69
Kak Neural Network Mehdi Soufifar: [email protected] Mehdi Hoseini: [email protected] Amir hosein Ahmadi: [email protected]
| Date post: | 27-Dec-2015 |
| Category: |
Documents |
| Upload: | mavis-adams |
| View: | 236 times |
| Download: | 2 times |

Kak Neural Network
Mehdi Soufifar:[email protected]
Mehdi Hoseini:[email protected]
Amir hosein Ahmadi:[email protected]

2
Corner Classification approach
00.2
0.40.6
0.8
1
0
0.2
0.4
0.6
0.8
10
0.2
0.4
0.6
0.8
1
Corners For XOR Function:
1
0
0
1

3
Corner Classification approach… Map n-dimensional binary vectors (input)
into m-dimensional binary vectors (as output)
Mapping function (f) is:
Using…: Backpropagation (does not quarantee
convergence). …
)( ii XfY
1
0
1
0
1
1
0
0
0
1
1
0
fY

4
Introduction Feedback (Hopfield with delta learning) and feedforward
(backpropagation) networks learn patterns slowly: the network must adjust weights connecting links between input and output until it obtains the correct response to the training patterns.
But biological learning is not a single process: some forms are very quick and others relatively slow. Short-term biological memory, in particular, works very quickly, so slow neural network models are not plausible candidates in this case

5
Training feedforward NN [1] Kak proposed CC1,CC2 in January 1993. Example:
Exclusive-OR mapping

6
Training feedforward NN [1] Kak proposed CC1,CC2 in January 1993. Example:
Exclusive-OR mapping

7
CC1 as an example Initialize all weight with zero. If result is true do nothing. If result=1 and supervise say 0 subtract x vector from
weight vector. If result=0 and supervise say 1 add x vector to weight
vector.
X1
X2
y11
1
Hidden Layer as corners
Input Layer Output Layer (OR Gate)
0 1
1 0

8
CC1… Result on first output corner:
samples
W1 W2 W3
Init,1 0 0 0
2 0 1 1
3 -1 1 0

9
CC1… Result on second output corner:
samples
W1 W2 W3
Init,1,2 0 0 0
3 1 0 1
4,1,2 0 -1 0
3 1 -1 1
4,1,2 0 -2 0
3,4 1 -2 1
1 1 -2 0

10
CC1 Algorithm Notations:
Mapping is Y=f(X), X,Y are n and m dimensional binary vectors. Therefore we have (i=1,…,k) (k=number of vectors).
Weight of Vector: number of 1 element on it. If the k output sequence are written out in an array then
the columns may be viewed as a sequence of m, k dimensional vectors .
Weight of is . Weight of is . Weight of is .
)( ii XfY
iWiY iiX is
)...( 21 kjjjj yyyW j
kmkjk
mj
mj
yyy
yyy
yyy
1
2221
1111
1W mWjW

11
CC1 Algorithm… Start with the random initial weight vector. If the neuron says no when it should say yes,
add the input vector to the weight vector. If the neuron says yes when it should say no,
subtract the input vector from the weight vector. Do nothing otherwise.
Note that a main problem is “what’s the number neurons in the hidden layer?”

12
Number of hidden neurons•Consider that:
iki
i 0
• And the number of hidden neurons can be reduced by the duplicating neurons equals to:

13
Number of hidden neurons… Theorem: The number of hidden neurons required to
realize the mapping ,i=1,2,…,k is equal to:
And since we can say: The number of hidden neurons required to realize
the mapping is at most k.
ii XY
k
i i
m
j j 11
k
i i
m
j j 11

14
Real Applications problem [1]
Comparison Training results:
Alg. On XOR problem Number of Iteration
BP 6,587 [1]
CC (CC1) 8 [1]

15
Proof of convergence [1] We would establish that the classification algorithm
converges if there is a weight vector such that for the corner that needs to be classified, and otherwise.
Wt is the weight vector of t-th iteration Θ is the angle between and Wt
If neuron say no, when it must say yes:
W XW XW
W

16
Proof of convergence… Numerator on cosine becomes:
produces correct result, we know that:
And:
And we get same inequality for the other type of misclassification( ).
XW
XW
W

