61
Inform ation and C om munications U niversity Korean Intellectual Property Office – ICU seminar Speech-based Information Retrieval Gary Geunbae Lee POSTECH Oct 15 2007, ICU
| Date post: | 28-Dec-2015 |
| Category: |
Documents |
| Upload: | lucinda-sims |
| View: | 216 times |
| Download: | 1 times |

Information and Communications University
Korean Intellectual Property Office – ICU seminar
Speech-based Information Retrieval
Gary Geunbae Lee
POSTECH
Oct 15 2007, ICU

2 / 50Information and Communications University
contents Why speech-based IR?
Speech recognition technology
Spoken document retrieval
Ubiquitous IR using spoken dialog

3 / 50Information and Communications University
Why speech IR? – SDR (backend multimedia material)[ch-icassp07]
In the past decade there has been a dramatic increase in the availability of on-line audio-visual material… More than 50% percent of IP traffic is video
…and this trend will only continue as cost of producing audio-visual content continues to drop
Raw audio-visual material is difficult to search and browse Keyword driven Spoken Document Retrieval (SDR):
User provides a set of relevant query terms Search engine needs to return relevant spoken documents and provide an easy
way to navigate them
3
Broadcast News Podcasts Academic Lectures
4 / 50Information and Communications University
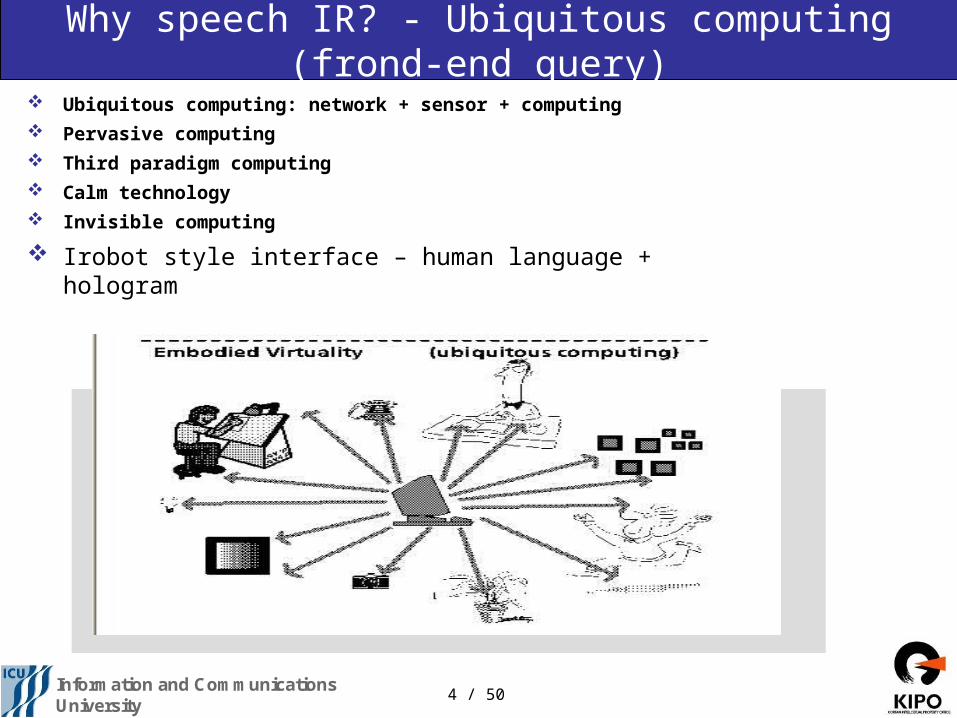
Why speech IR? - Ubiquitous computing (frond-end query)
Ubiquitous computing: network + sensor + computing
Pervasive computing
Third paradigm computing
Calm technology
Invisible computing
Irobot style interface – human language + hologram

5 / 50Information and Communications University
Ubiquitous computer interface? Computer – robot, home appliances, audio, telephone, fax machine,
toaster, coffee machine, etc (every objects)
VoiceBox (USA)
Telematics Dialog Interface (POSTECH, LG, DiQuest)
EPG guide (POSTECH)
Dialog Translation (POSTECH)

6 / 50Information and Communications University
Tele-serviceTele-service
Car-navigationCar-navigation Home networkingHome networking
Robot interfaceRobot interface
Example Domain for Ubiquitous IR

7 / 50Information and Communications University
What’s hard – ambiguities, ambiguities, all different levels of ambiguities
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours. But it turned out to be too expensive there. [from J. Eisner]
- donut: To get a donut (doughnut; spare tire) for his car?
- Donut store: store where donuts shop? or is run by donuts? or looks like a big donut? or made of donut?
- From work: Well, actually, he stopped there from hunger and exhaustion, not just from work.
- Every few hours: That’s how often he thought it? Or that’s for coffee?
- it: the particular coffee that was good every few hours? the donut store? the situation
- Too expensive: too expensive for what? what are we supposed to conclude about what John did?

8 / 50Information and Communications University
contents Why speech-based IR?
Speech Recognition Technology
Spoken document retrieval
Ubiquitous IR using spoken dialog

9 / 50Information and Communications University
The Noisy Channel Model Automatic speech recognition (ASR) is a process by which an acousti
c speech signal is converted into a set of words [Rabiner et al., 1993]
The noisy channel model [Lee et al., 1996]
Acoustic input considered a noisy version of a source sentence
Sourcesentence
Noisysentence
Guess atoriginal sentence
버스 정류장이어디에 있나요 ?
버스 정류장이어디에 있나요 ?
Noisy Channel Decoder

