55
Mining the Biomedical Literature Pengyu Hong State of the Art and Challenges Acknowledgement: Dr. Hagit Shatkay http://www.shatkay.org/
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 218 times |
| Download: | 1 times |

Mining the Biomedical Literature
Pengyu Hong
State of the Art and Challenges
Acknowledgement: Dr. Hagit Shatkay
http://www.shatkay.org/

2
Literature Experiments
e.g., Pathway
+ New Findings
e.g., Microarray

3
gene symptom disease
• Type 2 diabetes• Hypercholesterolemia• Coronary artery
disease• Essential hypertension
Insulin ResistanceTNFRSF1B
Genetic Basis of Disease

4
• Information Extraction• Information Retrieval• Cases• Integrate Text with Other Type of
Data• Conclusion
Overview

5
Automated identification of certain kinds of facts from text.
Information Extraction
Example:
Phosphorylation
Kinase Protein
glycogen synthase kinase-3 (GSK-3) BIN2
BES1
“…BES1 is phosphorylated and appears to be destabilized by the glycogen synthase kinase-3 (GSK-3) BIN2…”

6
Information Extraction
• Identify the relevant sentences
• Parse to extract specific information
• Assume “well-behaved” fact sentences
• Using co-occurrence relationships alone does not require parsing or good fact-structure
Usually it requires

7
Automatically retrieve documents satisfying the information need (Query) from a lot of documents
Information Retrieval

8
Means:
• Boolean query, Index based (e.g. “Gene and CDC”)
Information Retrieval
CD
Chagas' disease
cytosine deaminase
Crohn‘s disease
capillary density
Cortical dysplasia
(54,745 Pubmed entries)
compact disk...
Synonymy (AGP1, aka, Amino Acid Permease1)
Polysemy

9
Means:
• Boolean query, Index based
• Similarity query, e.g., Vector based.
Information Retrieval
Semantic search
TIME (Sept 5, 2005): Search engines are good at matching words … The next step is semantic search – looking for meaning, not just matching key words. … Nervana, which analyzes language by linking word patterns contextually to answer questions in defined subject areas, such as medical-research literature.

10
Both information extraction and information retrieval require to process text and store text and the processed results.

11
Text Processing
• Lexical Analysis: Tokenization, breaking the text into basic
building blocks. (Paragraphs, Sentences, Phrases, Words)

12
The growth-promoting effect of growth hormone (GH) is primarily mediated by insulin-like growth factor-1 (IGF-1). The liver is the main source of circulating IGF-I. The authors have used rodent primary hepatocytes for studies on pharmacological intervention of IGF-I mRNA expression. A 96-well nonradioactive IGF-1 mRNA quantification assay was developed, based on the hybridization of sense and antisense RNA probes, to replicate membranes with crude hepatocyte lysates.
The sense hybridization was used as an internal standard. The antagonistic properties of a set of GH-receptor binding compounds were evaluated. Two compounds were found to down-regulate IGF-I mRNA. Effects due to metabolic inhibition or toxicity were excluded using a cell proliferation assay.

13
Text Processing
• Lexical Analysis: Tokenization, breaking the text into basic
building blocks. (Paragraphs, Sentences, Phrases, Words)
• Parsing/Processing: (Identify Noun-phrases, Verb-phrases,
names and/or other proper nouns, stem)

14
The growth-promoting effect of growth hormone (GH) is primarily mediated by insulin-like growth factor-1 (IGF-1). The liver is the main source of circulating IGF-I. The authors have used rodent primary hepatocytes for studies on pharmacological intervention of IGF-I mRNA expression. A 96-well nonradioactive IGF-1 mRNA quantification assay was developed, based on the hybridization of sense and antisense RNA probes, to replicate membranes with crude hepatocyte lysates.
The sense hybridization was used as an internal standard. The antagonistic properties of a set of GH-receptor binding compounds were evaluated. Two compounds were found to down-regulate IGF-I mRNA. Effects due to metabolic inhibition or toxicity were excluded using a cell proliferation assay.
studystem

