36
Comparative Scaling Comparative Scaling
| Date post: | 17-Dec-2015 |
| Category: |
Documents |
| Upload: | randell-robinson |
| View: | 216 times |
| Download: | 0 times |

Comparative ScalingComparative Scaling

Some Key Concepts
• Measurement– Assigning numbers or other symbols to characteristics
of objects being measured, according to predetermined rules.
• Concept (or Construct)– A generalized idea about a class of objects, attributes,
occurrences, or processes.• Relatively concrete constructs
– Age, gender, number of children, education, income
• Relatively abstract constructs– Brand loyalty, personality, channel power, satisfaction

• Scale– A quantifying measure – a combination of items that
is progressively arranged according to value or magnitude.
– Purpose is to quantitatively represent an item’s, person’s, or event’s place in the scaling continuum.
Some Key Concepts
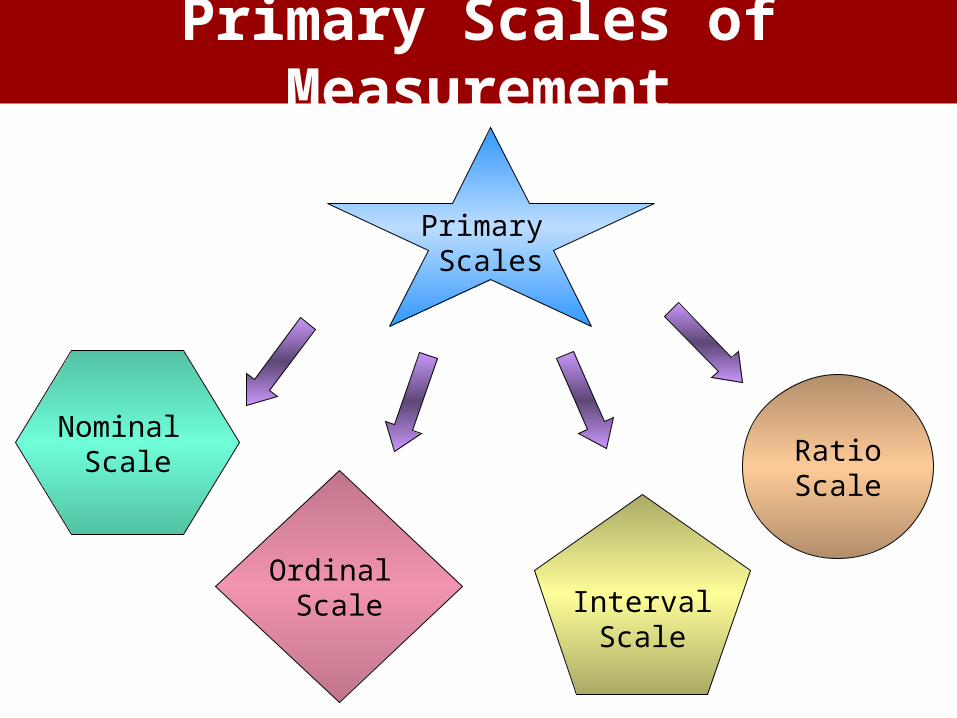
Primary Scales
Nominal Scale
Ordinal Scale
RatioScale
IntervalScale
Primary Scales of Measurement

• Nominal– A scale in which the numbers or letters
assigned to objects serve as labels for identification or classification.
• Ordinal– A scale that arranges objects or
alternatives according to their magnitude in an ordered relationship.
Primary Scales of Measurement

• Interval– A scale that both arranges objects
according to their magnitudes and
– Distinguishes the ordered arrangement in units of equal intervals
– I.e., indicate order and measure order (or distance) in units of equal intervals
Primary Scales of Measurement