10 / 50Information and Communications University
The Noisy Channel Model What is the most likely sentence out of all sentences in the languag
e L given some acoustic input O?
Treat acoustic input O as sequence of individual observations O = o1,o2,o3,…,ot
Define a sentence as a sequence of words: W = w1,w2,w3,…,wn
)|(maxargˆ OWPWLW
)()|(maxargˆ WPWOPWLW
)(
)()|(maxargˆ
OP
WPWOPW
LW
Bayes rule
Golden rule
11 / 50Information and Communications University
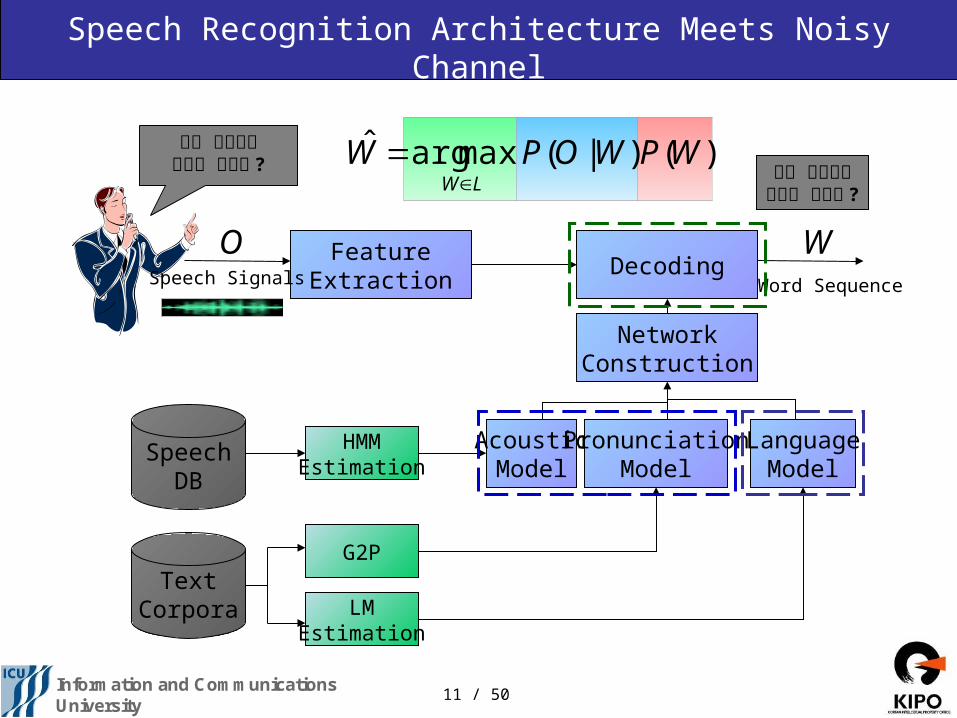
Speech Recognition Architecture Meets Noisy Channel
FeatureExtraction
Decoding
AcousticModel
PronunciationModel
LanguageModel
버스 정류장이어디에 있나요 ?
Speech Signals Word Sequence
버스 정류장이어디에 있나요 ?
NetworkConstruction
SpeechDB
TextCorpora
HMMEstimation
G2P
LMEstimation
)()|(maxargˆ WPWOPWLW
WO

12 / 50Information and Communications University
Feature Extraction The Mel-Frequency Cepstrum Coefficients (MFCC) is a popular choice [Paliw
al, 1992]
Frame size : 25ms / Frame rate : 10ms
39 feature per 10ms frame Absolute : Log Frame Energy (1) and MFCCs (12) Delta : First-order derivatives of the 13 absolute coefficients Delta-Delta : Second-order derivatives of the 13 absolute coefficients
Preemphasis/HammingWindow
FFT(Fast Fourier Transform)
Mel-scalefilter bank
log|.|DCT
(Discrete Cosine Transform)
MFCC(12-Dimension)
X(n)
25 ms
10ms . . .
a1 a2 a3
13 / 50Information and Communications University
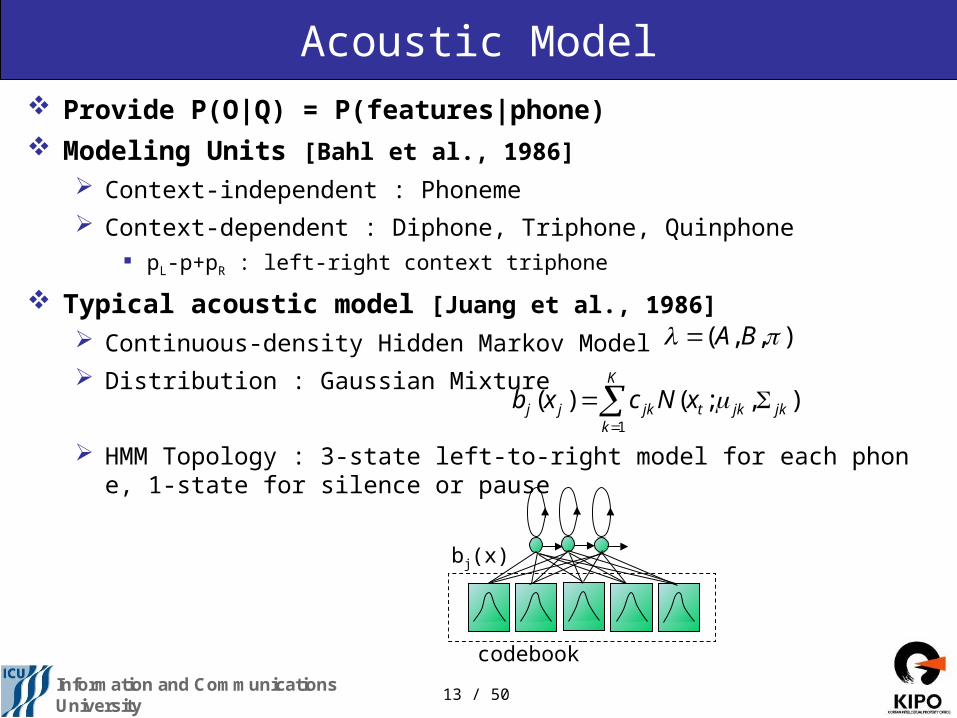
Acoustic Model Provide P(O|Q) = P(features|phone) Modeling Units [Bahl et al., 1986]
Context-independent : Phoneme
Context-dependent : Diphone, Triphone, Quinphone pL-p+pR : left-right context triphone
Typical acoustic model [Juang et al., 1986]
Continuous-density Hidden Markov Model
Distribution : Gaussian Mixture
HMM Topology : 3-state left-to-right model for each phone, 1-state for silence or pause
),,( BA
K
kjkjktjkjj xNcxb
1
),;()(
codebook
bj(x)

14 / 50Information and Communications University
Pronunciation Model
Provide P(Q|W) = P(phone|word) Word Lexicon [Hazen et al., 2002]
Map legal phone sequences into words according to phonotactic rules
G2P (Grapheme to phoneme) : Generate a word lexicon automatically
Several word may have multiple pronunciations
Example
Tomato P([towmeytow]|tomato) = P([towmaatow]|tomato) = 0.1
P([tahmeytow]|tomato) = P([tahmaatow]|tomato) = 0.4
[t]
[ow]
[ah]
[m]
[ey]
[aa]
[t] [ow]
0.2
0.8 1.0
1.0 0.5
0.5 1.0
1.01.0

15 / 50Information and Communications University
Training Training process [Lee et al., 1996]
Network for training
ONE TWO ONETHREEONE TWO THREE ONESentence HMM
W AH N
1 2 3
ONEWord HMM
Phone HMM W
FeatureExtraction
Baum-WelchRe-estimation
Converged? EndSpeech DB
HMM
yes
no

