48
Chord: A Scalable Peertopeer Lookup Protocol for Internet Applica:ons Ion Stoica, Robert Morris, David LibenNowell, David R. Karger, M. Frans Kaashoek, Frank Dabek, Hari Balakrishnan
| Date post: | 19-Jan-2017 |
| Category: |
Software |
| Upload: | tristan-penman |
| View: | 444 times |
| Download: | 0 times |

Chord: A Scalable Peer-‐to-‐peer Lookup Protocol for Internet
Applica:ons
Ion Stoica, Robert Morris, David Liben-‐Nowell, David R. Karger, M. Frans Kaashoek, Frank Dabek,
Hari Balakrishnan

What is Chord? • It’s all in the Etle: – Scalable – Peer-‐to-‐peer – Lookup protocol – For Internet ApplicaEons
• This talk: – We’ll start with peer-‐to-‐peer networks – Define the concept of a lookup protocol, – Discuss Chord’s scalability (and correctness) – Consider some alterna:ves – And finally, look at some poten:al applica:ons

Peer-‐to-‐peer networks
• Every node in the network performs the same funcEon • No disEncEon between client and server, and ideally,
no single point of failure
Client-‐server Peer-‐to-‐peer

A brief history of P2P networks
• Napster – Semi-‐centralised P2P network – Centralised index and network management – File transfers are peer-‐to-‐peer
• Gnutella – Originally developed by NullsoW, early 2000 – Fully de-‐centralised – New nodes connect via seed nodes to establish an overlay network
– Search implemented using query-‐flooding
1st gen
2nd gen
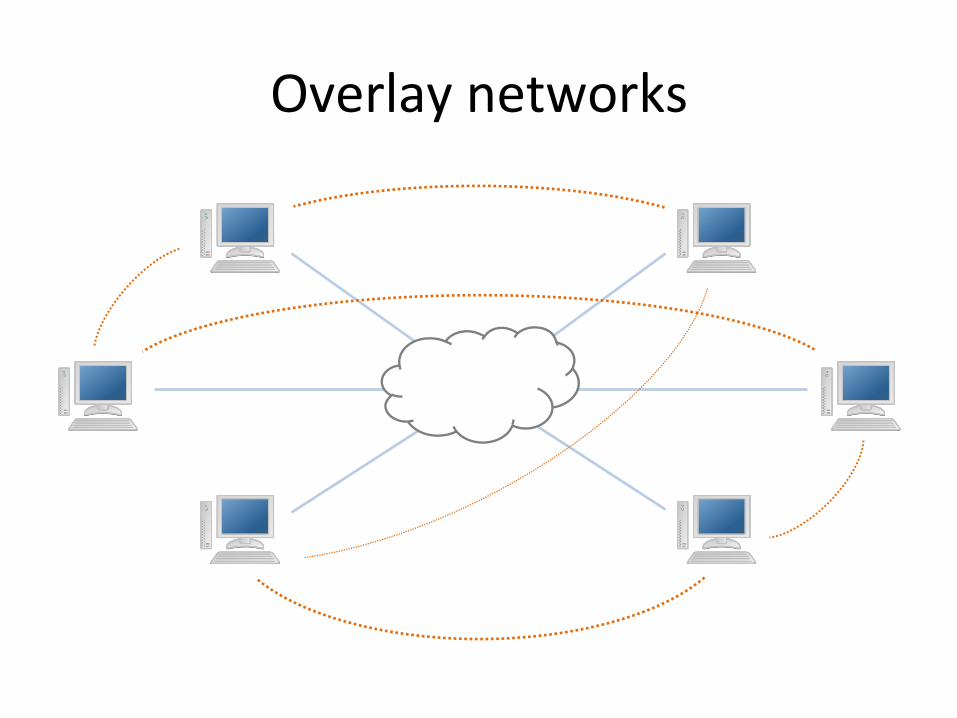
Overlay networks

Query flooding
Query q ($l) is broadcast up to N hops
q (2)
q (2) q (1)
q (1)
q (1)
q (1)
q (0)
q (0)
q (0)
q (0)
q (0)
q (0)
q (0)
q (0)

Results consolidated
X
X
• When max number of hops or TTL has been reached, results are consolidated, and sent back towards the source.
• Nodes that don’t respond in Eme will be excluded from results.

