Elias, Father of Coding Theory Convolutional Encoding Decoding a Convolutional Code An Exercise Introduction to Convolutional Codes, Part 1 Frans M.J. Willems, Eindhoven University of Technology September 29, 2009 Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Transcript
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Introduction to Convolutional Codes, Part 1
Frans M.J. Willems, Eindhoven University of Technology
September 29, 2009
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Elias, Father of Coding Theory
Convolutional EncodingTextbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
Decoding a Convolutional CodeThree Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
An Exercise
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Peter Elias (U.S., 1923 - 2001)
Figure: P. Elias.
1955 - ”Coding for Noisy Channels”.Hamming had already introduced ”parity-check codes,”but Peter went a giant step farther by showing for thebinary symmetric channel that such linear codes sufficeto exploit a channel to its fullest. In particular, heshowed that ”error probability as a function of delay isbounded above and below by exponentials, whoseexponents agree for a considerable range of values ofthe channel and the code parameters,” and that thesesame results apply to linear codes. These exponentialerror bounds presaged those obtained for generalchannels ten years later by Gallager. In this same paperPeter introduced and named ”convolutional codes”. Hismotivation was to show that it was in principle possible,by using a convolutional code with infinite constraintlength, ”to transmit information at a rate equal tochannel capacity with probability one that no decodedsymbol will be in error.” (by J.L. Massey)
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
Textbook Convolutional Encoder
We consider the encoder that appears in almost every elementary text onconvolutional codes. It consists of two connected delay elements (a shift register) andtwo modulo-2 adders (EXORs). The output of a delay element time t is equal to itsinput at time t − 1. The time t is integer.
� �� �
-
-
�
-
-
-
-
�?��⊕
⊕
D Du(t) s1(t) s2(t)
v1(t)
v2(t)
Motivation is that shift-registers can be used to produce random sequences, and wehave learned from Shannon that random codes reach capacity.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
Finite-State Description
Let T be the number of symbols that is to be encoded. For the input u(t) of theencoder we assume that
u(t) ∈ {0, 1}, for t = 1, 2, · · · ,T and
u(T + 1) = u(T + 2) = 0. (1)
For the outputs v1(t) and v2(t) of the encoder we then have that
v1(t) = u(t)⊕ s2(t),
v2(t) = u(t)⊕ s1(t)⊕ s2(t), for t = 1, 2, · · · ,T + 2, (2)
while the states s1(t) and s2(t) satisfy
s1(1) = s2(1) = 0,
s1(t) = u(t − 1),
s2(t) = s1(t − 1), for t = 2, 3, · · · ,T + 3. (3)
Note the the encoder starts and stops in the all-zero state (s1, s2) = (0, 0).
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
The length of the input words is T hence there are 2T codewords. We assume thatthey all have probability 2−T , or I (1),U(2), · · · ,U(T ) are all uniform.
The length of the codewords is 2(T + 2) therefore the rate
RT =log 2T
2(T + 2)=
T
2(T + 2)=
1
2−
1
T + 2. (5)
Note that R = RT→∞ = 1/2. We therefore call our encoder a rate-1/2 encoder.