16 / 50Information and Communications University
Language Model Provide P(W) ; the probability of the sentence [Beaujard et al., 1999]
We saw this was also used in the decoding process as the probability of transitioning from one word to another.
Word sequence : W = w1,w2,w3,…,wn
The problem is that we cannot reliably estimate the conditional word probabilities, for all words and all sequence lengths in a given language
n-gram Language Model n-gram language models use the previous n-1 words to represent the history
Bi-grams are easily incorporated in a viterbi search
n
iiin wwwPwwP
111 )|()1(
)|( 11 ii wwwP
)|()|( 1)1(11 iniiii wwwPwwwP
17 / 50Information and Communications University
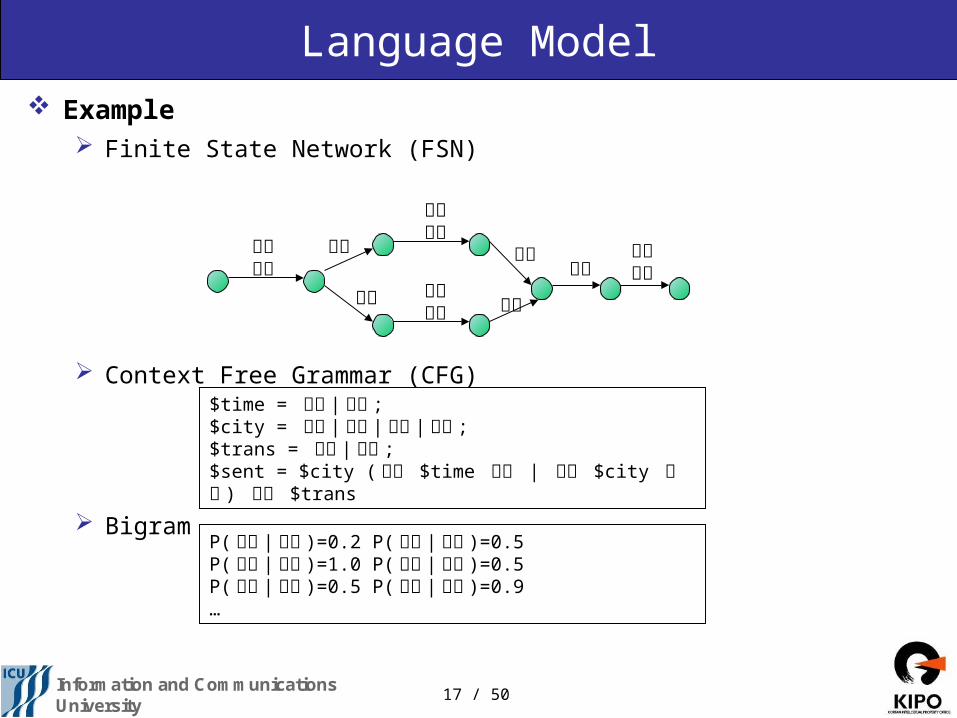
Language Model Example
Finite State Network (FSN)
Context Free Grammar (CFG)
Bigram
서울부산
에서
출발
세시네시
대구대전 도착
출발하는
기차버스
P(에서 |서울 )=0.2 P(세시 |에서 )=0.5P(출발 |세시 )=1.0 P(하는 |출발 )=0.5P(출발 |서울 )=0.5 P(도착 |대구 )=0.9…
$time = 세시 | 네시 ;$city = 서울 | 부산 | 대구 | 대전 ;$trans = 기차 | 버스 ;$sent = $city ( 에서 $time 출발 | 출발 $city 도착 ) 하는 $trans

18 / 50Information and Communications University
Network Construction
I
L
S
A
M
일
이
삼
사
I L
I
S A M
S A 삼
사
일
이
Acoustic Model Pronunciation Model Language Model
I
I L
S A M
Wordtransition
P(일 |x)
P(사 |x)
P(삼 |x)
P(이 |x)LM is applied
S A
startend이
일
사
삼
Between-wordtransition
Intra-wordtransition
Search Network
Expanding every word to state level, we get a search network [Demuynck et al., 1997]

19 / 50Information and Communications University
Decoding Find
Viterbi Search : Dynamic Programming Token Passing Algorithm [Young et al., 1989]
)|(maxargˆ OWPWLW
Initialize all states with a token with a null history and the likelihood that it’s a start state
For each frame ak
For each token t in state s with probability P(t), history H
For each state r
Add new token to s with probability P(t) Ps,r Pr(ak), and history s.H

20 / 50Information and Communications University
Decoding Pruning [Young et al., 1996]
Entire search space for Viterbi search is much too large
Solution is to prune tokens for paths whose score is too low
Typical method is to use: histogram: only keep at most n total hypotheses
beam: only keep hypotheses whose score is a fraction of best score
N-best Hypotheses and Word Graphs Keep multiple tokens and return n-best paths/scores
Can produce a packed word graph (lattice)
Multiple Pass Decoding Perform multiple passes, applying successively more fine-grained language
models

21 / 50Information and Communications University
Large Vocabulary Continuous Speech Recognition (LVCSR)
Decoding continuous speech over large vocabulary Computationally complex because of huge potential search space Weighted Finite State Transducers (WFST) [Mohri et al., 2002]
Dynamic Decoding On-demand network constructions
Much less memory requirements
WFST
WFST
WFST
WFST
Combination Optimization
Word : Sentence
Phone : Word
HMM : Phone
State : HMM
SearchNetwork

22 / 50Information and Communications University
Out-of-Vocabulary Word Modeling[ch-icassp07]
How can out-of-vocabulary (OOV) words be handled
Start with standard lexical network
Separate sub-word network is created to model OOVs
Add sub-word network to word network as new word, Woov
OOV model used to detect OOV words and provide phonetic transcription (Bazzi & Glass, 2000)

23 / 50Information and Communications University
Mixture Language Models[ch-icassp07]
When building a topic-specific language model: Topic-specific material may be limited and sparse
Best results when combining with robust general model
May desire a model based on a combination of topics …and with some topics weighted more heavily than others
Topic mixtures is one approach (Iyer & Ostendorf, 1996) SRI Language Modeling Toolkit provides an open source implementation (http://
www.speech.sri.com/projects/srilm)
A basic topic mixture-language model is defined as a weighted combination of N different topics T1 to TN :

24 / 50Information and Communications University
Automatic Alignment of Human Transcripts[ch-icassp07]
Goal: Align transcript w/o time markers to long audio file
Run recognizer over utterances to obtain word hypotheses Use language model strongly adapted to reference transcript
Align reference transcript against word hypotheses Identify matched words ( ) and mismatched words (X)
Treat multi-word matched sequences as anchor regions
Extract new segments starting and ending within anchors
Force align reference words within each new segment si

25 / 50Information and Communications University
contents Why speech-based IR?
Speech Recognition Technology
Spoken document retrieval
Ubiquitous IR using spoken dialog

26 / 50Information and Communications University
Spoken Document Processing[ch-icassp07]
The goal is to enable users to: Search for spoken documents as easily as they search for text
Accurately retrieve relevant spoken documents
Efficiently browse through returned hits
Quickly find segments of spoken documents they would most like to listen to or watch
Information (or meta-data) to enable search and retrieval: Transcription of speech
Text summary of audio-visual material
Other relevant information: speakers, time-aligned outline, etc.
slides, other relevant text meta-data: title, author, etc.
links pointing to spoken document from the www
collaborative filtering (who else watched it?)

