207
Opaque: A Secure Distributed Data Analytics Framework Wenting Zheng, Ankur Dave, Jethro Beekman, Raluca Ada Popa, Joseph Gonzalez, Ion Stoica
| Date post: | 12-Apr-2017 |
| Category: |
Data & Analytics |
| Upload: | spark-summit |
| View: | 293 times |
| Download: | 2 times |

Opaque: A Secure Distributed Data Analytics
FrameworkWenting Zheng, Ankur Dave, Jethro Beekman, Raluca Ada Popa, Joseph Gonzalez, Ion Stoica

Complex analytics run on sensitive data
client cloud provider
sensitive data

Complex analytics run on sensitive data
client
Spark SQL MLLib GraphX Spark
Streaming
cloud provider
sensitive data

Complex analytics run on sensitive data
client
Spark SQL MLLib GraphX Spark
Streaming
cloud provider
sensitive data






Threat model
client cloud provider
sensitive data

Threat model
client cloud provider
sensitive data
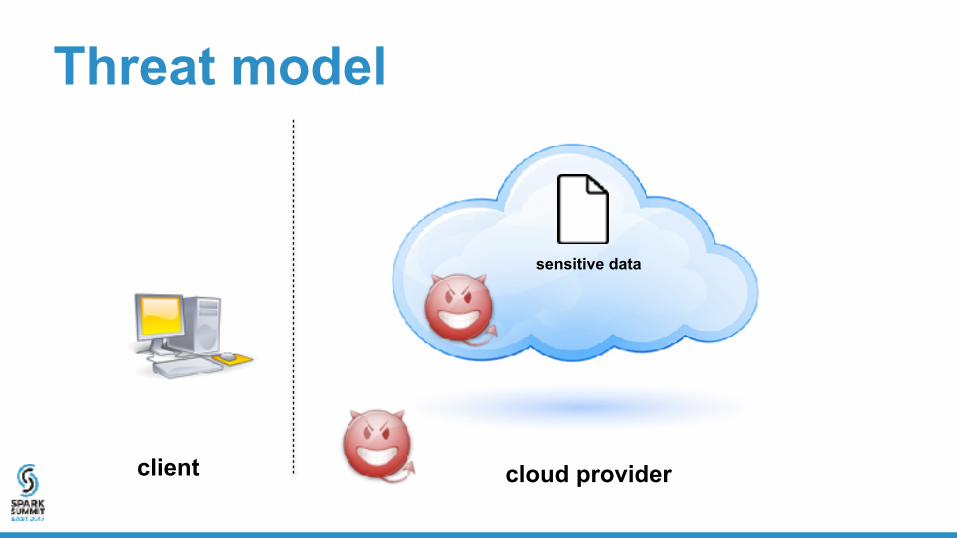
Threat model
client cloud provider
sensitive data

Threat model
client cloud provider
sensitive data

Challenge: protect data and preserve functionality

Spark SQL
Opaque*: secure data analytics
* Oblivious Platform for Analytic QUEries
SQL Machine Learning
Graph Analytics

Spark SQLOpaque
Opaque*: secure data analytics
* Oblivious Platform for Analytic QUEries
SQL Machine Learning
Graph Analytics

Prior work

Prior work• Computation on encrypted data

Prior work• Computation on encrypted data
– A cryptographic approach using homomorphic encryption

Prior work• Computation on encrypted data
– A cryptographic approach using homomorphic encryption– Either impractically slow (FHE), or limited functionality (CryptDB)

Prior work• Computation on encrypted data
– A cryptographic approach using homomorphic encryption– Either impractically slow (FHE), or limited functionality (CryptDB)
• Hardware-based systems

Prior work• Computation on encrypted data
– A cryptographic approach using homomorphic encryption– Either impractically slow (FHE), or limited functionality (CryptDB)
• Hardware-based systems– Use trusted hardware

Prior work• Computation on encrypted data
– A cryptographic approach using homomorphic encryption– Either impractically slow (FHE), or limited functionality (CryptDB)
• Hardware-based systems– Use trusted hardware – Only single machine computation (Haven), or weaker security
guarantees (VC3)

Prior work• Computation on encrypted data
– A cryptographic approach using homomorphic encryption– Either impractically slow (FHE), or limited functionality (CryptDB)
• Hardware-based systems– Use trusted hardware – Only single machine computation (Haven), or weaker security
guarantees (VC3)
Opaque utilizes trusted hardware

Hardware enclaves

Hardware enclaves• Hardware-protected containers in
presence of malicious OS

Hardware enclaves• Hardware-protected containers in
presence of malicious OS

Hardware enclaves• Hardware-protected containers in
presence of malicious OS

Hardware enclaves• Hardware-protected containers in
presence of malicious OS
Untrusted OS

Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
Untrusted OS
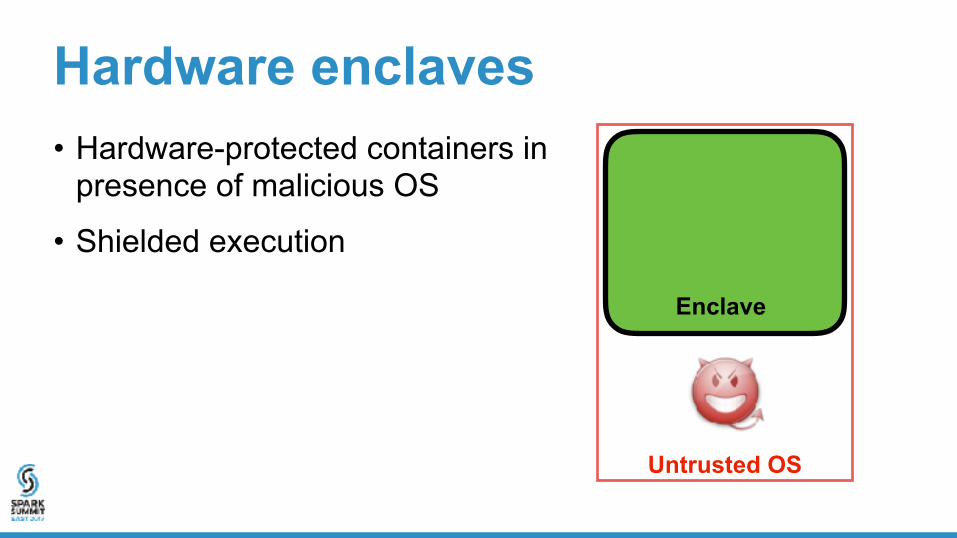
Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
• Shielded execution
Untrusted OS

Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
• Shielded execution
Untrusted OS
Secret data

Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
• Shielded execution
Untrusted OS
Secret data Code

Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
• Shielded execution
• Encrypted enclave memory
Untrusted OS
Secret data Code
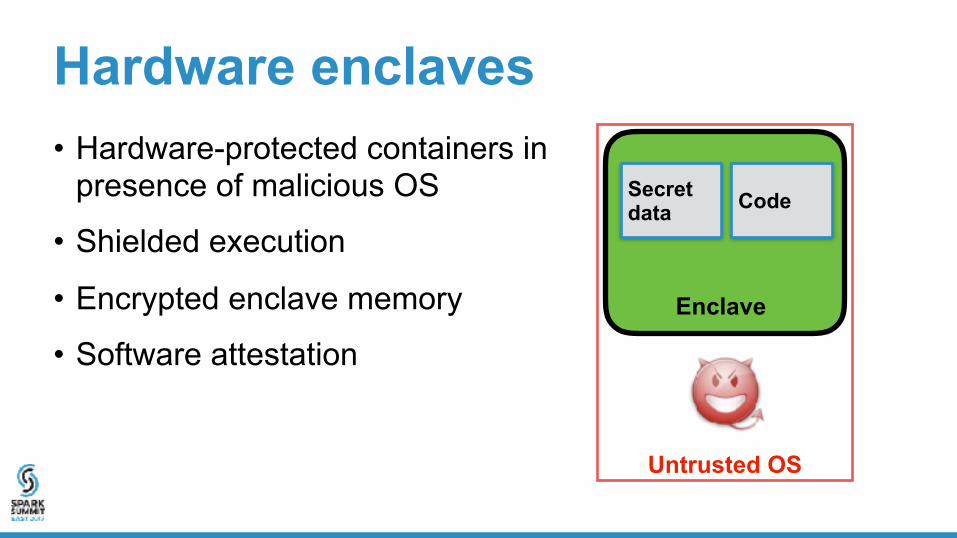
Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
• Shielded execution
• Encrypted enclave memory
• Software attestation
Untrusted OS
Secret data Code

Enclave
Hardware enclaves• Hardware-protected containers in
presence of malicious OS
• Shielded execution
• Encrypted enclave memory
• Software attestation
• Example: Intel SGX, AMD memory encryption Untrusted OS
Secret data Code