The memory M associated with our code is 2. In general the encoder uses the pastinputs ut−M , · · · , ut−1 and the current input ut to construct the outputs v1(t), v2(t).Related to this is the constraint length K = M + 1, since a new pair of outputs isdetermined by M previous input symbols and the current one.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
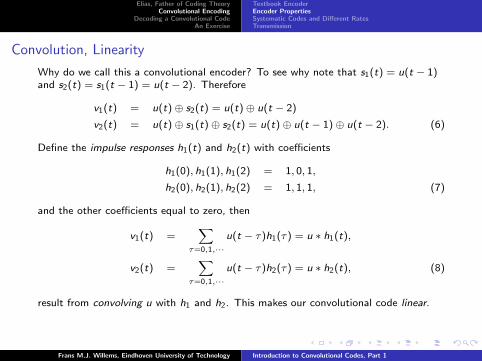
Convolution, Linearity
Why do we call this a convolutional encoder? To see why note that s1(t) = u(t − 1)and s2(t) = s1(t − 1) = u(t − 2). Therefore
Define the impulse responses h1(t) and h2(t) with coefficients
h1(0), h1(1), h1(2) = 1, 0, 1,
h2(0), h2(1), h2(2) = 1, 1, 1, (7)
and the other coefficients equal to zero, then
v1(t) =∑
τ=0,1,···u(t − τ)h1(τ) = u ∗ h1(t),
v2(t) =∑
τ=0,1,···u(t − τ)h2(τ) = u ∗ h2(t), (8)
result from convolving u with h1 and h2. This makes our convolutional code linear.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
A Systematic Convolutional Code
� �?- -
-
-
-
-
�⊕
D D D
u(t) v1(t)
v2(t)
The encoder in the figure above is systematic since one of its outputs is equal to theinput i.e. v1(t) = u(t). The rate R of this code is 1/2, its memory M = 3.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
A Rate-2/3 Convolutional Code
� �� �� �?
-
6?
-
-
?
?-
-
-
-
-
6
⊕
⊕
⊕
u2(t)
v2(t)
v1(t)
v3(t)
u1(t)
D
D
For every k = 2 binary input symbols the encoder in figure above produces n = 3binary output symbols. Therefore its rate R = k/n = 2/3. The memory M of thisencoder is 1 since only u1(t − 1) and u2(t − 1) are used to produce v1(t), v2(t), andv3(t).
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Textbook EncoderEncoder PropertiesSystematic Codes and Different RatesTransmission
Transmission via a BSC
Suppose that we use our example encoder and take the length T of the input wordsu = (u1, u2, · · · , uT ) equal to 6. We then get codewords x = (x1, x2, · · · , x2(T+2)) =(v1(1), v2(1), v1(2), · · · , v2(T + 2)) with codeword length equal to 2(T + 2) = 16. Weassume that all codewords are equiprobable.
These codewords are transmitted over a binary symmetric channel (BSC), see thefigure below, with cross-over probability 0 ≤ p ≤ 1/2.
How should we efficiently decode this received sequence?
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Communicating a Message, Error Probability
P(m) --- P(y |x)
m
d(y)
yx
e(m)
m̂-
Consider the communication system in the figure.A message source produces message m ∈M with a-priori probability Pr{M = m}.An encoder transforms the message into a channel input1 x ∈ X , hence x = e(m).Now the channel output2 y ∈ Y is received with probability Pr{Y = y |X = x}.The decoder observes y and produces an estimate m̂ ∈M of the transmittedmessage, hence m̂ = d(y).
How should decoding rule d(·) be chosen such that the error probability
Pe∆= Pr{M̂ 6= M} (10)
is minimized?
1This is in general a sequence.2Typically a sequence.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
The Maximum A-Posteriori Probability (MAP) Rule
First we form an upper bound for the probability that no error occurs:
1− Pe =∑
y
Pr{M = d(y),Y = y}
=∑
y
Pr{Y = y}Pr{M = d(y)|Y = y}
≤∑
y
Pr{Y = y}maxm
Pr{M = m|Y = y}. (11)
Observe that equality is achieved if and only if3
d(y) = arg maxm
Pr{M = m|Y = y}, for all y that can occur. (12)
Since {Pr{M = m|Y = y},m ∈M} are the a-posteriori probabilities after havingreceived y , we call this rule the maximum a-posteriori probability rule (MAP-rule).