27 / 50Information and Communications University
Transcription of Spoken Documents[ch-icassp07]
Manual transcription of audio material is expensive A basic text-transcription of a one hour lecture costs >$100
Human generated transcripts can contain many errors
MIT study on commercial transcripts of academic lectures Transcripts show a 10% difference against true transcripts
Many differences are actually corrections of speaker errors
However, ~2.5% word substitution rate is observed:
Misspelled wordsFurui Frewey
Makhoul McCoolTukey TukiEigen igan
Gaussian galsiancepstrum capstrum
Substitution errorsFourier for your
Kullback callbacka priori old prairieresonant resident
affricates aggregatespalatal powerful

28 / 50Information and Communications University
Rich Annotation of Spoken Documents[ch-icassp07]
Humans take 10 to 50 times real time to perform rich transcription of audio data including: Full transcripts with proper punctuation and capitalization
Speaker identities, speaker changes, speaker overlaps
Spontaneous speech effects (false starts, partial words, etc.)
Non-speech events and background noise conditions
Topic segmentation and content summarization
Goal: Automatically generate rich annotations of audio Transcription (What words were spoken?)
Speaker diarization (Who spoke and when?)
Segmentation (When did topic changes occur?)
Summarization (What are the primary topics?)
Indexing (Where were specific words spoken?)
Searching (How can the data be searched efficiently?)

29 / 50Information and Communications University
Text Retrieval[ch-icassp07]
Collection of documents:
“large” N: 10k-1M documents or more (videos, lectures)
“small” N: < 1-10k documents (voice-mails, VoIP chats)
Query:
ordered set of words in a large vocabulary
restrict ourselves to keyword search; other query types are clearly possible: Speech/audio queries (match waveforms)
Collaborative filtering (people who watched X also watched…)
Ontology (hierarchical clustering of documents, supervised or unsupervised)

30 / 50Information and Communications University
Text Retrieval: Vector Space Model[ch-icassp07]
Build a term-document co-occurrence (LARGE) matrix (Baeza-Yates, 99) rows indexed by word
columns indexed by documents
TF (term frequency): frequency of word in document could be normalized to maximum frequency in a given document
IDF (inverse document frequency): if a word appears in all documents equally likely, it isn’t very useful for ranking (Bellegarda, 2000) uses normalized entropy

31 / 50Information and Communications University
Text Retrieval: Vector Space Model (2) [ch-icassp07]
For retrieval/ranking one ranks the documents in decreasing order of relevance score:
query weights have minimal impact since queries are very short, so one often uses a simplified relevance score:

32 / 50Information and Communications University
Text Retrieval: TF-IDF Shortcomings[ch-icassp07]
Hit-or-Miss: returns only documents containing the query words
query for Coca Cola will not return a document that reads: “… its Coke brand is the most treasured asset of the soft drinks maker …”
Cannot do phrase search: “Coca Cola” needs post processing to filter out documents not matching the phrase
Ignores word order and proximity query for Object Oriented Programming:
“ … the object oriented paradigm makes programming a joy … “
“ … TV network programming transforms the viewer in an object and it is oriented towards…”

33 / 50Information and Communications University
Vector Space Model: Query/Document Expansion[ch-icassp07]
Correct the Hit-or-Miss problem by doing some form of expansion on the query and/or document side add similar terms to the ones in the query/document to increase number of terms
matched on both sides
corpus driven methods: TREC-7 (Singhal et al,. 99) and TREC-8 (Singhal et al,. 00)
Query side expansion works well for long queries (10 words) short queries are very ambiguous and expansion may not work well
Expansion works well for boosting Recall: very important when working on small to medium sized corpora
typically comes at a loss in Precision

34 / 50Information and Communications University
Vector Space Model: Latent Semantic Indexing[ch-icassp07]
Correct the Hit-or-Miss problem by doing some form of dimensionality reduction on the TF-IDF matrix Singular Value Decomposition (SVD) (Furnas et al., 1988)
Probabilistic Latent Semantic Analysis (PLSA) (Hoffman, 1999)
Non-negative Matrix Factorization (NMF)
Matching of query vector and document vector is performed in the lower dimensional space
Good as long as the magic works
Drawbacks: still ignores WORD ORDER
users are no longer in full control over the search engine Humans are very good at crafting queries that’ll get them the documents they want and expansion methods impair full use of their natural language faculty
35 / 50Information and Communications University
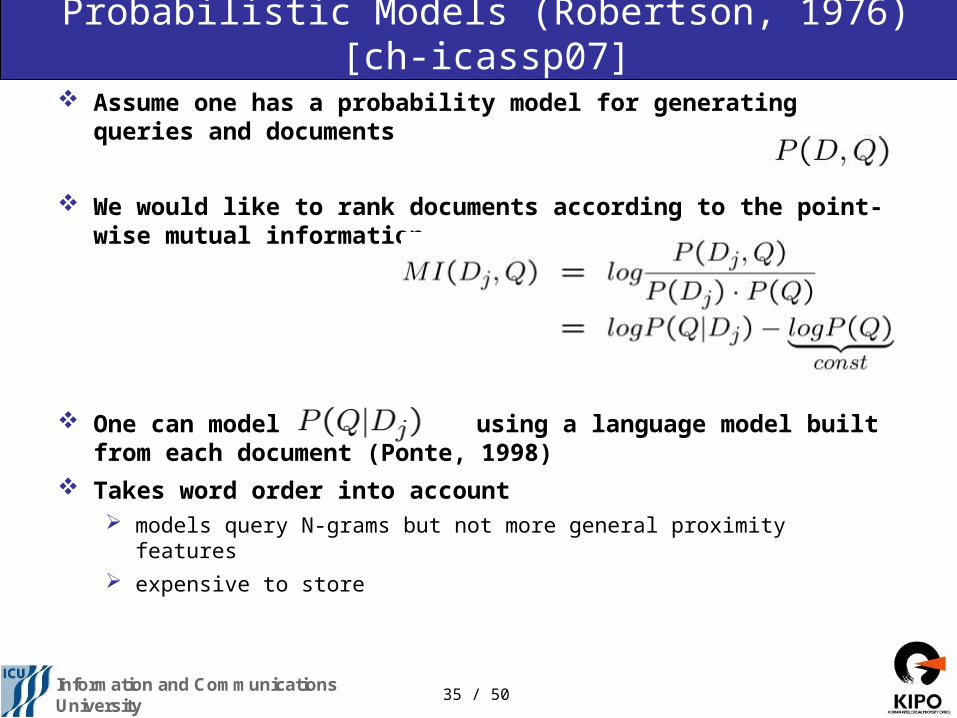
Probabilistic Models (Robertson, 1976) [ch-icassp07]
Assume one has a probability model for generating queries and documents
We would like to rank documents according to the point-wise mutual information
One can model using a language model built from each document (Ponte, 1998)
Takes word order into account models query N-grams but not more general proximity features
expensive to store