• Ratio–A scale that has absolute rather than
relative quantities and an absolute zero where a given attribute is absent.
–Money & weight are good examples of attributes that possess absolute zeros and interval properties.
Primary Scales of Measurement
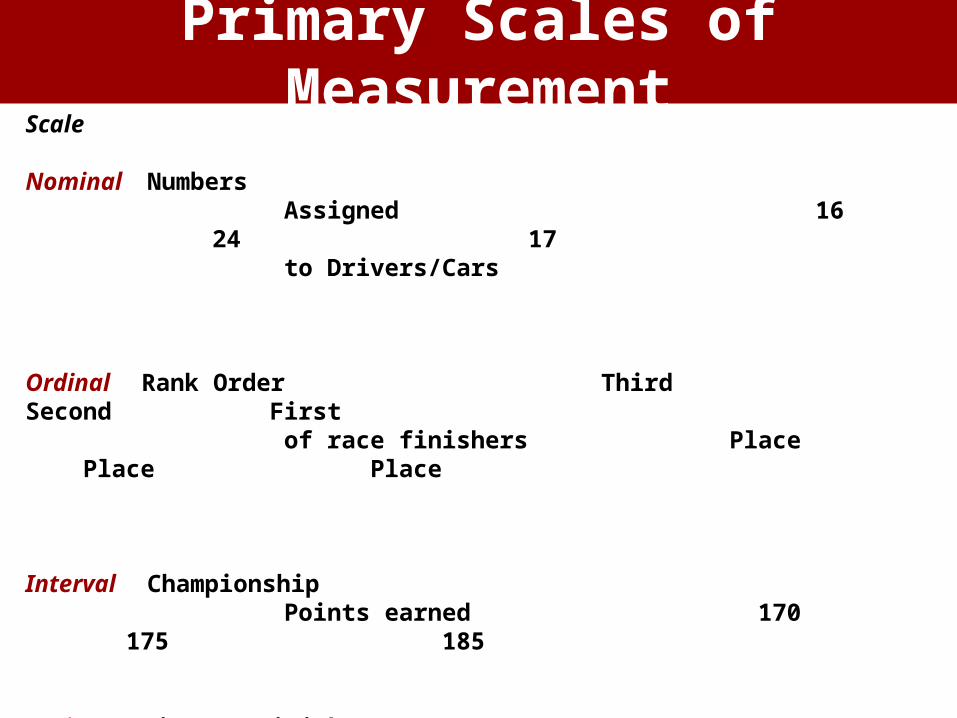
Scale
Nominal Numbers Assigned 16 24 17 to Drivers/Cars
Ordinal Rank Order Third Second First of race finishers Place Place Place
Interval Championship Points earned 170 175 185
Ratio Time to Finish, behind winner 5.1 2.3 0.0
Primary Scales of Measurement

• Comparative Scales–Involve the direct comparison of
two or more objects
• Noncomparative Scales–Objects or stimuli are scaled
independently of each other.
Classifying Scaling Techniques

ScalingTechniques
ComparativeScales
PairedComparison
ConstantSum
RankOrder
NoncomparativeScales
ItemizedRating Scales
Continuous Rating Scales
Likert
Semantic Differential
Stapel
Classifying Scaling Techniques

• Respondent is presented with two objects at a time
• Then asked to select one object in the pair according to some criterion
• Data obtained are ordinal in nature– Arranged or ranked in order of magnitude
• Easy to do if only a few items are compared.
• If number of comparisons is too large, respondents may become fatigued and no longer carefully discriminate among them.
Paired Comparison Scaling

Paired Comparison Scaling: Example
Cunningham Day Parker Thomas
Cunningham 0 0 0
Day 1 1 0
Parker 1 0 0
Thomas 1 1 1 0
# of times preferred
3 1 2 0
For each pair of professors, please indicate the professor from whom you prefer to take classes with a 1.

• Respondents are presented with several objects simultaneously
• Then asked to order or rank them according to some criterion.
• Data obtained are ordinal in nature– Arranged or ranked in order of magnitude
• Commonly used to measure preferences among brands and brand attributes
Rank Order Scaling

Rank Order Scaling
Instructor Ranking
Cunningham 1
Day 3
Parker 2
Thomas 4
Please rank the instructors listed below in order of preference. For the instructor you prefer the most, assign a “1”, assign a “2” to the instructor you prefer the 2nd most, assign a “3” to the instructor that you prefer 3rd most, and assign a “4” to the instructor that you prefer the least.

