp11 CMPEN 411 L20 S.14
� y3y2y1 = 011, P2 = P1+ (10*100100) =
11110111+01001000 = 001111111 (6310)
� An array multiplier needs N addtions, booth multiplier needs only N/2 additions
Page 15
Review: A 64-bit Adder/Subtractor
1-bit
FA S0
C0=Cin
C1
1-bit
FA S1
C2
1-bit
� Ripple Carry Adder (RCA) built out of 64 FAs
� Subtraction – complement all subtrahend bits (xor gates) and set the low order carry-in
A0
B0
A1
B1
A
add/subt
Sp11 CMPEN 411 L20 S.15
1-bit
FA S2
C3
C64=Cout
1-bit
FA S63
C63
. . .
� RCA
� advantage: simple logic, so small (low cost)
� disadvantage: slow (O(N) for N bits) and lots of glitching (so lots of energy consumption)
A2
B2
A63
B63
Page 16
Booth structure
Sp11 CMPEN 411 L20 S.16
Page 17
Wallace-Tree Multiplier
6 5 4 3 2 1 0 6 5 4 3 2 1 0
Partial products First stage
Bit position
(a) (b)
Sp11 CMPEN 411 L20 S.17
6 5 4 3 2 1 0 6 5 4 3 2 1 0
Second stage Final adder
FA HA
(a) (b)
(c) (d)
Page 18
Wallace-Tree Multiplier
Partial products
First stageHA HA
x3y3
x3y2
x2y3
x1y1x3y0 x2y0 x0y1
x0y2
x2y2
x1y3
x1y2x3y1
x0y3 x1y0 x0y0x2y1
Sp11 CMPEN 411 L20 S.18
Second stage
Final adder
FA FA FA FA
z7 z6 z5 z4 z3 z2 z1 z0
Full adder = (3,2) compressor
Page 19
Making it Faster: Tree Multiplier Structure
partial
product mux
Q (‘ier)
D (‘icand)
D
D
D
0
0
0
0
multiple
forming
circuits
Sp11 CMPEN 411 L20 S.19
product
array
reduction
tree
fast carry
propagate
adder (CPA)P (product)
mux
+
reduction
tree (log N)
+
CPA (log N) inte
rconnect
Page 20
(4,2) Counter
� Built out of two (3,2) counters (just FA’s!)
� all of the inputs (4 external plus one internal) have the same weight (i.e., are in the same bit position)
� the internal carry output is fed to the next higher weight position (indicated by the )
Sp11 CMPEN 411 L20 S.20
(3,2)
(3,2)Note: Two carry outs - one
“internal” and one “external”
Page 21
Tiling (4,2) Counters
(3,2)
(3,2)
(3,2)
(3,2)
(3,2)
(3,2)
Sp11 CMPEN 411 L20 S.21
� Reduces columns four high to columns only two high
� Tiles with neighboring (4,2) counters
� Internal carry in at same “level” (i.e., bit position weight) as the internal carry out
Page 22
Tiling (4,2) Counters
(3,2)
(3,2)
(3,2)
(3,2)
(3,2)
(3,2)
Sp11 CMPEN 411 L20 S.22
� Reduces columns four high to columns only two high
� Tiles with neighboring (4,2) counters
� Internal carry in at same “level” (i.e., bit position weight) as the internal carry out
Page 23
4x4 Partial Product Array Reduction
multiplicand
multiplier
partial
product
array
� Fast 4x4 multiplication using (4,2) counters
� How would you lay it out?
