19
Reading population codes: a neural implementation of ideal observers Sophie Deneve, Peter Latham, and Alexandre Pouget
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 215 times |
| Download: | 0 times |

Reading population codes: a neural implementation of ideal observers
Sophie Deneve, Peter Latham, and Alexandre Pouget
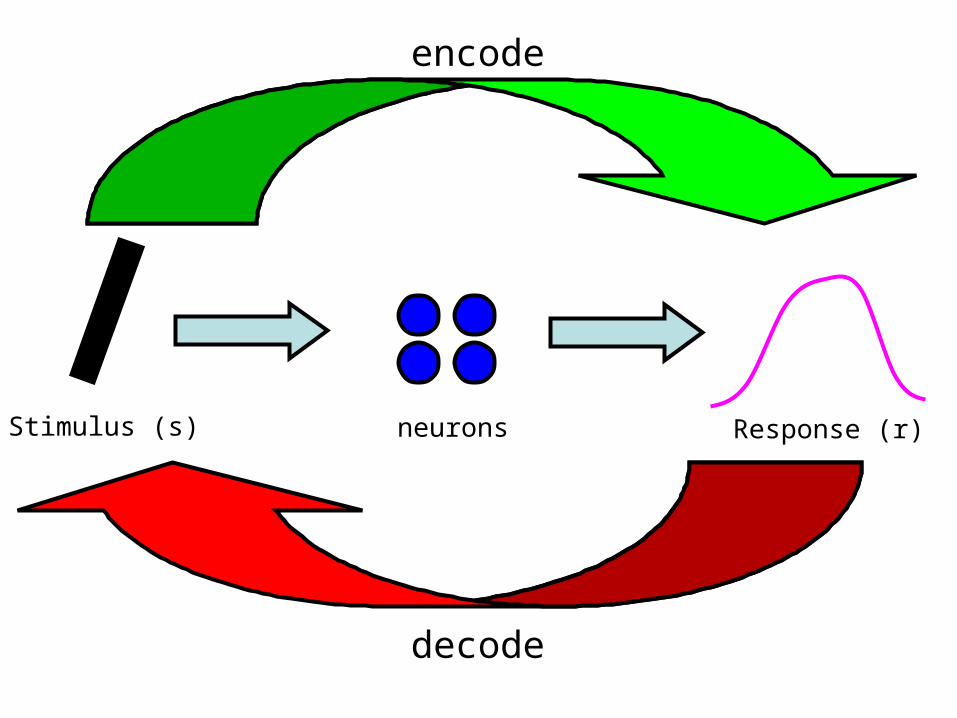
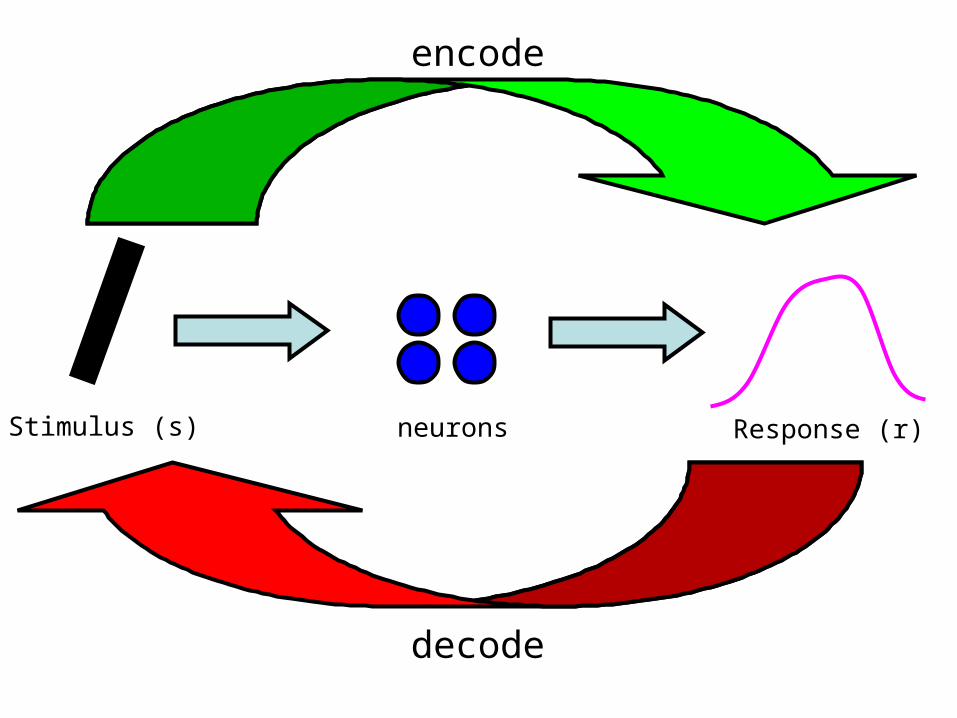
Stimulus (s) neurons
encode
Response (r)
decode
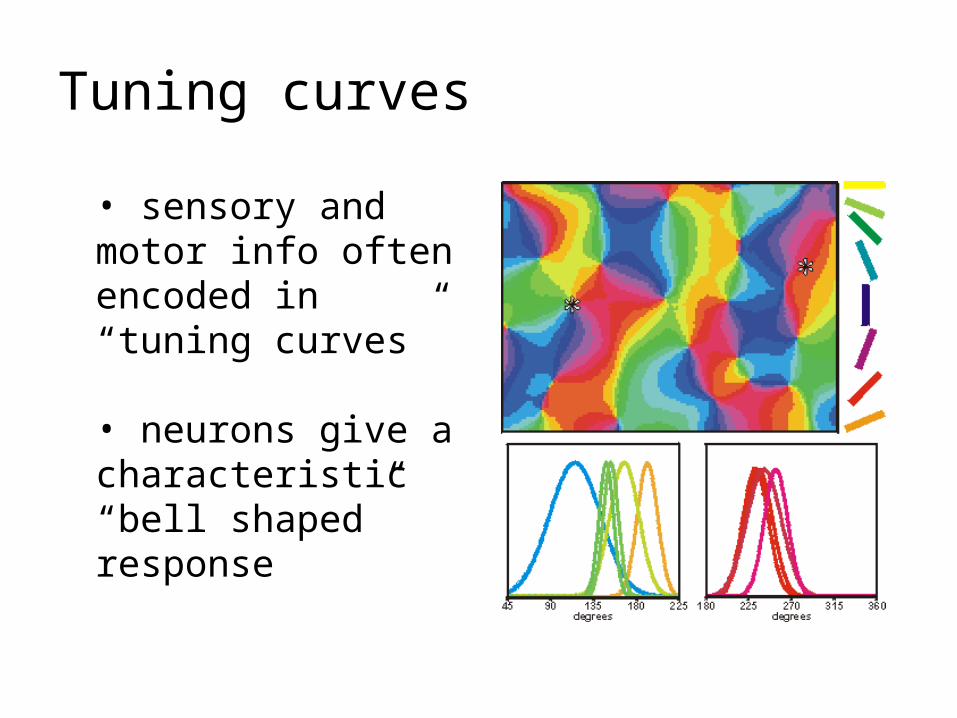
Tuning curves
• sensory and motor info often encoded in “tuning curves”
• neurons give a characteristic “bell shaped” response