Trade-‐offs
• Nodes in peer-‐to-‐peer systems tend to be unreliable – Increased rate of failure – Weak security – High latency variability
• Li^le to no centralised control – EvicEng a node from the network requires all other nodes to ignore that node
• Scalability issues

Scalability issues
• This may seem a bit unintuiEve – Bo^lenecks in individual nodes can limit the capacity or reliability of the network
• Example: searches in Gnutella became less reliable aWer a surge in popularity – Query flooding returns poor results if nodes fail – Bandwidth limitaEons may also increase latency – SoluEon: Tiered P2P networks

Tiered P2P networks • Many normal nodes connect to few high
capacity nodes, which act as routers

Ultrapeers in Gnutella
• Since version 0.6 (released in 2002) Gnutella has used a Eered network
• High capacity nodes are called Ultrapeers – Search requests are routed via Ultrapeers – Ultrapeers may be connected other Ultrapeers to efficiently route search requests large segments of the network
• Leaf nodes typically connect to ~3 ultrapeers
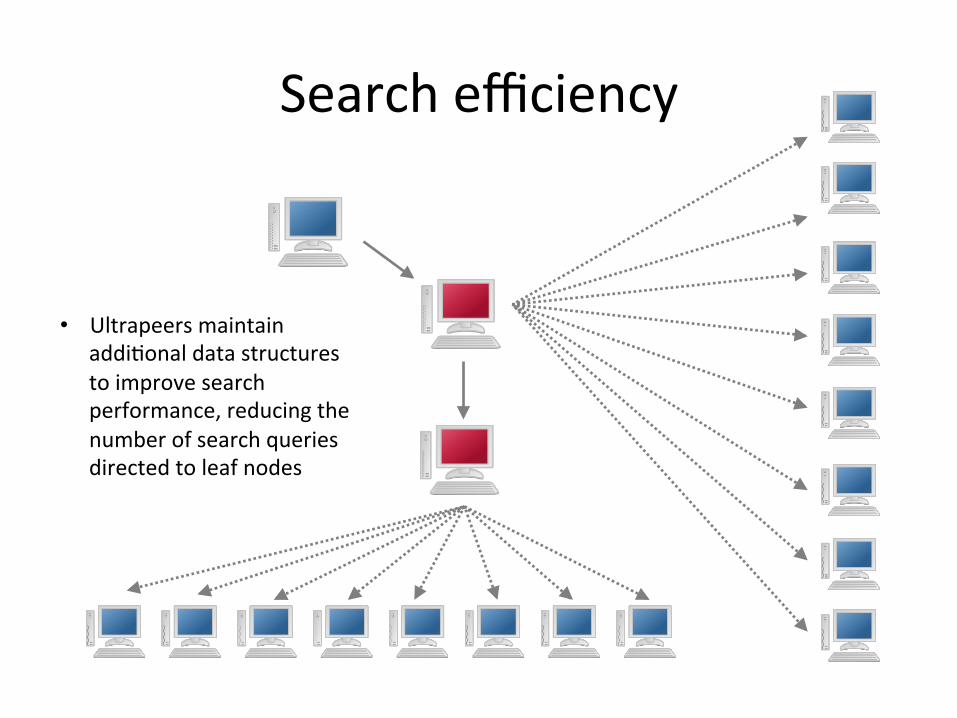
Search efficiency
• Ultrapeers maintain addiEonal data structures to improve search performance, reducing the number of search queries directed to leaf nodes

Another approach
• We want is an approach that is pure in the P2P sense, with good properEes relaEng to scalability and query performance
• What does this look like? – Take a search query and efficiently idenEfy the node (or nodes) that may know the answer
– Allow nodes to join or leave the network at any Eme, with minimal impact on query performance…

Lookup protocols
ApplicaEon
Lookup Service
Lookup (k) Insert (k, v) Result (v)
• Need to support two operaEons: – Insert (k, v) – Lookup (k) -‐> v

TradiEonal Hash Tables • A hash table is a data structure
used to implement an associaEve array
• Implements lookup protocol with operaEons run in constant-‐Eme
• Each element of the array is a bucket that contains one or more keys – Think of a bucket as owning a
porEon of the key-‐space
Visual representaEon of a hash table
Diagram from: h^p://math.hws.edu/eck/cs124/javanotes6/c10/s3.html

Distributed Hash Tables • Third genera4on approach to P2P networks • Nodes are hash buckets • Hash of key is used to idenEfy which node owns a key • DHT implementaEon defines how keys are distributed across
buckets, or nodes • DHT impl. also responsible for maintaining overlay network • ApplicaEon layer is responsible for defining replicaEon and
caching strategies