System initialization
Database
Client Server

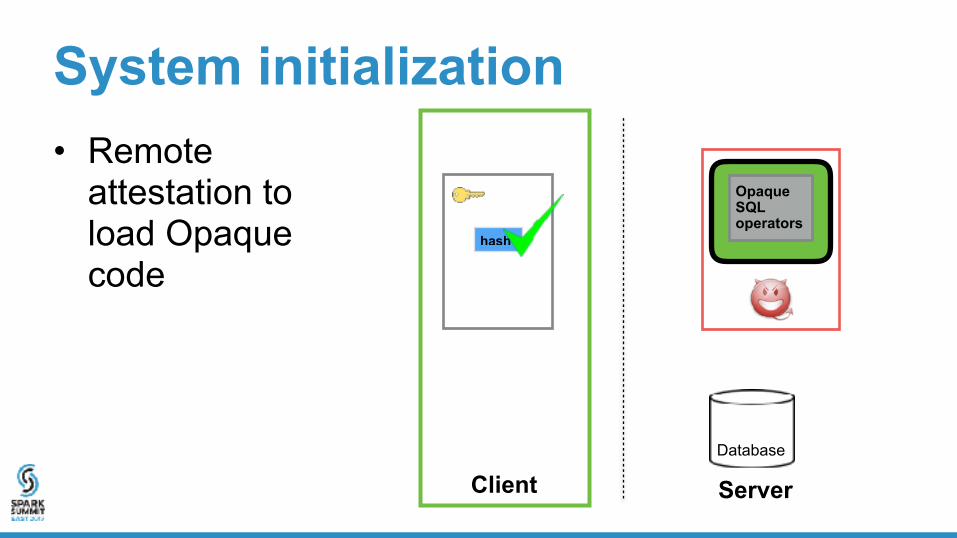
System initialization• Remote
attestation to load Opaque code
Database
Client Server

System initialization• Remote
attestation to load Opaque code
Opaque SQL operators
Database
Client Server
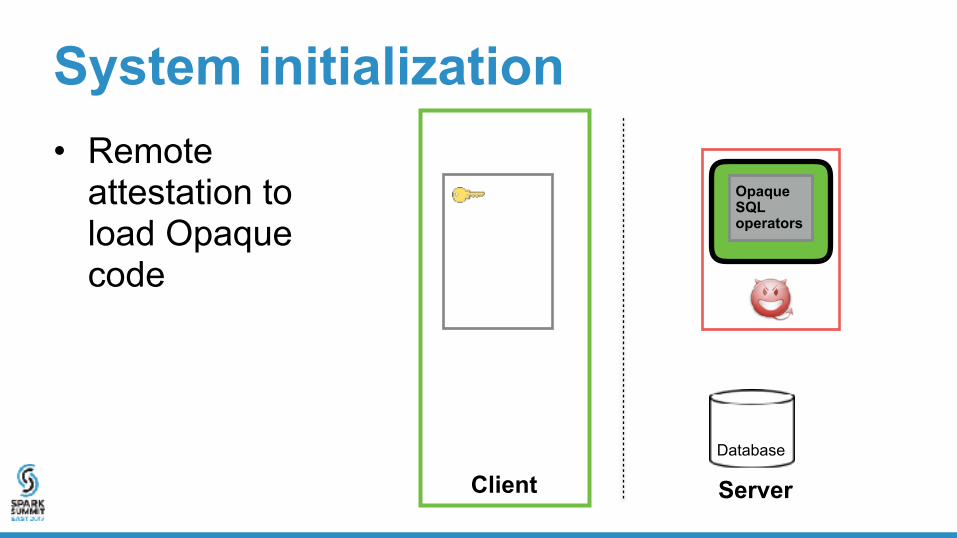
System initialization• Remote
attestation to load Opaque code
Opaque SQL operators
Database
Client Server

System initialization• Remote
attestation to load Opaque code
Opaque SQL operators
hash
Database
Client Server

System initialization• Remote
attestation to load Opaque code
Opaque SQL operators
hash
Database
Client Server
System initialization• Remote
attestation to load Opaque code
Opaque SQL operators
hash
Database
Client Server

System initialization• Remote
attestation to load Opaque code
Database
Client Server

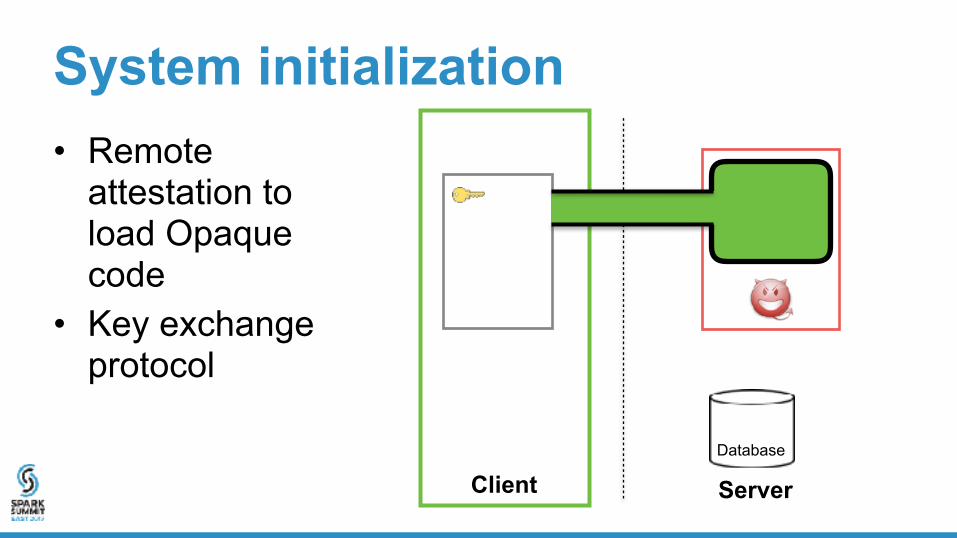
System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
Database
Client Server
System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
Database
Client Server

System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
Database
Client Server

System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
Database
Client Server

System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
Database
Client Server

System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
Database
Client Server
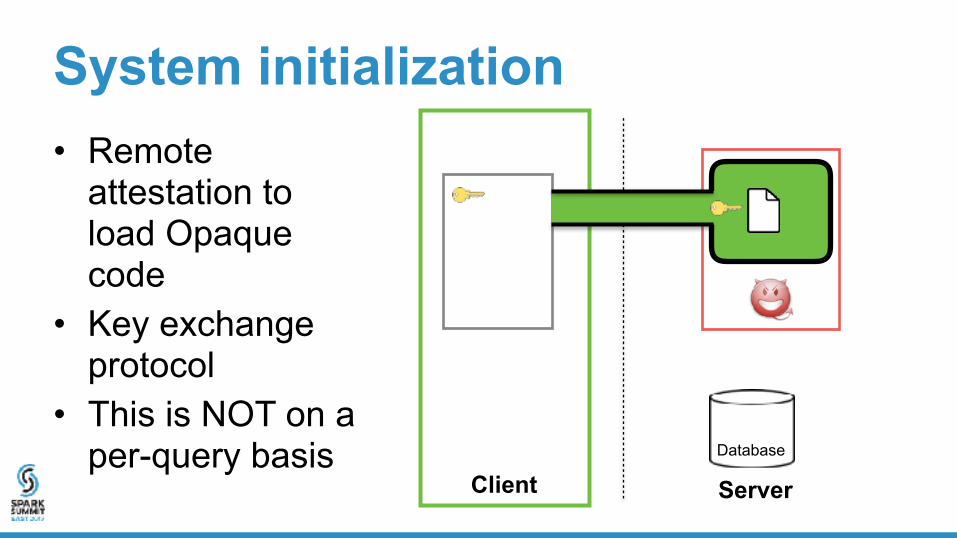
System initialization• Remote
attestation to load Opaque code
• Key exchange protocol
• This is NOT on a per-query basis Database
Client Server

