ECON 497 Final Exam Page 1 of 12 ECON 497: Economic Research and Forecasting Name:________________ Spring 2008 Bellas Final Exam Return this exam to me by 4:00 on Wednesday, April 23. It may be e-mailed to me. It may be delivered to my office in Minneapolis or faxed to me before 4:00 on the 25 th at 612-659-7268. You could even drop it by my house if you like, and I’d be pleased to introduce you to my wife and my kids. You can also send it to my office through the regular post or to my home via regular post, but it should be post-marked by the 23rd. You may consult any written source you like regarding the answers to these questions but you may not ask any person other than me any questions about this test. Questions to me must be sent via e-mail and responses will be sent to the entire class. Answer all questions, and explain your answers. Fifty points total, points per part indicated in parentheses. 1. It will probably come as no surprise to you that economists love a good fight. Graduate school was a long series of scuffles, brawls and flat out donnybrooks. Happily, we always noted who was involved and, more importantly, who won. We estimated a binomial logit model of the fight outcomes and came up with the following: 1− = −1.9 + 0.4+ 0.2+ 0.01Where F i is a female dummy variable, MI i is a microeconomist dummy and A i is the age of the participant in question. A. Without knowing any of the characteristics of his opponent (an admitted weakness of the model) calculate the probability that a 40 year old male microeconomist will win a fight. (3) 1 1+ −(−1.9+0.40+0.21+0.0140) = 1 1+ 1.3 = 1 1 + 3.7 = 0.2128 B. This is a bit trickier. Based on this model and assuming that no econ fight ever ended in a tie, discuss how you might arrive at the probability a 25 year old male macroeconomist would win a fight against a 50 year old female microeconomist. Remember, and this is the trick, that there are no ties and that the probability of all possible outcomes must sum to one. (2) + −(−.+.+.+.) = + .= + . = . + −(−.+.+.+.) = + .= + . = .
Transcript
ECON 497 Final Exam Page 1 of 12
ECON 497: Economic Research and Forecasting Name:________________
Spring 2008 Bellas
Final Exam
Return this exam to me by 4:00 on Wednesday, April 23. It may be e-mailed to me. It
may be delivered to my office in Minneapolis or faxed to me before 4:00 on the 25th
at
612-659-7268. You could even drop it by my house if you like, and I’d be pleased to
introduce you to my wife and my kids. You can also send it to my office through the
regular post or to my home via regular post, but it should be post-marked by the 23rd.
You may consult any written source you like regarding the answers to these questions but
you may not ask any person other than me any questions about this test. Questions to me
must be sent via e-mail and responses will be sent to the entire class.
Answer all questions, and explain your answers. Fifty points total, points per part
indicated in parentheses.
1. It will probably come as no surprise to you that economists love a good fight.
Graduate school was a long series of scuffles, brawls and flat out donnybrooks. Happily,
we always noted who was involved and, more importantly, who won. We estimated a
binomial logit model of the fight outcomes and came up with the following:
𝑙𝑛 𝑃 𝑖
1−𝑃 𝑖 = −1.9 + 0.4𝐹𝑖 + 0.2𝑀𝐼𝑖 + 0.01𝐴𝑖
Where Fi is a female dummy variable, MIi is a microeconomist dummy and Ai is the age
of the participant in question.
A. Without knowing any of the characteristics of his opponent (an admitted weakness of
the model) calculate the probability that a 40 year old male microeconomist will win a
fight. (3)
1
1 + 𝑒−(−1.9+0.4 0 +0.2 1 +0.01 40 )=
1
1 + 𝑒1.3=
1
1 + 3.7= 0.2128
B. This is a bit trickier. Based on this model and assuming that no econ fight ever ended
in a tie, discuss how you might arrive at the probability a 25 year old male
macroeconomist would win a fight against a 50 year old female microeconomist.