15
Text Processing
• Lexical Analysis: Tokenization, breaking the text into basic
building blocks. (Paragraphs, Sentences, Phrases, Words)
• Parsing/Processing:
* Part-of-Speech (PoS) TaggingInitial assignment of syntactic categories to a sequence of words. Categories may include: noun, verb, determiner, adjective, adverb, proper noun, etc.
PoS Tagging Paradigms: • Rule based [Brill 92, Brill 99]• Stochastic [Charniak93, Allan95…]• Supervised vs. Unsupervised [Schütze 93], more…

16
Text Processing
• Lexical Analysis: Tokenization, breaking the text into basic
building blocks. (Paragraphs, Sentences, Phrases, Words)
• Parsing/Processing:
* Part-of-Speech (PoS) Tagging
* Parsing: Complete assignment of syntactic structure to a word sequence. Including: Noun phrase, Verb phrase, Prepositional phrase, etc.
• Full parsing: Full assignment of every word and phrase to a syntactic structure . [e.g. Grishman95]. Slow, and error-prone...• Shallow/Partial parsing: Partial assignment of syntax structures. “… parse conservatively – only if there is strong evidence of the correctness of a reduction.” [Grishman97 ] [Appelt et al. 95, Appelt & Israel 99, Feldman et al. 2000]

17
Text Storage
Support quick access to facts/documents:
Terms/words
Structure
A document
Query is not 1-Dimensional

18
Information Extraction - DetailsExtract what?
• Entities: e.g., genes, proteins, diseases, chemical compounds, etc.
• Relationships: e.g., phosphorylation, activation of a gene by a transcription factor, etc.
• Events: e.g., a protein is activated, a gene is transcribed, etc.
It is hard!• Entities can have synonyms and be referred as anaphora (e.g.,
this gene, that protein, the former, etc.). Unrelated entities may share a name (polysyms).
• Relationships and events can be stated in various styles and indirect ways.

19
Information Extraction – Details (cont.)
Rule-BasedExplicit rules for identifying entities and relations are defined.
Kinase_Related_Activity :- <regulate> <protein> <kinase> <activity>|<activate> <protein> <kinase> |<increase> <rate> <protein> <kinase> <activity>;
Rules can be:
• Hand-coded [e.g. Appelt et al. 95, Hobbs et al. 97]
• Automatically acquired from examples (Supervised learning) [e.g. Riloff 93, Califf 98, Soderland 99]
• Automatically acquired, no examples (Unsupervised learning) [e.g. Yangarber et al. 2000]

20
Information Extraction – Details (cont.)
Statistical Machine-LearningLearn probabilistic models for “typical” sequences denoting entities and relations.
[Bikel et al. 97, Leek 97, Seymore et. al. 99, Ray and Craven 2001]
For every name-class, C, a bi-gram, Markov probability Pc(Wi|Wi-1).
Induces: P(C|W1…Wn) P(W1…Wn|C) = Pc(Wi|Wi-1)
High-level, transition and emission probabilities: P(C| C-1, W-1), P(W | C, W-1 )
start action entity end
Example:
{regulate, activate, increase
……}
{MAPK, MAPKK, MAPKKK
……}
property
{extent, rate,
frequency
……}

21
DB: Database of documents.
Vocabulary: {t1,…,tM } (Terms in DB, produced by the tokenization stage)
Index Structure: A term all the documents containing it.
Information Retrieval – DetailsBoolean Queries
acquired immunodeficiency
asthma
blood
blood pressure
IndexDatabase

22
DB: Database of documents.
Vocabulary: {v1,…,vM } {Terms in DB}
Document dDB: Vector, <w1d,…,wM
d>, of weights.
Information Retrieval – DetailsThe Vector Model
Weighting Principles • Document frequency: Terms occurring in a few documents are
more useful than terms occurring in many.
• Local term frequency: Terms occurring frequently within a document are likely to be significant for the document.
• Document length: A term occurring the same # of times in a long document and in a short one has less significance in the long one.
• Relevance: Terms occurring in documents judged as relevant to a query, are likely to be significant (WRT the query).
[Sparck Jones et al. 98]

23
Some Weighting Schemes:
Binary
TF Wid = fi
d = # of times ti occurs in d.
Wid=
fid
fi
(fi= # of docs containing ti)TF X IDF(one version...)
Information Retrieval - Details(cont.)
Wid =
1 if ti d
0 otherwise
Consider Local term frequency
Consider Local term frequency and Document frequency

24
Document d= <w1d,…,wM
d>DB
Query q = < w1q,…,wM
q> (q could itself be a document in DB...)
Information Retrieval - Details(cont.)
Vector-Based similarity
Sim(q, d) = cosine (q, d )
= q • d
|q| |d|
d
q
[Salton89, Witten et al99] Introductory IR.

