63
IBM PureData System for Analytics (Formerly known as, IBM Netezza) -Ravi www.etraining.guru [email protected]
| Date post: | 14-Aug-2015 |
| Category: |
Education |
| Upload: | ravikumar-nandigam |
| View: | 25 times |
| Download: | 3 times |

IBM PureData Systemfor Analytics
(Formerly known as, IBM Netezza)

CREATE DATABASE

Default Database: SYSTEM
Default Database Template: MASTER_DB
In Netezza world, DATABASE=CATALOG
Starting in 7.0.3, Netezza supports the ability to define multiple schemas within each database
In previous releases (i.e., before 7.0.3), the Netezza system supported one default schema per database.The default and only schema matched the name of the database user who created the database
Enable Multiple schema support:
vi /nz/data/postgresql.confVariable: enable_schema_dbo_check
0: Single schema
1: Enables multiple schema support in limited mode. You will get a warning, if a query references an invalid schema
2: Enables support for multiple schemas. Users can create, alter, set, and drop schemas. If a query references an invalid schema, the query returns an error
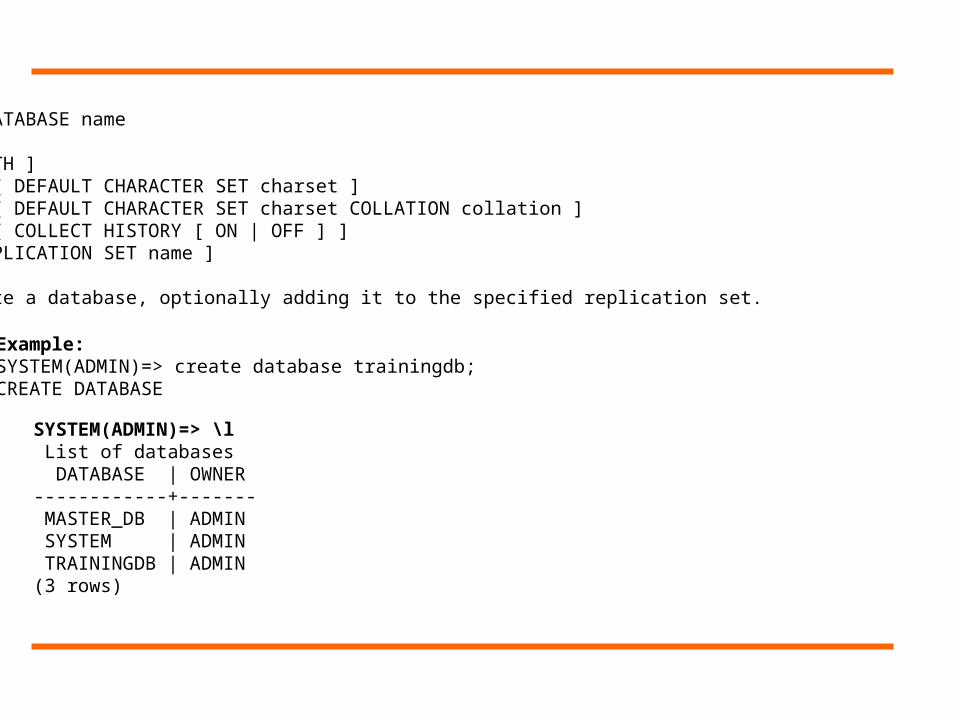
Syntax:CREATE DATABASE name
[ WITH ] [ DEFAULT CHARACTER SET charset ] [ DEFAULT CHARACTER SET charset COLLATION collation ] [ COLLECT HISTORY [ ON | OFF ] ] [ REPLICATION SET name ]
Create a database, optionally adding it to the specified replication set.
Example:SYSTEM(ADMIN)=> create database trainingdb;CREATE DATABASE
SYSTEM(ADMIN)=> \l List of databases DATABASE | OWNER------------+------- MASTER_DB | ADMIN SYSTEM | ADMIN TRAININGDB | ADMIN(3 rows)

SYSTEM(ADMIN)=> \c trainingdbYou are now connected to database trainingdb
TRAININGDB(ADMIN)=> select objid, database from _v_database; OBJID | DATABASE--------+------------ 2 | MASTER_DB 1 | SYSTEM 257262 | TRAININGDB(3 rows)
TRAININGDB(ADMIN)=> \q[nz@netezza 257323]$ nzstats -type database
DB Id DB Name Create Date Owner Id Num Tables Num Views Num Active Users------ ---------- ------------------- -------- ---------- --------- ---------------- 1 SYSTEM 2012-11-07 05:36:03 500 0 0 7 2 MASTER_DB 2012-11-07 05:36:03 500 0 0 0257262 TRAININGDB 2014-01-21 01:46:57 500 1 0 0
Any idea, where this newly created database stored? (In SPU disks (or) Netezza host disks?)
/nz/data/base/<database object id>
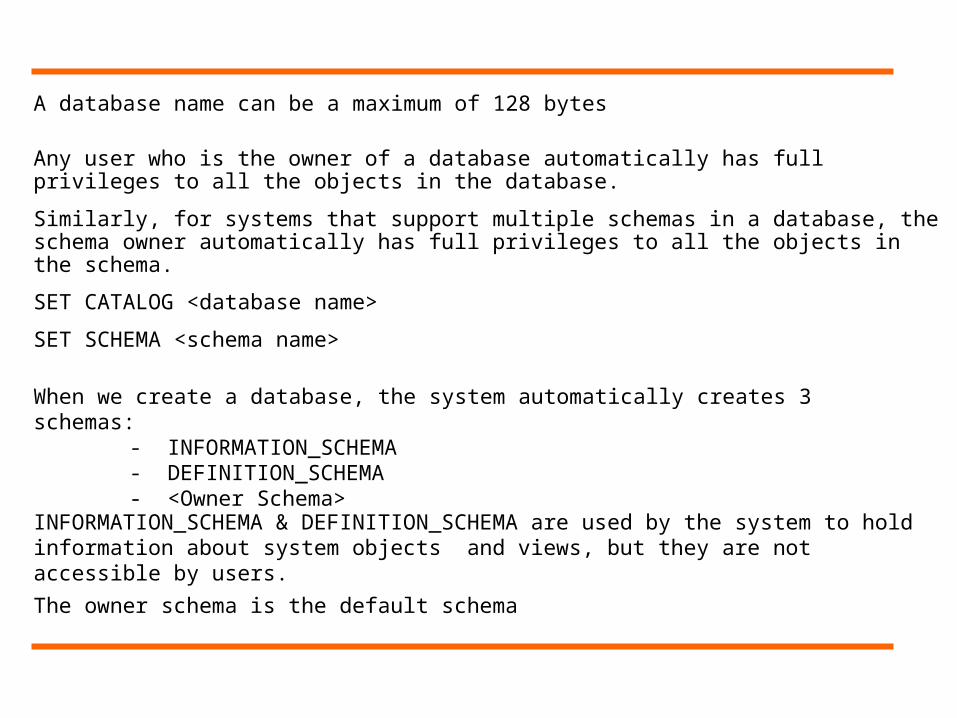
When we create a database, the system automatically creates 3 schemas:- INFORMATION_SCHEMA- DEFINITION_SCHEMA- <Owner Schema>
INFORMATION_SCHEMA & DEFINITION_SCHEMA are used by the system to hold information about system objects and views, but they are not accessible by users.
The owner schema is the default schema
A database name can be a maximum of 128 bytes
Any user who is the owner of a database automatically has full privileges to all the objects in the database.
Similarly, for systems that support multiple schemas in a database, the schema owner automatically has full privileges to all the objects in the schema.
SET CATALOG <database name>
SET SCHEMA <schema name>
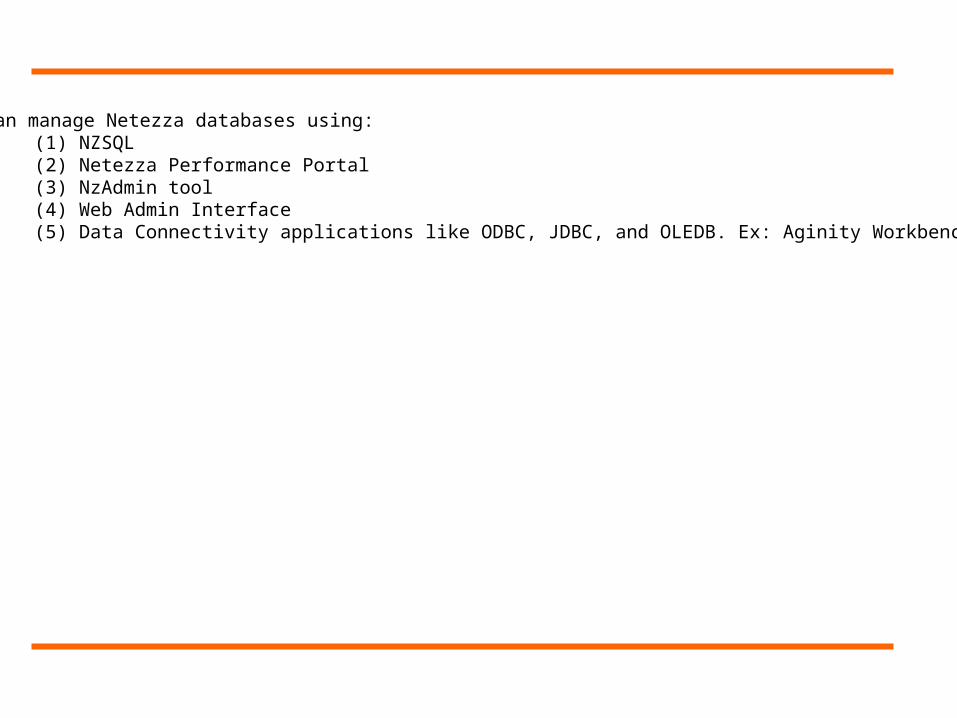
You can manage Netezza databases using:(1) NZSQL(2) Netezza Performance Portal(3) NzAdmin tool(4) Web Admin Interface(5) Data Connectivity applications like ODBC, JDBC, and OLEDB. Ex: Aginity Workbench
CREATE TABLE
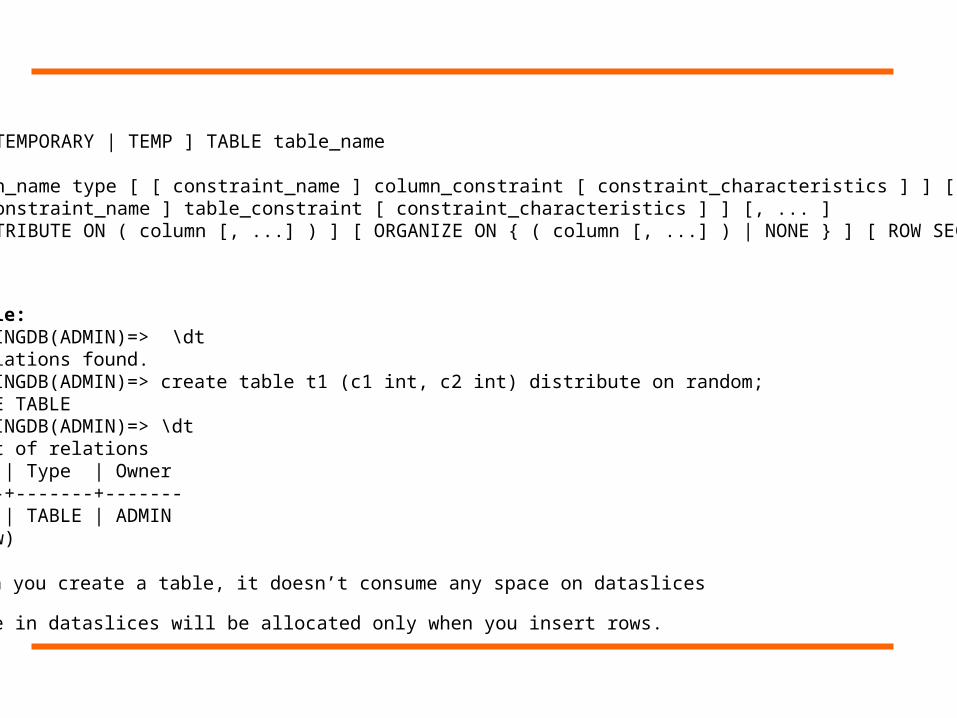
Syntax:
CREATE [ TEMPORARY | TEMP ] TABLE table_name ( column_name type [ [ constraint_name ] column_constraint [ constraint_characteristics ] ] [, ... ] [ [ constraint_name ] table_constraint [ constraint_characteristics ] ] [, ... ] ) [ DISTRIBUTE ON ( column [, ...] ) ] [ ORGANIZE ON { ( column [, ...] ) | NONE } ] [ ROW SECURITY ]…
Example:TRAININGDB(ADMIN)=> \dtNo relations found.TRAININGDB(ADMIN)=> create table t1 (c1 int, c2 int) distribute on random;CREATE TABLETRAININGDB(ADMIN)=> \dt List of relations Name | Type | Owner------+-------+------- T1 | TABLE | ADMIN(1 row)
When you create a table, it doesn’t consume any space on dataslices
Space in dataslices will be allocated only when you insert rows.

