Technologies, proprietary and confidential Constraint-Based Model Constraint-Based Model Mining: Algorithms and Mining: Algorithms and Applications Applications Minos Garofalakis Minos Garofalakis Internet Management Research Dept. Bell Labs, Lucent Technologies [email protected]http://www.bell-labs.com/~minos/
Transcript
Lucent Technologies, proprietary and confidential
Constraint-Based Model Mining: Constraint-Based Model Mining: Algorithms and ApplicationsAlgorithms and Applications
Minos Garofalakis Minos Garofalakis Internet Management Research Dept.
– Support-based Pruning:Support-based Pruning: ensuring all subsequences of a candidate that satisfy C’ are frequent (during pruning)
• If C is anti-monotone (all subsequences of a sequence that satisfies C also satisfy C) then C’ = C is obviously best
• If C is not anti-monotone (e.g., REs) things are not that clear-cut– Aggressive constraint-based pruning can have a negative impact Aggressive constraint-based pruning can have a negative impact
on support-based pruningon support-based pruning
Lucent Technologies, proprietary and confidential
The SPIRIT AlgorithmsThe SPIRIT Algorithms• Specific instantiations of the framework• Explore the entire spectrum of choices for employing RE
constraints during pattern mining
Algorithm Relaxation C’ ( C = R )
SPIRIT(N)
SPIRIT(L)
SPIRIT(V)
SPIRIT(R)
all elements appear in R
Legal wrt some state of A(R)
Valid wrt some state of A(R)
Valid (C’ = C = R)
Lucent Technologies, proprietary and confidential
SPIRIT(N) (“naïve”)SPIRIT(N) (“naïve”)
• Employs RE in a trivial manner ( consider only patterns of elements that appear in the RE )
• Essentially, it’s basic Apriori (only support-based pruning) with RE applied as an afterthought
Lucent Technologies, proprietary and confidential
SPIRIT(L) (“legal”) SPIRIT(L) (“legal”)
• F(k) = frequent k-sequences that are legal wrt some state of A(R)
• F(k,b) = frequent k-sequences legal wrt state b
• Candidate Generation– Idea: if <s1,…,sk> is frequent and legal wrt b then <s1,…,
s(k-1)> is in F(k-1,b) and <s2,…,sk> is in F(k-1,c)
s1b c
Join F(k-1)’s across all transitions of the automaton
• To effectively manage their networks Internet/Telecom Service Providers continuously gather utilization and traffic data
• Managed IP network elements collect huge amounts of traffic data – Switch/router-level monitoring (SNMP, RMON, NetFlow, etc.) – Typical IP router: several 1000s SNMP counters– Service-Level Agreements (SLAs), Quality-of-Service (QoS) guarantees => finer-grain monitoring (per
IP flow!!)
• Telecom networks: Call-Detail Records (CDRs) for every call – CDR = 100s bytes of data with several 10s of fields/attributes (e.g., endpoint exchanges, timestamps,
tarifs)
• End Result: Massive collections of Network-Management (NM) dataMassive collections of Network-Management (NM) data (can grow in the order of several TeraBytes/year!!)