25
Information Retrieval - Details (cont.)
[Sparck Jones et al. 98, Sahami98, Ponte&Croft 98, Hoffman 99]
Probabilistic Models
Query q ; Document d
Log[Log[PP(relevant | (relevant | dd, , qq))
PP(Irrelevant | (Irrelevant | dd, , qq))]]Maximize log-odds:Maximize log-odds:
• Goal:Goal: Find all Find all dd’s such that ’s such that PP(relevant | (relevant | dd, , qq) is high) is high

26
Information Retrieval - Details(cont.)
Latent Semantics Analysis [Dumais, Deerwester et al,1988,1990]
Motivation: Overcoming synonymy and polysemy. Reducing dimensionality.
Idea: Project from “explicit term” space to a lower dimension, “abstract concept” space.
Methodology: Singular Value Decomposition (SVD) applied to the document-term matrix. Highest singular values are used as the features for
representing documents.

27
Information Retrieval- Details(cont.)
Text Categorization (semantic)
Automatically place documents in right categories so as to make them easy-to-find.
......
Cancer
Apoptosis Elongation

28
Information Retrieval-Details(cont.)
Rule-Based Text Classification
A knowledge-engineering approach.
Boolean rules (DNF), based on the presence/absence of specific terms within the document, decide its membership in the class. (e.g. the CONSTRUE system [Hayes et al. 90,92] )
Example: If ( (<GENE_Name> ⋀ transcript) ⋁ ((<GENE_Name> Western Blot) ⋀ ⋁ ((<GENE_Name> Northern Blot))⋀ Then GeneExpressionDoc Else Gene⌝ ExpressionDoc

29
Information Retrieval-Details(cont.)
Machine Learning for Text Classification (supervised)
• Take a training set of pre-classified documents
• Build a model for the classes from the training examples
• Assign each new document to the class that best fits it (e.g. closest or most-probable class.)
Types of class assignment:
Hard: Each document belongs to exactly one class
Soft: Each document is assigned a “degree of membership” in several classes

30
Information Retrieval-Details(cont.)
Machine Learning for Text Classification (supervised)
* Training set: pre-classified documents
* Learning task: Infer C from the data
...< , C( )>; < , C( )>; < , C( )>;T=

31
Examples of Supervised Learning methods
• Memorize the classes of all documents• Choose a distance/similarity function between documents• Assign a new document to the class of the closest document
Nearest Neighbor
Main drawback: Does not summarize the data; classification
of a new document can be excruciatingly slow, comparing it against ALL documents in the dataset.

32
Machine Learning Methods for Text Classification
Information Retrieval-Details(cont.)
Builds a class term-weight vector, , summarizing the document vectors in the class (and those not in it). Assigns new document vector , to class
C
d
)],([argmax dCcosc
C
Rocchio (1971)
[Rocchio71, Buckley et al. 94, Lewis et al. 96, Joachims97, Schapire et al. 98]

33
Naïve Bayes Classifier
• Assumes conditional independence among features, given the class
• Builds for each class, C, a term distribution model, CM
• Assigns new document d’ to class C’ s.t.
Using Bayes’ rule and the “Naïve” assumption:
CM : <P(t1d|d C), P(t2d|d C),…, P(tnd|d C)>
(where: d – document, ti –term)
P(CM | d’) = P(d’|CM) P(CM )
P( d’ )= kP(d’|CM)= k P(tid|d CM )∏
ti d’
[McCallum& Nigam 99]
)]|'([argmax' CC
M
MdPC

34
Machine Learning Methods for Text Classification (cont.)
Information Retrieval-Details(cont.)
[Joachims 98, Yang and Liu 99, Yang 2001, Schapire et al.98]
Partitions the training documents by a maximum-margin hyperplane.Classifies new document-vector, , based on its position WRT the separating hyperplane.
d
Support Vector Machine
Boosting/Mixtures
Combines multiple weak classifiers.

