33
Managing Complexity with Object-Oriented Programming Andreou Dimitris 2 / 3 / 2007 Herakleio, Crete
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 223 times |
| Download: | 0 times |

Managing Complexity with Object-Oriented Programming
Andreou Dimitris
2 / 3 / 2007
Herakleio, Crete

Goals of this presentation
• Illustrate the importance of good API design, by example
• Motivate the adoption of object-oriented techniques, as a means to keep complex domains manageable
• Provide practical advice– Good OOP should be a commodity, not a luxury (or an
after-thought)!
– Productive APIs should shield as from boring, repetitive tasks, even for day to day work

What is design, and why it is important
• We don’t want to rewrite everything that is needed by our program to run
• We only care about our “interesting”/unique stuff, and regard anything else as “infrastructure”, an already invented wheel
• Someone along the way may think of our work as infrastructure, upon which he can build his own interesting stuff
• A program is always a provider of reusable software, and most of the time a consumer too
• A trivial, clarifying example follows

• This is a consumer (unless it calls no other method), but is it also a provider (of reusable software)?
• Well, one can still “reuse” it by:

Duality of code: Inbound / Outbound
• So, whatever code we write, it has two facets:– An outbound: executable (consumer) code
• In Java, that is code in curly brackets { }• Regarded as “implementation”
– An inbound: specification for potential consumers• Method/Type declarations• Regarded as “design”
• The outbound part is subject to good programming/algorithmic skills, and is out of scope for this presentation
• The inbound part is the one that defines the protocol (or API, or language) for potential consumers, onto which they can express tailored solutions for their specific problems, based on the reusable code
• Even the best algorithm for a problem is useless if there is no good way to reuse it for your problem instance

So, what is good design?
• A near-optimal balance between:– Expressiveness
• Can I express the problem at hand?
– Flexibility• Can I modify critical parts of an algorithm?
– Or these parts are hidden inside methods I can’t replace?
– Simplicity• Can I express only the problem at hand, and not
irrelevant (to me, the consumer) details?

Making an algorithm reusable
• Consider this code:• Assume we’ve
written many times such code. Then, we can observe that:– These parts are
recurring
– These are problem specific (i.e., not recurring)

Case-specific (variable) code abstracted away with the use of an interface.
Non-reusable method (details that could change are mixed with algorithm)

Resulting client code
• But this is not usable if the client needs to access the actual PreparedStatement object, or wants to use, say, a Set instead of a List.
• Flexibility comes with a cost (extra types/methods/complexity), even if one is not using it.
• There is no “best” design, unless there is a single, very well known set of usage patterns, with known relative frequency of each usage
•This is an improvement over the initial version, as now similar functions can be expressed more simply.

What’s the big difference?
• With lower-level APIs, you are usually able to tweak every little detail (e.g. Swing, JDBC).
• You gain flexibility, but at what price?– If you don’t use it (i.e., most of the times, you don’t care about
each and every detail you can tweak), you have to repeat code, and state, over and over again, that “I want this also this way”
• Because the framework can’t just assume you do
• If you can define the amount of flexibility you need, you can get away with being much more productive, with a higher-level API
• If the higher-level API allows to short-circuit it and use a lower-level API when needed, you can gain the best of both

Is that all?
• Erasure of duplications is an important part of design work (as it identifies the more used parts from the more case-specific), but far from all of it
• Typical design problems:– What methods do I need?– What parameters, of what type?– In what classes or interfaces?
• Goal: capture in the design the granularity upon which you need to express problem solutions
• An efficient answer to these, may not reduce code as drastically as erasure of duplications, but can provide the following qualities:– Less error prone code written against it– Less time spent searching the API– Simpler client code

Controlling complexity
• Complexity is the short term for: “too much information, can’t find what I’m looking for”
• If I need to implement an algorithm that relies on some specific methods, whatever else I see besides those methods are noise, or distractions
• Noise slows down API navigation, i.e. makes it harder to locate the methods you need
• How to keep the noise at a low level? Two answers:– Encapsulation

