

Lucent Technologies, proprietary and confidential
Constraint-Based Model Mining: Constraint-Based Model Mining: Algorithms and ApplicationsAlgorithms and Applications
Minos Garofalakis Minos Garofalakis Internet Management Research Dept.
Bell Labs, Lucent Technologies
http://www.bell-labs.com/~minos/

Lucent Technologies, proprietary and confidential
OutlineOutline• Motivation for mining with constraints• Algorithmic solutions
– Sequential patterns – SPIRIT
– Decision trees
• Application: Model-Based Semantic Compression - SPARTAN
• Future directions– Cost-based constraint pushing
– Mining continuous data streams
• Conclusions

Lucent Technologies, proprietary and confidential
MotivationMotivation• Data Mining: Extracting concise and interesting models
from large data sets– I/O and computation intensive, multiple passes over the data
• Lack of user-controlled focus – few “knobs” to specify models of interest to users– Patterns/Associations: Only specify a lower bound on support
– Decision trees: Search for some “optimal” tree (e.g., MDL)
– Often, huge numbers of patterns or models that are to large to comprehend/interpret
• Decision trees with 100s of nodes are not at all “easy to assimilate”…

Lucent Technologies, proprietary and confidential
Motivation Motivation (contd.)(contd.)• BUT ... users may only be interested in models of specific
form!! – Patterns conforming to a specific structure– “Best” decision tree with <= k nodes (to get rough picture of data)
• Problems with traditional, unfocused search:Problems with traditional, unfocused search:– Disproportionate cost for “selective” users– Overwhelming volume of (possibly) useless results
• Sorting through the results to find model(s) of interest can be non-trivial
• Goals of constraint-based data mining:Goals of constraint-based data mining:– Flexible languages for specifying structural and other constraints on
mining models– Algorithms for “pushing”/exploiting these constraints inside the
mining loop – Cost should be commensurate with user selectivityCost should be commensurate with user selectivity

Lucent Technologies, proprietary and confidential
OutlineOutline• Motivation for mining with constraints• Algorithmic solutions
– Constraint-based sequential pattern discovery – SPIRIT
– Decision trees
• Application: Model-Based Semantic Compression - SPARTAN
• Future directions– Cost-based constraint pushing
– Mining continuous data streams
• Conclusions

Lucent Technologies, proprietary and confidential
Sequential Pattern Discovery Sequential Pattern Discovery • Discovery of frequent sequential patterns (subsequences) in a
database of sequences
< 1 , 2 , 3 >
< 1 , 3 , 4 >
< 1, 2 , 3 , 4 >< 1, 5 , 6 , 3 , 4 >< 7 , 1 , 2 , 3 >< 1 , 8 , 2 , 3 >
support >= 50%
• Scope: market-basket (buying patterns) , page access patterns (WWW advertising) , alarm correlations (data networks), etc.
– Example (Yahoo! topic hierarchy) - distinct paths for hotels in NY < travel, yahoo!travel, north america, US, NY, NY city, lodging, hotels >
< travel, lodging, yahoo!lodging, NY, NY cities, NY city, hotels and motels>
Frequency is important, e.g., for advertisingFrequency is important, e.g., for advertising

Lucent Technologies, proprietary and confidential
Our Work Our Work [VLDB’99,TKDE’02][VLDB’99,TKDE’02]
• Our Contributions– Use of Regular Expressions (REs) as a user-level tool for
specifying interesting pattern structures (natural syntax + expressive power), e.g.,
travel (lodging | NY | NY city)* (hotels | hotels and motels) – Novel algorithms (SPIRIT) for pushing REs inside the pattern
mining loop• Differ in the degree to which the RE is enforced
• Interesting insights into incorporating complex constraints in ad-hoc data mining
• Srikant & Agrawal [ICDE’95,EDBT’96]: Unfocused search – User only specifies a lower bound on the pattern frequency (minimum
support)

Lucent Technologies, proprietary and confidential
Problem Formulation Problem Formulation • Sequence s = <s1,…, sn> contains pattern t = <t1,…,tm> if
for some j < k < … < p : t1 = sj, t2 = sk, …, tm = sp
• Regular expression R: language L(R) over the alphabet of sequence / pattern elements
s = < 1 , 2 , 4 , 5 , 7 , 9 >
t = < 1 , 5 , 9 >
p = < 2 , 4 , 5 >
R = 1*(2 2 | 2 3 4 | 4 4 )
L(R) = zero or more 1’s followed by 2 2 or 2 3 4 or 4 4

