Page 1
High Performance Embedded Computing
© 2007 Elsevier
Lecture 15: Embedded Multiprocessor Architectures
Embedded Computing SystemsMikko Lipasti, adapted from M. Schulte
Based on slides and textbook from Wayne Wolf
Page 2
© 2006 Elsevier
Topics
Overview and Motivation. Embedded Multiprocessor Design Techniques Embedded Multiprocessor Architectures. Processing Elements
Page 3
© 2006 Elsevier
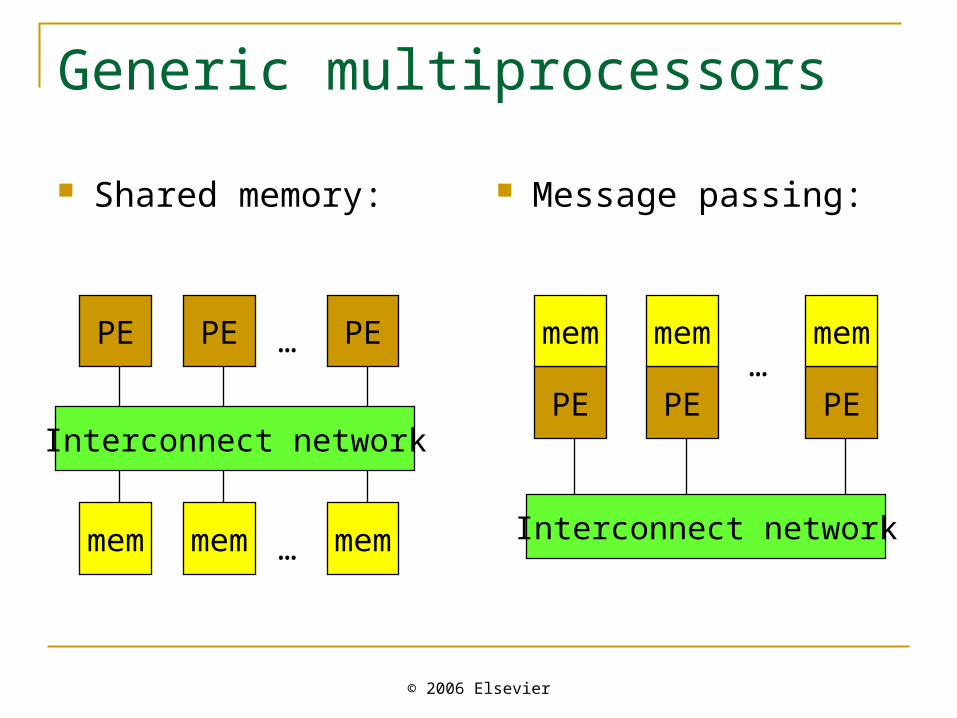
Generic multiprocessors
Shared memory: Message passing:
PE
mem
PE
mem
PE
mem
…
…
Interconnect networkPE
mem
PE
mem
PE
mem…
Interconnect network
Page 4
© 2006 Elsevier
Design choices
Processing elements: Number. Type. Homogeneous or heterogeneous.
Memory: Size and configuration. Shared or. private memories.
Interconnection networks: Topology. Protocol.
Page 5
© 2006 Elsevier
Why embedded multiprocessors? Real-time performance---segregate tasks to
improve predictability and performance. Low power/energy---segregate tasks to allow
idling, segregate memory traffic. Cost---several small processors may be more
efficient than one large processor.
Page 6
© 2006 Elsevier
Example: cell phones
Variety of tasks: Error detection and correction. Voice compression/decompression. Protocol processing. Position sensing. Music. Cameras. Web browsing.
Page 7
© 2006 Elsevier
Example: video compression
QCIF (177 x 144) used in cell phones and portable devices: 11 x 9 macroblocks of 16 x 16. Frame rate of 15 or 30 frames/sec. Seven correlations per macroblock = 177,408
pixel comparisons per frame. Feig/Winograd DCT algorithm uses 94
multiplications and 454 additions per 8 x 8 2D DCT.