Difficulty of decoding
• noisy neurons create variable responses to same stimuli
• brain must estimate encoded variables from the “noisy hill” of a population response
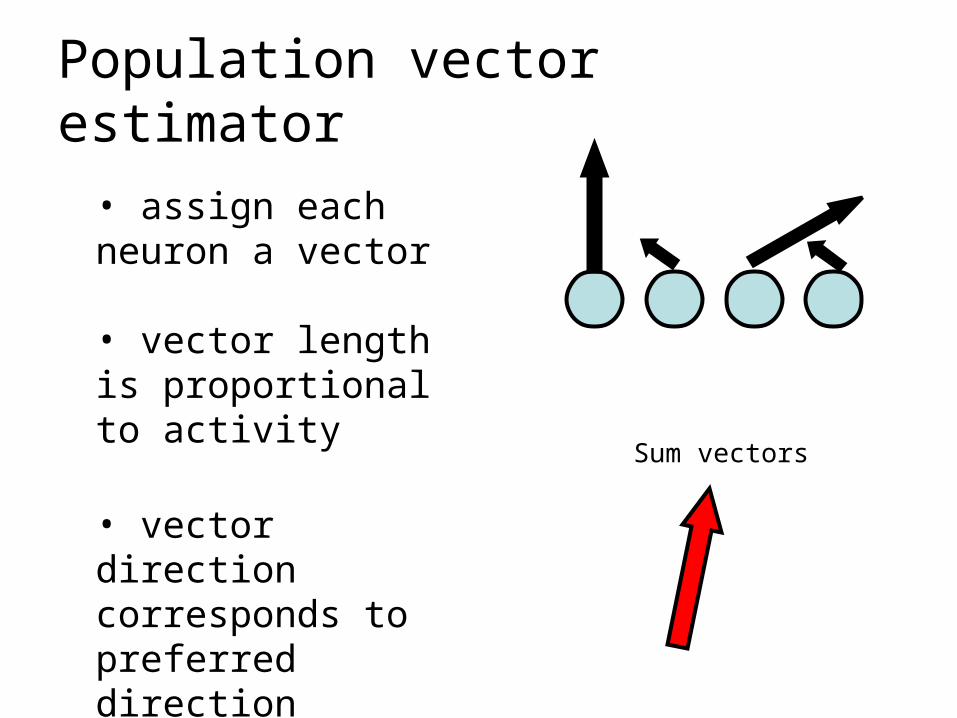
Population vector estimator
• assign each neuron a vector
• vector length is proportional to activity
• vector direction corresponds to preferred direction
Sum vectors
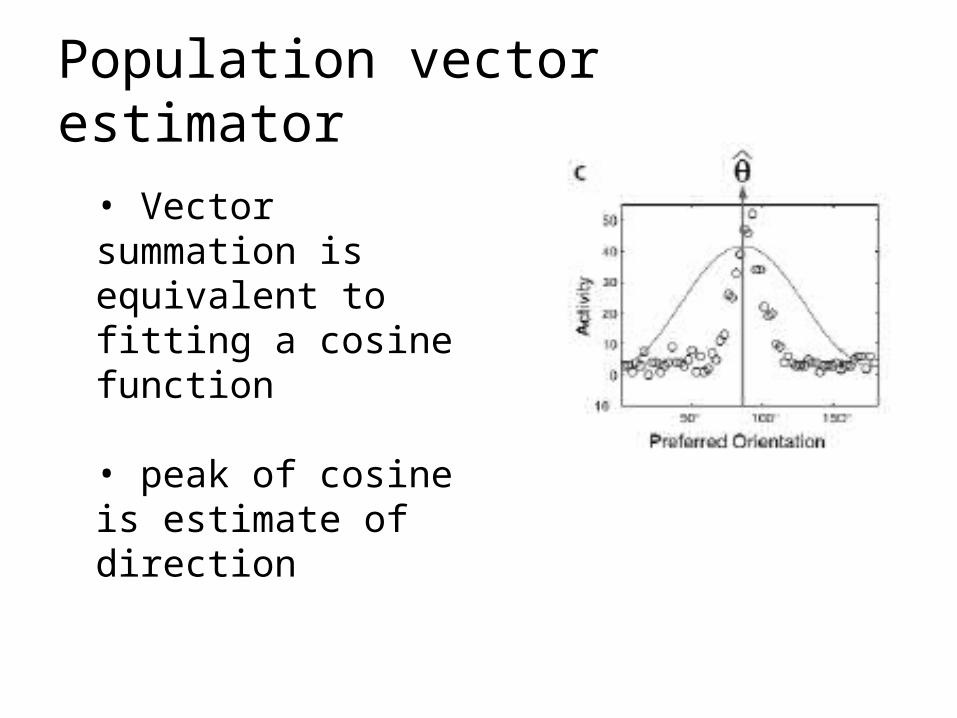
Population vector estimator
• Vector summation is equivalent to fitting a cosine function
• peak of cosine is estimate of direction

