Page 1
Comparacion del ModeloCOM-Poisson y el Modelo Poisson
Alvaro Arley Castano Colorado
Universidad Nacional de Colombia
Facultad de Ciencias, Escuela de Estadıstica
Medellın, Colombia
2017
Page 3
Comparacion del ModeloCOM-Poisson y el Modelo Poisson
Alvaro Arley Castano Colorado
Tesis o trabajo de grado presentada(o) como requisito parcial para optar al tıtulo de:
Magıster en Ciencias - Estadıstica
Director: Juan Carlos Correa Morales
Ph.D. en Estadıstica
Lınea de Investigacion:
Bioestadıstica
Universidad Nacional de Colombia
Facultad de Ciencias, Escuela de Estadıstica
Medellın, Colombia
2017
Page 5
Nunca consideres el estudio como una obliga-
cion, sino como una oportunidad para penetrar
en el bello y maravilloso mundo del saber.
Albert Einstein
Page 7
Agradecimientos
A mi madre y hermano quienes me brindaron su apoyo en las etapas de estudio, pasantıa y
en la elaboracion de esta investigacion.
A Juan Carlos Correa Morales, profesor asociado de la Universidad Nacional de Colombia,
por brindarme los elementos e ideas esenciales para el desarrollo de los objetivos propuestos
en esta disertacion.
Al destacado grupo humano que conforma la Escuela de Estadıstica de la Facultad de Cien-
cias por brindarme las experiencias academicas y de investigacion las cuales fueron de gran
ayuda para la ejecucion de este trabajo.
Page 9
ix
Resumen
La modelacion de datos de conteo se hace tıpicamente usando el modelo Poisson, en el
cual se asume que la media y la varianza son iguales. Cuando esta condicion no es facil de
justificar, se han propuesto diferentes alternativas, unas mas flexibles que otras, en cuanto a
la captura tanto de sobredispersion como de subdispersion. Una de ellas es el modelo COM-
Poisson el cual fue recientemente propuesto y ha sido evaluado en terminos inferenciales. La
propuesta de estudio que aquı se presenta quiere cuantificar la calidad predictiva del modelo
COM-Poisson con respecto al modelo Poisson, y ası establecer la perdida en la eficiencia
que se tiene al ajustar el modelo inadecuado cuando la propiedad de equidispersion no es
satisfactoria. Los estudios de simulacion efectuados determinaron que al ajustar el modelo
inadecuado, ya sea en sobre o subdispersion, no representa, en la mayorıa de los casos, ni
una ganancia o perdida en cuanto a la calidad predictiva. Dos estudios de caso aplicados a
la ecologıa ilustran los resultados obtenidos.
Palabras clave: Datos de Conteo, Modelos Lineales Generalizados, Eficiencia Relativa, Re-
gresion Poisson, Regresion Conway-Maxwell-Poisson, Capacidad Predictiva, Dispersion.
Abstract
Modeling count data is typically done using the Poisson model, in which it is assumed that
the mean and variance are equal. When this condition is not easy to justify, different al-
ternatives have been proposed, some more flexible than others in terms of the capture of
both overdispersion and underdispersion. One of them is the COM-Poisson model which was
recently proposed and has been evaluated in inferential terms. The study proposal presen-
ted here wants to quantify the COM-Poisson model predictive quality with respect to the
Poisson model and establish the loss in efficiency that occurs when the inadequate model
is fitted when the property of equidispersion is not satisfactory. Simulation studies made
determined that when adjusting the inappropriate model either in over or underdispersion
doesn’t represent in most cases, a gain or loss in regard to the predictive quality. Two case
studies applied to the ecology illustrate the results obtained.
Keywords: Count Data, Generalized Linear Models, Relative Efficiency, Poisson regression,
Conway-Maxwell-Poisson regression, Predictive Power, Dispersion.
Page 10
Contenido
Agradecimientos VII
Resumen IX
Contenido XII
Lista de Figuras XIII
Lista de Tablas XV
Lista de Ecuaciones XVIII
Lista de Sımbolos XIX
1. Introduccion 1
1.1. Los datos de conteo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Planteamiento del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3. Estructura de la investigacion . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2. Marco teorico 4
2.1. El Modelo Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2. El Modelo COM-Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3. Violacion al supuesto de equidispersion (ED) . . . . . . . . . . . . . . . . . . 7
2.3.1. Sobredispersion (OD) . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.2. Subdispersion (UD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.3. Pruebas de dispersion . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4. Modelos alternativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4.1. Modelo Binomial Negativo (BN) . . . . . . . . . . . . . . . . . . . . . 8
2.4.2. Modelo Poisson Generalizado Restringido (PGR) . . . . . . . . . . . 10
2.4.3. Modelo Poisson Doble (PD) . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.4. Modelo hyper-Poisson (hP) . . . . . . . . . . . . . . . . . . . . . . . 11
2.5. Estado del arte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3. Metodologıa 14
Page 11
Contenido xi
3.1. Programacion y analisis estadıstico . . . . . . . . . . . . . . . . . . . . . . . 14
3.2. Simulacion de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1. Seleccion de coeficientes asumidos para el vector β . . . . . . . . . . . 15
3.2.2. Simulacion de conteos . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2.3. Niveles de dispersion . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2.4. Tamano muestral (n) . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3. Procedimiento de las simulaciones . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3.1. Numero de simulaciones (nsim) . . . . . . . . . . . . . . . . . . . . . 17
3.3.2. Algoritmo para las simulaciones . . . . . . . . . . . . . . . . . . . . . 17
3.3.3. Modelos ajustados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4. Calculo de medidas estadısticas . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4.1. Sesgo de los coeficientes estimados . . . . . . . . . . . . . . . . . . . 20
3.4.2. Intervalos de confianza (IC) para los coeficientes de los modelos . . . 21
3.4.3. Raız Cuadrada del Error Cuadratico Medio (RECM) . . . . . . . . . 21
3.4.4. Raız Cuadrada del Error Cuadratico Medio de Prediccion (RECMP) 22
3.5. Eficiencia Relativa (ER) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.6. Mediana del Error Porcentual Absoluto (EPAMe) . . . . . . . . . . . . . . . 23
3.7. Calculo de medida de bondad de ajuste . . . . . . . . . . . . . . . . . . . . . 23
4. Comparacion de las funciones glm.comp y cmp 25
4.1. Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1.1. Descripcion de la simulacion . . . . . . . . . . . . . . . . . . . . . . . 25
4.1.2. Deteccion de diferencias . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2.1. Calidad de las estimaciones . . . . . . . . . . . . . . . . . . . . . . . 27
4.2.2. Calidad predictiva y ER . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2.3. Diferencias identificadas . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3. Discusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.4. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5. Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson 47
5.1. Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.1.1. Descripcion de la simulacion . . . . . . . . . . . . . . . . . . . . . . . 48
5.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
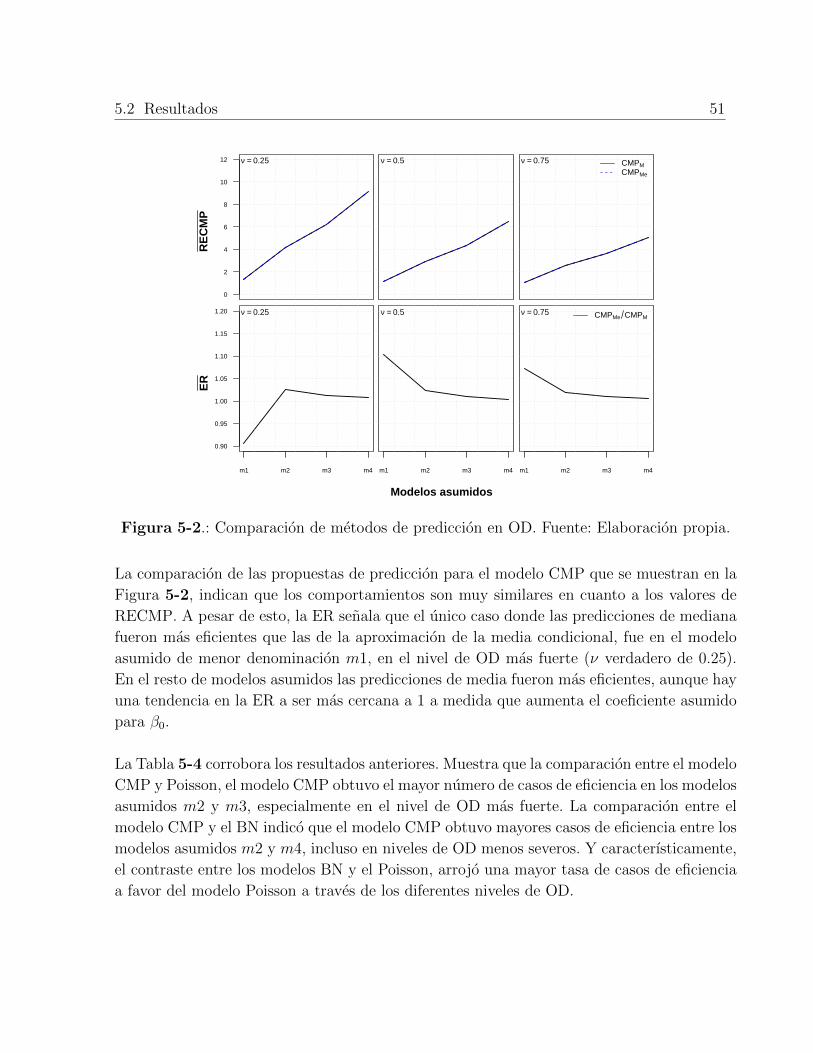
5.2.1. Eficiencia Relativa en OD . . . . . . . . . . . . . . . . . . . . . . . . 50
5.2.2. Eficiencia Relativa en ED . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.3. Eficiencia Relativa en UD . . . . . . . . . . . . . . . . . . . . . . . . 54
5.3. Discusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.4. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6. Aplicacion con datos reales en la ecologıa 60
Page 12
xii Contenido
6.1. Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.1.1. Descripcion de los datos . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6.2.1. Para el estudio de abundancia . . . . . . . . . . . . . . . . . . . . . . 63
6.2.2. Para el estudio del tamano del nido en aves . . . . . . . . . . . . . . 64
6.3. Discusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.4. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7. Conclusiones y recomendaciones 67
7.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
7.2. Recomendaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.3. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
A. Anexo: Errores estandar inconsistentes entre las funciones glm.comp y cmp 70
B. Anexo: Distribucion empırica de β0 en un modelo de regresion COM-Poisson 72
C. Anexo: Resumen de las simulaciones del Capıtulo 5 74
D. Anexo: Evaluacion de la bondad de ajuste 78
E. Anexo: Documentacion de las funciones desarrolladas para las simulaciones 79
simCorData . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
simData . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
simFit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
simFitCMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
Stats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Bibliografıa 90
Page 13
Lista de Figuras
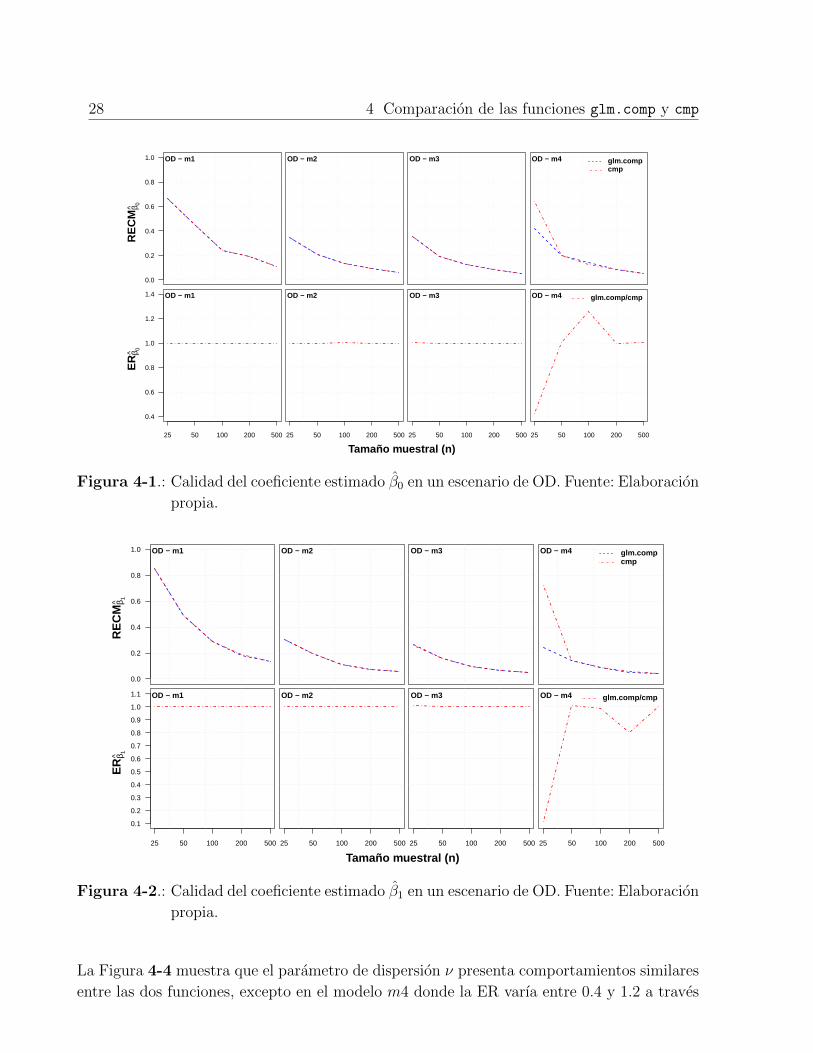
4-1 Calidad del coeficiente estimado β0 en un escenario de OD . . . . . . . . . . 28
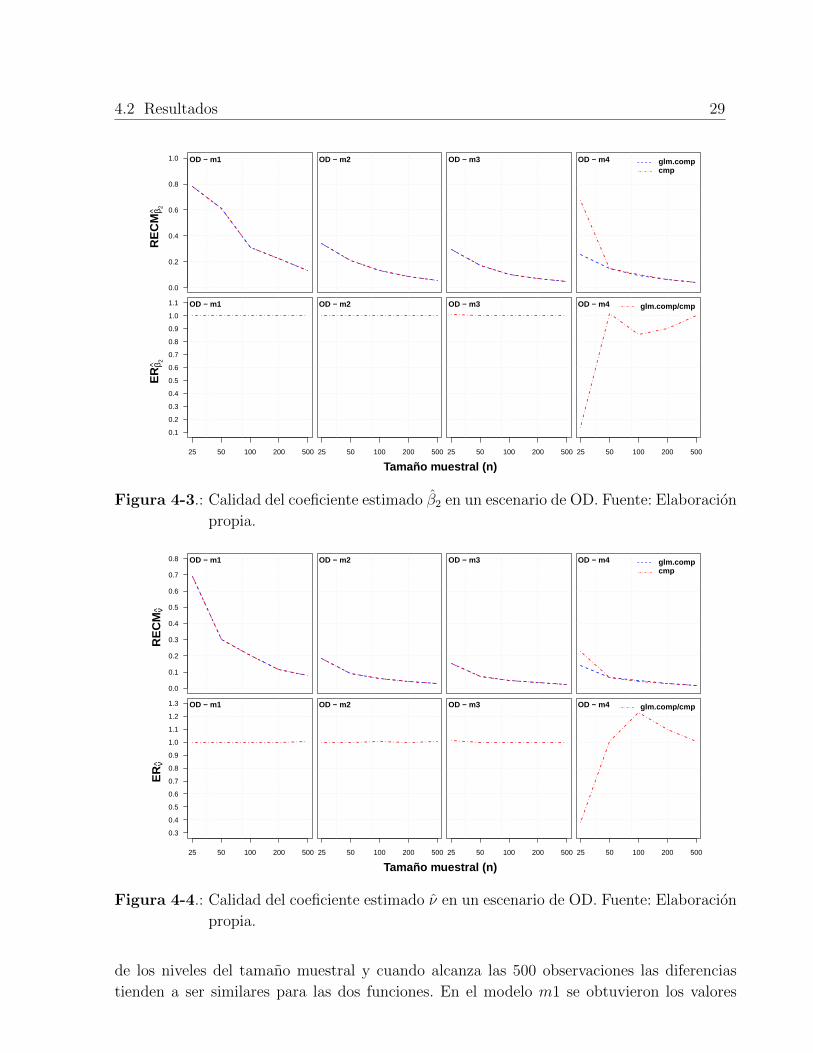
4-2 Calidad del coeficiente estimado β1 en un escenario de OD . . . . . . . . . . 28
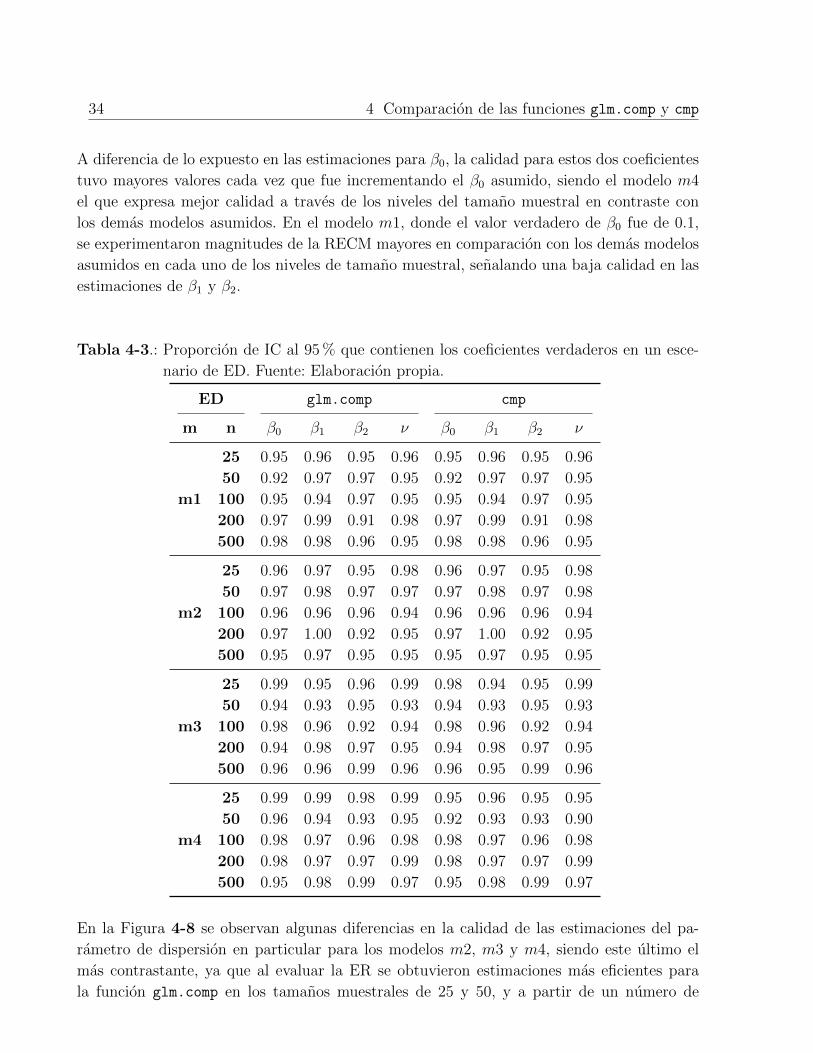
4-3 Calidad del coeficiente estimado β2 en un escenario de OD . . . . . . . . . . 29
4-4 Calidad del coeficiente estimado ν en un escenario de OD . . . . . . . . . . . 29
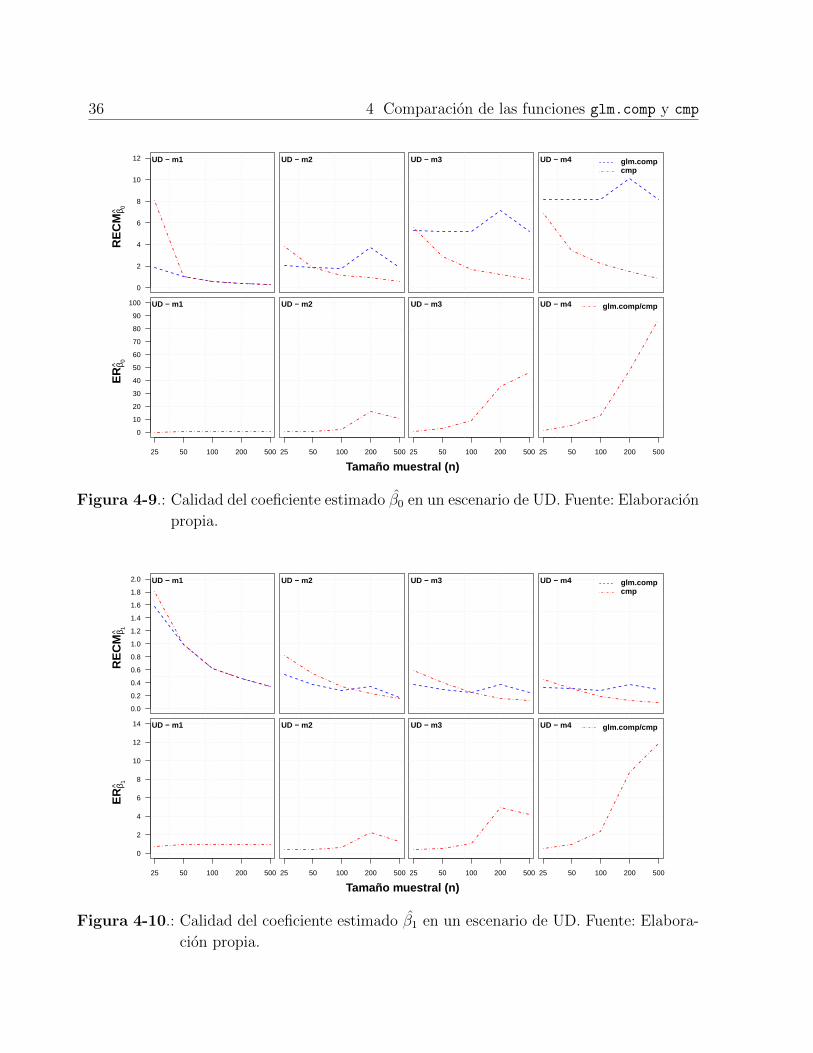
4-5 Calidad del coeficiente estimado β0 en un escenario de ED . . . . . . . . . . 32
4-6 Calidad del coeficiente estimado β1 en un escenario de ED . . . . . . . . . . 32
4-7 Calidad del coeficiente estimado β2 en un escenario de ED . . . . . . . . . . 33
4-8 Calidad del coeficiente estimado ν en un escenario de ED . . . . . . . . . . . 33
4-9 Calidad del coeficiente estimado β0 en un escenario de UD . . . . . . . . . . 36
4-10 Calidad del coeficiente estimado β1 en un escenario de UD . . . . . . . . . . 36
4-11 Calidad del coeficiente estimado β2 en un escenario de UD . . . . . . . . . . 37
4-12 Calidad del coeficiente estimado ν en un escenario de UD . . . . . . . . . . . 37
4-13 Contraste entre las estimaciones de las funciones glm.comp y cmp en terminos
de RECMP y ER en un escenario de OD . . . . . . . . . . . . . . . . . . . . 40
4-14 Contraste entre las estimaciones de las funciones glm.comp y cmp en terminos
de RECMP y ER en un escenario de ED . . . . . . . . . . . . . . . . . . . . 41
4-15 Contraste entre las estimaciones de las funciones glm.comp y cmp en terminos
de RECMP y ER en un escenario de UD . . . . . . . . . . . . . . . . . . . . 42
4-16 Tiempo medio de ajuste de un modelo CMP entre las funciones glm.comp y
cmp en un escenario de ED . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5-1 Desempeno predictivo en OD . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5-2 Comparacion de metodos de prediccion en OD . . . . . . . . . . . . . . . . . 51
5-3 Desempeno predictivo en ED . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5-4 Comparacion de metodos de prediccion en ED . . . . . . . . . . . . . . . . . 53
5-5 Desempeno predictivo en UD . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5-6 Comparacion de metodos de prediccion en UD . . . . . . . . . . . . . . . . . 55
6-1 Localizacion del area de muestreo del estudio de abundancia. . . . . . . . . . 61
B-1 Grafico de distribucion empırica de β0 en un modelo de regresion COM-
Poisson en diferentes tamanos muestrales . . . . . . . . . . . . . . . . . . . . 72
Page 14
xiv Lista de Figuras
B-2 Grafico de distribucion empırica de β0 en un modelo de regresion COM-
Poisson con n = 1000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Page 15
Lista de Tablas
4-1 Coeficientes asumidos para el estudio de simulacion de comparacion de las
funciones glm.comp y cmp . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4-2 Proporcion de IC al 95 % que contienen los coeficientes verdaderos en un
escenario de OD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4-3 Proporcion de IC al 95 % que contienen los coeficientes verdaderos en un
escenario de ED . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4-4 Proporcion de IC al 95 % que contienen los coeficientes verdaderos en un
escenario de UD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5-1 Coeficientes asumidos para el estudio de simulacion de eficiencia entre el mo-
delo CMP y el modelo Poisson en, OD . . . . . . . . . . . . . . . . . . . . . 48
5-2 Coeficientes asumidos para el estudio de simulacion de eficiencia entre el mo-
delo CMP y el modelo Poisson, en ED . . . . . . . . . . . . . . . . . . . . . 49
5-3 Coeficientes asumidos para el estudio de simulacion de eficiencia entre el mo-
delo CMP y el modelo Poisson, en UD . . . . . . . . . . . . . . . . . . . . . 49
5-4 Proporcion de ER en un escenario de OD con n = 1000 . . . . . . . . . . . . 52
5-5 Proporcion de ER en un escenario de ED con n = 1000 . . . . . . . . . . . . 54
5-6 Proporcion de ER en un escenario de UD con n = 1000 . . . . . . . . . . . . 56
6-1 Resumen de las estimaciones en los modelos comparados en el estudio de
abundancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6-2 Calidad de las predicciones en los modelos comparados en el estudio de abun-
dancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6-3 Resumen de las estimaciones en los modelos comparados en el estudio del
tamano del nido en aves . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6-4 Calidad de las predicciones en los modelos comparados en el estudio del ta-
mano del nido en aves . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
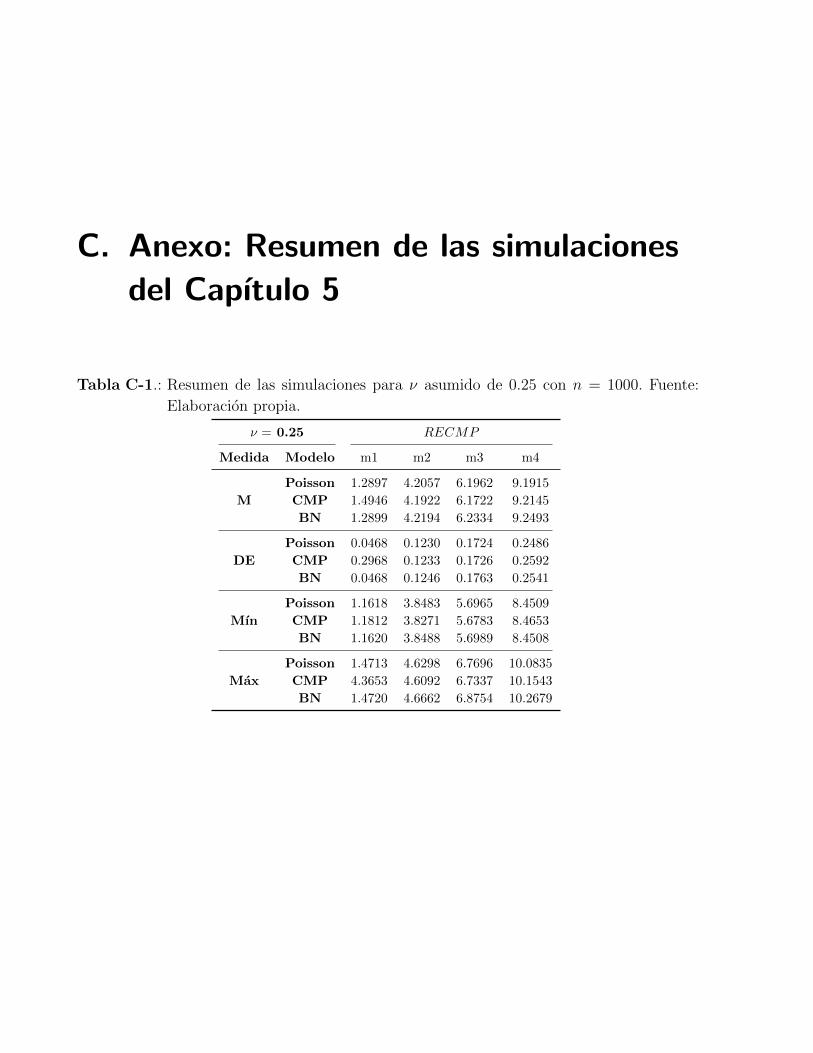
C-1 Resumen de las simulaciones para ν asumido de 0.25 con n = 1000 . . . . . . 74
C-2 Resumen de las simulaciones para ν asumido de 0.5 con n = 1000 . . . . . . 75
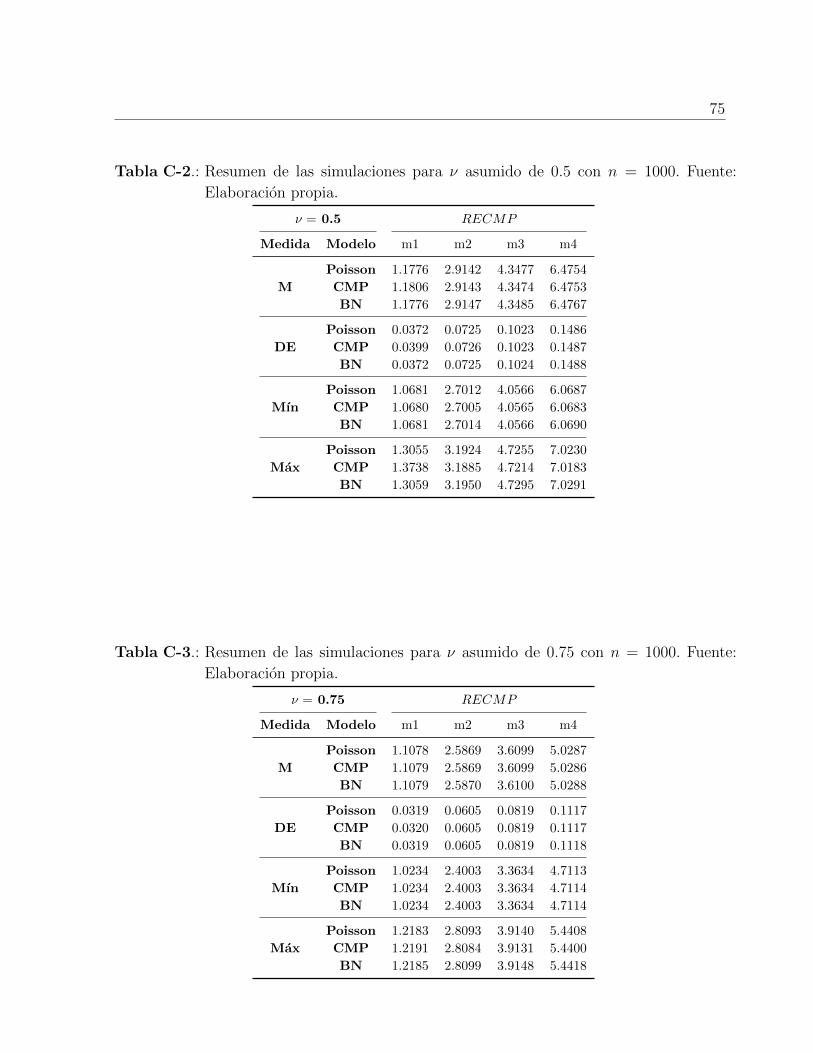
C-3 Resumen de las simulaciones para ν asumido de 0.75 con n = 1000 . . . . . . 75
C-4 Resumen de las simulaciones para ν asumido de 1 con n = 1000 . . . . . . . 76
C-5 Resumen de las simulaciones para ν asumido de 1.5 con n = 1000 . . . . . . 76
Page 16
xvi Lista de Tablas
C-6 Resumen de las simulaciones para ν asumido de 2.5 con n = 1000 . . . . . . 77
C-7 Resumen de las simulaciones para ν asumido de 5 con n = 1000 . . . . . . . 77
D-1 CIA medio con n = 1000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
Page 17
Lista de Ecuaciones
1–1 Propiedad de equidispersion en la distribucion Poisson . . . . . . . . . . . . . . 2
2–1 fmp de la distribucion Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2–2 Modelo de regresion Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2–3 Funcion de verosimilitud del modelo Poisson . . . . . . . . . . . . . . . . . . . . 5
2–4 fmp de la distribucion CMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2–5 Valor esperado del modelo CMP . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2–6 Varianza del modelo COM-Poisson . . . . . . . . . . . . . . . . . . . . . . . . . 6
2–7 Funcion de log-verosimilitud del modelo COM-Poisson . . . . . . . . . . . . . . 6
2–8 fmp de la distribucion BN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2–9 Valor esperado y varianza la distribucion BN . . . . . . . . . . . . . . . . . . . 9
2–10 Valor esperado y varianza la distribucion BN . . . . . . . . . . . . . . . . . . . 9
2–11 Funcion de log-verosimilitud en la regresion BN . . . . . . . . . . . . . . . . . . 9
2–12 fmp de la distribucion PGR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2–13 fmp de la distribucion PD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2–14 Valor esperado y varianza de la distribucion PD . . . . . . . . . . . . . . . . . . 10
2–15 fmp de la distribucion hP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2–16 Coincidencia de serie hipergeometrica en la distribucion hP . . . . . . . . . . . 11
2–17 Media de la distribucion hP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2–18 Varianza de la distribucion hP . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2–19 Funcion de log-verosimilitud en la regresion hP . . . . . . . . . . . . . . . . . . 11
3–1 Funcion de enlace para los modelos de regresion . . . . . . . . . . . . . . . . . . 15
3–2 Constante de normalizacion Z(λ, ν) aproximada . . . . . . . . . . . . . . . . . . 19
3–3 Estimacion de medias en la regresion CMP . . . . . . . . . . . . . . . . . . . . 19
3–4 Calculo de probabilidades para la estimacion de medianas en la regresion CMP 19
3–5 Sesgo de un estimador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3–6 IC para los coeficientes estimados . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3–7 Formula para el calculo de RECM . . . . . . . . . . . . . . . . . . . . . . . . . 21
3–8 Formula para el calculo de RECMP . . . . . . . . . . . . . . . . . . . . . . . . 22
3–9 Formula para el calculo de la ER de estimadores . . . . . . . . . . . . . . . . . 22
3–10 Formula para el calculo de la ER de las predicciones . . . . . . . . . . . . . . . 22
3–11 Formula para el calculo de los EPA . . . . . . . . . . . . . . . . . . . . . . . . . 23
3–12 Formula para el calculo del CIA . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Page 18
xviii Lista de Ecuaciones
3–13 Formula para el calculo del CIAc . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Page 19
Lista de Sımbolos
Abreviaturas
Abreviatura Termino
BN Binomial Negativa
CAP Circunferencia a la Altura del Pecho
CIA Criterio de Informacion de Akaike
CIAc Criterio de Informacion de Akaike corregido
CMP Conway-Maxwell-Poisson
DE Desviacion Estandar
ECM Error Cuadratico Medio
ECMP Error Cuadratico Medio de Prediccion
ECV Estimacion por Cuasi-Verosimilitud
EMV Estimacion por Maxima Verosimilitud
ED Equidispersion (en ingles: Equidispersion)
EPA Error Porcentual Absoluto
ER Eficiencia Relativa
ES Error Estandar
fmp Funcion de masa de probabilidad
hP hyper-Poisson
IC Intervalo de Confianza
iid Independientes e identicamente distribuidos
Max Maximo
MCMC (En ingles) Simulacion Monte Carlo por Cadenas de Markov