Page 8
© 2006 Elsevier
Austin et al.: portable supercomputer Next-generation workloads on portable device:
Speech compression. Video compression and analysis. High-resolution graphics. High-bandwidth wireless communications.
Workload is 10,000 SPECint = 16 x 2GHz Pentium 4.
Power budget of 75 mW.
Page 9
© 2006 Elsevier
Performance trends on desktop
[Aus04] © 2004 IEEE Computer Society
Page 10
© 2006 Elsevier
Energy trends on desktop
[Aus04] © 2004 IEEE Computer Society
Page 11
© 2006 Elsevier
Specialization and multiprocessing Many embedded multiprocessors are
heterogeneous: Processing elements. Interconnect. Memory.
Why use heterogeneous multiprocessors? Some operations (8 x 8 DCT) are standardized. Some operations are specialized. High-throughput operations may require specialized units.
Heterogeneity reduces power consumption. Heterogeneity improves real-time performance.
Page 12
© 2006 Elsevier
Multiprocessor design methodologies Analyze workload that
represents system’s usage. May include multiple programs.
Platform-independent optimizations eliminate side effects due to reference software implementation.
Platform design is based on operations, memory, etc.
Software can be further optimized to take advantage of platform.
Page 13
© 2006 Elsevier
Cai and Gajski modeling levels Implementation: corresponds directly to hardware. Cycle-accurate computation: captures accurate
computation times, approximate communication times.
Time-accurate communication: captures communication times accurately but computation times only approximately.
Bus-transaction: models bus operations but is not cycle-accurate.
PE-assembly: communication is untimed, PE execution is approximately timed.
Specification: functional model.
Page 14
© 2006 Elsevier
Multiprocessor systems-on-chips MPSoC is a complete platform for an
application. Platform is usually tailored for a particular
application domain. Generally heterogeneous processing
elements. Combine off-chip bulk memory with on-chip
specialized memory.
Page 15
© 2006 Elsevier
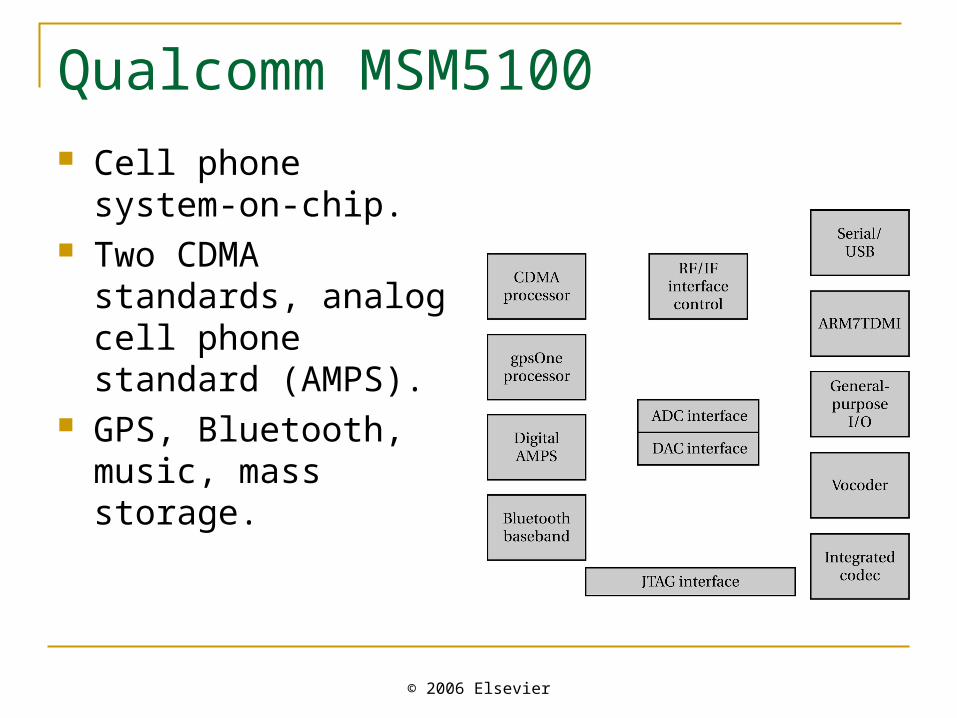
Qualcomm MSM5100 Cell phone system-on-
chip. Two CDMA standards,
analog cell phone standard (AMPS).