36 / 50Information and Communications University
Text Retrieval: Scaling Up[ch-icassp07]
Linear scan of document collection is not an option for compiling the ranked list of relevant documents Compiling a short list of relevant documents may allow for relevance score
calculation on the document side
Inverted index is critical for scaling up to large collections of documents think index at end of a book as opposed to leafing through it!
All methods are amenable to some form of indexing:
TF-IDF/SVD: compact index, drawbacks mentioned
LM-IR: storing all N-grams in each document is very expensive significantly more storage than the original document collection
Early Google: compact index that maintains word order information and hit context relevance calculation, phrase based matching using only the index

37 / 50Information and Communications University
TREC SDR: “A Success Story” [ch-icassp07]
The Text Retrieval Conference (TREC) pioneering work in spoken document retrieval (SDR)
SDR evaluations from 1997-2000 (TREC-6 toTREC-9)
TREC-8 evaluation: focused on broadcast news data
22,000 stories from 500 hours of audio
even fairly high ASR error rates produced document retrieval performance close to human generated transcripts
key contributions: Recognizer expansion using N-best lists
query expansion, and document expansion
conclusion: SDR is “A success story” (Garofolo et al, 2000)
Why don’t ASR errors hurt performance? content words are often repeated providing redundancy
semantically related words can offer support (Allan, 2003)

38 / 50Information and Communications University
Broadcast News: SDR Best-case Scenario[ch-icassp07]
Broadcast news SDR is a best-case scenario for ASR: primarily prepared speech read by professional speakers
spontaneous speech artifacts are largely absent
language usage is similar to written materials
new vocabulary can be learned from daily text news articles
state-of-the-art recognizers have word error rates <10% comparable to the closed captioning WER (used as reference)
TREC queries were fairly long (10 words) and have low out-of-vocabulary (OOV) rate
impact of query OOV rate on retrieval performance is high (Woodland et al., 2000)
Vast amount of content is closed captioned

39 / 50Information and Communications University
Beyond Broadcast News[ch-icassp07]
Many useful tasks are more difficult than broadcast news Meeting annotation (e.g., Waibel et al, 2001)
Voice mail (e.g., SCANMail, Bacchiani et al, 2001))
Podcasts (e.g., Podzinger, www.podzinger.com)
Academic lectures
Primary difficulties due to limitations of ASR technology: highly spontaneous, unprepared speech
topic-specific or person-specific vocabulary & language usage
unknown content and topics potentially lacking support in general language model
wide variety of accents and speaking styles
OOVs in queries: ASR vocabulary is not designed to recognize infrequent query terms, which are most useful for retrieval
General SDR still has many challenges to solve

40 / 50Information and Communications University
Spoken Term Detection Task[ch-icassp07]
A new Spoken Term Detection evaluation initiative from NIST Find all occurrences of a search term as fast as possible in heterogeneous audio
sources
Objective of the evaluation Understand speed/accuracy tradeoffs Understand technology solution tradeoffs: e.g., word vs. phone recognition Understand technology issues for the three STD languages: Arabic, English, and
Mandarin
TREC STD
Documents Broadcast News BN, Switchboard, Meeting
Languages English English, Arabic, Mandarin
Query Long Short (few words)
System Output
Ranked Relevant documents
Location of the query in the audioDecision Score indicating how likely the term exists“Actual” decision as to whether the detected term is a hit

41 / 50Information and Communications University
Text Retrieval: Evaluation[ch-icassp07]
trec_eval (NIST) package requires reference annotations for documents with binary relevance judgments for each query Standard Precision/Recall and Precision@N documents
Mean Average Precision (MAP)
R-precision (R=number of relevant documents for the query)
Ranking on reference side is flat (ignored)

42 / 50Information and Communications University
contents Why speech-based IR?
Speech Recognition Technology
Spoken document retrieval
Ubiquitous IR using spoken dialog

43 / 50Information and Communications University
Dialog System A system to provide interface between the user and a computer-bas
ed application [Cole, 1997; McTear, 2004]
Interaction on turn-by-turn basis Dialog manager
Control the flow of the dialog Main flow
information gathering from user communicating with external application communicating information back to the user
Three types of dialog system frame-based agent-based finite state- (or graph-) based (~ VoiceXML-based)
44 / 50Information and Communications University
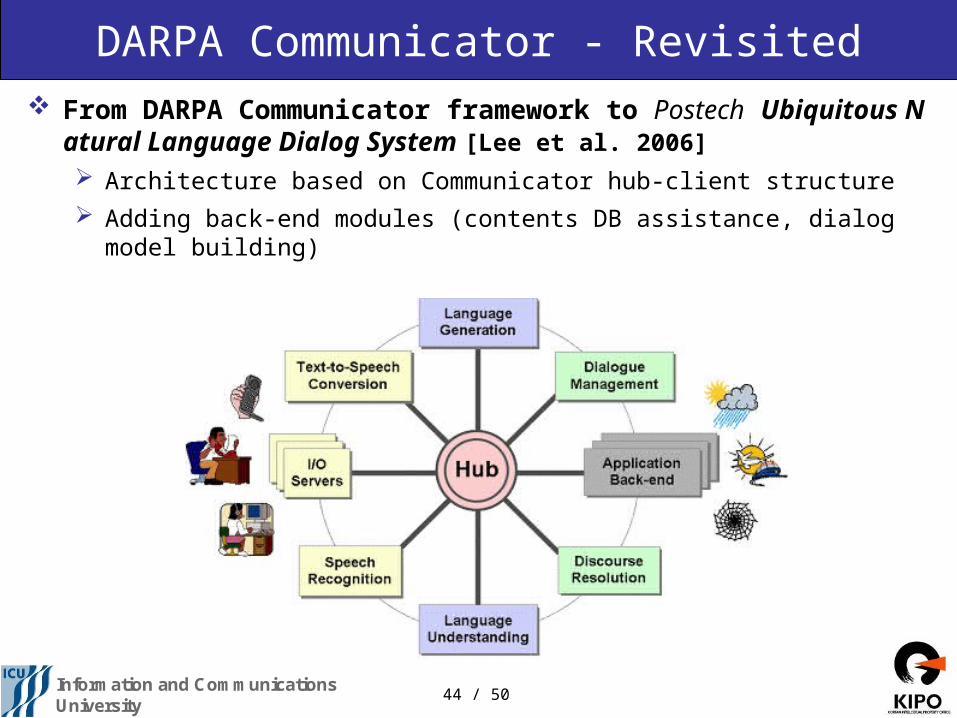
DARPA Communicator - Revisited From DARPA Communicator framework to Postech Ubiquitous Natu
ral Language Dialog System [Lee et al. 2006]
Architecture based on Communicator hub-client structure
Adding back-end modules (contents DB assistance, dialog model building)