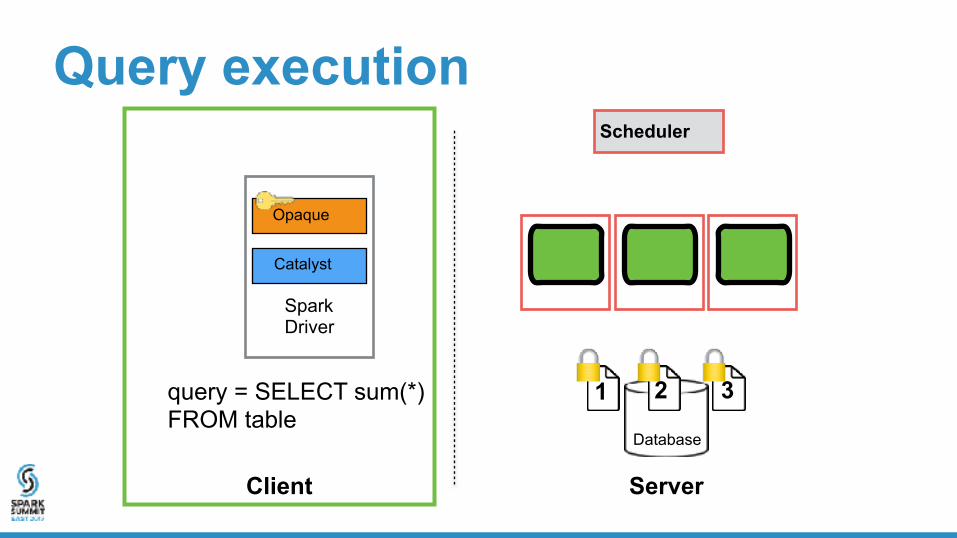
Spark Driver
Opaque
Catalyst
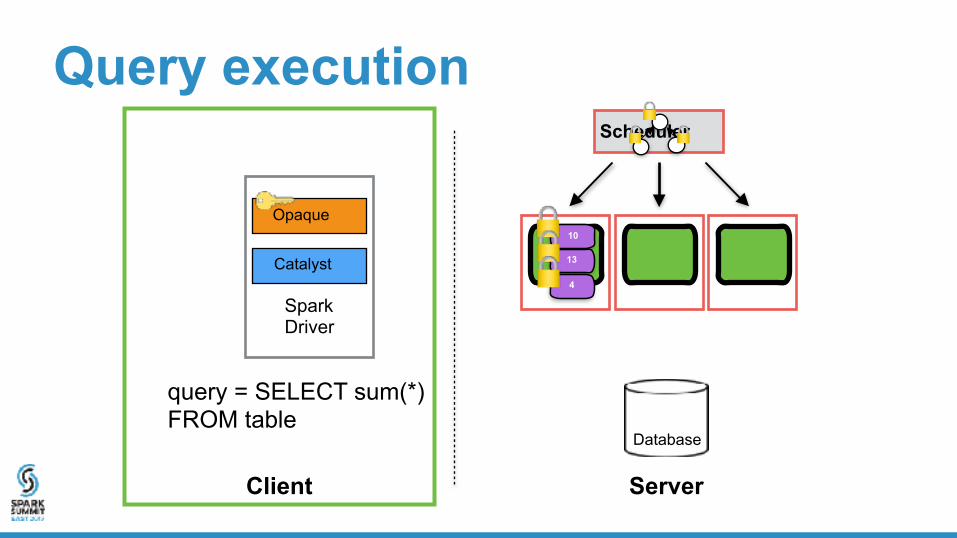
Query execution
Client Server
Database
Scheduler
1 2 3
Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3query = SELECT sum(*) FROM table
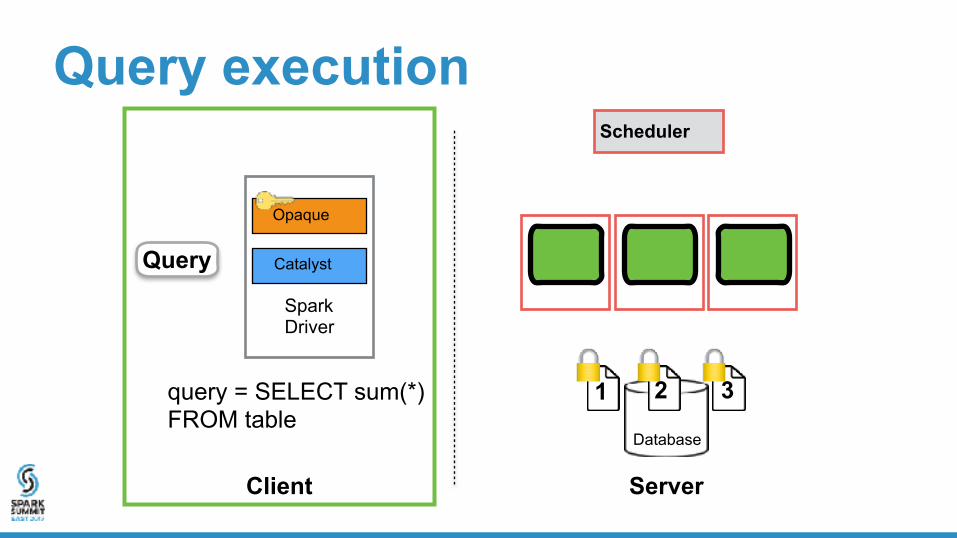
Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3
Query
query = SELECT sum(*) FROM table

Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3
Query
query = SELECT sum(*) FROM table

Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3query = SELECT sum(*) FROM table

Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3query = SELECT sum(*) FROM table

Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3query = SELECT sum(*) FROM table
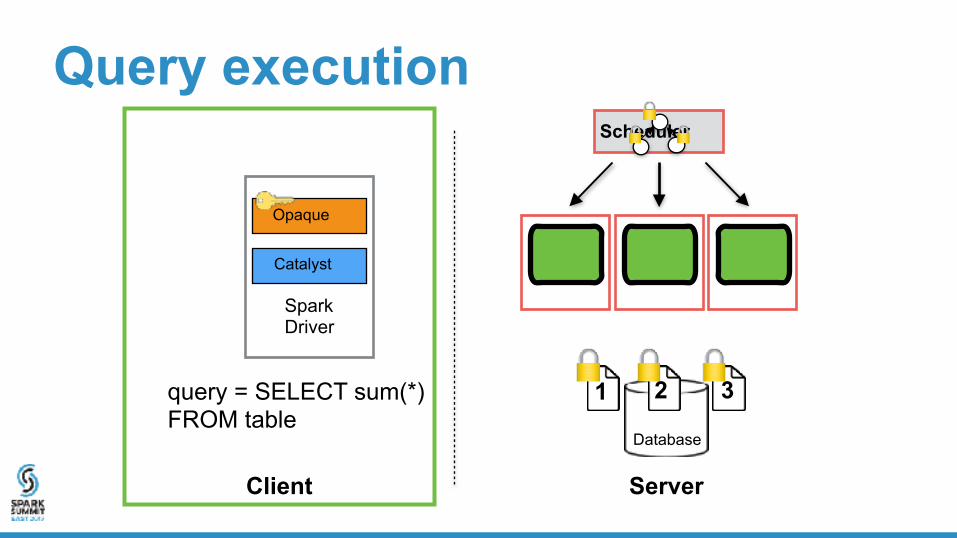
Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3query = SELECT sum(*) FROM table
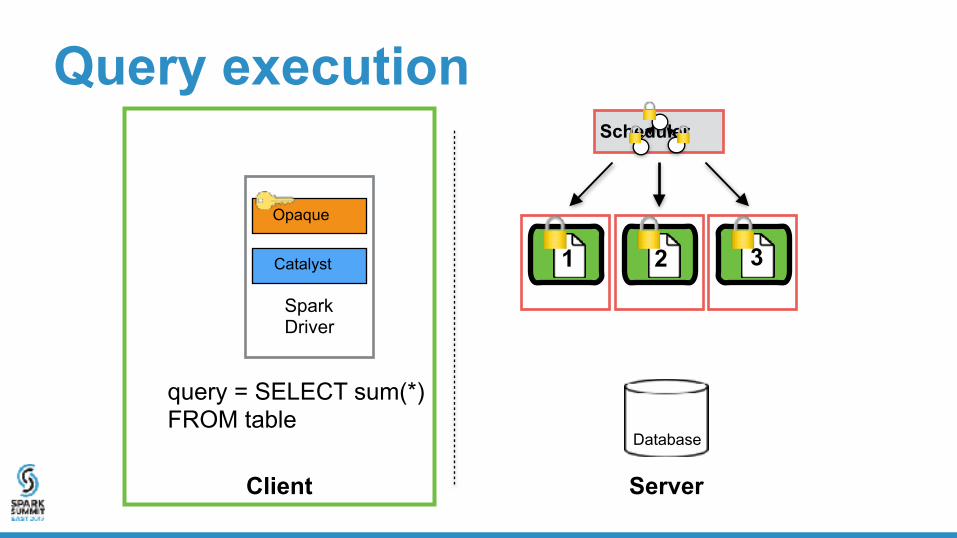
Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
1 2 3
query = SELECT sum(*) FROM table
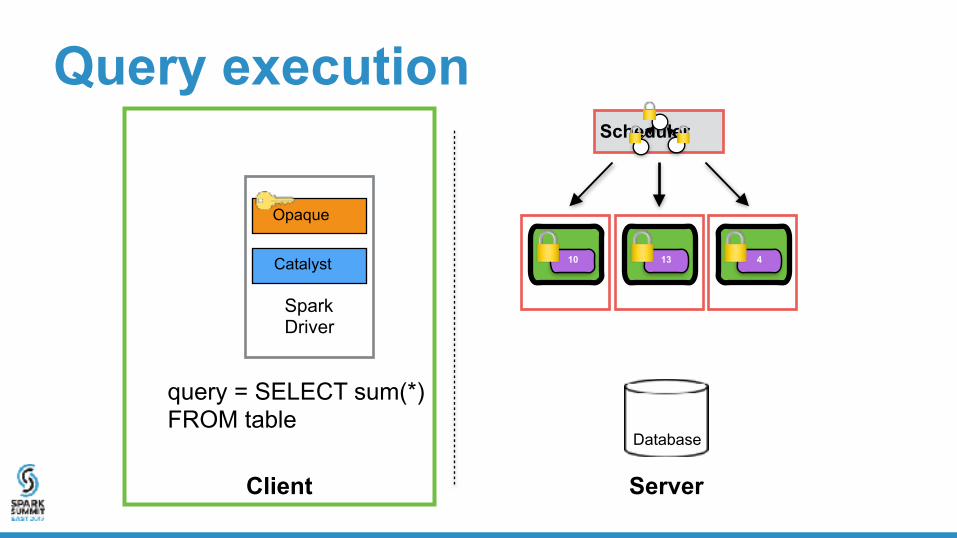
Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
query = SELECT sum(*) FROM table
10 13 4
Spark Driver
Opaque
Catalyst
Query execution
Client Server
Database
Scheduler
query = SELECT sum(*) FROM table
10
13
4