The Chord Protocol • Chord is a protocol and set of
algorithms for implemenEng the lookup opera:on of a Distributed Hash Table
• Key features are: – Number of hops is logarithmic in the
number of network nodes – Asynchronous network stabilizaEon
protocol – Consistent Hashing minimizes
disrupEons when nodes join or leave the network

Careful… there are three Chord papers
• SIGCOMM -‐ Special Interest Group on Data Communica4on – First published in 2001 – Won the test of Eme award in 2011
• PODC – Principles of Distributed Compu4ng – Follow up published in 2002
• TON – Transac4ons on Networking – Published in 2003
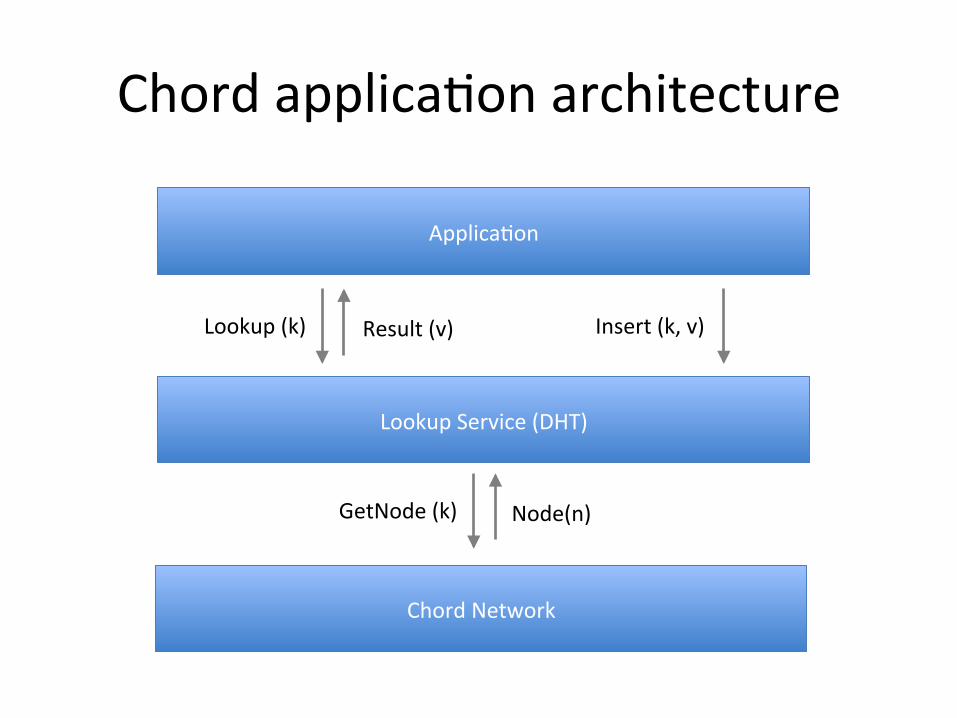
Chord applicaEon architecture
ApplicaEon
Lookup Service (DHT)
Lookup (k) Insert (k, v) Result (v)
Chord Network
GetNode (k) Node(n)

How does Chord scale?
• Several concerns involved in scaling a Chord network: – Efficiently idenEfying the node that is responsible for a key, even in very large networks
– Minimise impact of changes to the network on the performance of Chord lookups
– Even distribuEon of keys across nodes, using consistent hashing

Consistent Hashing • Instead of an array, we have a
key-‐space which can be visualized as a ring
• A hash funcEon is used to map keys onto locaEons on the ring
• Nodes are also mapped to locaEons on the ring – Typically determined by applying a
hash funcEon to their IP address and port number
Empty circles represent disEnct locaEons on the ring. Blue-‐filled circles indicate that nodes exist at those locaEons.
Diagram from: h^ps://www.cs.rutgers.edu/~pxk/417/notes/23-‐lookup.html

Successors • Chord assigns responsibility for segments of the ring to
individual nodes – This scheme is called Consistent Hashing – Allows nodes to be added or removed from the network while
minimizing the number of keys that will need to be reassigned
• We can figure out which node owns a given key by applying the hash funcEon, then choosing the node whose locaEon on the ring is equal to or greater than that of the key – This node is the ‘successor’ of the key.