3It is possible that the maximum is not obtained for a unique m.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
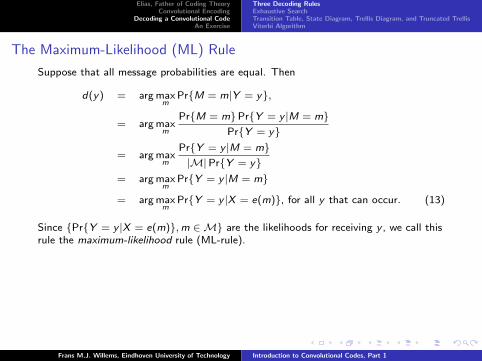
The Maximum-Likelihood (ML) Rule
Suppose that all message probabilities are equal. Then
d(y) = arg maxm
Pr{M = m|Y = y},
= arg maxm
Pr{M = m}Pr{Y = y |M = m}Pr{Y = y}
= arg maxm
Pr{Y = y |M = m}|M|Pr{Y = y}
= arg maxm
Pr{Y = y |M = m}
= arg maxm
Pr{Y = y |X = e(m)}, for all y that can occur. (13)
Since {Pr{Y = y |X = e(m)},m ∈M} are the likelihoods for receiving y , we call thisrule the maximum-likelihood rule (ML-rule).
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
The Minimum-Distance (MD) Rule
Suppose that all message probabilities are equal, and that e(m) is a binary codewordof length L, for all m ∈M. Moreover let y be the output sequence of a binarysymmetric channel with cross-over probability 0 ≤ p ≤ 1/2, when e(m) is its inputsequence. Then
Pr{Y = y |X = e(m)} = pdH(e(m),y)(1−p)L−dH(e(m),y) = (1−p)L
(p
1− p
)dH(e(m),y)
.
(14)where dH(·, ·) denotes Hamming distance. Now
d(y) = arg maxm
Pr{Y = y |X = e(m)},
= arg minm
dH(e(m), y), for all y that can occur. (15)
Since {dH(e(m), y),m ∈M} are the Hamming distances between codewords e(m)and the received sequence y , we call this rule the minimum (Hamming) distance rule(MD-rule).
Conclusion is that minimum Hamming distance decoding should be applied to decodey = (10, 11, 00, 11, 10, 11, 11, 00).
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Complexity of Exhaustive Search
We could do an exhaustive search. Using minimum-distance (MD) decoding we couldsearch all 2T = 64 codewords. A serious disadvantage of this approach is that thesearch complexity increases exponentially in the number of input symbols T . We willtherefore discuss an efficient method, called the Viterbi algorithm. The complexity ofthis method is linear in T .
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
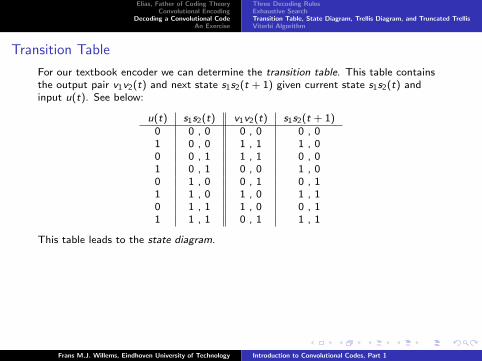
Transition Table
For our textbook encoder we can determine the transition table. This table containsthe output pair v1v2(t) and next state s1s2(t + 1) given current state s1s2(t) andinput u(t). See below:
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
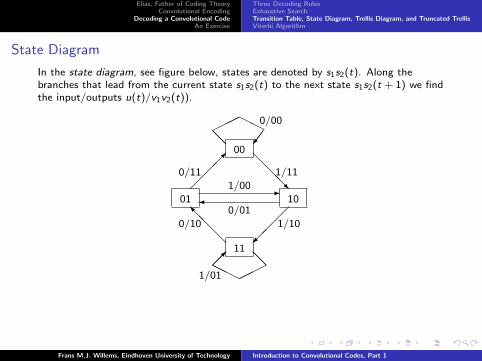
State Diagram
In the state diagram, see figure below, states are denoted by s1s2(t). Along thebranches that lead from the current state s1s2(t) to the next state s1s2(t + 1) we findthe input/outputs u(t)/v1v2(t)).