Extent size: 3 MB
Each extent is divided into 24*128KB pages (also called block)
Action Item: Login to NZADMIN and watch space getting allocated the moment you insert rows in a table

Checkpoint Time!
Test our learnings:(1) Create a new database(2) Find out its object ID(3) Create a table (Using hash/random distribution). Check if any space allocation through NZADMIN(4) Insert a new row. Now check space allocation through NZADMIN(5) Insert another row. Now check space allocation through NZADMIN

NETEZZA DATATYPES
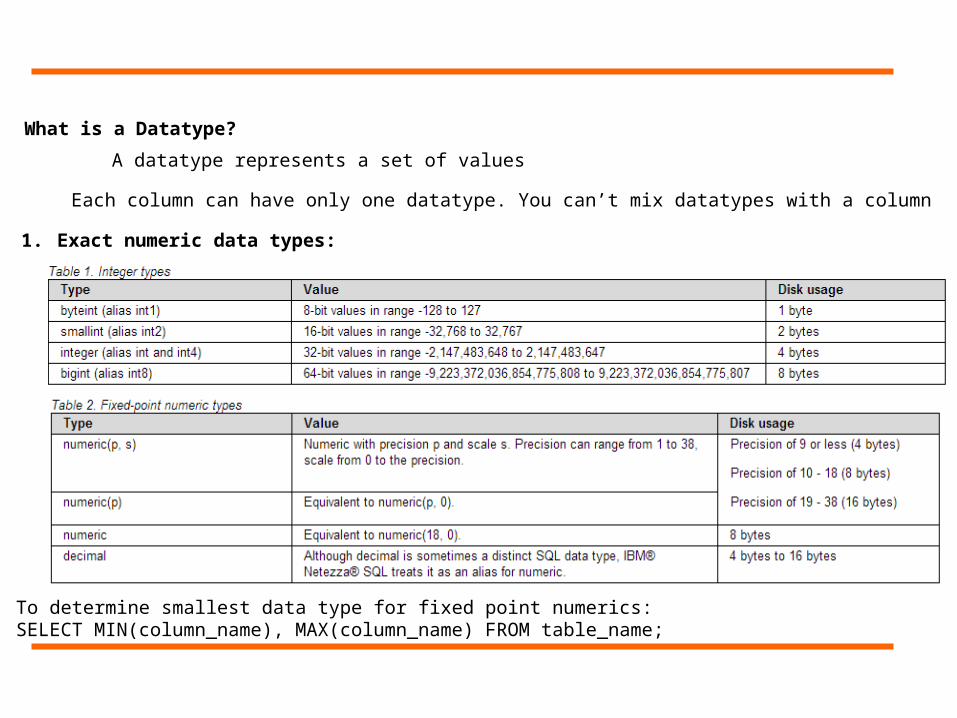
What is a Datatype?
A datatype represents a set of values
Each column can have only one datatype. You can’t mix datatypes with a column
1. Exact numeric data types:
To determine smallest data type for fixed point numerics: SELECT MIN(column_name), MAX(column_name) FROM table_name;