Sp11 CMPEN 411 L20 S.23
array
reduced pp
array (to
CPA)
double
precision
product
Page 24
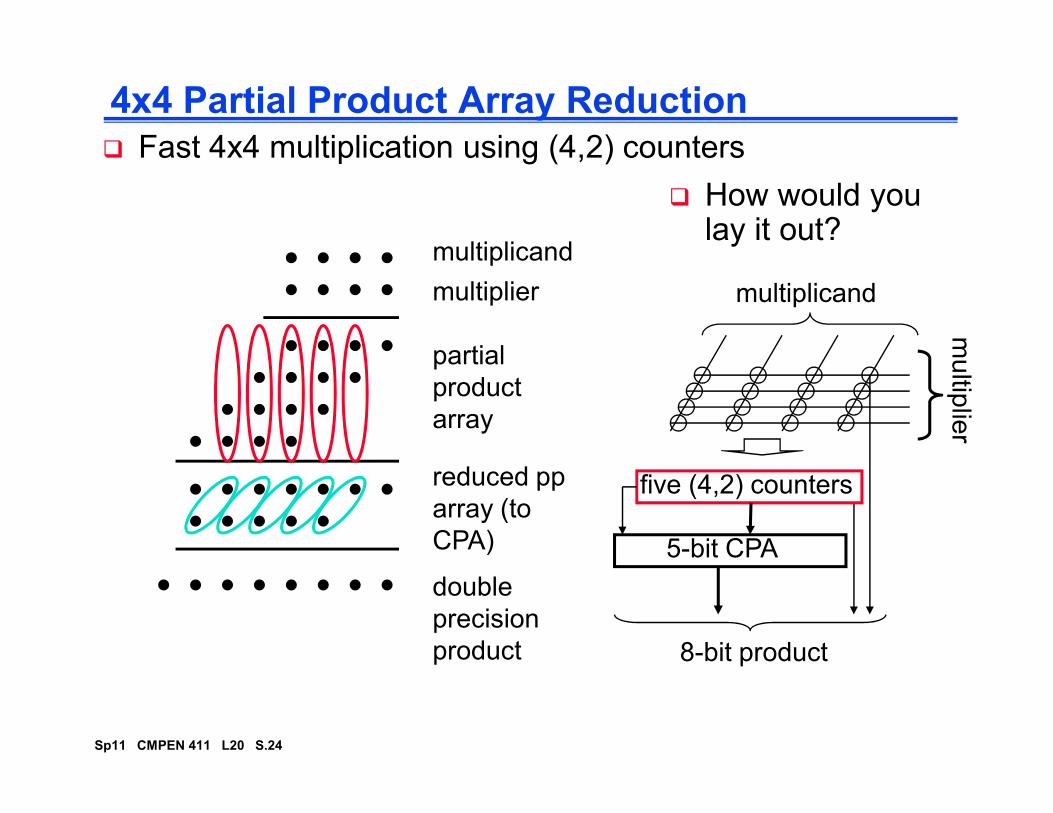
4x4 Partial Product Array Reduction
multiplicand
multiplier
partial
product
array
� Fast 4x4 multiplication using (4,2) counters
� How would you lay it out?
multiplicand
mu
ltiplie
r
Sp11 CMPEN 411 L20 S.24
array
reduced pp
array (to
CPA)
double
precision
product
five (4,2) counters
5-bit CPA
mu
ltiplie
r
8-bit product
Page 25
8x8 Partial Product Array Reduction
‘icand
‘ier
partial
product
array
� Wallace tree
multiplier
two rows of
nine (4,2)
counters
Sp11 CMPEN 411 L20 S.25
reduced
partial
product
array
one row of
thirteen
(4,2)
counters
to a 13-bit fast CPA
Page 26
An 8x8 Multiplier Layout
� How should it be laid out?multiplicand
mu
ltiplie
r
Sp11 CMPEN 411 L20 S.26
thirteen (4,2) counters
nine (4,2) counters
nine (4,2) counters
13-bit CPA
Page 27
Why Not Recode ?
� Multiplier recoding (modified Booth’s, canonical, P) recode the multiplier to allow base 4 multiplication with simple multiple formation
� with recoding have the base 4 multiplier digit set of -2, -1, 0, 1, 2
� Thus, with recoding the initial partial product array is only N/2 high N
Sp11 CMPEN 411 L20 S.27
2N
N/2� But, the first level of (4,2) counters also reduces the partial product array to N/2 high
� Which is better depends on the logic delay (recoding wins) and interconnect complexity (counters win big)
Page 28
Hitachi 54X54b Mulitplier
� A 4.4 ns CMOS 54X54 multiplier using pass-transitor multiplexer
Sp11 CMPEN 411 L20 S.28
Page 29
Hitachi Multiplier: Booth encoder and PPG
�
Sp11 CMPEN 411 L20 S.29
Page 30
Hitachi multiplier: 4-2 compressor
�
Sp11 CMPEN 411 L20 S.30
Page 31
What is the state of art?
Sp11 CMPEN 411 L20 S.31
ISSCC 2003
Page 32
Multipliers —Summary
• Optimization Goals Different Vs Binary Adder
• Once Again: Identify Critical Path
• Other possible techniques
- Logarithmic versus Linear (Wallace Tree Mult)
Sp11 CMPEN 411 L20 S.32
- Data encoding (Booth)
- Pipelining
FIRST GLIMPSE AT SYSTEM LEVEL OPTIMIZATION
Page 33
Next Lecture and Reminders
� Next lecture
� Shifters, decoders, and multiplexers
- Reading assignment – Rabaey, et al, 11.5-11.6
Sp11 CMPEN 411 L20 S.33