40
CS 182/CogSci110/Ling109 Spring 2008 Reinforcement Learning: Details and Biology 4/3/2008 Srini Narayanan – ICSI and UC Berkeley
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 216 times |
| Download: | 1 times |

CS 182/CogSci110/Ling109Spring 2008
Reinforcement Learning: Details and Biology
4/3/2008
Srini Narayanan – ICSI and UC Berkeley

Lecture Outline
Reinforcement Learning: Temporal Difference: TD-Learning, Q-
Learning Demos (MDP, Q-Learning)
Animal Learning and Biology Neuro-modulators and temporal difference Discounting Exploration and Exploitation
Neuroeconomics-- Intro

Demo of MDP solution

Example: Bellman Updates

Example: Value Iteration
Information propagates outward from terminal states and eventually all states have correct value estimates
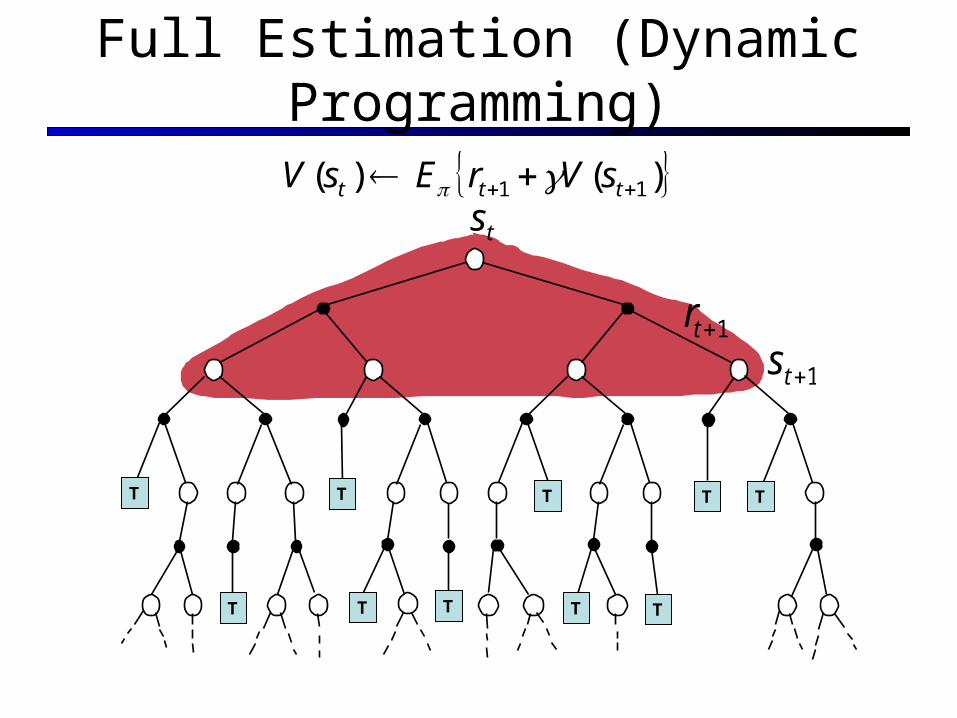
Full Estimation (Dynamic Programming)
)()( 11 ttt sVrEsV
T
T T T
st
rt1
st1
T
TT
T
TT
T
T
T

Simple Monte Carlo
T T T TT
T T T T T
V(st ) V(st) Rt V (st ) where Rt is the actual return following state st .
st
T T
T T
TT T
T TT

Combining DP and MC
T T T TT
T T T T T
st1
rt1
st
V(st ) V(st) rt1 V (st1 ) V(st )
TTTTT
T T T T T
PREDICTION ERROR

Model-Free Learning
Big idea: why bother learning T? Update each time we experience a transition Frequent outcomes will contribute more updates
(over time)
Temporal difference learning (TD) Policy still fixed! Move values toward value of whatever
successor occurs
a
s
s, a
s,a,s’s’

Q-Learning
Learn Q*(s,a) values Receive a sample (s,a,s’,r) Consider your old estimate: Consider your new sample estimate:
Nudge the old estimate towards the new sample:

Any problems with this?
No guarantee you will explore the state space. The value of unexplored states is never computed.
Fundamental problem in RL and in Biology How do we address this problem?
AI solutions include e-greedy Softmax
Evidence from Neuroscience (next lecture).

