1 Combined Features and Kernel Design for Noise Robust Phoneme Classification Using Support Vector Machines Jibran Yousafzai † , Student Member, IEEE Peter Sollich ‡ Zoran Cvetkovi´ c † , Senior Member, IEEE Bin Yu * , Fellow, IEEE Abstract— This work proposes methods for combining cepstral and acoustic waveform representations for a front-end of support vector machine (SVM) based speech recognition systems that are robust to additive noise. The key issue of kernel design and noise adaptation for the acoustic waveform representation is addressed first. Cepstral and acoustic waveform representations are then compared on a phoneme classification task. Experiments show that the cepstral features achieve very good performance in low noise conditions, but suffer severe performance degradation already at moderate noise levels. Classification in the acoustic waveform domain, on the other hand, is less accurate in low noise but exhibits a more robust behavior in high noise con- ditions. A combination of the cepstral and acoustic waveform representations achieves better classification performance than either of the individual representations over the entire range of noise levels tested, down to -18dB SNR. Index Terms—Robustness, Support vector machines, Acoustic waveforms, Kernels, Phoneme classification I. INTRODUCTION State-of-the-art systems for automatic speech recognition (ASR) use cepstral features, normally some variant of Mel- Frequency Cepstral Coefficients (MFCC) [1] or Perceptual Linear Prediction (PLP) [2] as their front-end. These repre- sentations are derived from the short-term magnitude spectra followed by non-linear transformations to model the process- ing of the human auditory system. The aim is to compress the highly redundant speech signal in a manner which removes variations that are considered unnecessary for recognition, and thus facilitate accurate modelling of the information relevant for discrimination using limited data. However, due to the nonlinear processing involved in the feature extraction, even a moderate level of distortion may cause significant departures from feature distributions learned on clean data, making these distributions inadequate for recognition in the presence of environmental distortions such as additive noise and linear filtering. It turns out that recognition accuracy of state-of-the- art ASR systems is indeed far below human performance in adverse conditions [3, 4]. To make the cepstral representations of speech less sensitive to noise, several techniques [5–13] have been developed that Copyright (c) 2010 IEEE. Personal use of this material is permitted. However, permission to use this material for any other purposes must be obtained from the IEEE by sending a request to [email protected]. The authors are with the Department of Informatics † and the De- partment of Mathematics ‡ at King’s College London, and the De- partment of Statistics * at University of California, Berkeley (e-mail: {peter.sollich,zoran.cvetkovic }@kcl.ac.uk, [email protected]). Finan- cial support from EPSRC under grant EP/D053005/1 is gratefully acknowl- edged. Bin Yu thanks the National Science Foundation for grants NSF SES- 0835531 (CDI) and NSFC (60628102). aim to reduce explicitly the effects of noise on spectral representations and thus approach the optimal performance which should be achieved when training and test conditions are matched [14]. State-of-the-art feature compensation methods include the ETSI advanced front-end (AFE) [11], which is based on MFCCs but includes denoising and voice activity detection, and the vector Taylor series (VTS) based feature compensation [7–10]. The latter estimates the distribution of noisy speech given the distribution of clean speech, a segment of noisy speech, and the Taylor series expansion that relates the noisy speech features to the clean ones, and then uses it to predict the unobserved clean cepstral feature vectors. Ad- ditionally, cepstral mean-and-variance normalization (CMVN) [12, 13] is performed to standardize the cepstral features, fixing their range of variation for both training and test data. CMVN computes the mean and variance of the feature vectors across a sentence and standardizes the features so that each has zero mean and a fixed variance. These methods contribute significantly to robustness by alleviating some of the effects of additive noise (as well as linear filtering). However, due to the non-linear transformations involved in extracting the cepstral features, the effect of additive noise is not merely an additive bias and multiplicative change of scale of the features, as would be required for CMVN to work perfectly [13]. Current ASR methods that are considered robust to envi- ronmental distortions are based on the assumption that the conventional cepstral features form a good enough represen- tation, so that in combination with a suitable language and context modelling the performance of ASR systems can be brought close to human speech recognition. But for such mod- elling to be effective, the underlying sequence of elementary phonetic units must be predicted sufficiently accurately. This is, however, where there are still significant gaps between human performance and ASR. Humans recognize isolated speech units above the level of chance already at -18dB SNR, and significantly above it at -9dB SNR [15]. Even in quiet conditions, the machine phone error rates for nonsense syllables are higher than human error rates [3, 4, 16, 17]. Several studies [17–22] have attributed the marked differ- ence between human and machine performance to the fun- damental limitations of the feature extraction process. Among them, the studies on human speech perception [17, 19, 21, 22] have shown that the information reduction that takes place in the conventional front-ends leads to a severe drop in human speech recognition performance and that there is a high correlation between humans and machines in terms of recognition accuracy in noisy environment when both are exposed to speech with the kind of distortions introduced
Transcript
1
Combined Features and Kernel Design for Noise RobustPhoneme Classification Using Support Vector Machines
Jibran Yousafzai†, Student Member, IEEE Peter Sollich‡
Zoran Cvetkovic†, Senior Member, IEEE Bin Yu∗, Fellow, IEEE
Abstract— This work proposes methods for combining cepstraland acoustic waveform representations for a front-end of supportvector machine (SVM) based speech recognition systems thatare robust to additive noise. The key issue of kernel designand noise adaptation for the acoustic waveform representation isaddressed first. Cepstral and acoustic waveform representationsare then compared on a phoneme classification task. Experimentsshow that the cepstral features achieve very good performance inlow noise conditions, but suffer severe performance degradationalready at moderate noise levels. Classification in the acousticwaveform domain, on the other hand, is less accurate in lownoise but exhibits a more robust behavior in high noise con-ditions. A combination of the cepstral and acoustic waveformrepresentations achieves better classification performance thaneither of the individual representations over the entire range ofnoise levels tested, down to−18dB SNR.
Index Terms—Robustness, Support vector machines, Acousticwaveforms, Kernels, Phoneme classification
I. INTRODUCTION
State-of-the-art systems for automatic speech recognition(ASR) use cepstral features, normally some variant of Mel-Frequency Cepstral Coefficients (MFCC) [1] or PerceptualLinear Prediction (PLP) [2] as their front-end. These repre-sentations are derived from the short-term magnitude spectrafollowed by non-linear transformations to model the process-ing of the human auditory system. The aim is to compress thehighly redundant speech signal in a manner which removesvariations that are considered unnecessary for recognition, andthus facilitate accurate modelling of the information relevantfor discrimination using limited data. However, due to thenonlinear processing involved in the feature extraction, even amoderate level of distortion may cause significant departuresfrom feature distributions learned on clean data, making thesedistributions inadequate for recognition in the presence ofenvironmental distortions such as additive noise and linearfiltering. It turns out that recognition accuracy of state-of-the-art ASR systems is indeed far below human performance inadverse conditions [3, 4].
To make the cepstral representations of speech less sensitiveto noise, several techniques [5–13] have been developed that
Copyright (c) 2010 IEEE. Personal use of this material is permitted.However, permission to use this material for any other purposes must beobtained from the IEEE by sending a request to [email protected].
The authors are with the Department of Informatics† and the De-partment of Mathematics‡ at King’s College London, and the De-partment of Statistics∗ at University of California, Berkeley (e-mail:peter.sollich,[email protected], [email protected]). Finan-cial support from EPSRC under grant EP/D053005/1 is gratefully acknowl-edged. Bin Yu thanks the National Science Foundation for grants NSF SES-0835531 (CDI) and NSFC (60628102).
aim to reduce explicitly the effects of noise on spectralrepresentations and thus approach the optimal performancewhich should be achieved when training and test conditions arematched [14]. State-of-the-art feature compensation methodsinclude the ETSI advanced front-end (AFE) [11], which isbased on MFCCs but includes denoising and voice activitydetection, and the vector Taylor series (VTS) based featurecompensation [7–10]. The latter estimates the distribution ofnoisy speech given the distribution of clean speech, a segmentof noisy speech, and the Taylor series expansion that relatesthe noisy speech features to the clean ones, and then uses itto predict the unobserved clean cepstral feature vectors. Ad-ditionally, cepstral mean-and-variance normalization (CMVN)[12, 13] is performed to standardize the cepstral features,fixing their range of variation for both training and test data.CMVN computes the mean and variance of the feature vectorsacross a sentence and standardizes the features so that eachhas zero mean and a fixed variance. These methods contributesignificantly to robustness by alleviating some of the effectsof additive noise (as well as linear filtering). However, dueto the non-linear transformations involved in extracting thecepstral features, the effect of additive noise is not merely anadditive bias and multiplicative change of scale of the features,as would be required for CMVN to work perfectly [13].
Current ASR methods that are considered robust to envi-ronmental distortions are based on the assumption that theconventional cepstral features form a good enough represen-tation, so that in combination with a suitable language andcontext modelling the performance of ASR systems can bebrought close to human speech recognition. But for such mod-elling to be effective, the underlying sequence of elementaryphonetic units must be predicted sufficiently accurately. Thisis, however, where there are still significant gaps betweenhuman performance and ASR. Humans recognize isolatedspeech units above the level of chance already at−18dBSNR, and significantly above it at−9dB SNR [15]. Even inquiet conditions, the machine phone error rates for nonsensesyllables are higher than human error rates [3, 4, 16, 17].