10�����
@@@I �
��
@@@R
@@���HH
��/
@@���HH
H���
11
0/01
1/00
0/11
0/10
1/01
1/10
1/11
0/00
00
01-
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
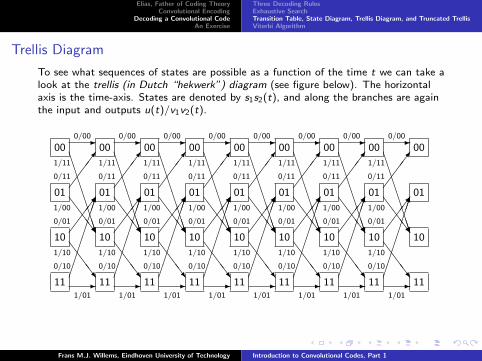
Trellis Diagram
To see what sequences of states are possible as a function of the time t we can take alook at the trellis (in Dutch “hekwerk”) diagram (see figure below). The horizontalaxis is the time-axis. States are denoted by s1s2(t), and along the branches are againthe input and outputs u(t)/v1v2(t).
11
-
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
-
1/011/01
0/100/10
1/011/011/01
0/100/100/100/100/10
1/011/011/01
0/10
0/00
1/11
0/11
1/00
0/01
1/10
00
01
10
1111
10
01
00
1/10
0/01
1/00
0/11
1/11
0/000/00
1/11
0/11
1/00
0/01
1/10
00
01
10
1111
10
01
00
1/10
0/01
1/00
0/11
1/11
0/000/00
1/11
0/11
1/00
0/01
1/10
00
01
10
1111
10
01
00
1/10
0/01
1/00
0/11
1/11
0/000/00
1/11
0/11
1/00
0/01
1/10
00
01
10
1111
10
01
00
1/10
0/01
1/00
0/11
1/11
0/00
00
01
10
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Truncated Trellis
Each codeword now corresponds to a path in the trellis diagram. This path starts att = 1 in state s1s2 = 00 and traverses along T + 2 branches and then ends att = T + 3 in state s1s2 = 00 again. The truncated trellis (see figure below) containsonly the states and branches that can actually occur.
11
BBBBBBBN
- -
BBBBBBBN���7
SSSw
-
���7
��������
���7
���7
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
-
SSSw��������
���7SSSw
BBBBBBBN
���7
-
- -
-
���7BBBBBBBN
SSSw���7
��������
SSSw
0/100/100/100/100/10
1/011/011/011/01
0000
1/11
0/00 0/00
1/11
0/01
1/10
00
10
0/00
00
01
0/11
11
10
01
00
0/01
0/11
0/00
START STOP
0/00
1/11
0/11
1/00
0/01
1/10
00
01
10
1111
10
01
00
1/10
0/01
1/00
0/11
1/11
0/00
11
10
01
00
1/10
0/01
1/00
0/11
1/11
0/00 0/00
1/11
0/11
1/00
0/01
1/10
00
01
10
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Trellis with Branch Distances
After having received channel output sequence y , to do MD-decoding, we must beable to compute Hamming distances dH(x , y) where x is a codeword. Since
dH(x , y) =T+2∑t=1
dH(v1v2(t), y(2t − 1)y(2t)), (16)
we first determine all branch distances dH(v1v2(t), y(2t − 1)y(2t)), see figure.
