35
Puppet Adoption in a Mature Environment How to get from 0 to 10,000 Jason O’Rourke Systems Engineering Lead [email protected] In/jsorourke
| Date post: | 18-Jul-2015 |
| Category: |
Software |
| Upload: | puppet-labs |
| View: | 332 times |
| Download: | 0 times |

Puppet Adoption in a Mature Environment How to get from 0 to 10,000
Jason O’Rourke Systems Engineering Lead [email protected] In/jsorourke

Safe harbor statement under the Private Securities Litigation Reform Act of 1995:
This presentation may contain forward-looking statements that involve risks, uncertainties, and assumptions. If any such uncertainties materialize or if any of the assumptions proves incorrect, the results of salesforce.com, inc. could differ materially from the results expressed or implied by the forward-looking statements we make. All statements other than statements of historical fact could be deemed forward-looking, including any projections of product or service availability, subscriber growth, earnings, revenues, or other financial items and any statements regarding strategies or plans of management for future operations, statements of belief, any statements concerning new, planned, or upgraded services or technology developments and customer contracts or use of our services.
The risks and uncertainties referred to above include – but are not limited to – risks associated with developing and delivering new functionality for our service, new products and services, our new business model, our past operating losses, possible fluctuations in our operating results and rate of growth, interruptions or delays in our Web hosting, breach of our security measures, the outcome of any litigation, risks associated with completed and any possible mergers and acquisitions, the immature market in which we operate, our relatively limited operating history, our ability to expand, retain, and motivate our employees and manage our growth, new releases of our service and successful customer deployment, our limited history reselling non-salesforce.com products, and utilization and selling to larger enterprise customers. Further information on potential factors that could affect the financial results of salesforce.com, inc. is included in our annual report on Form 10-K for the most recent fiscal year and in our quarterly report on Form 10-Q for the most recent fiscal quarter. These documents and others containing important disclosures are available on the SEC Filings section of the Investor Information section of our Web site.
Any unreleased services or features referenced in this or other presentations, press releases or public statements are not currently available and may not be delivered on time or at all. Customers who purchase our services should make the purchase decisions based upon features that are currently available. Salesforce.com, inc. assumes no obligation and does not intend to update these forward-looking statements.
Safe Harbor

§ A 16 year old cloud computing pioneer § Data centers around the world § Rapid growth and expansion § Tens of thousands of servers § Existing in-house automation tools
Growth required consistency and an automated process for making reliable, repeatable changes.
Salesforce

PART I: Intro

Scalability: without an effective form of system configuration, there is a point of sharply increasing costs and negative events (incidents) as the company’s server infrastructure grows. • For highly scaled applications (ex: cloud), server count > 1000. • For more diverse application set, server count > 250. • System Engineer team size > 20. Reliability and Velocity both suffer as a result. And you can’t fix it by simply hiring more people. So will Puppet adoption make my job unnecessary?
Why Do We All Want Puppet?

Scalability: without an effective form of system configuration, there is a point of sharply increasing costs and negative events (incidents) as the company’s server infrastructure grows. • For highly scaled applications (ex: cloud), server count > 1000. • For more diverse application set, server count > 500. • System Engineer team size > 20. Reliability and Velocity both suffer as a result. And you can’t fix it by simply hiring more people. So will Puppet adoption make my job unnecessary? I don’t think so. I’m busier than ever! Puppet will remove painful work and let you do valuable work instead. Let the machines do the rote work.
Why Do We All Want Puppet?

The Greenfield
In the Greenfield, you have a clean slate. This can be a new location, or a new product line, or even an entirely new company. Benefits: • Can work during normal business hours • Can afford setbacks and miscues. • Can experiment, redesign at will. “Fail Fast” should be the operating mantra. • Can go live when it’s ready.
In a greenfield, the primary cost is opportunity cost – time lost. The start up is the closest to a pure greenfield, but there may be competitors rushing to the same market.

The field has been paved over and built up. Servers have running applications in use by customers.
You may be restricted to making changes during off peak hours. The change window may be restricted. Changes need to be tested in dev or staging before production. It’s critical to have a back out plan or a viable DR option. A failure could translate directly to lost revenue, and potentially lost customers.
The Brownfield

Are these 4 web servers identical?
Snowflakes
Are these 4 web servers identical?
Of course not: snowflakes are unique!
Snowflakes are small variations of the same server type.
Causes of server variation: • Manual Process
• Multigenerational Scripts
• Remediation to Incidents
• Reliance on Tribal Knowledge
Snowflakes


The Company’s Lawn doesn’t get greener with age
Tech Debt accumulates over time, in the form of snowflakes and in deferred work. Compliance and regulatory requirements Change Management Staging environments can fall short The business has a revenue stream to protect. • Makes substantial change like this seem risky. • Yet it is your primary responsibility to keep the customer’s needs in mind. • Business needs may require your team and others to work on other priorities.
In hindsight, it is clear that the technical aspects of Puppetization are only a small part of the project. Be prepared for surprises.