Encapsulation (aka Information hiding)
• The major culprit that flies in the face of encapsulation today in Java development is public getters
• Do not start writing a class by exposing its fields; later is much harder to hide that information back– Admittedly, it is understandable to start out this way
when the class is needed for UI reporting or persistence– At least strive to make them immutable, then!
• It is easier later to expose more information than hide; and, hopefully, in the process you internalized operations in the class that would be scattered across the code base otherwise

Information hiding
• A related rule is stated:– Move operations close to their data
• For example, if you return a value, that you know the user will use with one of N methods, consider returning an interface which provides those exact methods
• Then, the user will find the available methods at his fingerprints!
• This technique can significantly reduce time spent by the user of the API navigating javadocs
• Concrete example follows

Instead of adding a getter method
• “Why do I need it?”– Most of the cases, in
order to do some processing
• For example:• It seems I should add a
getAge() method, but in this simple example it is easy to move this method in User class…

Another example
• Consider this code… If the user is only
going to use MyValue to either call m2 or m3 (or any known closed set of methods), why not provide him directly these methods instead?
• As a bonus, IDEs can be really generous then…

Implications
• This means more work for the designer– Instead of simply return
data, and place the burden of moving that around to the client, return operations along with (properly encapsulated) data
• Makes client code much easier and effortless, especially when you can predict what are client’s more common uses
• Usually client code is more, so lowering that burden matters more!

