21
Linear Discriminant Functions: Gradient Descent and Perceptron Convergence • The Two-Category Linearly Separable Case (5.4) • Minimizing the Perceptron Criterion Function (5.5)
| Date post: | 24-Jul-2019 |
| Category: |
Documents |
| Upload: | nguyenthuy |
| View: | 231 times |
| Download: | 0 times |

Linear Discriminant Functions:Gradient Descent and Perceptron
Convergence
• The Two-Category Linearly Separable Case (5.4)
• Minimizing the Perceptron Criterion Function (5.5)

CSE 555: Srihari
Role of Linear Discriminant Functions
• A Discriminative Approach • as opposed to Generative approach of Parameter Estimation
• Leads to Perceptrons and Artificial Neural Networks• Leads to Support Vector Machines

CSE 555: Srihari
Two-category Linearly Separable Case
• Set of n samples y1 , y2 , .. , yn• Some labelled ω1 and some labelled ω2• Use samples to determine weight vector a
such thatatyi > 0 implies class ω1
atyi < 0 implies class ω2
• If such a weight vector exists then the samples are said to be linearly separable
• w.l.o.g. solution vector passes through origin (by mapping from x-space to y-space)

CSE 555: Srihari
NormalizationRaw Data
Normalized Data:red points changed in sign
Solution vector separates red fromblack points
Solution vector places all vectorson same side of plane
Solution region is intersection of n half-spaces

CSE 555: Srihari
Margin• Solution vector is not unique• Additional requirements to
constrain solution vector. Two possible approaches:
1. Seek unit length weight vector that maximizes minimum distance from samples to separating hyperplane
2. Minimum length weight vector satisfying atyi > b > 0where b is called the margin
• It is insulated from old boundariesby b / ||yi||
No marginb = 0
Margin b > 0shrinks solution regionby margins b / ||yi||

CSE 555: Srihari
Gradient Descent Formulation•To find solution to set of inequalities atyi > 0
•Define a criterion function J(a) that is minimized if a is a solution vector
•We will define such a function J later
Start with an arbitrarily chosen weight a(1) and Compute gradient vector ∆ J(a(1))Next value a(2) obtained by moving some distance from a(1) in the direction of the steepest descent, i.e., along the negative of the gradient. In general,
Learning rate thatSets the step size

CSE 555: Srihari
Basic Gradient Descent Procedure

CSE 555: Srihari
Learning RateCriterion for step size of Basic Gradient Descent
Creiterion Function approximated by by second-order expansion around a(k):
Hessian matrix ofSecond order partialderivative
jiaaJ ∂∂ /2substituting
Can be minimized by the choice:

CSE 555: Srihari
Criterion for step size of Basic Gradient Descent
Hessian matrix ofSecond order partialderivative
jiaaJ ∂∂ /2
Can be minimized by the choice:
Alternative approach is Newton’s algorithm
CSE 555: Srihari
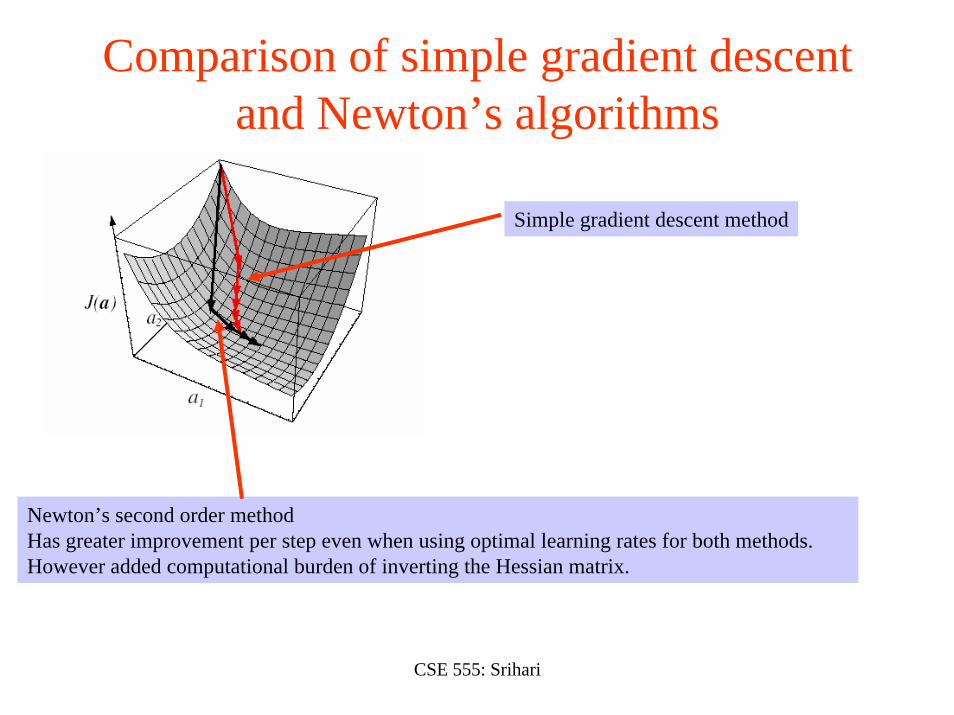
Comparison of simple gradient descent and Newton’s algorithms
Newton’s second order methodHas greater improvement per step even when using optimal learning rates for both methods.However added computational burden of inverting the Hessian matrix.
Simple gradient descent method

CSE 555: Srihari
Perceptron Criterion FunctionObvious criterion function is no of samples misclassified. A poor choice since it is piecewise linearAlternative is the Perceptron criterion function
Set of samples misclassified
If no samples are misclassified then criterion function evaluates to zero.Gradient function evaluates to:
Update Rule becomes

CSE 555: Srihari
Comparison of Four Criterion functionsNo of misclassified samples:Piecewise constant, unacceptable
Perceptron criterion:Piecewise linear, acceptable forgradient descent
Squared error:Useful when patternsare not linearly separable
Squared Error with margin

CSE 555: Srihari
Perceptron Criterion as function of weights
Criterion function plotted as a function of weights a1 and a2
Starts at origin,
Sequence is y2,y3, y1, y3
Second update by y3 takes solution further than first update by y3

CSE 555: Srihari
Convergence of Single-Sample Correction(simpler than batch)

CSE 555: Srihari
Perceptron Convergence TheoremTheorem (Perceptron Convergence)If training samples are linearly separable, then the sequence of weight vectors given by
Fixed Increment Error Correction Algorithm (Algorithm 4) will terminate at a solution vector

CSE 555: Srihari
Proof for Single-Sample Correction

CSE 555: Srihari
Proof for Single-Sample Correction

CSE 555: Srihari
Bound on the number of corrections

CSE 555: Srihari
Some Direct GeneralizationsCorrection whenever at(k) yk fails to exceed a margin

CSE 555: Srihari
Some Direct Generalizations: original gradient descent algorithm for Jp

CSE 555: Srihari
Some Direct Generalizations: Winnow Algorithm
Weights a+ and a- associated with each of the categories to be learnt
Advantages: convergence is faster than in a Perceptron because of proper setting of learning rate
Each constituent value does not overshoot its final value
Benefit is pronounced when there are a large number of irrelevant or redundant features

