10-1
��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
-
���7
���7
��������
���7
-
SSSw
���7
BBBBBBBN
--
BBBBBBBN
0000-0
11-2
10-1
01-1
11-0
00-2
01-1
10-1
10-1
01-1
00-2
11-0
11-0
00-2
01-2
10-0
10-0
01-2
00-1
11-1
11-1
00-1
01-1
10-1
10-1
01-1
00-2
11-0
11-0
00-2
01-1
10-1
10
00-1
11-1
11
10
01
0000
01
10
1111
10
01
0000
01
10
11
00
01
10
11
01
00
10
0000
11 00 11 10 11 11 00y =
START STOP
00-2
11-0
01-1
10-1
00-0
11-2
11-2
00-0
01-1
SSSw
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Viterbi’s Principle
Let s = s1s2 and v = v1v2.
s(t + 1)���*
���*
HHHj
HHHj
���*
HHHj
v ′′(t)
v ′(t)
s′′(t)
s′(t)
Assume that state s(t + 1) at time t + 1 can be reached only via states s′(t) and s′′(t)at time t through the branches v ′(t) and v ′′(t) respectively. Then (Viterbi [1967]):
Best path to s(t + 1) = best of ( all paths to s′(t) extended by v ′(t),all paths to s′′(t) extended by v ′′(t) )
= best of ( best path to s′(t) extended by v ′(t),best path to s′′(t) extended by v ′′(t) ).
This principle can be used recursively. First determine the best path leading from thestart state s(1) to all states at time 2, then the best path to all states at time 3, etc.,and finally determine the best part to the final state s(T + 3). Dijkstra’s shortest pathalgorithm [1959] is more general and more complex than the Viterbi method.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
The Viterbi Algorithm
Define Ds(t) to be the total distance of a best path leading to state s at time t. LetBs(t) denote a best path leading to this state. Define ds′,s(t − 1, t) to be the distancecorresponding to the branch connecting state s′ at time t − 1 to state s at time t. Letbs′,s(t − 1, t) denote this branch.
1. Set t := 1. Also set the total distance of the starting state D00(1) := 0 and setthe best path leading to it B00(1) := φ i.e. equal to the empty path.
2. Increment t i.e. t := t + 1. For all possible states s at time t let As(t) be the setof states at time t − 1 that have a branch leading to state s at time t. Assumethat s′ ∈ As(t) minimizes Ds′ (t − 1) + ds′,s(t − 1, t) i.e. survives. Then set
Ds(t) := Ds′ (t − 1) + ds′,s(t − 1, t)
Bs(t) := Bs′ (t − 1) ∗ bs′,s(t − 1, t).
Here ∗ denotes concatenation.
3. If t = T + 3 output the best path B00(t), otherwise go to step 2.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Forward: Add, Compare, and Select
Best-path-metrics are denoted in the states. An asterisk denotes that each of the twoincoming paths into a state can be chosen as survivor.
4
��������
��������
���� ��������
��������
������������
���� ����SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
-
���7
���7
��������
���7
-
SSSw
���7
BBBBBBBN
--
BBBBBBBN
-
00-0
11-2
10-1
01-1
11-0
00-2
01-1
10-1
10-1
01-1
00-2
11-0
11-0
00-2
01-2
10-0
10-0
01-2
00-1
11-1
11-1
00-1
01-1
10-1
10-1
01-1
00-2
11-0
11-0
00-2
01-1
10-1
10
00-1
11-1
11 00 11 10 11 11 00y =
START STOP
00-2
11-0
01-1
10-1
00-0
11-2
11-2
00-0
01-1
10-1
0 1
1
3
2
1
2
3
2
2
2
2
3*
3
3*
3
3
3
3
3
4*
3
4*
4
4
����
Note that there is a best path (codeword) at distance 4 from the received sequence.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
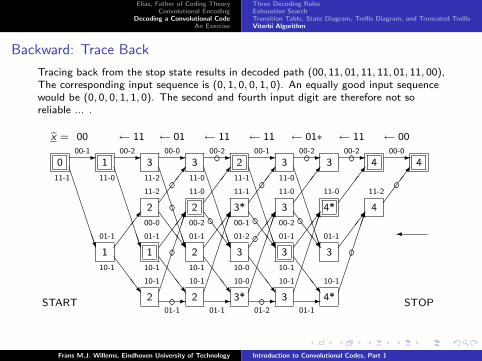
Backward: Trace Back
Tracing back from the stop state results in decoded path (00, 11, 01, 11, 11, 01, 11, 00),The corresponding input sequence is (0, 1, 0, 0, 1, 0). An equally good input sequencewould be (0, 0, 0, 1, 1, 0). The second and fourth input digit are therefore not soreliable ... .