MCRI Mınimos Cuadrados Reponderados Iterativamente
Mın Mınimo
MLG Modelo Lineal Generalizado
nsim Numero de simulaciones
OD Sobredispersion (en ingles: Overdispersion)
PD Poisson Doble
PGR Poisson Generalizada Restringida
RECM Raız Cuadrada del Error Cuadratico Medio
RECMP Raız Cuadrada del Error Cuadratico Medio de Prediccion
Page 20
xx Lista de Sımbolos
Abreviatura Termino
UD Subdispersion (en ingles: Underdispersion)
Sımbolos con letras latinas
Sımbolo Termino
M Media
m Modelo asumido
Me Mediana
n Tamano muestral
Sımbolos con letras griegas
Sımbolo Termino
α Parametro de dispersion de la distribucion PGR
β Vector de parametros del modelo de regresion
γ Parametro de dispersion de la distribucion hP
θ Parametro de dispersion de la distribucion BN y PD
λ Parametro de centralizacion de la distribucion Poisson
µ Media Poblacional o Parametro de centralizacion de la distribucion CMP MLG
ν Parametro de dispersion de las distribuciones CMP y CMP MLG
φ Parametro de dispersion, forma o variacion generalizado
Page 21
1. Introduccion
Este capıtulo tiene como objetivo presentar el contexto sobre el cual se ha desarrollado el
problema del analisis de datos de conteo (Seccion 1.1) cuando no se logra justificar la propie-
dad de equidispersion, para plantear las preguntas que seran objeto de evaluacion durante
la investigacion (Seccion 1.2). Tambien se presenta la estructura en la que se encuentra or-
ganizado este trabajo en la Seccion 1.3.
1.1. Los datos de conteo
Los datos de conteo se refieren al numero de veces que se da un evento en un perıodo de
tiempo o espacio definido como, por ejemplo, el numero de accidentes aereos, el numero de
dıas de permanencia en un hospital, la cantidad de frutos en un arbol. Este tipo de datos
toman valores enteros no negativos y se asume que los eventos en un intervalo de tiempo o
espacio determinado son independientes e identicamente distribuidos (iid) [4].
Cameron & Trivedi [4] presentan dos formulaciones para obtener este tipo de datos. Una for-
ma es por medio de conteos directamente observables en cualquier situacion, donde se asume
que hay un proceso homogeneo y estacionario en el cual el numero de eventos por unidad de
tiempo o espacio son iid. Otra formulacion es la que se da por medio de la discretizacion de
datos continuos, que consiste en aquellos conteos que se definen en una muestra de elementos
los cuales son clasificados segun el tipo de evento de interes.
El problema que han tenido los modelos para datos de conteo son los niveles de dispersion
que estos pueden tomar. Segun Hilbe [14], en la mayorıa de los casos es raro que los datos
de conteo en la realidad tengan equidispersion, lo cual siempre se asume en la distribucion
Poisson. Es mas comun encontrar datos con sobredispersion o subdispersion, aunque este
ultimo con menos frecuencia. Cuando se habla de sobredispersion en los conteos por unidad
de tiempo o espacio, se refiere a que la varianza excede su media y se habla de subdispersion
cuando la varianza es menor que la media. Segun Dobson [5], hay una forma de determinar
estos niveles de dispersion la cual consiste en hallar la constante de variacion (φ) de acuerdo
a la siguiente expresion:
V ar(Y ) = φE(Y ) = φµ (1–1)
Page 22
2 1 Introduccion
Si φ > 1, hay sobredispersion, Si φ < 1, hay subdispersion.
1.2. Planteamiento del problema
De acuerdo con Cameron & Trivedi [4], el analisis de datos de conteo se ha venido desarro-
llando con el fin de explicar un fenomeno en donde la variable respuesta toma valores enteros
no negativos en relacion al numero de veces que un evento de interes es observado en un inter-
valo de tiempo, espacio, longitud, etc. El modelo tıpico sobre el cual parte el analisis de este
tipo de datos es el modelo Poisson. Este se caracteriza por el supuesto de equidispersion, en
donde la media y la varianza son iguales, lo cual puede ser causante de un ajuste inadecuado
cuando no se cumpla dicha condicion, es decir, que este modelo no explica bien conjuntos
de datos que presentan casos de subdispersion o sobredispersion [32]. Recientemente se han
desarrollado diversas alternativas para modelar bajo la violacion de este supuesto, entre las
mas utilizadas estan la regresion Binomial Negativa (BN) [14], la regresion Poisson Genera-
lizada Restringida (PGR) [8], la regresion Conway-Maxwell-Poisson (CMP) [32], la regresion
hyper-Poisson [30], entre otras. Segun Sellers & Shmueli [32], la regresion BN, a pesar de que
explica correctamente datos con sobredispersion, no es adecuado para la modelacion cuando
la varianza es inferior a la media. En cuanto a la regresion PGR, estos autores enuncian
que dicho modelo puede ajustar tanto datos con sobredispersion como subdispersion, pero
es limitante en este ultimo caso. Recientemente ha surgido un modelo mas flexible el cual se
adapta bien a los diferentes niveles de dispersion en los datos de conteo, es denominado el
modelo CMP.
El establecimiento de esta ultima alternativa dentro de un marco inferencial esta en proceso
de estudio y evaluacion. Hasta ahora se han evaluado sus propiedades inferenciales e inclu-
so se han hecho modificaciones a la propuesta original, una de ellas es el planteamiento de
Guikema & Goffelt [13] quienes reparametrizaron el modelo CMP original y lo adaptaron
dentro del marco de un Modelo Lineal Generalizado (MLG). El analisis de las estimaciones
ha sido objeto de estudio en las diversas investigaciones relacionadas con esta regresion. Se
han desarrollado estudios con el fin de establecer la calidad de las estimaciones del mode-
lo, evaluando el comportamiento de los estimadores en diversos escenarios. Los metodos de
estimacion de parametros, los niveles de dispersion, las medias y tamanos muestrales han
sido los componentes para establecer dichos escenarios y hacer la comparacion y evaluacion
respectiva.
En vista de que se tiene un modelo tradicional, simple o basico como lo es el Poisson, surge
la necesidad de compararlo con un modelo mas flexible (Modelo CMP) que hasta ahora se
ha desarrollado para modelar datos de conteo, debido a su ajuste adecuado cuando los datos
Page 23
1.3 Estructura de la investigacion 3
presentan diferentes niveles de dispersion. Por lo anteriormente expuesto surgen las siguien-
tes preguntas:
¿Cual es la eficiencia de un modelo con respecto al otro?
¿Que tanto se pierde a nivel predictivo cuando se ajusta el modelo inadecuado?
Para responder estas inquietudes se quiere determinar vıa simulacion la eficiencia relativa
entre el modelo Poisson y el Modelo COM-Poisson y comparar estos modelos por medio de
medidas de calidad de las predicciones, en diversos escenarios que tendran como factores a
controlar, la variacion de la dispersion y del intercepto, ası como, los tamanos muestrales.
Con este estudio se quiere aportar informacion que permita determinar el comportamiento
inferencial de las estimaciones del modelo en cuanto al desempeno predictivo, y tambien que
el estudio permita ser contrastado con otros estudios similares lo cual permitira establecer
una base teorica y aplicada mas robusta respecto al modelo CMP.
1.3. Estructura de la investigacion
El presente trabajo tiene la siguiente organizacion. El Capıtulo 2 presenta una recopilacion
teorica sobre los aspectos mas relevantes de la investigacion, ademas de que se describen los
conceptos relacionados con el problema planteado. En el Capıtulo 3 se describen los diferen-
tes procedimientos que fueron considerados para los estudios de simulacion y las aplicaciones
con conjuntos de datos reales. El Capıtulo 4 se estudia mediante la comparacion de dos
implementaciones en R para ajustar modelos CMP, la calidad de las estimaciones ası como
de la calidad de las predicciones. En el Capıtulo 5, en un marco de normalidad asintotica
de las estimaciones, se determina la ER en cuanto a las predicciones de los modelos. En el
Capıtulo 6 se ilustra por medio de dos estudios de caso aplicados a la ecologıa los resultados
obtenidos vıa simulacion. Y finalmente, en Capıtulo 7 se dan a conocer las conclusiones mas
relevantes y recomendaciones en terminos de los objetivos planteados. Tambien se propone
un estudio a futuro siguiendo la misma lınea de investigacion propuesta para esta disertacion.
Page 24
2. Marco teorico
En este capıtulo se describen las propuestas planteadas dentro del contexto de los modelos
de regresion para ajustar datos de conteo. Tambien se presentan algunos de los conceptos e
investigaciones que se relacionan con el problema que ha sido previamente planteado en el
Capıtulo 1.
El contenido de este capıtulo esta organizado de la siguiente manera. La Seccion 2.1 se
comentan las caracterısticas de la distribucion y del modelo Poisson. En la Seccion 2.2 se
presentan los atributos de la distribucion CMP, ası como sus alcances a nivel inferencial como
modelo de regresion. La Seccion 2.3 describe las causas y consecuencias de violar el supuesto
de equidispersion en un modelo Poisson. Tambien una serie de alternativas de modelos de
regresion para datos de conteo son citadas en la Seccion 2.4. Para finalizar, este capıtulo da
a conocer en la Seccion 2.5, los antecedentes y diferentes propuestas que estan relacionadas
con el tema de investigacion formulado para este trabajo.
2.1. El Modelo Poisson
El modelo Poisson es la base del analisis de los datos de conteo que se cuantifican en un
intervalo de tiempo o espacio determinado. En esta seccion se describen algunas propiedades
de su distribucion y del modelo. Tambien se discute su debilidad a la hora de ajustar datos
con diferentes niveles de dispersion.
Segun Cameron & Trivedi [4], la distribucion Poisson que lleva el apellido de su formulador,
se establecio a partir de un caso lımite de la distribucion binomial. Su propiedad fundamental
es la equidispersion donde la varianza es igual a la media (V ar(Y ) = E(Y ) = µ), y a partir
de esta relacion se derivan los condicionamientos para la formulacion de otros modelos para
datos de conteo.
La ecuacion (2–1) muestra su funcion de masa de probabilidad (fmp). Donde λ = V ar(Y ) =
E(Y ).
Page 25
2.1 El Modelo Poisson 5
P (Y = y) =e−λλy
y!, y = 0, 1, 2, . . . (2–1)
De allı que λ es interpretada como la media del numero de eventos en un intervalo de longitud
de espacio o tiempo. Por ejemplo, el numero de huracanes por ano o el numero de arboles
enfermos por hectarea.
El modelo de regresion Poisson pertenece a la familia de los MLG, ya que su funcion de
distribucion pertenece a la familia exponencial, su predictor es lineal (η = Xβ) y tiene una
funcion de enlace g tal que E(Y ) = µ = g−1(η) [20]. Este modelo es expresado por la funcion
dada en la ecuacion (2–2), la cual sigue una distribucion condicional de yi (variable depen-
diente) en funcion de un vector de covariables xi y de parametros β [4].
E(yi|xi) = µi = exp {x′iβ} (2–2)
Esta es la forma multiplicativa del modelo y se expresa ası ya que de esta manera asegura
que µ tendra valores enteros no negativos. Si se plantea una forma aditiva hay un riesgo de
que ciertas combinaciones no cumplan con esta restriccion [4].
La ecuacion (2–3) es la funcion de log-verosimilitud obtenida para esta distribucion.
logL(β) =n∑i=1
{yix′iβ − exp(x′iβ)− log yi!} (2–3)
El modelo de regresion Poisson tiene diversas aplicaciones en el area de la salud, la econo-
mıa, las ciencias sociales, la ecologıa, entre otras. Cameron & Trivedi [4] presentan ejemplos
caracterısticos en este tipo de modelacion, en los cuales se encuentran investigaciones en
la economıa de la salud, el establecimiento de patentes al desarrollar nuevos productos, la
estimacion de la demanda recreacional por servicios ambientales, las fallas bancarias que se
dan en los bancos, en seguros de accidentes, en las tasas de credito, entre otras aplicaciones.
La mayor desventaja del modelo Poisson es que no explica correctamente muchos conjuntos
de datos en los que existe sobredispersion o subdispersion dada su propiedad de equidisper-
sion [32]. Por ello, se han disenado nuevas propuestas que pretenden ser mas flexibles y que
abarcan los diferentes niveles de dispersion que puede tomar este tipo de datos.
Page 26
6 2 Marco teorico
2.2. El Modelo COM-Poisson
La distribicion COM-Poisson fue propuesta por Conway y Maxwell en 1962, pero sus propie-
dades probabilısticas y de regresion fueron estudiadas por Shmueli, Minka, Kadane, Borle y
Boatwright en 2005 [34]. La fmp esta dada por la ecuacion (2–4).
P (Y = y) =λy
(y!)v Z (λ, v), y = 0, 1, 2, · · · , λ > 0, ν ≥ 0 (2–4)
Donde Z (λ, ν) = Σ∞s=0λs
(s!)νy ν ≥ 0 es el parametro de forma o de dispersion y λ que pro-
viene de la expresion P (Y=y−1)P (Y=y)
= yν
λ, que indica una tasa de decrecimiento de probabilidades
sucesivas [32].
Esta distribucion pertenece a la familia exponencial y contiene tres distribuciones, que son
la distribucion Poisson (Cuando ν = 1), la distribucion geometrica (Cuando ν = 0 y λ < 1)
y la distribucion Bernoulli (Cuando ν →∞, con probabilidad λ1+λ
) [34].
El valor esperado y la varianza estan dados por las ecuaciones (2–5) y (2–6). Como se puede
observar estas funciones no tienen una forma cerrada y se relacionan entre sı mediante ex-
presiones aproximadas [32].
E(Y ) =∂ logZ (λ, ν)
∂ log λ≈ λ1/ν − ν − 1
2ν(2–5)
V ar(Y ) =∂E(Y )
∂ log λ≈ 1
νλ1/ν (2–6)
La construccion del modelo se da a partir de un caso log-lineal de la regresion Poisson. De
allı se deduce la funcion de log-verosimilitud representada en la ecuacion (2–7).
logL(λi, ν) =n∑i=1
yi log λi − vn∑i=1
log yi!−n∑i=1
logZ(λi, v) (2–7)
Segun Sellers & Shmueli [32] con una prueba de dispersion se puede considerar que tan ra-
zonable es usar la regresion Poisson dado el caso particular cuando la dispersion es igual
a 1 (H0 : ν = 1) o la regresion COM-Poisson (H1 : ν 6= 1) (Subseccion 2.3.3). Los valores
ajustados se pueden obtener por medio de medias o medianas estimadas, ya que segun Minka
et al. [22] la aproximacion de la ecuacion (2–5) es buena cuando ν ≤ 1 o λi > 10ν [32].
Page 27
2.3 Violacion al supuesto de equidispersion (ED) 7
Este modelo ajusta bien datos con diferentes niveles de dispersion, pero tiene una restriccion
que es de cierta forma similar al supuesto de homocedasticidad en el caso de la regresion
lineal. Esta restriccion consiste en que se asume el modelo teniendo en cuenta un nivel de
dispersion constante a traves de todas las observaciones [32].
2.3. Violacion al supuesto de equidispersion (ED)
Cuando la media y la varianza no son iguales, la distribucion Poisson es deficiente debido a
que esta implica equidispersion (ED). Se determina que hay sobredispersion una vez la va-
rianza es mayor a la media, mientras que cuando la media supera a la varianza se considera
que hay subdispersion. Segun Cameron & Trivedi [3], la violacion al supuesto de equidisper-
sion en el modelo Poisson se asocia de alguna forma al supuesto de heterocedasticidad en el
modelo de regresion lineal. Estas son las caracterısticas de cada uno de estos escenarios de
dispersion.
2.3.1. Sobredispersion (OD)
Al modelar una variable de conteo con sobredispersion (OD) mediante un modelo Poisson
se incurre en varios problemas que pueden afectar su inferencia. Los errores estandar de
los coeficientes estimados por el modelo tienden a ser subestimados generando coeficientes
significativos cuando en realidad estos no lo son. Otro de los problemas es cuando se tienen
datos truncados y censurados, en donde se pueden obtener estimaciones inconsistentes [3].
Entre los factores que pueden generar este tipo de dispersion se encuentran la heterogeneidad
no observada, por ejemplo cuando el investigador define un λ el cual deberıa ser aleatorio.
Tambien son causantes de OD, los diferentes procesos de generacion de eventos, cuando el
proceso que genera el primer evento no es el mismo que genera el resto de los eventos; y la
falta de independencia en los eventos, es decir, cuando la ocurrencia de un evento tiene un
patron de generacion definido [3].
2.3.2. Subdispersion (UD)
Los conjuntos de datos con este tipo de dispersion no son tan comunes como los que se pre-
sentan en OD [29]. Segun Zou et al. [39], la causa de subdispersion (UD) se debe al proceso
de generacion de los datos o cuando la respuesta esta condicionada a la media. En conjuntos
de datos relacionados con el estudio de la accidentalidad vehicular, la UD es muy comun
Page 28
8 2 Marco teorico
cuando la media muestral es baja [17].
2.3.3. Pruebas de dispersion
Para diagnosticar cual es el nivel de dispersion en la variable de conteo se han propuesto
varias metodologıas, algunas mas flexibles que otras segun si diagnostican alguno de los es-
cenarios de dispersion o si lo hacen para ambos.
De acuerdo con Cameron & Trivedi [3], existe una prueba de dispersion que puede ser usada
tanto para OD como para UD. Consiste en el calculo de un estadıstico de prueba estimando
el modelo Poisson, obteniendo sus valores ajustados y ajustando un modelo mediante mıni-
mos cuadrados ordinarios sin intercepto. El contraste de hipotesis planteado para la prueba
define como H0 : α = 0 y H1 : α 6= 0, (siendo α el parametro o constante de dispersion)
indicando que puede haber OD o UD si la prueba es de dos colas, o definiendo la hipotesis
alterna en el sentido del nivel de dispersion a diagnosticar.
Sellers & Shmueli [32] proponen una prueba para determinar si es mas conveniente usar un
modelo Poisson o un modelo CMP para ajustar una respuesta de conteo. El juego de hipo-
tesis esta plateado en funcion del parametro de dispersion ν, donde H0 : ν = 1 y H1 : ν 6= 1,
al ser una prueba bilateral esta no indica si hay OD o UD, por lo tanto, para diagnosticar el
escenario de dispersion se recomienda hacer analisis exploratorio o ajustar el modelo CMP
para conocer el valor de ν.
2.4. Modelos alternativos
Estas son las diferentes propuestas que han sido desarrolladas dentro del marco de analisis
de datos de conteo, especialmente para cuando no se logra justificar el supuesto de ED en la
variable respuesta. Algunas son mas flexibles que otras en cuanto a su capacidad de capturar
mayores rangos de OD y UD.
2.4.1. Modelo Binomial Negativo (BN)
La regresion BN surgio como un metodo para modelar correctamente los datos con OD. En
esta seccion se hace una descripcion de las propiedades de su distribucion y de su modelo
de regresion. A pesar de que el modelo tiene varias derivaciones descritas por Hilbe [14], se
describira la forma tradicional de este metodo.
