76
NoSQL Hbase, Hive and Pig, etc. Adopted from slides By Ruoming Jin, Perry Hoekstra, Jiaheng Lu, Avinash Lakshman, Prashant Malik, and Jimmy Lin
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | rosamund-gilmore |
| View: | 222 times |
| Download: | 3 times |

NoSQLHbase, Hive and Pig, etc.
Adopted from slides By Ruoming Jin, Perry Hoekstra, Jiaheng Lu, Avinash
Lakshman, Prashant Malik, and Jimmy Lin

Outline
• Column Store• Basic Concept
– Distributed Transaction Processing– CAP
• NoSQL systems• Summary

An invention in 2000s:Column Stores for OLAP
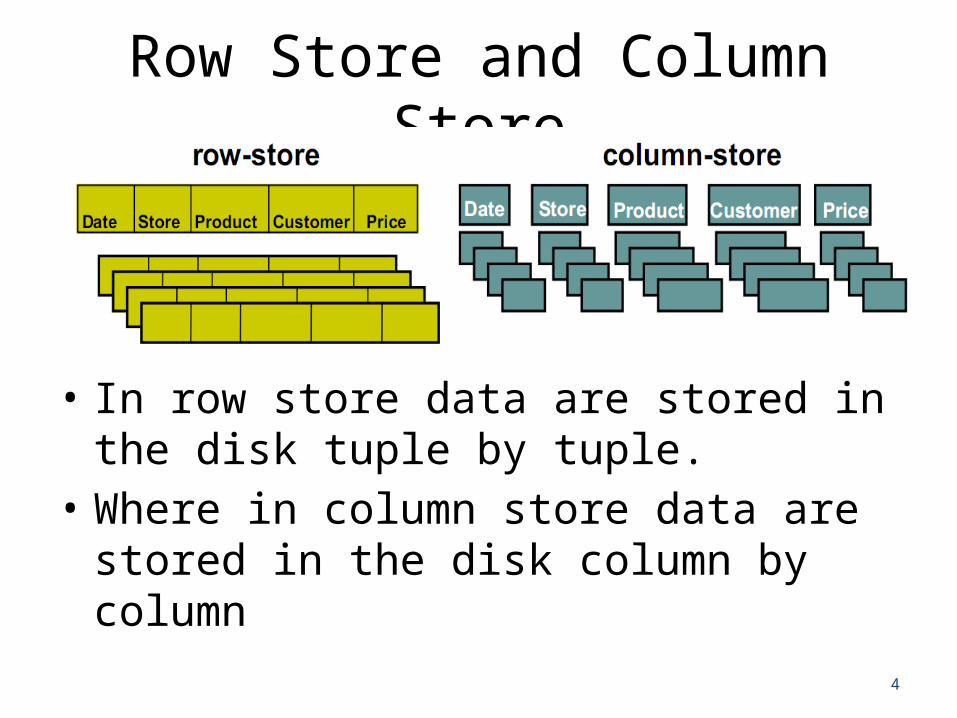
Row Store and Column Store
• In row store data are stored in the disk tuple by tuple.
• Where in column store data are stored in the disk column by column
4

Row Store vs Column Store
IBM 60.25 10,000 1/15/2006
MSFT 60.53 12,500 1/15/2006
Row Store:
Used in: Oracle, SQL Server, DB2, Netezza,…
IBM 60.25 10,000 1/15/2006
MSFT 60.53 12,500 1/15/2006
Column Store:
Used in: Sybase IQ, Vertica

Row Store and Column StoreFor example the query
SELECT account.account_number, sum (usage.toll_airtime), sum (usage.toll_price)FROM usage, toll, source, accountWHERE usage.toll_id = toll.toll_idAND usage.source_id = source.source_idAND usage.account_id = account.account_idAND toll.type_ind in (‘AE’. ‘AA’)AND usage.toll_price > 0AND source.type != ‘CIBER’AND toll.rating_method = ‘IS’AND usage.invoice_date = 20051013GROUP BY account.account_number
Row-store: one row = 212 columns!Column-store: 7 attributes
6

Row Store and Column Store
• So column stores are suitable for read-mostly, read-intensive, large data repositories
Row Store Column Store
(+) Easy to add/modify a record (+) Only need to read in relevant data
(-) Might read in unnecessary data (-) Tuple writes require multiple accesses
7

Column Stores: High Level
• Read only what you need
• “Fat” fact tables are typical
• Analytics read only a few columns
• Better compression
• Execute on compressed data
• Materialized views help row stores and
column stores about equally

