Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space Anh Nguyen, Jason Yosinski, Yoshua Bengio, Alexey Dosovitskiy, Jeff Clune [GitHub ] [Arxiv] Slides by Víctor Garcia UPC Computer Vision Reading Group (27/01/2017)
Transcript
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
Anh Nguyen, Jason Yosinski, Yoshua Bengio, Alexey Dosovitskiy, Jeff Clune
[GitHub] [Arxiv]
Slides by Víctor GarciaUPC Computer Vision Reading Group (27/01/2017)
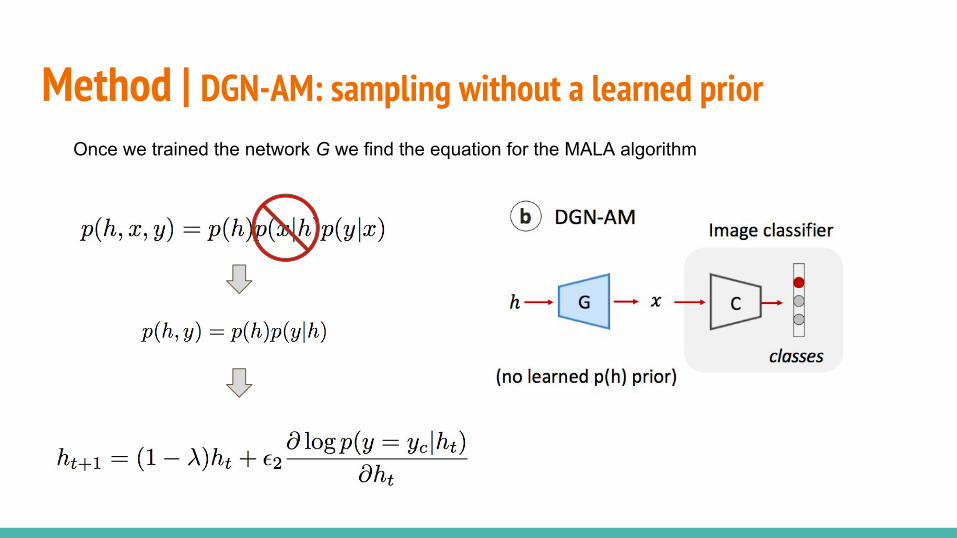
Probabilistic Interpretation of the methodMetropolis-adjusted Langevin algorithm (MALA) which is a MCMC algorithm for iteratively producing random samples from a distribution p(x):