2. Approximate numeric data types:
Don’t use Floating point data types for distribution columns, join columns, or for columns that require mathematical operations such as SUM and AVG
Netezza can’t run a fast hash join on a floating point data type, but instead must run a slower sort and merge join
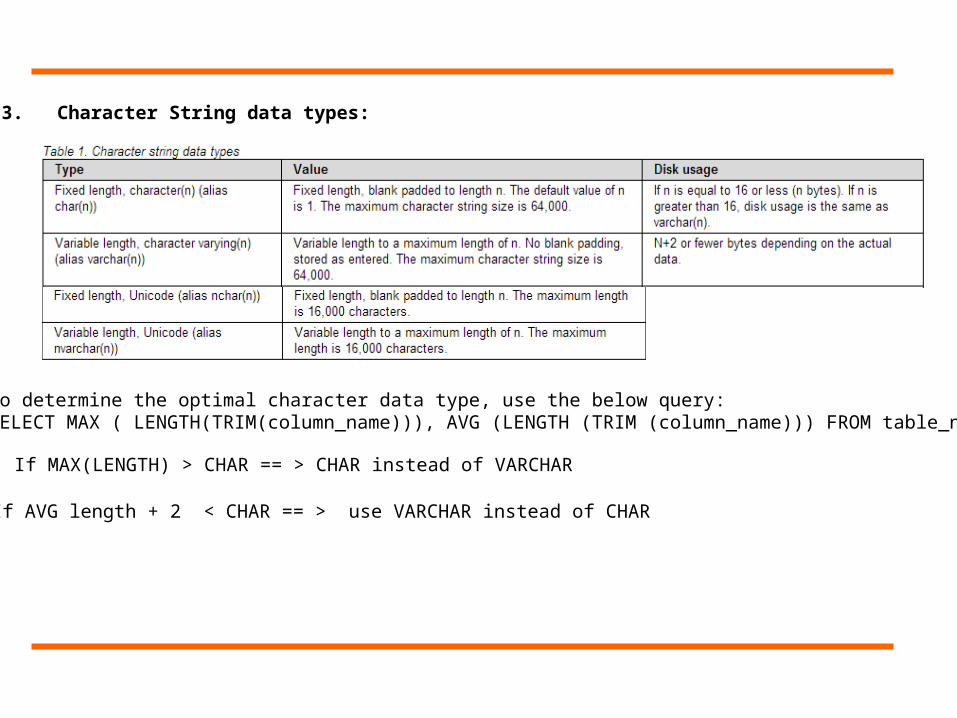
3. Character String data types:
To determine the optimal character data type, use the below query:SELECT MAX ( LENGTH(TRIM(column_name))), AVG (LENGTH (TRIM (column_name))) FROM table_name;
If MAX(LENGTH) > CHAR == > CHAR instead of VARCHAR
If AVG length + 2 < CHAR == > use VARCHAR instead of CHAR
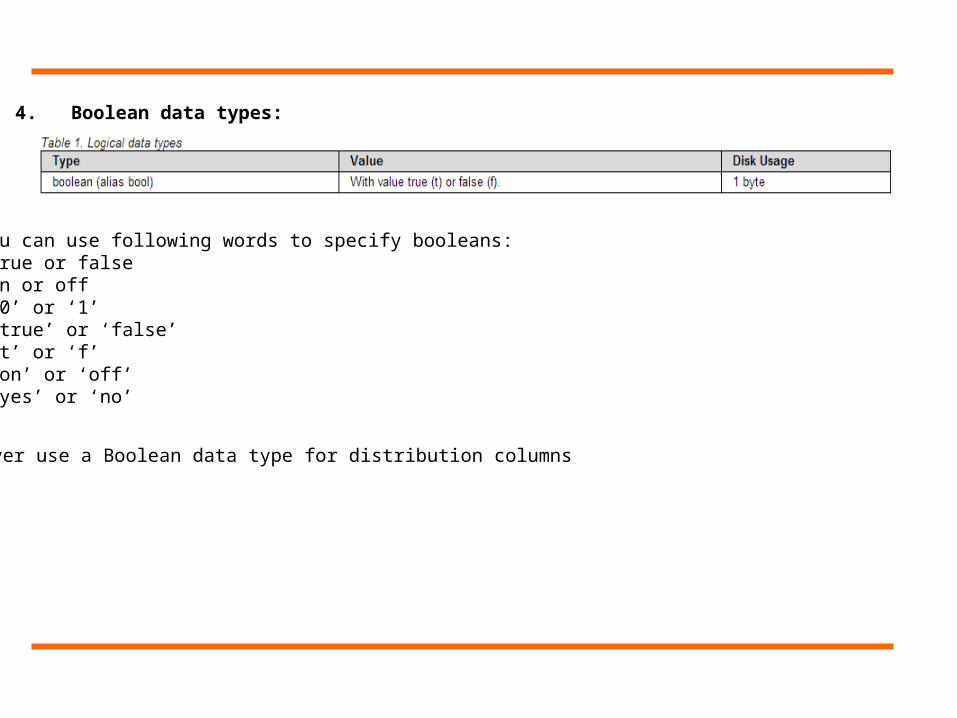
4. Boolean data types:
You can use following words to specify booleans:•True or false•On or off•‘0’ or ‘1’•“true’ or ‘false’•‘t’ or ‘f’•‘on’ or ‘off’•‘yes’ or ‘no’
Never use a Boolean data type for distribution columns
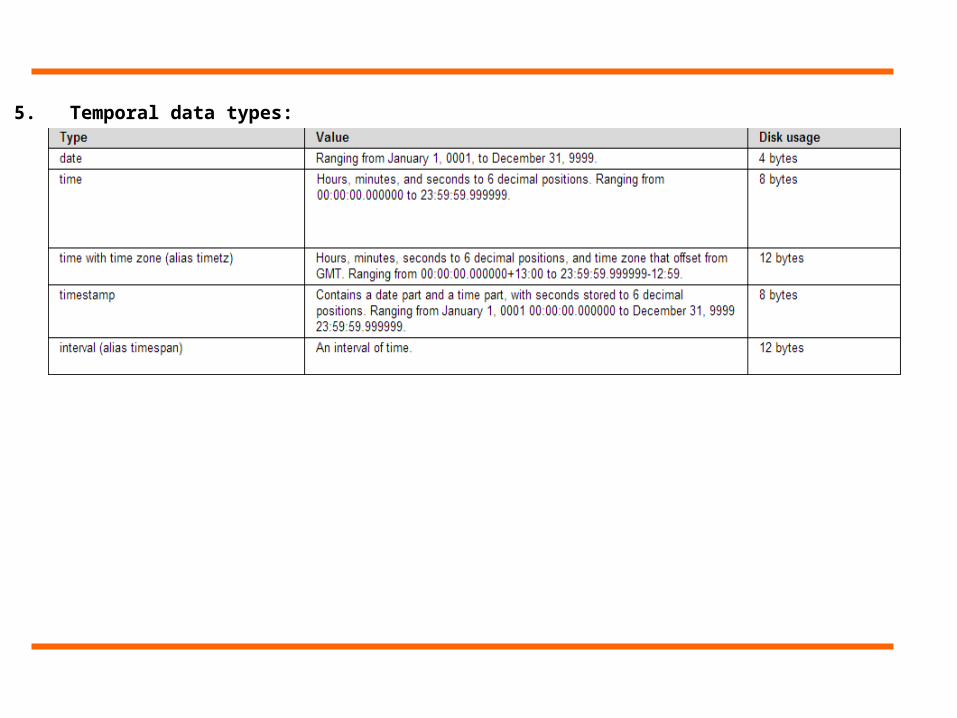
5. Temporal data types:
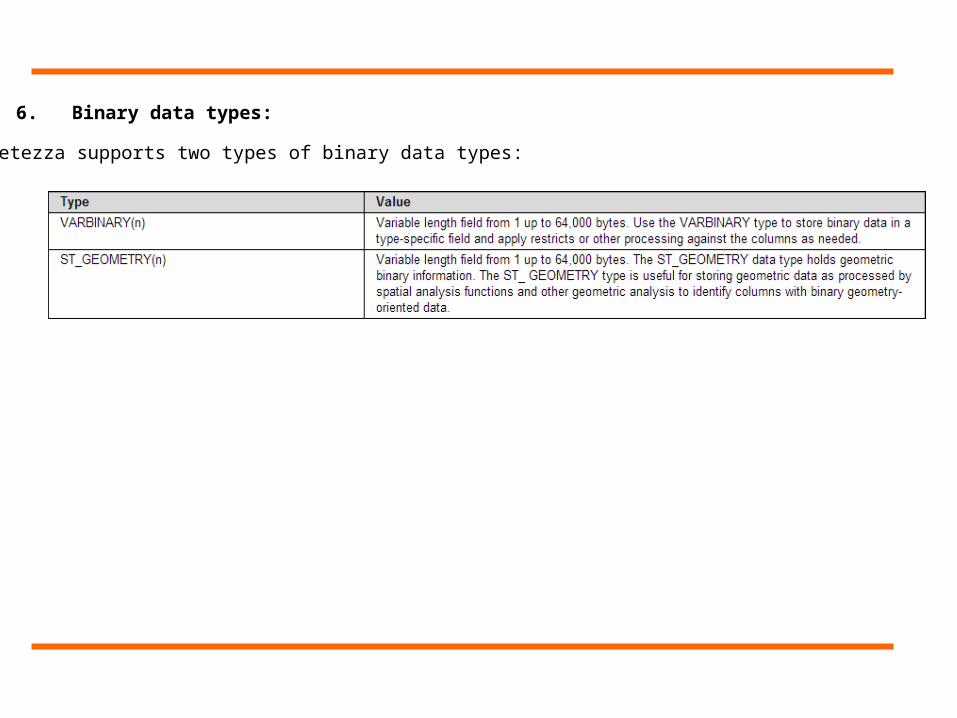
6. Binary data types:
Netezza supports two types of binary data types:
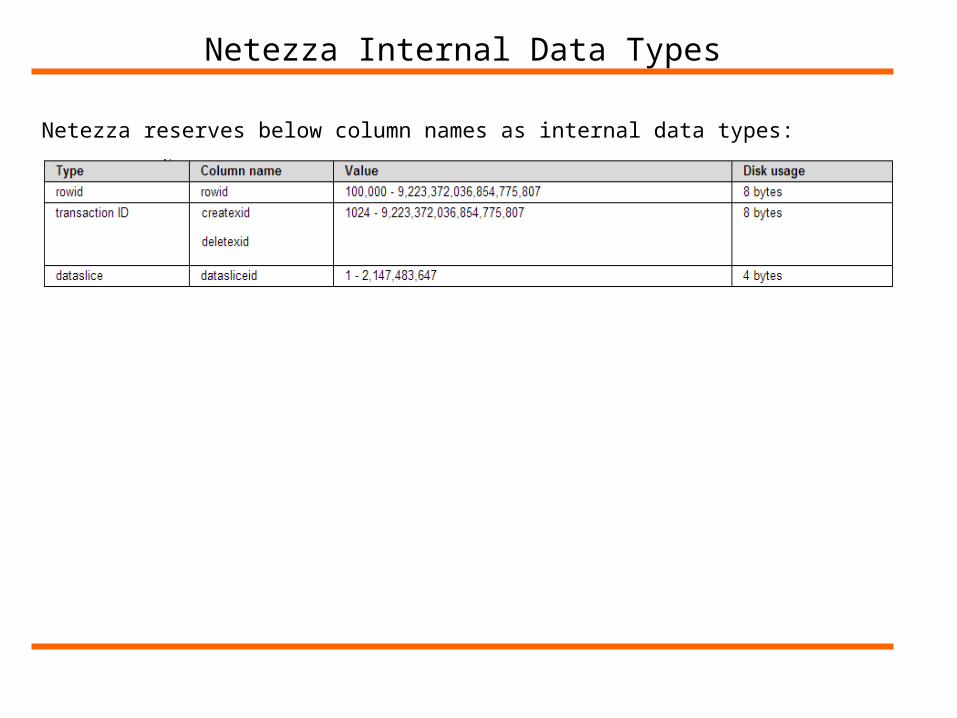
Netezza Internal Data Types
Netezza reserves below column names as internal data types:
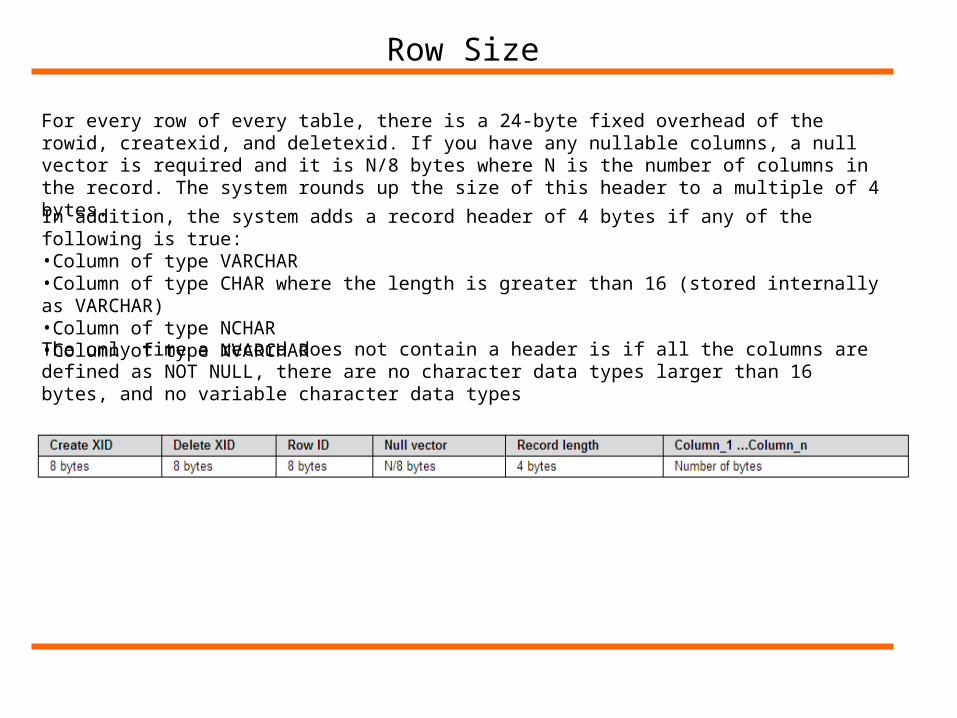
Row Size
For every row of every table, there is a 24-byte fixed overhead of the rowid, createxid, and deletexid. If you have any nullable columns, a null vector is required and it is N/8 bytes where N is the number of columns in the record. The system rounds up the size of this header to a multiple of 4 bytes.
In addition, the system adds a record header of 4 bytes if any of the following is true:•Column of type VARCHAR•Column of type CHAR where the length is greater than 16 (stored internally as VARCHAR)•Column of type NCHAR•Column of type NVARCHAR
The only time a record does not contain a header is if all the columns are defined as NOT NULL, there are no character data types larger than 16 bytes, and no variable character data types
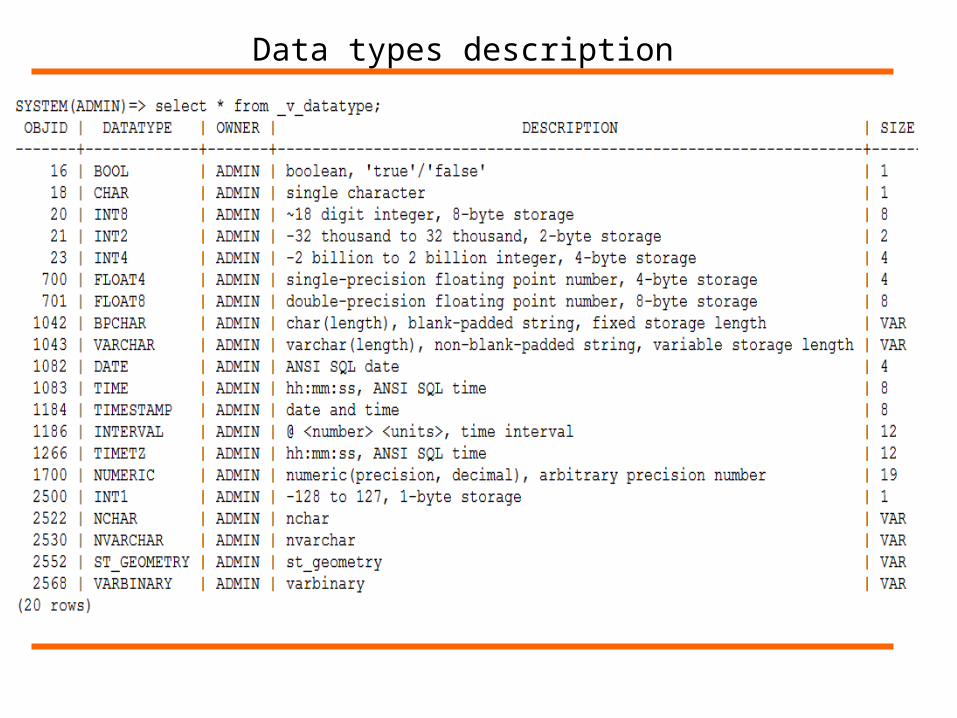
Data types description