35
Evaluating Extraction and Retrieval
To say how good a system is we need:
1. Performance metrics (numerical measures)
2. Benchmarks, on which performance is measured (the gold-standard).

36
Evaluating Extraction and Retrieval(cont.)
Performance Metrics
N items (e.g. documents, terms or sentences) in the collection
REL: Relevant items (documents, terms or sentences) in the collection.These SHOULD be extracted or retrieved.
RETR: Retrieved items (e.g. documents, terms or sentences) are actually extracted/retrieved
Some correctly (A = |REL ⋀ RETR|),Some incorrectly (B = |RETR – REL| )
|RETR| = A+B

37
Evaluating Extraction and Retrieval(cont.)
Performance Metrics (cont.)
|RETR – REL| = B
Collection
REL RETR
|REL RETR| = ⋀ A
|Collection| = N
|REL-RETR| = D
|NotREL – RETR| = C

38
Performance Metrics (cont.)
Precision: P = A/(A+B) How many of the retrieved/extracted items are correct
Recall: R = A/(A+D)How many of the items that should be retrieved are recovered
Accuracy: (A+C)/N (Ratio of Correctly classified items)
F-score: 2PR / (P+R)Harmonic mean, in the range [0,1]
Combination Scores:
Fβ-score: (1+β2)PR / (β2·P + R)
β >1 Prefer recall, β <1 Prefer precision
E-measure: 1 – F(β)-scoreInversely proportional to performance (Error measure).

39
Performance Metrics (cont.)
Precision-Recall Curves
4 relevant documents in the collection.
7 retrieved and ranked.
1
7
6
5
4
3
225% Recall
50%
75%
100%
6675
66
100
0102030405060708090
100
0 25 50 75 100
Recall
Pre
cisi
on

40
Performance Metrics (cont.)
Average ScoresAverage Precision: Average the precision over all the ranks in which a relevant document is retrieved.
Mean Average Precision: Mean of the Average Precision over all the queries.
Micro-Average: Average over individual items across queries
Macro-Average: Average over queries
For a given rank n, Pn: Precision at rank n (P@n)
R-Precision: PR where R is the number of relevant documents
Accounting for Ranks

41
Overview
• Information Extraction• Information Retrieval• Cases• Integrate Text with Other Type of
Data• Conclusion

42
T. Leek, MSc thesis, 1997 [Leek97]
Information Extraction
•Gene localization on chromosomes.
Example: Gene: HKE4 located on Chromosome: 6.
•HMMs characterize sentences describing localization relationships.
•Gene names and Chromosomes are identified through heuristics.
•Words denoting location (e.g. mapped, located, discovered) and methods (e.g. southern, blot) are pre-defined.
•Trained and tested on sentences from OMIM abstracts.
•Scored based on correct population of the relation slots.
method1
start
method2verb1 verb2Gene Chrom
end
“Southern analysis shows that HKE4 is located on human chromosome 6.”

43
M. Craven et al [Craven&Kumlien99, Ray&Craven01, Skounakis,Craven&Ray03]
•Protein sub-cellular localization and gene-disorder associations.
Examples: Protein: Enzyme UBC6 localized to Endoplasmic Reticulum.
Gene: PSEN1 associated with Alzheimer Disease
•HMMs (and their extensions) characterize sentences describing sub-cellular localization, and disease association.
(Other models for sub-cellular localization in [Craven&Kumlien99])
•HMMs’ states represent structural segments (e.g. NP_segment)
•Training: Sentences whose gene/protein/location/disease words are tagged, based on information from YPD and OMIM.(Protein and localization lexicon was provided in [Craven&Kumlien99])
•Scored on correct classification of relevant/irrelevant sentences.
Information Extraction (cont.)