17
Proof of convergence… Repeating this process for t iteration produces:
For the cosine’s denominator( ):
If neuron says no we have then:
And same result will be obtained for other type of misclassification( ).
01 XWt
XW

18
Proof of convergence… Repeating substitution produces:
Since ,we have:
Then we have:
tnWt 2
nX 2

19
Proof of convergence… From (1), (2) we can say:
nW
t
ntW
t
WW
WW
t
t
cos

20
Types of memory
Long-term In AI like BP & RBF,…
Short-term Learn instantaneously with good generalization

21
Current network characteristics
What the problem of BP and RBF They require iterative training Take long time to learn Sometimes doesn’t converge
Result They are not applicable in real-time application They could never learn short-term,
instantaneously-learned memory (the most significant aspects of biological working memory ).

22
CC2 algorithm In this algorithm weight are given as
follows:
The value of implies that the threshold of hidden neurons to separate this sequence is .
Ex: Result of CC2 on last example is:
0 1 1 0
-1 1 1 -1
W3 = -(si-1)=-(1-1)=0

23
Real Applications problem
Comparison Training results:
Alg. On XOR problem Number of Iteration
BP 6,587 [1]
CC (CC1) 8 [1]
CC (CC2) 1 [1]

24
CC2’s Generalization…[3] Hidden neurons’ weight are:
r is the radius of the generalized region If no generalization is needed then r = 0. For function mapping, where the input vectors are
equally distributed into the 0 and the 1 classes, then:
2
nr

25
About choice of h[3] consider a 2¡dimensional problem:
The function of the hidden node can be expressed by the separating line:

26
About choice of h[3] Assume that the input pattern being
classified is (0 1), then x2 = 1. Also,w1 = h, w2 = 1, and s = 1. The equation of the dividing line represented by the hidden node now becomes:

27
About choice of h…
-4 -3 -2 -1 0 1 2 3 4-4
-3
-2
-1
0
1
2
3
4
(h=-1 and r=0)

28
About choice of h…
-4 -3 -2 -1 0 1 2 3 4-4
-3
-2
-1
0
1
2
3
4
(h=-0.8 and r=0)

29
About choice of h…
(h=-1 and r=1)
-4 -3 -2 -1 0 1 2 3 4-5
-4
-3
-2
-1
0
1
2
3

30
CC4 [6] The CC4 network maps an input binary vector X to
an output vector Y. The input and output layers are fully connected. The neurons are all binary neurons with binary step
activation function as follows:
The number of hidden neurons is equal to the number of training samples with each hidden neuron representing one training sample.

31
CC4 Training[6] Let
be the weight of the connection from input neuron i to hidden neuron j and
let be the input for the i-th input neuron when the j-th training sample is presented to the network.
Then the weights are assigned as follows:
),...,1,..,1( HjNiwij
ijX

32
CC4 Training [6]… Let
be the weight of the connection from j-th hidden neuron to the k-th output neuron.
let be the output of the k-th output neuron for the j-th training sample.
The value of are determined by the following equation:
),...,1,..,1( MkHju jk
jkY
jku

33
Sample of CC4 Consider The 16 by 16 area of a spiral pattern that
contains 256 binary pixel (as black and white) as figure 2..
And we want to train a system with 1 exemplar sample as figure 2 that total 75 point are used for training.
Figure 1 Figure 2

34
Sample of CC4… We can code 16 integer
numbers with 4 binary bits.
Therefore for location (x,y), we will use 4 bits for x and 4 bits for y, and 1 extra bit (always equal to 1) for the bias.
Totally we have 9 inputs.
16
16

35
Sample of CC4…
(5,6)0
1
0
1
0
1
0
0
-1
1
-1
-1
-1
1
-1
-1
r-s+1=r-3+1=r-2
# corner
0 corner

36
Sample of CC4 result… Number of point
classified /misclassified in the spiral pattern.
Original spiral Training sample Output, r=1
Output, r=2 Output, r=3 Output, r=4

37
FC motivation
Disadvantages of CCs algorithm Input and output must be discrete Input is best presented in a unary code
increases the number of input neurons considerably
Degree of generalization for all nodes is the same

