28
Memory Hierarchy Cache DRAM Flash Disk L: 0.5ns, C: 10MB L: 50ns, C: 100GB BW: 100GB/s L: 10us, C: 2TB BW: 2GB/s L: 10ms, C: 4TB BW: 600MB/s Latency, Capacity, Bandwidth Controlle r
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | kieran-rodgerson |
| View: | 213 times |
| Download: | 0 times |

Memory Hierarchy
Cache
DRAM
Flash
Disk
L: 0.5ns, C: 10MB
L: 50ns, C: 100GB
BW: 100GB/s
L: 10us, C: 2TB
BW: 2GB/s
L: 10ms, C: 4TB
BW: 600MB/s
Latency, Capacity, Bandwidth
Controller

DRAM Primer<bank, row, column>
Page buffer per bank

DRAM Characteristics
DRAM page crossing Charge ~10K DRAM cells and bitlines
Increase power & latency
Decrease effective bandwidth
Sequential access VS. random access Less page crossing
Lower power consumption
4.4x shorter latency
10x better BW
5

Take Away: DRAM = Disk

Embedded Controller
Opportunities for customization
Bad News
None available as in general purpose processor
Good News

Agenda
Overview
Multi-Port Memory Controller (MPMC)
Design
“Out-of-Core” Algorithmic Exploration

9
Motivating Example: H.264 Decoder
6.4 9.6 1.2 164.8 0.09 31.0 156.7 94MB/s Dynamic latency,
BW and power
Diverse QoS requirements
Latency sensitive
Bandwidth sensitive

10
Wanted
Bandwidth guarantee
Prioritized access
Reduced page crossing

Previous Works Bandwidth guarantee
• Q0: Distinguish bandwidth guarantee for different classes of ports
• Q1: Distinguish bandwidth guarantee for each port Q2: Prioritized access Q3: Residual bandwidth allocation Q4: Effective DRAM bandwidth
Q0 Q1 Q2 Q3 Q4
[Rixner,00][McKee,00][Hur,04] ✓
[Heighecker,03,05][Whitty,08] ✓ ✓ ✓
[Lee,05] ✓ ✓
[Burchard,05] ✓ ✓
Proposed BCBR ✓ ✓ ✓ ✓11

12
Key Observations
Port locality: Same port requests
same DRAM page
Service time flexibility 1/24 second to decode a
video frame 4M cycles at 100 MHz for
request reordering
Residual bandwidth Statically allocated BW Underutilized at runtime
Weighted round robin: Minimum BW guarantee Busting service
Credit borrow & repay Reorder requests according
to priority
Dynamic BW calculation Capture and re-allocate
residual BW

13
R20
T(Rij): arriving time of jth requests for Qi
Weighted Round Robin
Assume bandwidth requirement Q2: 30% Q1: 50% Q0: 20%
Request time:
Service time:
Clock:
Tround = 10
Time: scheduling cycles
0 1 2 3 4 5 6 7 8 9
T(R2)
Q2
T(R1)
Q1
T(R0)
Q0
R00
R20
R10
R01
R21
R11
R21
R22
R12
R22
R13R10
R14R11 R12 R13 R14
R00 R01

14
Problem with WRR
Priority: Q0 > Q2
8 cycles of waiting time! Could be worse!
R20
Clock: 0 1 2 3 4 5 6 7 8 9
T(R2)
Q2
T(R1)
Q1
T(R0)
Q0
R00
R20
R10
R01
R21
R11
R21
R22
R12
R22
R13R10
R14R11 R12 R13 R14
R00 R01

15
Borrow Credits
Zero Waiting time for Q0!
Clock: 0 1 2 3 4 5 6 7 8 9
T(R2)
Q2
T(R1)
Q1
T(R0)
Q0*R00
R20
R10
R01
R21
R11
R22
R12
R20
R00 R01
debtQ0 Q2 Q2Q2
borrow

16
Repay Later
At Q0’s turn, BW guarantee is recovered
Clock: 0 1 2 3 4 5 6 7 8 9
T(R2)
Q2
T(R1)
Q1
T(R0)
Q0*R00
R20
R10
R01
R21
R11
R22
R12 R13R10
R14R11 R12 R13 R14
R00 R01
debtQ0 Q2 Q2Q2
R20
Q2Q2
Q2Q2
Q2Q2
Q2Q2
Q2Q2
R21 R22
Q2Q2
Q2
repay
Prioritized access!