Several studies [17–22] have attributed the marked differ-ence between human and machine performance to the fun-damental limitations of the feature extraction process. Amongthem, the studies on human speech perception [17, 19, 21, 22]have shown that the information reduction that takes placein the conventional front-ends leads to a severe drop inhuman speech recognition performance and that there is ahigh correlation between humans and machines in terms ofrecognition accuracy in noisy environment when both areexposed to speech with the kind of distortions introduced
2
by typical ASR front-ends. This makes finding methods thatwould more effectively account for noise effects, or featureswhose probability distributions would not alter significantly inthe presence of noise, of utmost importance for robust ASR.
In this paper, we propose combining cepstral features withhigh-dimensional acoustic waveform representations usingSVMs [23–26] to improve the robustness of phoneme classifi-cation to additive noise (convolutional noise is not consideredfurther in this paper). This is motivated by the fact that acousticwaveforms retain more information about speech than thecorresponding cepstral representation. Furthermore, thelinear-ity of the manner in which noise and speech are combinedin the acoustic waveform domain allows for straightforwardnoise compensation. The same would of course be true forany linear transform,e.g.Fourier Transform (linear spectrum)or discrete cosine transform. The high-dimensional space ofacoustic waveforms might also provide better separation ofthephoneme classes in high noise conditions and hence make theclassification more robust to additive noise. To effectively useacoustic waveforms with SVMs for phoneme classification,specially designed kernels that express the information relevantfor recognition need to be designed, and this is one of thecentral themes of this paper. In addition, we explore thebenefits of hybrid features that combine cepstral featureswith local energy features of acoustic waveform segments.These features can be compensated effectively, by exploitingthe approximate orthogonality of clean speech and noiseto subtract off the estimated noise energy before any non-linear transform is applied. The effectiveness of the hybridfeatures in improving robustness, when used with custom-designed kernels, is demonstrated in experiments. Acousticwaveforms and cepstral features are then compared on aphoneme classification task. Phoneme classification is a taskof reasonable complexity, studied by other researchers [27–35]for the purpose of testing different methods and representa-tions; the improvements achieved can be expected to extendto continuous speech recognition tasks [25, 36].
In broad terms, our experiments show that classificationin the cepstral domain gives excellent results in low noiseconditions but suffers severe degradation in high noise. Clas-sification in the acoustic waveform domain is not as accurateasin the cepstral domain in low noise but exhibits a more robustbehavior in severe noise. We therefore construct a convexcombination of the cepstral and acoustic waveform classifiers.The combined classifier outperforms the individual ones acrossall noise levels and even outperforms the cepstral classifiersfor which training and testing is performed under matchednoise conditions.
Short communications of the early stages of this workhave appeared in [37, 38]. Here we significantly extend ourapproach to account for the fine-scale and subband dynamicsof speech. We also investigate in detail the issues of noise com-pensation and classifier combination, and perform experimentsthat integrate an SNR estimation algorithm for noise compen-sation of acoustic features in the presence of non-stationarynoise. Basics of SVM classification are reviewed in Section II.In the same section we then describe our design of kernels forthe classification task in the cepstral and the acoustic waveform
domains, along with the compensation of features corruptedby additive noise. Results on phoneme classification using thetwo representations and their combination are then reported inSection III. Finally, Section IV presents conclusions and anoutlook toward future work.
II. SVM KERNELS FOR SPEECH RECOGNITION
Support vector machines are receiving increasing attentionas a tool for speech recognition applications [7, 24–26, 32,39–41]. The main aim of the present work is to find represen-tations along with corresponding kernels and effective noisecompensation methods for noise robust speech recognitionusing SVMs. We focus on fixed-length,D-samples long, seg-ments of acoustics waveforms, which we will denote byx, andtheir corresponding cepstral representationsc, and comparethem in a phoneme classification task. The classification inthe acoustic waveform domain opens up a whole set of issuesregarding the non-lexical invariances (sign, time alignment)and dynamics of speech that need to be taken into account bymeans of custom-designed kernels. Since this paper primarilyfocuses on comparison of different representations in termsof the robustness they provide, we conduct experiments usingfixed-length representations which could potentially be used asfront-ends for a continuous speech recognition system basedone.g.hidden Markov models (HMMs). Dealing with variablephoneme length lies beyond the scope of this paper; it has beenaddressed by means of dynamic kernels based on generativemodels such as Fisher kernels [41, 42], GMM supervectorkernels [40], as well as generative kernels [39] that combinethe strengths of generative statistical models and discriminativeclassifiers.
Our proposed approach can be used in a hybrid phone-basedarchitecture that integrates SVMs with HMMs for continuousspeech recognition [25, 26]. This is a two-stage process unlikethe systems described in [39, 42] where HMMs and SVMsare tied closely together via dynamic kernels. It requires abaseline HMM system to perform a first pass through thetest data. This generates for each utterance a set of possiblesegmentations into phonemes. The best segmentations are thenre-scored by the discriminative classifier to predict the finalphoneme sequence. This approach has provided improvementsin recognition performance over HMM baselines on bothsmall and large vocabulary recognition tasks, even thoughthe SVM classifiers were constructed solely from the cepstralrepresentations [25, 26]. The work presented in this papercan be integrated directly into this framework and would beexpected to similarly improve the recognition performanceover HMM baselines. This will be explored in future work,as will be extensions of our kernels for use with recently pro-posed frame-based architectures employing SVMs directly forcontinuous speech recognition using a token passing algorithmand dynamic time-warping kernel [43, 44].
A. Support Vector Machines
Given a set of training data(x1, . . . ,xp) with correspondingclass labels(y1, . . . , yp) , yi ∈ +1,−1, an SVM attemptsto find a decision surface which jointly maximizes the margin
3
between the two classes and minimizes the misclassificationerror on the training set. In the simplest case, these surfaces arelinear but most pattern recognition problems require nonlineardecision boundaries, and these are constructed by means ofnonlinear kernel functions. For the classification of a testpointx, an SVM trained to discriminate between two classes ofdata thus computes a scoreh(x) =
∑pi=1 αiyiK(x,xi) + b
whereK is a kernel function,αi is the Lagrange multipliercorresponding to theith training sample,xi, and b is theclassifier bias. The class ofx is then predicted based onthe sign of the score function,sgn (h (x)). While b andthe αi are optimized during training, the kernel functionKhas to be designed based ona priori knowledge about thespecific task. The simplest kernel is the inner product function,K(x, x) = 〈x, x〉, which produces linear decision boundaries.Nonlinear kernel functions implicitly map data points to ahigh-dimensional feature space where decision boundariesareagain linear. Kernel design is therefore effectively equivalent tofeature-space selection, and using an appropriate kernel for agiven classification task is crucial. Intuitively, the kernel shouldbe designed so thatK(x, x) is high if x and x belong to thesame class and low ifx and x are in different classes.
Two commonly used kernels are the polynomial kernel
Kp(x, x) = (1 + 〈x, x〉)Θ , (1)
and the radial basis function (RBF) kernelKr(x, x) =e−Γ‖x−x‖2
. The integer polynomial orderΘ in Kp and thewidth factorΓ are hyper-parameters which are tuned to a par-ticular classification problem. More sophisticated kernels canbe obtained by combining such basic kernels. In preliminaryexperiments we found that the standard polynomial and RBFkernels,Kp andKr, lead to similar speech classification per-formance. Hence the polynomial kernelKp in (1) will be usedas the baseline for both the cepstral and acoustic waveformrepresentations of speech. With cepstral representationshavingalready been designed to extract the information relevantfor the discrimination between phonemes, most of our effortwill address kernel design for classification in the acousticwaveform domain. The approach will be to a large extentinspired by the principles used in cepstral feature extraction,considering the effectiveness of cepstral representations forrecognition in low noise. The expected benefit of applyingSVMs to acoustic waveforms directly is that owing to theabsence of nonlinear dimension reduction, additive noise andacoustic waveforms are combined linearly. This leaves thenonlinear boundaries established on clean data less altered,and also makes noise compensation fairly straightforward.
For multiclass discrimination, binary SVM classifiers arecombined via error-correcting output code methods [45, 46].To summarize the procedure briefly,N binary classifiers aretrained to distinguish betweenM classes using a coding matrixWM×N , with elementswmn ∈ 0, 1,−1. Classifier n istrained only on data of classesm for which wmn 6= 0, withsgn(wmn) as the class label. The classm that one predictsfor test input x is then the one that minimizes the loss∑N
n=1 χ(wmnhn(x)), wherehn(x) is the output of thenth
classifier andχ is some loss function.