SYNONYMS

An alternative way of referencing tables, views, or functions
Allows us to create easily typed names for long object names
You can use following synonym commands:- Create Synonym- Drop Synonym- Alter Synonym- Grant Synonym- Revoke Synonym
Syntax: SYSTEM(ADMIN)=> \h create synonymCommand: CREATE SYNONYMDescription: Creates a new synonymSyntax:CREATE SYNONYM name FOR refname
Example: SYSTEM(ADMIN)=> create synonym s_skew_student for skew..student;CREATE SYNONYM
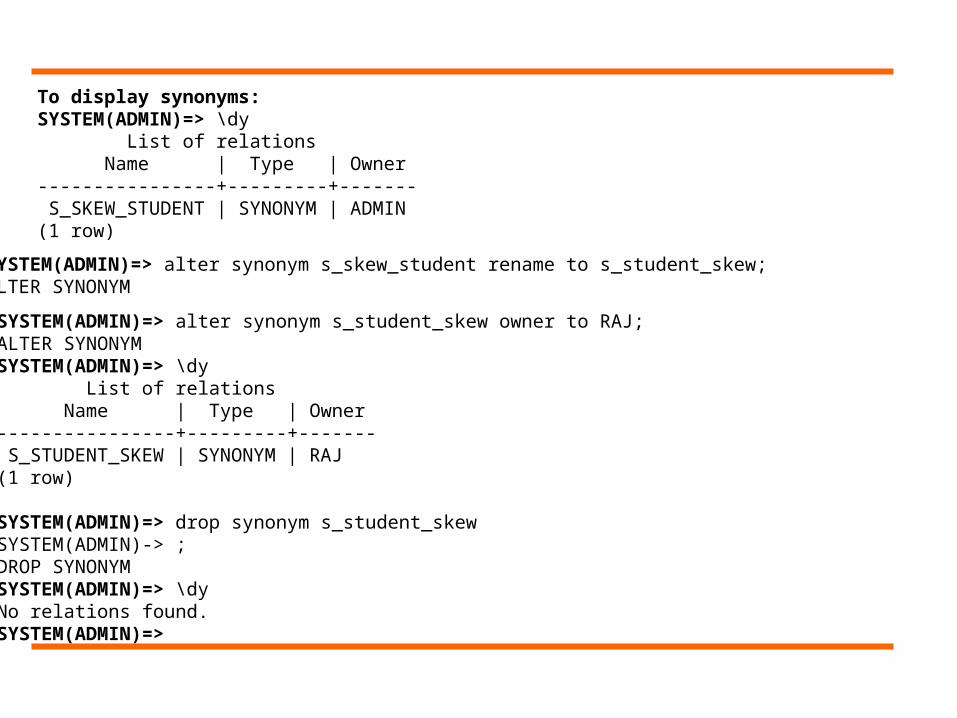
To display synonyms: SYSTEM(ADMIN)=> \dy List of relations Name | Type | Owner----------------+---------+------- S_SKEW_STUDENT | SYNONYM | ADMIN(1 row)
SYSTEM(ADMIN)=> alter synonym s_skew_student rename to s_student_skew;ALTER SYNONYM
SYSTEM(ADMIN)=> alter synonym s_student_skew owner to RAJ;ALTER SYNONYMSYSTEM(ADMIN)=> \dy List of relations Name | Type | Owner----------------+---------+------- S_STUDENT_SKEW | SYNONYM | RAJ(1 row)
SYSTEM(ADMIN)=> drop synonym s_student_skewSYSTEM(ADMIN)-> ;DROP SYNONYMSYSTEM(ADMIN)=> \dyNo relations found.SYSTEM(ADMIN)=>

VIEWS

A view is simply the representation of a SQL statement that is stored in memory so that it can be easily re-used
For example: If we frequently issue the following query:SELECT student.sid, student.sname, marks.per from student, marks where student.sid = marks.sid;
We can create here a view as below:CREATE VIEW v_student_marks AS SELECT student.sid, student.sname, marks.per from student, marks WHERE student.sid = marks.sid;
From next time onwards, we can simply select from view as below:
SELECT * FROM v_student_marks;
Syntax:SYSTEM(ADMIN)=> \h create viewCommand: CREATE VIEWDescription: Constructs a virtual tableSyntax:CREATE VIEW view AS SELECT query
Creates a new view.
CREATE OR REPLACE VIEW view AS SELECT query
Creates a new view or replaces an existing view.