Lets try a visual design experiment
• A program can be conceived as a graph• Lets define a procedural program graph, and see
what gains can we obtain by applying OOP techniques
• Participants:– Datum (an abstract data type)– Method
• A method takes datums as input,and returns one datum as output, from some options
• An example of a method with two inputsand two possible outputs
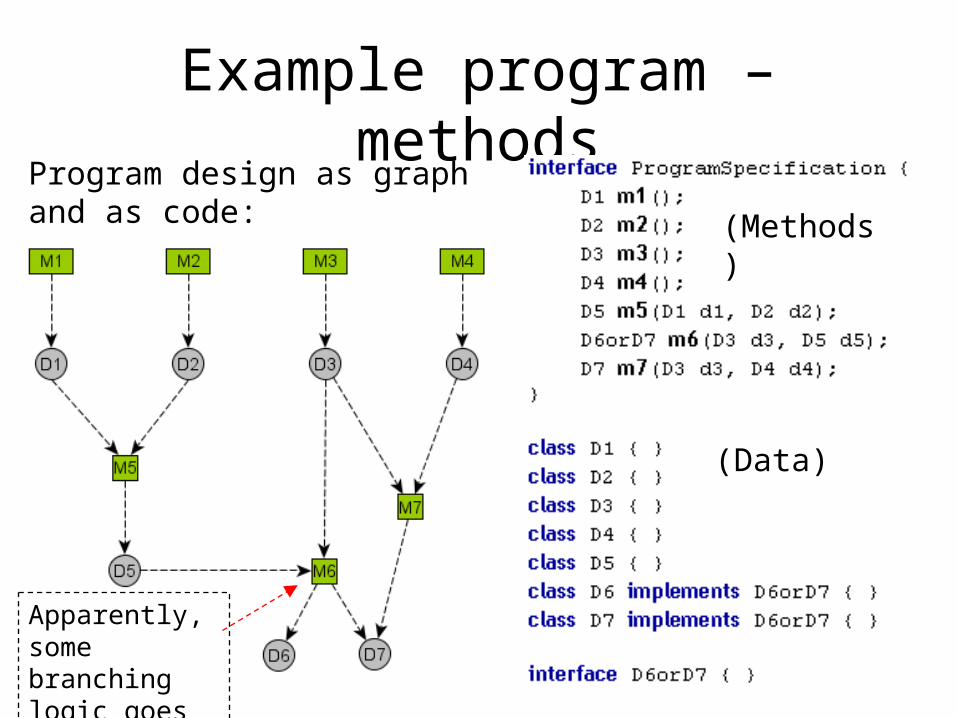
Example program – methodsProgram design as graph and as code:
(Data)
(Methods)
Apparently, some branching logic goes on here
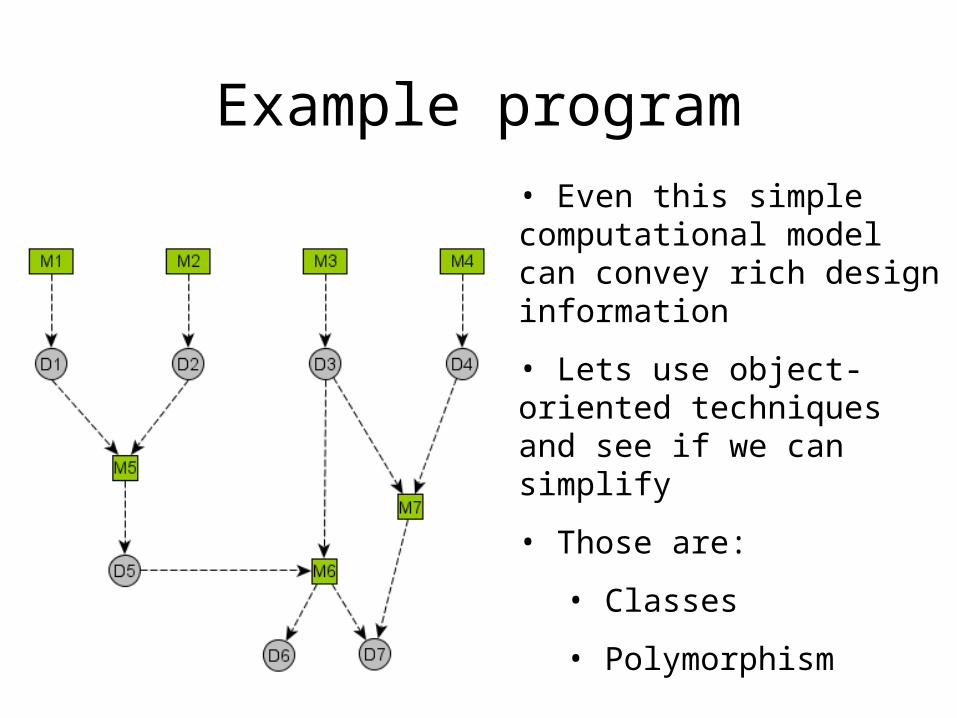
Example program• Even this simple computational model can convey rich design information
• Lets use object-oriented techniques and see if we can simplify