The error-correcting capability of a code is commensuratewith the minimum Hamming distance between the rows of acoding matrix [45]. However, one must also take into accountthe effect of the coding matrix on the accuracy of the resultingbinary classifiers, and the computational costs associatedwitha given code. In previous work [47, 48], codes formed bythe combination of theone-vs-one(pairwise) andone-vs-allcodes achieved good classification performance. But since theconstruction of one-vs-all binary classifiers for a problemwithlarge datasets is not computationally feasible, only one-vs-one(N = M(M − 1)/2) classifiers are used in the present study.A number of loss functions were compared, including hinge:χ(z) = max(1 − z, 0), Hamming:χ(z) = [1 − sgn(z)]/2,exponential:χ(z) = e−z, and linear:χ(z) = −z. The hingeloss function performed best and is therefore used throughoutthis paper. We also experimented with adaptive continuouscodes for multiclass SVMs as developed by Crammeret al.[49]. We do not report the details here: although this approachresulted in slight reductions in classification error on theorderof 1–2%, it did not change the relative performance of thevarious classification approaches discussed below.
B. Kernels for Cepstral Representations
1) Kernel Design: The time evolution of energy in aphoneme strongly correlates with phoneme identity and shouldtherefore be a useful cue for accurate phoneme classification.It is in principle encoded in the cepstral features, which area linear transform of Mel-log powers, but difficult to retrievefrom there in noise because of the residual noise contami-nation in the compensated cepstral features [13]. To improverobustness, we propose to embed the exact information aboutthe short-term energies of the acoustic waveform segments,treating them as a separate set of features in the evaluationof the SVM kernel. A straightforward compensation of thesefeatures can then be performed as explained below, and wehave previously shown that this works well in the sense thatthe compensated features have distributions close to thoseoffeatures derived from clean speech [50]. To define the energyfeatures, the fixed length acoustic waveform segmentx ∈ R
D
is divided intoT non-overlapping subsegments,
xt ∈ RD/T , t = 1, . . . , T , (2)
such that the centres of framet (as used for the calculationof MFCC features) and subsegmentxt are aligned. Letτ =[τ1, . . . , τT ], whereτt = log ‖xt‖2, denote the local energyfeatures of these subsegments1. Then, the cepstral featurevector c is augmented with the local energy feature vectorτ for the evaluation of a hybrid kernel given by
Kc(c, c, τ , τ ) = Kp(c, c)T
∑
t=1
Kε(τt, τt), (3)
whereKp is as given in (1),Kε(τt, τt) = e−(τt−τt)2/2a2
, anda is a parameter that is tuned experimentally. The vectorτ istreated as a separate set of features in the hybrid SVM kernel
1We consider logarithms to base10 throughout.
4
Kc rather than fused with the cepstral feature vectorc on aframe-by-frame basis. We sum the exponential terms in (3)over T segments rather than use the standard polynomial orRBF kernels in order to avoid the local energy features ofcertain subsegments dominating the evaluation of the kernel.(Alternatively, the local energy features can be standardizedusing CMVN and then evaluated using an RBF or polynomialkernel; this yields similar classification performance.) Finally,local energy features are calculated using non-overlappingsegments of speech in order to avoid any smoothing of thetime-profiles.
2) Noise Compensation:To investigate the robustness ofthe hybrid features to additive noise, we train the classifiersin quiet conditions with cepstral feature vectors standardizedusing CMVN [13]. Applying CMVN also to the noisy testdata provides some basic noise compensation. We standardizeso that the variance of each feature is the inverse of thedimension of the cepstral feature vector. On average bothtraining and test cepstral feature vectors then have unit norm.More sophisticated noise compensation methods, namely ETSIAFE and VTS, both followed by feature standardization usingCMVN, are also compared below. We do not consider heremulti-condition/multi-style classification methods [6] becausea previous study [37] showed that they generally performworse than AFE and VTS, due to high sensitivity to anymismatch between the type of noise contaminating the trainingand test data.
In using the hybrid kernelKc, the local energy featuresτmust also be compensated for noise in order for the classifiersto perform effectively. Given an actual or estimated SNR,this is done as follows. Letx = s + n, x ∈ R
D bea noise corrupted waveform, wheres and n represent theclean speech and the noise vector, respectively. The energyof the clean speech can then be approximated as‖s‖2 ≈‖x‖2−‖n‖2 ≈ ‖x‖2−Dσ2. Two approximations are involvedhere. Firstly, because speech and noise are uncorrelated, thevectorss and n are typically orthogonal:〈s,n〉 is of orderD−1/2‖s‖‖n‖ which can be neglected for large enoughD.Secondly, we replace the noise energy by its average valueσ2, the noise variance per sample. We work throughout witha default normalization of clean waveforms to unit energyper sample, so that1/σ2 is the SNR. Applying these generalarguments to the local energy features, we compensate theseby subtracting the estimated noise variance of a subsegment,Dσ2/T from the energies of the noisy subsegments,i.e. wecomputeτt = log
∣
∣‖xt‖2 − Dσ2/T∣
∣. This provides an esti-mate of the local energies of the subsegments of clean speech.Following the reasoning above, using local energy featuresofshorter subsegments of acoustic waveform (lowerD/T ) wouldmake fluctuations away from the orthogonality of speech andnoise more likely, thereforeKε should be evaluated on theenergies of long enough subsegments of speech. Note thatthe noise compensation discussed here is performed only onthe test features because training of classifiers that use hybridfeatures is always performed in quiet conditions; compensationof the local energy features of the training data is thereforenot required.
C. Kernels for Acoustic Waveforms
The use of kernels that express prior knowledge about thephysical properties of the data can also improve phonemeclassification in the acoustic waveform domain significantly.We propose several modifications of baseline SVM kernels totake into account relevant physical properties of speech andspeech perception.
1) Kernel Design: (a) Sign invariance. To account forthe fact that a speech waveform and its inverted versionare perceived as being the same, for any two waveformsx, x ∈ R
D, an evenkernel can be defined from a baselinepolynomial kernelKp (or indeed any kernel) as
Ke(x, x) = K ′p(x, x)+K ′
p(x,−x)+K ′p(−x, x)+K ′
p(−x,−x)(4)
where K ′p(x, x) is a modified polynomial kernel given by
K ′p(x, x) = Kp(x/ ‖x‖ , x/ ‖x‖). This kernel K ′
p, whichalways normalizes its input vectors to unit length, will be usedas a baseline kernel for the acoustic waveforms. On the otherhand, the standard polynomial kernelKp defined in (1) willbe employed for the cepstral representations, where CMVNalready ensures that feature vectors typically have unit norm.
(b) Shift invariance. A further invariance of acoustic wave-forms, to time alignment, is incorporated by using a kernel ofthe form (with normalization constantc = 1/(2L + 1)2)
Ks(x, x) = cL
∑
u,v=−L
Ke(xuδ, xvδ) , (5)
where xuδ is a segment of the same length as the original
waveform x but extracted from a position shifted byuδsamples,δ is the shift increment, and[−Lδ, Lδ] is the shiftrange.
(c) Phoneme energy.As the energy of a phoneme correlateswith phoneme identity, we embed this information into thekernel as
Kl(x, x) = c∑
u,v
Kε(log ‖xuδ‖2, log ‖xvδ‖2)Ke(xuδ, xvδ) ,
whereKε is as defined after (3).(d) Fine scale dynamics.Further, thedynamicsof speech
over a finer timescale is captured by evaluating the kernelover T subsegments as
Kd(x, x) = c∑
u,v
T∑
t=1
Kε(log ‖xuδt ‖2, log ‖xvδ
t ‖2)Ke(xuδt , xvδ
t ) ,
wherext and xt are thetth subsegments of the waveformsx
andx, respectively, andxuδt is a subsegment of the same length
asxt but extracted from a position shifted byuδ samples. Thiskernel captures the information about the phoneme energy atafiner resolution, which can help to distinguish phoneme classeswith different temporal dynamics and energy profiles.
(e) Subband dynamics. Features that capture the evolutionof energy and the dynamics of speech infrequency subbandsare also relevant for phoneme classification. To obtain thesesubband features, we divide the speech waveform intoframessimilar to those used to calculate MFCCs. The frames are cen-tred at the same locations as the non-overlapping subsegments
5
in (2). But we choose the frames to have a larger length ofR >D/T samples, to allow more accurate noise compensation andgood frequency localization. To construct the desired subbandenergy features, letXf [r], f = 1, . . . , F, r = 1, . . . , Rbe the discrete cosine transform (DCT) of thef th frame ofphonemex. The DCT coefficients are grouped intoB bands,each containingR/B coefficients, and the log-energyωb
f ofbandb is computed as
ωbf = log
(R/B∑
r=1
Xf [(b − 1)R/B + r]2)
, (6)
f = 1, . . . , F, b = 1, . . . , B .
These subband features are then concatenated into a vectorω =
[
ω11 , . . . , ω
B1 , . . . , ω1
F , . . . , ωBF
]Tand its time derivatives
[51, 52] are evaluated to form the dynamic subband features
Ω =[
ω, ∆ω, ∆2ω
]T. (7)
The subband energy featuresΩ are then combined with theacoustic waveformsx using a kernelKΩ which is givenby KΩ(x, x,Ω, Ω) = Kd(x, x)Kp(Ω, Ω), where Ω is thesubband feature vector corresponding to the waveformx.