GPS, Bluetooth, music, mass storage.
Page 16
© 2006 Elsevier
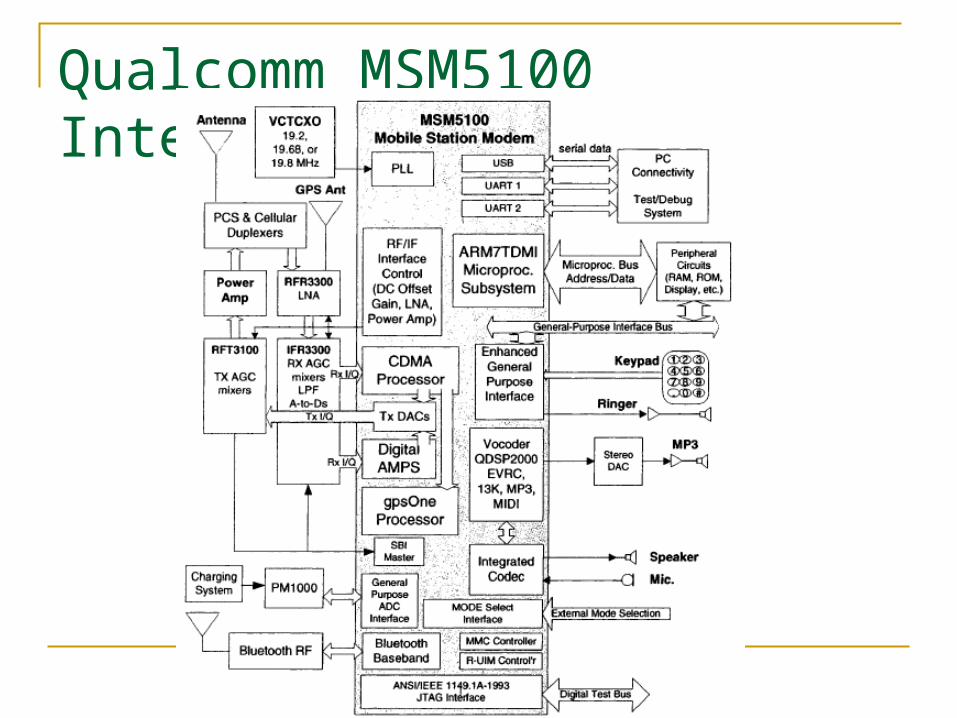
Qualcomm MSM5100 Integration
Page 17
© 2006 Elsevier
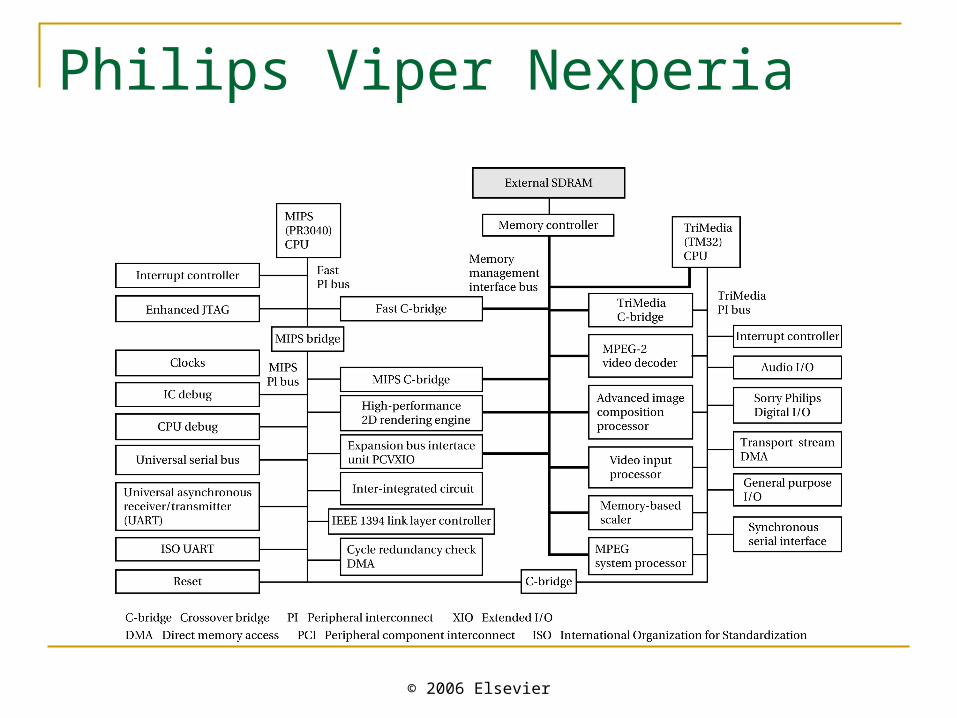
Philips Viper Nexperia
Page 18
© 2006 Elsevier
Viper Nexperia characteristics Designed to decode 1920 x 1080 HDTV. Trimedia runs video processing functions. MIPS runs operating system. Synchronous DRAM interface for bulk
storage. Variety of I/O devices. Accelerators: image composition, scaler,
MPEG-2 decoder, video input processors, etc.