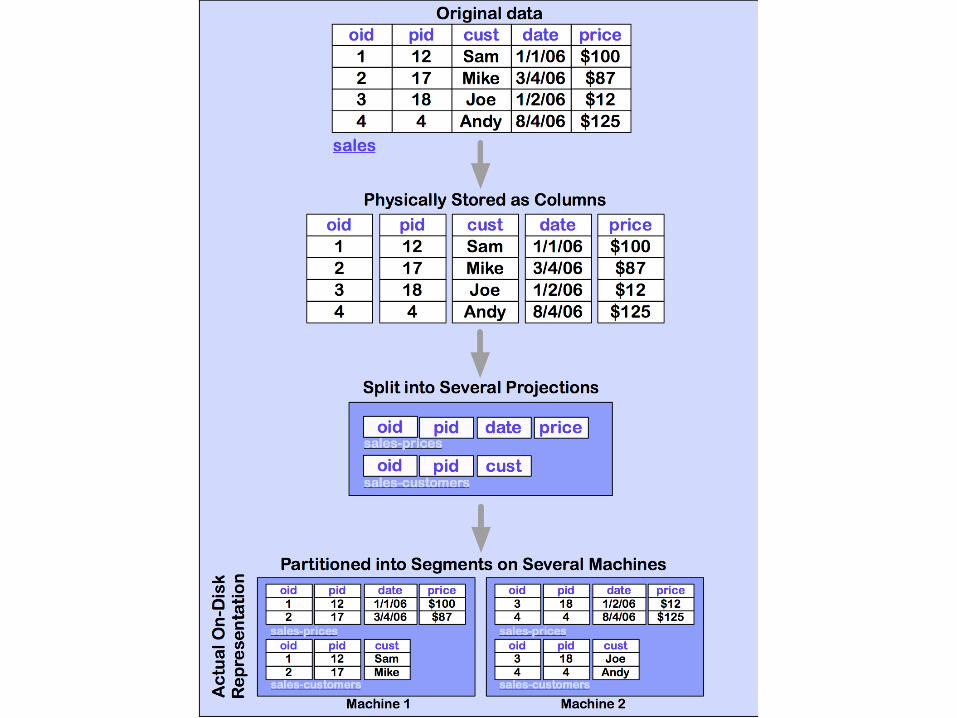
Data model (Vertica/C-Store)
• Same as relational data model– Tables, rows, columns– Primary keys and foreign keys– Projections
• From single table• Multiple joined tables
• ExampleEMP1 (name, age)EMP2 (dept, age, DEPT.floor)EMP3 (name, salary)DEPT1(dname, floor)
EMP(name, age, dept, salary)DEPT(dname, floor)
Normal relational model
Possible C-store model
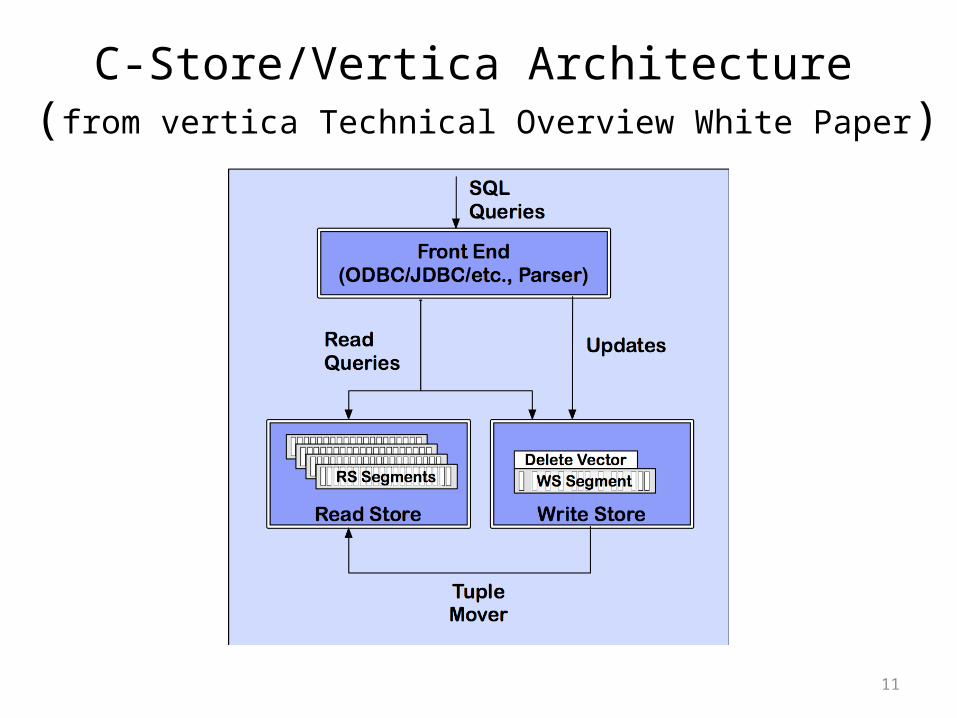
C-Store/Vertica Architecture (from vertica Technical Overview White Paper)
11

Summary: the performance gain
• Column representation – avoids reads of unused attributes
• Storing overlapping projections – multiple orderings of a column, more choices for query optimization
• Compression of data – more orderings of a column in the same amount of space
• Query operators operate on compressed representation

List of Column Databases
• Vertica/C-Store• SybaseIQ• MonetDB• LucidDB• HANA• Google’s Dremel • Parcell-> Redshit (Another Cloud-DB Service)

Outline
• Column Store• Why NoSQL• Basic Concept
– Distributed Transaction Processing– CAP
• NoSQL systems• Summary

Scaling Up
• Issues with scaling up when the dataset is just too big• RDBMS were not designed to be distributed• Began to look at multi-node database solutions• Known as ‘scaling out’ or ‘horizontal scaling’

Scaling RDBMS – Master/Slave
• Master-Slave– All writes are written to the master. All reads performed against
the replicated slave databases– Critical reads may be incorrect as writes may not have been
propagated down– Large data sets can pose problems as master needs to duplicate
data to slaves

What is NoSQL?
• Stands for Not Only SQL• Class of non-relational data storage systems• Usually do not require a fixed table schema nor do they use
the concept of joins• All NoSQL offerings relax one or more of the ACID properties
(will talk about the CAP theorem)

Dynamo and BigTable
• Three major papers were the seeds of the NoSQL movement– BigTable (Google)– Dynamo (Amazon)
• Gossip protocol (discovery and error detection)• Distributed key-value data store• Eventual consistency
– CAP Theorem (discuss in a sec ..)