Exploration / Exploitation
Several schemes for forcing exploration Simplest: random actions (-greedy)
Every time step, flip a coin With probability , act randomly With probability 1-, act according to current policy
(best q value for instance)
Problems with random actions? You do explore the space, but keep thrashing
around once learning is done One solution: lower over time Another solution: exploration functions

Q-Learning
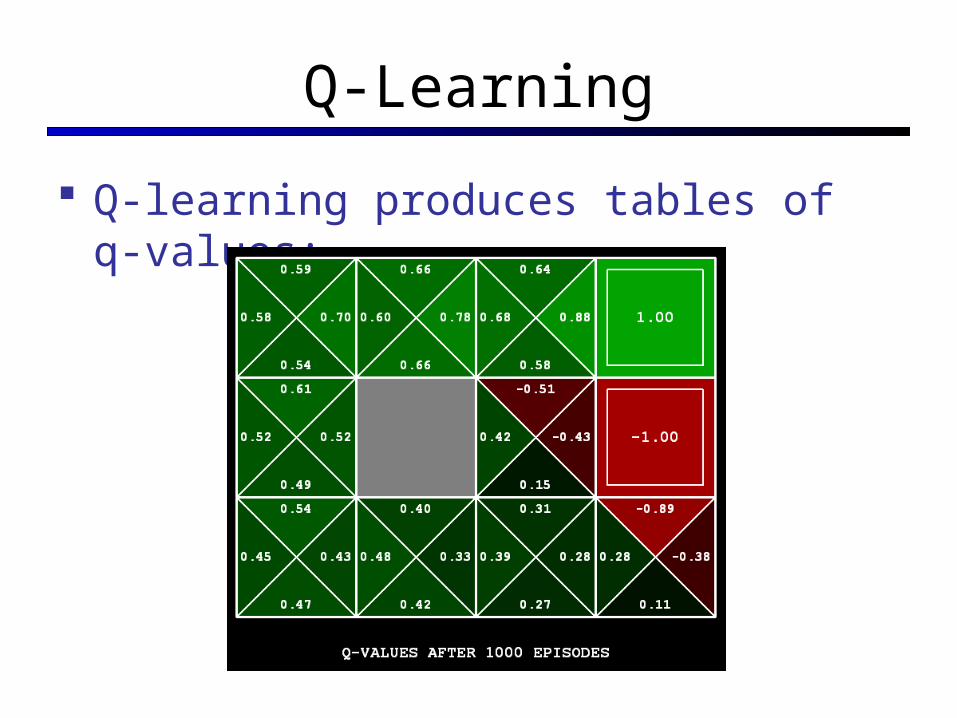
Q-Learning
Q-learning produces tables of q-values:

Q Learning features
On-line, Incremental Bootstrapping (like DP unlike MC) Model free Converges to an optimal policy (Watkins
1989). On average when alpha is small With probability 1 when alpha is high in the
beginning and low at the end (say 1/k)

Reinforcement Learning
Basic idea: Receive feedback in the form of rewards Agent’s utility is defined by the reward
function Must learn to act so as to maximize expected
utility Change the rewards, change the behavior
DEMO

Demo of Q Learning
Demo arm-control Parameters
learning rate) discounted reward (high for future rewards) exploration(should decrease with time)
MDP Reward= number of the pixel moved to the right/
iteration number Actions : Arm up and down (yellow line), hand up and
down (red line)

Helicopter Control (Andrew Ng)

Lecture Outline
Reinforcement Learning: Temporal Difference: TD-Learning, Q-
Learning Demos (MDP, Q-Learning)
Animal Learning and Biology Neuro-modulators and temporal difference Discounting Exploration and Exploitation
Neuroeconomics-- Intro

Example: Animal Learning
RL studied experimentally for more than 60 years in psychology Rewards: food, pain, hunger, drugs, etc. Conditioning Mechanisms and sophistication debated
More recently neuroscience has provided data on Biological reality of prediction error td-(and q) learning Utility structure and reward discounting Exploration vs. exploitation