Lucent Technologies, proprietary and confidential
Problem Formulation Problem Formulation (contd.)(contd.)
• Given: DB of sequences D , and (user-specified) minimum support minsup and RE constraint R
• Find: All patterns that are contained in at least minsup sequences of D and belong to L(R)
Extensions : sequences of itemsets , distance constraints

Lucent Technologies, proprietary and confidential
DefinitionsDefinitions• Well-known fact: REs are equivalent to DFAs
1*(2 2 | 2 3 4 | 4 4)a b c d
1
2 3 4
2
4Start state Accept state(s)
• A sequence s is :
– Legal wrt state b iff it defines a path in A(R) starting from b
– Valid wrt state b iff it defines a path to an accept state of A(R) starting from b
– Valid iff it defines a path from the start state to an accept state of A(R) (i.e., s belongs to L(R) )
R A(R)

Lucent Technologies, proprietary and confidential
Conventional Apriori Mining Conventional Apriori Mining Apriori(D, minsup)
repeat {
using F(k-1) generate set of candidate (i.e., potentially // generation
frequent) k-sequences C(k)
P = { s C(k) : any (k-1)-subsequence of s is not in F(k-1) } // pruning
C(k) = C(k) - P
scan D counting support for all sequences in C(k) // counting
F(k) = frequent sequences in C(k); F = F + F(k); k = k+1
} until F(k) is empty
• F(k) = frequent sequences of length k (k-sequences)
• C(k) = candidate frequent k-sequences

Lucent Technologies, proprietary and confidential
The SPIRIT Framework The SPIRIT Framework SPIRIT(D , minsup , C)
C’ = relaxation of C
repeat{
using F and C’ generate // generation
C(k) = { potentially frequent k-sequences that satisfy C’ }
P = { s C(k): s has a subsequence that satisfies C’ // pruning
and does not belong to F }
C(k) = C(k) - P
scan D counting support for sequences in C(k) // counting
F(k) = frequent sequences in C(k); F = F +F(k); k = k+1
} until TerminatingCondition(F , C’)
output sequences in F that satisfy C

Lucent Technologies, proprietary and confidential
The SPIRIT Framework The SPIRIT Framework (contd.)(contd.)• Invariant: at the end of pass k , F is the set of frequent
1,2,…,k-sequences that satisfy C’• “Strength” of the relaxation C’ determines the degree to
which C = R is enforced during mining
• Major cost = candidate counting ( proportional to |C(k)| )• Goal:
– Exploit minsup and C to restrict |C(k)| as much as possible
BUT, pushing C “all the way” may not be the best strategy!!BUT, pushing C “all the way” may not be the best strategy!!

Lucent Technologies, proprietary and confidential
The SPIRIT Framework The SPIRIT Framework (contd.)(contd.)• SPIRIT employs two types of pruning to restrict C(k)
– Constraint-based Pruning: Constraint-based Pruning: ensuring candidates in C(k) satisfy C’ (during generation)
– Support-based Pruning:Support-based Pruning: ensuring all subsequences of a candidate that satisfy C’ are frequent (during pruning)
• If C is anti-monotone (all subsequences of a sequence that satisfies C also satisfy C) then C’ = C is obviously best
• If C is not anti-monotone (e.g., REs) things are not that clear-cut– Aggressive constraint-based pruning can have a negative impact Aggressive constraint-based pruning can have a negative impact
on support-based pruningon support-based pruning

Lucent Technologies, proprietary and confidential
The SPIRIT AlgorithmsThe SPIRIT Algorithms• Specific instantiations of the framework• Explore the entire spectrum of choices for employing RE
constraints during pattern mining
Algorithm Relaxation C’ ( C = R )
SPIRIT(N)
SPIRIT(L)
SPIRIT(V)
SPIRIT(R)
all elements appear in R
Legal wrt some state of A(R)
Valid wrt some state of A(R)
Valid (C’ = C = R)

Lucent Technologies, proprietary and confidential
SPIRIT(N) (“naïve”)SPIRIT(N) (“naïve”)
• Employs RE in a trivial manner ( consider only patterns of elements that appear in the RE )
• Essentially, it’s basic Apriori (only support-based pruning) with RE applied as an afterthought