CAP Theorem• Suppose three properties of a system
– Consistency (all copies have same value)– Availability (system can run even if parts have failed)– Partitions (network can break into two or more parts, each with active
systems that can not influence other parts)• Brewer’s CAP “Theorem”: for any system sharing data it is
impossible to guarantee simultaneously all of these three properties
• Very large systems will partition at some point– it is necessary to decide between C and A– traditional DBMS prefer C over A and P– most Web applications choose A (except in specific applications such
as order processing)

20
ACID Transactions
• A DBMS is expected to support “ACID transactions,” processes that are:– Atomic : Either the whole process is done or none
is.– Consistent : Database constraints are preserved.– Isolated : It appears to the user as if only one
process executes at a time.– Durable : Effects of a process do not get lost if the
system crashes.

Consistency
• Two kinds of consistency:– strong consistency – ACID(Atomicity Consistency Isolation
Durability)
– weak consistency – BASE(Basically Available Soft-state Eventual consistency )

Consistency Model• A consistency model determines rules for visibility and apparent
order of updates.• For example:
– Row X is replicated on nodes M and N– Client A writes row X to node N– Some period of time t elapses.– Client B reads row X from node M– Does client B see the write from client A?– Consistency is a continuum with tradeoffs– For NoSQL, the answer would be: maybe– CAP Theorem states: Strict Consistency can't be achieved at the same
time as availability and partition-tolerance.
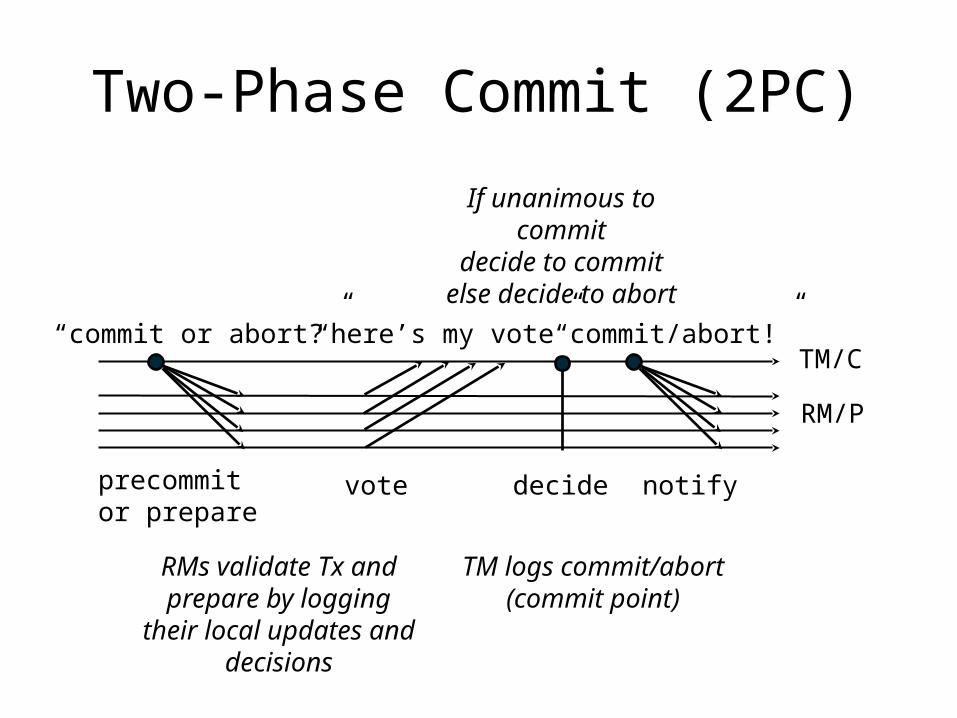
Two-Phase Commit (2PC)
“commit or abort?” “here’s my vote” “commit/abort!”TM/C
RM/P
precommitor prepare
vote decide notify
RMs validate Tx and prepare by logging their
local updates and decisions
TM logs commit/abort (commit point)
If unanimous to commitdecide to commit
else decide to abort

2PC: Phase 1✓ 1. Tx requests commit, by notifying coordinator (C)
• C must know the list of participating sites/RMs.✓ 2. Coordinator C requests each participant (P) to prepare.✓ 3. Participants (RMs) validate, prepare, and vote.
• Each P validates the request, logs validates updates locally, and responds to C with its vote to commit or abort.
• If P votes to commit, Tx is said to be “prepared” at P.

25
2PC: Phase 2
✓ 4. Coordinator (TM) commits.• Iff all P votes are unanimous to commit
– C writes a commit record to its log– Tx is committed.
• Else abort.✓ 5. Coordinator notifies participants.
• C asynchronously notifies each P of the outcome for Tx.• Each P logs the outcome locally• Each P releases any resources held for Tx.
25

Eventual Consistency
• When no updates occur for a long period of time, eventually all updates will propagate through the system and all the nodes will be consistent
• For a given accepted update and a given node, eventually either the update reaches the node or the node is removed from service
• Known as BASE (Basically Available, Soft state, Eventual consistency), as opposed to ACID

CAP Theorem
Consistency: Every node in the system contains the same data (e.g. replicas are never out of data)
Availability: Every request to a non-failing node in the system returns a response
Partition Tolerance: System properties (consistency and/or availability) hold even when the system is partitioned (communicate lost) and data is lost (node lost)