Probabilistic Interpretation of the methodMetropolis-adjusted Langevin algorithm (MALA) which is a MCMC algorithm for iteratively producing random samples:
Current state
Probabilistic Interpretation of the methodMetropolis-adjusted Langevin algorithm (MALA) which is a MCMC algorithm for iteratively producing random samples:
Future State Current state
Probabilistic Interpretation of the methodMetropolis-adjusted Langevin algorithm (MALA) which is a MCMC algorithm for iteratively producing random samples:
Future State Current state Gradient to the natural manifold of
p(x)
Probabilistic Interpretation of the methodMetropolis-adjusted Langevin algorithm (MALA) which is a MCMC algorithm for iteratively producing random samples:
Gradient to the natural manifold of
p(x)
NoiseFuture State Current state
Probabilistic Interpretation of the method
Future State Current state Gradient to the natural manifold
of p(x)
Noise
Probabilistic Interpretation of the method
p(x)
Probabilistic Interpretation of the method
p(x)
Step towards an image that causes the classifier to produce a higher score for class C
Step towards a more generic image
Noise
Probabilistic Interpretation of the method
xt
Rough example
Probabilistic Interpretation of the method
y_co = Content activations y_st = Style activationsRough example
Probabilistic Interpretation of the method
xt+iRough example
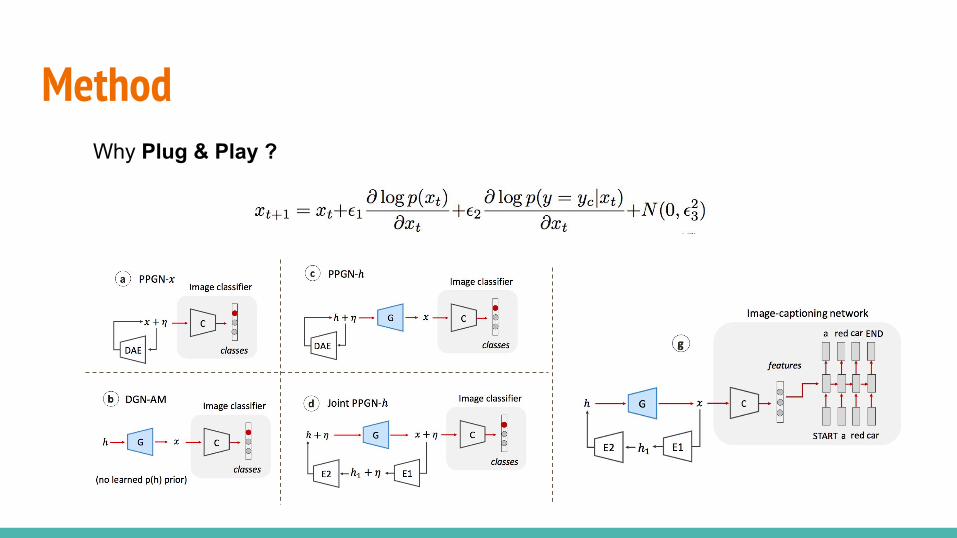
Index● Introduction ● Probabilistic Interpretation of the method● Methods and Experiments
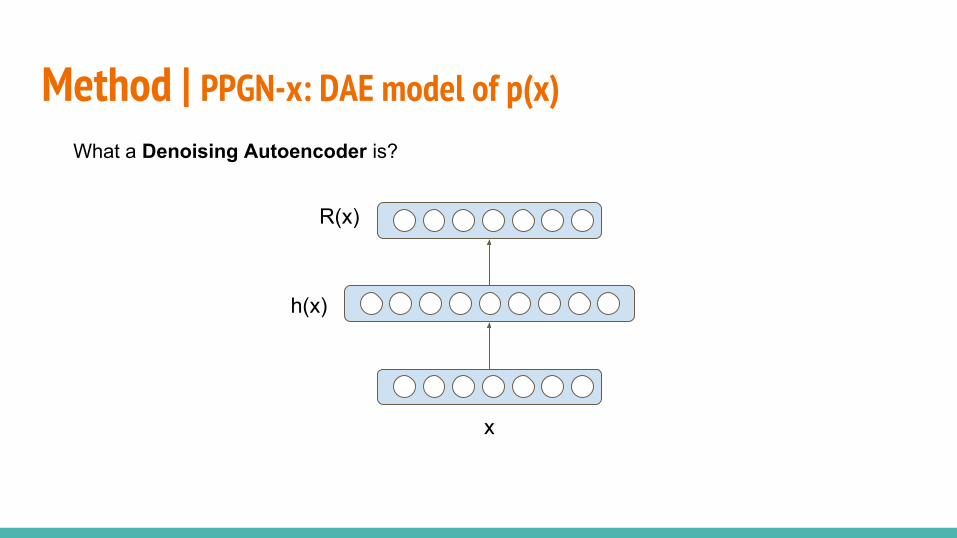
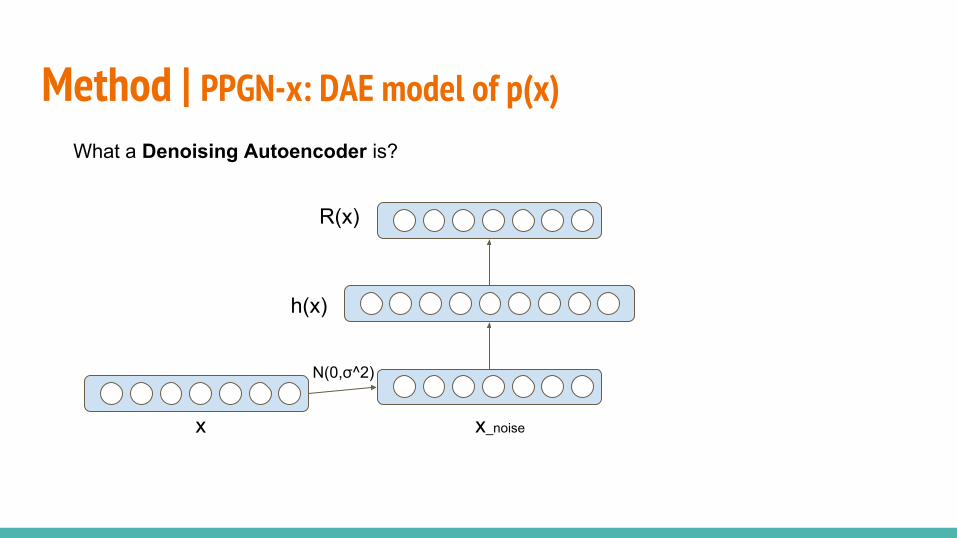
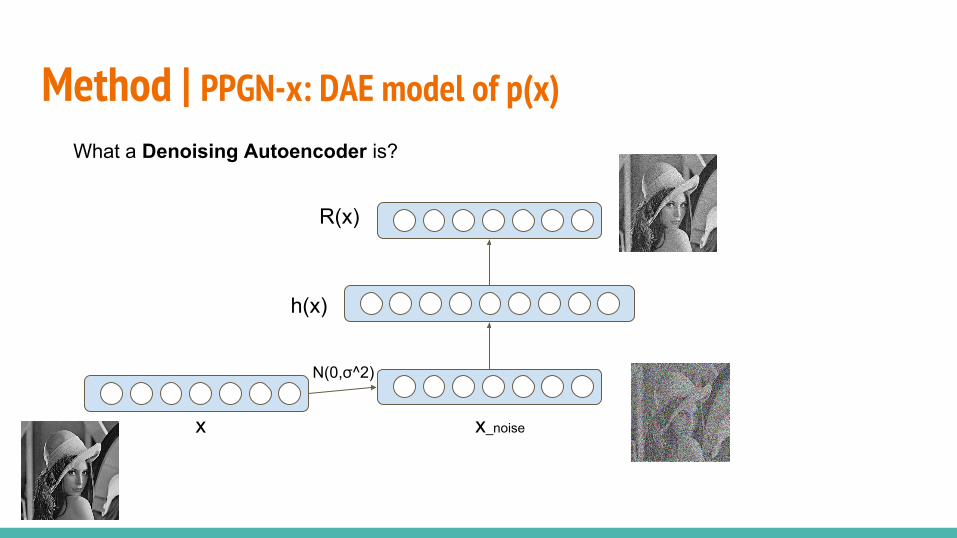
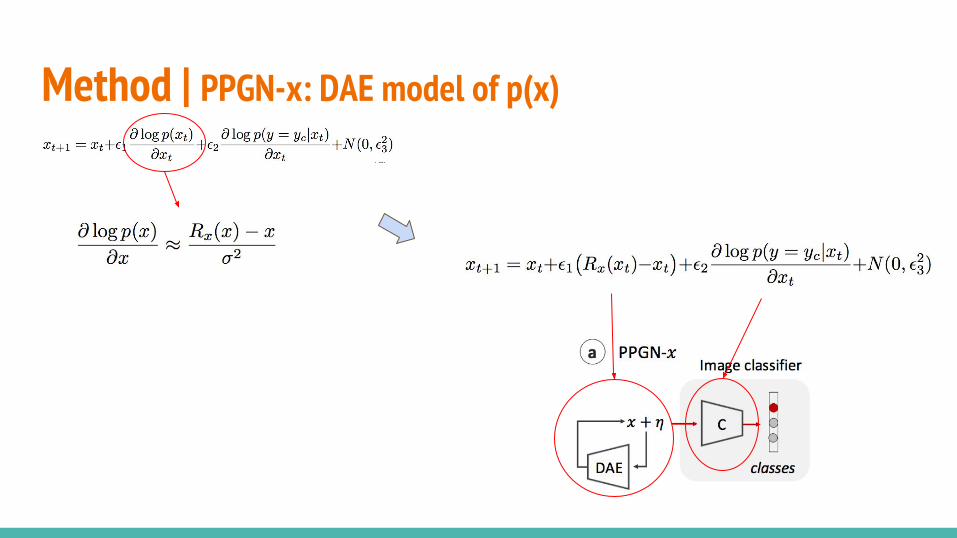
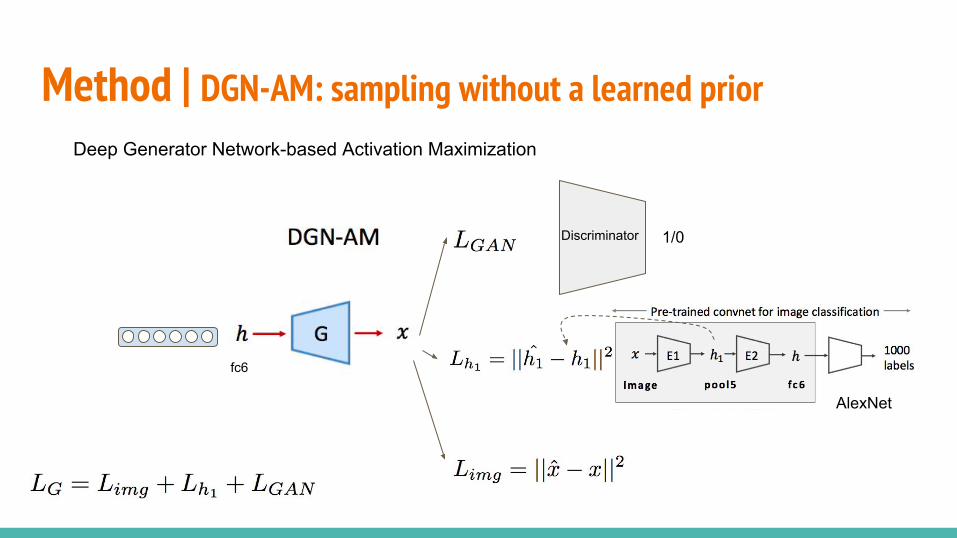
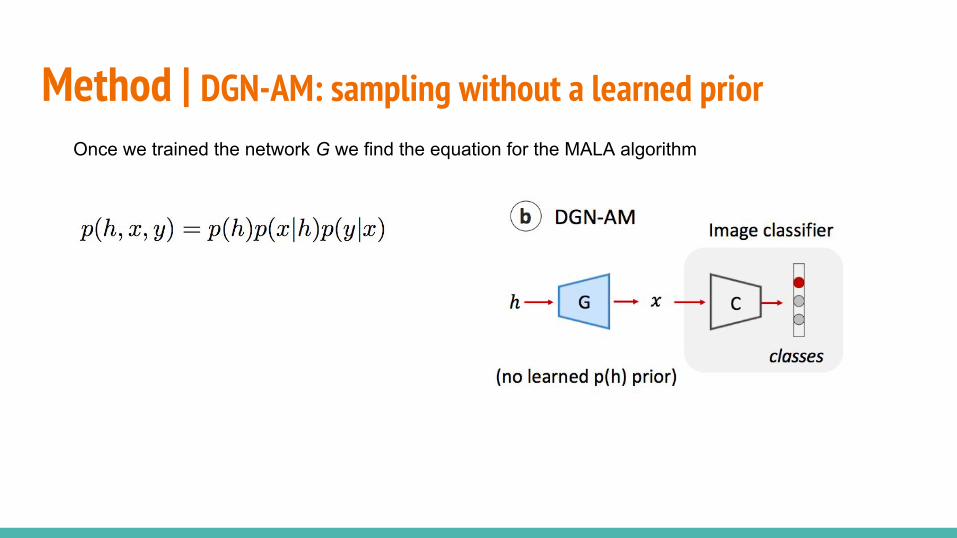
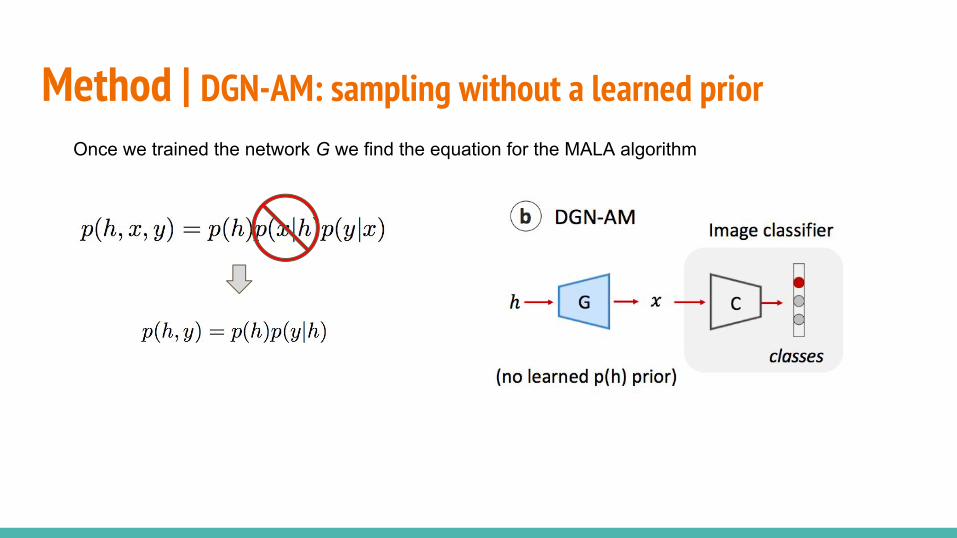