45 / 50Information and Communications University
Spoken Language Understanding Spoken language understanding is to map natural language speech
to frame structure encoding of its meanings. [Wang et al., 2005]
What’s difference between NLU and SLU? Robustness; noise and ungrammatical spoken language
Domain-dependent; further deep-level semantics (e.g. Person vs. Cast)
Dialog; dialog history dependent and utt. by utt. analysis
Traditional approaches; natural language to SQL conversion
ASRSpeech
SLUSQL
GenerateDatabase
TextSemantic
FrameSQL Response
A typical ATIS system (from [Wang et al., 2005])

46 / 50Information and Communications University
Semantic Representation Semantic frame (frame and slot/value structure) [Gildeaand Jurafsky, 200
2]
An intermediate semantic representation to serve as the interface between user and dialog system
Each frame contains several typed components called slots. The type of a slot specifies what kind of fillers it is expecting.
“Show me flights from Seattle to Boston”
ShowFlight
Subject Flight
FLIGHT Departure_City Arrival_City
SEA BOS
<frame name=‘ShowFlight’ type=‘void’> <slot type=‘Subject’> FLIGHT</slot> <slot type=‘Flight’/> <slot type=‘DCity’>SEA</slot> <slot type=‘ACity’>BOS</slot> </slot></frame>
Semantic representation on ATIS task; XML format (left) and hierarchical representation (right) [Wang et al., 2005]

47 / 50Information and Communications University
Semantic Frame Extraction
Dialog ActIdentification
Dialog ActIdentification
Frame-SlotExtractionFrame-SlotExtraction
RelationExtractionRelation
Extraction
UnificationUnification
Feature Extraction / SelectionFeature Extraction / Selection
Info.SourceInfo.
Source
++
++
++
++ ++
Overall architecture for semantic analyzer
롯데월드에 어떻게 가나요 ?
Domain: Navigation
Dialog Act: WH-question
Main Action: Search
Object.Location.Destination= 롯데월드
난 롯데월드가 너무 좋아 .
Domain: Chat
Dialog Act: Statement
Main Action: Like
Object.Location= 롯데월드
Examples of semantic frame structure
Semantic Frame Extraction (~ Information Extraction Approach)
1) Dialog act / Main action Identification ~ Classification
2) Frame-Slot Object Extraction ~ Named Entity Recognition
3) Object-Attribute Attachment ~ Relation Extraction
1) + 2) + 3) ~ Unification

48 / 50Information and Communications University
The Role of Dialog Management For example, in the flight reservation system
System : Welcome to the Flight Information Service. Where would you like to travel to?
Caller : I would like to fly to London on Friday arriving around 9 in the morning.
System :
????????????????????
In order to process this utterance, the system has to engage in the following
processes:
1) Recognize the words that the caller said. (Speech Recognition)
2) Assign a meaning to these words. (Language Understanding)
3) Determine how the utterance fits into the dialog so far and decide what to
do next. (Dialog Management)
There is a flight that departs at 7:45 a.m. and arrives at 8:50 a.m.

49 / 50Information and Communications University
Overall Architecture [on-going research]
Generic SLU
Agent / Domain Spotter
KeywordFeature Extractor
Linguistic Analysis
Dialog Management
Chat Agent
Discourse History
Task Agent
Dialog Example Database
Domain Knowledge Database
Domain-Specific SLU
Domain-SpecificDialog Expert
Domain-SpecificChat Expert
Domain-Specific SLU
Discourse History
ChatDialog Example
Database
Speech Recognizer
System Utterance
System Utterance
Text-To-Speech

50 / 50Information and Communications University
References - Recognition L. Bahl, P. F. Brown, P. V. de Souza, and R .L. Mercer, 1986. Maximum mutual informa
tion estimation of hidden Markov model ICASSP, pp.49–52.
C. Beaujard and M. Jardino, 1999. Language Modeling based on Automatic Word Concatenations, In Proceedings of 8th European Conference on Speech Communication and Technology, vol. 4, pp.1563-1566.
K. Demuynck, J. Duchateau, and D. V. Compernolle, 1997. A static lexicon network representation for cross-word context dependent phones, Proceedings of the 5th European Conference on Speech Communication and Technology, pp.143–146.
T. J. Hazen, I. L. Hetherington, H. Shu, and K. Livescu, 2002. Pronunciation modeling using a finite-state transducer representation, Proceedings of the ISCA Workshop on Pronunciation Modeling and Lexicon Adaptation, pp.99–104.
M. Mohri, F. Pereira, and M Riley, 2002. Weighted finite-state transducers in speech recognition, Computer Speech and Language, vol.16, no.1, pp.69–88.

51 / 50Information and Communications University
References -recognition B. H. Juang, S. E. Levinson, and M. M. Sondhi, 1986. Maximum likelihood estimation f
or multivariate mixture observations of Markov chains, IEEE Transactions on Information Theory, vol.32, no.2, pp.307–309.
C. H. Lee, F. K. Soong, and K. K. Paliwal, 1996. Automatic Speech and Speaker Recognition: Advanced Topics, Kluwer Academic Publishers.
K. K. Paliwal, 1992. Dimensionality reduction of the enhanced feature set for the HMMbased speech recognizer, Digital Signal Processing, vol.2, pp.157–173.
L. R. Rabiner, 1989, A tutorial on hidden Markov models and selected applications in speech recognition, Proceedings of the IEEE, vol.77, no.2, pp.257–286.
L. R. Rabiner and B. H. Juang, 1993. Fundamentals of Speech Recognition, Prentice-Hall.
S. J. Young, N. H. Russell, and J. H. S Thornton, 1989. Token passing: a simple conceptual model for connected speech recognition systems. Technical Report CUED/F-INFENG/TR.38, Cambridge University Engineering Department.
S. Young, J. Jansen, J. Odell, D. Ollason, and P. Woodland, 1996. The HTK book. Entropics Cambridge Research Lab., Cambridge, UK.