The CAP Theorem
Theorem: You can have at most two of these properties for any shared-data system
Consistency
Partition tolerance
Availability
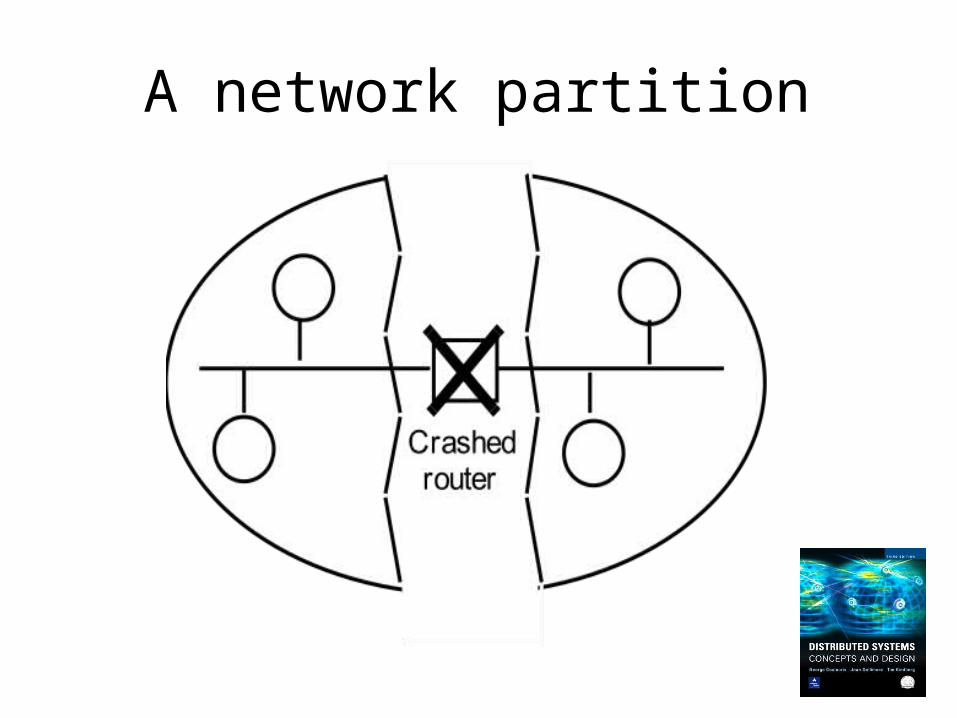
A network partition

CAP Theorem
• Three properties of a system: consistency, availability and partitions
• You can have at most two of these three properties for any shared-data system
• To scale out, you have to partition. That leaves either consistency or availability to choose from– In almost all cases, you would choose availability over
consistency

Outline
• Column Store• Why NoSQL• Basic Concept
– Distributed Transaction Processing– CAP
• NoSQL systems• Summary

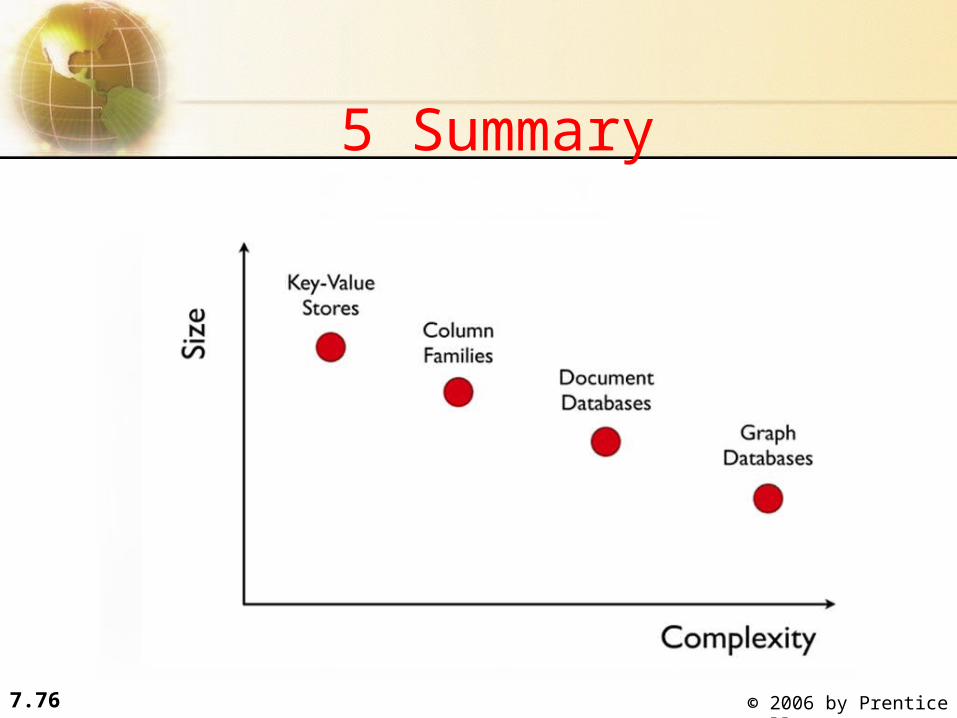
What kinds of NoSQL• NoSQL solutions fall into two major areas:
– Key/Value or ‘the big hash table’.• Amazon S3 (Dynamo)• Voldemort• Scalaris• Memcached (in-memory key/value store)• Redis
– Schema-less which comes in multiple flavors, column-based, document-based or graph-based.
• Cassandra (column-based)• CouchDB (document-based)• MongoDB(document-based)• Neo4J (graph-based)• HBase (column-based)
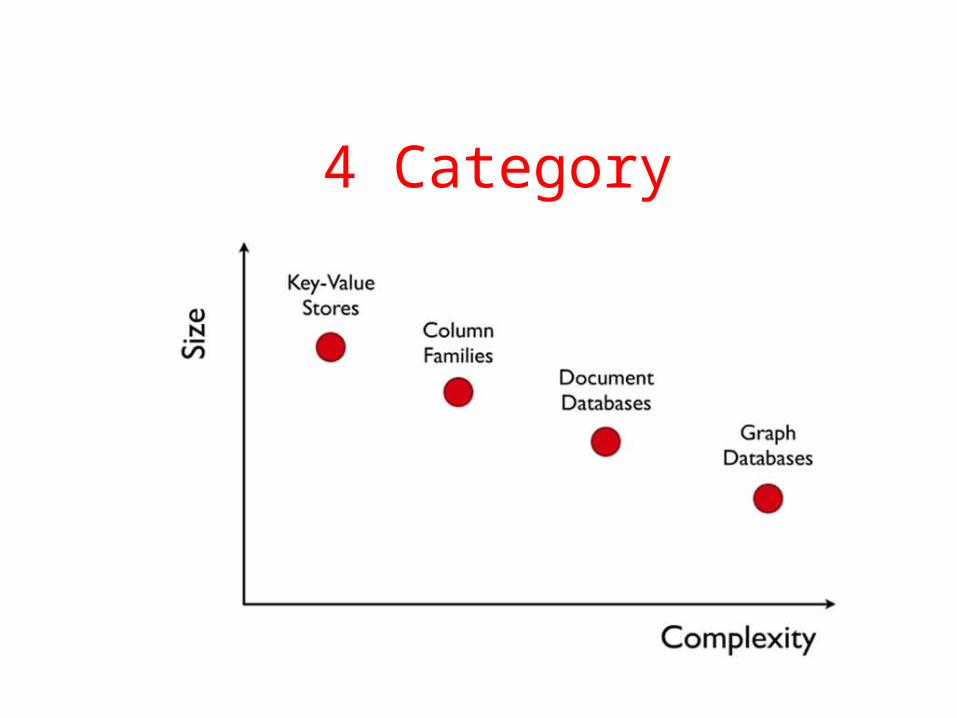
4 Category

