36
May 19, 2003 1 Analysis and Evaluation of a Native XML Database Kenneth H. Wenker, Ph.D. May 19, 2003 Dr. C. Edward Chow, Advisor University of Colorado, Colorado Springs
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 213 times |
| Download: | 0 times |

May 19, 2003 1
Analysis and Evaluation of a Native XML Database
Kenneth H. Wenker, Ph.D.
May 19, 2003
Dr. C. Edward Chow, Advisor
University of Colorado, Colorado Springs

May 19, 2003 2
Outline of the Presentation
1. The nature of this masters project
2. XML and databases
3. NeoCore XML database architecture
4. Testing architecture
5. Testing results
6. Conclusion

May 19, 2003 3
PART 1:
The nature of this masters project

May 19, 2003 4
Goals of the Master Project
• To analyze and explain some significant architectural features of the NeoCore XML database, specifically those that have been patented and are therefore public
• To test the performance of those features as they have been implemented in v. 2.6 for Windows
• To create benchmarks for evaluating the XML database performance

May 19, 2003 5
PART 2:
XML and databases

May 19, 2003 6
What is an XML Database?• information = data + context• THE CHALLENGE: with XML, not only the data, but
also the context, can vary. XML is inherently extensible.• A traditional RMDBS is not inherently extensible.• An “XML-enabled” database is an RMDBS which has
been modified in an attempt to handle XML extensibility.• XML-enabled databases need to deal with both storing and
reconstructing the tag structure.• A “native XML database” is specifically designed to
process XML documents efficiently– Tamino: must provide some sort of structure definition– dbXML: weak doing updates and inserts

May 19, 2003 7
USES FOR AN XML DATABASE
• e-commerce—since we are frequently using XML to transport data, it would be efficient to store it that way, provided we can store it, manipulate it, and retrieve it easily.
• When the tag structures are frequently and unpredictably changing, as in, for example, DNA research.
• When the tag structures are more important than the data, as in (perhaps) a next-generation search engine.

May 19, 2003 8
XML Database Benchmarks
• No authoritative group has recognized any benchmark for XML databases
• There are five academic benchmarks– The Michigan Benchmark (Univ. of Michigan)– XOO7 (Nat’l Univ. of Singapore)– XBench (Univ. of Waterloo, Canada)– XMach1 (Univ. of Leipzig)– XMark (National Research Institute for Mathematics and
Computer Science in the Netherlands)• The Michigan Benchmark is designed to allow developers to tune
databases. The others are usable for this project.• None of them provides an adequate test of extensibility, in my
opinion. The extensibility they allow is within the bounds of predefined schema.

May 19, 2003 9
XOO7 BENCHMARK• Document Structure:<Module>
<Manual>Text of Configurable Length</Manual><ComplexAssembly>
<ComplexAssembly><BaseAssembly>
<CompositePart><Document>Text of Configurable Length</Document><Connection>
<AtomicPart>
• Typical Configuration File:NumAssmPerAssm 3NumCompPerAssm 3NumCompPerModule 50NumAssmLevels 5NumAtomicPerComp 200NumConnPerAtomic 3DocumentSize 1000ManualSize 3800

May 19, 2003 10
PART 3:
NeoCore XML database architecture

May 19, 2003 11
CLIENT/SERVER OVERVIEW
CLIENT
Console (runs on client’s browser)
Used for administrationUsed for manual input
API
C++, Java,VB, .COM,or create your own HTTP
UserApplication
SERVER
HTTP
HTTP
NeoCore XMS
DB

May 19, 2003 12
OVERVIEW OF NEOCORE STORAGE ARCHITECTURE
Icon Gene-rator
Set of Indices MapStore
Tag Dictionary
Data Dictionary
Figure 2-2. Overview of NeoCore Database Architecture

May 19, 2003 13
THE “ICON”• It is a transform of a string of indefinite length to a n-bit
binary number.
• Similar to a hash or CRC code.
• The width of the icon is typically 64 bits. The first part of the icon, depending on the number of rows in the index, is used to specify which row of an index is to be accessed. The rest is used as a “confirmer” to be explained shortly.
• NeoCore uses a patented technique to create the icon: to create a 64-bit icon you would access four 256-row tables and XOR the resultant values. The technique allows processing 32 bits at a time from the input string.