52 / 50Information and Communications University
References – understanding & dialog J. Dowding, J. M. Gawron, D. Appelt, J. Bear, L. Cherny, R. Moore, D. and M
oran. 1993. Gemini: A natural language system for spoken language understanding. ACL, 54-61.
J. Eun, C. Lee, and G. G. Lee, 2004. An information extraction approach for spoken language understanding. ICSLP.
J. Eun, M. Jeong, and G. G. Lee, 2005. A Multiple Classifier-based Concept-Spotting Approach for Robust Spoken Language Understanding. Interspeech 2005-Eurospeech.
D. Gildea, and D. Jurafsky. 2002. Automatic labeling of semantic roles. Computational Linguistics, 28(3):245-288.
Y. He, and S. Young. January 2005. Semantic processing using the Hidden Vector State model. Computer Speech and Language, 19(1):85-106.
M. Jeong, and G. G. Lee. 2006. Exploiting non-local features for spoken language understanding. COLING/ACL.
J. Lafferty, A. McCallum, and F. Pereira. 2001. Conditional Random Fields: Probabilistic models for segmenting and labeling sequence data. ICML.

53 / 50Information and Communications University
References – understanding and dialog E. Levin, and R. Pieraccini. 1995. CHRONUS, the next generation, In Procee
dings of 1995 ARPA Spoken Language Systems Technical Workshop, 269--271, Austin, Texas.
B. Pellom, W. Ward., and S. Pradhan. 2000. The CU Communicator: An Architecture for Dialogue Systems. ICSLP.
R. E. Schapire., M. Rochery, M. Rahim, and N. Gupta. 2002, Incorporating prior knowledge into boosting. ICML. pp538-545.
S. Seneff. 1992. TINA: a natural language system for spoken language applications, Computational Linguistics, 18(1):61--86.
G. Tur, D. Hakkani-Tur, and R. E. Schapire. 2005. Combining active and semi-supervised learning for spoken language understanding. Speech Communication. 45:171-186
Y. Wang, L. Deng, and A. Acero. September 2005, Spoken Language Understanding: An introduction to the statistical framework. IEEE Signal Processing Magazine, 27(5)

54 / 50Information and Communications University
References – understanding and dialog J. F. Allen, B. Miller, E. Ringger and T. Sikorski. 1996. A Robust System for
Natural Spoken Dialogue, ACL. S. Bayer, C. Doran, and B. George. 2001. Dialogue Interaction with the DAR
PA Communicator Infrastructure: The Development of Useful Software. HLT Research.
R. Cole, editor., Survey of the state of the art in human language technology, Cambridge University Press, New York, NY, USA, 1997.
G. Ferguson, and J. F. Allen. 1998. TRIPS: An Integrated Intelligent Problem-Solving Assistant, AAAI, pp26-30.
K. Komatani, F. Adachi, S. Ueno, T. Kawahara, and H. Okuno. 2003. Flexible Spoken Dialogue System based on User Models and Dynamic Generation of VoiceXML Scripts. SIGDIAL.
S. Larsson, and D. Traum. 2000. Information state and dialogue management in the TRINDI Dialogue Move Engine Toolkit, Natural Language Engineering, 6(3-4).
S. Lang, M. Kleinehagenbrock, S. Hohenner, J. Fritsch, G. A. Fink, and G. Sagerer. 2003. Providing the basis for human-robotinteraction: A multi-modal attention system for a mobile robot. ICMI. pp. 28–35.

55 / 50Information and Communications University
References – understanding and dialog E. Levin, R. Pieraccini, and W. Eckert. 2000, A stochastic model of human-m
achine interaction for learning dialog strategies. IEEE Transactions on Speech and Audio Processing. 8(1):11-23
C. Lee, S. Jung, J. Eun, M. Jeong, and G. G. Lee. 2006. A Situation-based Dialogue Management using Dialogue Examples. ICASSP.
W. Marilyn, H. Lynette, and A. John. 2000. Evaluation for Darpa Communicator Spoken Dialogue Systems. LREC.
M. F. McTear, Spoken Dialogue Technology, Springer, 2004. I. O’Neil, P. Hanna, X. Liu, D. Greer, and M. McTear. 2005. Implementing adv
anced spoken dialog management in Java. Speech Communication, 54(1):99-124.
B. Pellom, W. Ward., and S. Pradhan. 2000. The CU Communicator: An Architecture for Dialogue Systems. ICSLP.
A. Rudnicky, E. Thayer, P. Constantinides, C. Tchou, R. Shern, K. Lenzo, W. Xu, and A. Oh. 1999. Creating natural dialogs in the Carnegie Mellon Communicator system. Eurospeech, 4, pp1531-1534.
W3C, Voice Extensible Markup Language (VoiceXML) Version 2.0 Working Draft, http://www.w3c.org/TR/voicexml20/

56 / 50Information and Communications University
References – spoken document retrieval
J. Allan, “Robust techniques for organizing and retrieving spoken documents”, EURASIP Journal on Applied Signal Processing, no. 2, pp. 103-114, 2003.
C. Allauzen, M. Mohri, and B. Roark, “A general weighted grammar library”, in Proc. of International Conf. on the Implementation and Application of Automata, Kingston, Canada, July 2004.
C. Allauzen,et al, “General Indexation of Weighted Automata – Application to Spoken Utterance Retrival,” Proc. of HLT-NAACL Workshop on Interdisciplinary Approaches to Speech Indexing and Retrieval, pp. 33-40, Boston, Massachusetts, USA, 2004.
M. Bacchiani, et al, “SCANMail: audio navigation in the voicemail domain,” in Proc. of the HLT Conf., pp. 1-3, San Diego, 2000.
R. Baeza-Yates and B. Ribeiro-Neto, Modern Information Retrieval, chapter 2, pages 27-30. Addison Wesley, New York, 1999.
I. Bazzi and J. Glass. “Modeling out-of-vocabulary words for robust speech recognition”, in Proc. of ICSLP, Beijing, China, October, 2000.
I. Bazzi and J. Glass. “Learning units for domain independent out-ofvocabulary word modeling”, in Proc. of Eurospeech, Aalborg, Sep. 2001.

