Computer Architecture 1 Computer Architecture Computer Architecture (“MAMAS”, 234267) (“MAMAS”, 234267) Spring 2015 Spring 2015 Lecturer: Yoav Etsion Reception: Mon 15:00, Fishbach 306-8 TAs: Tomer Gurevich, Franck Sala, Andrey Zhitnikov Presentation based on slides by David Patterson, Avi Mendelson, Lihu Rappoport, Adi Yoaz and Dan Tsafrir
TAs: Tomer Gurevich, Franck Sala, Andrey Zhitnikov
Presentation based on slides by David Patterson, Avi Mendelson, Lihu Rappoport, Adi Yoaz and Dan Tsafrir
Computer Architecture 2015 – Introduction2
General InfoGeneral Info Grade
25% Exercise (mandatory) תקף 75% Final exam
Textbook “Computer Architecture:
A Quantitative Approach” (4th Edition)by: Patterson & Hennessy
Other course information Course web site:
http://webcourse.cs.technion.ac.il/234267/Spring2013 Lectures will be upload to the web a day before the
class
Computer Architecture 2015 – Introduction3
AssignmentsAssignments Five mandatory assignments during the
semester Only programming assignments
NO CHEATING! Suspected parties will be sent to a Technion trial Typical outcome: course disqualified, which means
your graduation will be postponed by at least one semester
Possible examples of cheating (a few of many): Copying any part of the assignments from another student or using
a reference from a previous year Letting someone else copy from you Posting code/solutions to a shared forum We can track the code back to the posters!
Move on to Memory Hierarchy Caching and Main memory Virtual Memory
Finish with latency tolerance and parallelism Hardware multithreading
Computer Architecture 2015 – Introduction11
The ProcessorThe Processor
Computer Architecture 2015 – Introduction12
Architecture vs. Architecture vs. MicroarchitectureMicroarchitecture
Architecture:= The processor features as seen by its user= Interface Instruction set, number of registers, addressing modes,
…
Microarchitecture:= Manner by which the processor is implemented= Implementation details Caches size and structure, number of execution units, …
Note: different processors with different u-archs can support the same arch Intel Pentium-IV vs. Intel Core2 Duo ARMv9 implemented by Qualcomm, TI, Samsung
Computer Architecture 2015 – Introduction13
Why Should We Care?Why Should We Care?
Abstractions enhance productivity, so:If we know the arch (=interface),Why should we care about the u-arch (=internals)?
Same goes for archJust details for a programmer of a high-level language
Abstractions only work so long as what’s below worksThe taxi story: http://vimeo.com/11478146 (4:50-6:00)
• Compression, C complier, Perl, text-processing, … SPEC FP: floating point apps (mostly scientific) TPC benchmarks: measure transaction throughput (DB) SPEC JBB: models wholesale company (Java server, DB)
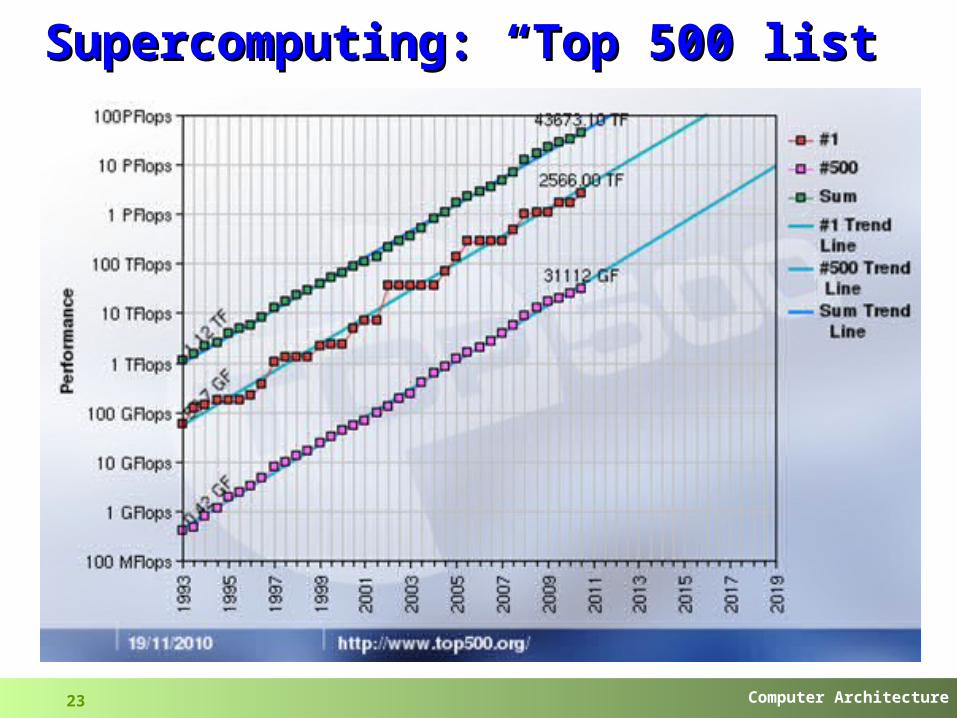
Sometimes you see FLOPS (“peak” or “sustained”) Supercomputers (top500 list), against LINPACK
Computer Architecture 2015 – Introduction31
-2%
0%
2%
4%
6%
Evaluating PerformanceEvaluating Performance Use a performance simulator to evaluate
the performance of a new feature / algorithm Models the uarch to a great detail Run 100’s of representative applications
Produce the performance s-curve Sort the applications according to the IPC increase Baseline (0%) is the processor without the new
feature
-4%
-3%
-2%
-1%
0%
1%
2%
3%
Negativeoutliers
Positiveoutliers
Bad S-curve
Small negativeoutliers
Positiveoutliers
Good S-curve
Computer Architecture 2015 – Introduction32
Amdahl’s LawAmdahl’s Law
Suppose we accelerate the computation such thatP = portion of computation we make fasterS = speedup experienced by the portion we improved
For exampleIf an improvement can speedup 40% of the computation
=> P = 0.4If the improvement makes the portion run twice as fast
=> S = 2
Then overall speedup = 1
(1 ) PP S
Computer Architecture 2015 – Introduction33
Amdahl’s Law - ExampleAmdahl’s Law - Example