Key/ValuePros:
– very fast– very scalable– simple model– able to distribute horizontally
Cons: - many data structures (objects) can't be easily modeled as key
value pairs

Schema-Less
Pros:- Schema-less data model is richer than key/value pairs- eventual consistency- many are distributed- still provide excellent performance and scalability
Cons: - typically no ACID transactions or joins

Common Advantages• Cheap, easy to implement (open source)• Data are replicated to multiple nodes (therefore
identical and fault-tolerant) and can be partitioned– Down nodes easily replaced– No single point of failure
• Easy to distribute• Don't require a schema• Can scale up and down• Relax the data consistency requirement (CAP)

What is given up?• joins• group by• order by• ACID transactions• SQL as a sometimes frustrating but still powerful query
language• easy integration with other applications that support SQL

Key-Value Stores
Extremely simple interface Data model: (key, value) pairs Operations: Insert(key,value), Fetch(key), Update(key), Delete(key)
Implementation: efficiency, scalability, fault-tolerance Records distributed to nodes based on key Replication Single-record transactions, “eventual consistency
User Case: Shopping Cart Data
• As we want the shopping carts to be available all the time, across browsers, machines, and sessions, all the shopping information can be put into value where the key is the userID

Not to Use
• Relationships among data• Multi-operation Transactions• Query by Data• Operations by Sets: since operations are
limited to one key at a time, there is no way to operate upon multiple keys at the same time. If you need to operate upon multiple keys, you have to handle this from the client side

Document Stores
Like Key-Value Stores except value is document Data model: (key, document) pairs Document: JSON, XML, other semistructured
formats Basic operations: Insert(key,document), Fetch(key), Update(key), Delete(key) Also Fetch based on document contents
Example systems CouchDB, MongoDB, SimpleDB etc

Document-Based
• based on JSON format: a data model which supports lists, maps, dates, Boolean with nesting
• Really: indexed semistructured documents • Example: Mongo
– {Name:"Jaroslav", Address:"Malostranske nám. 25, 118 00 Praha 1“Grandchildren: [Claire: "7", Barbara: "6", "Magda: "3",
"Kirsten: "1", "Otis: "3", Richard: "1"]}

MongoDB CRUD operations
• CRUD stands for create, read, update, and delete
• MongoDB stores data in the form of documents, which are JSON-like field and value pairs.

A collection of MongoDB documents

Suitable Use Cases
• Event Logging• Content Management Systems• Web Analytics or Real time Analysis• E-commerce Applications

Not to use
• Complex Transaction Spanning Different Operations
• Queries against Varying Aggregate Structure

HBase is an open-source, distributed, column-oriented database built on top of HDFS
based on BigTable!

BigTable Data Model
• A table in Bigtable is a sparse, distributed, persistent multidimensional sorted map
• Map indexed by a row key, column key, and a timestamp– (row:string, column:string, time:int64)
uninterpreted byte array• Supports lookups, inserts, deletes
– Single row transactions only
Image Source: Chang et al., OSDI 2006

BigTable Applications
• Data source and data sink for MapReduce• Google’s web crawl• Google Earth• Google Analytics

HBase is ..
• A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage.
• Designed to operate on top of the Hadoop distributed file system (HDFS) or Kosmos File System (KFS, aka Cloudstore) for scalability, fault tolerance, and high availability.