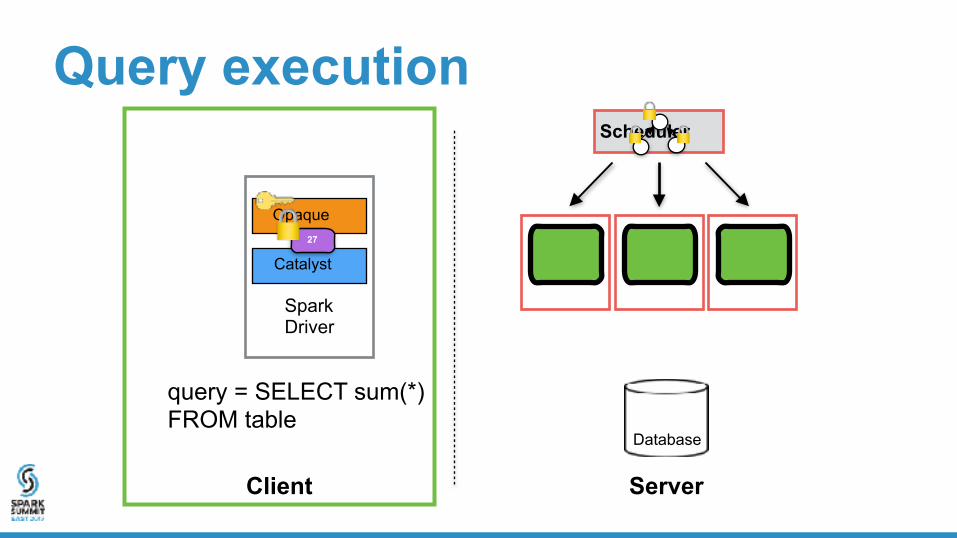
Spark Driver
Opaque
Catalyst 27
Query execution
Client Server
Database
Scheduler
query = SELECT sum(*) FROM table
Spark Driver
Opaque
Catalyst
27
Query execution
Client Server
Database
Scheduler
query = SELECT sum(*) FROM table

Problem: cloud can alter distributed computation

Problem: cloud can alter distributed computation
• Drop data

Problem: cloud can alter distributed computation
• Drop data• Modify data

Problem: cloud can alter distributed computation
• Drop data• Modify data• Skip task

Problem: cloud can alter distributed computation
• Drop data• Modify data• Skip task• Replay old state

Example: drop data
Spark Driver
Opaque
Catalyst
Server
Database
Scheduler
1 2 3
Client
query = SELECT sum(*) FROM table

Example: drop data
Spark Driver
Opaque
Catalyst
Server
Database
Scheduler
1 2 3
Client
query = SELECT sum(*) FROM table

Example: drop data
Spark Driver
Opaque
Catalyst
Server
Database
Scheduler
10 13 4
Client
query = SELECT sum(*) FROM table

Example: drop data
Spark Driver
Opaque
Catalyst
Server
Database
Scheduler
10
13
Client
query = SELECT sum(*) FROM table

Example: drop data
Spark Driver
Opaque
Catalyst
Server
Database
Scheduler
23
Client
query = SELECT sum(*) FROM table

Example: drop data
Spark Driver
Opaque
Catalyst
Server
Database
Scheduler
23
Client
query = SELECT sum(*) FROM table

Self-verifying computation

Self-verifying computation
Invariant: if computation does not abort, the execution completed so far is correct

Self-verifying computation
Invariant: if computation does not abort, the execution completed so far is correct

Self-verifying computation
Invariant: if computation does not abort, the execution completed so far is correct
If the computation is complete, then the entire query was executed correctly
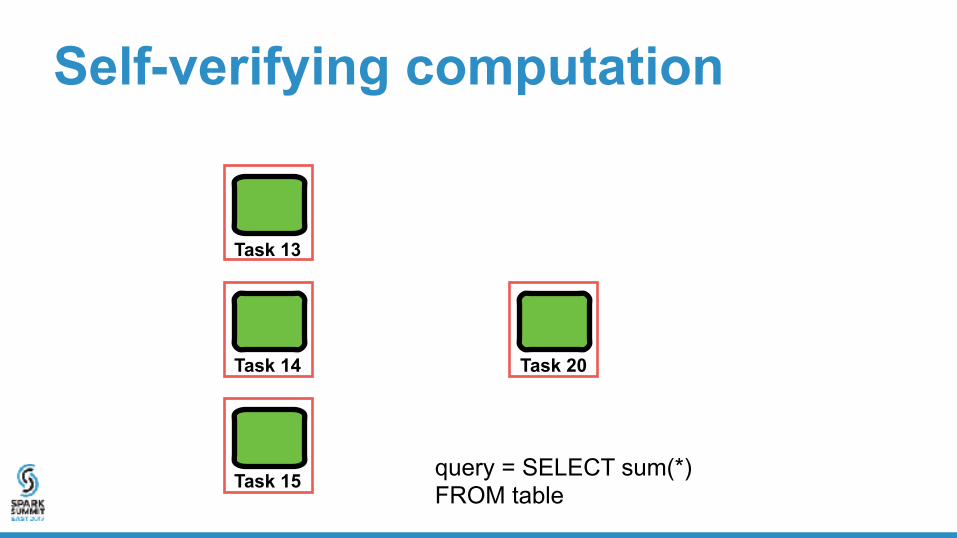
Self-verifying computation
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table
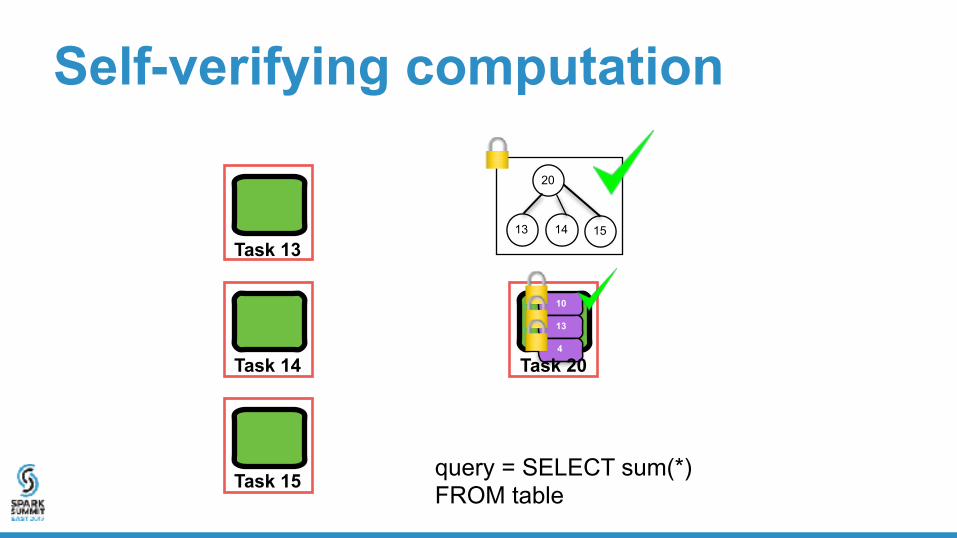
Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

Self-verifying computation
20
1413 15
10
13
4
Task 13
Task 14
Task 15
Task 20
query = SELECT sum(*) FROM table

ID Name Age Disease12809 Amanda D. Edwards 40 Diabetes29489 Robert R. McGowan 56 Diabetes13744 Kimberly R. Seay 51 Cancer18740 Dennis G. Bates 32 Diabetes98329 Ronald S. Ogden 53 Cancer
medical table:
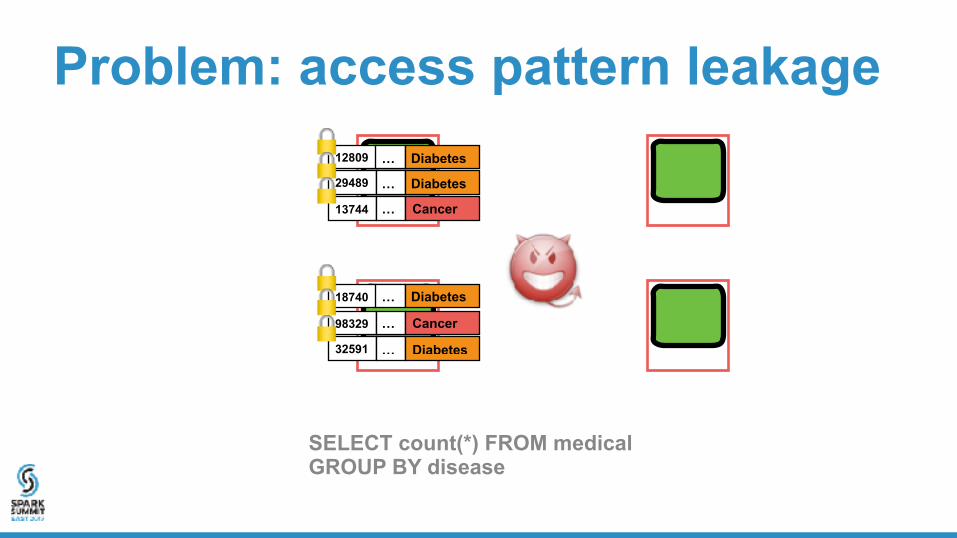
Problem: access pattern leakage
32591 Donna R. Bridges 26 Diabetes