← 11
��������
��������
���� ��������
��������
������������
���� ����SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
SSSw��������
���7SSSw
BBBBBBBN
���7
-
--
-
���7BBBBBBBN
SSSw���7
��������
SSSw
-
���7
���7
��������
���7
-
SSSw
���7
BBBBBBBN
--
BBBBBBBN
�
00x̂ = ← 11 ← 01 ← 11
00-0
11-2
10-1
01-1
11-0
00-2
01-1
10-1
10-1
01-1
00-2
11-0
11-0
00-2
01-2
10-0
10-0
01-2
00-1
11-1
11-1
00-1
01-1
10-1
10-1
01-1
00-2
11-0
11-0
00-2
01-1
10-1
00-1
11-1
START STOP
00-2
11-0
01-1
10-1
00-0
11-2
11-2
00-0
01-1
10-1
0 1
1
3
2
1
2
3
2
2
2
2
3*
3
3*
3
3
3
3
3
4*
3
4*
4
4
4
← 11 ← 00← 01∗
����
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Three Decoding RulesExhaustive SearchTransition Table, State Diagram, Trellis Diagram, and Truncated TrellisViterbi Algorithm
Complexity
Fortunately the complexity of the Viterbi algorithm is linear in the codeword length T .At each time we have to add, compare and select (ACS) in every state. Thecomplexity is therefore also linear in the number of states at each time, which is 4 inour case. In general the number of states is 2m where m is the number of delayelements in the encoder. Therefore Viterbi decoding is in practise only possible (now)if m is not much higher than say 10, i.e. the number of states is not much more than210 = 1024. Later we shall see that the code performance improves for increasingvalues of m.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1
Elias, Father of Coding TheoryConvolutional Encoding
Decoding a Convolutional CodeAn Exercise
Exercise
We transmit an information-word (x(1), x(2), x(3), x(4), x(5)) over aninter-symbol-interference (ISI) channel. This information-word is preceded andfollowed by zeroes, hence
x(t) = 0 for integer t /∈ {1, 2, 3, 4, 5}x(t) ∈ {−1, 1} for t ∈ {1, 2, 3, 4, 5}.
All 32 information-words occur with equal probability.For the ISI channel for integer times t we have that
y(t) = x(t) + x(t − 1) + n(t)
where the probability density function of the noise n(t) is given by
p(n) =1√
2πexp(−
n2
2),
thus n(t) has a Gaussian density.The received sequence satisfies y(1) = +0.3, y(2) = +0.2, y(3) = +0.1, y(4) = −1.1,y(5) = +2.5 en y(6) = +0.5.Decode the information-word with a decoder that minimizes the word-error probability.Show first that the decoder should minimize (squared) Euclidean distance.
Frans M.J. Willems, Eindhoven University of Technology Introduction to Convolutional Codes, Part 1


























![Convolutional Codes R-J Chen. p2. OUTLINE [1] Shift registers and polynomials [2] Encoding convolutional codes [3] Decoding convolutional codes.](https://static.documents.pub/doc/80x56/5697c02a1a28abf838cd7c3c/convolutional-codes-r-j-chen-p2-outline-1-shift-registers-and-polynomials.jpg)








![Convolutional Codes. p2. OUTLINE [1] Shift registers and polynomials [2] Encoding convolutional codes [3] Decoding convolutional codes [4] Truncated.](https://static.documents.pub/doc/80x56/56649ec95503460f94bd6446/convolutional-codes-p2-outline-1-shift-registers-and-polynomials-.jpg)