Benefits
• Distributed storage• Table-like in data structure
– multi-dimensional map• High scalability• High availability• High performance

HBase benefits than RDBMS
• No real indexes• Automatic partitioning• Scale linearly and automatically with new
nodes• Commodity hardware• Fault tolerance• Batch processing

Cassandra Structured Storage System over a P2P Network

Why Cassandra?
• Lots of data– Copies of messages, reverse indices of messages,
per user data.• Many incoming requests resulting in a lot of
random reads and random writes.• No existing production ready solutions in the
market meet these requirements.

Design Goals
• High availability• Eventual consistency
– trade-off strong consistency in favor of high availability• Incremental scalability• Optimistic Replication• “Knobs” to tune tradeoffs between consistency,
durability and latency• Low total cost of ownership• Minimal administration

innovation at scale• google bigtable (2006)
– consistency model: strong– data model: sparse map– clones: hbase, hypertable
• amazon dynamo (2007)– O(1) dht– consistency model: client tune-able– clones: riak, voldemort
cassandra ~= bigtable + dynamo
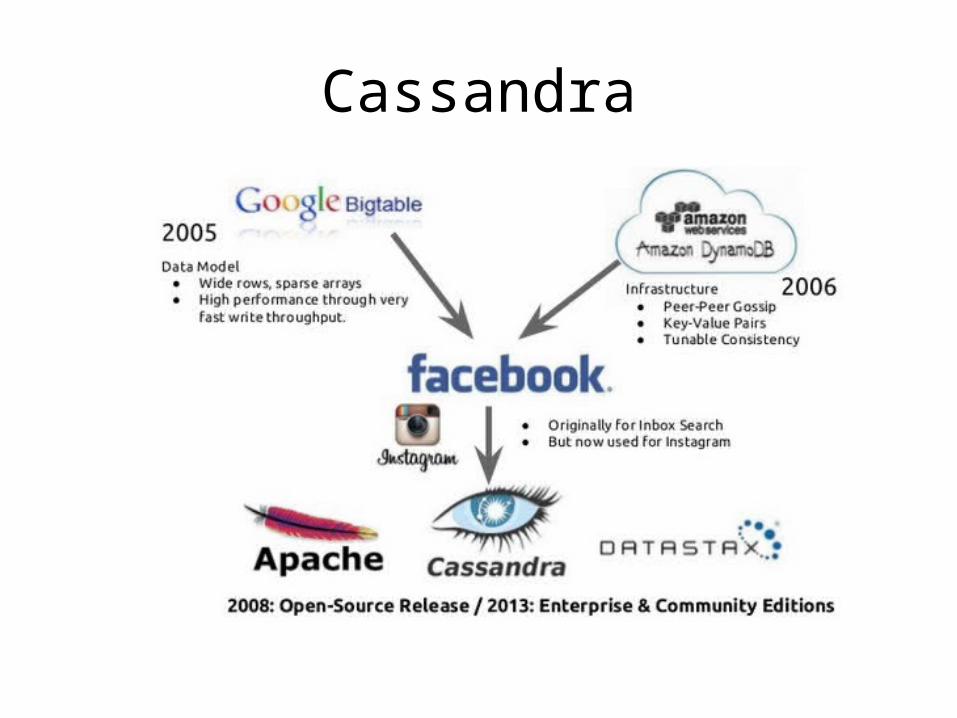
Cassandra

Suitable Use Cases
• Event Logging• Content management Systems, blogging
platforms

Not to use
• There are problems for which column-family databases are not best solutions, such as systems that require ACID transactions for writes and reads.
• If you need the database to aggregate the data using queries (such as SUM or AVG), you have to do this on the client side using data retrieved by the client from all the rows.

Hive and Pig

Need for High-Level Languages
• Hadoop is great for large-data processing!– But writing Java programs for everything is
verbose and slow– Not everyone wants to (or can) write Java code
• Solution: develop higher-level data processing languages– Hive: HQL is like SQL– Pig: Pig Latin is a bit like Perl

Hive and Pig
• Hive: data warehousing application in Hadoop– Query language is HQL, variant of SQL– Tables stored on HDFS as flat files– Developed by Facebook, now open source
• Pig: large-scale data processing system– Scripts are written in Pig Latin, a dataflow language– Developed by Yahoo!, now open source– Roughly 1/3 of all Yahoo! internal jobs
• Common idea:– Provide higher-level language to facilitate large-data processing– Higher-level language “compiles down” to Hadoop jobs

Hive Components
• Shell: allows interactive queries• Driver: session handles, fetch, execute• Compiler: parse, plan, optimize• Execution engine: DAG of stages (MR, HDFS,
metadata)• Metastore: schema, location in HDFS, SerDe
Source: cc-licensed slide by Cloudera

Data Model
• Tables– Typed columns (int, float, string, boolean)– Also, list: map (for JSON-like data)
• Partitions– For example, range-partition tables by date
• Buckets– Hash partitions within ranges (useful for sampling,
join optimization)
Source: cc-licensed slide by Cloudera

Physical Layout
• Warehouse directory in HDFS– E.g., /user/hive/warehouse
• Tables stored in subdirectories of warehouse– Partitions form subdirectories of tables
• Actual data stored in flat files– Control char-delimited text, or SequenceFiles– With custom SerDe, can use arbitrary format
Source: cc-licensed slide by Cloudera