How good is an estimator?
• need to compare variance of estimator after repeated presentations to a lower bound
• the maximum likelihood estimate gives the lower variance bound for a given amount of independent noise
VS
Stimulus (s) neurons
encode
Response (r)
decode

Maximum Likelihood Decoding
Maximum likelihood estimator
Decoding
Encoding

Goal: biological ML estimator
• recurrent neural network with broadly tuned units
• can achieve ML estimate with noise independent of firing rate
• can approximate ML estimate with activity-dependent noise
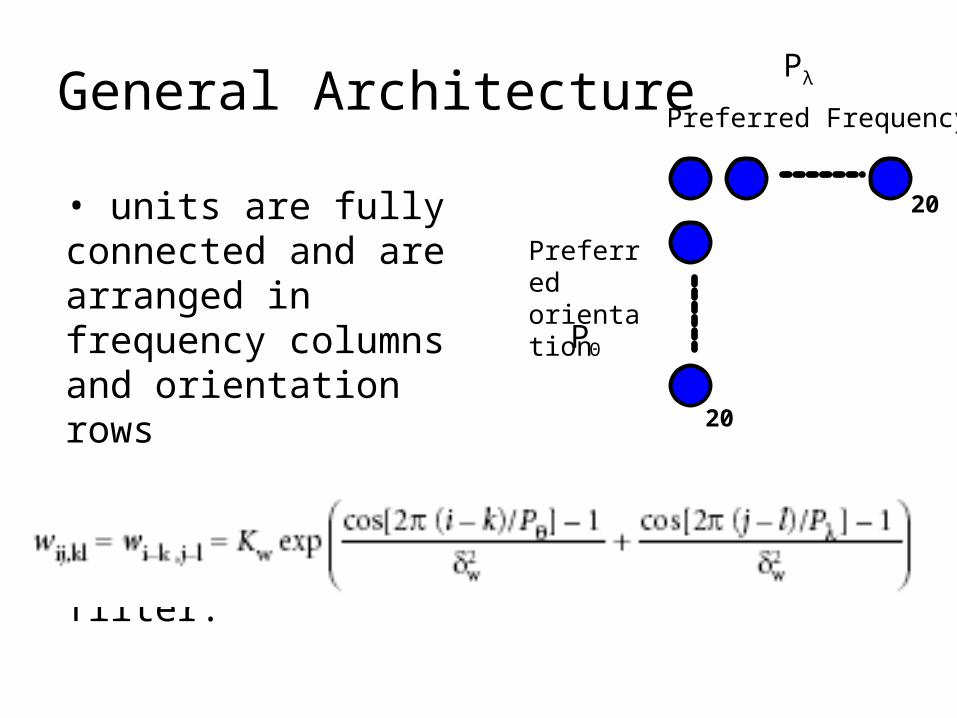
General Architecture
• units are fully connected and are arranged in frequency columns and orientation rows
• weights implement a 2-D Gaussian filter:
20
20
Preferred Frequency
Preferred orientation
PΘ
Pλ