• Those are:
• Classes
• Polymorphism
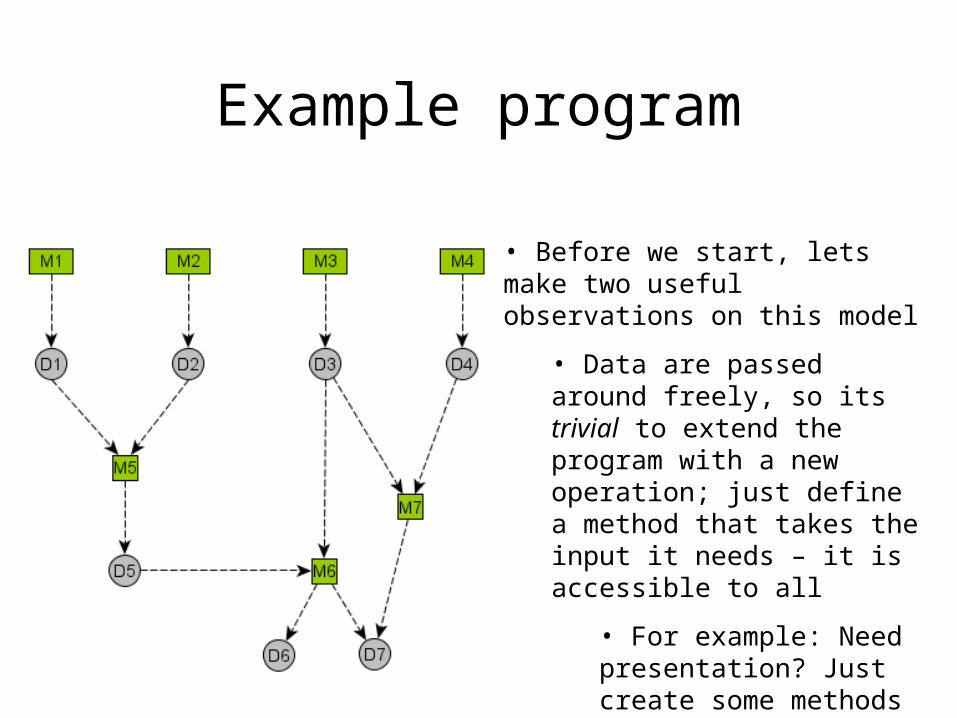
Example program
• Before we start, lets make two useful observations on this model
• Data are passed around freely, so its trivial to extend the program with a new operation; just define a method that takes the input it needs – it is accessible to all
• For example: Need presentation? Just create some methods that take as input the appropriate data to present
• Or persistence, or other layer
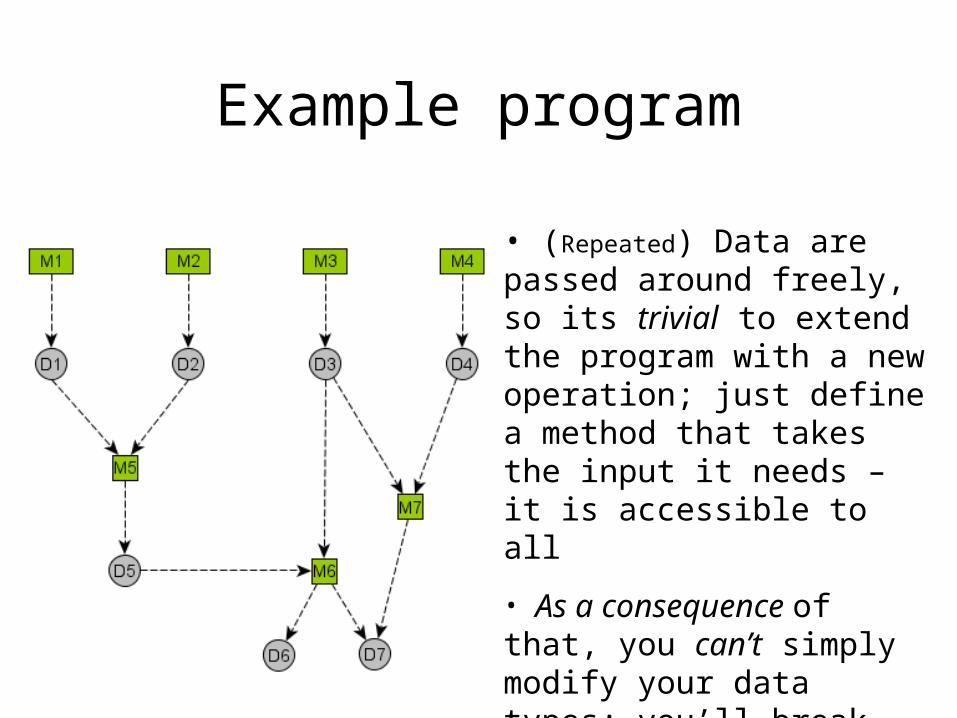
Example program
• (Repeated) Data are passed around freely, so its trivial to extend the program with a new operation; just define a method that takes the input it needs – it is accessible to all