Lucent Technologies, proprietary and confidential
SPIRIT(L) (“legal”) SPIRIT(L) (“legal”)
• F(k) = frequent k-sequences that are legal wrt some state of A(R)
• F(k,b) = frequent k-sequences legal wrt state b
• Candidate Generation– Idea: if <s1,…,sk> is frequent and legal wrt b then <s1,…,
s(k-1)> is in F(k-1,b) and <s2,…,sk> is in F(k-1,c)
s1b c
Join F(k-1)’s across all transitions of the automaton

Lucent Technologies, proprietary and confidential
SPIRIT(L) (“legal”) SPIRIT(L) (“legal”) (contd.)(contd.)
• Candidate Pruning– A candidate k-sequence can be pruned if any of its maximal legal subsequences is not
frequent (cannot be found in F)– We have an efficient Dynamic Programming algorithm that works off the automaton to
find such maximal legal subsequences– More expensive than Apriori pruning, but we found CPU overheads to be negligible
compared to counting costs
(details in the paper…)

Lucent Technologies, proprietary and confidential
Legal vs. NaiveLegal vs. Naive
a b c d
1
2 3 4
2
4
accept D: <1 2 3 2>
<1 1 2 2><2 4 3 4><2 3 4 3><1 1 2 3>
SPIRIT(N): F(2) = { <1 1> , <1 2>, <1 3>, <2 2>, <2 3>, <2 4>, <3 4>, <4 3> }
C(3) = { <1 1 1> , <1 1 2>, <1 1 3>, <1 2 2>, <1 2 3>,
<2 2 2>, <2 2 3>, <2 2 4>, <2 3 4>, <2 4 3> }
SPIRIT(L): F(2) = { <1 1> , <1 2>, <2 2>, <2 3>, <3 4>}
C(3) = { <1 1 1> , <1 1 2>, <1 2 2>, <1 2 3>, <2 3 4> }
minsup = 2

Lucent Technologies, proprietary and confidential
SPIRIT(V) (“valid”) SPIRIT(V) (“valid”) • F(k) = frequent k-sequences that are valid wrt some state
of A(R)• F(k,b) = frequent k-sequences valid wrt state b
• Candidate Generation– idea: if <s1,…,sk> is frequent and valid wrt b then <s2,
…,sk> is in F(k-1,c)
Extend F(k-1)’s “backwards” across all transitions
s1b c
accept
• Candidate Pruning– a version of our Dynamic Programming strategy developed for
SPIRIT(L) can be used

Lucent Technologies, proprietary and confidential
Valid vs. LegalValid vs. Legal
a b c d
1
2 3 4
2
4
accept D: <1 2 3 2>
<1 1 2 2><2 4 3 4><2 3 4 3><1 1 2 3>
SPIRIT(L): F(2) = { <1 1>, <1 2>, <2 2>, <2 3>, <3 4> }
C(3) = { <1 1 1> , <1 1 2>, <1 2 2>, <1 2 3>, <2 3 4> }
minsup = 2
SPIRIT(V): F(2) = { <2 2>, <3 4> }
C(3) = { <1 2 2>, <2 3 4> }

Lucent Technologies, proprietary and confidential
SPIRIT(R) (“regular”) SPIRIT(R) (“regular”)
• F(k) = frequent k-sequences that are valid ( satisfy R )
• Candidate Generation– No efficient mechanism -- “brute-force” enumeration of paths in the
automaton– Some optimizations (e.g., exploiting cycles) to reduce computation
• Candidate Pruning– A version of our Dynamic Programming strategy is once again
applicable

Lucent Technologies, proprietary and confidential
Experience with SPIRITExperience with SPIRIT
• Implemented and tested over real-life and synthetic data
• Speedups of more than an order of magnitude possible if constraints are exploited
• SPIRIT(V) offers a nice tradeoff and provides good performance over a range of RE constraints
• BUT…– In general, the choice of the “best” strategy depends critically on
the data-set and RE-constraint characteristics • E.g., RE “selectivity”