Part II: Methods

Form a DevOps Team
What does DevOps mean anyway? • For the system engineer, let’s simplify to the concept that infrastructure is code and should be managed as any
other software project. Dev and QE disciplines bring formalized methods around code revision and collaboration, and around automated testing and code coverage. Agile Methodology is well suited. Desired Experience for team members: • Prior Puppet conversion experience • Prior Datacenter experience • Production experience

Training and Skills Building
• Puppet Labs training • PuppetConf • Puppet Labs Professional Services • Puppet Forge • Puppet User Group Meetups

The Key Epics Game Plan
Create the Base Class • We split up the 100+ kickstart scripts with > 10,000 lines of bash code and separated the universal settings from the
role specific.
Build the Vagrant development environment “Puppet in a Box” • This virtualization allowed to provide every user with a functioning ppm, role instances, and puppet/git development
environment at their desk. • Also usable for solving other development problems.
Establish best practices • Determined and documented the ‘right’ (and only) method for solving some common Puppet FAQ situations. • All code required second eyes check over and functional testing before merging.

Open source tools used for developing and testing Puppet code
Jenkins • Handful of machines responsible for testing, packaging, and shipping our Puppet code
Vagrant • Configures and manages our VirtualBox based development environment
Rouster • Abstraction layer for managing Vagrant virtual machines • https://github.com/chorankates/rouster, https://www.youtube.com/watch?v=N-E6x6MGBpY (PuppetConf ‘13)
Git • Version control; use GitHub Enterprise as a repository hosting service
puppet-lint • Make sure Puppet manifests conform to the style guide
rspec-puppet • Testing Puppet’s behavior when it compiles manifests into a catalog of Puppet resources

At many larger companies it’s common for only the system engineers to have root access. • This may be a choice of the company, rather than a requirement.
It is very difficult for engineers to automate products they cannot actually see.
Under this limitation, testing iteration velocity is reduced to the bandwidth of the team members with access. Improvement 1: creation of a netgroup granting login access to most production servers
Improvement 2: addition of read-only sudoers rules (ex: noop puppet run, cert list reads, log files) • With this, the developers can investigate and frequently solve the problem, pending a release.
Production Access

Part III: Implementation

Different Approaches to Beginning Adoption Points of Engagement
1. New Data Center
2. New HW only
3. New role type
4. Convert one resource at a time
5. Convert one role type (completely) at a time • Our success. Start with internal facing or simple roles first.

In 2014 the company opted to standardize on the current rev of RHEL6. To achieve this, roughly 35% of production needed to be reimaged from RHEL5. Instead of kickstart, the engineers used Razor + Puppet.
Key selling factors: ü We had just successfully partnered with our Dublin office to convert the first 400 nodes to Puppet in the
span of a training week. This established the potential velocity. ü With our orchestration, we could convert production nodes faster than it would take engineers to use
kickstart and then redeploy the application. ü With the hosts now under puppet control, future updates and configuration changes would be easy(er).
Taking Advantage of an Opportunity To Make Lemonade