Materialized Views

Sorted, Projected, and Materialized (SPM) views
Projects subset of table’s columns, does sort, and stores on disk
Syntax:SYSTEM(ADMIN)=> \h create materialized viewCommand: CREATE MATERIALIZED VIEWDescription: Creates a new materialized viewSyntax:CREATE MATERIALIZED VIEW view AS SELECT column [, ...] FROM table [ ORDER BY column [, ...] ]
Creates a new materialized view.
CREATE OR REPLACE MATERIALIZED VIEW view AS SELECT column [, ...] FROM table [ ORDER BY column [, ...] ]
Creates a new materialized view or replaces an existing materialized view.
SPM views are used to improve query performance significantly
If selected column exists in materialized view, optimizer selects the data from materialized view instead of going through base table

Few Restrictions:- Only one base table in the FROM clause- No WHERE clause- No expressions are allowed in materialized view columns- Only user table as base table for SPM view. Don’t specifiy CBT, system table, etc as base table
When you insert a new record in base table, same will be inserted into materialized view table as well.So, as time goes on, we will be having unsorted records getting appended to materialized view table at the end.
So, we should periodically manually refresh SPM view by suspending and refreshing it.
ALTER VIEW M_STUDENT_SKEW MATERIALIZE REFERESH;
SKEW(ADMIN)=> create materialized view m_student_skew as select SID, SNAME from student order by sid;CREATE MATERIALIZED VIEWSKEW(ADMIN)=> \dm List of relations Name | Type | Owner | STATE----------------+-------------------+-------+-------- M_STUDENT_SKEW | MATERIALIZED VIEW | ADMIN | ACTIVE(1 row)
Setting Referesh Threshold: SET SYSTEM DEFAULT MATERIALIZE THRESHOLD TO <number>
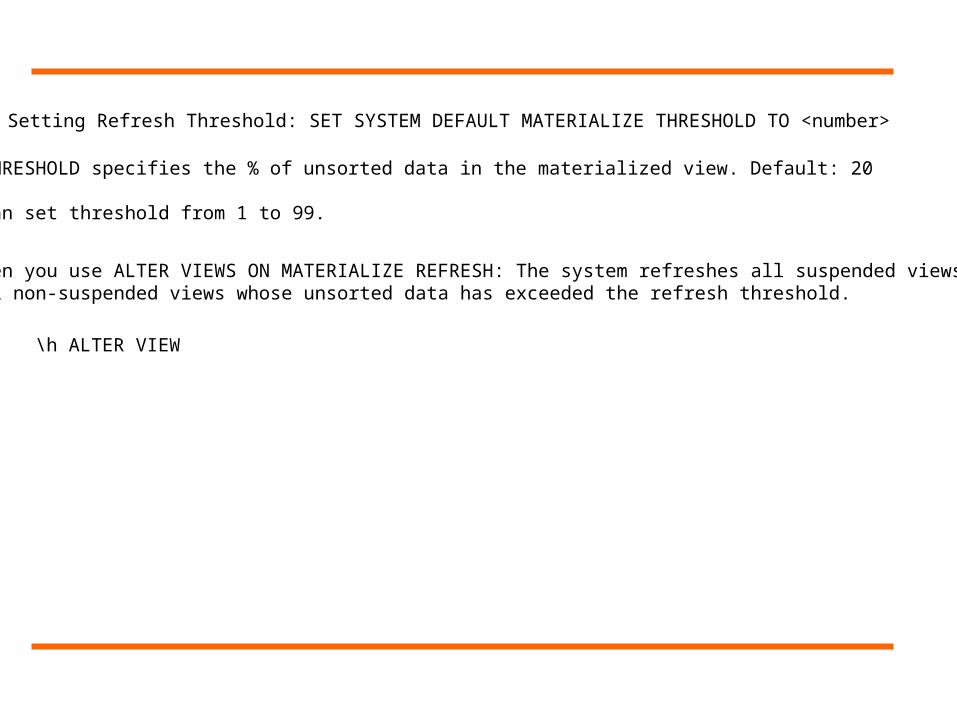
When you use ALTER VIEWS ON MATERIALIZE REFRESH: The system refreshes all suspended views, and all non-suspended views whose unsorted data has exceeded the refresh threshold.
Setting Refresh Threshold: SET SYSTEM DEFAULT MATERIALIZE THRESHOLD TO <number>
The THRESHOLD specifies the % of unsorted data in the materialized view. Default: 20
You can set threshold from 1 to 99.
\h ALTER VIEW

Nzbackup command just backs up SPM view definition, not the SPM view-specific dataNzrestore automatically creates/populates materialized views from base tables unless the SPM view is in suspend state.
Zone maps for ORDER BY columns in materialized views are created.
Best Practices:- Use most frequently used and most frequently restricted columns - Even though you can have more than one materialized view on a table, restrict this number- Limit columns in materialized views to as less as possible

System Views

There are N number of catalog views in Netezza. Let’s look at few of them here:
_v_view: To know what are available views in the Netezza
_v_database: All databases information
_v_user: About users information in the Netezza system
_v_table: List of tables. Both system tables & Management Tables
RAVI(ADMIN)=> select objid, tablename from _v_table where tablename='CUSTOMER'; OBJID | TABLENAME--------+----------- 236354 | CUSTOMER(1 row)
_v_relation_column: Table/column mappingRAVI(ADMIN)=> select OBJID, NAME, ATTNAME from _v_relation_column where objid=236354; OBJID | NAME | ATTNAME--------+----------+--------- 236354 | CUSTOMER | C3 236354 | CUSTOMER | C2 236354 | CUSTOMER | C1(3 rows)

_v_objects: Lists different objects like tables, views, functions, etc
_v_qrystat: currently running queries statistics
_v_qryhist: History of what has been run
_v_aggregate: Returns a list of all defined aggregates
_v_datatype: all system datatypes
_v_function: All defined functions
_v_group: List of all groups
_v_system_info: System information such as systemstatus, version info, etc
_v_index: List of all user indexes
_v_operator: List of all defined operators
_v_relation_column_def: Returns a list of all attributes of a relation that has defined defaults

_v_sequence: Returns a list of all defined sequences
_v_table_index: Returns a list of all user table indexes
_v_user: Returns a list of all users (\du)
_v_usergroups: Returns a list of all groups of which the user is a member
_v_groupusers: list of all users of a group
_v_sys_group_priv: Returns a list of all defined group privileges. (\dpg group_name)
_v_sys_index: Returns a list of all system indexes (\dSi)
_v_sys_priv: Returns a list of all user privileges. (\dp <user>)
_v_sys_table: Returns a list of all system tables. (\dSt)
_v_sys_user_priv: list permissions granted to a user. (\dpu <user>)
_v_sys_view: Returns a list of all system views. (\dSv)