38
In reality this degree vary from node to node We need to work on real data
An interative version of the CC algorithm that does provide a varying degree of generalization has been devised .
Problem :It is not instantaneous
Problem

39
Fast classification network
What is FC? a generalization of the CC network This network can operate on real data
directly Learn instantaneously
It reduces to CC in a way that : data is binary amount of generalization is fixed

40
Input
•All xi and Y are real data•K is determined by problem nature
X=( x1, x2, …,xk ) , F(x) Y
What to do Define weight for input & output weightDefine radius of generalization

41
Input
Index Input Output
1 x1,x2,x3,x4
Y1,Y2
2 x1,x2,x3,x4
Y1,Y2
..

42
FC network structure
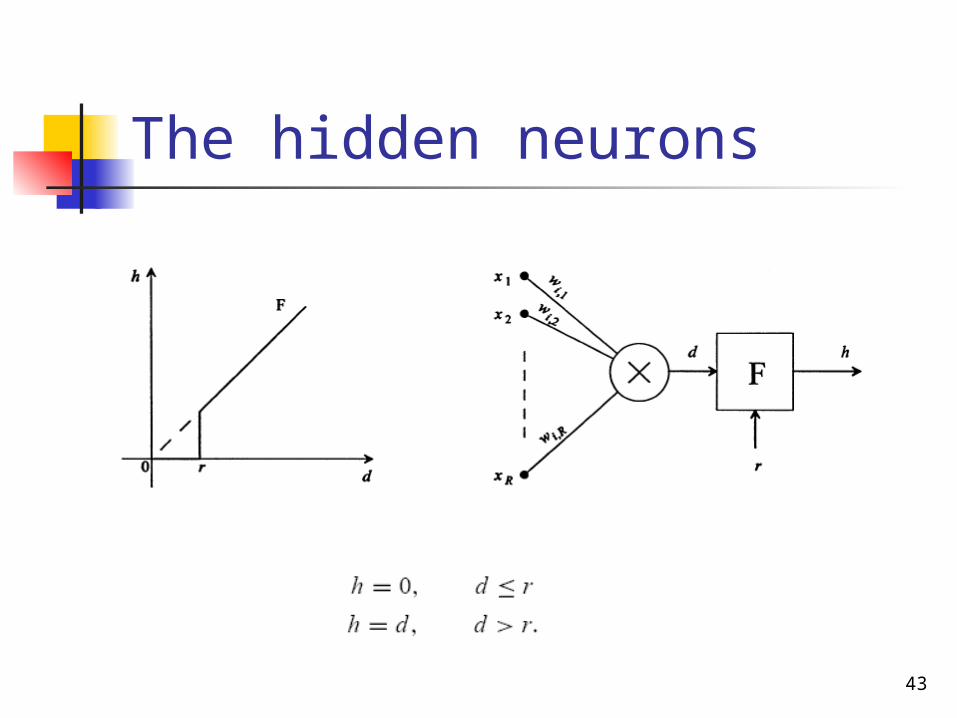
43
The hidden neurons

44
The rule base
M=the number of hi that equal to 0
• value of k is typically a small fraction of the size of the training set.
• Membership grades are normalized,
Rule 1: IF m = 1, THEN assign μi using single-nearest-neighbor (1NN)
Rule 2: IF m = 0, THEN assign μi using k-nearest-neighbor (kNN) heuristic.

45
1NN heuristic
when exactly one element in the distance vector h is 0

46
kNN heuristic
Based on k nearest neighbors.
Triangular membership

47
Training of the FC network
Training involves two separate step:
Step1:input and output weights are prescribed simply by inspection of the training input/output pairs
Step2:the radius of generalization for each hidden neuron is determined
ri=1/2dmin i

48
Radius of generalization
Soft generalization together with interpolationhard generalization with separated decision regions

49
Generalization by fuzzy membership
The output neuron then computes the dot product between the output weight vector and the membership grade vector

50
Other consideration Other membership function.
quadratic function known as S

51
Other consideration Other distance metric.
city block distance..
Result :
performance of the network is not seriously affected by the choice of distance metric and membership function