FP operations improved to run 2x fasterS = 2, but…P = only affects 10% of the programSpeedup:
ConclusionBetter to make common case fast…
1 1 11.053
0.1 0.95(1 ) (1 0.1) 2PP S
Computer Architecture 2015 – Introduction34
Amdahl’s Law – ParallelismAmdahl’s Law – Parallelism
When parallelizing a program P = proportion of program that can be made parallel 1 - P = inherently serial N = number of processing elements (say, cores)Speedup:
Serial component imposes a hard limit
1
(1 ) PP N
1 1lim
(1 )(1 )N P PP N
Computer Architecture 2015 – Introduction35
The ISA is what the user & compiler see
The HW implements the ISA
instruction set
software
hardware
Instruction Set DesignInstruction Set Design
Computer Architecture 2015 – Introduction36
Considerations in ISA DesignConsiderations in ISA Design Instruction size
Long instructions take more time to fetch from memory Longer instructions require a larger memory
• Important for small (embedded) devices
Number of instructions (IC) Reduce IC => reduce runtime (at a given CPI &
frequency)
Virtues of instructions simplicity Simpler HW allows for: higher frequency & lower power Optimization can be applied better to simpler code Cheaper HW
Computer Architecture 2015 – Introduction37
Basing Design Decisions on Basing Design Decisions on WorkloadWorkload
Immediate argument’s size in bits (histogram)
1% of data values > 16-bits Having 16 bits is likely good enough
0%
10%
20%
30%
0 1 2 3 4 5 6 7 8 9
10
11 12
13
14
15
Immediate data bits
Int. Avg.
FP Avg.
Computer Architecture 2015 – Introduction38
CISC ProcessorsCISC Processors CISC - Complex Instruction Set Computer
Example: x86 The idea: a high level machine language
• When people programmed in assembly, CISC supposedly easier
Characteristic Many instruction types, with a many addressing modes Some of the instructions are complex
• Execute complex tasks• Require many cycles
ALU operations directly on memory (e.g., arr[j] = arr[i]+n)• Registers not used (and, accordingly, only a few registers exist)
Variable length instructions• common instructions get short codes save code length
Computer Architecture 2015 – Introduction39
Rank instruction % of total executed
1 load 22%
2 conditional branch 20%
3 compare 16%
4 store 12%
5 add 8%
6 and 6%
7 sub 5%
8 move register-register 4%
9 call 1%
10 return 1%
Total 96%
Simple instructions dominate instruction frequency
But it Turns Out…But it Turns Out…
Computer Architecture 2015 – Introduction40
CISC DrawbacksCISC Drawbacks Complex instructions and complex addressing modes
complicates the processor slows down the simple, common instructions contradicts Make The Common Case Fast
Compilers don’t use complex instructions / indexing
methods
Variable length instructions are real pain in the neck Difficult to decode few instructions in parallel
• As long as instruction is not decoded, its length is unknown It is unknown where the instruction ends It is unknown where the next instruction starts
An instruction may be longer than a cache line• Or even longer longer than a page (in theory)
Computer Architecture 2015 – Introduction41
RISC ProcessorsRISC Processors RISC - Reduced Instruction Set Computer
The idea: simple instructions enable fast hardware
Characteristic A small instruction set, with only a few instructions
formats A few indexing methods Load/Store machine: operate only on registers
• Memory is accessed using Load and Store instructions only
• Many orthogonal registers • Three address machine: Add dst, src1, src2















































![Inter-thread Communication in Multithreaded, Reconfigurable Coarse …€¦ · Etsion [1], [2] recently introduced a coarse-grained reconfig-This research was supported by the Israel](https://static.documents.pub/doc/80x56/5f45439aad9416738920df31/inter-thread-communication-in-multithreaded-reconigurable-coarse-etsion-1.jpg)