Lucent Technologies, proprietary and confidential
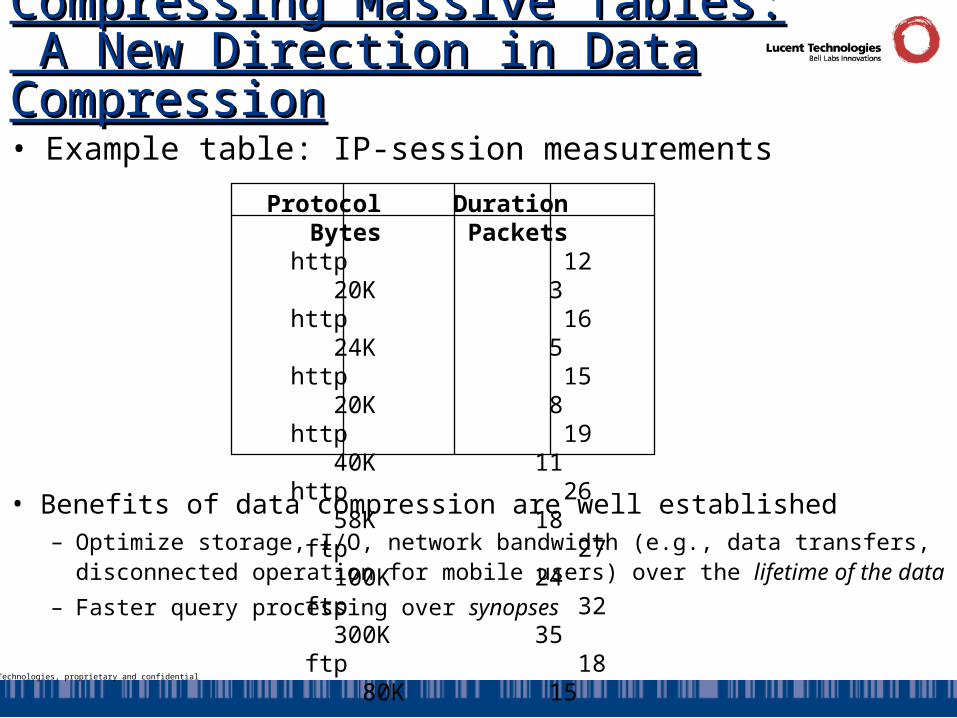
Compressing Massive Tables: A New Compressing Massive Tables: A New Direction in Data CompressionDirection in Data Compression
• Benefits of data compression are well established– Optimize storage, I/O, network bandwidth (e.g., data transfers, disconnected
operation for mobile users) over the lifetime of the data
Compressing Massive Tables: A New Compressing Massive Tables: A New Direction in Data CompressionDirection in Data Compression• Several generic compression tools and algorithms(e.g., gzip, Huffman,
Lempel-Ziv) – Syntactic methods: operate at the byte level, view data as large byte string
– Lossless compression only
• Effective compression of massive alphanumeric tables
– Need novel methods that are semantic: account for and exploit the meaning and data dependencies of attributes in the table
– Lossless or lossy compression: flexible mechanisms for users to specify acceptable information loss
Lucent Technologies, proprietary and confidential
SPARTAN SPARTAN : A Model-Based: A Model-BasedSemantic Compressor Semantic Compressor [SIGMOD’01][SIGMOD’01]
• New, general paradigm: Model-Based Semantic Compression (MBSC)– Extract Data Mining models from the data table– Use the extracted models to construct an effective compression
plan – Lossless or lossy compression (w/ guaranteed per-attribute error
bounds)
• SPARTAN system: Specific instantiation of MBSC framework– Key Idea: use carefully-selected collection of Classification and
Regression Trees (CaRTs) to capture strong data correlations and predict values for entire columns
Lucent Technologies, proprietary and confidential
SPARTAN SPARTAN Example CaRT Models Example CaRT Models
• Can use two compact trees (one decision, one regression) to eliminate two data columns (predicted attributes)
error=0 error<=3
Lucent Technologies, proprietary and confidential
SPARTAN SPARTAN Compression Problem Compression Problem FormulationFormulation
• Given: Data table T over set of attributes X and per-attribute error tolerances
• Find: Set of attributes P to be predicted using CaRT models (and corresponding CaRTs+outliers) such that– Each CaRT uses only predictor attributes in X-P