Input tuning curves
• circular normal functions with some spontaneous activity:
• Gaussian noise is added to inputs:

Unit updates & normalization
• units are convolved with filter (local excitation)
• responses are normalized divisively (global inhibition)

Results
• Rapidly converges
•strongly dependent on contrast
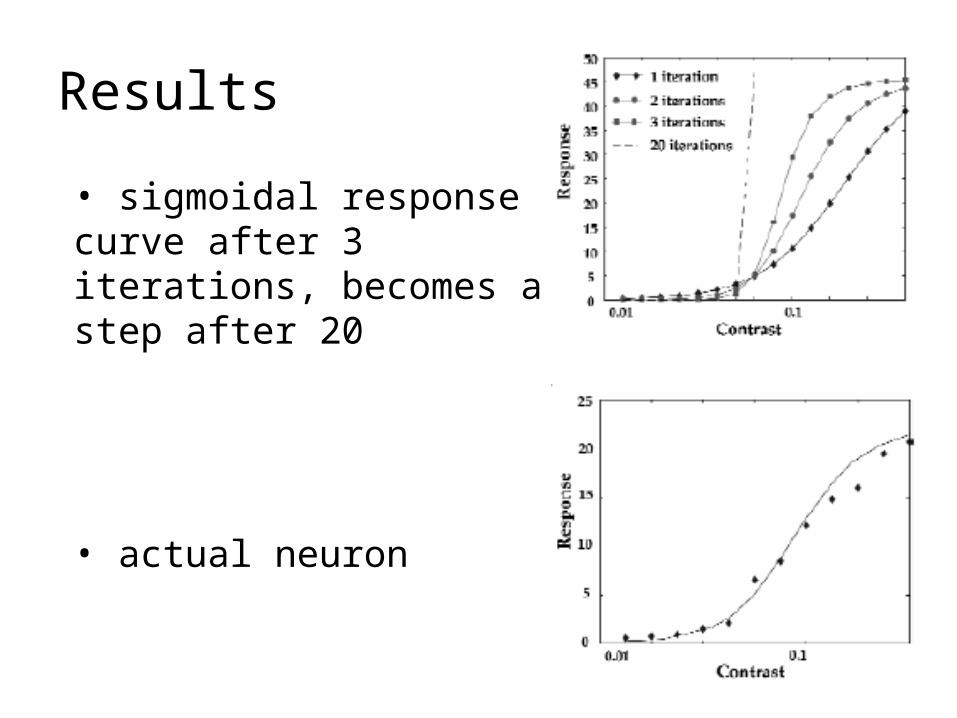
Results
• sigmoidal response curve after 3 iterations, becomes a step after 20
• actual neuron

Noise Effects
• Width of input tuning curve held constant
• width of output tuning curve varied by adjusting spatial extent of the weights
Flat Noise
Proportional Noise

Analysis
Q1: Why does the optimal width depend on noise?
Q2: Why does the network perform better for flat noise?
Flat Noise
Proportional Noise

Analysis
Smallest achievable variance:
= inverse of the covariance matrix of the noise
= vector of the derivative of the input tuning curve with respect to
For Gaussian noise:
Trace term is 0 when R is independent of Θ (flat noise)
Θ

Summary
• network gives a good approximation of the optimal tuning curve determined by ML
• type of noise (flat vs proportional) affected variance and optimal tuning width

