Page 29
2.4 Modelos alternativos 9
La distribucion es una mezcla de la distribucion Poisson y la distribucion gamma. Se relacio-
na tambien con la distribucion geometrica cuando el parametro r = α−1 (Numero de exitos
en n ensayos independientes) es igual a 1. Cuando el parametro de forma o de dispersion es
cero (α = 0) se convierte en una distribucion Poisson [14]. La ecuacion (2–8) muestra su fmp.
P (Y = y) =
(y + r − 1
r − 1
)prqy, y = 0, 1, 2, . . . (2–8)
Donde r = 1/θ , p = 11+θµ
y q = (1− p)
Las expresiones para la media y la varianza estan dadas en las ecuaciones (2–9) y (2–10),
respectivamente.
E(Y ) = µ =r(1− p)
p(2–9)
V ar(Y ) =r(1− p)p2
(2–10)
Segun Hilbe [14], el modelo BN se puede obtener a partir de la mezcla entre las distribuciones
Poisson y la Gamma. En la ecuacion (2–11) se presenta la funcion de log-verosimilitud para
este modelo de regresion.
log L(β; y, θ) =n∑i=1
{yi log
(θ exp(x′iβ)
1 + θ exp(x′iβ)
)−(
1
θ
)log (1 + θ exp(x′iβ)) +
log Γ
(yi +
1
θ
)− log Γ(yi + 1)− log Γ
(1
θ
)} (2–11)
Este modelo de regresion ha sido implementado como una alternativa en la modelacion de
datos de conteo ya que ajusta correctamente conjuntos de datos con OD, sin embargo, su
desempeno es inadecuado especialmente para datos donde la varianza es menor que la media
(cuando hay UD). Por eso, es necesario la generacion de nuevas propuestas que permitan
abarcar un rango mas amplio de niveles de dispersion [32].
Page 30
10 2 Marco teorico
2.4.2. Modelo Poisson Generalizado Restringido (PGR)
La regresion PGR fue propuesta por Famoye en 1993 [8], es un modelo que pertenece a la
familia exponencial, que ajusta tanto datos con OD como con UD, aunque esta ultima en
un grado menor [32]. La fmp esta dada por la ecuacion (2–12).
P (Yi = yi|µi, α) =
(µi
1 + αµi
)yi (1 + αyi)yi−1
yi!exp
(−µi(1 + αyi)
1 + αµi
), y = 0, 1, 2, . . . (2–12)
Donde log µi = β′Xi, µi y α son la media y el parametro de dispersion de la distribucion.
De acuerdo con Famoye [8], se le denomina como un modelo restringido debido a que el
parametro de dispersion α es limitado para los intervalos 1 +αµi > 0 y 1 +αyi > 0. Cuando
el parametro α = 0, el modelo pasa a ser un modelo Poisson, cuando α > 0 indica que hay
OD y cuando esta entre −2µi
y cero indica que hay UD.
Debido a que el modelo posee cierta limitacion en el ajuste de datos con UD, no es comple-
tamente flexible y computacionalmente eficiente para ser aplicado en los datos de conteo [32].
2.4.3. Modelo Poisson Doble (PD)
La distribucion Poisson Doble (PD) fue propuesta por Efron [7]. La ecuacion (2–13) muestra
su fmp.
f(y, λ, θ) = c(λ, θ)√θ exp(−θλ) exp(−y)
yy
y!
(eλ
y
)θy, y = 0, 1, 2, . . . (2–13)
Donde1
c(λ, θ)≈ 1 +
1− θ12λθ
(1 +
1
λθ
), siendo c(λ, θ) la constante de normalizacion [38].
Segun Winkelmann [35], esta distribucion tiene dos parametros (λ, θ). El parametro λ se
puede aproximar a la media de la distribucion, mientras que θ define el nivel de dispersion,
cuando es menor que 1 hay OD, cuando es mayor que 1 hay UD y cuando es igual a 1 la
distribucion se convierte en Poisson [38]. Su gran desventaja es que tanto la media como
la varianza no tienen formas cerradas y solo se pueden calcular por medio de las siguientes
aproximaciones:
E(Y ) ≈ λ V ar(Y ) ≈ λ
θ(2–14)
Page 31
2.4 Modelos alternativos 11
2.4.4. Modelo hyper-Poisson (hP)
La distribucion propuesta por Bradwell y Crow en 1964, tambien es denominada como hyper-
Poisson debido a los rasgos similares con una serie hipergeometrica [30]. En la ecuacion (2–15)
se define su fmp.
f(y; γ;λ) =1
1F1(1; γ;λ)
λy
(γ)y, y = 0, 1, 2, . . . (2–15)
Donde γ, λ > 0, (a)r = a(a+ 1) · · · (a+ r− 1) =Γ (a+ r)
Γ (a)para a > 0 y r un entero positivo
y la ecuacion (2–16) es el rasgo de que coincide con la serie hipergeometrica.
1F1(a; c; z) =∞∑r=0
(a)r(c)r
zr
r!(2–16)
Las expresiones tanto de la media como de la varianza para esta distribucion son dadas en
las ecuaciones (2–17) y (2–18), respectivamente [30].
E(Y ) = λ− (γ − 1)1F1(1; γ;λ)− 1
1F1(1; γ;λ)(2–17)
V ar(Y ) = λ+ (λ− (γ − 1)) µ− µ2 (2–18)
El parametro de forma para esta distribucion es γ, el cual define el nivel de dispersion. Si
γ = 1 la distribucion se convierte en Poisson, si γ > 1 se define OD y si γ < 1 se determina
UD [30]. La estimacion de los parametros del modelo se realiza maximizando la funcion de
log-verosimilitud (Ecuacion (2–19)).
log L (γ, λ|y) = −n∑
1=1
log Γ (γ + yi) + log(λ)ny + n(
log(y)− log(
1F1(1; γ;λ)))
(2–19)
Segun Saez y Conde [30], esta distribucion es flexible a la hora de capturar OD y UD, lo que
la establece como una alternativa para modelar datos de conteo. Tambien es de notar que las
expresiones de la media y la varianza son explıcitas y no aproximadas tal como se da en la dis-
tribucion CMP. Al parecer provee estimaciones de mejor calidad que las demas alternativas
propuestas a pesar de que demanda un gran esfuerzo computacional para ajustar los modelos.
Page 32
12 2 Marco teorico
2.5. Estado del arte
Winkelmann & Zimmermann [36] presentan una caracterizacion de los metodos mas recientes
de la epoca para modelar datos de conteo. Luego Cameron & Trivedi [4] publican la teorıa
de los analisis de regresion para los datos de conteo. El modelo Poisson, el BN, el modelo
cero Poisson y el Poisson truncado hacen parte de una recopilacion teorica y de aplicaciones
en cuanto a los datos de conteo se refiere. Actualmente, se han generado propuestas con el
fin de obtener un modelo que explique correctamente tanto bajo OD como UD [32].
Luego Shmueli et al. [34] retomaron la distribucion CMP originalmente propuesta por Con-
way & Maxwell en 1962, y determinaron sus propiedades distribucionales. Mas tarde, Sellers
& Shmueli [32] dan a conocer las propiedades inferenciales como modelo de regresion. Geedi-
pally [10] y Guikema & Goffelt [13] contribuyen a la especializacion del modelo, modificando
el modelo de regresion, caracterizando su desempeno a nivel predictivo y estableciendolo
dentro del marco de los MLG y por lo tanto, es denominado como el modelo CMP MLG.
Luego han venido una serie de estudios en los cuales se han evaluado las propiedades in-
ferenciales del modelo CMP, en especial de la version reparametrizada, teniendo en cuenta
diversos escenarios que van desde la variacion de los metodos de estimacion de los parame-
tros, los diferentes niveles de dispersion, las medias y tamanos muestrales. A continuacion se
presentan una serie de investigaciones que se han desarrollado a partir de este nuevo modelo.
Geedipally et al. [11] caracterizan el desempeno del MLG con respuesta CMP, en donde
se estiman los parametros del modelo mediante el metodo bayesiano de simulacion Monte
Carlo por cadenas de Markov (MCMC). El objetivo de este estudio fue caracterizar me-
diante simulaciones los parametros en cuanto a su precision en la estimacion, y estimar la
carga computacional al implementar este metodo de estimacion. Este estudio demostro que
los parametros estimados por MCMC son precisos y que la carga computacional para su
estimacion no es restrictiva.
Despues Jowaheer et al. [16] estiman los efectos del modelo CMP MLG (modelo reparame-
trizado) mediante simulaciones. Ellos comparan los metodos de estimacion de parametros de
maxima verosimilitud (EMV) y de cuasiverosimilitud (ECV) en cuanto a su desempeno y
eficiencia. Determinaron que la perdida de eficiencia en la estimacion de los parametros es
bastante insignificante y que las estimaciones de ECV son consistentes y casi tan eficientes
como los de EMV. Luego Lord et al. [18] evaluan el comportamiento del MLG con respuesta
CMP, por medio de una aplicacion en donde los datos de accidentes automovilısticos tienen
UD. Este estudio se enfoco en evaluar el desempeno de este modelo en una caso donde hay
UD. Los resultados que se obtuvieron demostraron que el modelo CMP MLG, puede mo-
delar datos donde la varianza es menor que la media y que el desempeno es mucho mejor
comparado con el de modelos tradicionales, al menos con esa base de datos.
Page 33
2.5 Estado del arte 13
Dentro del contexto de datos con censura pero aplicados a la modelacion de datos de conteo,
Sellers & Shmueli [33] evaluan por medio de diferentes medidas de calidad en las predicciones
algunas distribuciones caracterısticas, entre ellas, la alternativa como modelo de regresion
que los mismos autores han propuesto. Se trata de la distribucion CMP que ha sido adap-
tada dentro de un marco de analisis de datos con censura. Tambien evaluan dos metodos de
prediccion con datos reales y que fueron diagnosticados con censura a derecha y en UD. Los
resultados de este estudio determinaron que en un nivel alto de censura, el desempeno del
modelo Poisson estuvo por debajo de las demas alternativas comparadas, produciendo valo-
res ajustados muy altos. Mientras que las distribuciones CMP y PD obtuvieron desempenos
muy similares en terminos de comportamiento predictivo [33].
Zou et al. [39] comparan las distribuciones CMP y la PD por medio de simulaciones en diver-
sos escenarios variando la media muestral y el nivel de dispersion. El objetivo principal del
estudio fue determinar el potencial de la distribucion PD para explicar correctamente datos
con OD y UD. Al evaluar el desempeno entre cada modelo, se obtuvo un mejor comporta-
miento en el modelo CMP, con diferencias importantes en el ajuste estadıstico de datos con
UD.
Y por ultimo, Francis et al. [9] caracterizan el desempeno del MLG con respuesta CMP. Esti-
mando los parametros por EMV, y mediante simulaciones en escenarios con diferentes niveles
de dispersion y medias muestrales, se caracteriza la precision de los parametros estimados
y se evalua el comportamiento en las predicciones. El estudio demostro que los parametros
estimados por EMV son precisos y que este modelo tiene un buen desempeno a traves de los
diferentes escenarios.
Page 34
3. Metodologıa
En este capıtulo se describen los procedimientos que se realizaron durante la investigacion
para responder a las preguntas planteadas en el Capıtulo 1. Ademas de la informacion pro-
cedimental, se presenta una justificacion del por que se opto por un metodo o medida en
especıfico.
3.1. Programacion y analisis estadıstico
Se uso R project [27, R Core Team 2016], un paquete computacional con enfoque estadıstico
de caracter libre y gratuito, para implementar los codigos de las simulaciones y obtener los
resultados estadısticos que seran objeto de analisis dentro de la investigacion. Estos fueron
los paquetes que se utilizaron dentro del entorno de programacion y analisis:
COMPoissonReg [31]: Para ajustar y analizar modelos CMP.
CompGLM [26]: Para ajustar y analizar modelos CMP.
compoisson [6]: Para generar conteos a partir de una distribucion CMP.
VGAM [37]: Para ajustar y analizar modelos BN.
Todas las simulaciones se realizaron en un computador con procesador Intelr CoreTM i5-
2430M con velocidad de 2.4 Ghz, con capacidad de memoria RAM de 6 GB y con el sistema
operativo Microsoftr WindowsTM 7 Ultimate de arquitectura de 64 bits.
3.2. Simulacion de datos
La simulacion de datos consistio en la generacion de pseudovalores aleatorios a partir de una
distribucion probabilıstica especificando sus respectivos parametros y el tamano (n) deseado
para la muestra aleatoria.
Page 35
3.2 Simulacion de datos 15
Una muestra aleatoria esta constituida de una variable respuesta o de conteo y dos variables
predictoras generadas a partir de una distribucion uniforme. Segun Mooney [23], la distri-
bucion uniforme en su forma estandar (U [0, 1]) es el componente de construccion de una
simulacion Monte Carlo. De acuerdo a lo anterior y teniendo en cuenta el metodo usado por
Francis et al. [9], las covariables fueron generadas por medio de una distribucion uniforme
(x1 ∼ U [0, 1] y x2 ∼ U [0, 1]) las cuales se caracterizan por ser ortogonales.
3.2.1. Seleccion de coeficientes asumidos para el vector β
Antes de la simulacion de las variables de conteo, se realizaron simulaciones previas con dife-
rentes combinaciones de coeficientes asumidos teniendo en cuenta informacion literaria sobre
trabajos de simulacion previos. Por ejemplo, Francis et al. [9] hacen variar el intercepto y se
dejan constante los coeficientes asociados a las predictoras y ası determinar diferentes niveles
de media muestral. Winkelmann [35], en el estudio de simulacion sobre la distribucion de los
estimadores Poisson por MLG, define como vector coeficientes asumidos β = (−1, 1) para
generar los conteos Poisson. En resumen, para definir los coeficientes asumidos, especialmen-
te de los predictores, se tuvo en cuenta un rango entre -1 y 1, luego de evaluar los sesgos, la
significancia de los coeficientes estimados, y teniendo en cuenta la variacion del intercepto,
se selecciono una combinacion de valores asumidos para el vector β.
3.2.2. Simulacion de conteos
La variable respuesta fue determinada por conteos provenientes de una distribucion Poisson
(Y ∼ Poisson(λ)) en el caso de ED, mientras que para OD y UD los conteos se origina-
ron mediante una distribucion CMP (Y ∼ CMP (λ, ν)). Usando la ecuacion (3–1) y con
coeficientes asumidos para el vector β se obtuvo el vector λ el cual es el parametro de cen-
tralizacion de la distribucion Poisson.
ln(λi) = β0 +
p∑j=1
βjxij = xiβ (3–1)
Para la simulacion de conteos en ED, se implemento la funcion rpois especificando el tama-
no muestral deseado y el vector λ obtenido mediante la ecuacion (3–1). Para los escenarios
de OD y UD, se utilizo la funcion rcom del paquete compoisson, definiendo el nivel de
dispersion (ν) deseado y por medio de un bucle se realizo la simulacion de los valores del
vector λ hasta obtener el tamano muestral requerido (Ver detalles de la funcion rcom en [26]).
Page 36
16 3 Metodologıa
3.2.3. Niveles de dispersion
Basado en los trabajos de Francis et al. [9], Jowaheer et al. [16] y Zou et al. [39], se definie-
ron tres niveles de dispersion como escenarios para evaluar la calidad de las predicciones de
los modelos en estudio. En la distribucion CMP, el parametro ν define cual es el nivel de
dispersion. Si ν = 1 hay ED, si ν < 1 hay OD y si ν > 1 hay UD [32].
Dichos trabajos relacionados reportan el uso de diferentes intensidades en la dispersion en
los escenarios de OD y UD. Uno de ellos es el de Zou et al. [39], en donde se compara el
modelo CMP con el PD con una OD intermedia (ν = 0.5) y una UD con parametro de forma
definido ν = 1.3. Jowaheer et al. [16] evaluan dos metodos de estimacion para el modelo
CMP en varios niveles de dispersion. Para OD se determinaron niveles de ν entre 0.5 y 0.85
y para UD niveles de ν de 1.5 y 2. Francis et al. [9] tomaron en cuenta dos intensidades
tanto para OD como para UD; valores entre 0.27 y 0.67 fueron definidos para caracterizar
los escenarios en OD y entre 2.72 y 3.32 para los de UD.
Para abarcar mas niveles de dispersion dentro de la investigacion y evaluar el comportamien-
to de los modelos en casos mas extremos, se configuraron para los escenarios de OD niveles
entre 0.25 y 0.75 y para los de UD niveles entre 1.5 y 5.
3.2.4. Tamano muestral (n)
De acuerdo con Sellers & Shmueli [32] y Miller [21], la normalidad asintotica de la estimacio-
nes no se puede asegurar en pequenos tamanos muestrales. Teniendo en cuenta la anterior
afirmacion, ademas de los problemas de convergencia en el ajuste de los modelos y la deman-
da computacional al variar n, se definio un nivel constante de este factor para diagnosticar
su influencia en el comportamiento predictivo. Sellers & Shmueli [32] proponen realizar un
bootstrap parametrico para estimar la distribucion de los coeficientes en una regresion CMP
y ası obtener una base inferencial mas solida cuando n es pequeno. Sin embargo, es indis-
pensable definir a partir de que nivel de tamano muestral se empiezan a lograr estimaciones
razonables y ası definir si usar el metodo propuesto por Sellers & Shmueli [32], que de alguna
forma es mas demandante computacionalmente, o analizar el modelo ajustado directamente.
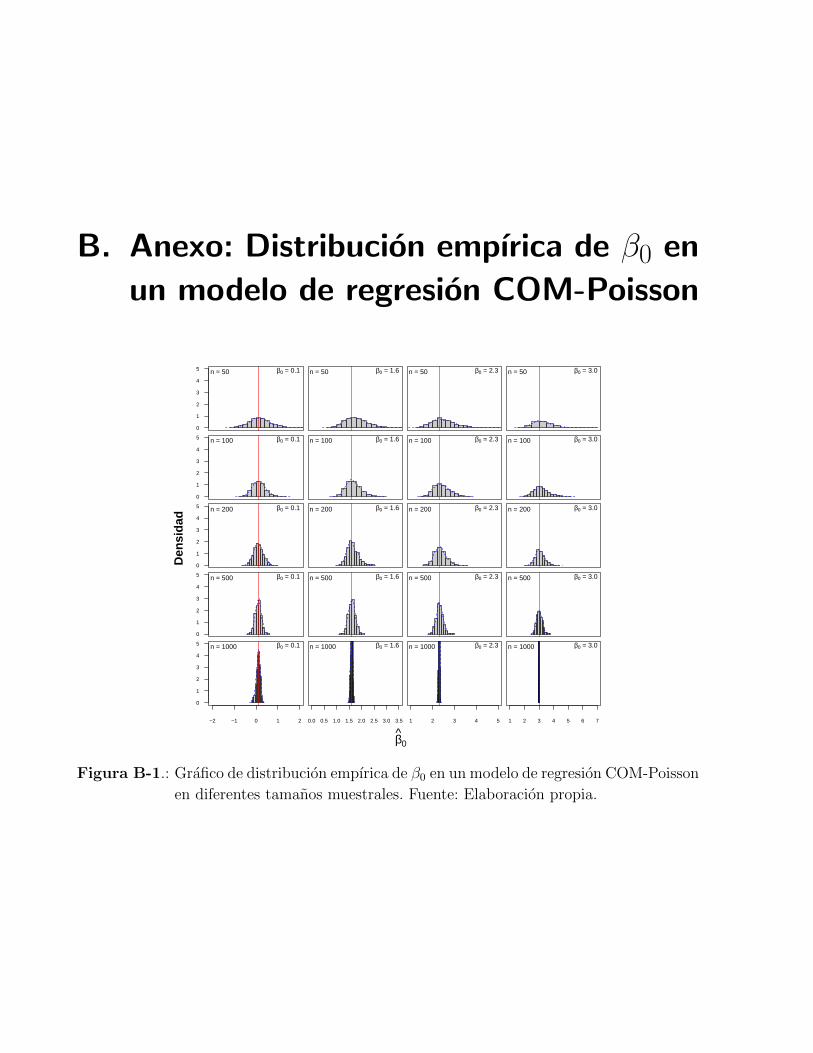
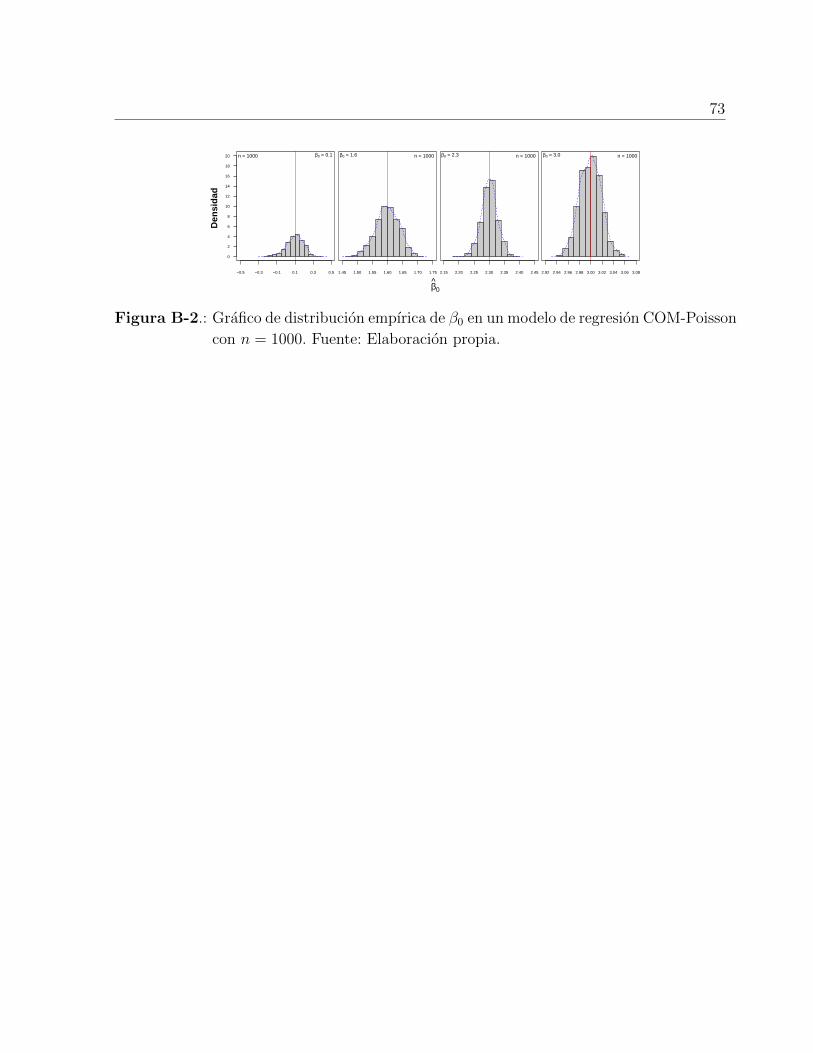
A manera de simulacion previa se determino la distribucion empırica del coeficiente β0 en
un modelo CMP. En el Anexo B, se puede notar en la Figura B-1 que en pequenos tamanos
muestrales la distribucion del coeficiente evaluado tiene una forma asimetrica y que a medi-
da que va incrementando n la asimetrıa tiende a centralizarse, es decir, que los coeficientes
estimados son menos sesgados, en especial cuando el tamano muestral es de 1000 (Figura B-
2). Por lo tanto, para comparar los modelos en terminos de calidad de las predicciones y
la eficiencia relativa se determino un tamano muestral de 1000 observaciones, el cual es el
Page 37
3.3 Procedimiento de las simulaciones 17
tamano muestral usado por los trabajos de Francis et al. [9] y Winkelmann [35].
3.3. Procedimiento de las simulaciones
Luego de generar la muestra aleatoria, a esta se le ajustaron los modelos de regresion y se
obtuvieron diferentes medidas estadısticas para las estimaciones logradas. Este proceso fue
replicado un numero de veces determinado (nsim) segun la demanda computacional y el
objeto de estudio.
3.3.1. Numero de simulaciones (nsim)
Segun Bonate [2], la definicion del numero replicaciones puede afectar la precision de las
estimaciones o la demanda y rendimiento computacional del estudio de simulacion. Mooney
[23] enuncia que definir “muchas” replicas es la mejor practica para definir el numero de
simulaciones en un experimento, sin embargo, un numero excesivo de replicas implicarıa una
demanda computacional muy alta.
Para evaluar la influencia del nivel de dispersion sobre la calidad de las predicciones y la
eficiencia relativa de los modelos se utilizo un nsim de 1000, ya que ademas de ser un numero
estandar es el implementado por Jowaheer et al. [16] y Winkelmann [35] en sus simulacio-
nes. Para comparar las funciones glm.comp y cmp se utilizo un numero de simulaciones de
100 ya que el proceso de optimizacion usado por la funcion cmp es considerablemente mas
demandante a nivel computacional que el de la funcion glm.comp (Capıtulo 4).
3.3.2. Algoritmo para las simulaciones
Para lograr las respuestas a las preguntas planteadas para la investigacion se diseno un pro-
tocolo de simulacion el cual esta descrito a partir de una serie de procedimientos secuenciales.
En resumen, los metodos implementados en las simulaciones se reducen en un algoritmo de
programacion, el cual fue interpretado en un lenguaje de codigo, en este caso R [27, R Core
Team 2016]. La siguiente lista describe brevemente las diferentes operaciones desarrolladas
secuencialmente para cada uno de los escenarios configurados por la combinacion de los di-
ferentes niveles de los factores involucrados en cada estudio de caso.
1. Generar covariables fijas y ortogonales x1 y x2 con un n definido a partir de una dis-
tribucion uniforme de 0 a 1.
Page 38
18 3 Metodologıa
x1 ∼ U(0, 1) y x2 ∼ U(0, 1)
2. Generar variable de conteo con un tamano n de una distribucion Poisson para ED o
de una distribucion CMP para OD y UD.
Yi ∼ Poisson(λ) , para ED
Yi ∼ CMP (λ, ν) , para OD y UD
3. Ajustar modelos Poisson y CMP al conjunto de datos generado. En OD, ajustar modelo
BN; y en ED y UD, ajustar modelo PGR .
4. Almacenar coeficientes estimados y calcular medidas estadısticas (Seccion 3.4).
5. Repetir los pasos del 1 al 4 hasta nsim.
3.3.3. Modelos ajustados
A cada conjunto de datos se le ajustaron diferentes modelos de regresion los cuales fueron
seleccionados segun su capacidad para modelar datos en un nivel de dispersion dado. Por
eso en OD, ademas de comparar los modelos Poisson y CMP se anadio un modelo caracte-
rıstico para ajustar este tipo de datos como lo es el modelo BN. En ED y UD los modelos
fueron contrastados con el modelo PGR. A continuacion se presentan las caracterısticas que
se tomaron en cuenta para llevar a cabo el ajuste de cada modelo.
Modelo Poisson
El modelo Poisson fue ajustado usando la funcion generica glm especificando el modelo, los
datos de la muestra aleatoria generada y la familia Poisson con funcion de enlace log. Esta
funcion utiliza el metodo de Mınimos Cuadrados Reponderados Iterativamente (MCRI) para
obtener las estimaciones de los coeficientes del modelo.