2) Noise Compensation:In order to make the waveform-based SVM classifiers effective in the presence of noise, fea-ture compensation is again essential. In the presence of colorednoise, the level of contamination in frequency componentsdiffers according to the noise strength at those frequencies andthus requires compensation based on the spectral shape of thenoise. To compensate the features, letX [r], r = 1, . . . , Dbe the DCT of the noisy test waveform,x ∈ R
D. For thepurposes of noise compensation, we consider the DCT of thewhole phoneme segment rather than individual subsegments orframes. Given the estimated noise variance of therth frequencycomponentσ2
r (note that∑D
r=1 σ2r = σ2), the frequency
componentX [r] is scaled by1/√
1 + Dσ2r in order to depress
the effect of DCT components with high noise variance onthe kernel evaluation, givingX [r] = X [r]/
√
1 + Dσ2r . Note
that we do not make specific assumptions on the spectrumof clean speech here, and simply take each DCT componentto have the same average clean energy1/D. The spectrallyadapted waveformx, obtained by inverse DCT of the scaledDCT coefficientsX[r], is then used for the evaluation of timecorrelations (dot products) in the kernelK ′
p; note that the localand subband energy features are extracted from the unadaptedwaveformx to obtain their exact values. Below we drop thehat subscript onx, to lighten the notation.
Let us consider now the overall normalization of acousticwaveforms. With clean speech, the kernelK ′
p used in (4)effectively normalizes all waveforms to unit norm. However,the scaling of the norm of the acoustic waveforms in thepresence of noise should be different, to keep the norm of theunderlying clean speech signal approximately constant acrossdifferent noise levels. Consider the inner product of the noisecorrupted waveformx = s + n (wheres is clean speech andn is noise as before) with a waveformxi from the trainingset. Considering again that noise and clean speech are roughlyuncorrelated, the contribution to this product fromn can beneglected, so that〈x,xi〉 ≈ 〈s,xi〉 wherexi is a training point.
The clean speech signal appearing here should approximatelyhave unit energy per sample,‖s‖2 ≈ D. Arguing as in sectionII-B, we therefore need‖x‖2 ≈ ‖s‖2 + Dσ2 ≈ D(1 + σ2).Thus, noisy waveforms have to be normalized to have alarger norm than clean waveforms, by a factor
√1 + σ2. So
while the training waveform is normalized to unit norm in(4), the spectrally adapted test waveformx is normalized to√
1 + σ2 for the evaluation of the baseline polynomial kernelK ′
p. To emphasize this, we write from now on generic kernelsevaluated between a test waveformx and a training waveformxi asK(x,xi) rather thanK(x, x).
A similar compensation as in the polynomial kernel can beused forKε by subtracting the estimated subsegment noisevariance,Dσ2/T , from the energy of each noisy subsegmentxt to approximate the energies of the clean subsegments (seesection II-B). The noise compensated kernelKd is then
Kd(x,xi) = c∑
u,v
T∑
t=1
Kε(log∣
∣
∣‖xuδ
t ‖2 − Dσ2
T
∣
∣
∣, log ‖xvδ
i,t‖2)
×Ke(xuδt ,xvδ
i,t). (8)
As training for acoustic waveforms is performed in quietconditions, local energy features of the training waveformxi
are again not compensated. The spectral shape adaptation ofthe test waveform segmentx ∈ R
D as discussed above isperformed before the evaluation ofKe on subsegments in (8).
There are two potential drawbacks in using (8) in thepresence of noise. Firstly, we need to normalize the cleansubsegments to unit norm and the noisy ones to
√1 + σ2.
However, for short subsegments there can be wide variationin local SNR in spite of the fixed global SNR, and so thisnormalization may not be in accordance with the local SNR.Secondly, using short (low dimensional) subsegments makesfluctuations away from the average orthogonality of speechand noise more pronounced. To avoid these problems, we alsoconsider a modified kernelK ′
d where we useKe(xuδ ,xvδ
i )instead ofKe(x
uδt ,xvδ
i,t) This leaves the time-correlation partof the kernel unsegmented, whileKε is still evaluated overTsubsegments of the phonemes. We will see thatKd gives sig-nificantly better performance thanK ′
d in less noisy conditionsbecause of its sensitivity to the correlation of the individualsubsegments. On the other hand,Kd performs worse thanK ′
d
at high noise due to the two limitations discussed above.Finally, if we want to use energies in the frequency subbands
from (6) as features, as inKΩ, then also these need to becompensated for noise. This is done in a manner similar tothe local energy features inKε as
ωbf = log
∣
∣
∣
∣
R/B∑
r=1
Xf [(b − 1)R/B + r]2 − R
R/B∑
r=1
σ2r
∣
∣
∣
∣
,
f = 1, . . . , F, b = 1, . . . , B ,
prior to evaluating time derivatives to form the dynamicsubband featuresΩ. The kernel KΩ is then given byKΩ(x,xi,Ω,Ωi) = Kd(x,xi)Kp(Ω,Ωi), whereΩi is the(uncompensated) subband feature vector of the training wave-form xi. A modified kernelK ′
Ω can be defined similarly, byreplacingKd by K ′
d.
6
Methods for additive noise compensation of the cepstral andacoustic waveform features discussed in this section require anestimate of the noise variance (σ2) or the signal-to-noise ratio(SNR) of the noisy speech, a problem for which a numberof approaches have been proposed [53–55]. The lowest clas-sification error would be obtained in our approach from exactknowledge of thelocal SNR at the phoneme level. In most ex-periments, we assume that only the trueglobal (per sentence)SNR is known, and approximate the local SNR by this globalone. The intrinsic variability of speech energy across differentphonemes means that this approximation will often be ratherpoor, and will not saturate the lower classification error boundthat would result for known local SNR. In Section III-D, wethen compare with classification results obtained by integratingthe decision-direction SNR estimation algorithm [55, 56] intoour proposed approach for compensation and normalizationof acoustic waveform features. Because the SNR estimationis done frame by frame, this approach can track variations inlocal SNR, which should improve performance. On the otherhand, the SNR estimates will deviate from the truth, also atthe global level, and this will increase error rates. Our resultsshow that these two effects essentially cancel in the resultingerror rates.
III. EXPERIMENTAL RESULTS
A. Experimental Setup
Experiments are performed on the ‘si’ (diverse) and ‘sx’(compact) sentences of TIMIT database [57]. The training setconsists of 3696 sentences from 462 different speakers. Fortesting we use the core test set which consists of 192 sentencesfrom 24 different speakers not included in the training set.Thedevelopment set consists of 1152 sentences uttered by 144speakers not included in either the training or the core testset. The glottal stops /q/ are removed from the class labelsand certain allophones are grouped into their correspondingphoneme classes using the standard Kai-Fu Lee clustering[58], resulting in a total ofM = 48 phoneme classes andN = M(M − 1)/2 = 1128 binary classifiers. Among theseclasses, there are 7 groups for which the contribution of within-group confusions toward multiclass error is not counted, againfollowing standard practice [32, 58].
Both artificial noise (white, pink) and recordings of realnoise (speech-babble) from the NOISEX-92 database are usedin our experiments. White noise was selected due to itsattractive theoretical interpretation as probing in an isotropicmanner the separation of phoneme classes in different rep-resentation domains. Pink noise was chosen because1/f -like noise patterns are found in music melodies, fan andcockpit noises, in nature etc. [59]. To test the classificationperformance of the cepstral features and acoustic waveformsin noise, each sentence is normalized to unit energy per sampleand then a noise sequence with varianceσ2 (per sample) isadded to the entire sentence. The SNR at the level of individualphonemes can then still vary widely. For cepstral features,two training-test scenarios are considered:(i) training SVMclassifiers using clean data, with standard noise compensationmethods to clean the test features and(ii) training and testing
under identical noise conditions. The latter is an impracticaltarget; nevertheless, we present the results as a referenceforcepstral features, since this setup is considered to give theoptimal achievable performance [14]. The cepstral featuresof both training and test data are standardized using CMVNin all scenarios. For classification using acoustic waveformstraining is always performed with noiseless (clean) data, andthen noisy test features are compensated as described in theprevious section.
For the cepstral (MFCC) representation,c, each sentence isconverted into a sequence of 13 dimensional feature vectors,their time derivatives and second order derivatives. Then,F = 10 frames (with frame duration of25ms and a framerate of 100 frames/sec) closest to the centre of a phonemeare concatenated to give a representation inR
390. Along thesame lines, each frame yields 14 AFE features (includinglog frame energy) and their time derivatives as defined bythe ETSI standard, giving a representation inR
420. For noisecompensation with vector Taylor series (VTS) [7–9], severalGaussian mixture models (GMMs) were trained to learn thedistribution of Mel log spectra of clean training data; we foundall of them to yield very similar performance. For the resultsreported below, a GMM with 64 mixture components wasused.