Dopamine levels track prediction error Unpredicted reward(unlearned/no stimulus)
Predicted reward(learned task)
Omitted reward(probe trial)
(Montague et al. 1996)Wolfram Schultz Lab 1990-1996
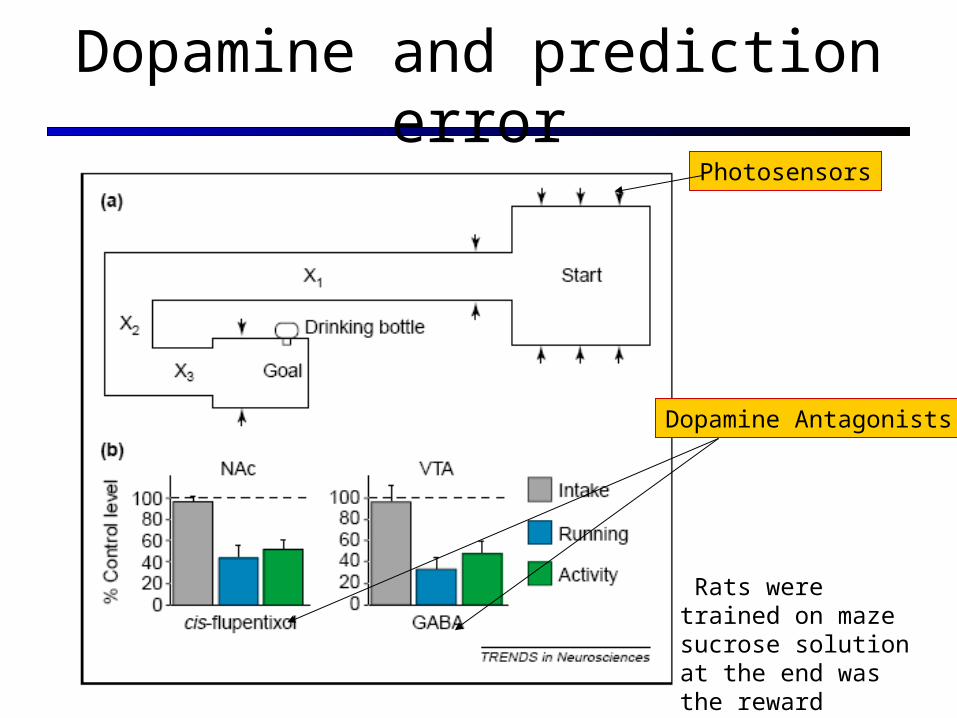
Dopamine and prediction error
Rats were trained on mazesucrose solution at the end was the reward
Photosensors
Dopamine Antagonists
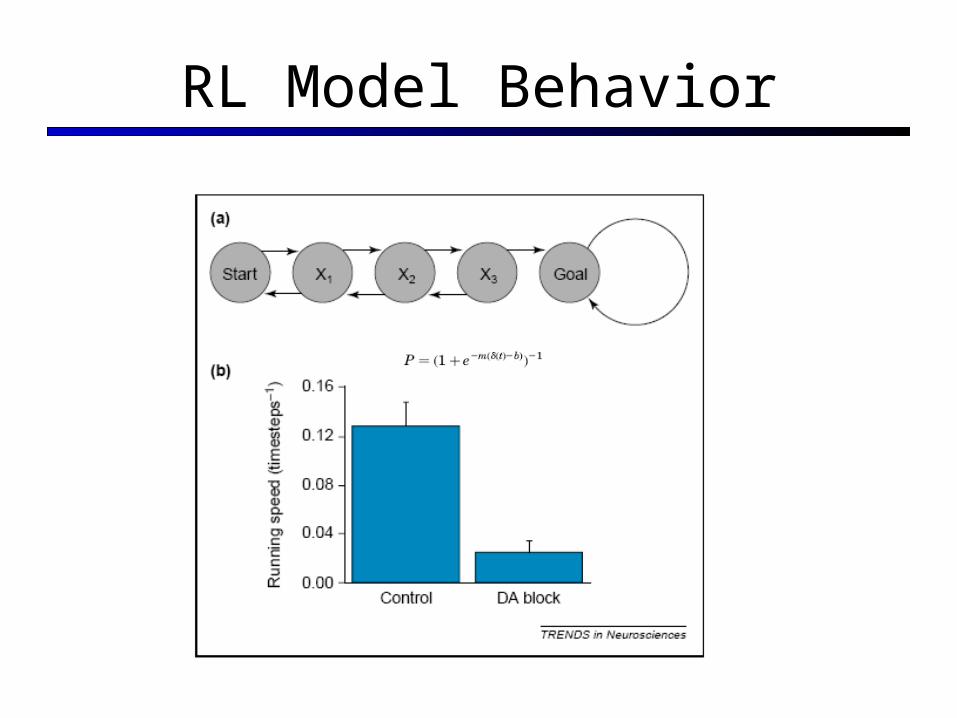
RL Model Behavior