44
Information Extraction (cont.)
•Protein-protein interactions.
Example: Protein: Spatzle Activates Protein: Toll
•Based on co-occurrence of the form “... p1...I1...p2...” within a sentence, where p1, p2 are proteins and I1 is an interaction term.
•Protein names and interaction terms (e.g. activate, bind, inhibit)are provided as a “dictionary”.
•Does not use formal modeling or machine-learning.
•Applied to two systems in Drosophila:
The Pelle system (6 proteins, 9 interactions) and
The cell-cycle control system (91 proteins), without quantitative analysis of the results.
A. Blaschke, A. Valencia et al,1999

45
•Gene-gene relations.
Example:
•Based on co-occurrence of the form “... g1...g2...” within a Pubmed abstract, where g1, g2 are gene names.
•Gene names are provided as a “dictionary”, harvested from HUGO, LocusLink, and other sources.
•Does not use formal modeling or machine-learning.
•Applied to 13,712 named human genes and millions of PubMed abstracts (Most extensive!)
•No extensive quantitative results analysis.
Information Extraction (cont.)
T. Jenssen, E. Hovig et al, 2001 (PubGene)
NR4A3NR4A2
[Pearson01] Discussion of this approach.

46
•Fukuda et al: PROPER. Rule-based (hand-coded); Identifies protein and domain names, without a dictionary. Tested on two sets of 30 and 50 domain-specific abstracts; 93-98% recall, 91-94% precision.
•Krauthammer et al: Uses gene/protein name dictionary, extracted from GenBank;Encodes text and dictionary as nucleotide sequences, and matches text to the dictionary using BLAST.
Tested on 1, full-text, review article (1162 gene/protein occurrences);78.8% recall, 71.7% precision.
Information Extraction (cont.)
Extracting Gene and Protein Names [Fukuda et al 98, Krauthammer et al 00, Tanabe&Wilbur 02, Hanisch et al 03]

47
•Tanabe&Wilbur: ABGene. Retrain Brill POS tagger, (on 7000 hand- tagged sentences from Medline abstracts), to identify a
new tag Gene. Augment with rules to eliminate false positives and recover false- negatives. Use a Naïve Bayes classifier (IR), to rank documents by likelihood to contain genes/proteins.
Tested on 56,469 Medline abstracts;Results for low-scoring documents, Precision <66% Recall <60%;for high-scoring gene-documents: Precision >85%, Recall >70%.
•Hanisch et al: Built a dictionary of ~38,000 proteins, and ~152,000 synonyms, combining multiple resources (OMIM, Swissprot, HUGO) and pruning/cleaning process. Extraction uses the dictionary and a scoring+optimization method to do better than naïve pattern matching.
Tested over 470 abstracts with 141 proteins occurring in them;Best case recall 90%, precision: 95%.
Extracting Gene and Protein Names (Cont.)
[Schwartz&Hearst PSB03, BioCreative04, Mika & Rost ISMB04]

48
Information Extraction (cont.)
Fish Oil
Blood Viscosity
Platelet aggregability
Vascular Reactivity Reduces(and co-occurs)
Raynaud’s Syndrome
Increased(and co-occurs)
Fish OilRaynaud’s Syndrome
•Based on transitivity of relationships in co-occurrence graph.
•This idea can be used to discover new facts by co-occurrence
[Swanson 86,Swanson87,Swanson90, Swanson and Smalheiser99, Weeber et al. 2001, Stapley & Benoit 2000, Srinivasan 2003, Srivinasan 2004]
Can Reduce