Hive: Example Hive looks similar to an SQL database
Relational join on two tables: Table of word counts from Shakespeare collection Table of word counts from the bible
Source: Material drawn from Cloudera training VM
SELECT s.word, s.freq, k.freq FROM shakespeare s JOIN bible k ON (s.word = k.word) WHERE s.freq >= 1 AND k.freq >= 1 ORDER BY s.freq DESC LIMIT 10;
the 25848 62394I 23031 8854and 19671 38985to 18038 13526of 16700 34654a 14170 8057you 12702 2720my 11297 4135in 10797 12445is 8882 6884

67
Graph Databases

68
NEO4J (Graphbase)• A graph is a collection nodes (things) and edges (relationships) that connect
pairs of nodes.
• Attach properties (key-value pairs) on nodes and relationships
•Relationships connect two nodes and both nodes and relationships can hold an
arbitrary amount of key-value pairs.
• A graph database can be thought of as a key-value store, with full support for
relationships.
• http://neo4j.org/

69
NEO4J

70
NEO4J
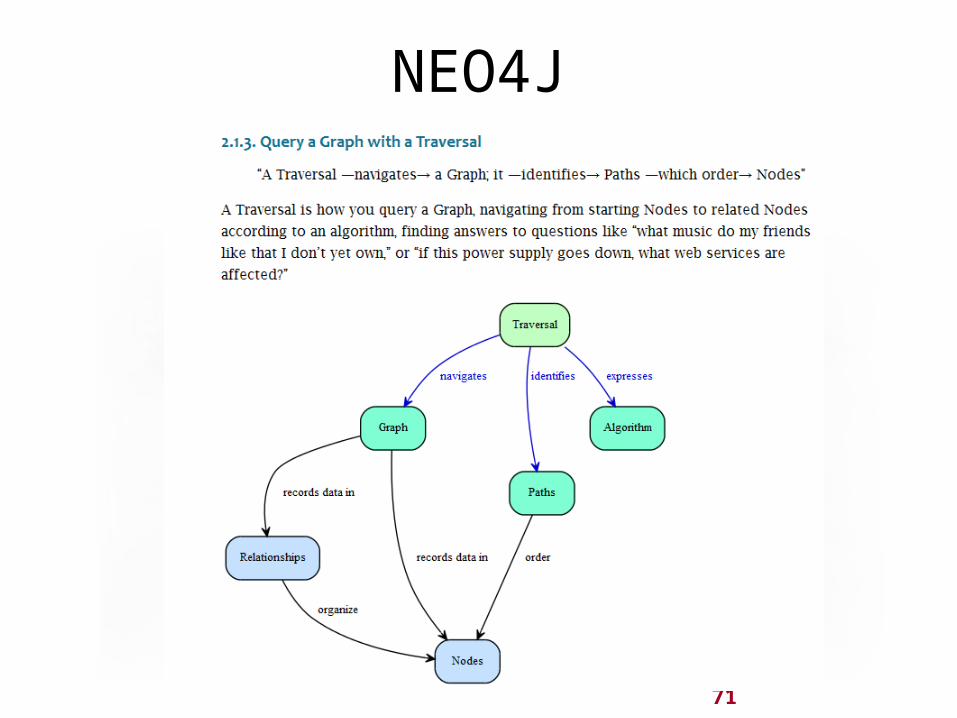
71
NEO4J
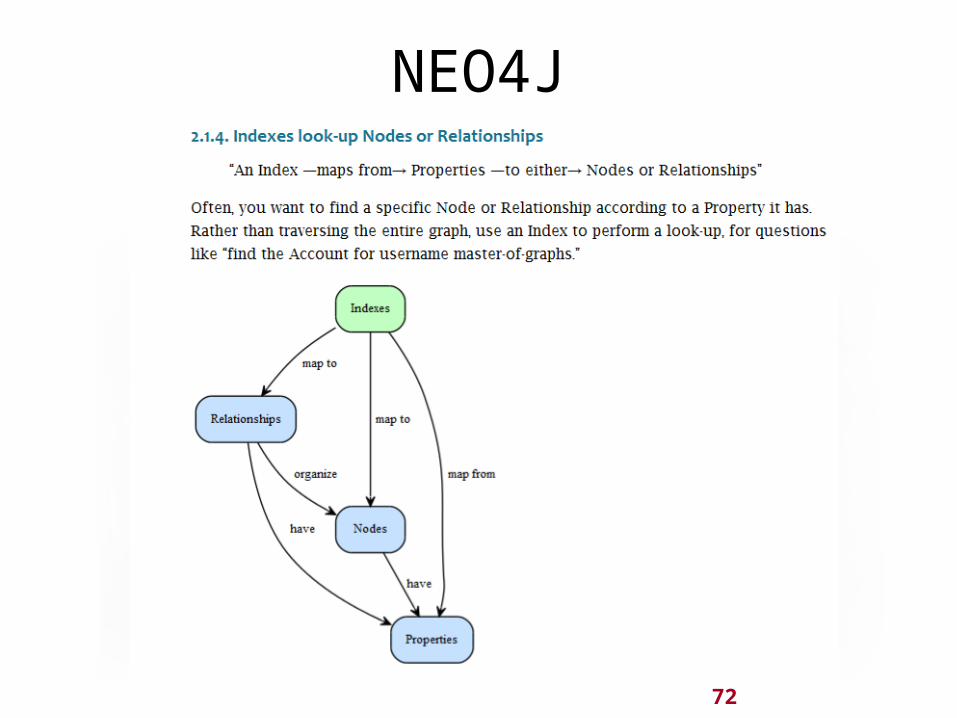
72
NEO4J
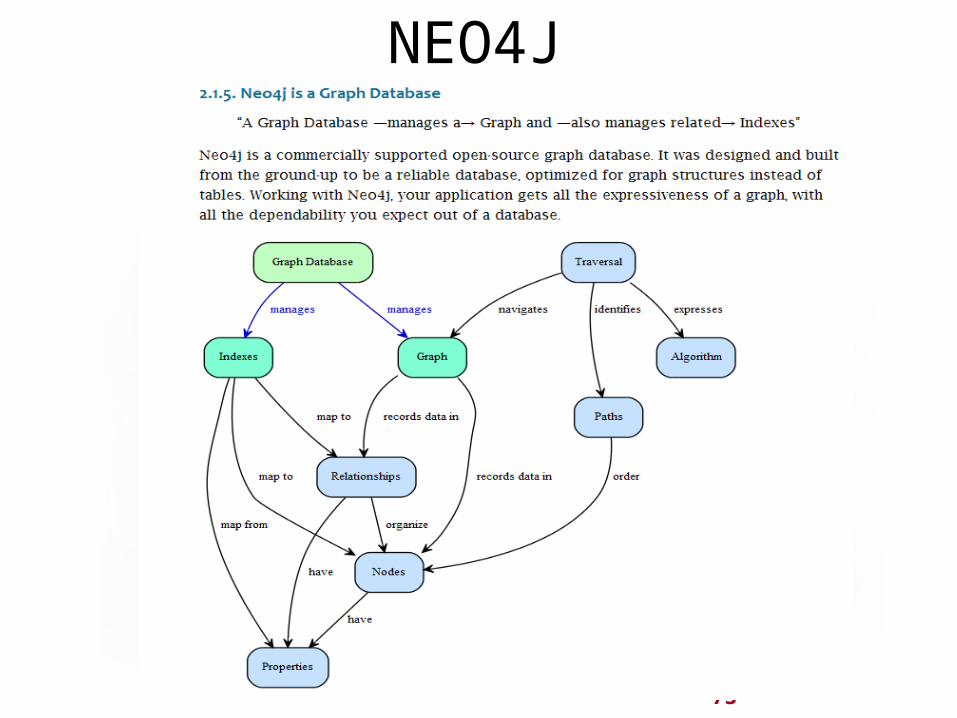
73
NEO4J