52
Hidden neuron
As in CC4: Number of training samples that
the network is required to learn.
Note: training sample are exemplar
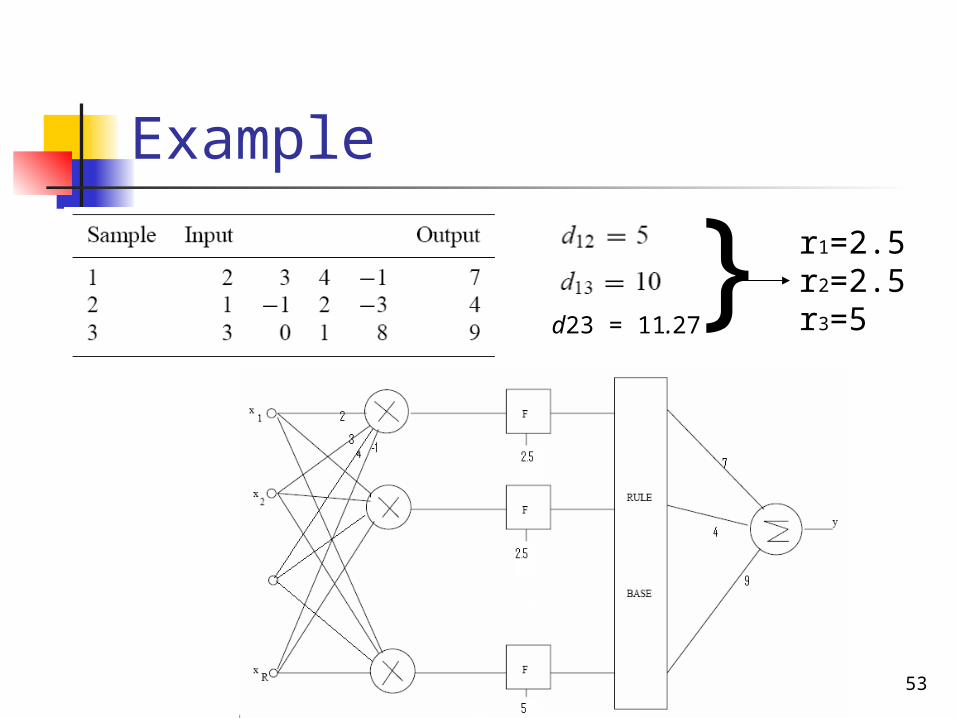
53
}Example
d23 = 11.27
r1=2.5r2=2.5r3=5

54
}
Example
d23 = 11.27
r1=2.5r2=2.5r3=5
Input :
Y=0.372*7 + 0.256*4 + 0.372*9 =6.976

55
Experimental result
Time-series prediction electric load demand Forecast Traffic volume forecast Prediction of stock prices, currency, and interest rates
describe the performance of the FC network using two benchmark
With different characteristic Henon map time series Mackey–Glass time series

56
Henon map
one-dimensional Henon map:
Generated point Training samples Testing samples Window size
544 500 out of 504 50 4
Input X Output Y
X(1), X(2), X(3), X(4) X(5)
X(2), X(3), X(4) ,X(5) X(6)

57
Henon map time-seriesprediction using FC (4-500-1), k = 5.

58
Result
Henon map time-series prediction using FC network
SSE : sum-of-squared error

59
Mackey-Glass time series
nonlinear time delay differential equation originally developed for modeling white blood cell production.
A, B, C : constants
D : the time delay parameter.
A B C D
0.2 0.1 10 30Popular case :