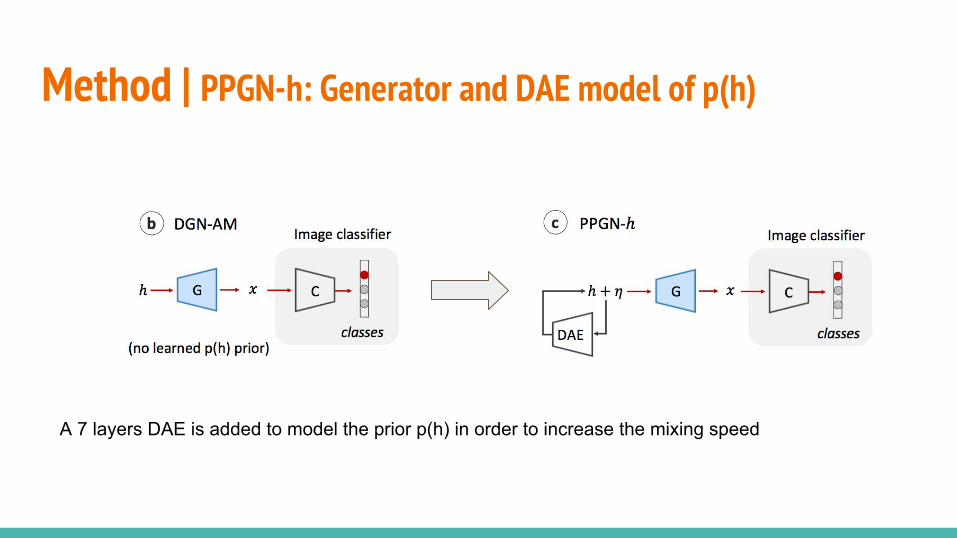
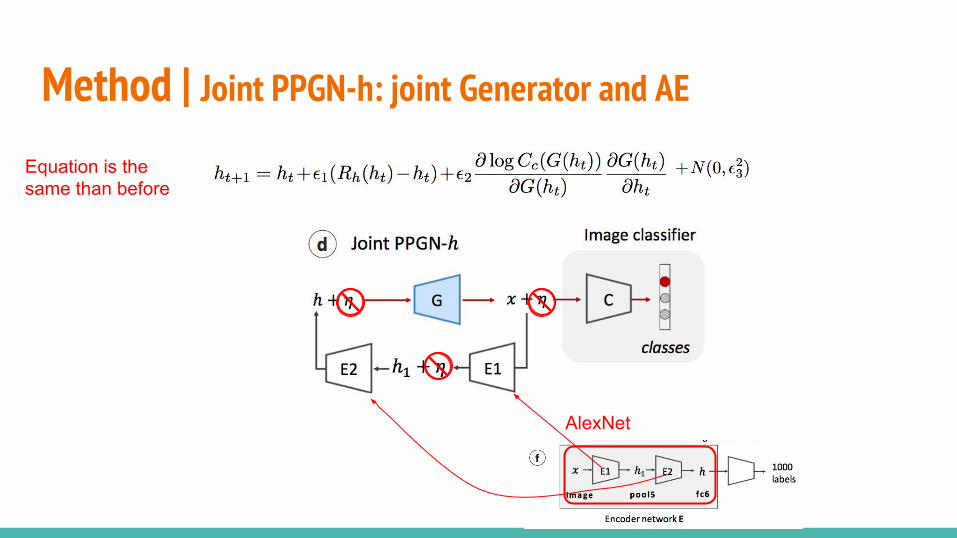
○ PPGN-x: DAE model of p(x)○ DGN-AM: sampling without a learned prior○ PPGN-h: Generator and DAE model of p(h)○ Joint PPGN-h: joint Generator and DAE
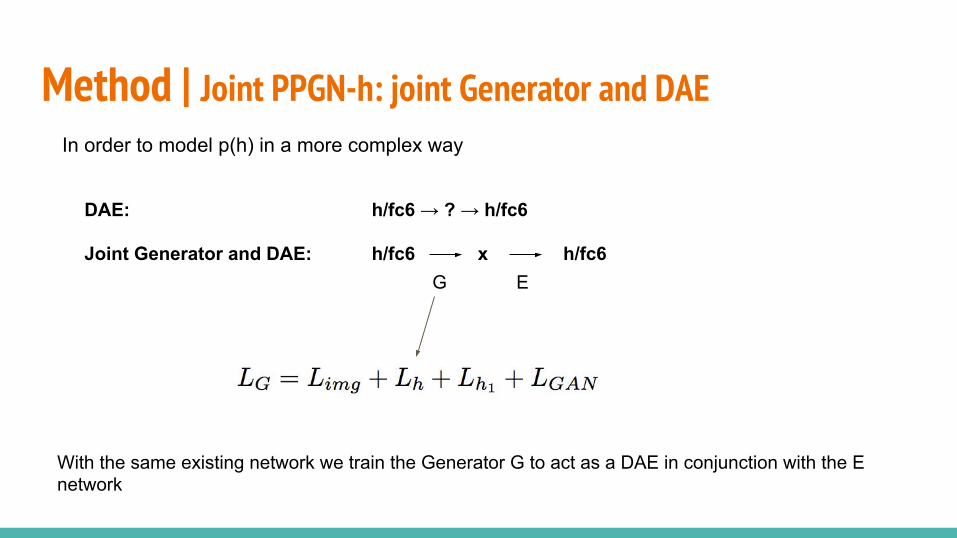
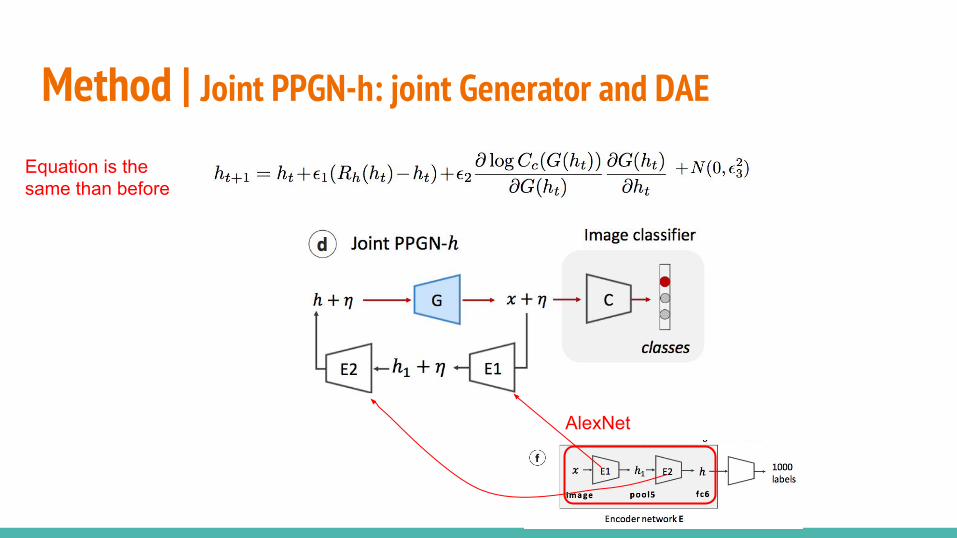
Method | Joint PPGN-h: joint Generator and DAE Noise sweepsFor the last model we test the reconstruction of different h/fc6 vectors when adding different noise levels:
fc6N(0, ) +
Method | Joint PPGN-h: joint Generator and AE Noise sweepsFor the last model we test the reconstruction of different h/fc6 vectors when adding different noise levels:
Method | Joint PPGN-h: joint Generator and AE Noise sweeps
Method | Joint PPGN-h: joint Generator and AE Noise sweeps
We can still recover large information from the image when mapping with a lot of noise.Many → one.
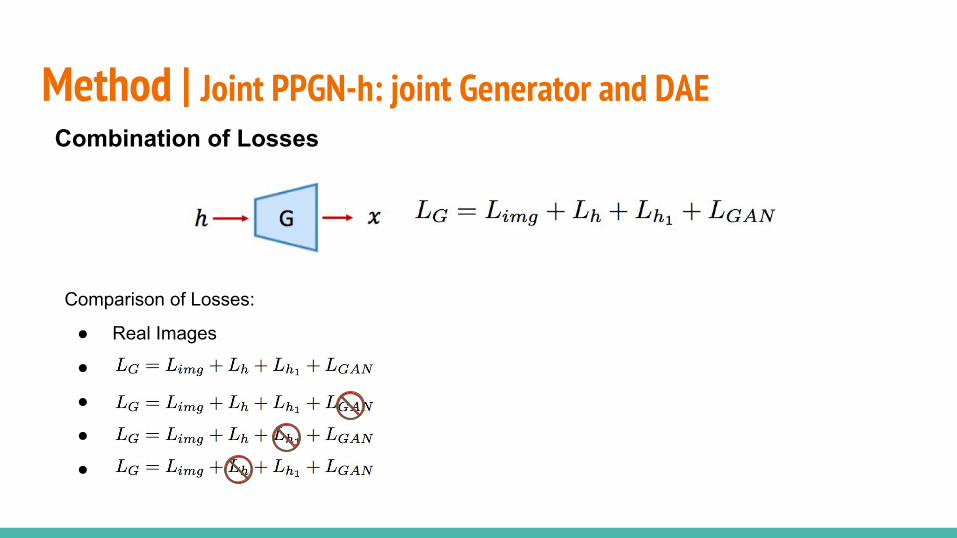
Method | Joint PPGN-h: joint Generator and DAE Combination of Losses
Comparison of Losses:
● Real Images
●
●
●
●
Method | Joint PPGN-h: joint Generator and DAE Combination of Losses
Method | Joint PPGN-h: joint Generator and DAE Combination of Losses
Method | Joint PPGN-h: joint Generator and DAE Evaluating: Qualitatively