Page 19
© 2006 Elsevier
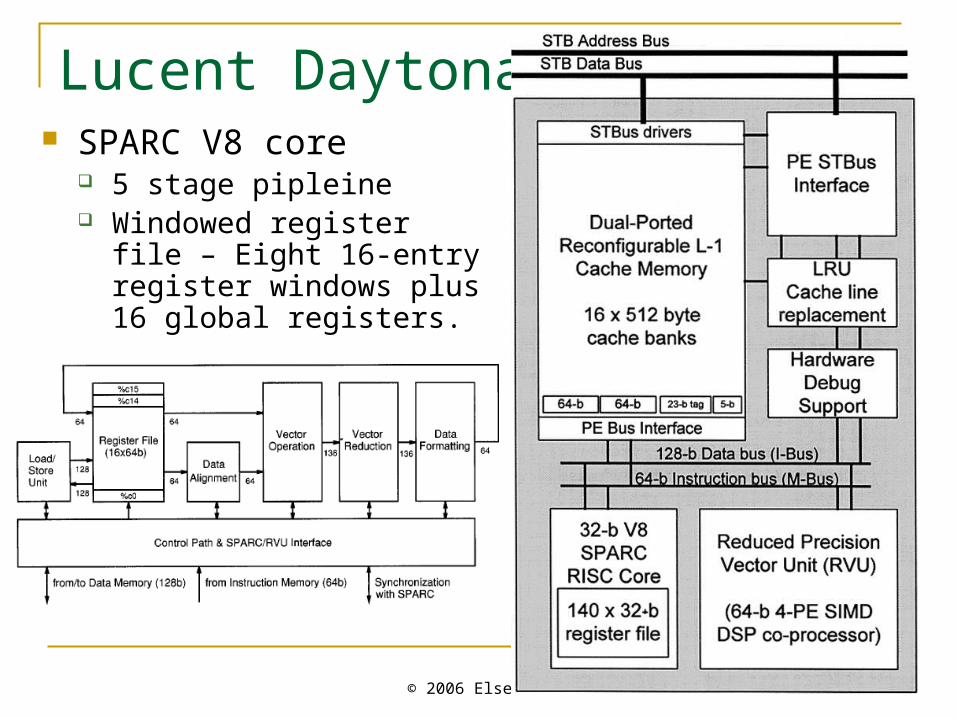
Lucent Daytona MIMD for signal processing
apps. Processing element is based on
SPARC V8. DSP extensions
Reduced precision vector unit has 16 x 64-bit vector register file.
Reconfigurable 8KB level 1 cache 16 banks configured as I-cache, D-
cache, or scratchpad Daytona split transaction bus.
Page 20
© 2006 Elsevier
Lucent Daytona PE SPARC V8 core
5 stage pipleine Windowed register file –
Eight 16-entry register windows plus 16 global registers.