• Respondents are asked to allocate a constant sum of units among a set of stimulus objects with respect to some criterion
• Units allocated represent the importance attached to the objects.
• Data obtained are interval in nature
• Allows for fine discrimination among alternatives
Constant Sum Scaling

Constant Sum Scaling
Instructor Availability Fairness Easy Tests
Cunningham 30 35 25
Day 30 25 25
Parker 25 25 25
Thomas 15 15 25
Sum Total 100 100 100
Listed below are 4 marketing professors, as well as 3 aspects that students typically find important. For each aspect, please assign a number that reflects how well you believe each instructor performs on the aspect. Higher numbers represent higher scores. The total of all the instructors’ scores on an aspect should equal 100.

Non-Comparative ScalingNon-Comparative Scaling
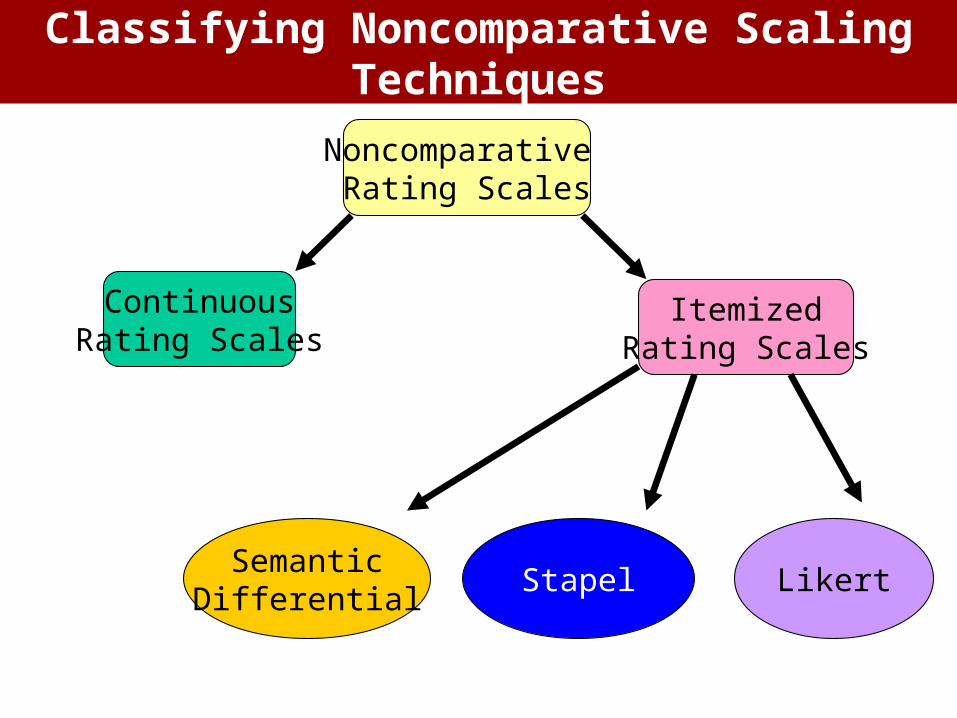
Noncomparative Rating Scales
ContinuousRating Scales
ItemizedRating Scales
SemanticDifferential
Stapel Likert
Classifying Noncomparative Scaling Techniques

Continuous Rating Scale Example
VeryPoor
VeryGood
0 10 20 30 40 50 60 70 80 90 100
X

Method of Summated Ratings: The Likert Scale
• Extremely popular means for measuring attitudes.
• Respondents indicate their own attitudes by checking how strongly they agree/disagree with statements.
• Response alternatives: – “strongly agree”, “agree”, “uncertain”,
“disagree”, and “strongly disagree”.
• Generally use either a 5- or 7-point scale

Semantic Differential Scales
• A series of numbered (usually seven-point) bipolar rating scales.
• Bipolar adjectives (for example, “good” and “bad”), anchor both ends (or poles) of the scale.
• A weight is assigned to each position on the rating scale. – Traditionally, scores are 7, 6, 5, 4, 3, 2, 1, or
+3, +2, +1, 0, -1, -2, -3.