ID Name Age Disease
SELECT count(*) FROM medical GROUP BY disease
12809 Amanda D. Edwards 40 Diabetes29489 Robert R. McGowan 56 Diabetes13744 Kimberly R. Seay 51 Cancer18740 Dennis G. Bates 32 Diabetes98329 Ronald S. Ogden 53 Cancer
medical table:
Problem: access pattern leakage
32591 Donna R. Bridges 26 Diabetes

Problem: access pattern leakage
SELECT count(*) FROM medical GROUP BY disease
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Problem: access pattern leakage
SELECT count(*) FROM medical GROUP BY disease
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes

Problem: access pattern leakage
SELECT count(*) FROM medical GROUP BY disease
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes

Problem: access pattern leakage12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Attack viable for both memory and network access patterns!

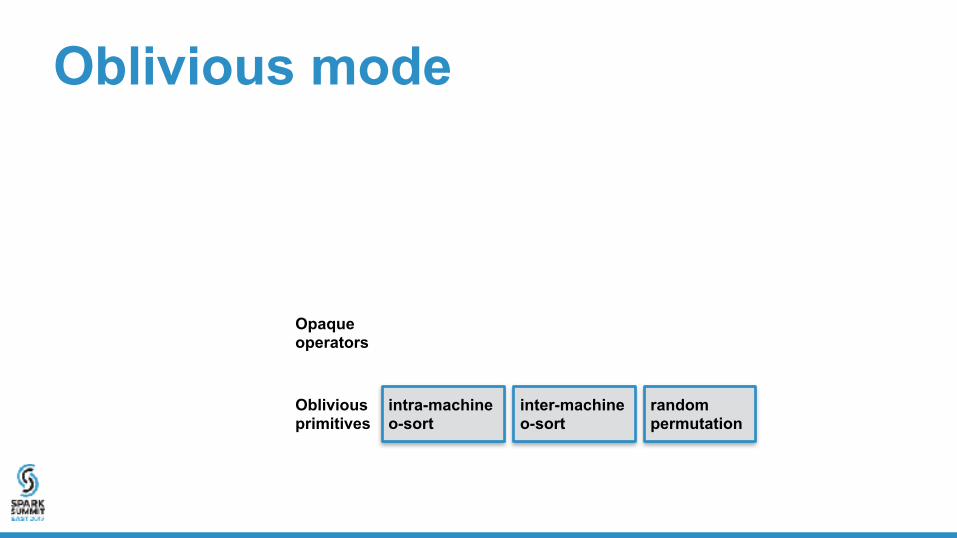
Oblivious mode

Oblivious mode
Oblivious primitives

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators
project-filter
low-cardinality agg.
sort-merge join
broadcast join …

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators
Oblivious operators
project-filter
low-cardinality agg.
sort-merge join
broadcast join …

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators
Oblivious operators
project-filter
low-cardinality agg.
sort-merge join
broadcast join …
Oblivious Filter
Oblivious Sort
Oblivious Aggregation
Oblivious Join

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators
Oblivious operators
project-filter
low-cardinality agg.
sort-merge join
broadcast join …
Oblivious Filter
Oblivious Sort
Oblivious Aggregation
Oblivious Join
Oblivious Query Plan

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators
Oblivious operators
project-filter
low-cardinality agg.
sort-merge join
broadcast join …
Oblivious Filter
Oblivious Sort
Oblivious Aggregation
Oblivious Join
Oblivious Query Plan{

Oblivious mode
intra-machine o-sort
inter-machine o-sort
random permutation
Oblivious primitives
Opaque operators
Oblivious operators
project-filter
low-cardinality agg.
sort-merge join
broadcast join …
Oblivious Filter
Oblivious Sort
Oblivious Aggregation
Oblivious Join
Oblivious Query Plan{Query optimization

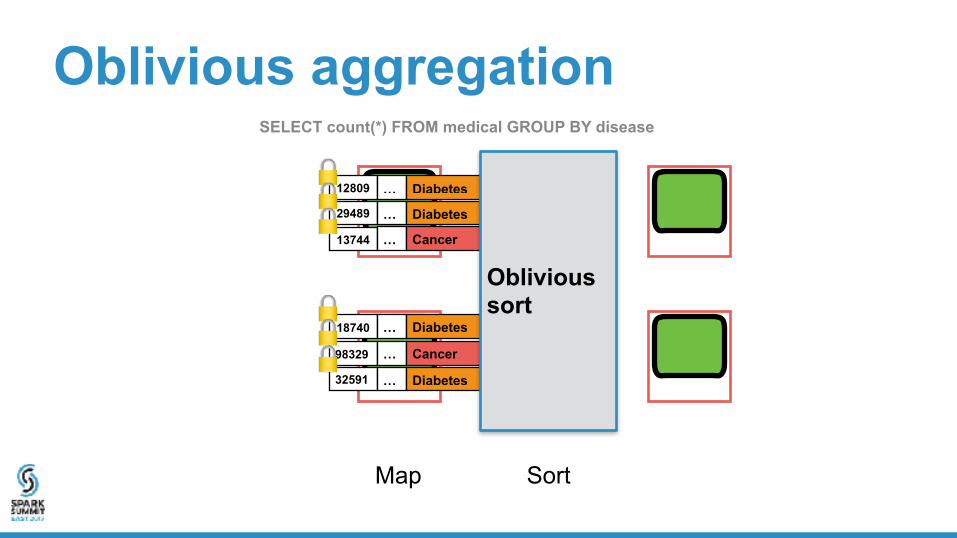
Oblivious aggregation
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Oblivious sort
SELECT count(*) FROM medical GROUP BY disease
Map Sort
Oblivious aggregation
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Oblivious sort
SELECT count(*) FROM medical GROUP BY disease
Map Sort

Oblivious aggregation
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Oblivious sort
SELECT count(*) FROM medical GROUP BY disease
Map Sort