Lucent Technologies, proprietary and confidential
OutlineOutline• Motivation for mining with constraints• Algorithmic solutions
– Sequential patterns – SPIRIT
– Constraint-based decision-tree induction
• Application: Model-Based Semantic Compression - SPARTAN
• Future directions– Cost-based constraint pushing
– Mining continuous data streams
• Conclusions

Lucent Technologies, proprietary and confidential
Decision Trees 101Decision Trees 101
salary education label10000 high school reject40000 under graduate accept15000 under graduate reject75000 graduate accept18000 graduate accept
accept reject
salary < 20000
noyes
noyesaccept
education in graduate
Credit Analysis
• Decision tree: Tree-structured predictor for a specified categorical class label using other data attributes
• Built based on training data set
• For numerical class labels: Regression tree

Lucent Technologies, proprietary and confidential
Conventional Decision-Tree Conventional Decision-Tree InductionInduction• Building phase
– Recursively split nodes using “best” splitting attribute for node
• E.g., using entropy of the split
• Pruning phase– Smaller imperfect decision tree generally achieves better
accuracy– Prune leaf nodes recursively to prevent overfitting
• Typically based on MDL cost of subtrees

Lucent Technologies, proprietary and confidential
The Need for Constraint SupportThe Need for Constraint Support
• MDL-optimal decision tree can be – Complex with hundreds or thousands of nodes– Difficult to comprehend
• Users may only be interested in a rough picture of the patterns in their data– A simple, quick-to-build, approximate decision tree is much
more useful

Lucent Technologies, proprietary and confidential
Our Work Our Work [KDD’00,DMKDJ’03][KDD’00,DMKDJ’03]
• Efficient algorithms for building MDL-optimal decision trees under
– Size Constraints: the number of tree nodes is <= k
– Error Constraints: the total number of misclassified records <= e
• Applying the constraints after tree-building is simple, but …
– A lot of effort is wasted on parts of the tree that are pruned later
• Our algorithms: Integrate constraints in the tree-building phase
– Reduce I/O and improve performance by early removal of useless parts of the tree
– Guarantee that the final tree is identical to that obtained by “naïve” late pruning

Lucent Technologies, proprietary and confidential
Key Ideas Key Ideas • Basic problem: Building works top-down, pruning works bottom-up
– How can we stop expanding “useless” nodes early? Don’t really know the true MDL cost of the tree underneath them…
• Key Intuition: Branch & Bound based on lower bounds on subtree cost computed for “yet-to-expand” nodes
– Details in the paper…
– Performance speedup of up to an order of magnitude wrt “late pruning”
• Similar ideas for constrained regression-trees
tree-building
N
LB( MDLcost(N, k) )

Lucent Technologies, proprietary and confidential
OutlineOutline• Motivation for mining with constraints• Algorithmic solutions
– Sequential patterns – SPIRIT
– Decision trees
• Application: Model-Based Semantic Compression of Massive Network-Data Tables - SPARTAN
• Future directions– Cost-based constraint pushing
– Mining continuous data streams
• Conclusions