– Each attribute in P is predicted within its specified tolerance
– The overall storage cost is minimized
• Non-trivial problem!– Space of possible CaRT predictors is exponential in the number of attributes
– CaRT construction is an expensive process (multiple passes over the data)
Lucent Technologies, proprietary and confidential
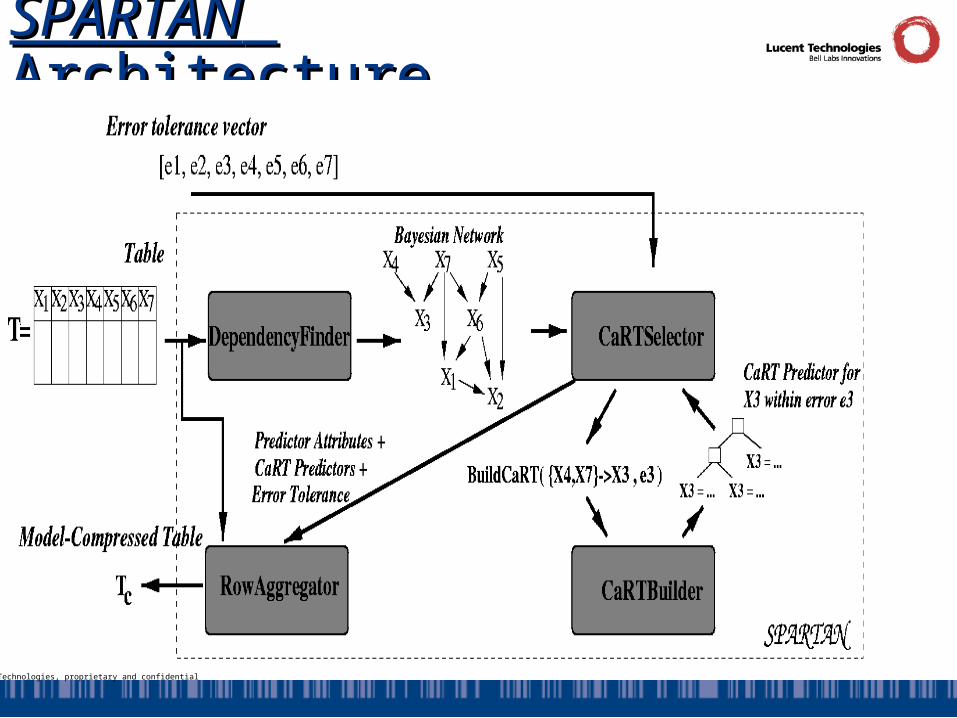
SPARTANSPARTAN Architecture Architecture
Lucent Technologies, proprietary and confidential
SPARTANSPARTAN’s CaRTSelector ’s CaRTSelector • “Heart” of the SPARTAN semantic-compression engine
– Uses the constructed Bayesian Network on T to drive the construction and selection of the “best” subset of CaRT predictors
• Output: Subset of attributes P to be predicted (within tolerance) and corresponding CaRTs
• Complication: An attribute in P cannot be used as a predictor for other attributes– Otherwise, errors will compound!!
• Hard optimization problem -- Strict generalization of Weighted Maximum Independent Set (WMIS) (NP-hard!!)
• Two solutions– Greedy heuristic
– Novel heuristic based on WMIS approximation algorithms
Lucent Technologies, proprietary and confidential
The CaRTBuilder ComponentThe CaRTBuilder Component
• Input: Target predicted attribute Xp; predictor attributes {X1,…,Xk}; and error tolerance for Xp
• Output: Minimum-storage-cost CaRT for Xp using {X1,…,Xk} as predictors, within the specified error tolerance
• Repeated calls from CaRTSelector: Efficiency is key!
• Efficient CaRT construction algorithms that exploit error tolerances – Integrated tree building and error-constraint pruning based on our cost
“lower bounding” ideas
• To keep compression times low, SPARTAN models are built on samples of the data
Lucent Technologies, proprietary and confidential
Experience with Experience with SPARTANSPARTAN• Significant improvements in compression ratio over gzip
– Factor of 3 for error tolerances in 5-10% range
• Compression times are also quite reasonable
– E.g., >500K tuples in a few minutes
– Model induction(s) over small samples of the data
• Despite the use of samples, exploiting CaRT constraints and integrated building/constraint-pruning makes a difference!