49
Information Retrieval (cont.)
Finding Protein-Protein-Interaction Abstracts [Marcotte et al., 01]
Yeast Medline(YM)665,807 abstracts
260 Protein-Protein Interaction (PPI) abstracts
Find Discriminating Words (DW) Pr(wA| AYM) != Pr(wA| A PPI)
A
Abstract
Naïve Bayes Classifier
APPI
APPI
Reaches about 65% precision at 65% recall on a set of 325 abstracts.
Train
50
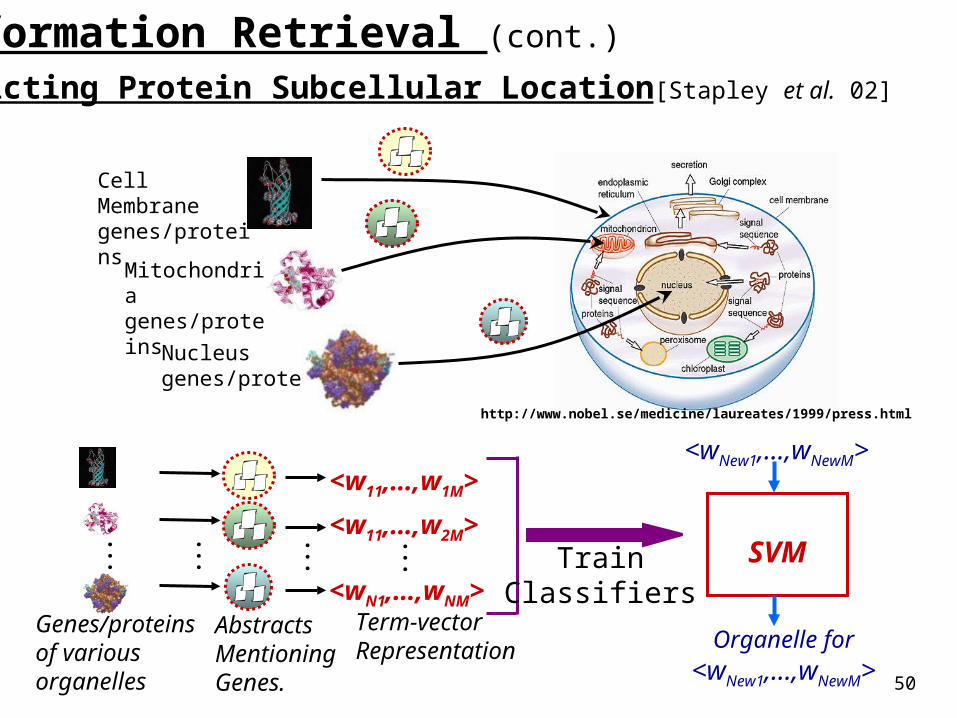
Predicting Protein Subcellular Location[Stapley et al. 02]
Information Retrieval (cont.)
http://www.nobel.se/medicine/laureates/1999/press.html
Genes/proteins of various organelles
...
AbstractsMentioning Genes.
......
<w11,…,w1M>
<w11,…,w2M>
<wN1,…,wNM>
...
Term-vector Representation
TrainClassifiers
SVM
<wNew1,…,wNewM>
Organelle for <wNew1,…,wNewM>
Mitochondria genes/proteins
Nucleus genes/proteins
Cell Membrane genes/proteins

51
Overview
• Information Extraction• Information Retrieval• Cases• Integrate Text with Other Type of
Data• Conclusion

52
Protein Homology by Sequence and Text [Chang et al. 01]
Integrate Text with Other Type of Data
P1 V G A H …P2
V G A N …P3
V E A D …P4
V N A N …
Find sequence homologyusing Psi-Blast, multiplealignment.
T2
T3
T4
T1
Create“documents” from all text associated with each protein (annotations and abstracts)
Find text similarity
Discard alignments with low document similarities.Create profile.

53
Gene Clustering by Expression and Text [Glenisson et al. 03,04]
Integrate Text with Other Type of Data
Find pair-wise dissimilarity between expression profiles
T2
T3
Tn
T1
Find pair-wise dissimilarity in text
Combine into a single gene-dissimilarity measure
G1
G3
G2
Gn
...
Create text-vectors based on all the abstracts curated for the genes (in SGD)
Hierarchically cluster the genes
......

54
Conclusion
Information Retrieval:• Looks for relevant documents• Does not give a tidy fact statement (Coarse granularity)• Can find relations among documents or document collections• Can create a coherent context for performing Information Extraction• Can foreshadow putative, yet-undiscovered relationships• Less sensitive to vocabulary and terminology
Information Extraction:• Extracts well-defined facts from the literature• Requires domain vocabulary or rules to identify these facts• Finds explicitly stated facts• Looks for facts stated within a sentence, a paragraph or a
single document (Fine granularity)

55
Conclusion
• Reduce dependency on vocabularies and nomenclature• Automate fact-finding about gene-disease interaction• Reconstruct metabolic, signaling or regulatory pathways• Integrate literature analysis with the analyses of large-
scale experimental data. A combined approach is likely to get us closer to our goal
Challenges:

