Adding a node
Diagram from: h^ps://www.cs.rutgers.edu/~pxk/417/notes/23-‐lookup.html
Node 6 has been added to the network

Efficient lookup operaEons
• Lookup operaEons are based on key ownership, so… – When we want to find a key, we use the hash funcEon to find its locaEon on the ring
– Given the locaEon of a key on the ring, Chord allows us to efficiently idenEfy its successor
– We ask the successor whether it knows about the key that we’re interested in
– For insert operaEons, applicaEon layer tells the successor node to store the given key
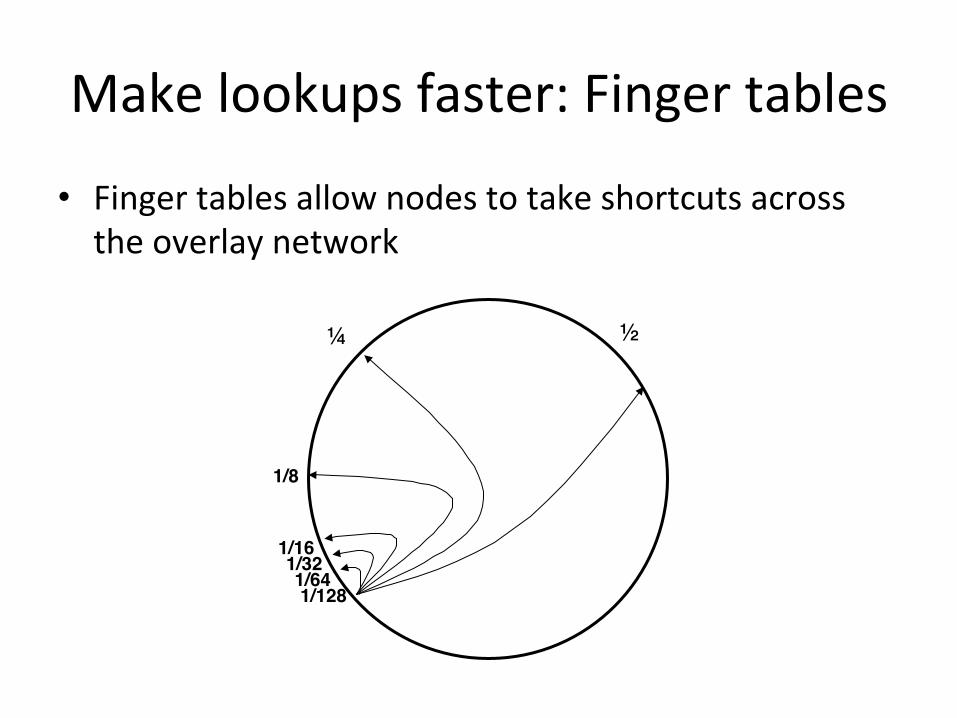
Make lookups faster: Finger tables
½¼
1/8
1/161/321/641/128
• Finger tables allow nodes to take shortcuts across the overlay network

Number of hops is O(lg n)
N32
N10
N5
N20N110
N99
N80
N60
Lookup(K19)
K19

Overlay network pointers • Each node needs to maintain
pointers to other nodes – Successor(s) – Predecessor – Finger table
• Finger table is a list of nodes at increasing distances from the current node – E.g. n, n+1, n+2, n+4, … – Allows for shortcuts across
segments of the network, hence the name Chord Red lines indicate
predecessor pointers, whereas blue lines are successor pointers

Chord algorithms • A Chord network can be thought of as a dynamic distributed
data structure • The Chord protocol defines a set of algorithms that are used
to navigate and maintain this data structure: – CheckPredecessor – ClosestPrecedingNode – FindSuccessor – FixFingers – Join – No:fy – Stabilize
Drive network stabilisaEon, underpinning correctness of lookups

Stabilise and NoEfy
• Stabilise – Detect nodes that might have joined the network – Opportunity to detect failure of successor node(s) – Update successor pointers if necessary – Announce existence to new successor using No0fy
• NoEfy – Allows a node to become aware of new, and potenEally closer, predecessors
– Update predecessor pointer if necessary

Stabilise and NoEfy algorithms

Visualizing stabilizaEon
• Node 3 joins network, with node 10 as its iniEal successor • Node 3 begins stabilizaEon; asks node 10 for its predecessor • Node 10 tells node 3 that its predecessor is node 8 • Node 8 is closer to node 3, and becomes its new successor • Node 3 noEfies node 8 of the change, so node 3 updates its predecessor pointer
Diagram adapted from: h^ps://www.cs.rutgers.edu/~pxk/417/notes/23-‐lookup.html

CheckPredecessor
• Periodic check; If the node does not respond, we just clear the predecessor pointer
• Predecessor pointer will be updated next Eme another node calls NoEfy