Pre Production • Review manifests against kickstart scripts for any recent changes • Jenkins testing is green.
Smoke Tests • Convert node on DR internal instance to confirm functional process • Convert node on Production internal instance – short bake (couple days) • Convert node(s) on Production customer facing instance – long bake (week or more) • Fix bugs and reiterate.
Full conversion • Use all hands available to complete remainder of conversions as quickly as possible • Do retrospective on the conversion and identify any corrections or additional tooling needed before next one
The Conversion of a Role
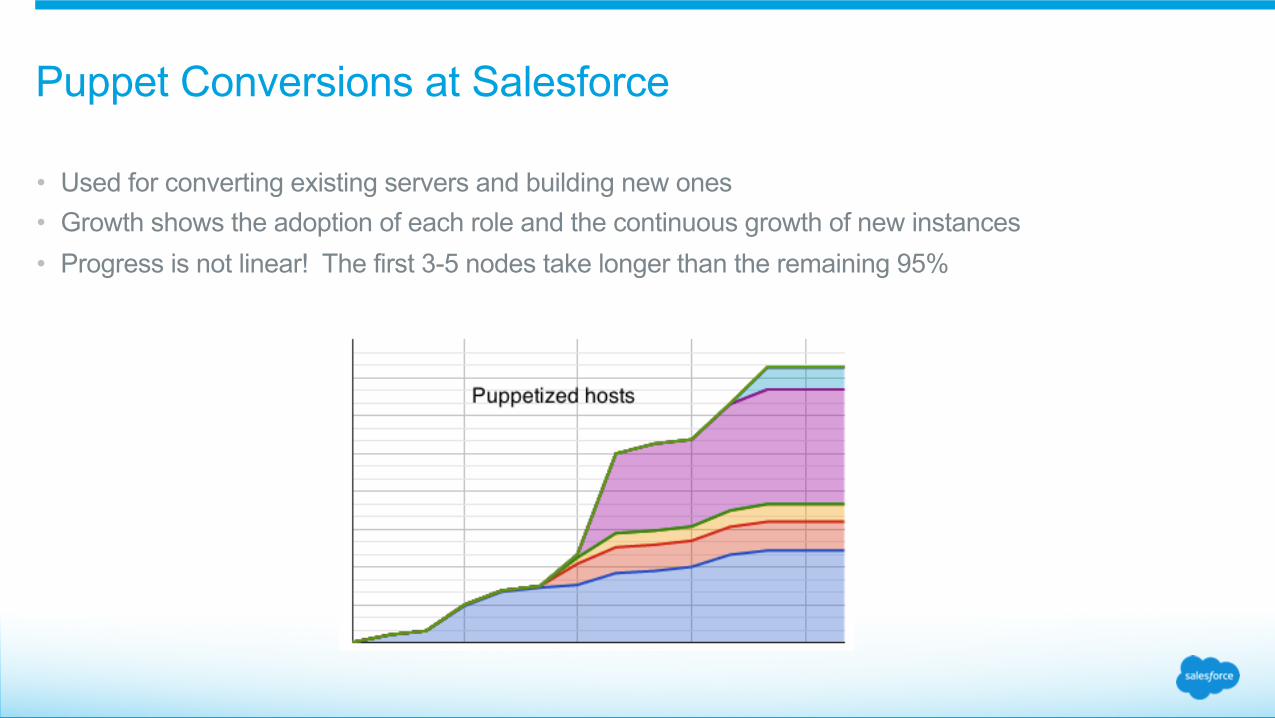
Puppet Conversions at Salesforce
• Used for converting existing servers and building new ones • Growth shows the adoption of each role and the continuous growth of new instances • Progress is not linear! The first 3-5 nodes take longer than the remaining 95%

Key Strategic Decisions
1. Continuous Puppet client runs – clients run Puppet every 4 hours • Undoes any manual edits quickly • If you don’t run continuously, you’ve reinvented kickstart
2. Canary release method – based on directory environments • Code deploys go to our canaries • This is our defense against bad code that is not covered by automated testing
3. Puppet code remains centralized with the primary team • A lot of learning and iteration as the footprint grew in production. One team can maintain consistency and has
the expertise to make course corrections.

Part IV: Lessons and Wins

#1 The proper setting for Transparent Huge Pages changed with RHEL6.
Cause: the role was running RHEL5 up to the time of Puppet conversion and thus its manifest was based on that OS version.
Resolution: quick correction to related etc. files, node updates, reboot.
Silver lining: caught in early smoke tests. Proved that bad manifests will be consistently bad on all nodes, reducing time to ID culprit.
Lessons Learned

#1 The proper setting for kernel tunable changed with RHEL6.
Cause: the role was running RHEL5 up to the time of Puppet conversion and thus its manifest was based on that OS version.
Resolution: quick correction to related conf files, node updates, reboot.
Silver lining: caught in early smoke tests. Proved that bad manifests will be consistently bad on all nodes, reducing time to ID culprit.
#2 Security hardening change caused regression in our legacy automation tooling.
Cause: no effective way to do automated testing of this legacy tool.
Resolution: reverted template to prior version.
Silver lining: Just as Puppet will allow you to quickly deploy changes, you can just as quickly (or more so) undo most changes.
Lessons Learned

Puppet conversion progress reports are great, but it’s the benefits that sell the story and get managerial buy in to commit people and time to the project.
Puppet first showed its value with a request for a simple change to the resolver settings. • For 20 minutes of effort, change made to ~2000 nodes, and for all future Puppet nodes. • For 10k or 100k nodes, same 20 minutes. • Can trust that 100% of nodes will be updated. For non puppet servers, this might take hours to days to script and execute. • Less reliable • Have to repeat or add to kickstart scripts. • Cost increases with node count.
Winning the Hearts and Minds

• Simpler changes like credential rotations or file permission hardening are now very simple code commits. • Small wants that were deferred due to cost are easily achieved.
Patching Faster

External teams were contributing Puppet code, but… Increasing Velocity: What wasn’t working
Teams were gated by the Puppet Team’s availability to code review & test pull requests • This caused long feedback loops and slow iterations
Not scalable. Could only support a handful of teams at a time.
We needed a new self-service contribution model to support multiple teams doing parallel Puppet development without requiring any intervention from the Puppet team.
We also needed to keep the build healthy.