For the acoustic waveform representation, phoneme seg-mentsx are extracted from the TIMIT sentences by applyinga 100ms rectangular window at the centre of each phoneme,which at 16kHz sampling frequency gives fixed length vectorsin R
D with D = 1600. In the evaluation of the shift-invariantkernel Ks from (5), we use a shift increment ofδ = 100samples (≈ 6 ms) over a shift range±100 (so thatL = 1),giving three shifted segments. Each of these segments isbroken into T = 10 subsegments of equal length for theevaluation of kernelsKd andK ′
d.For the subband features,Ω (see (7)), the energy features
and their time derivatives inB = 8 frequency subbands ofequal bandwidth are combined to form a24-dimensional fea-ture vector for each frame of speech. These subband featuresare standardized to zero mean and unit variance within eachsentence of TIMIT. Then, the standardized subband featuresof F = 10 frames with frame duration of25ms (R = 400samples per frame) and a frame rate of100 frames/sec, againclosest to the centre of a particular phoneme, are concatenatedto give a representationΩ in R
240. We did not use a largernumber of subbands to avoid an excessive number of subbandfeatures, and also to keep enough frequencies,R/B, persubband to allow accurate noise compensation of theωb
f .The effect of custom-designed kernels on performance is in-
vestigated by comparing the different kernel functions definedabove. The best classification performance with acoustic wave-forms is achieved withK ′
Ω. For the cepstral representations,we compare the performance of the baseline kernelKp withthat of the hybrid kernelKc. Initially, we experimented withdifferent values of the hyperparameters for the binary SVMclassifiers but decided to use fixed values for all classifiersasparameter optimization had a large computational overheadbutonly a small impact on the multiclass classification error. Thedegree ofKp is set toΘ = 6, the penalty parameter (for slack
7
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
MFCC: K
p − Quiet
MFCC − AFE: Kp − Quiet
MFCC + VTS: Kp − Quiet
MFCC + VTS: Kc − Quiet
MFCC: Kp − Matched
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
MFCC: K
p − Quiet
MFCC − AFE: Kp − Quiet
MFCC + VTS: Kp − Quiet
MFCC + VTS: Kc − Quiet
MFCC: Kp − Matched
Fig. 1. Classification error versus SNR for SVM phoneme classificationin the presence of (top) white noise, (bottom) pink noise, using the MFCCrepresentation with standard kernelKp and hybrid kernelKc, for differenttraining and test conditions and feature compensation methods.
variables in the SVM training algorithm) toC = 1 and thevalue ofa in Kε is tuned experimentally on the developmentdata to givea = 0.5.
B. Classification based on the Cepstral Representation
In Figure 1, the results of SVM phoneme classification withthe polynomial kernelKp in the presence of additive whiteand pink noise are shown for the standard MFCC cepstralrepresentation, as well as for MFCC features compensatedusing VTS and AFE. For comparison, results for matchedtraining and test conditions are presented as well. The plotsdemonstrate that the SVM classifier trained with the AFErepresentation outperforms the standard MFCC representationfor SNRs below18dB, but is worse in quiet conditions. TheVTS-compensated MFCC features, on the other hand, performcomparably to standard MFCC in quiet, and thus in factbetter than the more sophisticated AFE features. However,for SNR below0dB, the classification performance of VTS-compensated MFCC features degrades relatively quickly ascompared to the AFE features. Since the (log) frame energy isincluded in the AFE features as defined by the ETSI standard,we consider as a hybrid representation only the one formedby the combination of the local energy features and the VTS-compensated MFCC features, using kernelKc. The resultsshow that this hybrid representation performs better than bothnoise compensation methods (AFE and VTS) at all noiseconditions and approaches the performance achieved undermatched conditions. For instance, the hybrid representationachieves an average improvement of5.5% and5.8% over thestandard VTS-compensated MFCC features and AFE featuresrespectively, across all SNRs in the presence of white noiseas shown in Figure 1(top), with similar conclusions in pinknoise.
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
Waveform: Kp ′
Waveform: Ke
Waveform: Ks
Waveform: Kl
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
Waveform: K
d
Waveform: KΩ
Waveform: Kd ′
Waveform: KΩ ′
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
Waveform: KΩ (White)
Waveform: KΩ (Pink)
Waveform: KΩ ′ (White)
Waveform: KΩ ′ (Pink)
Fig. 2. Effects of custom-designed kernels on the classification performanceof SVMs using acoustic waveform representations. (top) Results for classifica-tion with kernelsK ′
p, Ke, Ks, Kl in the presence of white noise. (middle)Classification with the more advanced kernelsKd, KΩ and their unsegmentedanalogsK ′
d, K ′
Ωin white noise. (bottom) Comparison of classification with
kernelsKΩ andK ′Ω
in the presence of white and pink noise.
C. Classification based on Acoustic Waveforms
Let us now consider classification using acoustic wave-forms. First, Figure 2 illustrates the effects of our custom-designed kernels for acoustic waveforms on the classificationperformance in the presence of additive (white and pink) noise.As we had hoped, embedding more physical aspects of speechand speech perception into the SVM kernels does indeedreduce classification error. Classification results using acousticwaveforms with the standard SVM kernelK ′
p are shown inFigure 2(top); the resulting performance is clearly worse thanMFCC classifiers (see Figure 1) for all noise levels. The evenpolynomial kernelKe (see (4)), which is a sign-invariantkernel based onK ′
p, gives an8% average improvement inclassification performance. The largest improvement,14%, isachieved at0dB SNR in white noise. Adding shift-invarianceand the noise-compensated local energy features to the kernelimproves results further. The resulting kernelsKs and Kl
reduce the classification error by approximately3% and 4%respectively, on average across all noise levels. Overall,areduction in classification error of approximately18% isobtained by using kernelKl over our baselineK ′
p kernel at0dB SNR in white noise.
Next, the temporal dynamics of speech and informationfrom frequency subbands are incorporated via the kernelsKd
8
and KΩ. The results for these kernels are shown in Figure2(middle). One can observe that these kernels give major im-provements in low noise conditions because of their sensitivityto correlation of individual subsegments of phonemes,e.g.KΩ achieves31.3% error in quiet condition, an improvementin classification performance of15% over Kl. However,KΩ
performs worse thanKl below a crossover point between−6dB and−12dB SNR, as anticipated in the discussion inSection II-C. In a comparison ofKΩ with K ′
Ω, where thetime-correlation part of the kernel is left unsegmented, wesee thatKΩ performs better thanK ′
Ω in low noise conditionsbut the latter gives better results in high noise. Overall,incorporating invariances and additional information about theacoustic waveforms into the kernel results in major cumula-tive performance gains. For instance, in quiet conditions anabsolute30% reduction in error is achieved byKΩ over thestandard polynomial kernelK ′
p.Figure 2(bottom) summarizes the classification results for
the kernels that give the best classification performance withacoustic waveforms in white noise,KΩ andK ′
Ω, and compareswith results for pink noise. It is clear that the noise type affectsclassification performance minimally in low noise conditions,SNR≥ 0dB. At extremely high noise, SNR≤ −6dB, pinknoise has more severe effects than white noise. We alsotested other noise types,e.g. speech-weighted noise (resultsnot shown) and qualitatively similar conclusions apply.
D. Classifier Combination
In previous work [38, 50], we introduced an approach thatcombined the cepstral and acoustic waveform classifiers toattain better classification performance than either of theindi-vidual representations. Since waveform classifiers with kernelK ′
Ω achieve best results in high noise (see Figure 1 and Figure2), we consider them in combination with the SVM classifierstrained on hybrid VTS-compensated MFCC features usingkernelKc. In particular, a convex combination of the scores ofthe classifiers in the individual feature spaces is considered,i.e. for binary classifiershw and hm in the waveform andMFCC domains respectively, we define the combined classifieroutput ashc = λhw + (1 − λ) hm. Here λ = λ(σ2) is aparameter which needs to be selected, depending on the noisevariance, to achieve optimal performance. These combinedbinary classifiers are then in turn combined for multiclassclassification as detailed in Section II-A.
Figure 3(top) shows the classification error on the coretest set of TIMIT at various SNRs as a function of thecombination parameterλ; classification in the MFCC cepstraldomain is obtained withλ = 0, whereasλ = 1 correspondsto classification in the acoustic waveform domain. One canobserve that the minimum error is achieved for0 < λ < 1 foralmost all noise conditions. To retain unbiased test errorsonthe core test set, we determine from the distinctdevelopmentset the “optimal” values ofλ(σ2), λopt(σ
2), i.e. the values ofλwhich give the minimum classification error for a given SNR.These are marked by ‘o’ in Figure 3(bottom); the error barsgive the range of values ofλ for which the classification erroron the development set is less than the minimum error plus
0 0.5 120
30
40
50
60
70
80
90
λ
ER
RO
R [%
]
−18dB
−12dB
−6dB
0dB
6dB
12dB
18dB
Quiet
−18 −12 −6 0 6 12 18 Q
0
0.2
0.4
0.6
0.8
1
SNR [dB]
λ
λopt
λapp
Fig. 3. (top) Classification error on the core test set over a range of SNRsin the presence of white noise as a function ofλ; λ = 0 corresponds toclassification with hybrid VTS-compensated MFCC features using kernelKc,λ = 1 is waveform classification with kernelK ′
Ω. (bottom) Optimal and
approximate values ofλ for a range of SNRs (in white noise). Error barsgive the range of values ofλ(σ2) for which the classification error on thedevelopment set is less than the minimum error(%) + 2%.