USERS GROUPS PRIVILEGES
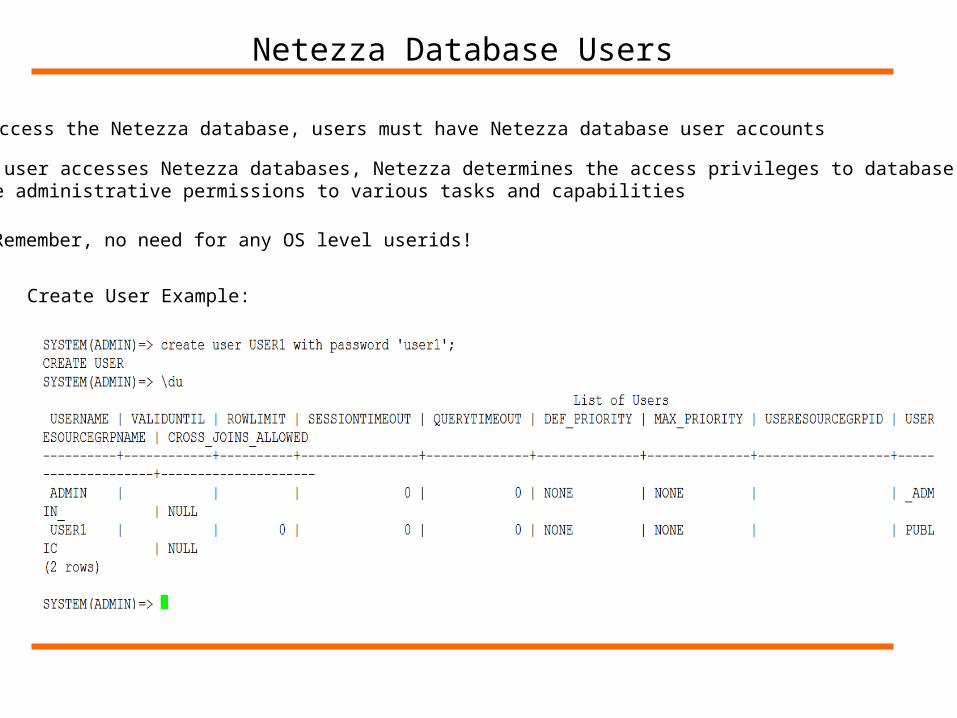
Netezza Database Users
To access the Netezza database, users must have Netezza database user accounts
Remember, no need for any OS level userids!
When a user accesses Netezza databases, Netezza determines the access privileges to database objectsand the administrative permissions to various tasks and capabilities
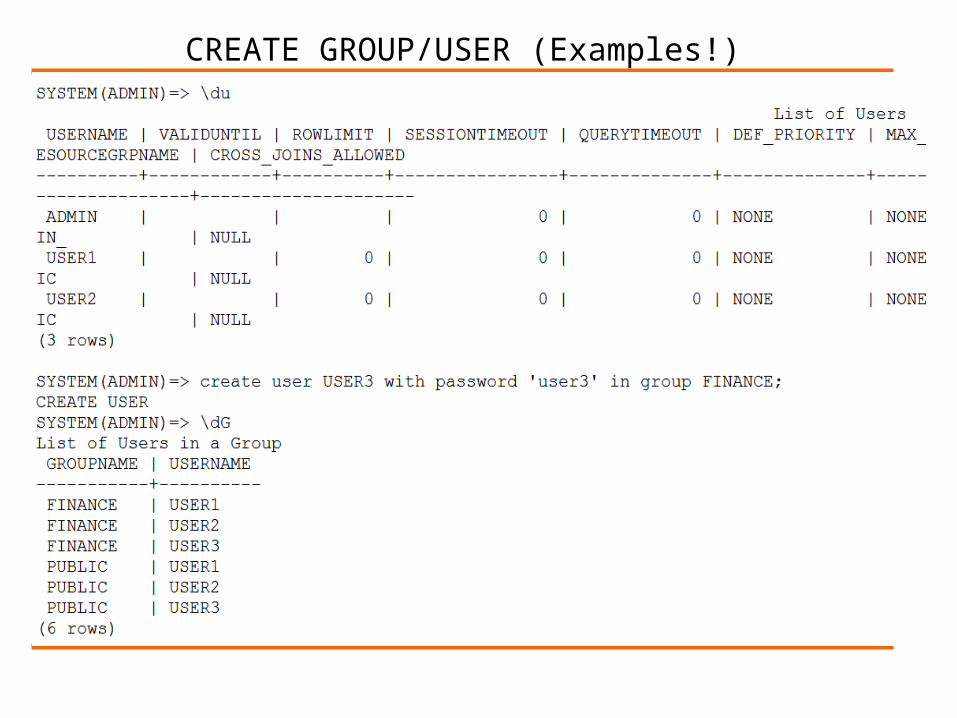
Create User Example:
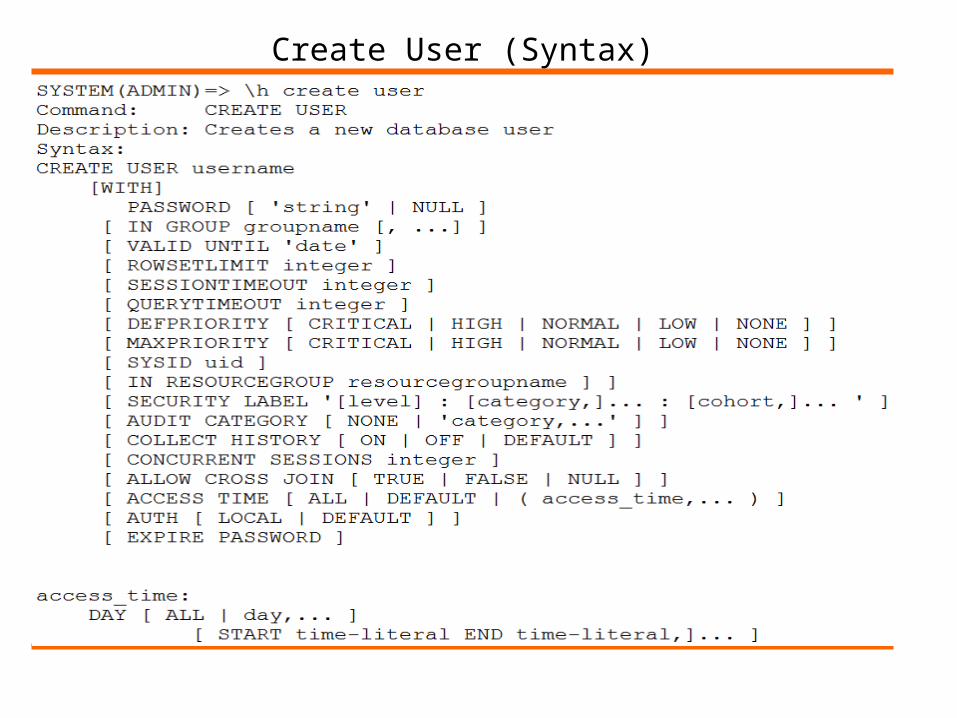
Create User (Syntax)
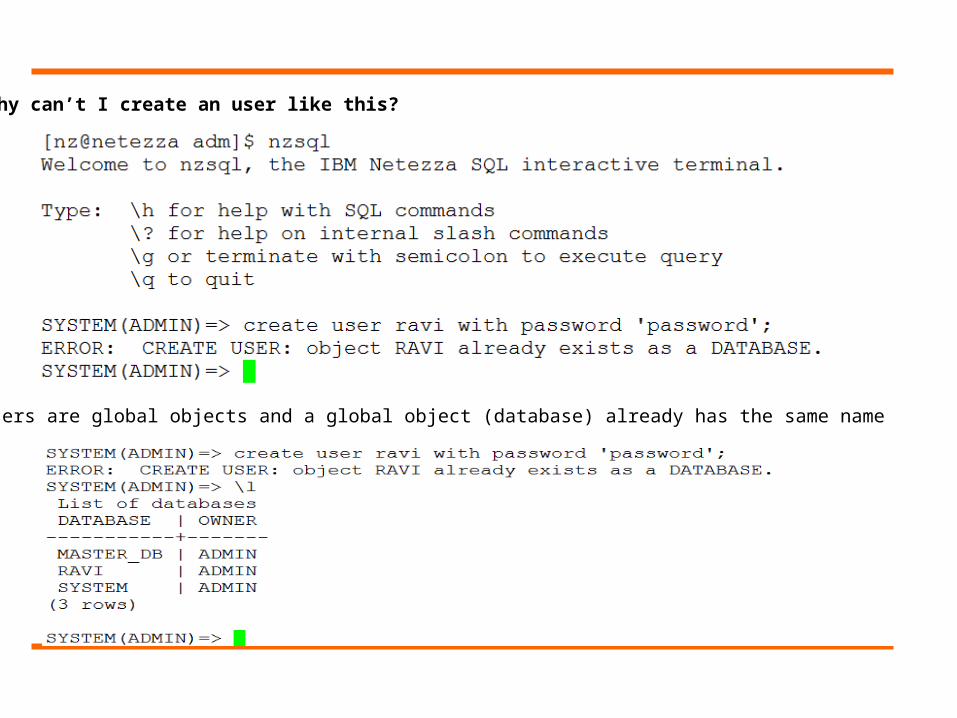
Why can’t I create an user like this?
Yes, users are global objects and a global object (database) already has the same name
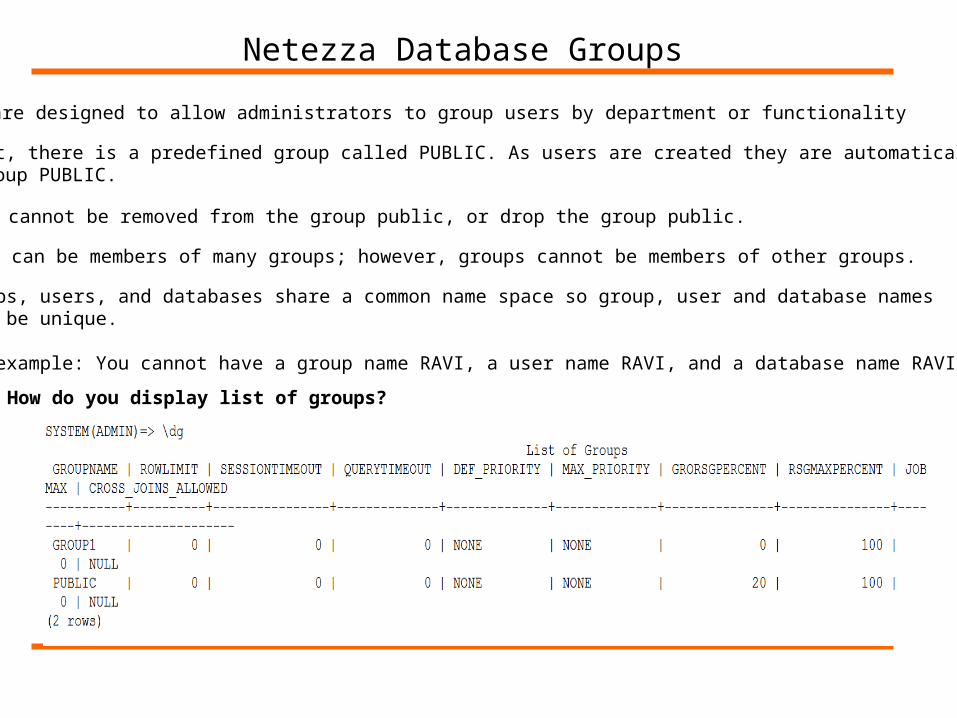
Netezza Database Groups
Groups are designed to allow administrators to group users by department or functionality
By default, there is a predefined group called PUBLIC. As users are created they are automatically added To the group PUBLIC.
Users cannot be removed from the group public, or drop the group public.
Users can be members of many groups; however, groups cannot be members of other groups.
Groups, users, and databases share a common name space so group, user and database namesmust be unique.
For example: You cannot have a group name RAVI, a user name RAVI, and a database name RAVI
How do you display list of groups?