May 19, 2003 14
AN EXAMPLE: 1. The XML Document
<my-phone-book>
<entry>
<name>me</name>
<nmbr>6198654227</nmbr>
</entry>
</my-phone-book>

May 19, 2003 15
AN EXAMPLE: 2. The Data Dictionary
me 6198654227

May 19, 2003 16
AN EXAMPLE: 3. The Tag Dictionary
my-phone-book>entry>name> entry>name> name> my-phone-book>entry>nmbr> entry>nmbr> nmbr>

May 19, 2003 17
AN EXAMPLE: 4. The Map Store
Formatting codes 00000000000003 00000000000003
Formatting codes 00000000000050 00000000000007
May 19, 2003 18
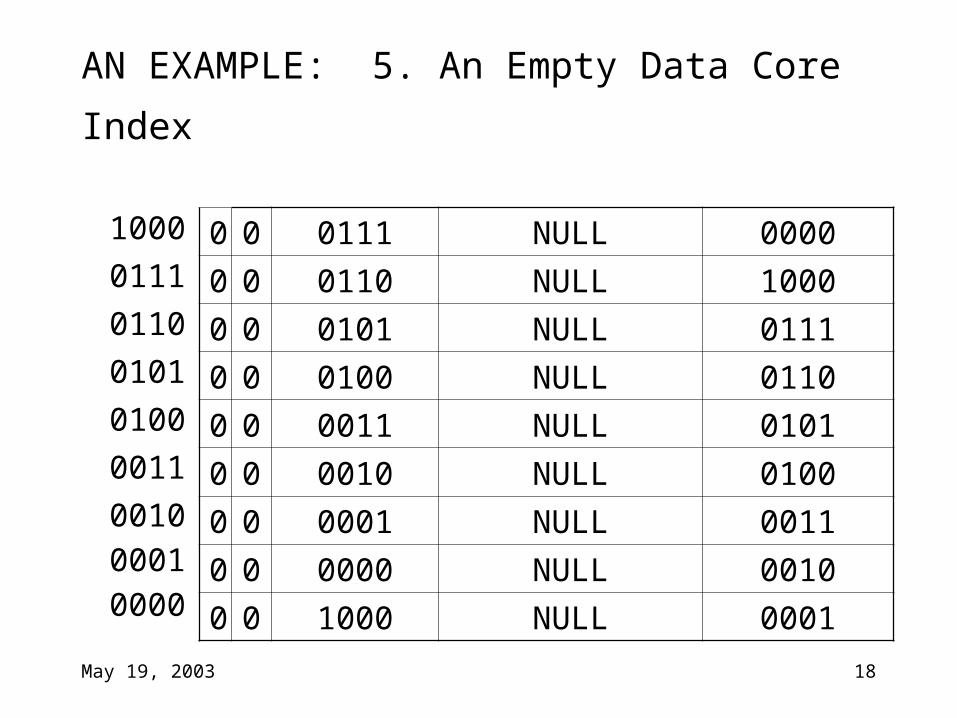
AN EXAMPLE: 5. An Empty Data Core Index
0 0 0111 NULL 0000
0 0 0110 NULL 1000
0 0 0101 NULL 0111
0 0 0100 NULL 0110
0 0 0011 NULL 0101
0 0 0010 NULL 0100
0 0 0001 NULL 0011
0 0 0000 NULL 0010
0 0 1000 NULL 0001
1000
0111
0110
0101
0100
0011
0010
0001
0000

May 19, 2003 19
AN EXAMPLE: 6. The Data Core Index, 1 entry
0 0 0111 NULL 0000
0 0 0110 NULL 1000
0 0 0101 NULL 0111
0 0 0100 NULL 0110
0 0 0010 NULL 0101
1 1 MapStoreLine 1 0101 0011
0 0 0001 NULL 0100
0 0 0000 NULL 0010
0 0 1000 NULL 0001
1000
0111
0110
0101
0100
0011
0010
0001
0000