Map Sort
Oblivious sort
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

Sort
Oblivious sort
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan
Statistics
Statistics
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
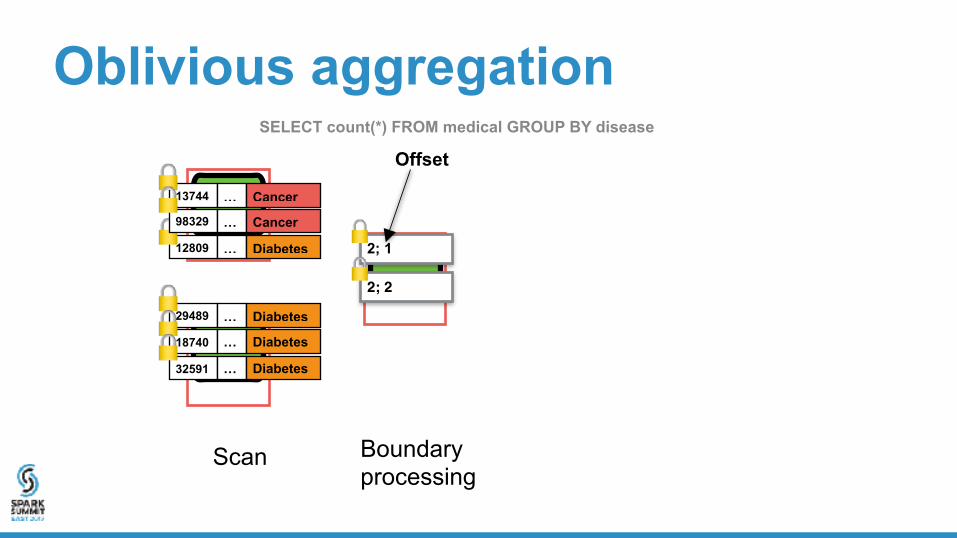
Scan Boundary processing
Statistics
Statistics
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing
Statistics
Statistics
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease
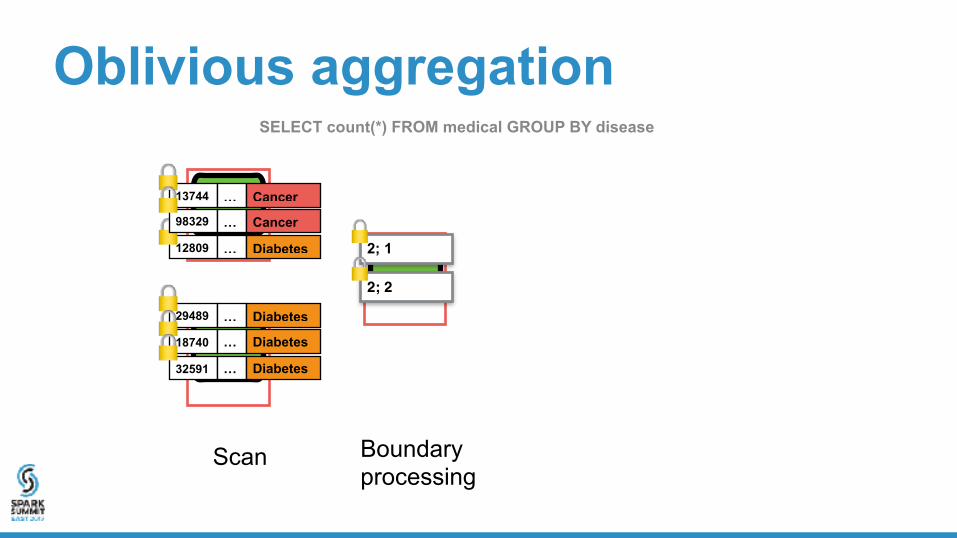
2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing
Result size
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease
2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing
Offset
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
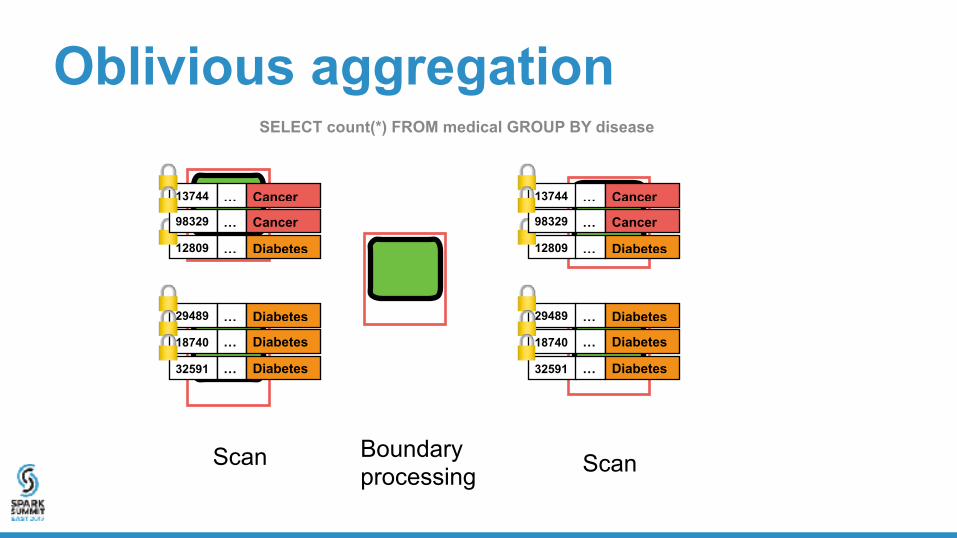
Scan Boundary processing Scan
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
2; 1
2; 2
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing Scan
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing Scan
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing Scan
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing Scan
Cancer:2
Diabetes:3
Diabetes:1
DUMMY
Final result
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
12809 … Diabetes
29489 … Diabetes
13744 … Cancer
18740 … Diabetes
98329 … Cancer
32591 … Diabetes
Scan Boundary processing Scan Final
result
Cancer:2
Diabetes:4
Oblivious aggregationSELECT count(*) FROM medical GROUP BY disease

Opaque modes

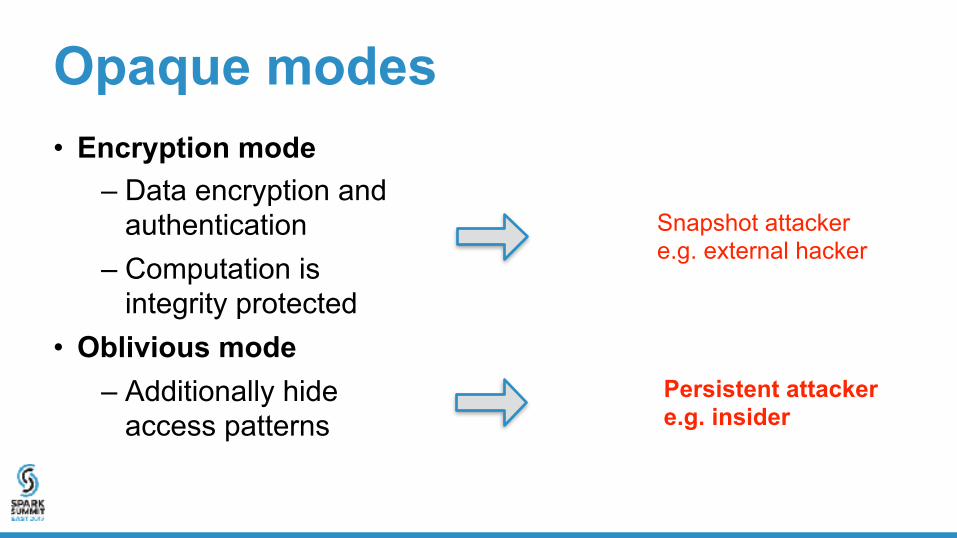
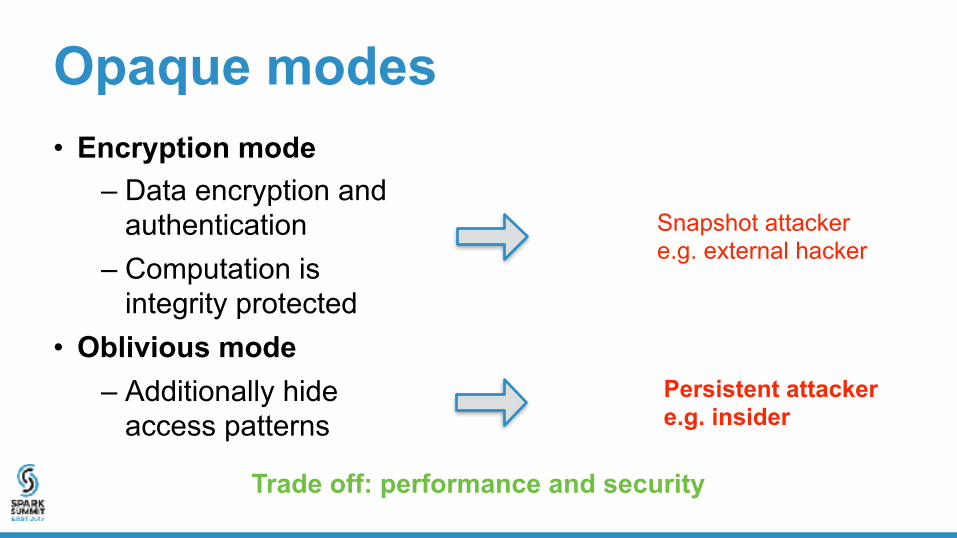
Opaque modes• Encryption mode

Opaque modes• Encryption mode
– Data encryption and authentication

Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected

Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected

Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected
Snapshot attacker e.g. external hacker

Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected
• Oblivious mode
Snapshot attacker e.g. external hacker

Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected
• Oblivious mode– Additionally hide
access patterns
Snapshot attacker e.g. external hacker

Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected
• Oblivious mode– Additionally hide
access patterns
Snapshot attacker e.g. external hacker
Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected
• Oblivious mode– Additionally hide
access patterns
Snapshot attacker e.g. external hacker
Persistent attacker e.g. insider
Opaque modes• Encryption mode
– Data encryption and authentication
– Computation is integrity protected
• Oblivious mode– Additionally hide
access patterns
Snapshot attacker e.g. external hacker
Persistent attacker e.g. insider
Trade off: performance and security

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Obliv. sort
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical

Project-filter
Filter
Query optimization - oblivious
SELECT count(*) FROM medical WHERE age > 30 GROUP BY disease
Low-card. obliv. agg.
Scan
Obliv. sort
Aggregate
medical
Reduced # of oblivious sorts by 1

D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
Query optimization - mixed sensitivity

D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
Query optimization - mixed sensitivity

D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
Query optimization - mixed sensitivity