Modelo CMP
En el Capıtulo 4 se comparan dos implementaciones en R para ajustar modelos CMP. La
funcion glm.comp del paquete CompGLM [26] y la funcion cmp del paquete COMPoisson-
Reg [31]. Con base al contraste entre estas dos funciones se definio la implementacion mas
adecuada para usar en los demas estudios de caso. Ademas de especificar el modelo y los
Page 39
3.3 Procedimiento de las simulaciones 19
datos de la muestra aleatoria, se debe especificar el lımite de la sumatoria en la constan-
te de normalizacion (Ecuacion (3–2)), por defecto este lımite es de 100 para las dos funciones.
Z(λ, ν) =∞∑j=0
λj
(j!)ν≈
100∑j=0
λj
(j!)ν(3–2)
Cuando Yi+10 > 100, es necesario ajustar este lımite, de lo contrario el modelo no podra ser
ajustado cuando se usa la funcion glm.comp. Para evitar que se termine el proceso de ajuste
del modelo, se elimino esta restriccion ya que especialmente en el caso donde se especifica
un nivel de λ alto a un mayor nivel de OD, se obtienen conteos que superan ese lımite, aun
ajustandolo a un valor de 150.
En cuanto a los valores iniciales asignados para el proceso de optimizacion, estas dos imple-
mentaciones ajustan en primera instancia el modelo Poisson y luego utilizan los coeficientes
estimados de esa regresion como valores iniciales para el vector β.
Sellers & Shmueli [32] proponen dos metodos de estimacion para obtener las predicciones.
El metodo de estimacion de medias que se basa en el calculo de la media condicional la cual
esta en funcion de λ y ν (Ecuacion (3–3)). El metodo de estimacion de medianas consiste en
el calculo de probabilidades consecutivas por medio de la ecuacion (3–4) hasta que la suma
supere el valor de 0.5 [33].
yi|xi = λ1/νi −
ν − 1
2ν(3–3)
P (Yi = yi) =
(λiyi
)νP (Yi = yi − 1) (3–4)
Aunque Sellers & Shmueli [33] senalan que el metodo de prediccion de medianas tiene ven-
tajas en cuanto a que predice valores enteros y que la mediana es una medida de tendencia
central mas robusta en distribuciones sesgadas, no es claro si es mas adecuada o no en termi-
nos del comportamiento predictivo, especialmente en el escenario de UD donde de acuerdo
con Minka et al. [22] la aproximacion a la media no es tan exacta. Para evaluar cual de los
metodos es mas adecuado se compararon las predicciones obtenidas en los diferentes escena-
rios configurados en terminos de la calidad predictiva.
Page 40
20 3 Metodologıa
Modelo BN
Para el ajuste del modelo BN se utilizo la funcion vglm del paquete VGAM [37]. Luego de
definir la formula y los datos dentro de la funcion, se especifico la familia “negbinomial” y
como control del proceso de iteracion un numero maximo de 10000 para aumentar la proba-
bilidad de convergencia. Tambien se suministraron los coeficientes estimados de la regresion
Poisson como valores iniciales para el vector β y para el parametro de dispersion θ se asigno
un valor de 0.
Modelo PGR
Las estimaciones de este modelo fueron obtenidas utilizando las funciones definidas por Se-
llers & Shmueli [32], quienes usaron este modelo para comparar su propuesta en un escenario
de UD por medio de una aplicacion con datos reales. Lastimosamente, en dichas aplicaciones
este modelo no logro convergencia en el proceso de estimacion de los parametros debido a
que este captura parcialmente algunos niveles de UD. De aquı surge la necesidad de evaluar
el comportamiento de este modelo, especialmente en los escenarios donde la media excede la
varianza. La definicion de la funcion consiste en un proceso de optimizacion no restringida
a traves de la funcion nlminb en la que se definio en primera instancia la funcion negativa
de log-verosimilitud que fue objeto de minimizacion. Al igual que en el modelo BN tambien
se asignaron los mismos valores iniciales tanto para el vector β como para el parametro de
dispersion en este caso identificado como α.
3.4. Calculo de medidas estadısticas
Luego de obtener las estimaciones para cada modelo y en cada conjunto de datos generado
se determinaron una serie de medidas estadısticas para caracterizar el comportamiento pre-
dictivo en los diferentes escenarios planteados anteriormente. Estas fueron las medidas que
se tomaron en cuenta:
3.4.1. Sesgo de los coeficientes estimados
El sesgo de los coeficientes estimados se calculo siguiendo la metodologıa de Francis et al.
[9] mediante la ecuacion (3–5).
Sesgoφ = E(φ)− φ (3–5)
Page 41
3.4 Calculo de medidas estadısticas 21
Donde:
φ : Coeficiente verdadero o asumido.
φ : Coeficiente estimado.
3.4.2. Intervalos de confianza (IC) para los coeficientes de los
modelos
Se obtuvieron los intervalos de confianza tipo Wald (que asumen normalidad asintotica) de
los coeficientes de regresion y los parametros de dispersion que aplica para cada tipo de mo-
delo (Ecuacion (3–6)), para determinar la proporcion de parametros verdaderos contenidos
dentro de ellos.
φ± z(1−α/2)ESφ (3–6)
Donde:
ES es el Error Estandar asociado al coeficiente estimado (φ).
3.4.3. Raız Cuadrada del Error Cuadratico Medio (RECM)
Esta medida de calidad de los estimadores se obtuvo mediante el calculo del Error Cuadra-
tico Medio (ECM) por medio de la ecuacion (3–7).
RECMφ =
√√√√ 1
N
N∑i=1
(φi − φ)2 (3–7)
Donde:
φ : Valor verdadero o asumido.
φ : Coeficiente estimado.
N : Numero de coeficientes estimados hasta nsim.
Page 42
22 3 Metodologıa
3.4.4. Raız Cuadrada del Error Cuadratico Medio de Prediccion
(RECMP)
Esta medida de calidad predictiva se obtuvo mediante el calculo del Error Cuadratico Medio
de Prediccion (ECMP) por medio de la ecuacion (3–8). Es implementada por Lord et al. [19]
y Sellers & Shmueli [33] para evaluar el comportamiento de las predicciones de los modelos
comparados.
RECMP =
√√√√ 1
n
n∑i=1
(yi − yi)2 (3–8)
Donde:
y : Respuesta observada.
y : Valor ajustado o predicho.
n : Numero de observaciones o tamano muestral.
3.5. Eficiencia Relativa (ER)
Obenido el ECM y el ECMP se calculo la Eficiencia Relativa (ER) tanto de los estimadores
de parametros de cada modelo como de sus respectivas predicciones utilizando las ecuaciones
(3–9) y (3–10).
ER(φ1,φ2)=ECMφ2
ECMφ1
(3–9)
ER(Y1,Y2)=ECMPY2ECMPY1
(3–10)
A manera de interpretacion, si ER > 1, entonces, φ1 es mas eficiente que φ2. La interpretacion
es similar pero dentro del contexto donde se comparan las predicciones entre dos modelos.
Con esta medida se establece un criterio para evaluar si se pierde o no calidad en las predic-
ciones al ajustar un modelo equivocado respecto al modelo adecuado o alternativo.
Page 43
3.6 Mediana del Error Porcentual Absoluto (EPAMe) 23
3.6. Mediana del Error Porcentual Absoluto (EPAMe)
Esta medida es aplicada en el Capıtulo 7 como un metodo complementario para evaluar la
calidad de las predicciones. Ademas es una medida adecuada para datos de conteo ya que
evita posibles indeterminaciones en el caso de la existencia de ceros [1]. Su calculo consiste en
obtener la mediana de los errores porcentuales absolutos (EPA) los cuales se pueden lograr
mediante la ecuacion (3–11).
EPAi =
∣∣∣∣ yi − yiyi
∣∣∣∣ (3–11)
Esta medida es implementada por Sellers & Shmueli [33] para evaluar el desempeno de las
predicciones de varias distribuciones en datos de conteo censurados.
3.7. Calculo de medida de bondad de ajuste
Se decidio incluir una medida de bondad de ajuste ya que proporciona un criterio de com-
paracion entre los modelos en terminos de que tan bueno es el ajuste del modelo al conjunto
de observaciones. La medida implementada fue el Criterio de Informacion de Akaike (CIA),
obtenida mediante la ecuacion (3–12). Tambien se utilizo el CIAc el cual es una correccion
del CIA cuando el tamano muestral es pequeno [15] (Ecuacion (3–13)).
CIA = 2p− 2 logLik (3–12)
CIAc = CIA+2p(p+ 1)
n− p− 1(3–13)
Donde:
p : Numero de parametros del modelo.
n : Tamano muestral.
logLik : Valor maximo de la funcion de log-verosimilitud para el modelo estimado.
Page 44
24 3 Metodologıa
A pesar de que no es una medida que evalua el comportamiento a nivel predictivo, esta fue
incorporada a manera de complemento en la investigacion para evaluar si el modelo CMP
podrıa tener ventajas a la hora de explicar la relacion funcional entre una variable respuesta
de conteo y su(s) predictora(s).
Page 45
4. Comparacion de las funciones
glm.comp y cmp
En este capıtulo se efectua un contraste entre las caracterısticas, las estimaciones y las pre-
dicciones logradas entre dos implementaciones para ajustar modelos CMP en el paquete
estadıstico R [27, R Core Team 2016]. El objetivo de esta comparacion es seleccionar la
implementacion mas adecuada para llevar a cabo los ajustes de los modelos CMP en las
diferentes simulaciones que demande la investigacion. Tambien se describen algunas de las
diferencias encontradas en cuanto al uso y resultados logrados por dichas funciones. Ademas
de esta comparacion, se realizo una caracterizacion del desempeno del modelo CMP evaluan-
do la calidad de los coeficientes estimados y la calidad predictiva.
Este capıtulo tiene la siguiente organizacion. La Seccion 4.1 describe como se configuraron
las simulaciones efectuadas. En la Seccion 4.2 se presentan los resultados obtenidos tanto en
la caracterizacion del desempeno de las estimaciones como en el comportamiento predictivo.
Esos resultados son posteriormente analizados y discutidos en la Seccion 4.3. Y en la Sec-
cion 4.4 se definieron los casos donde se utilizaran las implementaciones y demas conclusiones
relevantes que arrojo el estudio.
4.1. Metodologıa
En esta seccion se presenta de forma detallada los procedimientos que se realizaron para
lograr los objetivos planteados para este capıtulo. Se describe el proceso de las simulaciones
en los diferentes escenarios configurados por el tamano muestral y el nivel de dispersion para
diferentes modelos asumidos variando β0 y dejando constantes los coeficientes asociados a
las variables predictoras.
4.1.1. Descripcion de la simulacion
Un estudio de simulacion fue llevado a cabo para determinar la precision de las estimaciones
y el desempeno predictivo del modelo CMP de acuerdo a dos implementaciones en R dadas
Page 46
26 4 Comparacion de las funciones glm.comp y cmp
por la funcion glm.comp del paquete CompGLM [26] y la funcion cmp del paquete COM-
PoissonReg [31]. Para ello se generaron 100 conjuntos de datos (tal como se describio en la
Seccion 3.2) para cada uno de los escenarios conformados por los niveles de n (25, 50, 100,
200 y 500), en diferentes categorıas de dispersion (OD, ED y UD). En cada uno de estos
escenarios se generaron los diferentes conjuntos de datos asumiendo diferentes modelos en
donde el coeficiente verdadero β0 fue variando mientras que los coeficientes asumidos asocia-
dos a las variables predictoras se dejaron fijos. A estos conjuntos de datos se les ajustaron
los modelos CMP usando las dos funciones de R que son objeto de comparacion. Luego se
almacenaron las estimaciones y se calcularon las diferentes medidas descritas en el Capıtulo
3. La Tabla 4-1 muestra los coeficientes asumidos para generar los datos para cada uno de
los escenarios.
Tabla 4-1.: Coeficientes asumidos para el estudio de simulacion de comparacion de las fun-
ciones glm.comp y cmp. Fuente: Elaboracion propia.
OD ED UD
m1 m2 m3 m4 m1 m2 m3 m4 m1 m2 m3 m4
β0 -0.50 0.30 0.50 0.70 0.10 1.60 2.30 3.00 2.00 8.50 12.00 15.00
β1 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50
β2 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50
ν 0.25 0.25 0.25 0.25 1.00 1.00 1.00 1.00 5.00 5.00 5.00 5.00
Tal como se ve en la Tabla 4-1 y de acuerdo con lo expuesto en Subseccion 3.2.1, en los
diferentes modelos asumidos (m1, m2, m3, m4) el coeficiente verdadero para β0 es diferente
mientras que para β1 y β2 fueron constantes. Con el fin de evaluar las dos funciones de R
(glm.comp y cmp) en escenarios de dispersion altos, se definieron los parametros de dispersion
asumidos; un valor de ν de 0.25 que indica una alta OD, un valor para ν de 5 para alta UD
y un valor para ν de 1 para ED.
4.1.2. Deteccion de diferencias
En el proceso de ajuste y analisis convencional de un modelo de regresion CMP se compa-
raron los resultados obtenidos por cada una de las dos funciones de R para examinar que
tan parecidos son los diferentes valores estadısticos. Ademas, se revisaron los codigos y la
documentacion disponible para cada una de las implementaciones.
Page 47
4.2 Resultados 27
4.2. Resultados
Efectuadas las simulaciones se obtuvieron las diferentes medidas estadısticas, las cuales se
presentan graficamente y cuantitativamente en esta seccion. Vale la pena aclarar que en OD
no se tuvieron en cuenta algunos casos en donde se presentaron subestimaciones atıpicas del
parametro de forma ν (Seccion 4.3).
4.2.1. Calidad de las estimaciones
El desempeno del modelo CMP en diferentes escenarios de dispersion presento comporta-
mientos contrastantes entre las dos implementaciones. Estas son las diferencias mas relevantes
que se presentaron para los coeficientes estimados tanto del vector β, como del parametro
de dispersion.
Calidad de las estimaciones en OD
El coeficiente de β0 en el escenario de OD presento comportamientos similares en los tres
primeros modelos asumidos. En el modelo m4 se detectaron las diferencias mas notorias,
especialmente cuando el tamano muestral fue mınimo. La Figura 4-1 muestra con mas de-
talle tal diferencia al observar la ER, en donde dicha medida fluctua entre un rango de 0.4
a 1.3 a traves de tamanos muestrales menores a 200, luego de este nivel de observaciones el
comportamiento tiende a igualarse. En los demas modelos asumidos la ER es constante, lo
que indica que las estimaciones para β0 son muy similares a traves de los escenarios evaluados.
Al evaluar la calidad de las estimaciones para este coeficiente se nota la tendencia a dismi-
nuir la RECM cada vez que aumenta el tamano muestral. En todos los modelos asumidos se
presentaron las estimaciones de menor calidad en tamanos muestrales pequenos, pero carac-
terısticamente el modelo m1 presento los niveles mas bajos de calidad respecto a los demas
modelos, incluso cuando el tamano muestral fue superior a 100.
Comportamientos similares se muestran al observar los desempenos de la RECM y la ER a
traves de los niveles del tamano muestral en cada uno de los modelos asumidos. De nuevo,
en el modelo m4 se presentan las diferencias, pero en contraste de las obtenidas para β0,
estas fluctuan entre niveles de ER que favorecen las estimaciones logradas por la funcion
glm.comp, ya que los valores de eficiencia en la mayorıa de los casos es menor que 1 (Figu-
ra 4-2 y Figura 4-3).
La ER en los modelos asumidos m1, m2 y m3, es muy cercana a 1, por lo tanto, en estos
escenarios las diferencias en las estimaciones de β1 y β2 entre las dos funciones comparadas
son casi imperceptibles.
Page 48
28 4 Comparacion de las funciones glm.comp y cmp
Valores asumidos para β0
RE
CM
β 0
0.0
0.2
0.4
0.6
0.8
1.0 OD − m1
Valores asumidos para β0
RE
CM
β 0
OD − m2
Valores asumidos para β0
RE
CM
β 0
OD − m3
Valores asumidos para β0
RE
CM
β 0
OD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 0
0.4
0.6
0.8
1.0
1.2
1.4
25 50 100 200 500
OD − m1
Valores asumidos para β0
ER
β 0
25 50 100 200 500
OD − m2
Valores asumidos para β0
ER
β 0
25 50 100 200 500
OD − m3
Valores asumidos para β0
ER
β 0
25 50 100 200 500
OD − m4 glm.comp/cmp
RE
CM
β 0
ER
β 0
Tamaño muestral (n)
Figura 4-1.: Calidad del coeficiente estimado β0 en un escenario de OD. Fuente: Elaboracion
propia.
Valores asumidos para β0
RE
CM
β 1
0.0
0.2
0.4
0.6
0.8
1.0 OD − m1
Valores asumidos para β0
RE
CM
β 1
OD − m2
Valores asumidos para β0
RE
CM
β 1
OD − m3
Valores asumidos para β0
RE
CM
β 1
OD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 1
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
25 50 100 200 500
OD − m1
Valores asumidos para β0
ER
β 1
25 50 100 200 500
OD − m2
Valores asumidos para β0
ER
β 1
25 50 100 200 500
OD − m3
Valores asumidos para β0
ER
β 1
25 50 100 200 500
OD − m4 glm.comp/cmp
RE
CM
β 1
ER
β 1
Tamaño muestral (n)
Figura 4-2.: Calidad del coeficiente estimado β1 en un escenario de OD. Fuente: Elaboracion
propia.
La Figura 4-4 muestra que el parametro de dispersion ν presenta comportamientos similares
entre las dos funciones, excepto en el modelo m4 donde la ER varıa entre 0.4 y 1.2 a traves
Page 49
4.2 Resultados 29
Valores asumidos para β0
RE
CM
β 2
0.0
0.2
0.4
0.6
0.8
1.0 OD − m1
Valores asumidos para β0
RE
CM
β 2
OD − m2
Valores asumidos para β0
RE
CM
β 2
OD − m3
Valores asumidos para β0
RE
CM
β 2
OD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 2
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
25 50 100 200 500
OD − m1
Valores asumidos para β0
ER
β 2
25 50 100 200 500
OD − m2
Valores asumidos para β0
ER
β 2
25 50 100 200 500
OD − m3
Valores asumidos para β0
ER
β 2
25 50 100 200 500
OD − m4 glm.comp/cmp
RE
CM
β 2
ER
β 2
Tamaño muestral (n)
Figura 4-3.: Calidad del coeficiente estimado β2 en un escenario de OD. Fuente: Elaboracion
propia.
Valores asumidos para β0
RE
CM
ν
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8 OD − m1
Valores asumidos para β0
RE
CM
ν
OD − m2
Valores asumidos para β0
RE
CM
ν
OD − m3
Valores asumidos para β0
RE
CM
ν
OD − m4 glm.comp cmp
Valores asumidos para β0
ER
ν
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
25 50 100 200 500
OD − m1
Valores asumidos para β0
ER
ν
25 50 100 200 500
OD − m2
Valores asumidos para β0
ER
ν
25 50 100 200 500
OD − m3
Valores asumidos para β0
ER
ν
25 50 100 200 500
OD − m4 glm.comp/cmp
RE
CM
ν E
Rν
Tamaño muestral (n)
Figura 4-4.: Calidad del coeficiente estimado ν en un escenario de OD. Fuente: Elaboracion
propia.
de los niveles del tamano muestral y cuando alcanza las 500 observaciones las diferencias
tienden a ser similares para las dos funciones. En el modelo m1 se obtuvieron los valores
Page 50
30 4 Comparacion de las funciones glm.comp y cmp
Tabla 4-2.: Proporcion de IC al 95 % que contienen los coeficientes verdaderos en un esce-
nario de OD. Fuente: Elaboracion propia.
OD glm.comp cmp
m n β0 β1 β2 ν β0 β1 β2 ν
m1
25 0.95 0.97 0.97 0.96 0.95 0.97 0.97 0.96
50 0.94 0.96 0.97 1.00 0.94 0.96 0.97 1.00
100 0.97 0.97 0.96 0.98 0.97 0.97 0.96 0.98
200 0.93 0.98 0.93 0.99 0.93 0.97 0.93 0.99
500 0.94 0.95 0.93 0.99 0.94 0.95 0.93 0.99
m2
25 0.96 0.98 0.98 0.97 0.96 0.98 0.98 0.97
50 0.98 0.95 0.98 0.98 0.98 0.95 0.98 0.98
100 0.97 0.94 0.94 0.97 0.97 0.94 0.94 0.97
200 0.94 0.99 0.93 0.97 0.94 0.99 0.93 0.97
500 0.99 0.94 0.95 0.94 0.99 0.94 0.95 0.94
m3
25 0.98 0.98 0.97 0.97 0.98 0.98 0.97 0.97
50 0.97 0.97 0.98 0.98 0.97 0.97 0.98 0.98
100 0.96 0.95 0.96 0.95 0.96 0.95 0.96 0.95
200 0.95 0.99 0.94 0.97 0.95 0.99 0.94 0.97
500 0.96 0.95 0.94 0.91 0.96 0.95 0.94 0.91
m4
25 0.97 0.99 0.99 0.99 0.90 0.79 0.76 0.90
50 0.98 0.98 0.99 0.98 0.98 0.98 0.99 0.98
100 0.94 0.96 0.96 0.96 0.96 0.97 0.96 0.96
200 0.97 1.00 0.96 0.97 0.92 0.98 0.96 0.95
500 0.96 0.95 0.93 0.95 0.96 0.95 0.93 0.95
mas bajos de calidad para este coeficiente estimado, si se comparan con los demas modelos
asumidos en cada uno de los niveles de tamano muestral. Al igual que los coeficientes ante-
riores, el parametro ν experimento un comportamiento constante de la ER en cada nivel de
tamano muestral y de los modelos asumidos.
La proporcion de IC que contienen los coeficientes asumidos en cada uno de los modelos,
indica que en general las dos funciones estimaron el verdadero parametro al evaluar los IC
al 95 % de confianza para cada uno de los coeficientes estimados y a traves de los diferentes
tamanos muestrales. Sin embargo, se presentaron dos casos en donde dicha afirmacion no es
tan clara. Esto sucedio en las estimaciones de la funcion cmp, para los coeficientes β1 y β2,
en el modelo m4 y cuando el tamano muestral fue de 25, en donde se obtuvieron los niveles
Page 51
4.2 Resultados 31
de cobertura de los IC mas bajos, con valores menores al 80 % (Tabla 4-2).
Adicionalmente, vale la pena indicar que durante el proceso de simulacion la mayorıa de
los modelos lograron convergencia. Aun ası, los escenarios del modelo m4 en los tamanos
muestrales de 25, 50 y 200 experimentaron entre un 70 % y 82 % de casos de convergencia,
indicando problemas durante el proceso de estimacion como tal, al implementarse la funcion
glm.comp. Mientras que la funcion cmp exhibio eventos de no convergencia menores al obte-
ner un 3 % de casos donde se presentaron problemas en el proceso de estimacion del modelo,
esto se dio en m4 cuando n fue mınimo.
Calidad de las estimaciones en ED
En ED las estimaciones para β0 presentaron diferencias que fueron incrementando a traves de
los modelos asumidos. Estas fueron mas notorias en tamanos muestrales pequenos. Al mirar
la Figura 4-5 se nota que en el modelo m4 las diferencias entre las dos funciones son visibles
en los tamanos muestrales menores a 100, luego de este nivel de observaciones las diferencias
son practicamente imperceptibles. Al examinar la ER, esta indica que las estimaciones para
el coeficiente β0 obtenidas por la funcion glm.comp son de mas calidad respecto a las de la
funcion cmp, especialmente en tamanos muestrales pequenos.
Tal como se esperaba, los comportamientos de la RECM al aumentar el tamano muestral
tuvieron una tendencia a incrementar la calidad de las estimaciones, pero al comparar los
valores obtenidos en cada uno de los modelos asumidos, se logro determinar ligeras diferen-
cias que indican un incremento de la RECM al incrementar el β0 asumido para los modelos.
En el modelo m1 se obtuvieron los valores mas altos de calidad de las estimaciones, mientras
que en los modelos m3 y m4 se exhibieron estimaciones de baja calidad, principalmente en
los tamanos muestrales pequenos.
Comportamientos similares presentan las estimaciones de β1 y β2 (Figura 4-6 y Figura 4-
7). Sin embargo, al evaluar la RECM se detectan unas diferencias leves fundamentalmente
cuando el β0 asumido fue muy bajo, es decir, en el modelo m1. La ER senala que en tamanos
muestrales pequenos, las estimaciones para estos dos coeficientes fueron de mayor calidad en
la funcion glm.comp y que a partir de tamanos muestrales similares o superiores a 100, no
hay diferencias bien marcadas entre estas dos funciones.
Page 52
32 4 Comparacion de las funciones glm.comp y cmp
Valores asumidos para β0
RE
CM
β 0
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8 ED − m1
Valores asumidos para β0
RE
CM
β 0
ED − m2
Valores asumidos para β0
RE
CM
β 0
ED − m3
Valores asumidos para β0
RE
CM
β 0
ED − m4 glm.comp cmp
Valores asumidos para β0
ER
β 0
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
25 50 100 200 500
ED − m1
Valores asumidos para β0
ER
β 0
25 50 100 200 500
ED − m2
Valores asumidos para β0
ER
β 0
25 50 100 200 500
ED − m3
Valores asumidos para β0
ER
β 0
25 50 100 200 500
ED − m4 glm.comp/cmp
RE
CM
β 0
ER
β 0
Tamaño muestral (n)
Figura 4-5.: Calidad del coeficiente estimado β0 en un escenario de ED. Fuente: Elaboracion
propia.
Valores asumidos para β0
RE
CM
β 1
0.0
0.2
0.4
0.6
0.8
1.0 ED − m1
Valores asumidos para β0
RE
CM
β 1
ED − m2
Valores asumidos para β0
RE
CM
β 1
ED − m3
Valores asumidos para β0
RE
CM
β 1
ED − m4 glm.comp cmp
Valores asumidos para β0
ER
β 1
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
25 50 100 200 500
ED − m1
Valores asumidos para β0
ER
β 1
25 50 100 200 500
ED − m2
Valores asumidos para β0
ER
β 1
25 50 100 200 500
ED − m3
Valores asumidos para β0
ER
β 1
25 50 100 200 500
ED − m4 glm.comp/cmp
RE
CM
β 1
ER
β 1
Tamaño muestral (n)
Figura 4-6.: Calidad del coeficiente estimado β1 en un escenario de ED. Fuente: Elaboracion
propia.
Page 53
4.2 Resultados 33
Valores asumidos para β0
RE
CM
β 2
0.0
0.2
0.4
0.6
0.8
1.0 ED − m1
Valores asumidos para β0
RE
CM
β 2
ED − m2
Valores asumidos para β0
RE
CM
β 2
ED − m3
Valores asumidos para β0
RE
CM
β 2
ED − m4 glm.comp cmp
Valores asumidos para β0
ER
β 2
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
25 50 100 200 500
ED − m1
Valores asumidos para β0
ER
β 2
25 50 100 200 500
ED − m2
Valores asumidos para β0
ER
β 2
25 50 100 200 500
ED − m3
Valores asumidos para β0
ER
β 2
25 50 100 200 500
ED − m4 glm.comp/cmp
RE
CM
β 2
ER
β 2
Tamaño muestral (n)
Figura 4-7.: Calidad del coeficiente estimado β2 en un escenario de ED. Fuente: Elaboracion
propia.