Groups Creation (Syntax)
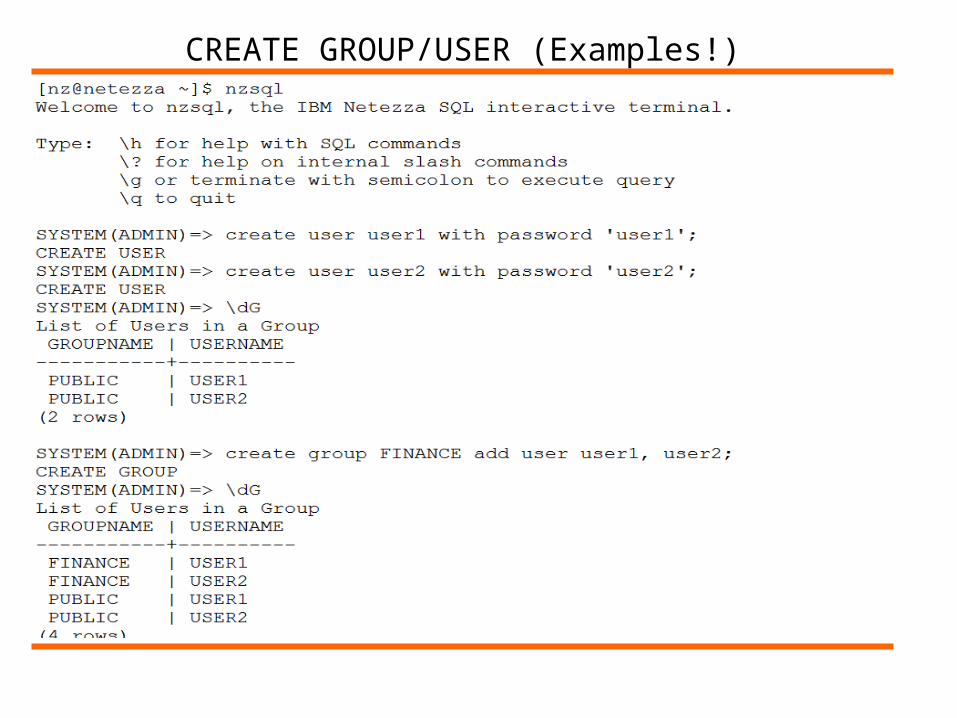
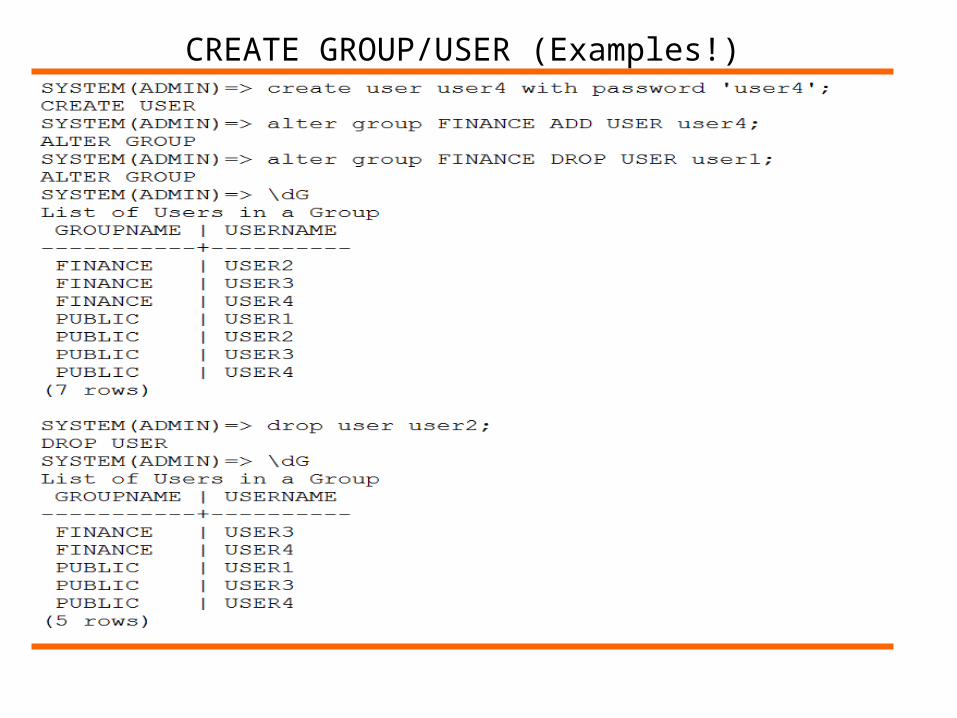
CREATE GROUP/USER (Examples!)
CREATE GROUP/USER (Examples!)
CREATE GROUP/USER (Examples!)

nz(nz): Linux user, not exposed to NPS client users
admin(password): NPS database super-user for the NPS host software, with full access to all system functions and objects at all times
root(Netezza): Linux super-user which provides system root login
Default Users & Passwords
The default database group is called public. All users are automatically assigned as members of the public group. You cannot delete the public group, or remove users from it.

Privileges
Netezza has two types of privileges:(1) Object Privileges(2) Administrative Privileges
Object privileges apply to individual object instances. Administrative privileges apply to the system as a whole.
List of Object Privileges:
Abort: Allows the user to abort sessions. i.e., you can use nzsession command
All: Allows the user to have all the object privileges
Alter: Allows the user to modify the object attributes
Delete: Allows the user to delete table rows
Drop: Allows the user to drop all objects
Execute: Allows the user to execute UDFs and UDAs in SQL queries
GenStats: Allows the user to generate statistics on tables/databases
Groom: Allows the user to run GROOM TABLE command
Insert: Allows the user to insert rows into a table

List: Allows the user to display an object name
Select: Allows the user to select (or query) rows within a table
Truncate: Allows the user to delete all rows from a table
Update: Allows the user to modify table rows
List of Administrator Privileges:
Backup: Allows the user to perform backups. The user can run nzbackup command
[Create] Aggregate: Allows the user to create user-defined aggregates (UDA’s) and to operate on existing UDAs.[Create] Database: Allows the user to create a databases
[Create] External Table: Allows the user to create external tables. Permissions to operate on existing tables is controlled by object privileges.
[Create] Function: Allows the user to create user-defined functions (UDF’s) and to operate on existing UDFs.
[Create] Group: Allows the user to create groups. Permissions to operate on existing groups is controlled by object privileges
Privileges

[Create] Index: For system use only. User cannot create indexes
[Create] Library: Allows the user to create user-defined shared libraries.
[Create] Materialized View: Allows the user to create Materialized views
[Create] Procedure: Allows the user to create stored procedures
[Create] Sequence: Allows the user to create sequences
[Create] Synonym: Allows the user to create synonyms
[Create] Table: Allows the user to create tables
[Create] Temp Table: Allows the user to create temporary tables
[Create] User: Allows the user to create users
[Create] View: Allows the user to create views
[Manage] Hardware: Allows the user to do the following hardware-related operations: View hardware status, manage SPUs, manage topology and mirroring, and run diagnostic tests. The user can run nzds and nzhw commands
Privileges

[Manage] Security: Allows the user to run commands and operations that relate to history databases such as creating and cleaning up history databases
[Manage] System: Allows the user to do management operations. For example: nzsystem, nzstate, nzstats, and nzsession priority
restore: Allows the user to restore the system. can run nzrestore command
Unfence: Allows the user to create an unfenced user-defined function (UDF) or user-defined aggregate(UDF)
Privileges