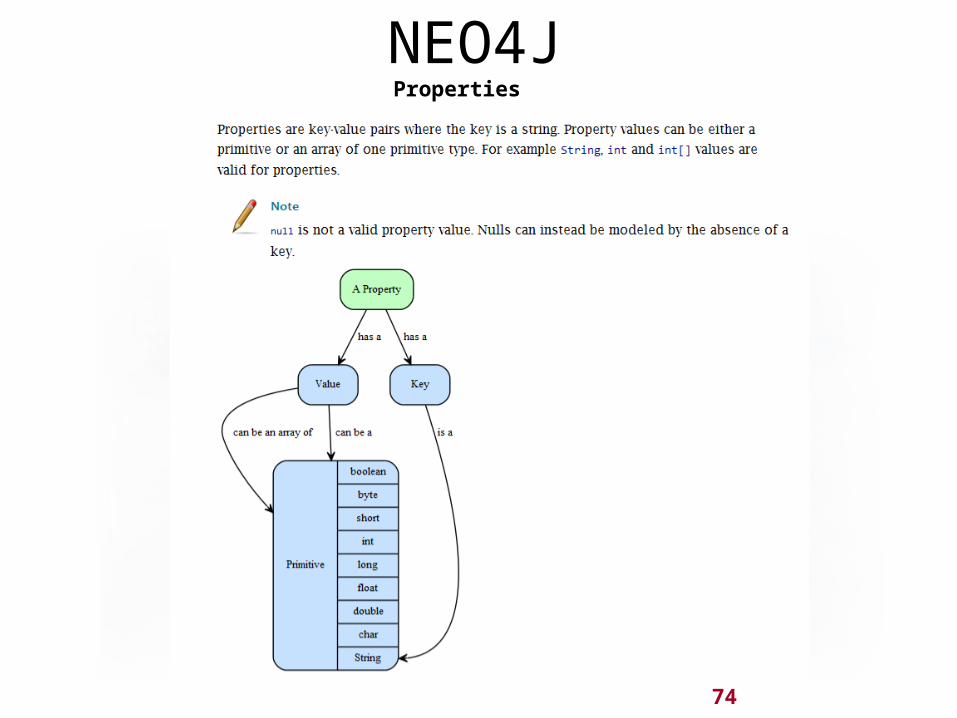
74
NEO4JProperties

75
NEO4J Features• Dual license: open source and commercial
•Well suited for many web use cases such as tagging, metadata annotations,
social networks, wikis and other network-shaped or hierarchical data sets
• Intuitive graph-oriented model for data representation. Instead of static and
rigid tables, rows and columns, you work with a flexible graph network
consisting of nodes, relationships and properties.
• Neo4j offers performance improvements on the order of 1000x
or more compared to relational DBs.
• A disk-based, native storage manager completely optimized for storing
graph structures for maximum performance and scalability
• Massive scalability. Neo4j can handle graphs of several billion
nodes/relationships/properties on a single machine and can be sharded to
scale out across multiple machines
•Fully transactional like a real database
•Neo4j traverses depths of 1000 levels and beyond at millisecond speed.
(many orders of magnitude faster than relational systems)
7.76 © 2006 by Prentice Hall
5 Summary

