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
MFCC + VTS: K
p − Quiet
MFCC + VTS: Kc − Quiet
Waveform: KΩ ′
Combination: λapp
MFCC: Kp − Matched
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
MFCC + VTS: K
p − Quiet
MFCC + VTS: Kc − Quiet
Waveform: KΩ ′
Combination: λapp
MFCC: Kp − Matched
Fig. 4. Comparison of classification in the MFCC (with kernels Kp andKc) and acoustic waveform (with kernelK ′
Ω) domains with the combined
classifier, forλapp(σ2) given by (9) and (top) white and (bottom) pink noise.The combined classifier outperforms the MFCC classifier evenunder matchedtraining and test conditions and in fact is more robust than individual MFCCand acoustic waveform classifiers.
2%. A reasonable approximation toλopt(σ2) is given by
λapp(σ2) = η + ζ/[1 +
(
σ20/σ2
)
] , (9)
with η = 0.2, ζ = 0.5 andσ20 = 0.03, and is shown in Figure
3(bottom) by the solid line.Having determinedλapp(σ
2) from the development set, wecan now go back to the core test set and compare (Figure 4)
9
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
MFCC + VTS: Kp
MFCC + VTS: Kc
Waveform: KΩ ′
Combination: λapp
−18 −12 −6 0 6 12 18 Q 20
40
60
80
100
SNR [dB]
ER
RO
R [%
]
MFCC + VTS: Kp
MFCC + VTS: Kc
Waveform: KΩ ′
Combination: λapp
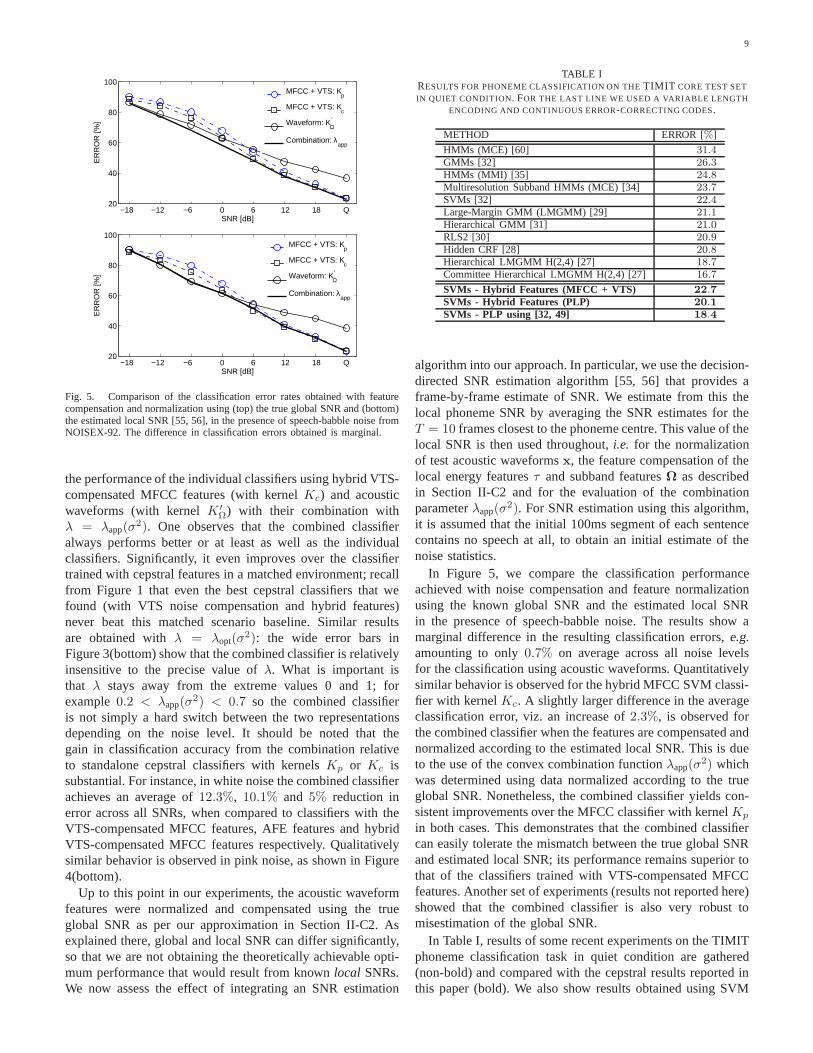
Fig. 5. Comparison of the classification error rates obtained with featurecompensation and normalization using (top) the true globalSNR and (bottom)the estimated local SNR [55, 56], in the presence of speech-babble noise fromNOISEX-92. The difference in classification errors obtained is marginal.
the performance of the individual classifiers using hybrid VTS-compensated MFCC features (with kernelKc) and acousticwaveforms (with kernelK ′
Ω) with their combination withλ = λapp(σ
2). One observes that the combined classifieralways performs better or at least as well as the individualclassifiers. Significantly, it even improves over the classifiertrained with cepstral features in a matched environment; recallfrom Figure 1 that even the best cepstral classifiers that wefound (with VTS noise compensation and hybrid features)never beat this matched scenario baseline. Similar resultsare obtained withλ = λopt(σ
2): the wide error bars inFigure 3(bottom) show that the combined classifier is relativelyinsensitive to the precise value ofλ. What is important isthat λ stays away from the extreme values 0 and 1; forexample0.2 < λapp(σ
2) < 0.7 so the combined classifieris not simply a hard switch between the two representationsdepending on the noise level. It should be noted that thegain in classification accuracy from the combination relativeto standalone cepstral classifiers with kernelsKp or Kc issubstantial. For instance, in white noise the combined classifierachieves an average of12.3%, 10.1% and 5% reduction inerror across all SNRs, when compared to classifiers with theVTS-compensated MFCC features, AFE features and hybridVTS-compensated MFCC features respectively. Qualitativelysimilar behavior is observed in pink noise, as shown in Figure4(bottom).
Up to this point in our experiments, the acoustic waveformfeatures were normalized and compensated using the trueglobal SNR as per our approximation in Section II-C2. Asexplained there, global and local SNR can differ significantly,so that we are not obtaining the theoretically achievable opti-mum performance that would result from knownlocal SNRs.We now assess the effect of integrating an SNR estimation
TABLE IRESULTS FOR PHONEME CLASSIFICATION ON THETIMIT CORE TEST SET
IN QUIET CONDITION. FOR THE LAST LINE WE USED A VARIABLE LENGTHENCODING AND CONTINUOUS ERROR-CORRECTING CODES.
algorithm into our approach. In particular, we use the decision-directed SNR estimation algorithm [55, 56] that provides aframe-by-frame estimate of SNR. We estimate from this thelocal phoneme SNR by averaging the SNR estimates for theT = 10 frames closest to the phoneme centre. This value of thelocal SNR is then used throughout,i.e. for the normalizationof test acoustic waveformsx, the feature compensation of thelocal energy featuresτ and subband featuresΩ as describedin Section II-C2 and for the evaluation of the combinationparameterλapp(σ
2). For SNR estimation using this algorithm,it is assumed that the initial 100ms segment of each sentencecontains no speech at all, to obtain an initial estimate of thenoise statistics.
In Figure 5, we compare the classification performanceachieved with noise compensation and feature normalizationusing the known global SNR and the estimated local SNRin the presence of speech-babble noise. The results show amarginal difference in the resulting classification errors, e.g.amounting to only0.7% on average across all noise levelsfor the classification using acoustic waveforms. Quantitativelysimilar behavior is observed for the hybrid MFCC SVM classi-fier with kernelKc. A slightly larger difference in the averageclassification error, viz. an increase of2.3%, is observed forthe combined classifier when the features are compensated andnormalized according to the estimated local SNR. This is dueto the use of the convex combination functionλapp(σ
2) whichwas determined using data normalized according to the trueglobal SNR. Nonetheless, the combined classifier yields con-sistent improvements over the MFCC classifier with kernelKp
in both cases. This demonstrates that the combined classifiercan easily tolerate the mismatch between the true global SNRand estimated local SNR; its performance remains superior tothat of the classifiers trained with VTS-compensated MFCCfeatures. Another set of experiments (results not reportedhere)showed that the combined classifier is also very robust tomisestimation of the global SNR.
In Table I, results of some recent experiments on the TIMITphoneme classification task in quiet condition are gathered(non-bold) and compared with the cepstral results reportedinthis paper (bold). We also show results obtained using SVM
10
classifiers trained with a hybrid cepstral representation withkernel Kc (Section II-B), but using PLP instead of MFCCfeatures. This gives better performance in quiet conditions.Note that the benchmarks (non-bold entries in the table)use cepstral representations that encode information fromtheentire variable length phonemes and our result of20.1% errorimproves on all benchmarks except [27] even though we usea fixed length cepstral representation. Further improvementscan be expected by including all frames within a variablelength phoneme and the transition regions [32] (see last entryin table), and by incorporating techniques such as committeeclassifiers [27, 61]. More importantly, our classifiers signifi-cantly outperform the benchmarks in the presence of noise. Aclassification error of77.8% is reported by Rifkinet al. [30]at 0dB SNR in pink noise whereas our combined classifierachieves an error of46.2% in the same conditions as shownin Figure 4(bottom).