Semantic Differential Scales for Measuring Attitudes Toward Tennis
Exciting ___ : ___ : ___ : ___ : ___ : ___ : ___ : Calm
Interesting ___ : ___ : ___ : ___ : ___ : ___ : ___ : Dull
Simple___ : ___ : ___ : ___ : ___ : ___ : ___ Complex
Passive ___ : ___ : ___ : ___ : ___ : ___ : ___ Active

Stapel Scales
• Modern versions of the Stapel scale place a single adjective as a substitute for the semantic differential when it is difficult to create pairs of bipolar adjectives.
• The advantage and disadvantages of a Stapel scale, as well as the results, are very similar to those for a semantic differential.
• However, the Stapel scale tends to be easier to conduct and administer.

A Stapel Scale for Measuring a Store’s Image
Department
Store Name
+3
+2
+1
Wide Selection
-1
-2
-3

Graphic Rating Scales
A graphic rating scale presents respondents with a graphic continuum.

Graphic Rating Scale Stressing Pictorial Visual Communications
3 2 1Very VeryGood Poor
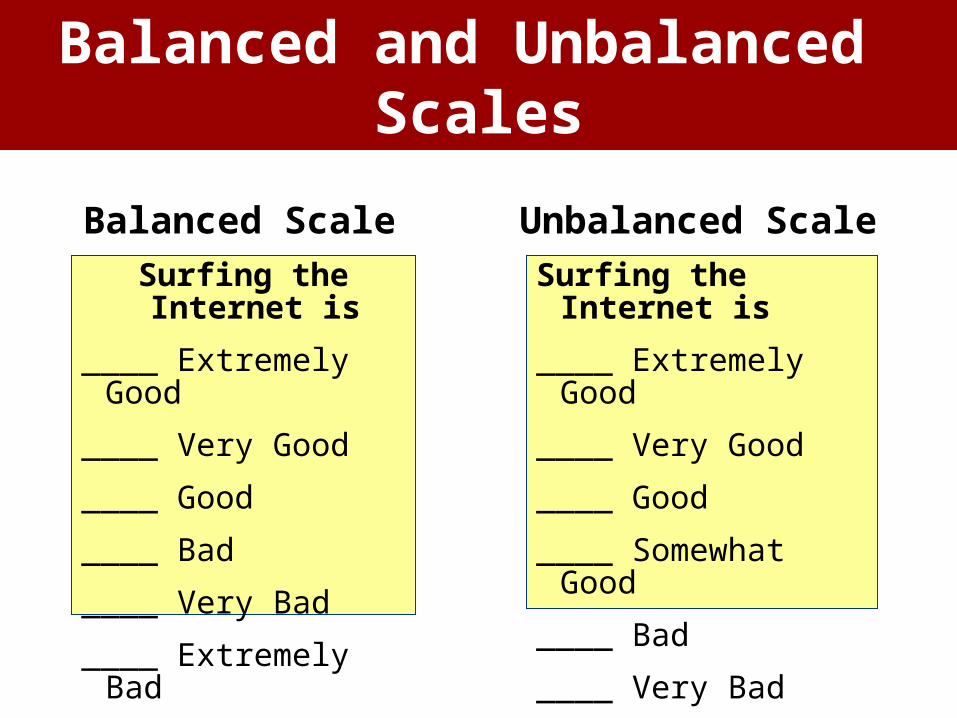
Surfing the Internet is
____ Extremely Good
____ Very Good
____ Good
____ Bad
____ Very Bad
____ Extremely Bad
Surfing the Internet is
____ Extremely Good
____ Very Good
____ Good
____ Somewhat Good
____ Bad
____ Very Bad
Balanced Scale Unbalanced Scale
Balanced and Unbalanced Scales