• As a consequence of that, you can’t simply modify your data types; you’ll break any method depending on them
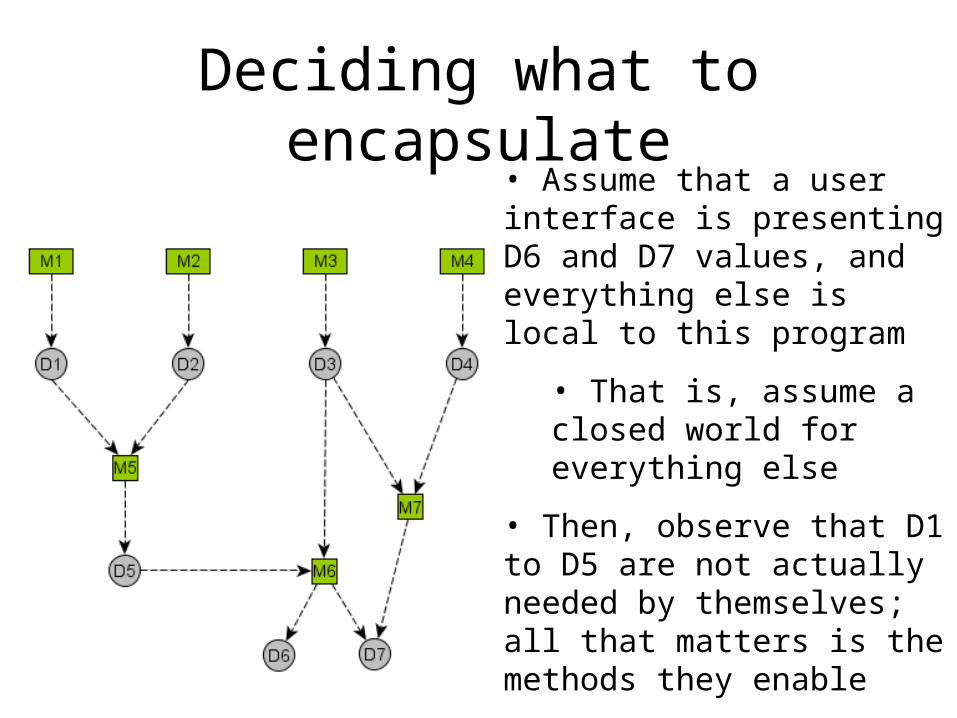
Deciding what to encapsulate• Assume that a user interface is presenting D6 and D7 values, and everything else is local to this program
• That is, assume a closed world for everything else
• Then, observe that D1 to D5 are not actually needed by themselves; all that matters is the methods they enable
• But they are still useful as types, so you know how you can proceed
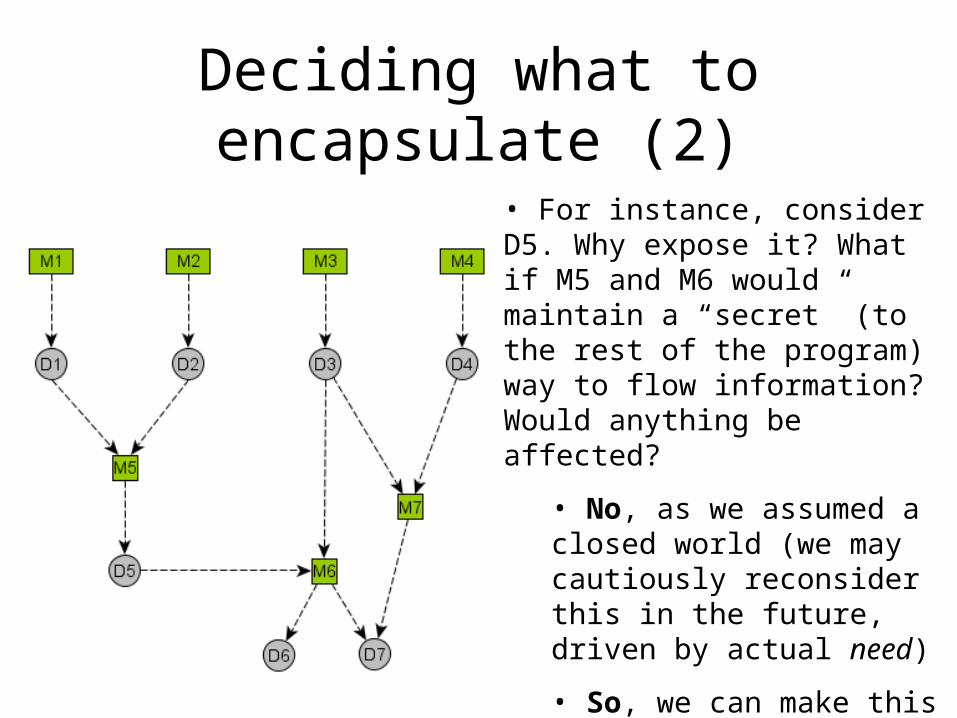
Deciding what to encapsulate (2)
• For instance, consider D5. Why expose it? What if M5 and M6 would maintain a “secret” (to the rest of the program) way to flow information? Would anything be affected?