Lucent Technologies, proprietary and confidential
Networks Networks CreateCreate Data! Data!
• To effectively manage their networks Internet/Telecom Service Providers continuously gather utilization and traffic data
• Managed IP network elements collect huge amounts of traffic data – Switch/router-level monitoring (SNMP, RMON, NetFlow, etc.) – Typical IP router: several 1000s SNMP counters– Service-Level Agreements (SLAs), Quality-of-Service (QoS) guarantees => finer-grain monitoring (per
IP flow!!)
• Telecom networks: Call-Detail Records (CDRs) for every call – CDR = 100s bytes of data with several 10s of fields/attributes (e.g., endpoint exchanges, timestamps,
tarifs)
• End Result: Massive collections of Network-Management (NM) dataMassive collections of Network-Management (NM) data (can grow in the order of several TeraBytes/year!!)
Lucent Technologies, proprietary and confidential
Compressing Massive Tables: A New Compressing Massive Tables: A New Direction in Data CompressionDirection in Data Compression
• Benefits of data compression are well established– Optimize storage, I/O, network bandwidth (e.g., data transfers, disconnected
operation for mobile users) over the lifetime of the data
– Faster query processing over synopses
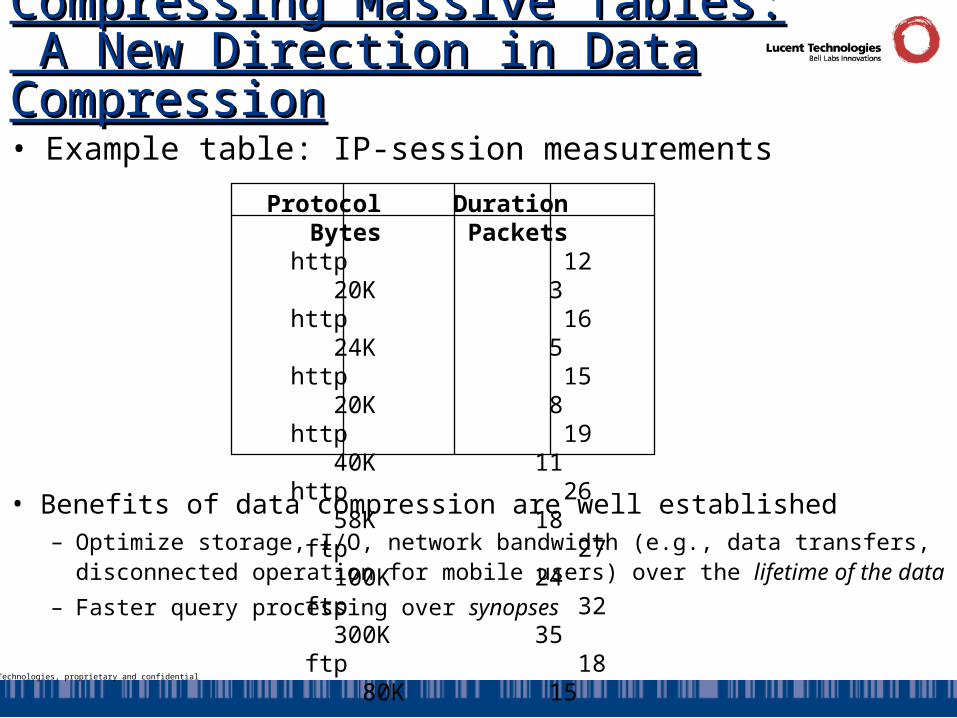
Protocol Duration Bytes Packets http 12 20K 3 http 16 24K 5 http 15 20K 8 http 19 40K 11 http 26 58K 18 ftp 27 100K 24 ftp 32 300K 35 ftp 18 80K 15
• Example table: IP-session measurements

Lucent Technologies, proprietary and confidential
Compressing Massive Tables: A New Compressing Massive Tables: A New Direction in Data CompressionDirection in Data Compression• Several generic compression tools and algorithms(e.g., gzip, Huffman,
Lempel-Ziv) – Syntactic methods: operate at the byte level, view data as large byte string
– Lossless compression only
• Effective compression of massive alphanumeric tables
– Need novel methods that are semantic: account for and exploit the meaning and data dependencies of attributes in the table
– Lossless or lossy compression: flexible mechanisms for users to specify acceptable information loss

Lucent Technologies, proprietary and confidential
SPARTAN SPARTAN : A Model-Based: A Model-BasedSemantic Compressor Semantic Compressor [SIGMOD’01][SIGMOD’01]
• New, general paradigm: Model-Based Semantic Compression (MBSC)– Extract Data Mining models from the data table– Use the extracted models to construct an effective compression
plan – Lossless or lossy compression (w/ guaranteed per-attribute error
bounds)
• SPARTAN system: Specific instantiation of MBSC framework– Key Idea: use carefully-selected collection of Classification and
Regression Trees (CaRTs) to capture strong data correlations and predict values for entire columns

Lucent Technologies, proprietary and confidential
SPARTAN SPARTAN Example CaRT Models Example CaRT Models
error = 0Protocol Duration Bytes Packets http 12 20K 3 http 16 24K 5 http 15 20K 8 http 19 40K 11 http 26 58K 18 ftp 27 100K 24 ftp 32 300K 35 ftp 18 80K 15
Protocol = httpProtocol = ftp
yes no
yes no
Packets > 10
Bytes > 60K
Protocol = http
error <= 3
Duration = 15 (outlier: Packets = 11)
Duration = 29
yes no
Packets > 16
• Can use two compact trees (one decision, one regression) to eliminate two data columns (predicted attributes)
error=0 error<=3