Summary of Itemized Rating Scale Decisions
1. Number of categories While there is no single, optimal number, traditional guidelines
suggest that there should be between five and nine categories.
2. Balanced vs. unbalanced In general, the scale should be balanced to obtain objective data.
3. Odd or even number of If a neutral or indifferent scale response is possible for
categories at least some of the respondents, an odd number of categories
should be used.
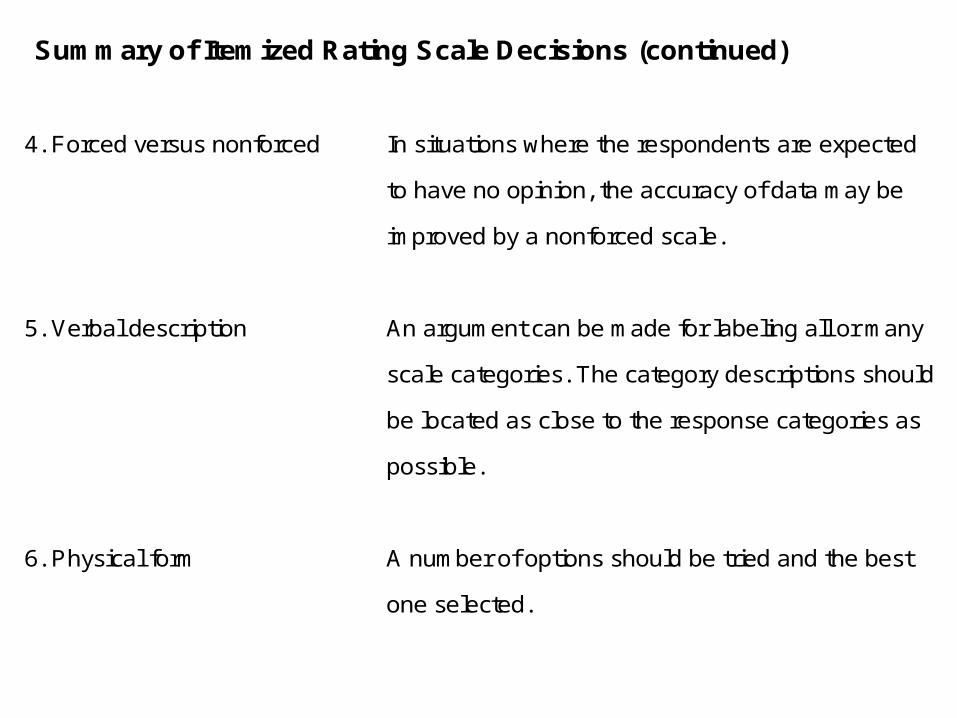
Summary of Itemized Rating Scale Decisions (continued)
4. Forced versus nonforced In situations where the respondents are expected
to have no opinion, the accuracy of data may be
improved by a nonforced scale.
5. Verbal description An argument can be made for labeling all or many
scale categories. The category descriptions should
be located as close to the response categories as
possible.
6. Physical form A number of options should be tried and the best
one selected.

Scale Evaluation
Scale Evaluation
Reliability Validity
Test-RetestInternal
ConsistencyAlternative Forms Construct
Criterion
Content
Convergent Validity
Discriminant Validity Nomological
Validity

Reliability
• Extent to which a scale produces consistent results
• Test-retest Reliability– Respondents are administered scales at 2 different
times under nearly equivalent conditions
• Alternative-form Reliability– 2 equivalent forms of a scale are constructed, then
tested with the same respondents at 2 different times

Reliability
• Internal Consistency Reliability– The consistency with which each item represents the
construct of interest– Used to assess the reliability of a summated scale– Split-half Reliability
• Items constituting the scale divided into 2 halves, and resulting half scores are correlated
– Coefficient alpha (most common test of reliability)• Average of all possible split-half coefficients resulting
from different splittings of the scale items

Validity
• Extent to which true differences among the objects are reflected on the characteristic being measured
• Content Validity– A.k.a., face validity
– Subjective, but systematic evaluation of the representativeness of the content of a scale for the measuring task at hand
• Criterion Validity– Examines whether measurement scale performs as expected in
relation to other variables selected as meaningful criteria
– I.e., predicted and actual behavior should be similar

Construct Validity
• Addresses the question of what construct or characteristic the scale is actually measuring
• Convergent Validity– Extent to which scale correlates positively with other
measures of the same construct
• Discriminant Validity– Extent to which a measure does not correlate with other
constructs from which it is supposed to differ
• Nomological Validity– Extent to which scale correlates in theoretically predicted
ways with measures of different but related constructs

Relationship Between Reliability and Validity
• A scale can be reliable, but not valid
• In order for a scale to valid, it must also be reliable.
• In other words,–Reliability is a necessary but
insufficient condition for Validity.

Reliability and Validity on Target
Old Rifle New Rifle New Rifle SunglareLow Reliability High Reliability Reliable but Not
Valid(Target A) (Target B) (Target C)

