Remember, and this is the trick, that there are no ties and that the probability of all
possible outcomes must sum to one. (2)
𝟏
𝟏 + 𝒆−(−𝟏.𝟗+𝟎.𝟒 𝟎 +𝟎.𝟐 𝟎 +𝟎.𝟎𝟏 𝟐𝟓 )=
𝟏
𝟏 + 𝒆𝟏.𝟔𝟓=
𝟏
𝟏 + 𝟓.𝟐𝟎𝟕= 𝟎.𝟏𝟔𝟏𝟏
𝟏
𝟏+ 𝒆−(−𝟏.𝟗+𝟎.𝟒 𝟏 +𝟎.𝟐 𝟏 +𝟎.𝟎𝟏 𝟓𝟎 )=
𝟏
𝟏+ 𝒆𝟎.𝟖=
𝟏
𝟏+ 𝟐.𝟐𝟐𝟓𝟓= 𝟎.𝟑𝟏𝟎𝟎
ECON 497 Final Exam Page 2 of 12
You might say that the probability that either one of these economists wins the fight
is equal to their probability divided by the sum of the predicted probabilities. So,
for the 25 year old male macroeconomist, the predicted probability would be:
𝟎.𝟏𝟔𝟏𝟏
𝟎.𝟏𝟔𝟏𝟏+𝟎.𝟑𝟏𝟎𝟎=
𝟎.𝟏𝟔𝟏𝟏
𝟎.𝟒𝟕𝟏𝟏= 𝟎.𝟑𝟒𝟐
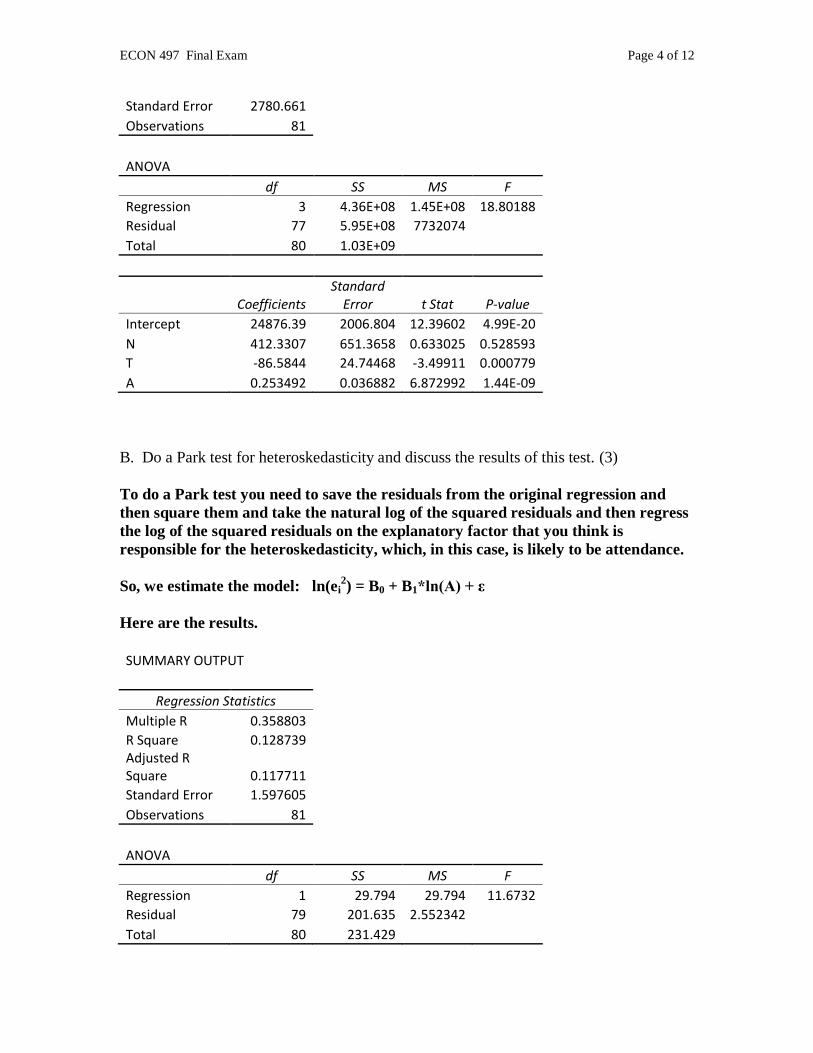
2. Use the coffee data from assignment #2 to estimate the attendance elasticity of coffee
demand (basically
𝑑𝐶𝑡𝐶𝑡𝑑𝐴 𝑡𝐴𝑡
or, if you prefer, %∆𝐶
%∆𝐴 ). You should also include the other
explanatory variables in your model.
To do this you need to regress the natural log of coffee sales on the natural log of
attendance. You should also include the other explanatory factors as well.
A. Present your results. (2)
SUMMARY OUTPUT
Regression Statistics Multiple R 0.643815 R Square 0.414497 Adjusted R Square 0.391686 Standard Error 0.102851 Observations 81
ANOVA df SS MS F
Regression 3 0.576638 0.192213 18.17032
Residual 77 0.814536 0.010578 Total 80 1.391174
Coefficients Standard
Error t Stat P-value
Intercept 8.565642 0.420669 20.36193 9.9E-33
lnA 0.250342 0.036715 6.818522 1.83E-09
lnT -0.22716 0.060034 -3.78389 0.000304
N 0.01227 0.024091 0.509322 0.611983
The elasticity is the estimated coefficient on ln(A), which is 0.250342. You might
also have done this with T instead of lnT as an explanatory variable and gotten the
following:
ECON 497 Final Exam Page 3 of 12
SUMMARY OUTPUT
Regression Statistics Multiple R 0.645610663 R Square 0.416813128 Adjusted R
Square 0.394091561 Standard Error 0.102647716 Observations 81
ANOVA df SS MS F
Regression 3 0.579859742 0.193287 18.34438
Residual 77 0.811314631 0.010537 Total 80 1.391174373