Page 21
© 2006 Elsevier
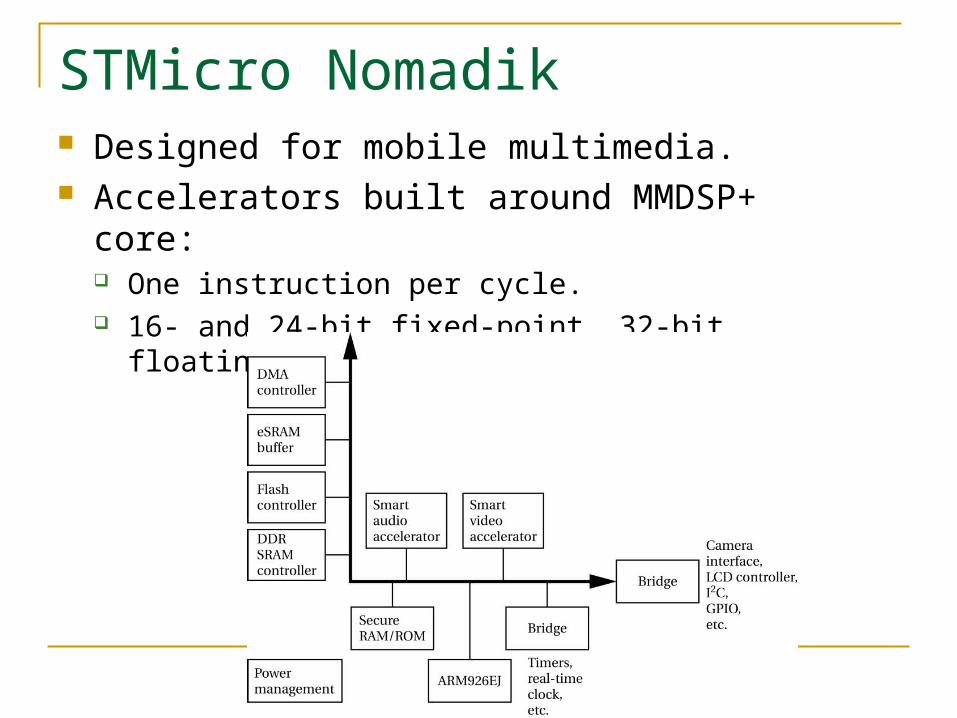
STMicro Nomadik Designed for mobile multimedia. Accelerators built around MMDSP+ core:
One instruction per cycle. 16- and 24-bit fixed-point, 32-bit floating-point.
Page 22
© 2006 Elsevier
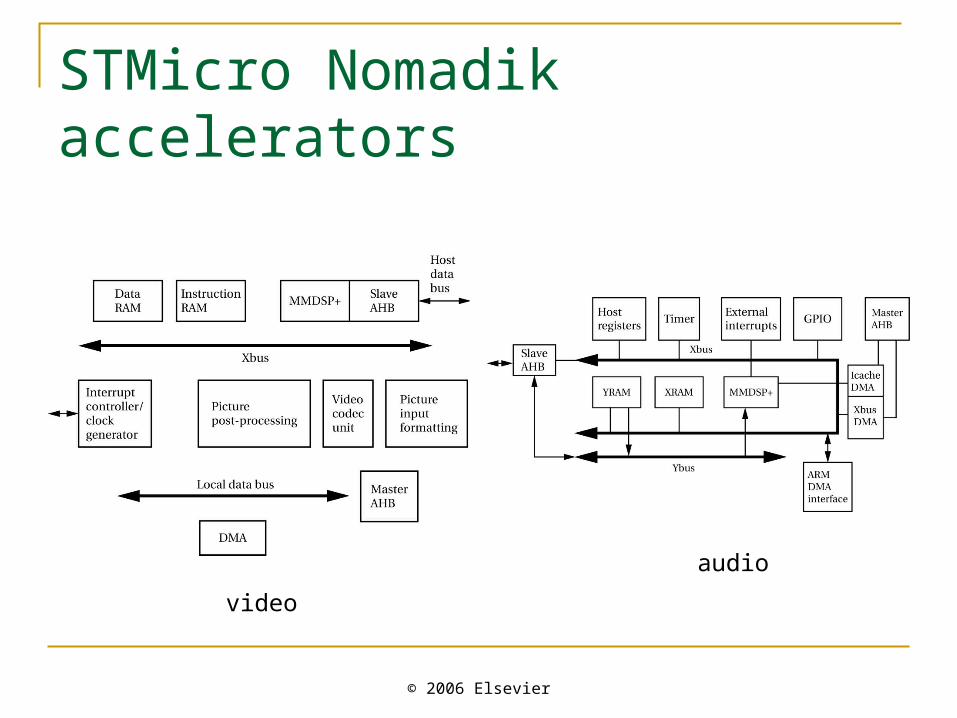
STMicro Nomadik accelerators
video
audio
Page 23
© 2006 Elsevier
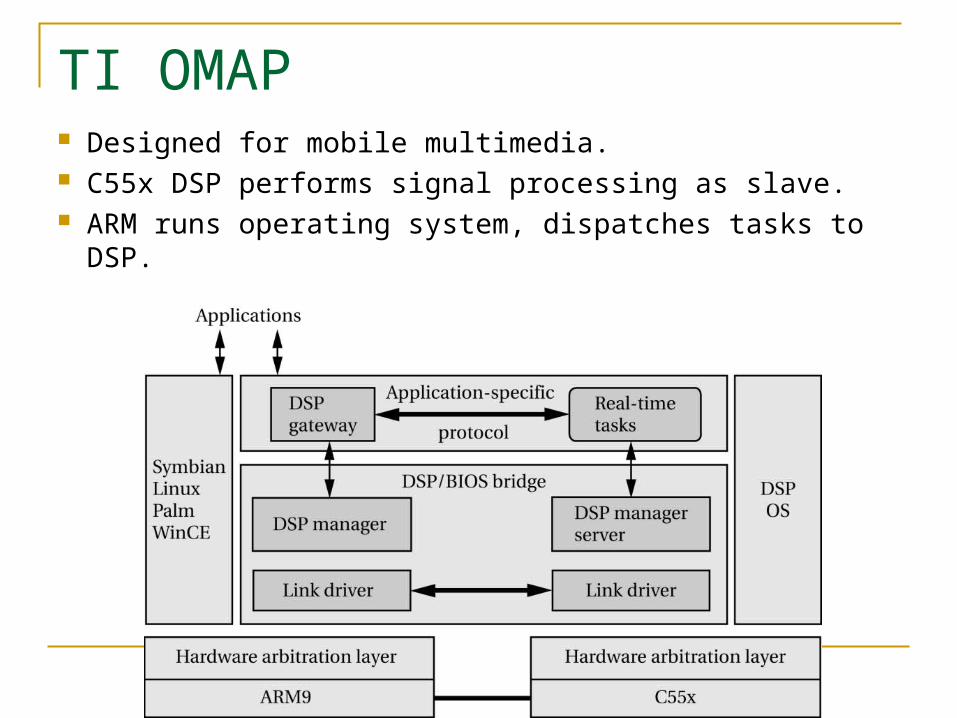
TI OMAP Designed for mobile multimedia. C55x DSP performs signal processing as slave. ARM runs operating system, dispatches tasks to DSP.
Page 24
© 2006 Elsevier
TI OMAP 5912
Page 25
© 2006 Elsevier
Processing elements issues
How many do we need? What types of processing elements do we
need? Analyze performance/power requirements of
each process in the application. Choose a processor type for each process. Determine what processes should share
processing elements
Page 26
© 2006 Elsevier
Embedded Multiprocessor Questions Of the embedded multiprocessors we discussed in
this lecture, which one seemed The most general purpose? Why? The most application-specific? Why?
What are advantages and disadvantages of the configurable cache used in the Lucent Daytona architecture?
What benefits do the accelerators in the Viper Nexperia processor provide?
For what types of applications are accelerators most important?