Lucent Technologies, proprietary and confidential
SPARTAN SPARTAN Compression Problem Compression Problem FormulationFormulation
• Given: Data table T over set of attributes X and per-attribute error tolerances
• Find: Set of attributes P to be predicted using CaRT models (and corresponding CaRTs+outliers) such that– Each CaRT uses only predictor attributes in X-P
– Each attribute in P is predicted within its specified tolerance
– The overall storage cost is minimized
• Non-trivial problem!– Space of possible CaRT predictors is exponential in the number of attributes
– CaRT construction is an expensive process (multiple passes over the data)
Lucent Technologies, proprietary and confidential
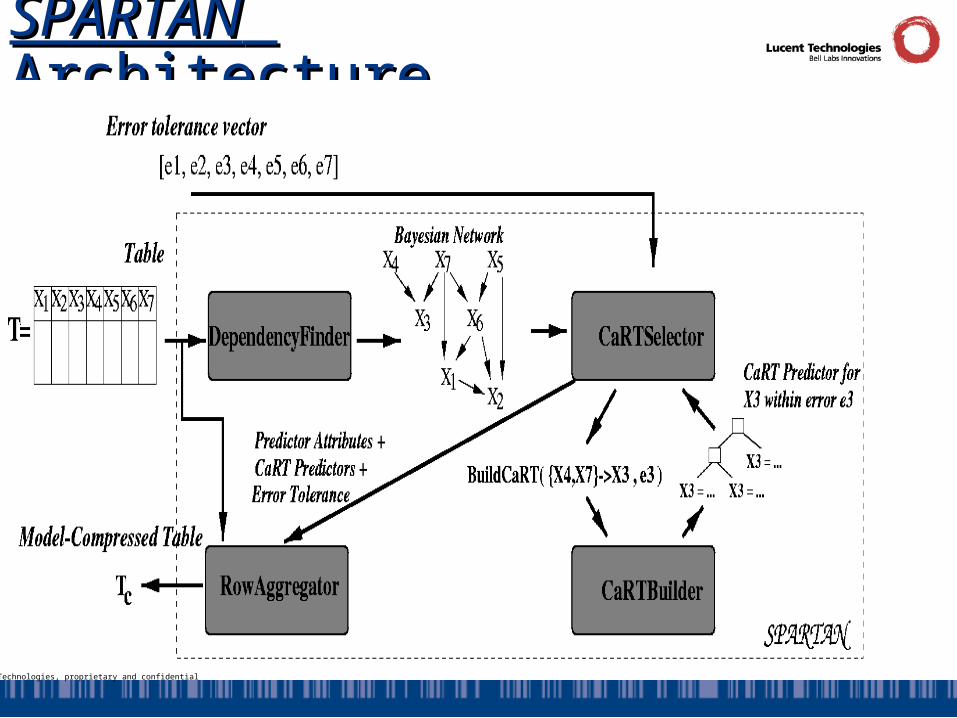
SPARTANSPARTAN Architecture Architecture

Lucent Technologies, proprietary and confidential
SPARTANSPARTAN’s CaRTSelector ’s CaRTSelector • “Heart” of the SPARTAN semantic-compression engine
– Uses the constructed Bayesian Network on T to drive the construction and selection of the “best” subset of CaRT predictors
• Output: Subset of attributes P to be predicted (within tolerance) and corresponding CaRTs
• Complication: An attribute in P cannot be used as a predictor for other attributes– Otherwise, errors will compound!!
• Hard optimization problem -- Strict generalization of Weighted Maximum Independent Set (WMIS) (NP-hard!!)
• Two solutions– Greedy heuristic
– Novel heuristic based on WMIS approximation algorithms

Lucent Technologies, proprietary and confidential
The CaRTBuilder ComponentThe CaRTBuilder Component
• Input: Target predicted attribute Xp; predictor attributes {X1,…,Xk}; and error tolerance for Xp
• Output: Minimum-storage-cost CaRT for Xp using {X1,…,Xk} as predictors, within the specified error tolerance
• Repeated calls from CaRTSelector: Efficiency is key!
• Efficient CaRT construction algorithms that exploit error tolerances – Integrated tree building and error-constraint pruning based on our cost
“lower bounding” ideas
• To keep compression times low, SPARTAN models are built on samples of the data