• No, as we assumed a closed world (we may cautiously reconsider this in the future, driven by actual need)
• So, we can make this information local, and not pollute the rest of the program with unneeded information
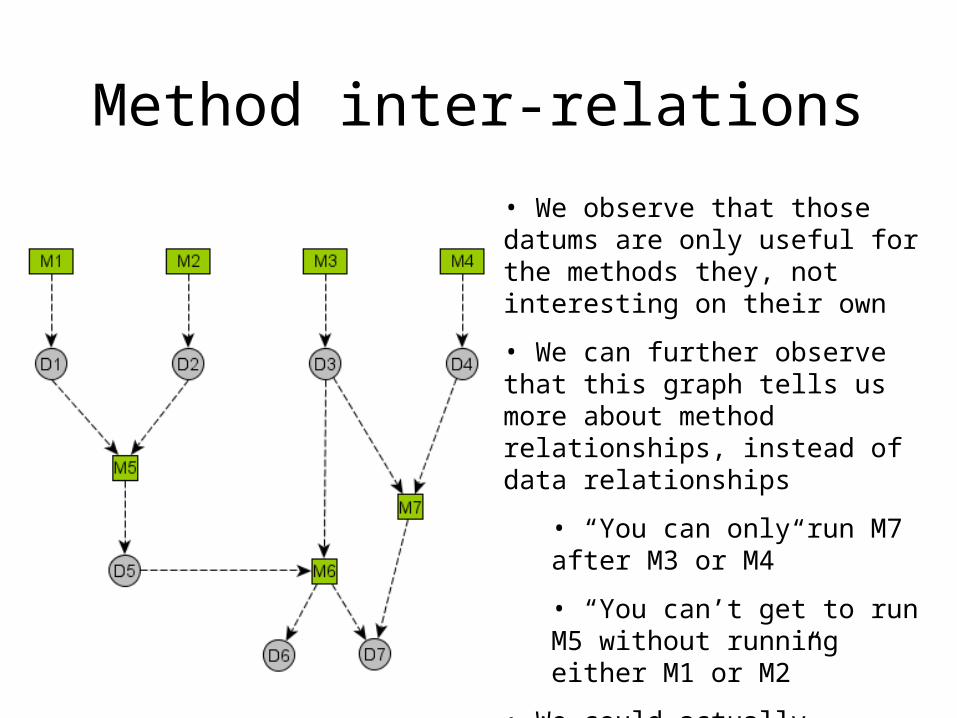
Method inter-relations
• We observe that those datums are only useful for the methods they, not interesting on their own
• We can further observe that this graph tells us more about method relationships, instead of data relationships
• “You can only run M7 after M3 or M4”
• “You can’t get to run M5 without running either M1 or M2”
• We could actually construct the graph by a set of such rules
• It is valuable to take note of such order relationships while designing