Method | Joint PPGN-h: joint Generator and DAE Evaluating: Qualitatively
Method | Joint PPGN-h: joint Generator and DAE Evaluating: Qualitatively
Index● Introduction ● Probabilistic Interpretation of the method● Methods and Experiments
○ PPGN-x: DAE model of p(x)○ DGN-AM: sampling without a learned prior○ PPGN-h: Generator and DAE model of p(h)○ Joint PPGN-h: joint Generator and DAE
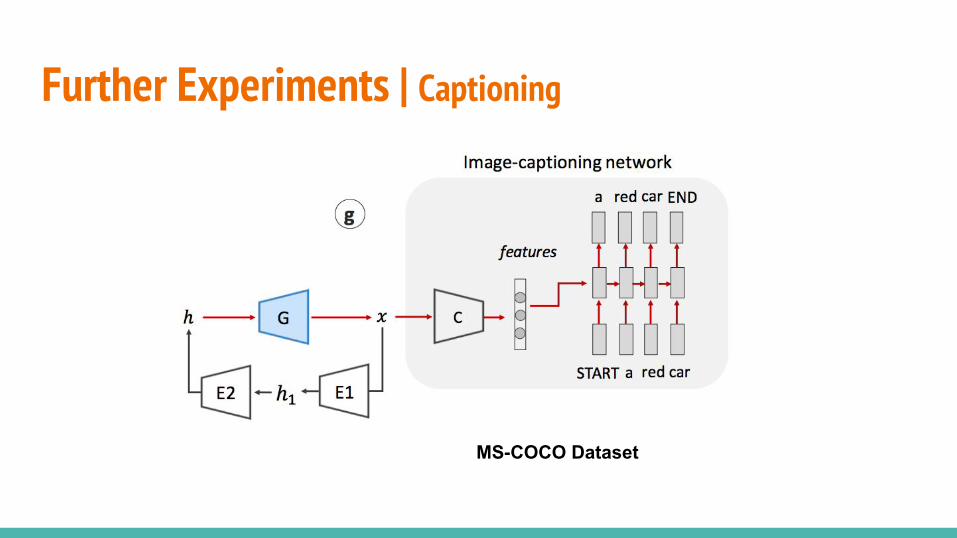
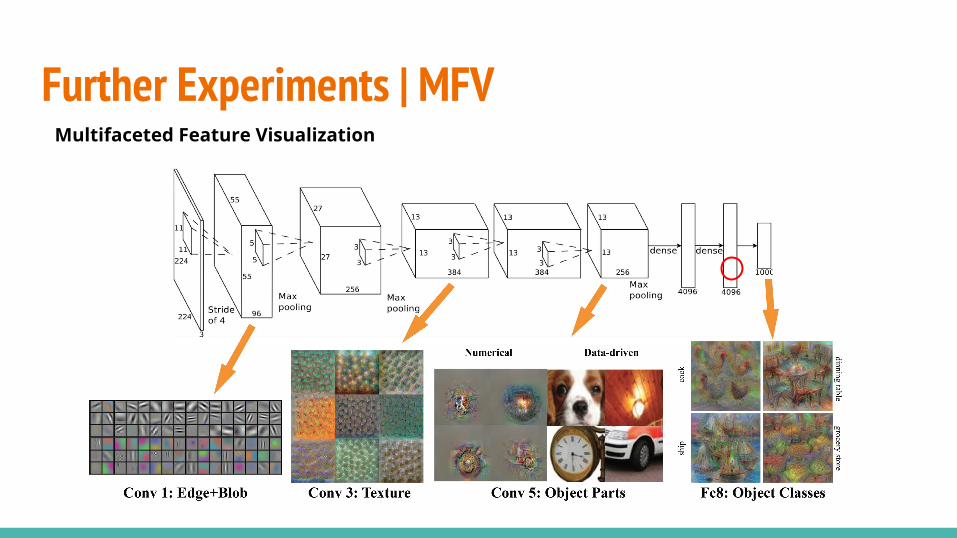
Further Experiments | InpaintingMultifaceted Feature Visualization
Further Experiments | InpaintingMultifaceted Feature Visualization
Further Experiments | InpaintingMultifaceted Feature Visualization
Further Experiments | InpaintingMultifaceted Feature Visualization
Further Experiments | InpaintingMultifaceted Feature Visualization
Conclusions
● Only using GANs for the reconstruction, GANs collapse into fewer modes, far from the original p(x).
● Using extra Losses it is possible to better reconstruct the images even for 1000 classes and for higher resolution. Mapping one-to-one helps to prevent typical latent → missing modes.
● It would be great to generate also the embedding space for this super-resolution multi-class images instead of using a supervised learned space.