Human learning
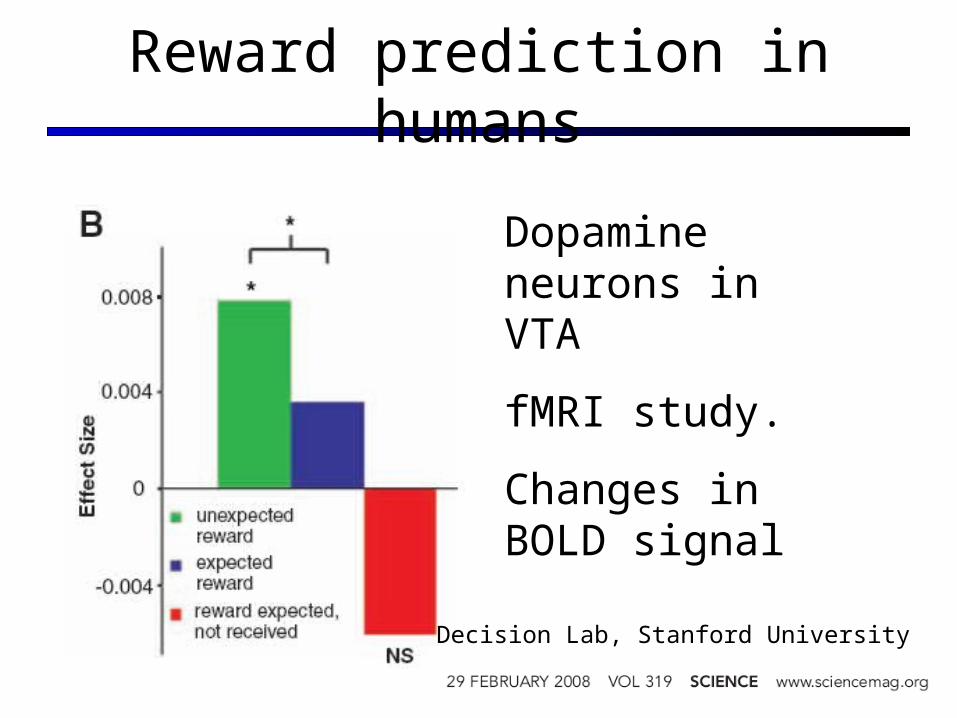
Reward prediction in humans
Dopamine neurons in VTA
fMRI study.
Changes in BOLD signal
Decision Lab, Stanford University

Reward prediction in humans
Explicit losses (punishment) seems to have a different circuit than the positive signal
Changes modulated by probability of reward
Decision Lab, Stanford University

Dopamine neurons and their role
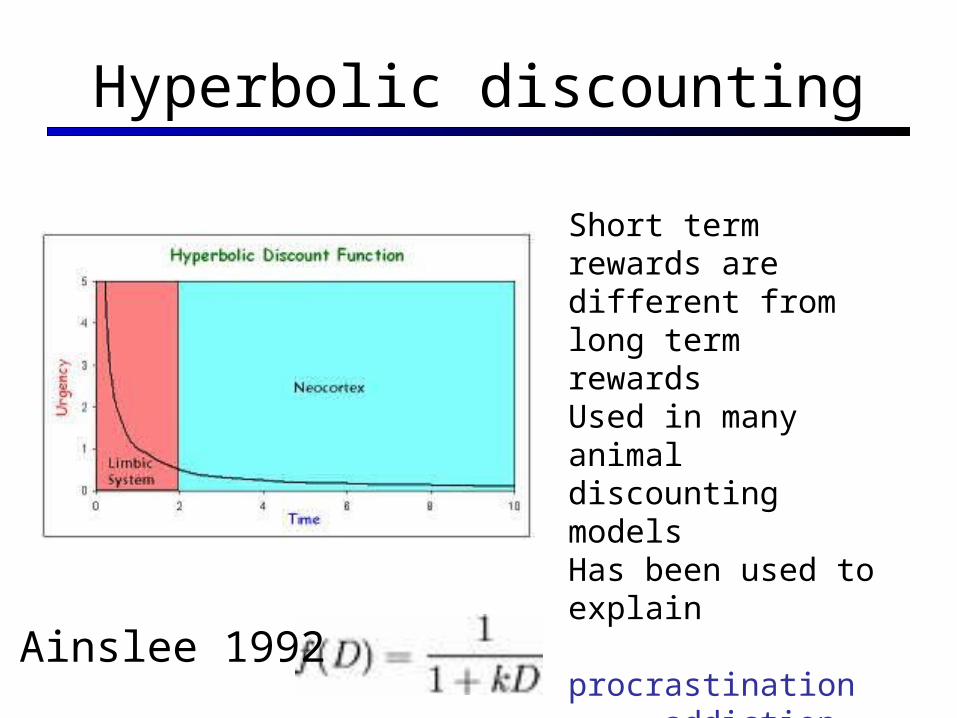
Hyperbolic discounting
Ainslee 1992
Short term rewards are different from long term rewardsUsed in many animal discounting modelsHas been used to explain
procrastinationaddiction
Behavior changes as rewards become imminent