One might be concerned about the computational complex-ity because for SVMs, training time scales approximatelyquadratically with the number of data points. However, thiseffect is independent of which front-end is used, and alreadya number of years ago it was possible to use SVMs forlarge vocabulary speech recognition tasks such as Switchboardrecognition [25]. The only difference between front-ends arisesin the time it takes to evaluate the required kernel elementsK(xi,xj). The evaluation of scalar products scales with thefeature space dimension, leading to an increase in trainingtimeby a factor around five when using acoustic waveform ratherthan cepstral front-ends. The use of shift-invariant kernelsleads to a similar factor, so that overall computation time isroughly an order of magnitude larger for waveforms than forcepstral features. This increase is modest and so our approachremains practical, particularly bearing in mind improvementsin computing hardware since [25] was published: graphicsprocessing units (GPUs) can provide approximate speedupsof up to 100 times over standard SVM implementations suchas LIBSVM [62].
IV. CONCLUSIONS
In this study, we proposed methods for combining cep-stral and acoustic waveform representations to improve therobustness of phoneme classification with SVMs to additivenoise. To this end, we developed kernels and showed thatembedding invariances of speech and relevant dynamical infor-mation via custom-designed kernels can significantly improveclassification performance. While the cepstral representationallows for very accurate classification of phonemes in lownoise conditions, especially for clean data, its performancesuffers degradation at high noise levels. The high-dimensionalacoustic waveform representation, on the other hand, is lessaccurate on clean data but more robust in severe noise. Wehave also shown that a convex combination of the MFCCand acoustic waveform classifiers achieves performance thatis consistently better than both classifiers in the individualdomains across the entire range of noise levels.
The work reported in this paper could serve as a point ofdeparture to address some key issues in the construction of
robust ASR systems. An important and necessary extensionwould be to investigate the robustness of the waveform-basedrepresentations to linear filtering. It would also be interestingto extend our work to handle continuous speech recognitiontasks using SVM/HMM hybrids [25]. In future work, wewould seek to further improve the results by incorporatingtechniques proposed by other authors, such as committeeclassifiers [27] that combine a number of representations withdifferent parameters as well as hierarchical classification toreduce broad phoneme class confusions [61].
ACKNOWLEDGMENT
Zoran Cvetkovic would like to thank Jont Allen, BishnuAtal, and Andreas Buja for encouragement and inspiration.
REFERENCES
[1] S. B. Davis and P. Mermelstein, “Comparison of ParametricRepresentations for Monosyllabic Word Recognition in Con-tinuously Spoken Sentences,”IEEE Trans. ASSP, vol. 28, pp.357–366, 1980.
[2] H. Hermansky, “Perceptual Linear Predictive (PLP) Analysis ofSpeech,”J. Acoust. Soc. Amer., vol. 87, no. 4, pp. 1738–1752,April 1990.
[3] R. Lippmann, “Speech Recognition by Machines and Humans,”Speech Comm., vol. 22, no. 1, pp. 1–15, 1997.
[4] J. Sroka and L. Braida, “Human and Machine ConsonantRecognition,”Speech Comm., vol. 45, no. 4, pp. 401–423, 2005.
[5] M. Holmberg, D. Gelbart, and W. Hemmert, “Automatic SpeechRecognition with an Adaptation Model Motivated by AuditoryProcessing,”IEEE Trans. ASLP, vol. 14, no. 1, pp. 43–49, 2006.
[6] R. Lippmann and E. A. Martin, “Multi-Style Training forRobust Isolated-Word Speech Recognition,”Proc. ICASSP, pp.705–708, 1987.
[7] P. J. Moreno, B. Raj, and R. M. Stern, “A Vector Taylor SeriesApproach for Environment-Independent Speech Recognition,”Proc. ICASSP, pp. 733–736, 1996.
[8] J. Li, L. Deng, D. Yu, Y. Gong, and A. Acero, “High-Performance HMM Adaptation With Joint Compensation ofAdditive and Convolutive Distortions Via Vector Taylor Series,”in Automat. Speech Recogn. & Understading, pp. 65–70, 2007.
[9] M. J. F. Gales and F. Flego, “Combining VTS Model Com-pensation and Support Vector Machines,”Proc. ICASSP, pp.3821–3824, 2009.
[10] H. Liao, “Uncertainty Decoding For Noise Robust SpeechRecognition,” Ph.D. Thesis, Cambridge University, 2007.
[11] ETSI standard doc., “Speech processing, TransmissionandQuality aspects (STQ): Advanced front-end feature extraction,”ETSI ES 202 050, 2002.
[12] O. Viikki and K. Laurila, “Cepstral Domain Segmental FeatureVector Normalization for Noise Robust Speech Recognition,”Speech Comm., vol. 25, pp. 133–147, 1998.
[13] C. Chen and J. Bilmes, “MVA Processing of Speech Features,”IEEE Trans. ASLP, vol. 15, no. 1, pp. 257–270, 2007.
[14] M. Gales and S. Young, “Robust Continuous Speech Recogni-tion using Parallel Model Combination,”IEEE Trans. SpeechAudio Process., vol. 4, pp. 352–359, Sept. 1996.
[15] G. Miller and P. Nicely, “An Analysis of Perceptual Confusionsamong some English Consonants,”J. Acoust. Soc. Amer., vol.27, no. 2, pp. 338–352, 1955.
[16] J. B. Allen, “How do humans process and recognize speech?,”IEEE Trans. Speech Audio Process., vol. 2, no. 4, pp. 567–577,1994.
[17] B. Meyer, M. Wachter, T. Brand, and B. Kollmeier, “PhonemeConfusions in Human and Automatic Speech Recognition,”Proc. INTERSPEECH, pp. 2740–2743, 2007.
11
[18] B.S. Atal, “Automatic Speech Recognition: a CommunicationPerspective,”Proc. ICASSP, pp. 457–460, 1999.
[19] S. D. Peters, P. Stubley, and J. Valin, “On the Limits of SpeechRecognition in Noise,”Proc. ICASSP, pp. 365–368, 1999.
[20] Herve Bourlard, Hynek Hermansky, and Nelson Morgan, “To-wards Increasing Speech Recognition Error Rates,”SpeechComm., vol. 18, no. 3, pp. 205–231, 1996.
[21] Kuldip K. Paliwal and Leigh D. Alsteris, “On the Usefulnessof STFT Phase Spectrum in Human Listening Tests,”SpeechComm., vol. 45, no. 2, pp. 153–170, 2005.
[22] Leigh D. Alsteris and Kuldip K. Paliwal, “Further IntelligibilityResults from Human Listening Tests using the Short-TimePhase Spectrum,”Speech Comm., vol. 48, no. 6, pp. 727–736,2006.
[23] V. N. Vapnik, The Nature of Statistical Learning Theory,Springer-Verlag, New York, 1995.
[24] A. Sloin and D. Burshtein, “Support Vector Machine Trainingfor Improved Hidden Markov Modeling,”IEEE Trans. SignalProcess., vol. 56, no. 1, pp. 172–188, 2008.
[25] A. Ganapathiraju, J. E. Hamaker, and J. Picone, “Applicationsof Support Vector Machines to Speech Recognition,”IEEETrans. Signal Process., vol. 52, no. 8, pp. 2348–2355, 2004.
[26] S. E. Kruger, M. Schaffner, M. Katz, E. Andelic, and A.Wen-demuth, “Speech Recognition with Support Vector Machines ina Hybrid System,”Proc. INTERSPEECH, pp. 993–996, 2005.
[27] H. Chang and J. Glass, “Hierarchical Large-Margin GaussianMixture Models for Phonetic Classification,” in Automat.Speech Recogn. & Understading, pp. 272–275, 2007.
[28] D. Yu, L. Deng, and A. Acero, “Hidden Conditional RandomFields with Distribution Constraints for Phone Classification,”Proc. INTERSPEECH, pp. 676–679, 2009.
[29] F. Sha and L. K. Saul, “Large Margin Gaussian MixtureModeling for Phonetic Classification and Recognition,”Proc.ICASSP, pp. 265–268, 2006.
[30] R. Rifkin, K. Schutte, M. Saad, J. Bouvrie, and J. Glass,“NoiseRobust Phonetic Classification with Linear Regularized LeastSquares and Second-Order Features,”Proc. ICASSP, pp. 881–884, 2007.
[31] A. Halberstadt and J. Glass, “Heterogeneous Acoustic Mea-surements for Phonetic Classification,”Proc. EuroSpeech, pp.401–404, 1997.
[32] P. Clarkson and P. J. Moreno, “On the Use of Support VectorMachines for Phonetic Classification,”Proc. ICASSP, pp. 585–588, 1999.
[33] A. Gunawardana, M. Mahajan, A. Acero, and J. C. Platt,“Hidden Conditional Random Fields for Phone Classification,”Proc. INTERSPEECH, pp. 1117–1120, 2005.
[34] P. McCourt, N. Harte, and S. Vaseghi, “Discriminative Multi-resolution Sub-band and Segmental Phonetic Model Combina-tion,” IET Electronics Letters, vol. 36, no. 3, pp. 270 –271,2000.