Lucent Technologies, proprietary and confidential
Experience with Experience with SPARTANSPARTAN• Significant improvements in compression ratio over gzip
– Factor of 3 for error tolerances in 5-10% range
• Compression times are also quite reasonable
– E.g., >500K tuples in a few minutes
– Model induction(s) over small samples of the data
• Despite the use of samples, exploiting CaRT constraints and integrated building/constraint-pruning makes a difference!
– SPARTAN spends 50-75% of its time building CaRTs
– Integrated algorithms can improve performance by 25-30%
• Constraint-based data mining in the context of a “bigger-picture” problem

Lucent Technologies, proprietary and confidential
OutlineOutline• Motivation for mining with constraints• Algorithmic solutions
– Sequential patterns – SPIRIT
– Decision trees
• Application: Model-Based Semantic Compression - SPARTAN
• Future directions– Cost-based constraint pushing
– Mining continuous data streams
• Conclusions

Lucent Technologies, proprietary and confidential
Cost-based Constraint PushingCost-based Constraint Pushing
• Support for user/application-defined constraints is a “must” for
large-scale, ad-hoc data mining
• Interesting early work on simple constraint forms, e.g., for
associations [J. Han et al.]
• Need effective support for more complex constraint forms
– E.g., structural constraints for mining structured/semi-structured
data (sequences, trees, graphs, …)

Lucent Technologies, proprietary and confidential
Cost-based Constraint PushingCost-based Constraint Pushing (contd.) (contd.)
• SPIRIT: Broad spectrum of available choices for dealing with
complex, non-antimonotone constraints
• Winning strategy? Not always obvious, and clearly dependent on
constraint and data characteristics
– E.g., “selectivity” of the RE constraint over the data sequences
– Push highly-selective REs more aggressively to maximize the
benefit from constraint-based pruning
• Best strategy may in fact be adaptive
– Different degrees of “constraint pushing” at different stages of
the search

Lucent Technologies, proprietary and confidential
Cost-based Constraint PushingCost-based Constraint Pushing (contd.) (contd.)• Problem very reminiscent of query optimization in DBMSs
– Mining operator with constraints = user query, processing strategy = query
execution plan
• Need a principled, cost-based approach to effectively handling
complex data-mining constraints
– “Optimizer” to evaluate alternatives and pick a “best” plan
• Several issues need to be fundamentally rethought for
pattern/inductive DBs
– Appropriate statistical summaries (“histograms” for mining), plan
optimization strategies, adaptive optimization/execution, …
• Initial steps: “Adaptive SPIRIT” technique [J-F Boulicaut et al.]
• Still, lots more interesting problems here!!

Lucent Technologies, proprietary and confidential
Mining Continuous Data StreamsMining Continuous Data Streams • Stream-query processing arises naturally in Network Management
– Data records arrive continuously, at high rates from different parts of the network
– Shipped for archival storage off-site (expensive access)– Real-time reaction - data-analysis algorithms can only look at the tuples
once, in the fixed order of arrival and with limited available memory
IP Network
Network Operations Center (NOC)
MeasurementsAlarms R1
R2 R3

Lucent Technologies, proprietary and confidential
Mining Data Streams Mining Data Streams (contd.)(contd.)
• Requirements for stream synopses– Single Pass: Each record is examined at most once, in fixed (arrival) order
– Small Space: Log or poly-log in data stream size
– Real-time: Per-record processing time (to maintain synopses) must be low
Stream AnalysisEngine
(Approximate) Patterns/Models
Stream Synopses (in memory)
Data Streams
• A data stream is a (massive) sequence of records: – General model permits deletion of records as well
nrr ,...,1

Lucent Technologies, proprietary and confidential
Mining Data Streams Mining Data Streams (contd.)(contd.)• Several interesting recent results: Clustering [Guha et al.], Decision
trees [Domingos et al.], Frequent itemsets [Manku et al.], …– Overview in data streaming tutorial with J. Gehrke, R. Rastogi
[SIGMOD/VLDB/KDD’02]
• Still, tons of open problems– Mining structured/semi-structured data streams (sequences, trees,
graphs) is wide open– How can constraints on the models of interest be exploited in the
streaming context?• Reduce synopsis size, improve error guarantees, etc…
– “Sliding window” stream mining?• How do you expire the effects of stale data from your models?• CVFDT [Domingos et al.] takes some initial steps in this direction

Lucent Technologies, proprietary and confidential
ConclusionsConclusions• Personal, biased perspective on constraint-based data mining through
a brief summary of some of my own work in the area– Sequential patterns, decision/regression trees, and application to model-based
semantic compression
• Similarly-biased discussion of challenging directions for future work– Principled, cost-based constraint pushing, and data-stream mining
• Effective support for constraints is essential for next-generation ad-hoc data mining, analysis, and exploration systems– So far, we’ve only scratched the surface…
– As we move forward towards “Pattern/Inductive DBMSs” (and, DSMSs) research challenges abound!!