McCLure, Cohen fMRI expts
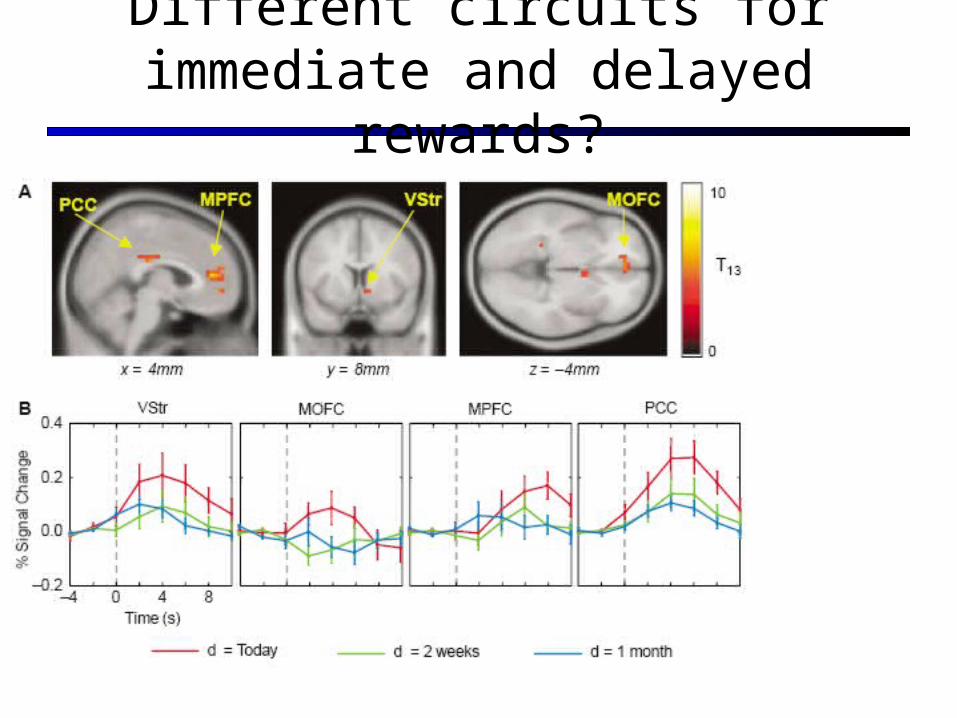
Different circuits for immediate and delayed rewards?

Immediate and Long-term rewards

Basic Conclusion of the McClure, Cohen experiments
Two critical predictions: Choices that include a reward today will preferentially engage limbic
structures relative to choices that do not include a reward today Trials in which the later reward is selected will be associated with
relatively higher levels of lateral prefrontal activation, reflecting the ability of this system to value greater rewards even when they
are delayed. The hyperbolic discounting may reflect a tension between limbic and
more pre-frontal structures… As in the grasshopper and the ant (from Aesop) Lots of implications for marketing, education…
Twist: More recent results suggest that the systems may be involved at different activity levels for immediate and delayed reward (Kable 2007, Nat. Neuroscience)
Either case provides unambiguous evidence that subjective value is explicity represented in neural activity.

Exploration vs. Exploitation
Fundamental issue in adapting to a complex (changing) world.
Complex biological issue. Multiple factors may play a role. Consistently implicates neuro-modulatory systems thought to be
involved in assessing reward and uncertainty. (D, NE, Ach) The midbrain dopamine system has been reward prediction errors The locus coeruleus (LC) noradrenergic system has been proposed
to govern the balance between exploration and exploitation in response to reward history (Aston-Jones & Cohen 2005).
Basal forebrain cholinergic system together with the adrenergic system have been proposed
to monitor uncertainty, signalling both expected and unexpected forms, respectively, which in turn might be used to promote exploitation or exploration (Yu & Dayan 2005).