[35] M.I. Layton and M.J.F. Gales, “Augmented Statistical Modelsfor Speech Recognition,”Proc. ICASSP, pp. I29–132, 2006.
[36] A. Halberstadt and J. Glass, “Heterogeneous Measurements andMultiple Classifiers for Speech Recognition,”Proc. ICSLP, pp.995–998, 1998.
[37] J. Yousafzai, Z. Cvetkovic, and P. Sollich, “Towards RobustPhoneme Classification with Hybrid Features ,”Proc. ISIT, pp.1643–1647, 2010.
[38] J. Yousafzai, Z. Cvetkovic, and P. Sollich, “Tuning Support Vec-tor Machines for Robust Phoneme Classification with AcousticWaveforms,” Proc. INTERSPEECH, pp. 2391–2395, 2009.
[39] N. Smith and M. Gales, “Speech Recognition using SVMs,”inAdv. Neural Inf. Process. Syst., 2002, vol. 14, pp. 1197–1204.
[40] W.M. Campbell, D. Sturim, and D.A. Reynolds, “SupportVector Machines using GMM Supervectors for Speaker Ver-ification,” IEEE Signal Process. Letters, vol. 13, no. 5, pp.308–311, 2006.
[41] J. Louradour, K. Daoudi, and F. Bach, “Feature Space
Mahalanobis Sequence Kernels: Application to SVM SpeakerVerification,” IEEE Trans. ASLP, vol. 15, no. 8, pp. 2465–2475,2007.
[42] T. Jaakkola and D. Haussler, “Exploiting Generative Models inDiscriminative Classifiers,” inAdv. Neural Inf. Process. Syst.,1999, vol. 11, pp. 487–493.
[43] R. Solera-Urena, D. Martın-Iglesias, A. Gallardo-Antolın,C. Pelaez-Moreno, and F. Dıaz-de Marıa, “Robust ASR usingSupport Vector Machines,”Speech Comm., vol. 49, no. 4, pp.253–267, 2007.
[44] J. Padrell-Sendra, D. Martın-Iglesias, and F. Dıaz-de Marıa,“Support Vector Machines for Continuous Speech Recognition,”Proc. EUSIPCO, 2006.
[45] T. Dietterich and G. Bakiri, “Solving Multiclass LearningProblems via Error-Correcting Output Codes,”J. Artif. Intell.Res., vol. 2, pp. 263–286, 1995.
[46] R. Rifkin and A. Klautau, “In Defense of One-Vs-All Classifi-cation,” J. Mach. Learn. Res., vol. 5, pp. 101–141, 2004.
[47] J. Yousafzai, M. Ager, Z. Cvetkovic, and P. Sollich, “Discrim-inative and Generative Machine Learning Approaches TowardsTobust Phoneme Classification,”Proc. IEEE Workshop Inform.Theory Appl., pp. 471–475, 2008.
[48] N. Garcia-Pedrajas and D. Ortiz-Boyer, “Improving MulticlassPattern Recognition by the Combination of Two Strategies,”IEEE Trans. PAMI, vol. 28, no. 6, pp. 1001–1006, 2006.
[49] K. Crammer and Y. Singer, “On the Algorithmic Implemen-tation of Multiclass Kernel-based Vector Machines,”J. Mach.Learn. Res., vol. 2, pp. 265–292, 2002.
[50] J. Yousafzai, Z. Cvetkovic, and P. Sollich, “Custom-DesignedSVM Kernels for Improved Robustness of Phoneme Classifica-tion,” Proc. EUSIPCO, pp. 1765–1769, 2009.
[51] D. Ellis, “PLP and RASTA (and MFCC, and inversion) inMatlab,” 2005, Online Web Resource.
[52] S. Furui, “Speaker-Independent Isolated Word Recognitionusing Dynamic Features of Speech Spectrum,”IEEE Trans.ASSP, vol. 34, no. 1, pp. 52–59, 1986.
[53] J. Tchorz and B. Kollmeier, “Estimation of the Signal-to-Noise Ratio with Amplitude Modulation Spectrograms,”SpeechComm., vol. 38, no. 1, pp. 1–17, 2002.
[54] E. Nemer, R. Goubran, and S. Mahmoud, “SNR Estimation ofSpeech Signals Using Subbands and Fourth-Order Statistics,”IEEE Signal Process. Letters, vol. 6, no. 7, pp. 171–174, 1999.
[55] Y. Ephraim and D. Malah, “Speech Enhancement Using aMinimum Mean-Square Error Short-time Spectral AmplitudeEstimator,” IEEE Trans. ASSP, vol. ASSP-32, pp. 1109–1121,1984.
[56] Y. Ephraim and D. Malah, “Speech Enhancement Using aMinimum Mean-Square Log-Spectral Amplitude Estimator,”IEEE Trans. ASSP, vol. ASSP-33, pp. 443–445, 1985.
[57] J. Garofolo, L. Lamel, W. Fisher, J. Fiscus, D. Pallet, andN. Dahlgren, “TIMIT Acoustic-Phonetic Continuous SpeechCorpus,” Linguistic Data Consortium, 1993.
[58] K. F. Lee and H. W. Hon, “Speaker-Independent PhoneRecognition Using Hidden Markov Models,” IEEE Trans.ASSP, vol. 37, no. 11, pp. 1641–1648, 1989.
[59] R. F. Voss and J. Clarke, “1/f Noise in Music: Music from1/f Noise,” J. Acoust. Soc. Amer., vol. 63, no. 1, pp. 258–263,1978.
[60] C. Rathinavelu and L. Deng, “HMM-based Speech RecognitionUsing State-dependent, Discriminatively Derived Transformson Mel-Warped DFT Features,,”IEEE Trans. Speech AudioProcess., vol. 5, no. 3, pp. 243–256, 1997.
[61] F. Pernkopf, T. V. Pham, and J. Bilmes, “Broad Phonetic Clas-sification Using Discriminative Bayesian Networks,”SpeechComm., vol. 51, no. 2, pp. 151–166, 2009.
[62] B. Catanzaro, N. Sundaram, and K. Keutzer, “Fast SupportVector Machine Training and Classification on Graphics Pro-cessors,”Proc. ICML, pp. 104–111, 2008.
12
Jibran Yousafzai (S’08) received his B.S.degree in computer system engineering fromGIK Institute, Pakistan in 2004 and the M.Sc.degree in signal processing from King’s Col-lege London in 2006. In 2004-2005, he workedas a teaching assistant at GIK Institute. Heis currently a Ph.D. candidate at the Depart-ment of Informatics at King’s College London.His areas of interest include automatic speech
recognition, machine learning and audio processing for surroundsound technology.
Peter Sollich is Professor of Statistical Mechan-ics at King’s College London. He obtained anM.Phil. from Cambridge University in 1992 anda Ph.D. from the University of Edinburgh in1995, and held a Royal Society Dorothy HodgkinResearch Fellowship until 1999. He works onstatistical inference and applications of statisticalmechanics to complex and disordered systems.He is a member of the Institute of Physics, afellow of the Higher Education Academy, and
serves on the editorial boards of Europhysics Letters and Journal ofPhysics A.
Zoran Cvetkovic received his Dipl.Ing.El. andMag.El. degrees from the University of Belgrade,Yugoslavia, in 1989 and 1992, respectively; theM.Phil. from Columbia University in 1993; andthe Ph.D. in electrical engineering from the Uni-versity of California, Berkeley, in 1995. He heldresearch positions at EPFL, Lausanne, Switzerland(1996), and at Harvard University (2002-04). Be-tween 1997 and 2002 he was a member of thetechnical staff of AT&T Shannon Laboratory. He
is now Reader in Signal Processing at Kings College London. Hisresearch interests are in the broad area of signal processing, rangingfrom theoretical aspects of signal analysis to applications in sourcecoding, telecommunications, and audio and speech technology.
Bin Yu is Chancellor’s Professor in the depart-ments of Statistics and of Electrical Engineering& Computer Science at UC Berkeley. She iscurrently the chair of department of Statistics,and a founding co-director of the MicrosoftLab on Statistics and Information Technologyat Peking University, China. She got her B.S.in mathematics from Peking University in 1984,M.S. and Ph.D. in Statistics from UC Berkeleyin 1987 and 1990. She has published over 80
papers on a wide range of research areas including empiricalprocesstheory, information theory (MDL), MCMC methods, signal process-ing, machine learning, high dimensional data inference (boosting andLasso and sparse modeling in general), bioinformatics, andremotessensing. She has been and is serving on many leading journals’editorial boards including Journal of Machine Learning Research,The Annals of Statistics, and Technometrics. Her current researchinterests include statistical machine learning for high dimensionaldata and solving data problems from remote sensing, neuroscience,and newspaper documents.
She was a 2006 Guggenheim Fellow, and is a Fellow of AAAS,IEEE, IMS (Institute of Mathematical Statistics) and ASA (AmericanStatistical Association). She is a co-chair of National Scientific
Committee of SAMSI and on the Board of Mathematical Sciencesand Applications of the National Academy of Sciences in the US.