Lucent Technologies, proprietary and confidential
Thank you! Thank you!
http://www.bell-labs.com/~minos/http://www.bell-labs.com/~minos/ [email protected]@research.bell-labs.com

Lucent Technologies, proprietary and confidential
The The NEMESISNEMESIS Project Project• Massive NM data sets “hide” knowledge that is crucial to key
management tasks– Application/user profiling, proactive/reactive resource management & traffic
engineering, capacity planning, etc.
• Data Mining research can help!– Develop novel tools for the effective storage, exploration, and Develop novel tools for the effective storage, exploration, and
analysis of massive Network-Management dataanalysis of massive Network-Management data• Several challenging research themes
– semantic data compression, approximate query processing, XML, mining models for event correlation and fault analysis, network-recommender systems, . . .
• Loooooong-term goal :-)– Intelligent, self-tuning, self-”healing” communication networks

Lucent Technologies, proprietary and confidential
SPARTAN’s SPARTAN’s DependencyFinder DependencyFinder
• Use BN to restrict (huge!) search space of possible CaRT models: Build CaRTs using “neighboring” attributes as predictors
• SPARTAN uses an (enhanced) constraint-based BN builder
Season?
Sprinkler on? It rained?
Ground wet?
Ground slippery?
• Input: Random sample of input table T • Output: A Bayesian Network (BN) identifying strong dependencies
and “predictive correlations” among T’s attributes• BN Semantics: An attribute is independent of all its non-descendants
given its parents

Lucent Technologies, proprietary and confidential
The Greedy The Greedy CaRTSelectorCaRTSelector
1. MatSet = {}, PredSet = {}
2. For each attribute Xi in the Bayesian Network in topological sort order
if Xi has no parents add Xi to MatSetelse { 2.1 build CaRT for Xi with the attributes in MatSet as predictors 2.2 if materializationCost(Xi) > CT * predictionCost(Xi) add Xi to PredSet else add Xi to MatSet }
3. PredSet is the set of attributes to be predicted
X1
X4
X5 X6
X2
X3
X7

Lucent Technologies, proprietary and confidential
The MaxIndependentSet (MIS) The MaxIndependentSet (MIS) CaRTSelectorCaRTSelector
• What is wrong with Greedy?– Myopic strategy: ignores the potential benefits of using an attribute as a
predictor for its descendants– Effect of the relative benefit parameter CT ?!?
• MIS CaRTSelector– Addresses both problems of Greedy -- much more “global” view of the
attribute correlations
– Exploits natural mapping of WMIS to the CaRTSelector problem

Lucent Technologies, proprietary and confidential
The MaxIndependentSet (MIS) The MaxIndependentSet (MIS) CaRTSelector (contd.)CaRTSelector (contd.)
• Key idea: Use a WMIS approximation algorithm iteratively to solve different instances of WMIS– “Weight” of a node (attribute) = materializationCost - predictionCost
– Prediction cost using the materialized “predictive neighborhood” of the node
– Each WMIS iteration improves earlier solution by moving a (“near-optimal”) subset of nodes to the predicted set
– Stop when no improvement is possible
• Number of CaRTs built– Greedy CaRTSelector: O(n)
– MIS CaRTSelector : O(n^2/2) in the worst case, O(n logn) “on average”

Lucent Technologies, proprietary and confidential
The RowAggregator ComponentThe RowAggregator Component
• Input: Sub-table TM of materialized data attributes returned by the CaRTSelector
• Output: Fascicle-based (lossy) compression scheme for TM
• Summary
– Tricky: Attribute errors in TM should not propagate through the CaRTs to the predicted attributes
– Algorithms based on fascicle algorithms of [JMN99]