17
Problem: Depth of DebtQ DebtQ as residual BW collector
BW allocated to Q0 increases to: 20% + residual BW
Requirement for the depth of DebtQ0 decreasesClock: 0 1 2 3 4 5 6 7 8 9
T(R2)Q2
T(R1)Q1
T(R0)Q0*
R00
R20
R10
R01
R21
R11
R22
R12 R13
R10
R03
R11 R12 R13
R00 R01
debtQ0 Q2 Q2Q2
R20
Q2Q2
Q2Q2
Q2Q2
Q2Q2
Q2Q2
R21 R22
Q2Q2
Q2
Help repay
R03

18
Evaluation Framework Simulation Framework
Workload: ALPBench suite DRAMSim: simulates DRAM latency+BW+power Reference schedulers: PQ, RR, WRR, BGPQ

Port 0 1 2 3 4
RR 1.08% 24% 24% 24% 24%PQ 0.73% 80% 18% 0% 0%BGPQ 1.07% 39% 20% 20% 20%WRR 0.76% 33% 22% 22% 22%BCBR 0.76% 33% 22% 22% 22%
19
Bandwidth Guarantee
Bandwidth guarantees: P0: 2% P1: 30% P2: 20% P3:20%
P4:20%
System residual: 8%No BW
guarantee
Provides BW guarantee!

20
Cache Response Latency
Average 16x faster than WRR As fast as PQ (prioritized access)
Late
ncy
(ns)

21
DRAM Energy & BW Efficiency
30% less page crossing (compared to RR) 1.4x more energy efficient 1.2x higher effective DRAM BW
As good as WRR (exploit port locality)
RR BGPQ WRR BCBR
GB/J 0.298 0.289 0.412 0.411
Act-Pre Ratio 29.6% 30.1% 23.0% 23.0%
Improvement 1.0x 0.97x 1.38x 1.38x

Hardware Cost
22
Xilinx MPMC: frontend + backend 3450 LUTs 5540 registers 1-9 BRAMs
BCBR + Speedy 3379 LUTs 2264 registers 4 BRAMs
BCBR: frontend 1393 LUTs 884 registers 0 BRAM
Reference backend: speedy DDRMC 1986 LUTs 1380 registers 4 BRAMs
Better performance without higher cost!

Agenda
Overview
Multi-Port Memory Controller (MPMC)
Design
“Out-of-Core” Algorithm / Architecture
Exploration

Idea
24
Remember DRAM=DISK
So let’sAsk the same questionPlug-on DRAM parametersGet DRAM-specific answers
Out-of-core algorithmsData does not fit DRAMPerformance dominated by IO
Key questionsReduce #IOsBlock granularity
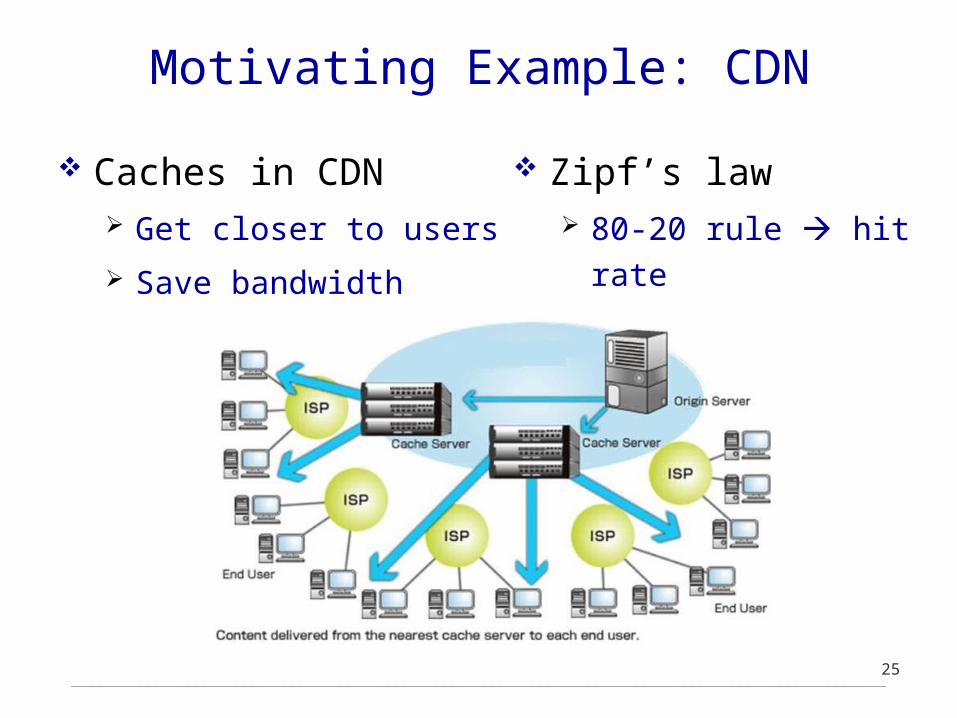
Motivating Example: CDN
Caches in CDN Get closer to users
Save bandwidth
Zipf’s law 80-20 rule hit
rate
25

Video Cache

27
Defining the KnobsTransaction
a number of column access commands enclosed by row activation / precharge
W: burst sizes : # bursts
Function of array organization & timing params
Function of array organization & timing params
Function of algorithmic parameters

D-nary Heap
Algorithmic Design Variable:Branching Factor
Record Size

B+ Tree

Lessons Learned
Optimal result can be beautifully
derived!
Big O does not matter in some cases Depending on data input characteristics

