Discounting and exploration
Aston-Jones, G. & Cohen, J. D. 2005 An integrative theory of locus coeruleus–norepinephrine function: adaptive gain and optimal performance. Annu. Rev. Neurosci. 28, 403–450.

Toward a biological model
McClure et al Phil. Trans. of the Royal Society Proc. 2007
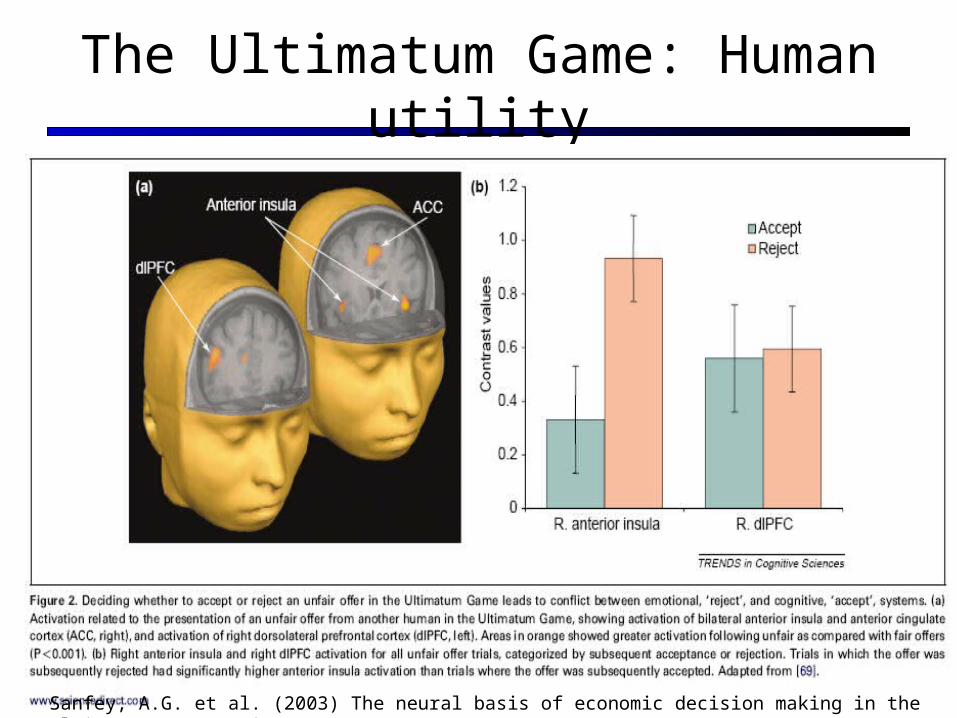
The Ultimatum Game: Human utility
Sanfey, A.G. et al. (2003) The neural basis of economic decision making in the Ultimatum Game. Science

Summary
Biological evidence for Prediction error and td-learning Discounting
Hyperbolic Two systems?
Exploitation and Exploration LC and NE phasic and tonic Social features cue relationship between
discounting, utility, and explore/exploit

Areas that are probably directly involved in RL
Basal Ganglia Striatum (Ventral/Dorsal), Putamen, Substantia Nigra
Midbrain (VT) and brainstem/hypothalamus (NC) Amygdala Orbito-Frontal Cortex Cingulate Circuit (ACC) Cerebellum PFC Insula

Neuroeconomics: Current topics How (and where) are value and probability combined in the brain to
provide a utility signal? What are the dynamics of this computation? What neural systems track classically defined forms of expected
and discounted utility? Under what conditions do these computations break down?
How is negative utility signaled? Is there a negative utility prediction signal comparable to the one for positive utility?
How are rewards of different types mapped onto a common neural currency like utility?
How do systems that seem to be focused on immediate decisions and actions interact with systems involved in longer-term planning (e.g. making a career decision)? For example, does an unmet need generate a tonic and progressively
increasing signal (i.e. a mounting ‘drive’), or does it manifest as a recurring episodic/phasic signal with increasing amplitude?
What are the connections between utility and ethics? Social issues.

Reinforcement Learning: What you should know
Basics Utilities, preferences, conditioning
Algorithms MDP formulation, Bellman’s equation Basic learning formulation, temporal-difference, q-learning
Biology Role of neuromodulators
Dopamine role Short vs. long term rewards, Hyperbolic discounting Exploration vs. exploitation
Neuroeconomics –The basic idea and questions. What you might wonder
Role of reinforcement learning in language learning Role of rewards and utility maximization in ethics, boredom… Role of Neuro-modulation in cognition and behavior..

