– SPARTAN spends 50-75% of its time building CaRTs
– Integrated algorithms can improve performance by 25-30%
• Constraint-based data mining in the context of a “bigger-picture” problem
Lucent Technologies, proprietary and confidential
OutlineOutline• Motivation for mining with constraints• Algorithmic solutions
– “Sliding window” stream mining?• How do you expire the effects of stale data from your models?• CVFDT [Domingos et al.] takes some initial steps in this direction
Lucent Technologies, proprietary and confidential
ConclusionsConclusions• Personal, biased perspective on constraint-based data mining through
a brief summary of some of my own work in the area– Sequential patterns, decision/regression trees, and application to model-based
semantic compression
• Similarly-biased discussion of challenging directions for future work– Principled, cost-based constraint pushing, and data-stream mining
• Effective support for constraints is essential for next-generation ad-hoc data mining, analysis, and exploration systems– So far, we’ve only scratched the surface…
– As we move forward towards “Pattern/Inductive DBMSs” (and, DSMSs) research challenges abound!!
• Data Mining research can help!– Develop novel tools for the effective storage, exploration, and Develop novel tools for the effective storage, exploration, and
analysis of massive Network-Management dataanalysis of massive Network-Management data• Several challenging research themes
– semantic data compression, approximate query processing, XML, mining models for event correlation and fault analysis, network-recommender systems, . . .
• Loooooong-term goal :-)– Intelligent, self-tuning, self-”healing” communication networks
• Use BN to restrict (huge!) search space of possible CaRT models: Build CaRTs using “neighboring” attributes as predictors
• SPARTAN uses an (enhanced) constraint-based BN builder
Season?
Sprinkler on? It rained?
Ground wet?
Ground slippery?
• Input: Random sample of input table T • Output: A Bayesian Network (BN) identifying strong dependencies
and “predictive correlations” among T’s attributes• BN Semantics: An attribute is independent of all its non-descendants
given its parents
Lucent Technologies, proprietary and confidential
The Greedy The Greedy CaRTSelectorCaRTSelector
1. MatSet = {}, PredSet = {}
2. For each attribute Xi in the Bayesian Network in topological sort order
if Xi has no parents add Xi to MatSetelse { 2.1 build CaRT for Xi with the attributes in MatSet as predictors 2.2 if materializationCost(Xi) > CT * predictionCost(Xi) add Xi to PredSet else add Xi to MatSet }
3. PredSet is the set of attributes to be predicted
X1
X4
X5 X6
X2
X3
X7
Lucent Technologies, proprietary and confidential
The MaxIndependentSet (MIS) The MaxIndependentSet (MIS) CaRTSelectorCaRTSelector
• What is wrong with Greedy?– Myopic strategy: ignores the potential benefits of using an attribute as a
predictor for its descendants– Effect of the relative benefit parameter CT ?!?
• MIS CaRTSelector– Addresses both problems of Greedy -- much more “global” view of the
attribute correlations
– Exploits natural mapping of WMIS to the CaRTSelector problem
Lucent Technologies, proprietary and confidential
The MaxIndependentSet (MIS) The MaxIndependentSet (MIS) CaRTSelector (contd.)CaRTSelector (contd.)
• Key idea: Use a WMIS approximation algorithm iteratively to solve different instances of WMIS– “Weight” of a node (attribute) = materializationCost - predictionCost
– Prediction cost using the materialized “predictive neighborhood” of the node
– Each WMIS iteration improves earlier solution by moving a (“near-optimal”) subset of nodes to the predicted set
– Stop when no improvement is possible
• Number of CaRTs built– Greedy CaRTSelector: O(n)
– MIS CaRTSelector : O(n^2/2) in the worst case, O(n logn) “on average”
Lucent Technologies, proprietary and confidential
The RowAggregator ComponentThe RowAggregator Component
• Input: Sub-table TM of materialized data attributes returned by the CaRTSelector
• Output: Fascicle-based (lossy) compression scheme for TM
• Summary
– Tricky: Attribute errors in TM should not propagate through the CaRTs to the predicted attributes
– Algorithms based on fascicle algorithms of [JMN99]