Valores asumidos para β0
RE
CM
ν
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8 ED − m1
Valores asumidos para β0
RE
CM
ν
ED − m2
Valores asumidos para β0
RE
CM
ν
ED − m3
Valores asumidos para β0
RE
CM
ν
ED − m4 glm.comp cmp
Valores asumidos para β0
ER
ν
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
25 50 100 200 500
ED − m1
Valores asumidos para β0
ER
ν
25 50 100 200 500
ED − m2
Valores asumidos para β0
ER
ν
25 50 100 200 500
ED − m3
Valores asumidos para β0
ER
ν
25 50 100 200 500
ED − m4 glm.comp/cmp
RE
CM
ν E
Rν
Tamaño muestral (n)
Figura 4-8.: Calidad del coeficiente estimado ν en un escenario de ED. Fuente: Elaboracion
propia.
Page 54
34 4 Comparacion de las funciones glm.comp y cmp
A diferencia de lo expuesto en las estimaciones para β0, la calidad para estos dos coeficientes
tuvo mayores valores cada vez que fue incrementando el β0 asumido, siendo el modelo m4
el que expresa mejor calidad a traves de los niveles del tamano muestral en contraste con
los demas modelos asumidos. En el modelo m1, donde el valor verdadero de β0 fue de 0.1,
se experimentaron magnitudes de la RECM mayores en comparacion con los demas modelos
asumidos en cada uno de los niveles de tamano muestral, senalando una baja calidad en las
estimaciones de β1 y β2.
Tabla 4-3.: Proporcion de IC al 95 % que contienen los coeficientes verdaderos en un esce-
nario de ED. Fuente: Elaboracion propia.
ED glm.comp cmp
m n β0 β1 β2 ν β0 β1 β2 ν
m1
25 0.95 0.96 0.95 0.96 0.95 0.96 0.95 0.96
50 0.92 0.97 0.97 0.95 0.92 0.97 0.97 0.95
100 0.95 0.94 0.97 0.95 0.95 0.94 0.97 0.95
200 0.97 0.99 0.91 0.98 0.97 0.99 0.91 0.98
500 0.98 0.98 0.96 0.95 0.98 0.98 0.96 0.95
m2
25 0.96 0.97 0.95 0.98 0.96 0.97 0.95 0.98
50 0.97 0.98 0.97 0.97 0.97 0.98 0.97 0.98
100 0.96 0.96 0.96 0.94 0.96 0.96 0.96 0.94
200 0.97 1.00 0.92 0.95 0.97 1.00 0.92 0.95
500 0.95 0.97 0.95 0.95 0.95 0.97 0.95 0.95
m3
25 0.99 0.95 0.96 0.99 0.98 0.94 0.95 0.99
50 0.94 0.93 0.95 0.93 0.94 0.93 0.95 0.93
100 0.98 0.96 0.92 0.94 0.98 0.96 0.92 0.94
200 0.94 0.98 0.97 0.95 0.94 0.98 0.97 0.95
500 0.96 0.96 0.99 0.96 0.96 0.95 0.99 0.96
m4
25 0.99 0.99 0.98 0.99 0.95 0.96 0.95 0.95
50 0.96 0.94 0.93 0.95 0.92 0.93 0.93 0.90
100 0.98 0.97 0.96 0.98 0.98 0.97 0.96 0.98
200 0.98 0.97 0.97 0.99 0.98 0.97 0.97 0.99
500 0.95 0.98 0.99 0.97 0.95 0.98 0.99 0.97
En la Figura 4-8 se observan algunas diferencias en la calidad de las estimaciones del pa-
rametro de dispersion en particular para los modelos m2, m3 y m4, siendo este ultimo el
mas contrastante, ya que al evaluar la ER se obtuvieron estimaciones mas eficientes para
la funcion glm.comp en los tamanos muestrales de 25 y 50, y a partir de un numero de
Page 55
4.2 Resultados 35
observaciones de 100 las diferencias ya no son perceptibles entre las dos implementaciones.
Al igual que para las estimaciones de β1 y β2, las estimaciones de ν exhibieron una mayor
calidad a medida que aumento el β0 asumido, especialmente para n mayores o iguales a 100,
por lo tanto, el modelo m4 obtuvo estimaciones de mejor calidad a traves de los diferentes
niveles del tamano muestral respecto al modelo m1.
Al evaluar la proporcion de IC al 95 % que contienen el verdadero parametro, se pudo notar
un buen desempeno generalizado a traves de todos los escenarios configurados por los niveles
del tamano muestral y los modelos asumidos. Las tasas que se muestran en la Tabla 4-3
demuestran que hubo un buen desempeno del modelo CMP a la hora de estimar los coefi-
cientes asumidos ya que dichas proporciones no fueron inferiores al 90 %, es decir, que solo
en el 10 % o menos los IC no incluyeron los coeficientes asumidos para los modelos.
Los casos convergencia total indicaron un buen desempeno durante el proceso de ajuste del
modelo CMP en las dos implementaciones. Tanto las proporciones de convergencia en la
funcion glm.comp como en la funcion cmp fueron del 100 %, es decir, que ninguna de las
funciones tuvo problemas en la estimacion de los modelos.
Calidad de las estimaciones en UD
En este nivel de dispersion fue donde se presentaron las diferencias mas fuertes en las esti-
maciones de los coeficientes asumidos en las dos funciones. Para el coeficiente β0 la calidad
de su estimacion presento resultados coherentes (especialmente cuando n fue grande) para la
funcion cmp a traves de los diferentes modelos asumidos y aunque la funcion glm.comp pre-
sento resultados algo similares en el modelo asumido m1, en los demas presento una calidad
muy baja especialmente en tamanos muestrales altos. La ER muestra como incrementa la
eficiencia de las estimaciones de la funcion cmp a medida que aumenta n y el valor verdadero
de β0. En los modelos asumidos m1 y m2 cuando el tamano muestral es mınimo es donde la
funcion glm.comp tiene alguna ventaja sobre la funcion cmp ya que obtuvo una mayor cali-
dad, pero a partir de 50 observaciones tienden a igualarse los valores de RECM (Figura 4-9).
Basado en el comportamiento de las estimaciones de la funcion cmp, al evaluar el desempeno
del modelo CMP para estimar β0, se nota la tendencia a disminuir la RECM cada vez que
aumenta el tamano muestral, pero al mirar el comportamiento a traves de los diferentes mo-
delos asumidos se percibe que hay menor calidad cada vez que aumento el valor verdadero
para el intercepto, excepto para m1 en el tamano muestral mas pequeno.
Page 56
36 4 Comparacion de las funciones glm.comp y cmp
Valores asumidos para β0
RE
CM
β 0
0
2
4
6
8
10
12 UD − m1
Valores asumidos para β0
RE
CM
β 0
UD − m2
Valores asumidos para β0
RE
CM
β 0
UD − m3
Valores asumidos para β0
RE
CM
β 0
UD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 0
0
10
20
30
40
50
60
70
80
90
100
25 50 100 200 500
UD − m1
Valores asumidos para β0
ER
β 0
25 50 100 200 500
UD − m2
Valores asumidos para β0
ER
β 0
25 50 100 200 500
UD − m3
Valores asumidos para β0
ER
β 0
25 50 100 200 500
UD − m4 glm.comp/cmp
RE
CM
β 0
ER
β 0
Tamaño muestral (n)
Figura 4-9.: Calidad del coeficiente estimado β0 en un escenario de UD. Fuente: Elaboracion
propia.
Valores asumidos para β0
RE
CM
β 1
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0 UD − m1
Valores asumidos para β0
RE
CM
β 1
UD − m2
Valores asumidos para β0
RE
CM
β 1
UD − m3
Valores asumidos para β0
RE
CM
β 1
UD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 1
0
2
4
6
8
10
12
14
25 50 100 200 500
UD − m1
Valores asumidos para β0
ER
β 1
25 50 100 200 500
UD − m2
Valores asumidos para β0
ER
β 1
25 50 100 200 500
UD − m3
Valores asumidos para β0
ER
β 1
25 50 100 200 500
UD − m4 glm.comp/cmp
RE
CM
β 1
ER
β 1
Tamaño muestral (n)
Figura 4-10.: Calidad del coeficiente estimado β1 en un escenario de UD. Fuente: Elabora-
cion propia.
Page 57
4.2 Resultados 37
Valores asumidos para β0
RE
CM
β 2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0 UD − m1
Valores asumidos para β0
RE
CM
β 2
UD − m2
Valores asumidos para β0
RE
CM
β 2
UD − m3
Valores asumidos para β0
RE
CM
β 2
UD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 2
0
2
4
6
8
10
25 50 100 200 500
UD − m1
Valores asumidos para β0
ER
β 2
25 50 100 200 500
UD − m2
Valores asumidos para β0
ER
β 2
25 50 100 200 500
UD − m3
Valores asumidos para β0
ER
β 2
25 50 100 200 500
UD − m4 glm.comp/cmp
RE
CM
β 2
ER
β 2
Tamaño muestral (n)
Figura 4-11.: Calidad del coeficiente estimado β2 en un escenario de UD. Fuente: Elabora-
cion propia.
Valores asumidos para β0
RE
CM
ν
0
2
4
6
8
10
12
14 UD − m1
Valores asumidos para β0
RE
CM
ν
UD − m2
Valores asumidos para β0
RE
CM
ν
UD − m3
Valores asumidos para β0
RE
CM
ν
UD − m4 glm.comp cmp
Valores asumidos para β0
ER
ν
0
10
20
30
40
50
60
70
80
90
100
25 50 100 200 500
UD − m1
Valores asumidos para β0
ER
ν
25 50 100 200 500
UD − m2
Valores asumidos para β0
ER
ν
25 50 100 200 500
UD − m3
Valores asumidos para β0
ER
ν
25 50 100 200 500
UD − m4 glm.comp/cmp
RE
CM
ν E
Rν
Tamaño muestral (n)
Figura 4-12.: Calidad del coeficiente estimado ν en un escenario de UD. Fuente: Elaboracion
propia.
Page 58
38 4 Comparacion de las funciones glm.comp y cmp
En cuanto a la ER, las estimaciones de los coeficientes asociados a las variables predictoras
presentan comportamientos parecidos a los obtenidos para β0, lo cual no se da con los valores
de la RECM. Las diferencias se presentan fundamentalmente cuando el tamano muestral es
pequeno donde la eficiencia favorece las estimaciones de la funcion glm.comp, mientras que
en tamanos muestrales altos hay mayor eficiencia de las estimaciones logradas por la funcion
cmp (Figura 4-10 y Figura 4-11).
Tabla 4-4.: Proporcion de IC al 95 % que contienen los coeficientes verdaderos en un esce-
nario de UD. Fuente: Elaboracion propia.
UD glm.comp cmp
m n β0 β1 β2 ν β0 β1 β2 ν
m1
25 0.95 0.96 0.96 0.99 0.95 0.96 0.96 0.99
50 0.97 0.99 0.94 0.95 0.97 0.99 0.94 0.95
100 0.93 0.99 0.94 0.95 0.93 0.99 0.94 0.95
200 0.92 0.97 0.93 0.93 0.92 0.97 0.93 0.93
500 0.91 0.90 0.95 0.95 0.91 0.90 0.95 0.95
m2
25 0.98 0.97 0.98 1.00 0.99 0.97 0.94 0.98
50 0.91 0.99 0.98 0.98 0.96 0.97 0.96 0.97
100 0.70 0.96 0.96 0.74 0.98 0.93 0.95 0.98
200 0.00 0.63 0.69 0.00 0.97 0.96 0.90 0.96
500 0.00 0.87 0.94 0.00 0.97 0.96 0.94 0.94
m3
25 0.00 0.96 0.96 0.00 0.97 0.98 0.94 0.98
50 0.00 0.94 0.94 0.00 0.96 0.96 0.95 0.96
100 0.00 0.84 0.84 0.00 0.96 0.94 0.97 0.97
200 0.00 0.03 0.25 0.00 0.97 0.99 0.91 0.97
500 0.00 0.25 0.26 0.00 0.95 0.95 0.93 0.96
m4
25 0.00 0.90 0.92 0.00 0.97 0.98 0.93 0.97
50 0.00 0.66 0.81 0.00 0.99 0.97 0.96 0.99
100 0.00 0.24 0.31 0.00 0.95 0.95 0.96 0.96
200 0.00 0.00 0.03 0.00 0.96 0.98 0.89 0.97
500 0.00 0.00 0.01 0.00 0.95 0.96 0.96 0.95
Segun la Figura 4-12 los comportamientos de la RECM y la ER favorecen las estimaciones
producidas por la funcion cmp en la mayorıa de los escenarios configurados. Los casos don-
de esto no sucede es cuando el tamano muestral es mınimo particularmente en los modelos
asumidos m1 y m2, donde la funcion glm.comp obtuvo un mejor desempeno.
Page 59
4.2 Resultados 39
Excepto en el modelo asumido m1, la funcion glm.comp no presenta una tendencia bien
marcada en la relacion entre la calidad de las estimaciones y el tamano muestral, ya que es
casi constante a traves de los diferentes niveles de n. Por esto, si se toma como referencia los
resultados dados por la funcion cmp, la calidad de la estimacion de ν en el modelo CMP fue
deficiente particularmente cuando se asumio un valor de β0 bajo y donde el tamano muestral
fue de 25 observaciones.
La Tabla 4-4 presenta la proporcion de IC al 95 % que contienen el verdadero parametro.
En ella se complementan los resultados obtenidos en cuanto a la calidad de las estimaciones
en el modelo CMP, ya que se presentan contrastes bien marcados entre las dos funciones.
Mientras que en general la funcion cmp realiza estimaciones adecuadas en los diversos es-
cenarios y para todos los parametros, la funcion glm.comp no logro ese nivel de estimacion
especialmente de los parametros β0 y ν. La proporcion de IC al 95 % en la funcion cmp no
son inferiores al 90 %, caso contrario al de la funcion glm.comp donde se presentan casos
donde en ningun momento el IC logro contener el verdadero parametro siendo los casos mas
llamativos, los presentados en los escenarios de los modelos asumidos m3 y m4 , en donde
tanto β0 y ν presentaron coberturas de los IC desfavorables en todos los niveles de n.
En general las dos implementaciones obtuvieron tasas de convergencia casi absolutas lo que
indica un proceso adecuado de ajuste del modelo CMP. Solo en el escenario donde el modelo
asumido m1 y el tamano muestral fue de 25, la funcion glm.comp presento una proporcion
del 98 % de convergencia, es decir, que en solo dos casos no se logro estimar el modelo.
4.2.2. Calidad predictiva y ER
A continuacion se presentan los resultados obtenidos para las predicciones logradas por las
dos funciones que son objeto de comparacion. Se hace una descripcion de los resultados ob-
tenidos en terminos de la calidad predictiva en los diferentes escenarios configurados.
Calidad predictiva en OD
La Figura 4-13 muestra que las predicciones difieren caracterısticamente en el modelo asu-
mido m4, es decir cuando el β0 asumido fue mayor. En este escenario se presentan eficiencias
en mayor parte a favor de la funcion glm.comp ya que en los tamanos muestrales con 25, 100
y 200 observaciones se presentaron valores medios de RECMP mas altos para las prediccio-
nes logradas por la funcion cmp. En los demas modelos asumidos no se perciben diferencias
marcadas y eso lo demuestra la ER entre las dos funciones la cual es constante a traves de
diferentes valores verdaderos del intercepto.
Page 60
40 4 Comparacion de las funciones glm.comp y cmp
Valores asumidos para β0
RE
CM
β 0
0
4
8
12
16
20 OD − m1
Valores asumidos para β0
RE
CM
β 0
OD − m2
Valores asumidos para β0
RE
CM
β 0
OD − m3
Valores asumidos para β0
RE
CM
β 0
OD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 0
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
25 50 100 200 500
OD − m1
Valores asumidos para β0
ER
β 0
25 50 100 200 500
OD − m2
Valores asumidos para β0
ER
β 0
25 50 100 200 500
OD − m3
Valores asumidos para β0
ER
β 0
25 50 100 200 500
OD − m4 glm.comp/cmp
RE
CM
P
ER
Y
Tamaño muestral (n)
Figura 4-13.: Contraste entre las estimaciones de las funciones glm.comp y cmp en terminos
de RECMP y ER en un escenario de OD. Fuente: Elaboracion propia.
Al establecer las tendencias se puede notar que la RECMP es casi constante a traves de
los diferentes niveles del tamano muestral. Pero al variar el valor asumido para β0 se logro
determinar un comportamiento deficiente en cuanto a la calidad de las predicciones ya que
al aumentar dicho valor la RECMP fue aumentando, es decir, que al aumentar β0 se perdio
calidad predictiva.
Calidad predictiva en ED
En este escenario de dispersion los comportamientos fueron muy similares. Tanto la funcion
cmp como la glm.comp presentaron resultados muy parecidos ya que a simple vista es difıcil
percibir diferencias. Al aumentar el numero de cifras decimales para los valores de ER se al-
canza a experimentar una leve diferencia entre el desempeno predictivo de las dos funciones.
Esto se dio en el modelo asumido m4 cuando el tamano muestral fue el mas bajo.
Page 61
4.2 Resultados 41
Valores asumidos para β0
RE
CM
β 0
0
1
2
3
4
5
6 ED − m1
Valores asumidos para β0
RE
CM
β 0
ED − m2
Valores asumidos para β0
RE
CM
β 0
ED − m3
Valores asumidos para β0
RE
CM
β 0
ED − m4 glm.comp cmp
Valores asumidos para β0
ER
β 0
0.990
0.992
0.994
0.996
0.998
1.000
1.002
1.004
1.006
1.008
1.010
25 50 100 200 500
ED − m1
Valores asumidos para β0
ER
β 0
25 50 100 200 500
ED − m2
Valores asumidos para β0
ER
β 0
25 50 100 200 500
ED − m3
Valores asumidos para β0
ER
β 0
25 50 100 200 500
ED − m4 glm.comp/cmp
RE
CM
P
ER
Y
Tamaño muestral (n)
Figura 4-14.: Contraste entre las estimaciones de las funciones glm.comp y cmp en terminos
de RECMP y ER en un escenario de ED. Fuente: Elaboracion propia.
Las predicciones presentan comportamientos muy similares en cuanto al desempeno predic-
tivo y la ER y sin diferencias marcadas cuando varıa n. En la Figura 4-14 se puede observar
un comportamiento incremental de la RECMP, indicando que a un mayor de β0 asumido
menor fue la calidad predictiva de los modelos ajustados con estas dos funciones.
Calidad predictiva en UD
La calidad de las predicciones entre las dos funciones no presentan diferencias muy marcadas
pero si perceptibles, particularmente en el modelo m4. La ER muestra que en el modelo asu-
mido m1 fue donde ambas funciones presentaron resultados muy similares, excepto cuando el
tamano muestral fue de 25, en donde la funcion glm.comp fue ligeramente mas eficiente. En
los demas modelos asumidos, la ER experimento ciertas fluctuaciones a traves de los diversos
niveles del tamano muestral, aun ası, en ninguno de aquellos escenarios las predicciones de
la funcion glm.comp fueron mas eficientes que las de la funcion cmp.
Cuando la media es mayor que la varianza se lograron percibir reducciones graduales en el
desempeno predictivo a medida que aumento el valor asumido de β0 y ademas no se detectan
rasgos notorios que indiquen diferencias en cuanto al tamano muestral ya que los comporta-
mientos son casi constantes a traves de sus diferentes niveles (Figura 4-15).
Page 62
42 4 Comparacion de las funciones glm.comp y cmp
Valores asumidos para β0
RE
CM
β 0
0.0
0.5
1.0
1.5
2.0
2.5 UD − m1
Valores asumidos para β0
RE
CM
β 0
UD − m2
Valores asumidos para β0
RE
CM
β 0
UD − m3
Valores asumidos para β0
RE
CM
β 0
UD − m4 glm.comp cmp
Valores asumidos para β0
ER
β 0
0.90
0.92
0.94
0.96
0.98
1.00
1.02
1.04
1.06
1.08
1.10
25 50 100 200 500
UD − m1
Valores asumidos para β0
ER
β 0
25 50 100 200 500
UD − m2
Valores asumidos para β0
ER
β 0
25 50 100 200 500
UD − m3
Valores asumidos para β0
ER
β 0
25 50 100 200 500
UD − m4 glm.comp/cmp
RE
CM
P
ER
Y
Tamaño muestral (n)
Figura 4-15.: Contraste entre las estimaciones de las funciones glm.comp y cmp en terminos
de RECMP y ER en un escenario de UD. Fuente: Elaboracion propia.
4.2.3. Diferencias identificadas
En primera instancia se resalta la capacidad que tiene la funcion glm.comp del paquete
CompGLM [26] para obtener los resultados tal como se obtienen en la funcion glm generica
para ajustar MLG, de allı su nombre. La funcion cmp del paquete COMPoissonReg [31]
aunque no tiene este marco de presentacion de resultados es mas completa para el analisis
inferencial y el diagnostico del modelo. En la siguiente lista se describen algunas de las
diferencias detectadas entre estas dos funciones.
Los errores estandar asociados a los coeficientes del modelo y al parametro de dispersion
estimados en la funcion glm.comp estan intercalados respecto a los obtenidos con la
funcion cmp (Anexo A). Examinando el resumen del modelo se identifico que el error
estandar de β1 en glm.comp es parecido al error estandar para β0 en cmp, el error
estandar de β2 en glm.comp es similar al error estandar para β1 en cmp y el error
estandar de ν en glm.comp es parecido al error estandar para β2 en cmp CMP.
La calidad predictiva en UD, cuando se asignan valores de λ muy altos, la funcion
glm.comp al obtener el resumen del modelo para los coeficientes estimados, muestra
valores no numericos (NaN’s), indicando problemas a la hora de calcular la matriz
de informacion, a pesar de que no se experimentan problemas de iteracion. Tambien
presenta coeficientes estimados muy sesgados. El comportamiento de la funcion cmp en
las mismas condiciones fue mas favorable ya que presento estimaciones coherentes con
Page 63
4.3 Discusion 43
los valores asumidos para el modelo.
Valores asumidos para β0
RE
CM
β 0
0
20
40
60
80
100
25 50 100 200 500
ED − m1
Valores asumidos para β0
RE
CM
β 0
25 50 100 200 500
ED − m2
Valores asumidos para β0
RE
CM
β 0
25 50 100 200 500
ED − m3
Valores asumidos para β0
RE
CM
β 0
25 50 100 200 500
ED − m4 glm.comp cmp
Tie
mp
o(s
egun
dos)
Tamaño muestral (n)
Figura 4-16.: Tiempo medio de ajuste de un modelo CMP entre las funciones glm.comp y
cmp en un escenario de ED. Fuente: Elaboracion propia.
La Figura 4-16 muestra el tiempo medio en segundos que demando cada una de las
funciones para ajustar modelos CMP en un escenario de ED. Es claro el efecto consi-
derable que tiene el tamano muestral sobre el tiempo de ajuste de un modelo con la
funcion cmp, mientras que con la funcion glm.comp la influencia del numero de observa-
ciones no fue tan notorio. La eficiencia computacional es mayor en la funcion glm.comp
ya que tiene implementado mediante el paquete Rcpp algunos codigos escritos con C++
(caracterısticamente las funciones para obtener la constante de normalizacion Z) y su
proceso de optimizacion se hace por medio de la funcion optim. En cambio, la funcion
cmp tiene todo su codigo escrito en R [27, R Core Team 2016] y utiliza la funcion
nlminb para optimizacion no restringida de la funcion de log-verosimilitud y si no se
logra convergencia usa como metodo alternativo la funcion optim.
4.3. Discusion
En esta seccion se discuten algunas de las diferencias encontradas entre dos implementaciones
en R [27, R Core Team 2016] para ajustar modelos CMP. Tambien se analiza el desempeno
de dicho modelo a la hora de estimar los parametros y de obtener las predicciones por medio
de la esperanza condicional de la media propuesta para este modelo en diferentes escenarios
de dispersion.
En OD, al examinar los resultados de las dos funciones se lograron identificar ciertos casos
donde el parametro de dispersion es poco coherente con respecto al valor asumido. Vale la
pena anotar que en este escenario de dispersion se asigno un ν de 0.25 (Tabla 4-1) y cuando
se comparo este valor con los valores estimados de ambas funciones donde el tamano muestral
Page 64
44 4 Comparacion de las funciones glm.comp y cmp
y el modelo asumido tuvo las mas baja denominacion (m1), en algunos casos esos valores
fueron iguales a 0 (coeficientes estimados iguales a cero) en la funcion cmp y muy cercanos
a 0 (con tres cifras decimales nulas) en la funcion glm.comp, lo que da a entender que al
parecer el modelo (no solo las funciones) tiene dificultades para lograr buenas estimaciones
en el modelo asumido m1 y en tamanos muestrales pequenos. Para efectos de analisis se
omitieron aquellos casos donde se presentaron dichas estimaciones incoherentes.
La ER en las estimaciones de los parametros y las predicciones del modelo CMP en el esce-
nario donde la varianza fue mayor que la media estuvo en la mayorıa de los casos alrededor
de 1, indicando que las dos implementaciones presentan estimaciones similares, excepto en el
modelo asumido m4 en donde se obtuvieron eficiencias en mayor parte a favor de la funcion
glm.comp, pero con una tendencia a igualarse cuando el tamano muestral fue mayor a 200.
La presencia de diferencias en este caso pudieron darse debido a contrastes en la estimacion
de la constante de normalizacion, ya que la funcion glm.comp esta limitada por defecto para
ajustar conteos muy altos que superen el lımite descrito en la Seccion 3.3.3, al eliminarse
dicha restriccion se obtuvieron las diferencias respecto a la funcion cmp la cual no tiene tal
limitacion.
En ED, los contrastes mas fuertes se presentan en las estimaciones de los parametros justo
entre los modelos asumidos m2 y m4 y cuando el tamano muestral es menor a 50. Lo contra-
rio se experimenta cuando n es mayor, donde hay una tendencia obtener resultados similares
en ambas implementaciones ya que la ER para las estimaciones de los parametros es muy
cercana a 1, a partir de tamanos muestrales superiores a 100; y en las predicciones la ER,
solo cuando n es igual a 25, hay una leve eficiencia a favor de la funcion cmp, de resto no hay
una funcion mas eficiente que otra en los demas niveles de n.
La mayores diferencias entre las funciones en cuanto calidad de los coeficientes estimados
y el comportamiento de las predicciones, se presentaron en el escenario de UD cuando el
modelo asumido tuvo valores altos de β0 y de tamano muestral. En el modelo asumido m1
se presentaron resultados similares excepto cuando el tamano muestral fue muy bajo, ya que
tanto la ER de las estimaciones como de las predicciones obtuvieron eficiencias a favor de
la funcion glm.comp, es decir, que es el unico caso donde la funcion cmp esta en desventaja
ya que en el resto de los escenarios es claro que dicha funcion presenta resultados acordes
con los coeficientes asumidos y por supuesto con las predicciones. El factor principal que
influye en el resultado de la calidad predictiva es la estimacion deficiente de los parametros
del modelo en especial del parametro de dispersion, debido a que la esperanza condicional
de la media ademas de estar en funcion de λ tambien depende de ν el cual actua como un
coeficiente de escalamiento para el vector β (Ecuacion (2–5)).
En cuanto al desempeno del modelo a la hora de estimar los parametros, se pudo caracterizar
Page 65
4.4 Conclusiones 45
que en el escenario de OD el modelo CMP tuvo un desempeno deficiente cuando se asumio
un valor bajo para β0 ya que obtuvo los valores mas bajos de calidad de las estimaciones
respecto a los demas modelos asumidos, caracterısticamente en tamanos muestrales bajos.