New contribution model
Every module is its own Git repository. Owned by relevant team. Development, code reviews, and testing of Puppet modules are all done by the contributing team When a change is ready for deployment, a pull request is submitted to the Puppet repo updating the modules commit hash in the Puppetfile Pull requests are automatically tested by an in-house tool called PAI (Puppet Auto Integration) • Runs puppet-lint and rspec-puppet on modules that were changed • Runs functional tests on all server types that are effected by the changes
If the pull request passes, it is merged into the integration branch of Puppet • Contributors are alerted on any test failures • Changes to shared, core functionality (such as the external node classifier) are left open for code review from the
Puppet Team
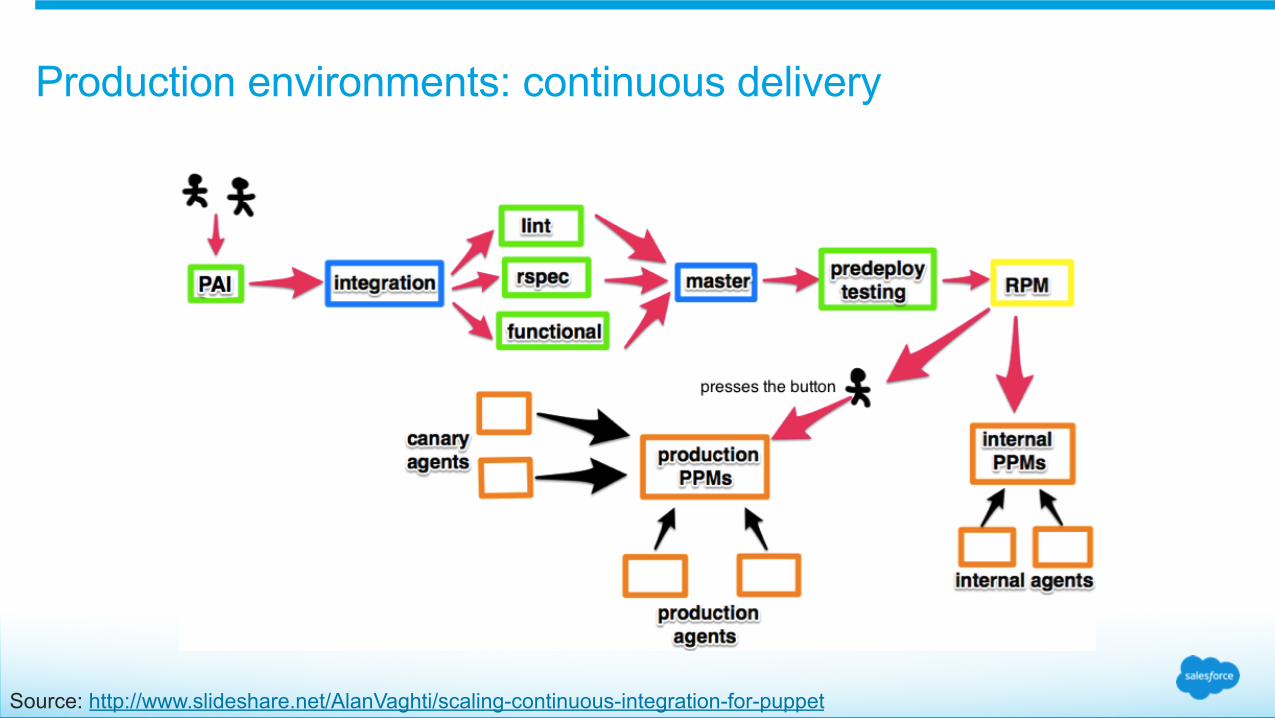
Production environments: continuous delivery
Source: http://www.slideshare.net/AlanVaghti/scaling-continuous-integration-for-puppet

Releasing Puppet changes to production involves: Production environments: continuous delivery
Publishing a diff file & summary between the last release and the current release A thumbs up from Site Reliability Pressing the shiny red button & letting post deployment smoke tests run Canary releases: • Utilizing Puppet’s directory environments, new releases are consumed only by a subset of representative servers
(“canary servers”) • Other servers continue to consume the previous Puppet release • Releases are automatically consumed by non-canary servers after 18 hours
Nagios and Graphite are used to monitor, alert, and gather metrics on Puppet health and performance

• Automation of Puppet code releases – enable up to 3 releases per day • Separate team formed to drive new conversions with role owners • Continued improvements to patching capabilities – puppet versus orchestration for deployment • Greater use of feature flagging and the “baking” class • Support for selective freezes in production.
Next Steps: 2015 Feature Objectives

Thank you

