Grant Syntax
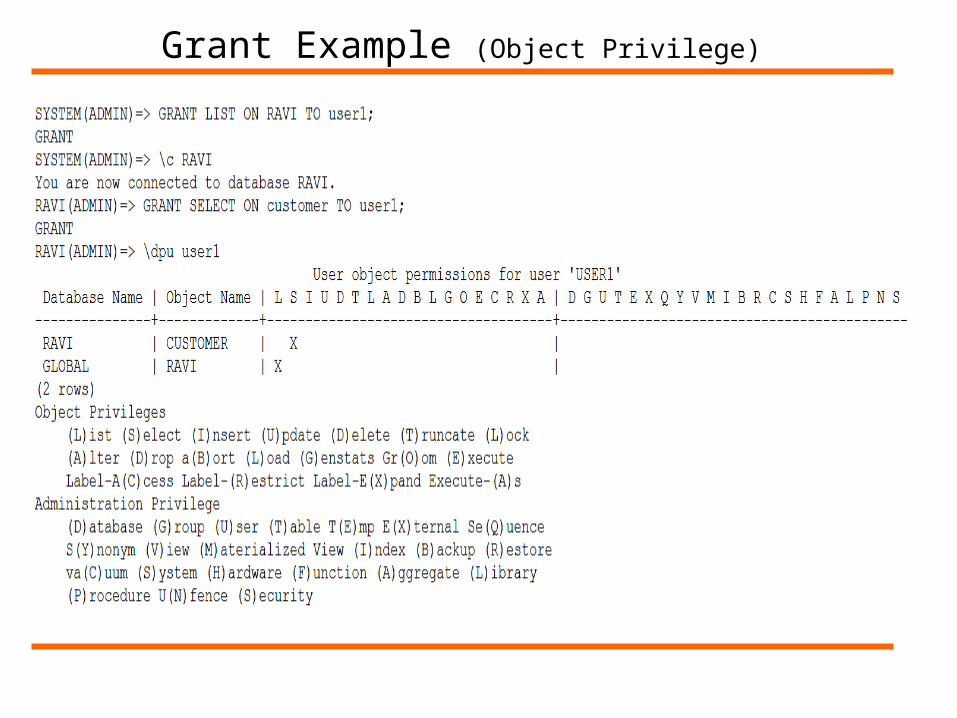
Grant Example (Object Privilege)
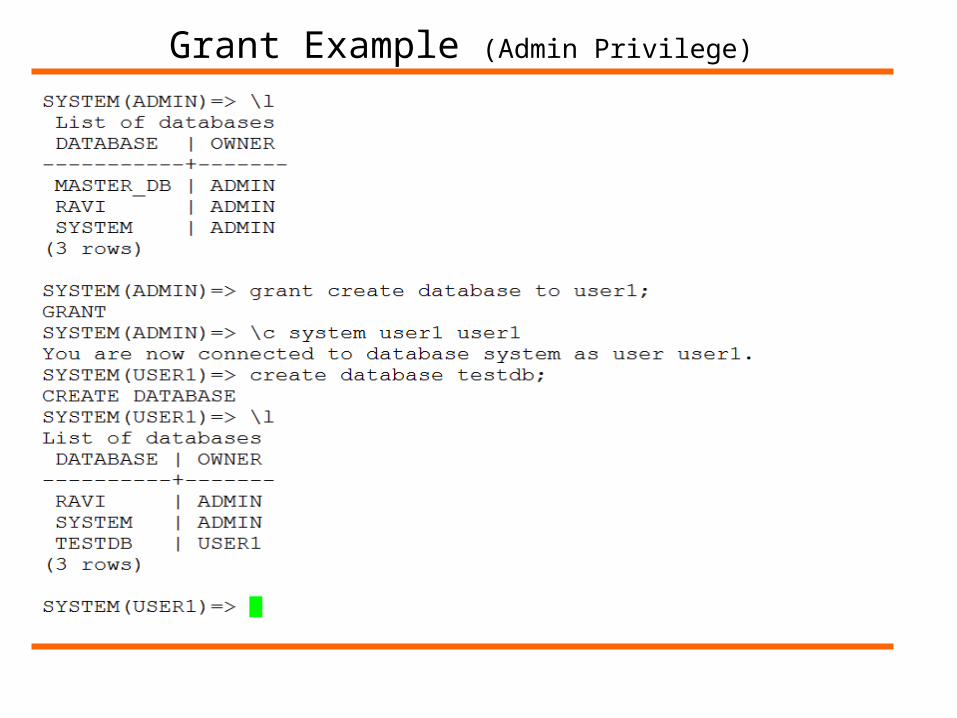
Grant Example (Admin Privilege)

REVOKE Syntax

SQL IDENTIFIERS

Types of Identifiers
There are 2 types of Identifiers in Netezza
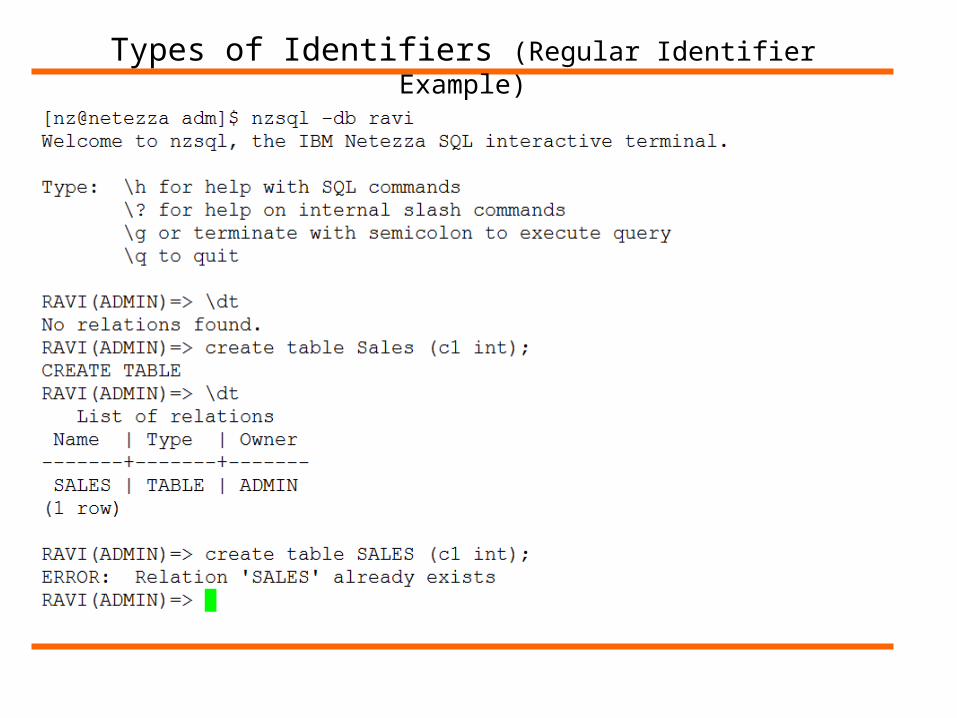
• Regular Identifiers
• Are case-insensitive
• Are converted to default system case
• For example: Sales and SALES are the equivalent
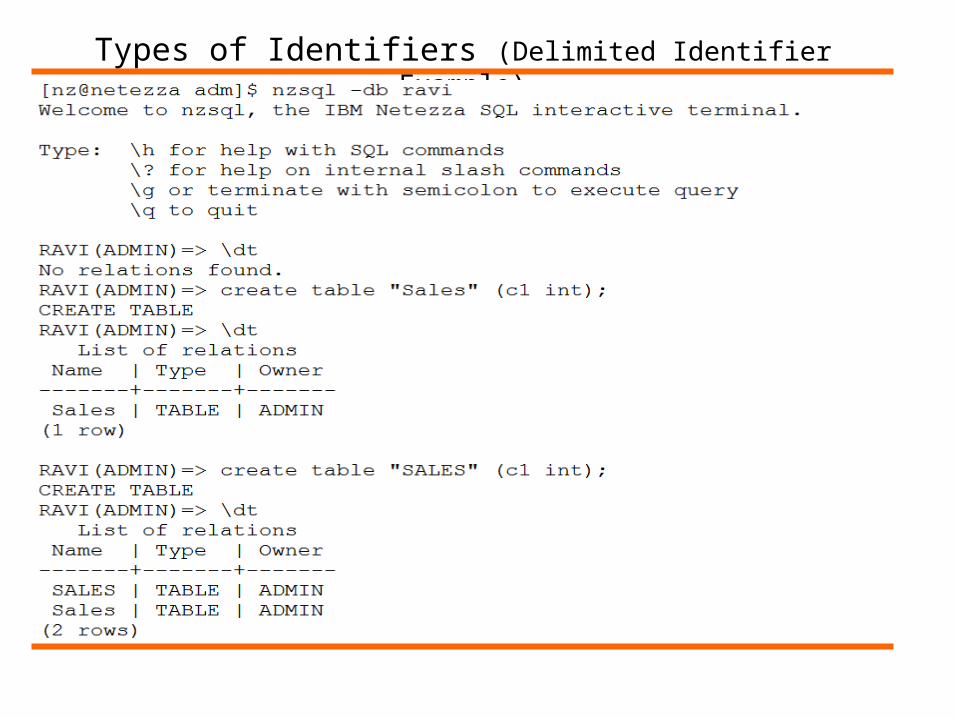
• Delimited Identifiers
• Are enclosed in double-quotation marks
• Are case-sensitive
• Are not converted to default system case
• For example: “Sales” and “SALES” are different
Types of Identifiers (Regular Identifier Example)
Types of Identifiers (Delimited Identifier Example)
SEQUENCE

What is a sequence?
A sequence is a named object in a database that can be used to generate unique numbers
A sequence may be byteint, smallint, integer, bigint
You can use sequence values wherever you would use numeric values
You can create, alter, and drop named sequences
Syntax:CREATE SEQUENCE sequence_name AS data_type[<options>];
where the options are the following:> START WITH start_value> INCREMENT BY increment_value> NO MINVALUE | MINVALUE minimum_value> NO MAXVALUE | MAXVALUE maximum_value> NO CYCLE | CYCLE


Sequences do not support cross database access; you cannot obtain a sequence value from a sequence defined in a different database.

Questions?

