Esto concuerda con lo obtenido por Francis et al. [9], en donde la distribucion CMP MLG es
limitada para obtener estimaciones adecuadas en OD cuando se asumieron valores bajos para
el intercepto. En ED, el parametro estimado con mas bajo nivel de calidad fue el β0, excepto
en el modelo asumido m1 en donde se presentaron comportamientos no tan contrastantes
entre los diversos coeficientes estimados. En el escenario de UD, si se toma como referencia
los resultados adecuados que arroja la funcion cmp, se logro determinar una calidad mas baja
de las estimaciones en comparacion con los escenarios de dispersion anteriores cuando n es
pequeno. Tambien las estimaciones de β0 y de ν tuvieron comportamientos deficientes por
sus altos valores de RECM.
Al evaluar el papel del tamano muestral se puede decir que tuvo influencia a la hora de eva-
luar la calidad de las estimaciones de los parametros mas no en el desempeno predictivo de
las dos funciones. Cuando se evaluaron las funciones en tamanos muestrales bajos fue donde
mas se detectaron diferencias entre las dos funciones, especialmente en las estimaciones del
parametro de dispersion. Esto es debido a que en el modelo de regresion CMP, segun Sellers
& Shmueli [32], no se puede asegurar la normalidad asintotica de los coeficientes estimados
del modelo cuando n es muy pequeno. Cuando n fue en aumento se lograron percibir dife-
rencias un poco mas leves y casi imperceptibles, mas aun cuando se alcanzo el mayor nivel
de tamano muestral, excepto en UD.
4.4. Conclusiones
Por medio de un estudio de simulacion se logro determinar ciertas diferencias entre dos
implementaciones en R [27, R Core Team 2016] para ajustar modelos CMP en diferentes
variaciones del intercepto, tamanos muestrales y escenarios de dispersion. Por medio de me-
didas de calidad de las estimaciones, de desempeno predictivo y de ER se caracterizo el
comportamiento de dicho modelo y se determinaron los casos en donde segun la calidad
predictiva es mas conveniente usar una u otra implementacion.
En terminos generales las dos implementaciones para ajustar modelos CMP en R [27, R
Core Team 2016] producen predicciones similares en escenarios de ED y OD, especialmente
cuando el tamano muestral es grande, por lo tanto, en estos escenarios serıa conveniente usar
la funcion glm.comp por su ventaja en cuanto a la eficiencia computacional. En UD, sera
conveniente usar la funcion cmp ya que sus estimaciones fueron mas eficientes en tamanos
muestrales grandes y porque no presento las inconsistencias anteriormente descritas al obte-
ner los errores estandar del modelo. El unico caso donde se podrıa usar la funcion glm.comp
Page 66
46 4 Comparacion de las funciones glm.comp y cmp
en UD serıa al asumir valores bajos para β0, es decir, para el modelo asumido m1, ya que
dicha funcion resulto ser mas eficiente en tamanos muestrales bajos; y en tamanos grandes,
a pesar de no presentar diferencias marcadas con la funcion cmp, tal impementacion es mas
eficiente a nivel computacional.
La caracterizacion del modelo CMP arrojo resultados contrastantes en los diferentes escena-
rios de dispersion. En OD y en ED se lograron comportamientos similares en la calidad de las
estimaciones ya que presentaron valores similares en la mayorıa de los parametros (Excepto
para β0 en ED). En UD, se obtuvieron estimaciones deficientes para β0 y ν en comparacion
con la calidad lograda por los coeficientes estimados asociados a las variables predictoras. Y
en general, al evaluar el efecto de la variacion del coeficiente asumido β0 se logro determinar
que cuando este valor es bajo, el modelo tiene un mal desempeno en la calidad de las estima-
ciones, respecto a los demas modelos asumidos en cualquiera de los escenarios de dispersion.
Se logro detectar la calidad de la estimacion del parametro de dispersion como un factor que
puede determinar el comportamiento predictivo en el modelo CMP, ya que dicha estimacion
tuvo problemas en algunos escenarios de OD y UD, lo cual puede afectar los valores ajusta-
dos obtenidos por el metodo de prediccion de medias.
Page 67
5. Eficiencia Relativa de la predicciones
entre los modelos CMP y Poisson
En este capıtulo se evaluo con mas detalle la calidad predictiva dentro de un marco de nor-
malidad asintotica en los estimadores de los parametros de las distribuciones que son objeto
de comparacion en esta disertacion. Por ello, se realizo un estudio de simulacion con un ta-
mano muestral suficiente para lograr representar dicho marco y en donde se compararon las
medidas de desempeno predictivo de los modelos ajustados a traves de su ER. A diferencia
de algunos trabajos relacionados [9, 10], en donde los escenarios de dispersion se definieron
unos cuantos valores para el parametro de dispersion ν, en este capıtulo se evaluo el efecto
en el comportamiento predictivo a traves un rango mas amplio de intensidades de OD y UD.
Tambien se hace una comparacion especıfica entre dos metodos de prediccion propuestos por
Sellers & Shmueli [32], por lo tanto, se evaluara la ER de las predicciones obtenidas por el
metodo de medias y medianas definidas para el modelo CMP con el fin de recomendar la
implementacion mas adecuada a la hora de obtener valores ajustados ya que la aproximacion
a la media condicional en este modelo es acertada solo cuando ν ≤ 1 o λi > 10ν .
Este capıtulo se compone de las siguientes secciones. La Seccion 5.1 se describen los diferen-
tes escenarios configurados por los niveles de factores que son objeto de evaluacion en las
simulaciones. Luego se presentan los resultados de las medidas estadısticas en la Seccion 5.2
y posteriormente son discutidos en la Seccion 5.3. Finalmente, en la Seccion 5.4 se dan a
conocer las conclusiones que marcaron relevancia en el analisis de los resultados.
5.1. Metodologıa
En esta seccion se dan a conocer los diferentes procedimientos que se realizaron para efec-
tuar las simulaciones. Se describe como se definieron los diferentes escenarios configurados
segun las combinaciones de los niveles de factores considerados para el presente trabajo. En
este estudio de simulacion se considero un numero de observaciones constante y suficiente
para asegurar la normalidad asintotica de las estimaciones de las diferentes alternativas para
ajustar datos de conteo.
Page 68
48 5 Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson
5.1.1. Descripcion de la simulacion
Para evaluar la eficiencia entre las predicciones de los modelos que son objeto de comparacion
en este estudio, se diseno un procedimiento de simulacion basado en el algoritmo descrito en la
Seccion 3.3. Una de las caracterısticas especıficas de tal procedimiento es que se utilizo un ta-
mano muestral constante para todos los conjuntos de datos generados de 1000 observaciones.
En total, se generaron 1000 conjuntos de datos (nsim = 1000) para cada uno de los escena-
rios conformados por las intensidades de dispersion y los modelos asumidos. Las intensidades
de dispersion abarcan una rango amplio tanto de OD como UD. Por ello, se definieron tres
intensidades para OD (ν = 0.25, 0.5, 0.75) y tres para UD (ν = 1.5, 2.5, 5) y ν = 1 para
el caso de ED. Cuatro clases de los modelos asumidos se definieron segun el valor verdadero
adoptado para el parametro β0 dejando constantes los coeficientes asumidos asociados a las
variables predictoras, indicando que el menor valor asumido de β0 corresponde al modelo
asumido de mas baja denominacion y ası respectivamente hasta el modelo de mayor deno-
minacion.
A los conjuntos de datos generados se les ajustaron los modelos CMP y Poisson, para ser
comparados en OD con el modelo BN; y en ED y UD con el modelo PGR. Luego se al-
macenaron las estimaciones y se calculo la RECMP y la ER. En la Tabla 5-1, Tabla 5-2,
Tabla 5-3, se muestran los coeficientes asumidos para generar los datos para cada uno de los
escenarios de dispersion.
Tabla 5-1.: Coeficientes asumidos para el estudio de simulacion de eficiencia entre el modelo
CMP y el modelo Poisson en, OD. Fuente: Elaboracion propia.
ν =0.25 ν =0.50 ν =0.75
m1 m2 m3 m4 m1 m2 m3 m4 m1 m2 m3 m4
β0 -0.50 0.30 0.50 0.70 -0.30 0.70 1.10 1.50 -0.10 1.20 1.70 2.20
β1 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50
β2 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50
ν 0.25 0.25 0.25 0.25 0.50 0.50 0.50 0.50 0.75 0.75 0.75 0.75
Page 69
5.2 Resultados 49
Tabla 5-2.: Coeficientes asumidos para el estudio de simulacion de eficiencia entre el modelo
CMP y el modelo Poisson, en ED. Fuente: Elaboracion propia.
ν =1.00
m1 m2 m3 m4
β0 0.10 1.60 2.30 3.00
β1 -0.50 -0.50 -0.50 -0.50
β2 0.50 0.50 0.50 0.50
ν 1.00 1.00 1.00 1.00
Tabla 5-3.: Coeficientes asumidos para el estudio de simulacion de eficiencia entre el modelo
CMP y el modelo Poisson, en UD. Fuente: Elaboracion propia.
ν=1.50 ν =2.50 ν =5.00
m1 m2 m3 m4 m1 m2 m3 m4 m1 m2 m3 m4
β0 0.50 2.50 3.50 4.50 1.00 4.20 6.00 7.50 2.00 8.50 12.0 15.0
β1 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50 -0.50
β2 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50 0.50
ν 1.50 1.50 1.50 1.50 2.50 2.50 2.50 2.50 5.00 5.00 5.00 5.00
Tal como se ve en las tablas anteriores, el rango de niveles de dispersion es amplio y en los
diferentes modelos asumidos (m1, m2, m3, m4) el coeficiente verdadero para β0 es diferente
mientras que para β1 y β2 fueron constantes.
5.2. Resultados
La presente seccion da a conocer los resultados que arrojaron las simulaciones. En cada es-
cenario de dispersion se obtuvieron los comportamientos de la calidad predictiva y la ER de
los diferentes modelos que son objeto de comparacion. Tambien se presenta por medio de
tablas, informacion sobre la proporcion de veces durante el proceso de simulacion en don-
de un modelo mas basico fue mas eficiente respecto al modelo alternativo o propuesto para
ajustar datos de conteo. Para complementar la informacion presentada graficamente se puede
consultar los resumenes de las simulaciones en el Apendice C; allı la informacion numerica
se encuentra distribuida por cada una de las intensidades de dispersion planteadas dando a
conocer medidas de resumen basicas del desempeno predictivo de los modelos comparados.
Page 70
50 5 Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson
Por ultimo, se comparan por medio de la ER las propuestas de [32] para obtener los valores
ajustados en un modelo CMP.
5.2.1. Eficiencia Relativa en OD
La Figura 5-1 muestra los comportamientos de la calidad predictiva de los modelos ajustados
en un escenario de OD. En ella se puede observar que en general los valores de RECMP son
muy similares entre las diferentes propuestas de analisis de datos de conteo.
Valores asumidos para β0
RM
SP
Eβ 0
0
2
4
6
8
10 ν = 0.25
Valores asumidos para β0
RM
SP
Eβ 0
ν = 0.5
Valores asumidos para β0
RM
SP
Eβ 0
ν = 0.75 Poisson CMP BN
Valores asumidos para β0
RM
SP
Eβ 0
0.9
1.0
1.1
1.2
1.3
1.4
1.5
m1 m2 m3 m4
ν = 0.25
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 0.5
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 0.75 CMP Poisson CMP BN BN Poisson
RE
CM
P
ER
Modelos asumidos
Figura 5-1.: Desempeno predictivo en OD. Fuente: Elaboracion propia.
La evaluacion de la ER muestra que la diferencias mas notorias se presentan en el nivel de
OD mas fuerte. En el modelo asumido m1 fue poco eficiente el modelo CMP respecto a los
modelos Poisson y BN. Lo contrario se dio en los modelos asumidos m2 y m3, en donde el
modelo CMP es mas eficiente que los otros dos modelos. Y en el modelo asumido m4, el mo-
delo CMP solo es eficiente respecto al modelo BN. Tambien se alcanza a notar que el modelo
Poisson es ligeramente mas eficiente que el modelo BN. En los niveles de OD menos severos
las diferencias fueron menos perceptibles entre las diversas distribuciones contrastadas.
Page 71
5.2 Resultados 51
Valores asumidos para β0
RM
SP
Eβ 0
0
2
4
6
8
10
12 ν = 0.25
Valores asumidos para β0 R
MS
PE
β 0
ν = 0.5
Valores asumidos para β0
RM
SP
Eβ 0
ν = 0.75 CMPM CMPMe
Valores asumidos para β0
RM
SP
Eβ 0
0.90
0.95
1.00
1.05
1.10
1.15
1.20
m1 m2 m3 m4
ν = 0.25
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 0.5
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 0.75 CMPMe CMPM
RE
CM
P
ER
Modelos asumidos
Figura 5-2.: Comparacion de metodos de prediccion en OD. Fuente: Elaboracion propia.
La comparacion de las propuestas de prediccion para el modelo CMP que se muestran en la
Figura 5-2, indican que los comportamientos son muy similares en cuanto a los valores de
RECMP. A pesar de esto, la ER senala que el unico caso donde las predicciones de mediana
fueron mas eficientes que las de la aproximacion de la media condicional, fue en el modelo
asumido de menor denominacion m1, en el nivel de OD mas fuerte (ν verdadero de 0.25).
En el resto de modelos asumidos las predicciones de media fueron mas eficientes, aunque hay
una tendencia en la ER a ser mas cercana a 1 a medida que aumenta el coeficiente asumido
para β0.
La Tabla 5-4 corrobora los resultados anteriores. Muestra que la comparacion entre el modelo
CMP y Poisson, el modelo CMP obtuvo el mayor numero de casos de eficiencia en los modelos
asumidos m2 y m3, especialmente en el nivel de OD mas fuerte. La comparacion entre el
modelo CMP y el BN indico que el modelo CMP obtuvo mayores casos de eficiencia entre los
modelos asumidos m2 y m4, incluso en niveles de OD menos severos. Y caracterısticamente,
el contraste entre los modelos BN y el Poisson, arrojo una mayor tasa de casos de eficiencia
a favor del modelo Poisson a traves de los diferentes niveles de OD.
Page 72
52 5 Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson
Tabla 5-4.: Proporcion de ER en un escenario de OD con n = 1000. Fuente: Elaboracion
propia.
OD M
ν m CMP vs Poisson CMP vs BN BN vs Poisson YMe vs YM
ν =0.25
m1 1.000 1.000 0.996 0.353
m2 0.226 0.159 0.996 1.000
m3 0.173 0.095 0.995 1.000
m4 0.659 0.351 0.992 0.656
ν =0.50
m1 0.945 0.931 0.999 1.000
m2 0.481 0.448 0.996 1.000
m3 0.407 0.371 0.996 0.994
m4 0.432 0.319 0.992 0.944
ν =0.75
m1 0.755 0.730 1.000 1.000
m2 0.494 0.471 1.000 1.000
m3 0.466 0.407 0.998 0.975
m4 0.468 0.315 1.000 0.931
En cuanto a la comparacion de las propuestas de prediccion, se nota la ventaja en casos de
eficiencia de la prediccion de medianas en el nivel de OD mas fuerte y en m1, ya que en el
resto de escenarios fue predominante los casos de eficiencia de la prediccion de medias.
5.2.2. Eficiencia Relativa en ED
Cuando la media y la varianza son iguales, los comportamientos en el desempeno predictivo
reflejados por los valores de la RECMP a traves de los diferentes modelos asumidos son muy
similares entre los diversos modelos comparados. Incluso al evaluar la ER entre ellos, es casi
imperceptible algun rasgo que de un indicio de eficiencia en las predicciones a favor de uno
u otro modelo. La Figura 5-3 muestra que con numero de tres cifras decimales ninguna de
las propuestas para analisis de datos de conteo es mas eficiente una de la otra.
La comparacion de los metodos de prediccion a pesar de ser muy similares entre sı en cuan-
to a su calidad predictiva, muestra segun la ER que fue mas eficiente en todos los casos
la prediccion de medias respecto a la de medianas (Figura 5-4). Sin embargo, se nota una
tendencia a disminuir la brecha en el desempeno predictivo a medida que aumenta el valor
asumido para β0, es decir, la denominacion del modelo asumido.
En cuanto a la proporcion de casos de ER, la mayorıa de los escenarios muestran que hubie-
ron proporciones equilibradas de eficiencia de un modelo respecto al otro. Las comparaciones
Page 73
5.2 Resultados 53
Valores asumidos para β0
RM
SP
Eβ 0
0
1
2
3
4
5
6 ν = 1 Poisson CMP PGR
Valores asumidos para β0
RM
SP
Eβ 0
0.990
0.992
0.994
0.996
0.998
1.000
1.002
1.004
1.006
1.008
1.010
m1 m2 m3 m4
ν = 1 CMP Poisson CMP PGR PGR Poisson
RE
CM
P
ER
Modelos asumidos
Figura 5-3.: Desempeno predictivo en ED. Fuente: Elaboracion propia.
Valores asumidos para β0
RM
SP
Eβ 0
0
1
2
3
4
5
6 ν = 1 CMPM CMPMe
Valores asumidos para β0
RM
SP
Eβ 0
0.90
0.95
1.00
1.05
1.10
m1 m2 m3 m4
ν = 1 CMPMe CMPM
RE
CM
P
ER
Modelos asumidos
Figura 5-4.: Comparacion de metodos de prediccion en ED. Fuente: Elaboracion propia.
Page 74
54 5 Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson
Tabla 5-5.: Proporcion de ER en un escenario de ED con n = 1000. Fuente: Elaboracion
propia.
ED M
ν m CMP vs Poisson CMP vs PGR PGR vs Poisson YMe vs YM
ν =1.00
m1 0.664 0.666 0.445 1.000
m2 0.519 0.521 0.447 0.996
m3 0.495 0.530 0.408 0.974
m4 0.491 0.545 0.400 0.914
del modelo CMP respecto al modelo Poisson y el modelo PGR muestran que la proporcion de
casos de eficiencia entre estos tres modelos fue cercana al 50 %, con una leve ventaja de estos
dos ultimos en m1. En la comparacion del modelo PGR y el Poisson hay una proporcion de
ventaja a favor de la eficiencia del modelo PGR.
El metodo de prediccion de medias en el modelo CMP demostro su predominante eficiencia
en ED ya que la proporcion de casos de eficiencia de este metodo estuvo siempre por encima
del 90 % respecto a las predicciones de mediana en todos los modelos asumidos (Tabla 5-5).
5.2.3. Eficiencia Relativa en UD
En UD, la RECMP segun la Figura 5-5 fue muy similar entre las propuestas contrastadas
y por ello no marcan una diferencia notoria en cuanto los comportamientos de la calidad
predictiva. Sin embargo, la ER demostro que las predicciones del modelo CMP fueron menos
eficientes respecto a los demas modelos cuando se asumio el valor mas bajo de β0. Mientras,
que en la comparacion del modelo PGR y el Poisson no se logro detectar una eficiencia de
un modelo respecto al otro, dado que los valores de ER son muy cercanos 1.
La Figura 5-6 muestra los comportamientos de la calidad predictiva entre los dos metodos
de prediccion planteados para obtener valores ajustados en el modelo CMP. Los valores de
la RECMP muestran curvas muy similares a traves de los diversos modelos asumidos, pero
al evaluar la ER se pudo determinar que de forma generalizada el procedimiento de obtener
valores ajustados por medio de la aproximacion a la media fue mas eficiente que el metodo
de prediccion de medianas.
La Tabla 5-6 complementa la informacion grafica descrita anteriormente. La comparacion en
el comportamiento de las predicciones entre el modelo CMP y las dos propuestas muestran
Page 75
5.2 Resultados 55
Valores asumidos para β0
RM
SP
Eβ 0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0 ν = 1.5
Valores asumidos para β0
RM
SP
Eβ 0
ν = 2.5
Valores asumidos para β0
RM
SP
Eβ 0
ν = 5 Poisson CMP PGR
Valores asumidos para β0
RM
SP
Eβ 0
0.990
0.995
1.000
1.005
1.010
m1 m2 m3 m4
ν = 1.5
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 2.5
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 5 CMP Poisson CMP PGR PGR Poisson
RE
CM
P
ER
Modelos asumidos
Figura 5-5.: Desempeno predictivo en UD. Fuente: Elaboracion propia.
Valores asumidos para β0
RM
SP
Eβ 0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0 ν = 1.5
Valores asumidos para β0
RM
SP
Eβ 0
ν = 2.5
Valores asumidos para β0
RM
SP
Eβ 0
ν = 5 CMPM CMPMe
Valores asumidos para β0
RM
SP
Eβ 0
0.90
0.95
1.00
1.05
1.10
m1 m2 m3 m4
ν = 1.5
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 2.5
Valores asumidos para β0
RM
SP
Eβ 0
m1 m2 m3 m4
ν = 5 CMPMe CMPM
RE
CM
P
ER
Modelos asumidos
Figura 5-6.: Comparacion de metodos de prediccion en UD. Fuente: Elaboracion propia.
Page 76
56 5 Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson
Tabla 5-6.: Proporcion de ER en un escenario de UD con n = 1000. Fuente: Elaboracion
propia.
UD M
ν m CMP vs Poisson CMP vs PGR PGR vs Poisson YMe vs YM
ν =1.50
m1 1.000 1.000 0.000 1.000
m2 0.557 0.598 0.002 0.997
m3 0.528 0.584 0.001 0.978
m4 0.522 0.657 0.000 0.931
ν =2.50
m1 1.000 1.000 0.003 1.000
m2 0.665 0.693 0.005 0.999
m3 0.546 0.572 0.012 0.990
m4 0.524 0.572 0.012 0.951
ν =5.00
m1 1.000 1.000 0.001 1.000
m2 0.957 0.955 0.616 1.000
m3 0.641 0.628 0.920 0.999
m4 0.546 0.523 0.944 0.992
proporciones similares en los casos mas leves de UD (ν = 1.5 y ν = 2.5); mientras que el en
el caso mas fuerte de UD, ademas de presentar casos totales de menor eficiencia en m1, en
m2 esta proporcion fue superior al 95 %, indicando que los modelos Poisson y PGR obtu-
vieron mayores casos eficiencia respecto al modelo CMP cuando se asumieron valores bajos
de β0. La comparacion entre el modelo Poisson y el PGR muestra que este ultimo obtuvo
los mayores casos de eficiencia en ν = 1.5 y ν = 2.5 y en el caso mas severo de UD, las
proporciones muestran ventajas para el modelo Poisson excepto en m1.
En cuanto a la comparacion de los metodos de prediccion, es claro que los valores ajustados
por medio de la media condicional propuesta para el modelo CMP superan en mayor numero
de casos de eficiencia a aquellos obtenidos por prediccion de medianas.
5.3. Discusion
Los resultados presentados en la seccion anterior mostraron varios componentes de analisis
que son discutidos en esta seccion. Aspectos tanto de la calidad predictiva como de la eva-
luacion del metodo de prediccion mas adecuado para el modelo CMP, son analizados en esta
dentro del marco de la normalidad asintotica de las estimaciones.
Page 77
5.3 Discusion 57
El efecto de los modelos asumidos en el desempeno predictivo indico que a medida que se
aumento el valor asumido para β0, los valores de la RECMP aumentaron, es decir, que dis-
minuyo la calidad de las predicciones en las diferentes propuestas comparadas. Sin embargo,
al mirar el comportamiento de la calidad predictiva se logro percibir que hay una tendencia
a aumentar a medida que la intensidad de la dispersion se incrementa, es decir, que a mayor
nivel de ν se observaron reducciones graduales en los valores de la RECMP, por lo tanto, en
el nivel mas extremo de OD se presentaron los valores mas bajos y en el nivel mas alto de
UD se experimentaron los valores mas altos de calidad predictiva a traves de los diferentes
modelos asumidos.
El contraste entre las propuestas de analisis de datos de conteo marcaron algunos resultados
relevantes. Uno de ellos, se relaciona con la comparacion que es objeto de esta disertacion.
El desempeno predictivo entre el modelo CMP y el modelo Poisson en el marco de la norma-
lidad asintotica de las estimaciones determino que unicamente en el caso de OD mas severo
y cuando se definieron los modelos asumidos m2 y m3, las predicciones de media del modelo
CMP fueron ligeramente mas eficientes que las del modelo Poisson. El modelo CMP presento
un desempeno deficiente de sus predicciones especialmente cuando se asumio el valor mas
bajo para el intercepto, siendo el nivel de OD mas fuerte la evidencia mas clara ya que allı
fueron mucho mas eficientes las predicciones de los modelos Poisson y BN. En UD tambien
se detecto un bajo desempeno de las predicciones del modelo CMP en valores bajos asumidos
para β0 pero en una escala menor a la presentada en OD. Tambien este resultado concuerda
con lo expresado por Francis et al. [9], en donde se concluye que el modelo reparametrizado
CMP MLG tiene un desempeno deficiente o limitado en OD cuando se asumieron valores
bajos para β0.
Respecto a la comparacion del modelo BN con el modelo CMP, se destaca la eficiencia en OD
extrema que hay a favor de la calidad predictiva de este ultimo, excepto cuando se asumio
el valor mas bajo para el intercepto. En los escenarios de OD mas cercanos a la ED ya no se
marcan eficiencias a favor de uno u otro modelo. Lo mismo sucedio al establecer la ER entre
los modelos BN y Poisson, donde solo en el caso mas fuerte de OD las predicciones logradas
por el modelo BN obtuvieron mejor desempeno predictivo. El modelo CMP comparado con
el modelo PGR en UD, solo logro ser mas eficiente justo donde las predicciones de media
tuvieron limitaciones, es decir, cuando se asumieron valores bajos para β0. Tanto en ED como
en UD, no se logro determinar una eficiencia marcada entre los modelos PGR y Poisson, ya
que su ER fue muy cercana a 1 en todos los escenarios configurados, a pesar de que la
proporcion de casos de eficiencia fue a favor del modelo PGR en los niveles de UD menos
fuertes, lo cual no se dio cuando se asumio un valor para ν de 5. Esto puede evidenciar
la limitacion que senalan Sellers & Shmueli [32], respecto al modelo PGR, en donde dicha
propuesta es una alternativa para ajustar datos de conteo en UD pero en un rango no tan
flexible como lo hace el modelo CMP.
Page 78
58 5 Eficiencia Relativa de la predicciones entre los modelos CMP y Poisson
En cuanto a la comparacion de los metodos de prediccion propuestos para el modelo CMP,
el unico caso donde las predicciones de mediana fueron mas eficientes que las logradas por
la aproximacion a la media, se dio en el escenario de OD mas extrema en m1. En el resto de
los casos incluso en UD, los valores ajustados obtenidos por medio de la media condicional
fueron mas eficientes, con una ligera tendencia a reducir la brecha en la calidad predictiva al
aumentar el valor asumido de β0. Sellers & Shmueli [32] proponen el metodo de prediccion
de medianas como una alternativa generalizada para obtener valores ajustados, ya que se
obtienen cifras enteras y por la naturaleza de la mediana, esta es una medida de tendencia
central mas robusta en distribuciones sesgadas [33]. Sin embargo, al parecer esta propuesta
no logra ser mas eficiente incluso cuando las predicciones de media segun Sellers & Shmue-
li [32] son de baja calidad, es decir, cuando ν > 1, por lo tanto, aun en UD en donde se
presumıa que las predicciones de mediana lograrıan cierta ventaja, estas no obtuvieron un
desempeno predictivo suficiente para minimizar la baja calidad de la aproximacion de la
media condicional en este escenario de dispersion.