60
Henon map time-series prediction using FC (4-500-1), k = 5.

61
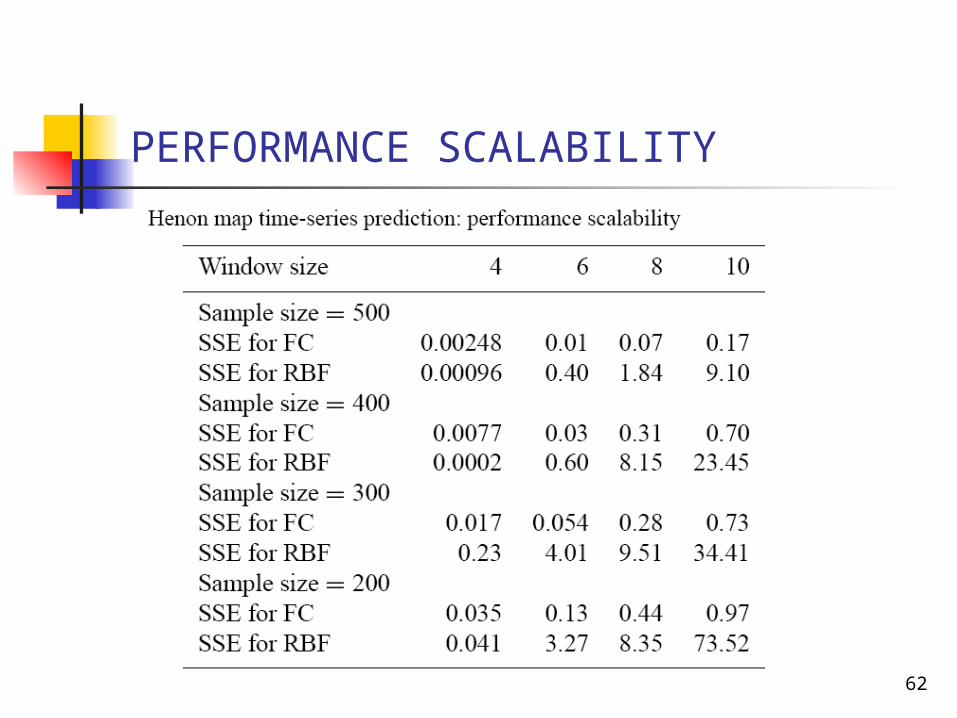
PERFORMANCE SCALABILITY
FC network and RBF network are optimized for a sample size of 500 and window size of 4.Parameter such as spread constant for RBF are set to the best value
Then
The window and the sample size are allowed to change without reoptimization
62
PERFORMANCE SCALABILITY

63
PERFORMANCE SCALABILITY

64
Result
performance of the FC network remains good and reasonably consistent throughout all window and sample sizes
RBF network is adversely affected by changes in the window size or sample size or both
Conclusion
The performance of the RBF network can become erratic for certain combinations of these parameters.
FC is generally applicable to other window sizes and sample sizes

65
Pattern recognition
pattern in a 32-by-32 area Input : row and column coordinates
of the training samples [1,32] Two output neurons, one for each
class White region : (1,0) black region : (0,1)

66
Result
Two-class spiral pattern classification
Output neuronInput neuron Training sample

67
Result
Output neuronInput neuron Training sample
Four-class spiral pattern classification

68
References[1] S.C. Kak, On training feedforward neural networks.
Pramana -J. of Physics, 40, 35-42 (1993).[2] G. Mirchandani and W. Cao, On hidden nodes for neural
nets. IEEE Trans. on Circuits and Systems 36, 661-664 (1989).
[3] S. Kak (1998), “On generalization by neural networks”, Information Sciences, vol. 111, pp. 293-302.
[4] S. Kak, Better web searches and prediction with instantaneously trained neural networks, IEEE Intelligent Systems, vol. 14(6), pp. 78–81, 1999.
[5] CHAPTER 7 , RESULTS AND DISCUSSION[6] Bo Shu, Subhash Kak, A neural network-based intelligent
metasearch engine ,Information Sciences, 120 (1999)1-11

69
References [7] S. Kak (2002), “A class of instantaneously trained
neural networks”, Information Sciences, vol. 148, pp. 97-102.
[8] K.W. Tang and S. Kak (2002), “Fast Classification Networks for Signal Processing”, Circuits Systems Signal Processing, vol. 21, pp. 207-224.
[9] S. Kak, “Three languages of the brain: Quantum, reorganizational, and associative, “ In Learning as Self-Organization, K. Pribram and J. King, eds., Lawrence Erlbaum, Mahwah, N.J., 1996, pp. 185--219.

