Query optimization - mixed sensitivity

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
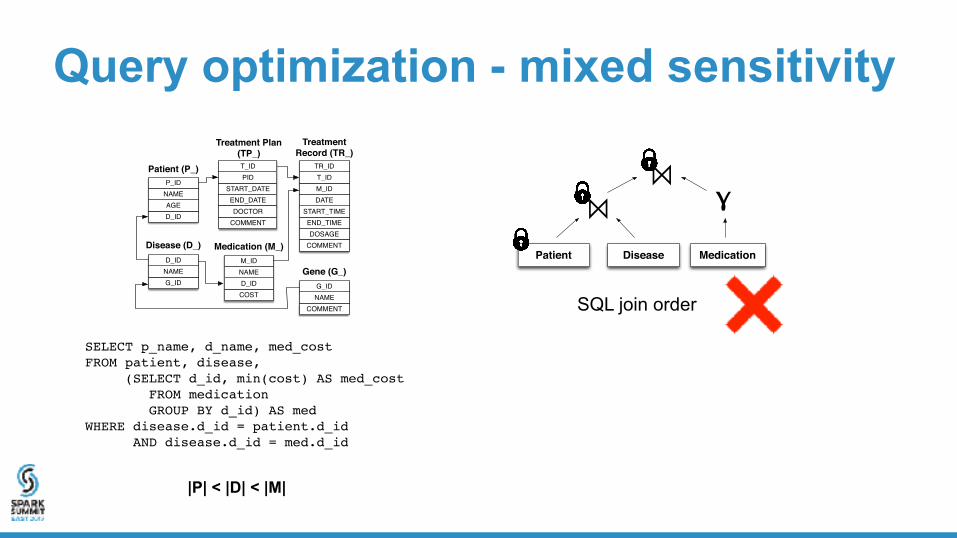
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
|P| < |D| < |M|

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
Patient Disease
⨝Medication
⨝ᵞ
|P| < |D| < |M|

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
Patient Disease
⨝Medication
⨝ᵞ
SQL join order
|P| < |D| < |M|
Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
Patient Disease
⨝Medication
⨝ᵞ
SQL join order
|P| < |D| < |M|

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
Patient Disease
⨝Medication
⨝ᵞ
Patient
Disease
⨝
Medication
⨝ ᵞ
SQL join order
|P| < |D| < |M|

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
Patient Disease
⨝Medication
⨝ᵞ
Patient
Disease
⨝
Medication
⨝ ᵞ
SQL join order
Opaque join order |P| < |D| < |M|

Query optimization - mixed sensitivity
D_IDAGENAMEP_ID
END_DATESTART_DATE
PID
COMMENTDOCTOR
T_ID
DOSAGEEND_TIMESTART_TIME
M_IDT_ID
COMMENT
DATE
TR_ID
G_IDNAMED_ID
COSTD_IDNAMEM_ID
COMMENTNAMEG_ID
Patient (P_)
Treatment Plan (TP_)
Treatment Record (TR_)
Disease (D_) Medication (M_)
Gene (G_)
SELECT p_name, d_name, med_costFROM patient, disease, (SELECT d_id, min(cost) AS med_cost FROM medication GROUP BY d_id) AS medWHERE disease.d_id = patient.d_id AND disease.d_id = med.d_id
Patient Disease
⨝Medication
⨝ᵞ
Patient
Disease
⨝
Medication
⨝ ᵞ
SQL join order
Opaque join order |P| < |D| < |M|

Evaluation setup

Evaluation setup• Single machine experiments
– Intel Xeon E3-1280 v5, 4 cores, 64 GB RAM – Intel SGX: 128 MB of enclave page cache (EPC) – Hardware mode

Evaluation setup• Single machine experiments
– Intel Xeon E3-1280 v5, 4 cores, 64 GB RAM – Intel SGX: 128 MB of enclave page cache (EPC) – Hardware mode
• Distributed experiments – EC2: five r3.2xlarge instances, 8 cores, 61 GB RAM – Simulation mode only

Evaluation

Evaluation• How does Opaque compare to Spark SQL?

Evaluation• How does Opaque compare to Spark SQL?
– Big Data Benchmark (BDB)

Evaluation• How does Opaque compare to Spark SQL?
– Big Data Benchmark (BDB)• Queries 1, 2, 3: filter, aggregation, join

Evaluation• How does Opaque compare to Spark SQL?
– Big Data Benchmark (BDB)• Queries 1, 2, 3: filter, aggregation, join• 1 million records

Evaluation• How does Opaque compare to Spark SQL?
– Big Data Benchmark (BDB)• Queries 1, 2, 3: filter, aggregation, join• 1 million records
• How does Opaque compare to state-of-the-art oblivious systems?

Evaluation• How does Opaque compare to Spark SQL?
– Big Data Benchmark (BDB)• Queries 1, 2, 3: filter, aggregation, join• 1 million records
• How does Opaque compare to state-of-the-art oblivious systems?
– GraphSC (graph analytics)

Evaluation• How does Opaque compare to Spark SQL?
– Big Data Benchmark (BDB)• Queries 1, 2, 3: filter, aggregation, join• 1 million records
• How does Opaque compare to state-of-the-art oblivious systems?
– GraphSC (graph analytics)• PageRank

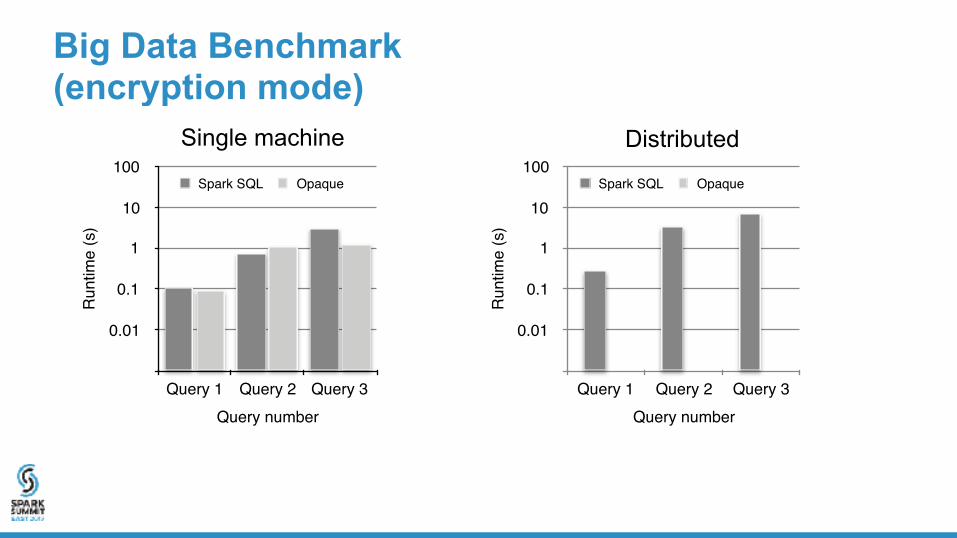
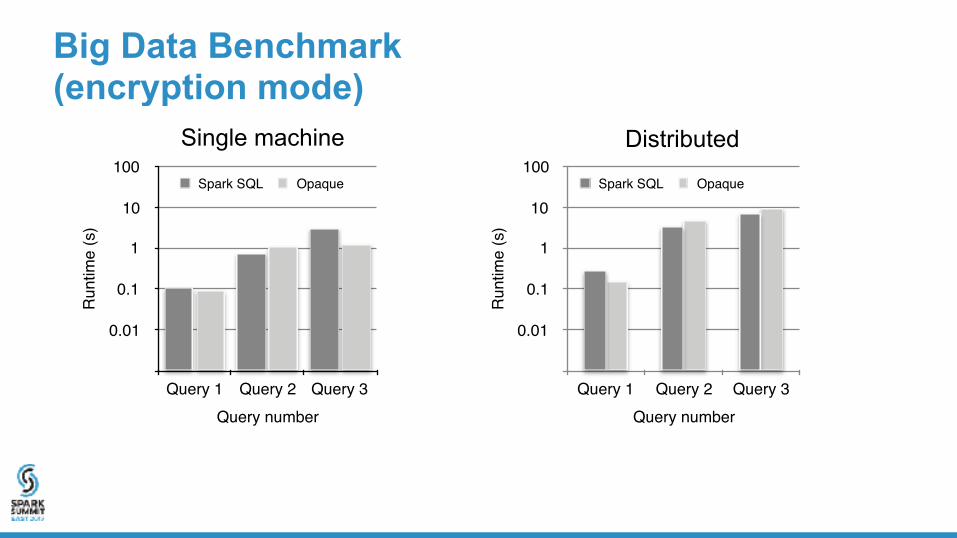
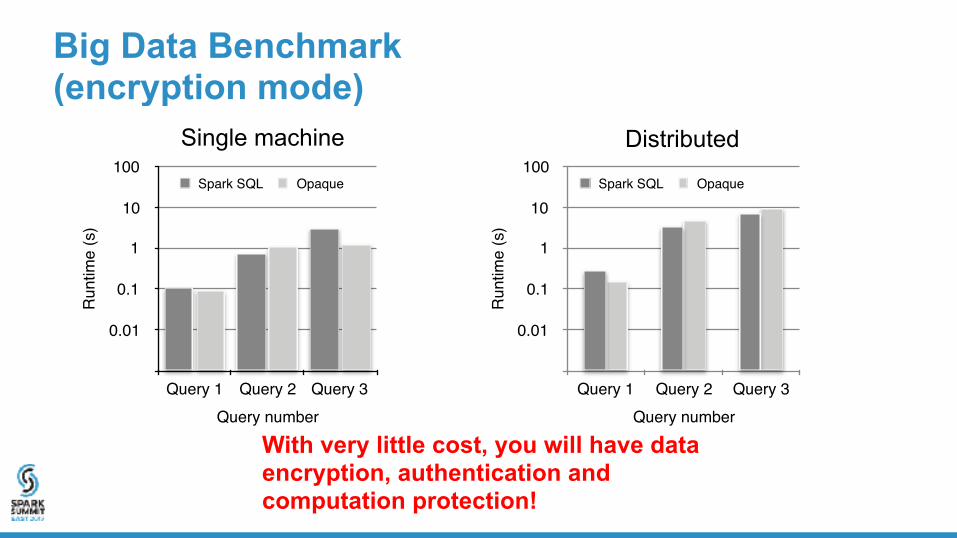
Big Data Benchmark (encryption mode)
Single machine

Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Single machine

Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Single machine

Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Single machine

Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
DistributedSingle machine

Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
DistributedSingle machine
Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
DistributedSingle machine
Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
DistributedSingle machine
Big Data Benchmark (encryption mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
Distributed
With very little cost, you will have data encryption, authentication and computation protection!
Single machine

Single machine Distributed
Big Data Benchmark (oblivious mode)

Single machine Distributed
Big Data Benchmark (oblivious mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
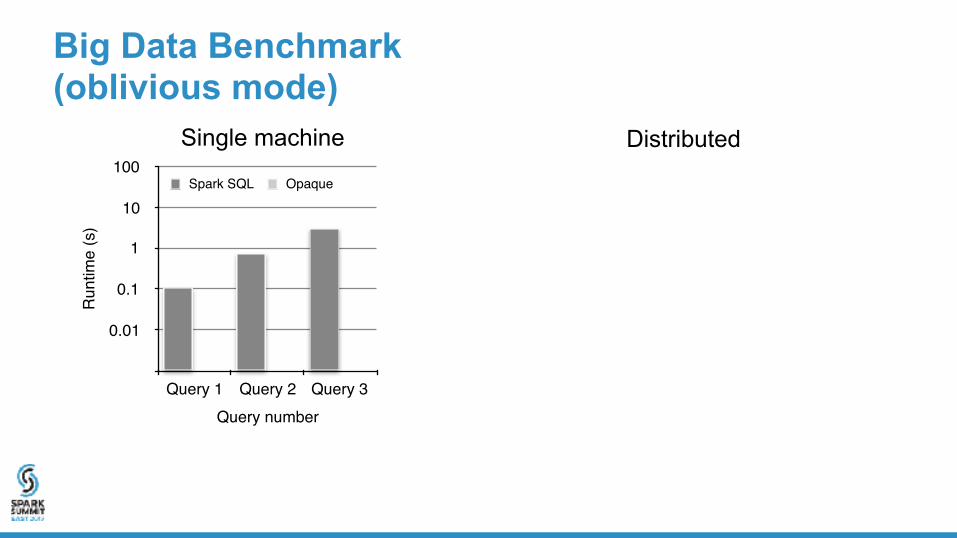
Single machine Distributed
Big Data Benchmark (oblivious mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque

Single machine Distributed
Big Data Benchmark (oblivious mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
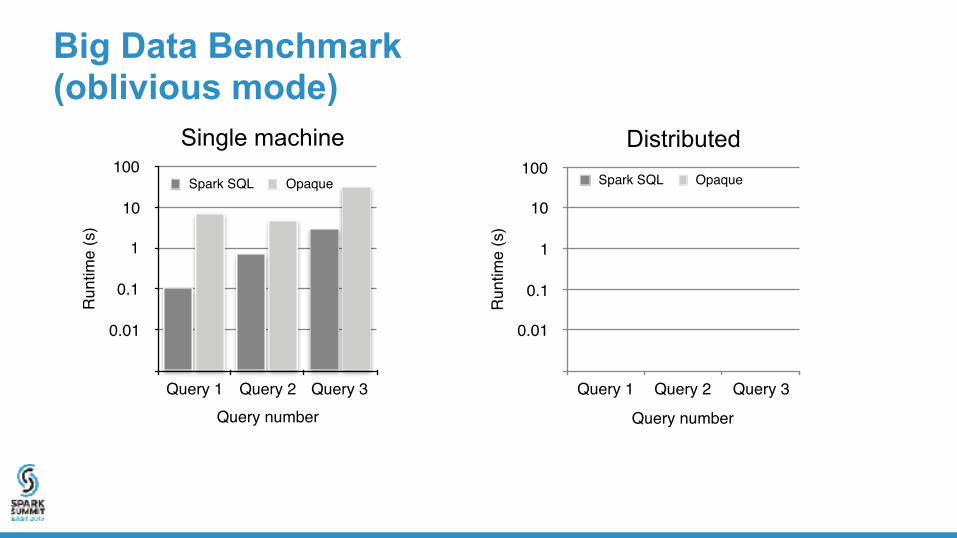
Run
time
(s)
0.01
0.1
1
10
100
Query number
Query 1 Query 2 Query 3
Spark SQL Opaque
Single machine Distributed
Big Data Benchmark (oblivious mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque

Run
time
(s)
0.01
0.1
1
10
100
Query number
Query 1 Query 2 Query 3
Spark SQL Opaque
Single machine Distributed
Big Data Benchmark (oblivious mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque

Run
time
(s)
0.01
0.1
1
10
100
Query number
Query 1 Query 2 Query 3
Spark SQL Opaque
Single machine Distributed
Big Data Benchmark (oblivious mode)
Run
time
(s)
0.01
0.1
1
10
100
Query numberQuery 1 Query 2 Query 3
Spark SQL Opaque
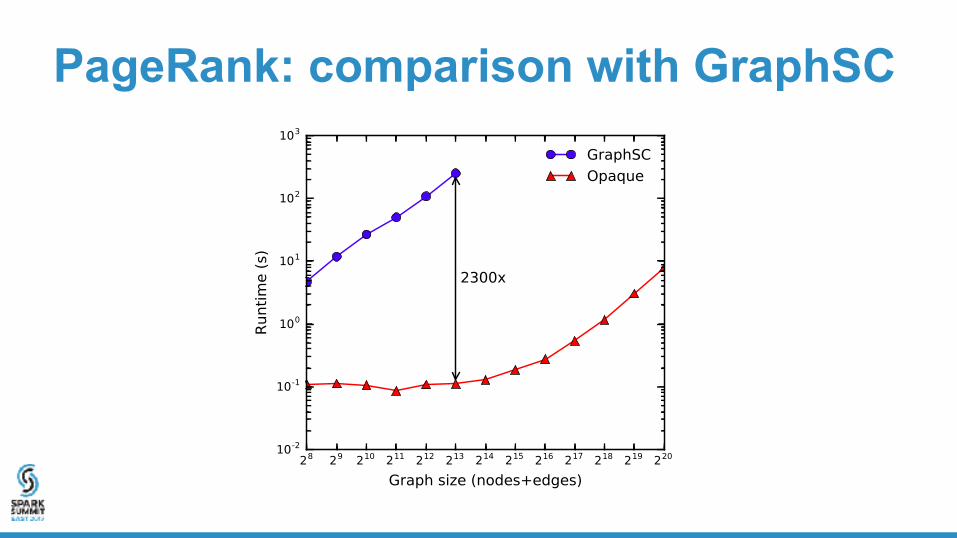
PageRank: comparison with GraphSC

We have an NSDI 2017 paper!

Open source release

Open source release• Available at github.com/ucbrise/opaque

Open source release• Available at github.com/ucbrise/opaque• Opaque is implemented as a Spark package

Open source release• Available at github.com/ucbrise/opaque• Opaque is implemented as a Spark package• Features

Open source release• Available at github.com/ucbrise/opaque• Opaque is implemented as a Spark package• Features
– Supports DataFrame select, filter, group by, join

Open source release• Available at github.com/ucbrise/opaque• Opaque is implemented as a Spark package• Features
– Supports DataFrame select, filter, group by, join– Allows users to specify DataFrames in encryption/
oblivious modes

Open source release• Available at github.com/ucbrise/opaque• Opaque is implemented as a Spark package• Features
– Supports DataFrame select, filter, group by, join– Allows users to specify DataFrames in encryption/
oblivious modes• Automatic sensitivity propagation in mixed
sensitivity

Open source release

Open source release • Extension

Open source release • Extension
– More functionality requires rewriting operators in C++

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions
• Automatically generate C++

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions
• Automatically generate C++• Run JVM in the enclave

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions
• Automatically generate C++• Run JVM in the enclave
• Deployment

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions
• Automatically generate C++• Run JVM in the enclave
• Deployment– Master must be trusted

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions
• Automatically generate C++• Run JVM in the enclave
• Deployment– Master must be trusted– SGX available now on Skylake processors

Open source release • Extension
– More functionality requires rewriting operators in C++– No UDF support yet– Possible solutions
• Automatically generate C++• Run JVM in the enclave
• Deployment– Master must be trusted– SGX available now on Skylake processors
• Cloud providers have no support yet

Demo

ConclusionOpaque is a secure distributed analytics platform
Opaque
SQL Machine Learning
Graph Analytics
Try it out at github.com/ucbrise/opaque Wenting Zheng - [email protected]

