5.4. Conclusiones
La comparacion entre la calidad predictiva del modelo CMP y el modelo Poisson fue eva-
luada mediante un estudio de simulacion en el cual se tuvieron en cuenta factores como
la intensidad de la dispersion y la variacion del intercepto expresada mediante los modelos
asumidos, en un marco donde el tamano muestral fue lo suficientemente grande para ası
asegurar la normalidad asintotica de las estimaciones logradas por las diferentes propuestas
para ajustar datos de conteo. Los resultados que fueron objeto de analisis en la anterior
discusion arrojaron las conclusiones descritas a continuacion.
Debido al desempeno limitado que tuvo el modelo CMP en cuanto a sus predicciones espe-
cialmente en el escenario mas severo de OD cuando se asumio el valor mas bajo de β0, la ER
entre este modelo y el modelo Poisson fue a favor de este ultimo. En esa misma intensidad
de dispersion, en los unicos casos que el modelo CMP logro ser mas eficiente fue en m2 y m3.
Mientras que en las intensidades mas cercanas a la ED, no se logro establecer una eficiencia
marcada de un modelo respecto al otro. En UD, se detecto una eficiencia leve a favor del
modelo Poisson a traves de las diferentes intensidades de dispersion y especıficamente en m1.
La propuesta de Sellers & Shmueli [32] logro en algunos casos ser mas eficiente y en otros no
tanto, respecto a los modelos BN y PGR. El modelo CMP obtuvo una mayor eficiencia de las
predicciones sobre las del modelo BN en el caso mas fuerte de OD, pero cuando la intensidad
de OD fue mas cercana a 1, y en la misma ED, las diferencias en desempeno predictivo ya no
fueron tan notorias. Mientras que en UD, se lograron percibir eficiencias a favor del modelo
PGR en m1.
Page 79
5.4 Conclusiones 59
La calidad predictiva fue afectada por la variacion del intercepto en los diferentes modelos
asumidos logrando una menor calidad en las predicciones cada vez que aumentaba el valor
asumido para β0. Tambien se percibio un efecto de la intensidad de la dispersion experimen-
tando una reduccion gradual de los valores de la RECMP a medida que el valor asumido
para el parametro de dispersion fue mayor.
Incluso en UD donde se esperaba un mejor desempeno de las predicciones de mediana, estas
no lograron la suficiente calidad predictiva para superar a la de las predicciones logradas
por la aproximacion de la media condicional de la distribucion CMP. Particularmente, en
el caso de OD extrema cuando se asumio el valor mas bajo para el intercepto el comporta-
miento de las predicciones logrado por el metodo de prediccion de medianas supero a la de
las predicciones de media, por lo tanto, solo serıa recomendable utilizar esta propuesta en
este escenario.
Page 80
6. Aplicacion con datos reales en la
ecologıa
El objetivo de este capıtulo es evaluar la calidad tanto de las predicciones de media como
de mediana en las distribuciones que han sido comparadas en los capıtulos anteriores por
medio de dos casos de estudio reales aplicados dentro del campo de la ecologıa. El primer
caso consiste en la prediccion de la abundancia de una especie de interes en terminos algunas
variables ambientales, lo cual es un proceso de analisis esencial a la hora de tomar decisiones
de manejo y conservacion silvestre en lugares donde no se ha hecho un muestreo previo.
El segundo caso se desarrolla dentro del contexto del estudio de fauna silvestre ya que se
trata de establecer la relacion entre el tamano del nido en aves (asociado con el numero de
huevos por nido) y las caracterısticas morfologicas de las especies observadas y ası configu-
rar estrategias de produccion sostenible y/o de conservacion basadas en la caracterizacion
del potencial de crecimiento de un conjunto de aves con caracterısticas taxonomicas similares.
Este capıtulo tiene la siguiente estructura. La Seccion 6.1 da a conocer los diferentes proce-
dimientos que se llevaron a cabo en cada uno de los estudios de caso. En la Seccion 6.2 se
presentan los resultados obtenidos luego de obtener las diferentes medidas estadısticas que
seran objeto de discusion en la Seccion 6.3. Finalmente, en la Seccion 6.4 se presentan las
conclusiones mas relevantes que lograron los estudios de caso planteados para este capıtulo.
6.1. Metodologıa
Esta seccion da a conocer los procesos que se realizaron de forma general para los estudios de
caso planteados. Las bases de datos que son descritas en la Subseccion 6.1.1 fueron filtradas
de tal forma que se pudiera resumir la informacion que fue considerada en cada caso. A los
conjuntos de datos resultantes se les ajustaron los modelos que fueron objeto de compara-
cion en los anteriores capıtulos utilizando la configuracion presentada en la Subseccion 3.3.3
y luego se calcularon las medidas estadısticas descritas en la Seccion 3.4 con el fin de evaluar
tanto la calidad de las estimaciones ası como de las predicciones. Tambien se tuvieron en
cuenta los aspectos definidos en la Seccion 3.1 para realizar los analisis estadısticos y las
recomendaciones de uso de la implementacion mas adecuada en R [27, R Core Team 2016]
Page 81
6.1 Metodologıa 61
para ajustar modelos CMP del Capıtulo 4.
6.1.1. Descripcion de los datos
Los procedimientos que se realizaron para la coleccion de informacion son descritos de forma
resumida para cada uno de los estudios de caso planteados. Aun ası, en el caso de que se
quiera profundizar sobre los aspectos metodologicos y el contenido de los conjuntos de datos
obtenidos se recomienda consultar los trabajos de Ramesh et al. [28] y Myhrvold et al. [25],
en donde se encuentra la informacion detallada de cada uno de los estudios efectuados res-
pectivamente. Hay que senalar que estas dos bases de datos consultadas hacen parte de The
Ecological Society of America (ESA) la cual publica material complementario de sus artıculos
en Ecological Archives con licencia de Creative Commons Atribucion 4.0 Internacional .
Descripcion del estudio de abundancia
La informacion tenida en cuenta para este estudio de caso esta contenida en un conjunto de
datos en donde se determino la abundancia de especies de plantas lenosas en un total de 96
parcelas de muestreo distribuidas a traves de un area que tiene una superficie de unos 22,000
km2, considerada como una region con una gran biodiversidad por Myers et al. [24] y la cual
esta localizada al suroeste de la India (Figura 6-1).
Fuente: Ramesh et al. [28]
Figura 6-1.: Localizacion del area de muestreo del estudio de abundancia.
Page 82
62 6 Aplicacion con datos reales en la ecologıa
Las parcelas de muestreo fueron establecidas entre los anos 1996 y 1997 dentro el marco
de un proyecto de colaboracion entre el Departamento Forestal de Karnataka y el Instituto
Frances de Pondicherry. Estas tienen una hectarea de tamano (100 × 100 m) y se encuentran
en diversos tipos de bosque definidos por una serie de condiciones ambientales caracterısticas
de cada uno. En total fueron registrados 61965 individuos de 400 especies de arboles y lianas
con una circunferencia a la altura del pecho (CAP) igual o superior a 10 cm. Tambien se
midieron tanto parametros estructurales de los bosques, ası como variables bioclimaticas [28].
Para obtener las predicciones de abundancia, se eligio una especie de interes que es nativa
y por lo tanto, se presenta de forma silvestre en la India. El arbol de mango (Mangifera
indica) ademas de ser conocido por su fruto que es exportado a muchos paıses, tiene un uso
maderable para construir mueblerıa de bajo costo; tambien es muy utilizado en el campo de
la medicina por sus propiedades astringentes [12]. El estudio de caso planteado consistio en
estimar las existencias por hectarea que hay de esta especie de forma silvestre dadas unas
condiciones de ambientales definidas por el numero de estratos del bosque y la duracion en
meses de la epoca de sequıa. Dado esto, el conjunto de datos para este analisis contiene 96
observaciones correspondientes las mediciones en cada una de las parcelas de muestreo para
cada una de las variables consideradas.
Descripcion del estudio del tamano del nido
La base de datos utilizada para este estudio de caso fue aquella que contenıa los registros
dados unicamente para aves. En general, el conjunto de datos total es una compilacion de
una serie de investigaciones y publicaciones relacionadas con el estudio de especies de aves,
reptiles y mamıferos. Dada la carencia de estandarizacion en la clasificacion taxonomica y la
medicion de las variables en las diferentes fuentes consultadas fue necesario crear una base
de datos general que facilite los analisis comparativos de los parametros medidos para los
tres grupos de que conforman el clado de los amniotas. Como resultado final de este proceso
de normalizacion se obtuvo un conjunto de datos con 29 parametros de la historia de vida
para 21322 especies de los amniotas [25].
Para la base de datos de aves se planteo estudiar la relacion del tamano del nido que es una
medida asociada con el numero de huevos por nido, respecto a la masa del huevo y al peso
de la hembra en gramos. Para ello se filtro la informacion respectiva para el analisis de la
base de datos general y se considero realizar el estudio especıficamente en especies del orden
de los Passeriformes. Este conjunto de datos tiene un total de 2061 observaciones para cada
una de las tres variables consideradas para este estudio.
Page 83
6.2 Resultados 63
6.2. Resultados
Esta seccion presenta en dos partes los resultados de la calidad predictiva de las distribu-
ciones comparadas durante este trabajo. La primera parte da a conocer los contrastes de
la calidad de las predicciones para el estudio de abundancia. La segunda parte presenta las
medidas estadısticas que evaluan el desempeno predictivo en el estudio del tamano del nido
en aves.
6.2.1. Para el estudio de abundancia
La informacion que presenta la Tabla 6-1 es el resumen de las estimaciones de los parametros
de los diferentes modelos ajustados. En primer lugar se logro diagnosticar que la variable
de conteo tiene una varianza mayor que la media y por lo tanto el parametro de dispersion
estimado por el modelo CMP cae en el rango de OD. Al comparar los coeficientes de estimados
se nota la gran diferencia que obtuvieron los coeficientes estimados y sus respectivos errores
estandar (ES) en el modelo CMP luego de ser escalados. Tambien se logro identificar que los
ES obtenidos por el modelo Poisson fueron los mas bajos en contraste con los de las demas
distribuciones.
Tabla 6-1.: Resumen de las estimaciones en los modelos comparados en el estudio de abun-
dancia. Fuente: Elaboracion propia.
Modeloβ0 β1 β2 Dispersion
β0 σβ0 β1 σβ1 β2 σβ2 φ σφ
Poisson -5.9071 1.0324 0.8820 0.0735 0.7693 0.1642 – –
CMPa -13636.9261ν 4178.7752ν 1337.6726ν 331.7317ν 1283.5193ν 677.7827ν 0.0001 11.8296
BN -5.8599 2.1009 0.9914 0.1865 0.7069 0.3340 0.5072 0.2142
PGR -5.6810 2.0868 1.0419 0.2089 0.6540 0.3278 0.5844 0.1071
aLos coeficientes y sus ES estan divididos por ν (excepto los de dispersion) ya que segun Sellers & Shmueli [32] deben
ser escalados para ser comparados con los de la regresion Poisson
La Tabla 6-2 presenta las diferentes medidas que se adoptaron para evaluar la calidad de
las predicciones en el estudio de la abundancia de la especie Mangifera indica. Se nota que
el modelo Poisson fue el que obtuvo el mejor desempeno tanto en la calidad de las predic-
ciones de media como de mediana respecto a las demas distribuciones. Tambien se resalta la
calidad deficiente de las predicciones de media del modelo CMP debido a sus valores altos
de RECMP y EPAMe, lo cual no sucede con las predicciones de mediana en donde si bien
no presentaron un buen desempeno es considerable la diferencia que marca este metodo res-
pecto al de los valores ajustados obtenidos mediante la aproximacion a la media condicional
propuesta para esta distribucion.
Page 84
64 6 Aplicacion con datos reales en la ecologıa
Tabla 6-2.: Calidad de las predicciones en los modelos comparados en el estudio de abun-
dancia. Fuente: Elaboracion propia.
MedidaPoisson CMP BN PGR
M Me M Me M Me M Me
RECMP 4.227 4.180 3447.570 4.460 4.285 4.596 4.341 4.775
EPAMe 5.850 3.000 3449.608 1.000 6.808 0.955 7.465 1.000
6.2.2. Para el estudio del tamano del nido en aves
Para este conjunto de datos se diagnostico UD, dado que el parametro de forma estimado
por el modelo CMP fue de 1.815. La comparacion de las estimaciones y sus respectivos ES
marca una similaridad entre aquellas obtenidas por el modelo Poisson y el modelo BN.
Tabla 6-3.: Resumen de las estimaciones en los modelos comparados en el estudio del ta-
mano del nido en aves. Fuente: Elaboracion propia.
Modeloβ0 β1 β2 Dispersion
β0 σβ0 β1 σβ1 β2 σβ2 φ σφ
Poisson 1.2283 0.0185 -0.0312 0.0067 0.0013 0.0003 – –
CMPa 1.2925ν 0.0471ν -0.0279ν 0.0049ν 0.0011ν 0.0002ν 1.8151 0.0020
BN 1.2283 0.0185 -0.0312 0.0067 0.0013 0.0003 13903.3396 0.0585
PGR 1.2317 0.0181 -0.0329 0.0066 0.0013 0.0003 0.9895 0.0046
aLos coeficientes y sus ES estan divididos por ν (excepto los de dispersion) ya que segun Sellers &
Shmueli [32] deben ser escalados para ser comparados con los de la regresion Poisson
Tabla 6-4.: Calidad de las predicciones en los modelos comparados en el estudio del tamano
del nido en aves. Fuente: Elaboracion propia.
MedidaPoisson CMP BN PGR
M Me M Me M Me M Me
RECMP 1.602 1.638 1.603 1.639 1.602 1.638 1.601 1.639
EPAMe 0.328 0.400 0.327 0.400 0.328 0.400 0.326 0.400
Tambien se logro detectar ciertas diferencias en los ES del modelo CMP respecto a las otras
distribuciones, especialmente en las estimaciones de β0 y β1. En la estimacion del parametro
de dispersion del modelo BN se presento el ES mas elevado, mientras que el del modelo CMP
Page 85
6.3 Discusion 65
fue el mas bajo.
Las predicciones de media del numero de huevos de aves de la orden Passeriformes evaluadas
mediante la RECMP y el EPAMe indican que la distribucion PGR obtuvo el mejor desem-
peno mientras que en las predicciones de mediana los modelos Poisson y BN obtuvieron la
mejor calidad predictiva en cuanto a la RECMP, lo que no sucedio en el EPAMe donde no se
logro diferenciar un desempeno a favor o en contra entre los modelos comparados (Tabla 6-4).
6.3. Discusion
Los resultados que se presentaron en el estudio de las predicciones de abundancia de la especie
Mangifera indica reflejan las consecuencias de un caso de OD extrema ya que el parametro
de dispersion estimado por el modelo CMP al parecer tuvo problemas en su estimacion. Este
comportamiento fue muy comun en el escenario mas severo de OD asumido en las simula-
ciones, en donde con tamanos muestrales pequenos y en valores muy bajos asumidos para
el intercepto dicho parametro presento problemas en su estimacion obteniendo valores muy
cercanos a cero. Al dividir los coeficientes y sus respectivos ES por el valor de ν tal como lo
proponen Sellers & Shmueli [32], se obtuvieron coeficientes sobrestimados en comparacion
con los obtenidos por las demas distribuciones.
Otro aspecto que se evidencia en los resultados es la subestimacion de los ES asociados a los
coeficientes del vector de β en el modelo Poisson. Tal como lo senalan Cameron & Trivedi
[3], una de las consecuencias de ajustar un modelo Poisson en OD es que los ES tienden a
ser subestimados generando coeficientes significativos cuando en realidad estos no lo son.
En cuanto a la calidad de las predicciones, es claro que el modelo Poisson es el que me-
jor desempeno logro. Debido a las estimaciones deficientes que produjo el modelo CMP,
especialmente del parametro de dispersion, las predicciones obtenidas a traves de la apro-
ximacion a la media condicional presentaron valores muy bajos de desempeno predictivo,
lo que contrasto con lo obtenido por el metodo de estimacion de medianas. Esto corrobora
los resultados de las simulaciones previas en donde definitivamente no es conveniente usar la
aproximacion de la media en casos de OD extrema y con valores muy bajos para el intercepto.
El estudio del tamano del nido en especies de aves del orden los Passeriformes, demostro ser
coherente con los resultados presentados en los estudios de simulacion. En primera instancia,
el nivel de dispersion estimado por el modelo CMP indico que los conteos del numero de
huevos tuvo una media mayor que la varianza aunque no tan contrastantes ya que ν fue
muy cercano a 1. Considerando el alto numero de observaciones con el cual se puede asegu-
rar la normalidad asintotica de las estimaciones y que los interceptos estimados son bajos,
Page 86
66 6 Aplicacion con datos reales en la ecologıa
se puede deducir que el desempeno del modelo CMP no fue tan bueno como el del mode-
lo Poisson e incluso del modelo BN que logro una calidad en las predicciones de media similar.
A pesar del buen desempeno del modelo Poisson respecto al modelo CMP, para el conjunto
de datos considerado en el estudio de aves, la distribucion PGR fue la que mejor calidad de
prediccion de medias obtuvo. Lo anterior, se puede explicar ya que esta distribucion captura
correctamente un rango parcial de UD [32], por lo tanto, en un nivel bajo de UD se esperarıa
un buen desempeno en su calidad predictiva. De igual forma, vale la pena indicar que a
partir de la tercera cifra decimal se empezaron a notar las diferencias entre las distribuciones
contrastadas. Lo mismo sucedio con la estimacion de medianas, pero ya las diferencias fueron
a favor de los modelos BN y Poisson.
6.4. Conclusiones
Por medio de datos reales aplicados en el campo de la ecologıa, se trato de implementar va-
rias propuestas para el analisis de datos de conteo y por medio de la evaluacion de la calidad
predictiva se definieron cuales de ellas logran un buen desempeno para ser adoptadas dentro
del procedimiento para configurar estrategias de produccion sostenible y/o de conservacion
segun el enfoque de cada estudio.
Un estudio de abundancia de la especie Mangifera indica la cual es nativa de la India, indico
segun la base de datos analizada, que el numero de individuos por hectarea dado un numero
de estratos en el bosque y una duracion en meses de la epoca de sequıa puede obtener me-
jores predicciones si se ajusta un modelo Poisson incluso utilizando el metodo de estimacion
de medianas. Por lo tanto, el modelo CMP no serıa recomendable ya que fue muy limitado
a la hora de obtener valores ajustados a traves de su aproximacion a la media dadas las
caracterısticas de OD extrema, de bajos valores estimados para el intercepto y un tamano
muestral insuficiente.
En el estudio del tamano del nido en especies del orden de los Passeriformes se diagnostico
un nivel de UD no tan fuerte ya que los valores entre la media y la varianza del numero de
huevos por nido fueron ligeramente similares. Para determinar el potencial de crecimiento de
este conjunto de aves mediante la prediccion del numero de huevos por nido en terminos del
peso del huevo y el de la hembra en gramos, se recomienda utilizar el modelo PGR, aunque
las diferencias en el comportamiento predictivo con las demas distribuciones no fueron tan
marcadas. Las condiciones de un gran tamano muestral, ademas de un bajo nivel de UD
y de un valor bajo para el intercepto estimado fueron propicias para que la propuesta que
pertenece a la familia de las distribuciones Poisson generalizadas tuviera tal desempeno.
Page 87
7. Conclusiones y recomendaciones
Se realizaron varios estudios de simulacion con el fin de caracterizar la calidad de las predic-
ciones del modelo CMP y el Poisson y ası determinar la perdida en eficiencia al ajustar el
modelo inadecuado ya sea en OD o en UD. A continuacion se presentan las conclusiones y
recomendaciones que arrojo esta investigacion.
7.1. Conclusiones
Ya sea en OD o UD, el ajustar un modelo inadecuado, en este caso el modelo Poisson, no se
incurre en una perdida en la calidad predictiva incluso en escenarios con OD y UD fuertes.
Por lo tanto, se concluye que en la mayorıa de los escenarios, el modelo Poisson fue tan
eficiente como el modelo CMP en terminos de calidad de las predicciones. Si bien en el nivel
de OD mas fuerte, hubo dos escenarios que representaron una ligera eficiencia a favor de las
predicciones del modelo CMP, esto no justifica su uso generalizado, ya que cuando se asu-
mieron valores bajos para el intercepto fue claramente ineficiente, particularmente en el nivel
mas alto de OD e incluso comparado con el modelo BN. En UD, se presento un resultado
similar aunque no tan notorio como en OD. La ineficiencia detectada en las predicciones de
media del modelo CMP a bajos valores de β0 tambien es una evidencia de que el modelo
inadecuado lograra una mayor eficiencia o una ganancia en el desempeno predictivo. Pero
cuando el valor asumido por el intercepto fue en aumento es casi imperceptible la eficiencia
de una u otra distribucion.
La caracterizacion del desempeno de las estimaciones en el modelo CMP mostro que esta
distribucion es muy limitada en escenarios donde la varianza en considerablemente mayor
que la media. La calidad de las estimaciones de los parametros del vector de β y en espe-
cial del parametro de dispersion, se vieron afectadas por los bajos tamanos muestrales al no
asegurar la normalidad asintotica de los estimadores. Esto produjo estimaciones para ν muy
cercanas a cero y por lo tanto muy desviadas del verdadero valor asumido.
Los factores de la variacion del intercepto ası como de la intensidad de dispersion marcaron
un efecto sobre la calidad de las predicciones. Al aumentar los valores asumidos para β0se experimento una menor calidad de las predicciones, mientras que al reducir el nivel de
dispersion, es decir, cuando ν fue mas cercano a cero, la calidad predictiva logro igualmente
Page 88
68 7 Conclusiones y recomendaciones
una perdida. Por lo tanto, un mayor desempeno predictivo es favorecido cuando el nivel de
dispersion representado por el parametro ν, es mas lejano a cero y cuando los valores asu-
midos para el intercepto son bajos.
Complementando la comparacion de las distribuciones en cuanto a su desempeno predictivo,
se evaluo la bondad de ajuste por medio del CIA. Los resultados se pueden consultar en
el Apendice D. Allı se puede observar la capacidad que tiene el modelo CMP para explicar
la relacion funcional entre una respuesta de conteo y las variables predictoras, respecto las
otras distribuciones contrastadas. Unicamente en el nivel de ED, el modelo Poisson presento
ventajas en cuanto a la bondad de ajuste, de resto en OD y UD la distribucion con mejor
desempeno incluso en los niveles de dispersion mas fuertes fue la CMP. Por lo tanto, se
concluye que al parecer el modelo CMP no representa una mayor eficiencia a la hora de
hacer predicciones, sin embargo, este posee ventajas en cuanto a su capacidad de explicar
una relacion funcional.
7.2. Recomendaciones
Para realizar predicciones de una variable de conteo sea cual sea el nivel de dispersion diag-
nosticado, se recomienda utilizar el modelo Poisson ya que en la mayorıa de los casos obtuvo
un desempeno similar o mejor en la calidad de las predicciones y por ende es mas eficiente no
solo a nivel predictivo sino en terminos de demanda computacional. A menos de que se quiera
explicar la relacion funcional en OD o en UD entre una respuesta de conteo y sus variables
predictoras, se recomienda usar la distribucion CMP ya que presento un mejor desempeno
en cuanto a la bondad de ajuste.
En el caso de optar por el ajuste de un modelo CMP en R [27, R Core Team 2016], la
implementacion mas adecuada para OD serıa la funcion glm.comp pero con el limitante de
que no se puede ajustar conjuntos de datos donde al menos un valor de la respuesta mas un
umbral de 10 exceda el valor configurado para el argumento SumTo (Yi + 10 > 100). Si es
este el caso, entonces se podrıa aumentar el valor de SumTo o usar la funcion cmp teniendo en
cuenta que esta tiene una mayor demanda computacional. En UD, se recomienda de forma
generalizada usar la funcion cmp ya que obtuvo las estimaciones de mejor calidad, mientras
que la funcion glm.comp se deberıa usar exclusivamente en valores bajos del intercepto.
Luego del ajuste del modelo CMP tomando en cuenta la anterior recomendacion, se sugiere
utilizar el metodo de prediccion de medianas unicamente para el caso que se diagnostique
una fuerte OD y en valores bajos para el intercepto. De resto, la aproximacion a la media
condicional serıa el metodo de prediccion adecuado incluso cuando ν > 1, en donde segun
Sellers & Shmueli [32] las predicciones de media serıan de baja calidad.
Page 89
7.3 Trabajo futuro 69
7.3. Trabajo futuro
Siguiendo la misma lınea de investigacion y dados los resultados en cuanto a lo limitante
que fue la calidad predictiva del modelo CMP, se propone un estudio a futuro para evaluar
el comportamiento a nivel predictivo del modelo reparametrizado CMP MLG propuesto por
Guikema & Goffelt [13] y la nueva alternativa planteada por Saez & Conde [30] como lo es
el caso de la regresion hP, ya que al menos en las aplicaciones con datos reales desarrolla-
das en su artıculo, se lograron estimaciones de mejor calidad a pesar de su gran demanda
computacional, que tambien serıa un aspecto interesante para estudiar.
Page 90
A. Anexo: Errores estandar
inconsistentes entre las funciones
glm.comp y cmp
> library(CompGLM);library(COMPoissonReg)
> set.seed(561)
> db <- simData(100, 1.6, -0.5, 0.5, v = 1) # Generar base de datos
> CMP_glm <- glm.comp(y ~ x1 + x2, data = db) # Ajuste glm.comp
> summary(CMP_glm) # Resumen del modelo para mostrar glm.comp ES
Call:
glm.comp(lamFormula = y ~ x1 + x2, data = db)
Beta:
Estimate Std.Error t.value p.value
(Intercept) 1.69241 0.15514 10.9092 < 2.2e-16 ***
x1 -0.69876 0.30427 -2.2965 0.0238211 *
x2 0.71741 0.18654 3.8458 0.0002162 ***
Zeta:
Estimate Std.Error t.value p.value
(Intercept) 0.083821 0.192428 0.4356 0.6641
AIC: 434.8594
Log-Likelihood: -213.4297
> CMP_cmp <- cmp(y ~ x1 + x2, data = db) # Ajuste cmp
(Intercept) x1 x2
1.5470236 -0.6484555 0.6657879
Page 91
71
> sdev(CMP_cmp) # cmp ES
(Intercept) x1 x2 nu
0.3042728 0.1865441 0.1924286 0.1686995
Notese en el resumen del modelo de la funcion glm.comp que el error estandar de β1 es simi-
lar al error estandar para β0 de la funcion cmp, el error estandar de β2 es parecido al error
estandar para β1 de la funcion cmp y el error estandar de ζ es equivalente al error estandar
para β2 de la funcion cmp.
Page 92
B. Anexo: Distribucion empırica de β0 en
un modelo de regresion COM-Poisson
β0
Den
sida
d
0
1
2
3
4
5 β0 = 0.1 n = 50
β0
Den
sida
d
β0 = 1.6 n = 50
β0
Den
sida
d
β0 = 2.3 n = 50
β0 D
ensi
dad
β0 = 3.0 n = 50
β0
Den
sida
d
0
1
2
3
4
5 β0 = 0.1 n = 100
β0
Den
sida
d
β0 = 1.6 n = 100
β0
Den
sida
d
β0 = 2.3 n = 100
β0
Den
sida
d
β0 = 3.0 n = 100
β0
Den
sida
d
0
1
2
3
4
5 β0 = 0.1 n = 200
β0
Den
sida
d
β0 = 1.6 n = 200
β0
Den
sida
d
β0 = 2.3 n = 200
β0
Den
sida
d
β0 = 3.0 n = 200
β0
Den
sida
d
0
1
2
3
4
5 β0 = 0.1 n = 500
β0
Den
sida
d
β0 = 1.6 n = 500
β0
Den
sida
d
β0 = 2.3 n = 500
β0
Den
sida
d
β0 = 3.0 n = 500
β0
Den
sida
d
0
1
2
3
4
5
−2 −1 0 1 2
β0 = 0.1 n = 1000
β0
Den
sida
d
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5
β0 = 1.6 n = 1000
β0
Den
sida
d
1 2 3 4 5
β0 = 2.3 n = 1000
β0
Den
sida
d
1 2 3 4 5 6 7
β0 = 3.0 n = 1000
Den
sida
d
β0
Figura B-1.: Grafico de distribucion empırica de β0 en un modelo de regresion COM-Poisson
en diferentes tamanos muestrales. Fuente: Elaboracion propia.