May 19, 2003 20
AN EXAMPLE: 7. The Data Core Index, 2 entries
0 0 0111 NULL 0000
0 0 0110 NULL 1000
0 0 0100 NULL 0111
1 0 MapStoreLine 2 0010 0011
0 0 0010 NULL 0110
1 1 MapStoreLine 1 0101 0101
0 0 0001 NULL 0100
0 0 0000 NULL 0010
0 0 1000 NULL 0001
1000
0111
0110
0101
0100
0011
0010
0001
0000
May 19, 2003 21
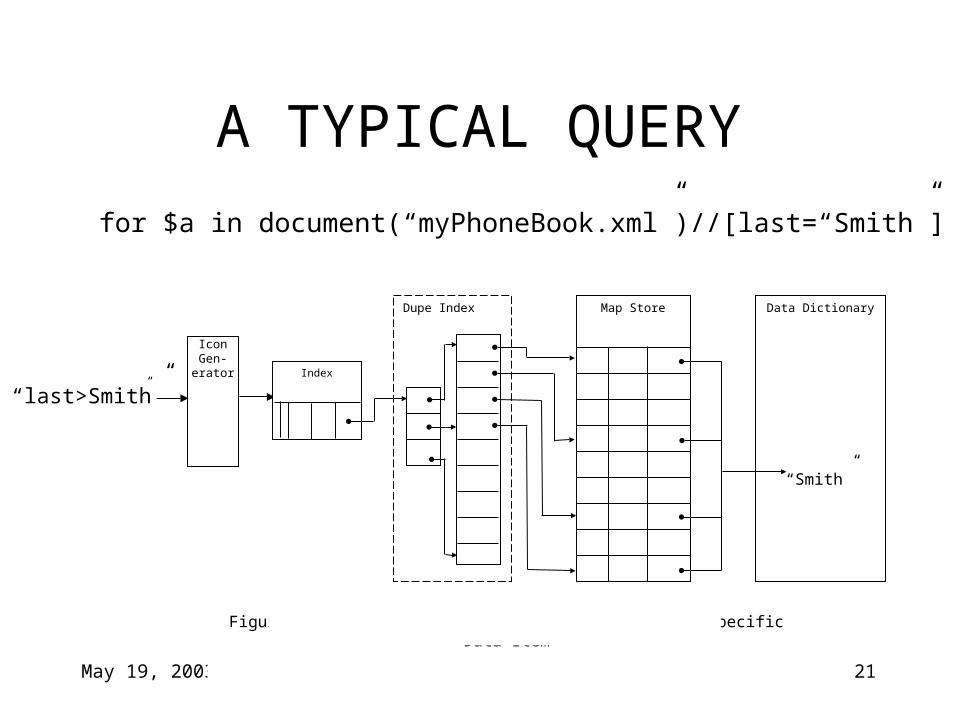
A TYPICAL QUERY
“Smith”
Icon Gen-erator
Index
Dupe Index Map Store Data Dictionary
Figure 6-2. Pointers in the Duplicate Index for a Specific Data Item
“Smith”
for $a in document(“myPhoneBook.xml”)//[last=“Smith”] return count($a)
“last>Smith”

May 19, 2003 22
KEY ARCHITECTURAL INNOVATIONS
• Separate Tag Store and Data Store
• No-string Map Store
• Multi-Table Icon Generator
• 1.5 Look-ups Core Indices
• Use of Duplicate Indices

May 19, 2003 23
PART 4:
Testing architecture

May 19, 2003 24
TESTING PHILOSOPHY
• Interested only in the core database, not in the broader XMS
• For this round of testing, did not evaluate the ability to handle huge amounts of data
• A good test of the NeoCore architecture requires testing it with several different kinds of XML documents, as shown on the next page.

May 19, 2003 25
DOCUMENT TYPES USED
Name Description PurposeAll Dupe
Every tag and data item has same value. Docs have one structure.
Extreme challenge to duplicate indices
Dupe BMarkUse one BMark file. Store it many times.
In case All-Dupe is too extreme for DB to handle, this also challenges dupe index
Single BMarkMake many different BMark files, but use only “small3.config”
This is the kind of document the XOO7 team used for their Benchmark queries.
Multi BMarkMake many different BMark files, using 6 different config files
This is closest to what we would experience in normal business-to-business scenarios.
ExtensibilityEach document has a different tag structure from all others
Verify the database can handle the extensibility that is inherent in XML
No DupeEvery tag name and every data item has a unique value over all docs
Extreme challenge to core indices
TextHuge text surrounded by a single “<text_document>” tag
Challenge icon generator. Do baseline testing on non-indexed string search algorithm.