57 / 50Information and Communications University
References – spoken document retrieval
S. Brin and L. Page, “The anatomy of a large-scale hypertextual Web search engine”, Computer Networks and ISDN Systems, Vol. 30, pp. 107-117, 1998.
C. Chelba and A. Acero, “Position specific posterior lattices for indexing speech”, In Proc. of the Annual Meeting of the ACL (ACL'05), pp. 443-450, Ann Arbor, Michigan, June 2005.
R. Fagin, R. Kumar, and D. Sivakumar. “Comparing top k lists”, In SIAM Journal of Discrete Math, vol. 17, no. 1, pp. 134-160, 2003.
S. Furui, T. Kikuchi, Y. Shinnaka and C. Hori, “Speech-to-text and speech-tospeech summarization of spontaneous speech”, IEEE Trans. on Speech and Audio Processing, vol. 12, no. 4, pp. 401-408, July 2004.
G. Furnas, et al. “Information retrieval using a singular value decomposition model of latent semantic structure”, in Proc. of ACM SIGIR Conf., pp. 465-480 Grenoble, France, June 1988.
J. Garofolo, C. Auzanne, and E. M. Voorhees, “The TREC spoken document retrieval track: A success story,” in Proc. 8th Text REtrieval Conference (1999), vol. 500-246 of NIST Special Publication, pp. 107–130, NIST, Gaithersburg, MD, USA, 2000.
J. Gauvain and C. Lee, “Maximum a posteriori estimation for multivariate Gaussian mixture observations of Markov chains”, IEEE Trans. on Speech and Audio Processing, vol. 2, no. 2, pp. 291-298, April 1994.

58 / 50Information and Communications University
References – spoken document retrieval J. Glass, T. Hazen, L. Hetherington and C. Wang, “Analysis and processing
of lecture audio data: Preliminary investigations”, in Proc. of the HLT-NAACL 2004 Workshop on Interdisciplinary Approaches to Speech Indexing and Retrieval, pp. 9-12, Boston, May 2004.
T. Hofmann, “Probabilistic latent semantic analysis”, in Proc. of Uncertainty in Artificial Intelligence (UAI'99), Stockholm, 1999.
A. Inoue, T. Mikami and Y. Yamashita, “Prediction of sentence importance for speech summarization using prosodic features”, in Proc. Eurospeech, 2003.
R. Iyer and M. Ostendorf, “Modeling long distance dependence in language: Topic mixtures vs. dynamic cache models”, in Proc. ICSLP, Philadelphia, 1996.
D. James, The Application of Classical Information Retrieval Techniques to Spoken Documents, PhD thesis, University of Cambridge, 1995.
D. Jones, et al, “Measuring the readability of automatic speech-to-text transcripts”, in Proc. Eurospeech, Geneva, Switzerland, September 2003.
G. Jones, J. Foote, K. Spärck Jones, and S. Young, “Retrieving spoken documents by combining multiple index sources”, In Proc. of ACM SIGIR Conf., pp. 30-38, Zurich, Switzerland, 1996.

59 / 50Information and Communications University
References – spoken document retrieval
K. Koumpis and S. Renals, “Transcription and summarization of voicemail speech”, in Proc. ICSLP, Beijing, October 2000.
C. Leggetter and P. Woodland, “Maximum likelihood linear regression for speaker adaptation on continuous density hidden Markov Models”, Computer Speech and Language, vol. 9, no. 2, pp. 171-185, April 1995.
B. Logan, P. Moreno, and O. Deshmukh, “Word and sub-word indexing approaches for reducing the effects of OOV queries on spoken audio”, in Proc. of HLT, San Diego, March 2002.
I. Malioutov and R. Barzilay, “Minimum cut model for spoken lecture segmentation”, in Proc. of COLING-ACL, 2006.
S. Matsoukas, et al, “BBN CTS English System,” available at http:www.nist.gov/speech/tests/rt/rt2003/spring/presentations.
Kenney Ng, Subword-Based Approaches for Spoken Document Retrieval, PhD thesis, Massachusetts Institute of Technology, 2000.
NIST. The TREC evaluation package available at: http://www-nlpir.nist.gov/projects/trecvid/trecvid.tools/trec_eval
Douglas W. Oard, et al, “Building an information retrieval test collection for spontaneous conversational speech”, In Proc. ACM SIGIR Conf., pp. 41--48, New York, 2004.

60 / 50Information and Communications University
References –spoken document retrieval
J. Ponte and W. Croft, “A language modeling approach to information retrieval”, Proc. ACM SIGIR), pp. 275--281, Melbourne, Australia, August1998.
J. Silva Sanchez, C. Chelba, and A. Acero, “Pruning analysis of the position specific posterior lattices for spoken document search”, in Proc. of ICASSP, Toulouse, France, May 2006.
M. Saraclar and R. Sproat, “Lattice-based search for spoken utterance retrieval”, In Proc. of HLT-NAACL 2004, pp. 129-136, Boston, May 2004.
F. Seide and P. Yu, “Vocabulary-independent search in spontaneous speech”, in Proc. of ICASSP, Montreal, Canada, 2004.
F. Seide and P. Yu, “A hybrid word/phoneme-based approach for improved vocabulary-independent search in spontaneous speech”, in Proc. of ICSLP, Jeju, Korea, 2004.
M. Siegler, Integration of Continuous Speech Recognition and Information Retrieval for Mutually Optimal Performance, PhD thesis, Carnegie Mellon University, 1999.
A. Singhal, J. Choi, D.Hindle, D. Lewis and F. Pereira, “AT&T at TREC-7”, in Text REtrieval Conference, pages 239-252, 1999.

61 / 50Information and Communications University
References – spoken document retrieval
A. Singhal, S. Abney, M. Bacchiani, M. Collins, D. Hindle and F. Pereira, “AT&T at TREC-8”. In Text REtrieval Conference, pp. 317-330, 2000.
O. Siohan and M. Bacchiani, Fast Vocabulary-Independent Audio Search Using Path-Based Graph Indexing, Proc. of Interspeech, Lisbon, Portugal, 2005.
J. M. Van Thong, et al, “SpeechBot: An experimental speech-based search engine for multimedia content on the web”, IEEE Trans. on Multimedia, Vol. 4, No. 1, March 2002.
A. Waibel, et al, “Advances in automatic meeting record creation and access,” in Proc. of ICASSP, Salt Lake City, May 2001.
P. Woodland, S. Johnson, P. Jourlin, and K. Spärck Jones, “Effects of out of vocabulary words in spoken document retrieval”, In Proc. of SIGIR, pp. 372-374, Athens, Greece, 2000.

