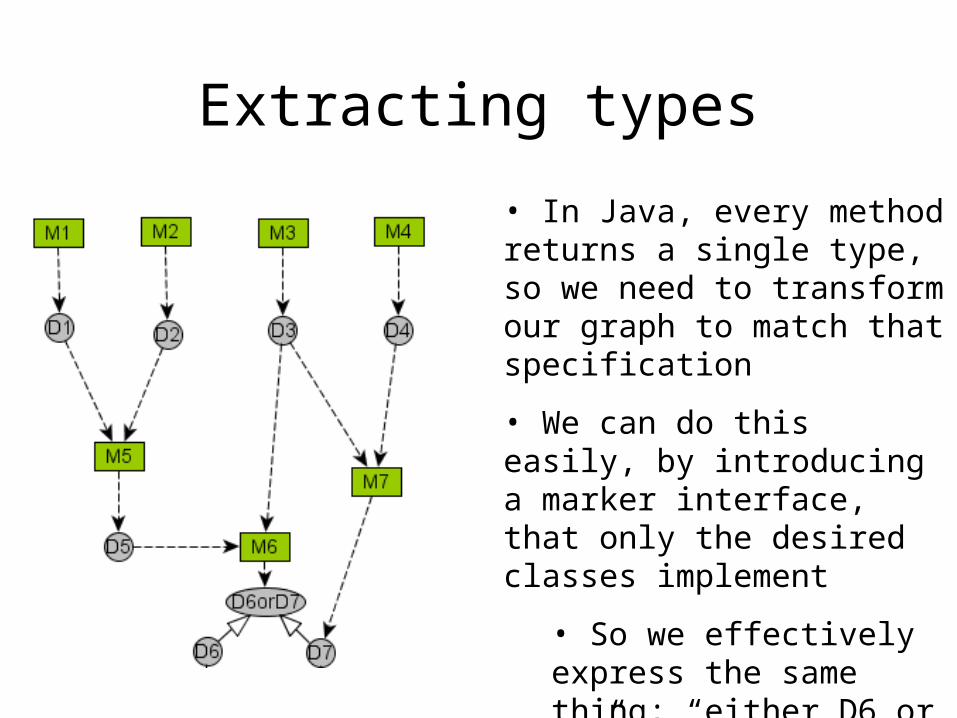
Extracting types
• In Java, every method returns a single type, so we need to transform our graph to match that specification
• We can do this easily, by introducing a marker interface, that only the desired classes implement
• So we effectively express the same thing; “either D6 or D7”
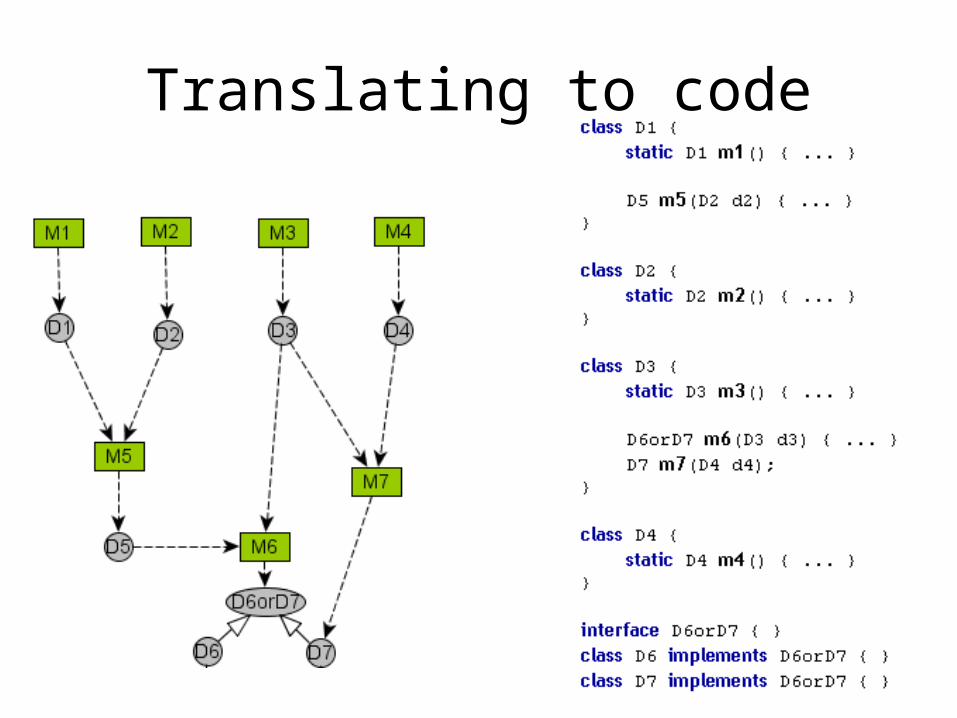
Translating to code
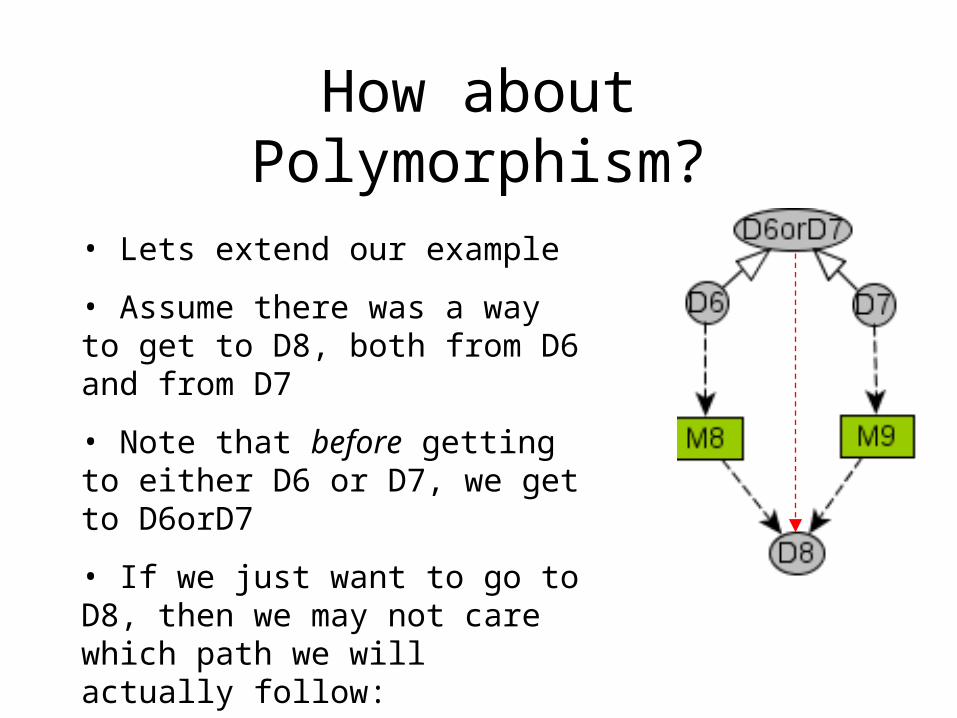
How about Polymorphism?
• Lets extend our example
• Assume there was a way to get to D8, both from D6 and from D7
• Note that before getting to either D6 or D7, we get to D6orD7
• If we just want to go to D8, then we may not care which path we will actually follow:

PolymorphismThe respective code:
Polymorphic method invocation:
Please prefer this !
Non-polymorphic

Assigning methods to objects
• Should this be mapped toD1.m5(D2)? OrD2.m5(D1)?
• Choosing what object plays therole of “this” is not easy
• As “this” decides the hierarchy upon the method is dispatched, an informed proposal would be:– The object which it’s prime concern is most related to
the method, should adopt it. That is, the concern that is the most probable reason for the object to change in the future
– (Assuming D1.m5(D2)) So, this choice enables an easy migration in the future to a hierarchy of types rooted at D1, instead of having just a single concrete class D1

In retrospect
• Instead of focusing separately to data and operations, we merged them to objects
• We strived for a better collocation of operations and their data they depend upon– So, we had more opportunities for
encapsulation, and reducing the visible information flow of the program
• Moved methods closer to where we need them, so less time spent on API searching – more time to code!

Interesting APIs to See Also
• JMock framework– Nice navigational (or fluent) API for declaring
test specifications
• Hibernate’s Criteria API– A nice mapping of SQL clauses in object-
oriented types

…Any Questions?
Thank you!






![Eleni Andreou -2.12.16 last [Compatibility Mode]](https://static.documents.pub/doc/80x56/586b5b4d1a28abba488b4908/eleni-andreou-21216-last-compatibility-mode.jpg)