FixFingers
• Periodically refresh entries in the finger table so that they are eventually consistent with the state of the Chord network

ClosestPrecedingNode
• Scan finger table for the closest node that precedes the query ID
• Implicitly wraps around key-‐space, so if the node has a successor, this is always completes

FindSuccessor
• Uses ClosestPrecedingNode funcEon to recursively idenEfy nodes whose IDs are closer to the query ID:

Joining a network
• Tell a node to join a network • Using the address of an exisEng node as a ‘seed node’
• New node uses seed node to locate its successor (by calling FindSuccessor)

Correctness…
• The Chord papers include various proofs of correctness and performance
• But model checking has been used to find defects in the design of Chord as described in all three papers – This work has been spear-‐headed by Pamela Zave – “Using Lightweight Modeling To Understand Chord” – “How to Make Chord Correct”
• Impact of issues range invalidaEng performance proofs to incorrect behaviour in various failure scenarios

Trivial example of failure
• Performance claims rely on invariant relaEng to correct ordering of nodes when they join the network:

Impact of correctness issues
• In the paper “Using Lightweight Modeling To Understand Chord”, Zave menEons the construcEon of a (probably) correct protocol – Based on porEons of all three papers – Introduces reconciliaEon steps to address impact of node failures, and some of these steps involve the applicaEon layer
– Paper does not claim correctness, conclusion being that researchers should be much more cauEous about claiming correctness of proofs without some kind of rudimentary model checking

AlternaEve DHT protocols
• Chord was one of four original DHT protocols: – CAN (Content Addressable Network) – Chord – Pastry – Tapestry
• Followed closesly by Kademlia – Used as the basis for BitTorrent

AlternaEves: CAN • Nodes take ownership of a
porEon (zone) of an n-‐dimensional key-‐space
• Nodes keep track of neighbouring zones
• IntuiEvely, locaEng a node is a ma^er of following a straight line to zone that contains the query key
• Nodes join by spliung exisEng zones

AlternaEves: Pastry
• Nodes are assigned random IDs • Each node maintains – RouEng table, sized appropriately for the key-‐space – Leaf node list – closest nodes in terms of node ID – Neighbour list – closest nodes based on rouEng metric (e.g. ping latency, number of hops)
• Messages/requests are routed to nodes that are progressively closer to the desEnaEon ID
• Preference is given to nodes with a lower cost, based on rouEng metric

Pastry network pointers
Row index indicates first digit of node ID that varies from current node Column index is value of that digit Entries are closest known nodes with the derived prefix
Closest node IDs greater than current node ID
Closest node IDs less than
current node ID

ApplicaEons of Pastry
• PAST – A distributed file system – Hash of filename is used to idenEfy node that is responsible for a file
– Files are replicated to nearby nodes using the node’s neighbour and leaf lists
• SCRIBE -‐ decentralized publish/subscribe system – Topics are assigned to random nodes – Messages for a given topic are routed to the appropriate node, then pushed to subscribers via mulEcast

AlternaEves: Tapestry
• Similar in concept to Pastry (rouEng based on prefixes, but without necessarily considering rouEng metric)
• Formalises DOLR (Distributed Object LocaEon and RouEng) API: – PublishObject – UnpublishObject – RouteToObject – RouteToNode
• InteresEng applicaEon is: – Bayeux: an applicaEon-‐level mulEcast system, ideal for streaming

AlternaEves: Kademlia • Nodes are assigned random IDs • XOR of node IDs is used as rouEng metric – A xor A == 0, A xor B == B xor A – Triangle equality holds
• Messages are routed such that they are one bit closer to the desEnaEon aWer each hop
• For each bit in a node ID, Kademlia nodes maintain a list of K nodes that are an equal distance from the node
• These lists are constantly updated as a node interacts with other nodes in the network, making it resilient to failure

ApplicaEons of Kademlia
• Academic value – XOR metric forms an abelian group, which allows for closed analysis rather than relying on simulaEon
• BitTorrent – Allows for trackerless torrents
• Gnutella – Protocol augmented to allow for alternaEve file locaEons to be discovered

ApplicaEons for Chord • CooperaEve mirroring – Basically caching, with a level of load balancing
• Time-‐shared storage – Caching for availability rather than load balancing
• Distributed indexes – Add a block storage layer and you can use Chord as the basis for a Distributed File System
• CombinaEonal search – Use Chord to assign responsibility for porEons of a computaEon to nodes in a network, and to later retrieve the results

