Page 93
73
β0
Den
sida
d
0
2
4
6
8
10
12
14
16
18
20
−0.5 −0.3 −0.1 0.1 0.3 0.5
β0 = 0.1 n = 1000
β0
Den
sida
d
1.45 1.50 1.55 1.60 1.65 1.70 1.75
β0 = 1.6 n = 1000
β0
Den
sida
d
2.15 2.20 2.25 2.30 2.35 2.40 2.45
β0 = 2.3 n = 1000
β0
Den
sida
d
2.92 2.94 2.96 2.98 3.00 3.02 3.04 3.06 3.08
β0 = 3.0 n = 1000
Den
sida
d
β0
Figura B-2.: Grafico de distribucion empırica de β0 en un modelo de regresion COM-Poisson
con n = 1000. Fuente: Elaboracion propia.
Page 94
C. Anexo: Resumen de las simulaciones
del Capıtulo 5
Tabla C-1.: Resumen de las simulaciones para ν asumido de 0.25 con n = 1000. Fuente:
Elaboracion propia.
ν = 0.25 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 1.2897 4.2057 6.1962 9.1915
CMP 1.4946 4.1922 6.1722 9.2145
BN 1.2899 4.2194 6.2334 9.2493
DE
Poisson 0.0468 0.1230 0.1724 0.2486
CMP 0.2968 0.1233 0.1726 0.2592
BN 0.0468 0.1246 0.1763 0.2541
Mın
Poisson 1.1618 3.8483 5.6965 8.4509
CMP 1.1812 3.8271 5.6783 8.4653
BN 1.1620 3.8488 5.6989 8.4508
Max
Poisson 1.4713 4.6298 6.7696 10.0835
CMP 4.3653 4.6092 6.7337 10.1543
BN 1.4720 4.6662 6.8754 10.2679
Page 95
75
Tabla C-2.: Resumen de las simulaciones para ν asumido de 0.5 con n = 1000. Fuente:
Elaboracion propia.
ν = 0.5 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 1.1776 2.9142 4.3477 6.4754
CMP 1.1806 2.9143 4.3474 6.4753
BN 1.1776 2.9147 4.3485 6.4767
DE
Poisson 0.0372 0.0725 0.1023 0.1486
CMP 0.0399 0.0726 0.1023 0.1487
BN 0.0372 0.0725 0.1024 0.1488
Mın
Poisson 1.0681 2.7012 4.0566 6.0687
CMP 1.0680 2.7005 4.0565 6.0683
BN 1.0681 2.7014 4.0566 6.0690
Max
Poisson 1.3055 3.1924 4.7255 7.0230
CMP 1.3738 3.1885 4.7214 7.0183
BN 1.3059 3.1950 4.7295 7.0291
Tabla C-3.: Resumen de las simulaciones para ν asumido de 0.75 con n = 1000. Fuente:
Elaboracion propia.
ν = 0.75 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 1.1078 2.5869 3.6099 5.0287
CMP 1.1079 2.5869 3.6099 5.0286
BN 1.1079 2.5870 3.6100 5.0288
DE
Poisson 0.0319 0.0605 0.0819 0.1117
CMP 0.0320 0.0605 0.0819 0.1117
BN 0.0319 0.0605 0.0819 0.1118
Mın
Poisson 1.0234 2.4003 3.3634 4.7113
CMP 1.0234 2.4003 3.3634 4.7114
BN 1.0234 2.4003 3.3634 4.7114
Max
Poisson 1.2183 2.8093 3.9140 5.4408
CMP 1.2191 2.8084 3.9131 5.4400
BN 1.2185 2.8099 3.9148 5.4418
Page 96
76 C Anexo: Resumen de las simulaciones del Capıtulo 5
Tabla C-4.: Resumen de las simulaciones para ν asumido de 1 con n = 1000. Fuente: Ela-
boracion propia.
ν = 1.0 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 1.0569 2.2380 3.1738 4.5118
CMP 1.0570 2.2380 3.1738 4.5118
PGR 1.0569 2.2380 3.1738 4.5118
DE
Poisson 0.0288 0.0524 0.0724 0.1018
CMP 0.0288 0.0524 0.0724 0.1018
PGR 0.0289 0.0524 0.0725 0.1018
Mın
Poisson 0.9529 2.0788 2.9219 4.2090
CMP 0.9533 2.0788 2.9219 4.2090
PGR 0.9529 2.0788 2.9219 4.2090
Max
Poisson 1.1558 2.4455 3.4147 4.8152
CMP 1.1556 2.4453 3.4147 4.8153
PGR 1.1558 2.4456 3.4147 4.8153
Tabla C-5.: Resumen de las simulaciones para ν asumido de 1.5 con n = 1000. Fuente:
Elaboracion propia.
ν = 1.5 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 0.9705 1.8780 2.6168 3.6469
CMP 0.9709 1.8780 2.6168 3.6469
PGR 0.9705 1.8779 2.6168 3.6469
DE
Poisson 0.0236 0.0423 0.0581 0.0798
CMP 0.0236 0.0423 0.0581 0.0798
PGR 0.0236 0.0423 0.0581 0.0798
Mın
Poisson 0.8878 1.7468 2.4336 3.4166
CMP 0.8886 1.7466 2.4336 3.4165
PGR 0.8878 1.7467 2.4336 3.4166
Max
Poisson 1.0573 2.0408 2.8199 3.9358
CMP 1.0574 2.0409 2.8200 3.9358
PGR 1.0573 2.0408 2.8198 3.9357
Page 97
77
Tabla C-6.: Resumen de las simulaciones para ν asumido de 2.5 con n = 1000. Fuente:
Elaboracion propia.
ν = 2.5 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 0.7875 1.4625 2.0937 2.8228
CMP 0.7883 1.4625 2.0937 2.8228
PGR 0.7875 1.4624 2.0937 2.8228
DE
Poisson 0.0179 0.0326 0.0459 0.0622
CMP 0.0180 0.0326 0.0459 0.0622
PGR 0.0179 0.0326 0.0459 0.0622
Mın
Poisson 0.7232 1.3423 1.9530 2.6228
CMP 0.7239 1.3422 1.9529 2.6229
PGR 0.7232 1.3423 1.9529 2.6228
Max
Poisson 0.8634 1.5822 2.2576 3.0409
CMP 0.8644 1.5822 2.2577 3.0410
PGR 0.8634 1.5821 2.2575 3.0408
Tabla C-7.: Resumen de las simulaciones para ν asumido de 5 con n = 1000. Fuente: Ela-
boracion propia.
ν = 5.0 RECMP
Medida Modelo m1 m2 m3 m4
M
Poisson 0.5302 1.0441 1.4808 1.9978
CMP 0.5303 1.0441 1.4808 1.9978
PGR 0.5297 1.0441 1.4808 1.9978
DE
Poisson 0.0142 0.0229 0.0324 0.0440
CMP 0.0142 0.0229 0.0324 0.0440
PGR 0.0142 0.0229 0.0324 0.0440
Mın
Poisson 0.4795 0.9745 1.3842 1.8614
CMP 0.4796 0.9745 1.3842 1.8614
PGR 0.4795 0.9745 1.3842 1.8614
Max
Poisson 0.5796 1.1283 1.5955 2.1786
CMP 0.5798 1.1283 1.5955 2.1786
PGR 0.5796 1.1283 1.5955 2.1786
Page 98
D. Anexo: Evaluacion de la bondad de
ajuste
Tabla D-1.: CIA medio con n = 1000. Fuente: Elaboracion propia.
ν ModeloCIA
m1 m2 m3 m4
0.25
Poisson 2862.57 5938.47 7063.43 8151.06
CMP 2754.79 5205.56 6042.69 6879.13
BN 2756.01 5239.09 6111.37 7011.29
0.50
Poisson 2780.35 4963.18 5897.52 6752.51
CMP 2741.41 4780.93 5655.68 6485.71
BN 2742.42 4791.97 5674.22 6507.11
0.75
Poisson 2742.20 4683.20 5388.81 6067.10
CMP 2734.63 4651.69 5352.39 6029.63
BN 2735.09 4654.46 5355.55 6032.63
1.00
Poisson 2722.06 4393.98 5115.94 5828.02
CMP 2723.03 4395.03 5116.97 5829.06
PGR 2723.05 4395.03 5116.98 5829.07
1.50
Poisson 2692.08 4139.74 4819.80 5492.22
CMP 2662.67 4074.89 4749.92 5419.55
PGR 2664.84 4079.37 4753.16 5421.90
2.50
Poisson 2500.21 3883.10 4621.72 5228.84
CMP 2322.12 3589.59 4314.13 4914.71
PGR 2344.98 3608.64 4325.66 4922.80
5.00
Poisson 2250.09 3694.62 4418.88 5029.17
CMP 1579.36 2924.71 3626.86 4227.10
PGR 1751.59 2969.73 3650.32 4241.97
Page 99
E. Anexo: Documentacion de las
funciones desarrolladas para las
simulaciones
Paquete ‘CMPvsPoissonSims’
Tipo Paquete
Tıtulo Realiza simulaciones para comparar modelos de regresion Poisson y Conway-
Maxwell-Poisson (CMP).
Version 0.1
Fecha 2016-06-01
Autor Alvaro Arley Castano C. <[email protected] >
Descripcion Genera covariables con un nivel de correlacion determinado. Genera con-
juntos de datos con dos covariables y una respuesta de conteo en un nivel de dispersion
deseado. Realiza simulaciones ajustando modelos para datos de conteo, almacena los coefi-
cientes estimados y calcula medidas de calidad predictiva y de bondad de ajuste. Obtiene
resumen estadıstico de las medidas calculadas.
Licencia GPL-2
Depende COMPoissonReg, compoisson, CompGLM, VGAM
Page 100
80 simCorData
simCorData Generar covariables
Descripcion
Genera covariables ortogonales o correlacionadas con una distribucion uniforme.
Uso
simCorData(n, rho = 0, met = 1, sem = 19318905)
Argumentos
n un valor entero para el tamano muestral deseado.
rho correlacion deseada. Debe estar entre [0,1). Por defecto rho = 0.
met metodo para obetener las covariables. Por defecto 1, que genera covaria-
bles con un nivel de correlacion deseado. La opcion 2 genera covariables
usando la funcion runif, sin una correlacion fija.
sem un valor entero que define la semilla para generar las covariables. Por
defecto sem = 19318905.
Valor
Un objeto de clase data.frame con dos variables (x1, x2).
Ejemplos
simCorData(10) # Por defecto produce dos covariables con n = 10.
simCorData(10, met = 2, sem = 17) # Produce dos covariables con n = 10, sin
# una correlacion fija y una semilla inicial de 17.
Page 101
simData 81
simData Generar un conjunto de datos
Descripcion
Genera un conjunto de datos con una respuesta de conteo y dos covariables.
Uso
simData(n, a, b, c, v, ...)
Argumentos
n un valor entero para el tamano muestral deseado.
a, b, c valores asumidos para los parametros del modelo (a = β0, b = β1, c = β2).
v valor asumido para el parametro de dispersion. No debe ser igual a cero.
... argumentos de la funcion simCorData.
Valor
Un objeto de clase data.frame con tres variables (Respuesta y covariables).
Ejemplos
simData(10, 1, -0.5, 0.5, v=0.5) # Genera un conjunto de datos en
# OD con 10 observaciones.
simFit Realizar simulaciones y calcular medidas estadısticas
Descripcion
Realiza simulaciones para comparar los modelos CMP y Poisson.
Uso
simFit(n, a, b, c, v, nsim, md, ...)
Page 102
82 simFit
Argumentos
n un valor entero para el tamano muestral deseado.
a, b, c valores asumidos para los parametros del modelo (a = β0, b = β1, c = β2).
v valor asumido para el parametro de dispersion. No debe ser igual a cero.
nsim numero de simulaciones deseado.
md un valor de 1 para ajustar modelos CMP con la funcion glm.comp (Por
defecto) y un valor de 2 para ajustarlos con la funcion cmp.
... argumentos de la funcion simData.
Valor
Un objeto de clase data.frame con 51 variables correspondientes a las diferentes medidas
estadısticas calculadas.
SM valor asumido para el intercepto.
D valor asumido para el parametro de dispersion.
N valor deseado para el tamano muestral.
M codigo asignado al modelo ajustado.
B# valor asumido para el coeficiente verdadero.
b# valor del coeficiente estimado.
Sb# desviacion entre B# y b#.
Db# diferencia porcentual de la desviacion entre B# y b#.
SEb# error estandar estimado para b#.
Infb# lımite inferior del IC al 95 % para b#.
Supb# lımite superior del IC al 95 % para b#.
ContB# valor logico. TRUE si el coeficiente verdadero esta contenido en el IC.
Vt valor asumido para el coeficiente de dispersion verdadero.
V valor del coeficiente de dispersion estimado.
SV desviacion entre Vt y V.
DV diferencia porcentual de la desviacion entre Vt y V.
SEV error estandar estimado para V.
InfV lımite inferior del IC al 95 % para V.
SupV lımite superior del IC al 95 % para V.
Page 103
simFit 83
ContVt valor logico. TRUE si Vt esta contenido en el IC.
MSPE ECMP para predicciones de media.
MSPEme ECMP para predicciones de mediana.
RMSPE RECMP para predicciones de media.
RMSPEme RECMP para predicciones de mediana.
MdAPE EPAMe para predicciones de media.
MdAPEme EPAMe para predicciones de mediana.
AIC CIA.
AICc CIA corregido para tamanos muestrales pequenos.
logL valor de la funcion de log-verosimilitud.
Conv valor logico. TRUE si no se presentaron problemas de convergencia en el
ajuste del modelo.
tmp tiempo que requerido para ajustar el modelo en segundos.
ERba ER de b/a. a y b se definen segun el orden jerarquico del codigo asignado
al modelo ajustado (M).
ERca ER de c/a. a y c se definen segun el orden jerarquico del codigo asignado
al modelo ajustado (M).
ERba.me ER de b/a para las predicciones de mediana. a y b se definen segun el
orden jerarquico del codigo asignado al modelo ajustado (M).
ERca.me ER de c/a para las predicciones de mediana. a y c se definen segun el
orden jerarquico del codigo asignado al modelo ajustado (M).
Nota
Los valores de ER se calcularon teniendo en cuenta el criterio de un modelo mas basico en
el denominador y el modelo propuesto o alternativo en el numerador. Por ello, al modelo
Poisson se le asigno un codigo M=1, al modelo CMP M=2, al modelo BN M=3 en OD. Y en
UD y ED, al modelo PGR se le asigno M=3.
Ejemplos
simData(10, 1, -0.5, 0.5, v=0.5, nsim=1000) # Genera un conjunto de datos en
# OD con 10 observaciones y 1000 simulaciones.
Page 104
84 simFitCMP
simFitCMP Realizar simulaciones para comparar las funciones glm.comp y
cmp
Descripcion
Realiza simulaciones para comparar los modelos CMP de dos impementaciones en R.
Uso
simFitCMP(n, a, b, c, v, nsim, ...)
Argumentos
n un valor entero para el tamano muestral deseado.
a, b, c valores asumidos para los parametros del modelo (a = β0, b = β1, c = β2).
v valor asumido para el parametro de dispersion. No debe ser igual a cero.
nsim numero de simulaciones deseado.
... argumentos de la funcion simData.
Valor
Un objeto de clase data.frame con 51 variables correspondientes a las diferentes medidas
estadısticas calculadas.
Nota
Los valores de ER se calcularon teniendo en cuenta el criterio de un modelo mas basico
en el denominador y el modelo propuesto o alternativo en el numerador. Por ello, al
modelo Poisson se le asigno un codigo M=1, al modelo CMP de la funcion glm.comp M=2,
al modelo CMP de la funcion cmp se le asigno M=3.
Ver Tambien
simFit.
Ejemplos
simFitCMP(10, 1, -0.5, 0.5, v=2.5, nsim=100) # Genera un conjunto de datos en
# UD con 10 observaciones y 100 simulaciones.
Page 105
Stats 85
Stats Calcular medidas de resumen de las simulaciones
Descripcion
Calcula medidas resumen de las simulaciones logradas por simFit.
Uso
Stats(e)
Argumentos
e un objeto de clase data.frame con los resultados de simFit en diferentes
escenarios.
Valor
Un objeto de clase list que contiene objetos de clase data.frame con medidas de resu-
men de las diferentes medidas estadısticas calculadas en simFit.
Coef valores medios de los coeficientes estimados.
Linf valores medios de los lımites inferiores de los IC al 95 %.
Linf valores medios de los lımites superiores de los IC al 95 %.
Cont proporciones de IC al 95 % que contienen el verdadero parametro.
Bias sesgos de las estimaciones.
MSE ECM.
RMSE RECM.
SE valores medios de los errores estandar estimados.
GOF valores medios de las medidas de bondad de ajuste.
Mpred valores medios las medidas de calidad predictiva.
MdAPE valores medios de EPAMe en las predicciones de media y mediana.
Pred valores medios, DE, Mın y Max de las medidas de calidad predictiva.
P.ER proporcion de ER.
Time tiempo medio requerido para ajustar el modelo en segundos.
ER21 ER de 2/1 en las estimaciones.
Page 106
86 Stats
ER23 ER de 2/3 en las estimaciones.
ER31 ER de 3/1 en las estimaciones.
ERpred ER en las predicciones.
Nota
Los valores de ER se calcularon teniendo en cuenta el criterio de un modelo mas basico en
el denominador y el modelo propuesto o alternativo en el numerador. Por ello, al modelo
Poisson se le asigno un codigo M=1, al modelo CMP M=2, al modelo BN M=3 en OD. Y en
UD y ED, al modelo PGR se le asigno M=3.
Ejemplos
# Union en un mismo data.frame de varios resultados de simFit.
v0.25a <- data.frame(rbind(v0.25m1,v0.25m2,v0.25m3,v0.25m4))
# Por ejemplo: El resumen de las simulaciones en OD con v=0.25
# y en m1, m2, m3 y m4
v0.25 <- Stats(v0.25a)
Page 107
Bibliografıa
[1] Armstrong, By J S. ; Collopy, Fred: Error Measures For Generalizing About Fore-
casting Methods: Empirical Comparisons. 8 (1992), Nr. 1, p. 69–80
[2] Bonate, P. L.: A brief introduction to Monte Carlo simulation. En: Clinical Pharma-
cokinetics 40 (1992), p. 15–22
[3] Cameron, A C. ; Trivedi, Pravin K.: Essentials of Count Data Regression. En:
Baltagi, B. H. (Ed.): A Companion to Theoretical Econometrics. Blackwell Publishing
Ltd, 2003. – ISBN 9780470996249, p. 331–348
[4] Cameron, A.C. ; Trivedi, Pravin K.: Regression Analysis of Count Data. New York
: Cambridge University Press, 1998. – 411 p.. – ISBN 0521635675
[5] Dobson, Annette J.: An introduction to generalized linear models. 2nd Ed. Chapman
& Hall/CRC, 2002. – 225 p.. – ISBN 1–58488–165–8
[6] Dunn, Jeffrey: compoisson: Conway-Maxwell-Poisson Distribution, 2012. – R package
version 0.3
[7] Efron, B: Double exponential families and their use in generalized linear Regression.
En: Journal of the American Statistical Association 81 (1986), p. 709–721
[8] Famoye, Felix: Restricted generalized poisson regression model. En: Communications
in Statistics - Theory and Methods 22 (1993), Nr. 5, p. 1335–1354
[9] Francis, Royce ; Geedipally, Srinivas R. ; Guikema, Seth D. ; Dhavala, Soma S. ;
Lord, Dominique ; Larocca, Sarah: Characterizing the Performance of the Conway-
Maxwell Poisson Generalized Linear Model. En: Risk Analysis 32 (2012), Nr. 1, p.
167–183. – ISSN 02724332
[10] Geedipally, Srinivas R.: Examining the Application of Conway-Maxwell- Poisson
Models for Analyzing Traffic Crash Data, Texas A&M University, Ph.D. Thesis, 2008.
– 129 p.
[11] Geedipally, Srinivas R. ; Guikema, Seth D. ; Dhavala, Soma S. ; Lord, Dominique:
Characterizing the Performance of the Bayesian Conway-Maxwell Poisson Generalized
Linear Model. En: Association, American S. (Ed.): Joint Statistical Meetings, 2008,
p. 22
Page 108
88 Bibliografıa
[12] Green Clean Guide ; Pranali Telang (Ed.): Economic Importance of Tree Spe-
cies. 2012. – 62 p.
[13] Guikema, Seth D. ; Goffelt, Jeremy P.: A Flexible Count Data Regression Model
for Risk Analysis. En: Risk Analysis 28 (2008), Nr. 1, p. 213–223. – ISBN 4105166042
[14] Hilbe, Joseph: Negative Binomial Regression. 2nd Ed. Cambridge University Press,
2011. – 553 p.. – ISBN 9780874216561
[15] Hurvich, C. L.: Regression and Time Series Model Selection in Small Samples. En:
Biometrika 76 (1989), p. 297–307
[16] Jowaheer, Vandna ; Mamode, Naushad: Estimating Regression Effects in Com
Poisson Generalized Linear Model. En: World Academy of Science, Engineering and
Technology 29 (2009), Nr. 1, p. 1040–1044. – ISSN 20103905
[17] Lord, D. ; Mannering, F.: The Statistical Analysis of Crash-Frequency Data: A
Review and Assessment of Methodological Alternatives. En: Transportation Research -
Part A 44(5) (2010), p. 291–305
[18] Lord, Dominique ; Geedipally, Srinivas R. ; Guikema, Seth D.: Extension of the
Application of Conway-Maxwell-Poisson Models: Analyzing Traffic Crash Data Exhi-
biting Underdispersion. En: Risk Analysis 30 (2010), Nr. 8, p. 1268–1276. – ISBN
1539–6924 (Electronic) 0272–4332 (Linking)
[19] Lord, Dominique ; Guikema, Seth D. ; Geedipally, Srinivas R.: Application of the
Conway-Maxwell-Poisson generalized linear model for analyzing motor vehicle crashes.
En: Accident Analysis and Prevention 40 (2008), Nr. 3, p. 1123–1134. – ISBN 0001–4575
[20] McCullagh, P ; Nelder, J: Generalized linear models. 2nd Ed. New York : Chapman
& Hall/CRC, 1972. – 511 p.. – ISBN 0412317605
[21] Miller, J: Comparing Poisson, Hurdle and ZIP model fit under varying degrees of
Skew and Zero-Inflation, University of Florida, Ph.D. Thesis, 2007. – 201 p.
[22] Minka, Thomas P. ; Shmueli, Galit ; Kadane, Joseph B. ; Borle, Sharad ; Boatw-
right, Peter: Computing with the COM-Poisson distribution / Carnegie Mellon Uni-
versity. Pittsburgh, PA, 2003. – Informe de Investigacion. – 7 p.
[23] Mooney, C. Z.: Quantitative Applications in the Social Sciences. Vol. 116: Monte Carlo
Simulation. London : SAGE Publications, 1997. – 112 p.
[24] Myers, Norman ; Fonseca, Gustavo a B. ; Mittermeier, Russell a. ; Fonseca, G
a B. ; Kent, Jennifer: Biodiversity hotspots for conservation priorities. En: Nature 403
(2000), Nr. 6772, p. 853–858. – ISBN 0028–0836
Page 109
Bibliografıa 89
[25] Myhrvold, N. ; Baldridge, E. ; Chan, B. ; Sivam, D. ; Freeman, D. ; Morgan, E.:
An amniote life-history database to perform comparative analyses with birds, mammals,
and reptiles. En: Ecology 96 (2015), Nr. October, p. 3109
[26] Pollock, Jeffrey: CompGLM: Conway-Maxwell-Poisson GLM and distribution fun-
ctions, 2014. – R package version 1.0
[27] R Core Team: R: A Language and Environment for Statistical Computing. Vienna,
Austria: R Foundation for Statistical Computing, 2016
[28] Ramesh, B. R. ; Swaminath, M. H. ; Patil, Santoshgouda V. ; Dasappa ; Pelissier,
Raphael ; Venugopal, P. D. ; Aravajy, S. ; Elouard, Claire ; Ramalingam, S.:
Forest stand structure and composition in 96 sites along environmental gradients in the
central Western Ghats of India. En: Ecology 91 (2010), Nr. January, p. 3118–3118. –
ISSN 0012–9658
[29] Ridout, M.S. ; Besbeas, P.: An empirical model for underdispersed count data. En:
Statistical Modelling 4 (2004), p. 77–89. – ISSN 1471–0820
[30] Saez-Castillo, A.J. ; Conde-Sanchez, A.: A hyper-Poisson regression model for
overdispersed and underdispersed count data. En: Computational Statistics & Data
Analysis 61 (2013), p. 148–157. – ISSN 01679473
[31] Sellers, Kimberly ; Lotze, Thomas: COMPoissonReg: Conway-Maxwell Poisson
(COM-Poisson) Regression, 2015. – R package version 0.3.5
[32] Sellers, Kimberly F. ; Shmueli, Galit: A flexible regression model for count data.
En: Annals of Applied Statistics 4 (2010), Nr. 2, p. 943–961
[33] Sellers, Kimberly F. ; Shmueli, Galit: Predicting Censored Count Data with COM-
Poisson Regression. En: SSRN Electronic Journal (2010), p. 18
[34] Shmueli, G. ; Minka, T.P. ; Kadane, J.B. ; Borle, S. ; Boatwright, P.: A
Useful Distribution for Fitting Discrete Data: Revival of the Conway-Maxwell-Poisson
Distribution. En: Journal of the Royal Statistical Society. Series C (Applied Statistics)
54 (2005), Nr. 1, p. 127–142
[35] Winkelmann, Rainer: Econometric Analysis of Count Data. 5th Ed. Berlin : Springer-
Verlag, 2008. – 333 p.. – ISBN 978–3–540–78389–3
[36] Winkelmann, Rainer ; Zimmermann, Klaus F.: Recent Developments in Count Data
Modelling: Theory and Application. En: Journal of Economic Surveys 9 (1995), Nr. 1,
p. 1–24. – ISBN 1467–6419
Page 110
90 Bibliografıa
[37] Yee, Thomas W.: VGAM: Vector Generalized Linear and Additive Models, 2015. – R
package version 0.9-8
[38] Zou, Yaotian ; Geedipally, Srinivas R. ; Lord, Dominique: Evaluating the double
Poisson generalized linear model. En: Accident; analysis and prevention 59 (2013), Nr.
979, p. 497–505. – ISSN 1879–2057
[39] Zou, Yaotian ; Lord, Dominique ; Geedipally, Srinivas R. Over- and Under-
Dispersed Count Data : Comparing the Conway-Maxwell-Poisson and Double-Poisson
Distributions. 2011