May 19, 2003 26
TESTING ARCHITECTURECLIENT
Console
NeoCoreAPI
StoreTool
SERVER
HTTP
HTTP
NeoCore XMS
DB
Docu-mentGene-ration
QueryGene-ration
OS File System
KornShell Tools
Query Tool
Client and server were run on the same Dell 350 platform, using Windows XP Professional, a 3.0 GHz CPU, and 1.50 GB of RAM.

May 19, 2003 27
NINE TESTS
1. Disk space used
2. Flattening & restoring
3. Storage speed
4. Query accuracy
5. Query speed
6. Full core-index check
7. Extensibility test
8. Insertion test
9. Non-indexed string searches

May 19, 2003 28
PART 5:
Testing results

May 19, 2003 29
DISK STORAGE USED
0
50
100
150
200
250
300
0 10 20 30 40 50 60 70 80 90 100
Total size of input documents (Megabytes)
Dis
k S
tora
ge
Use
d (
Meg
abyt
es)
0
200
400
600
800
1000
1200
1400
1600
Ext
ensi
bili
ty S
cale
All Dupe
Dupe BMark
Single BMark
Multi BMark
TEXT
Extensibility
Original XOO7 Benchmark Mean Results: approx 3.0:1NeoCore XOO7 Benchmark Results: approx 2.5:1

May 19, 2003 30
Storage Time
• Mean time to store a “small3.config” XOO7 Document was slightly over 21 seconds.
• The XOO7 team reported the time to prepare or convert the XML document so that it could be stored. The mean time for a “small3.config” document was about 5 minutes. They did not report how much time it subsequently took to store the document.
• Our testing: Dell 350, Windows XP Professional, 3GHz CPU, 1.5GB RAM. XOO7 original testing: SunOS 5.7 Unix, 333MHz, 256MB RAM

May 19, 2003 31
QUERY TIME
Query Category
Mean Query Time for NeoCore
Mean Query Time for XOO7
Team
1 317 millisec 20 seconds
2 5.75 sec 65 seconds
3 92 millisec 26 seconds

May 19, 2003 32
FINDINGS--STRENGTHS
• Handles extensibility well—no difference between extensibility documents and XOO7 documents
• Indexed searches very fast (if enough RAM)—almost 300 times faster than the original XOO7 findings for some queries (although some of that difference is due to difference in platform capabilities)
• Disk requirements about the same as needed by the XOO7 team just for their conversion documents
• Efficiency remains even when the core indices are full—effective collision management

May 19, 2003 33
FINDINGS--WEAKNESSES• In some cases, we do not get out exactly
what was put in:– White-Space inaccuracies– Some dropped comments– Some DOCTYPE information is dropped or
enclosed in database-created “<prolog>” tags
• Duplicate indices can be a bottleneck
• Core indices do not scale easily if expansion is needed

May 19, 2003 34
PART 6:
Conclusion

May 19, 2003 35
FUTURE RESEARCH NEEDS• Conduct this testing on a more heavy-duty platform using
more robust data sets.
• Test future releases—3.0 to have significant changes.
• Analyze the patent for new duplicate indices once it is published on the USPTO site.
• Publish an article on the (currently unimplemented) non-indexed substring search algorithm.
• Do the same testing with NeoCore competitors, if they will support it (Tamino would not).
• Publish related articles in IT journals.

May 19, 2003 36
Conclusion• On each key performance indicator the NeoCore XMS is
as good or better than the initial results reported by the XOO7 team.
• It handles the extensibility of XML well—its primary strength.
• To realize full performance, run with enough accessible RAM to hold all indices and still have plenty of room for buffers.
• The NeoCore database remains a work in progress: significant improvements are being planned for future releases.
• Acceptance likely to depend more on the broader management system than on the database at its heart.

















