This is an electronic reprint of the original article. This reprint may differ from the original in pagination and typographic detail. Powered by TCPDF (www.tcpdf.org) This material is protected by copyright and other intellectual property rights, and duplication or sale of all or part of any of the repository collections is not permitted, except that material may be duplicated by you for your research use or educational purposes in electronic or print form. You must obtain permission for any other use. Electronic or print copies may not be offered, whether for sale or otherwise to anyone who is not an authorised user. Rinne, Mikko; Nuutila, Esko Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL Published in: JOURNAL ON DATA SEMANTICS DOI: 10.1007/s13740-016-0073-4 Published: 01/06/2017 Document Version Peer reviewed version Please cite the original version: Rinne, M., & Nuutila, E. (2017). Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL. JOURNAL ON DATA SEMANTICS, 6(2), 57-69. https://doi.org/10.1007/s13740-016-0073-4
Transcript
This is an electronic reprint of the original article.This reprint may differ from the original in pagination and typographic detail.
Powered by TCPDF (www.tcpdf.org)
This material is protected by copyright and other intellectual property rights, and duplication or sale of all or part of any of the repository collections is not permitted, except that material may be duplicated by you for your research use or educational purposes in electronic or print form. You must obtain permission for any other use. Electronic or print copies may not be offered, whether for sale or otherwise to anyone who is not an authorised user.
Rinne, Mikko; Nuutila, EskoConstructing Event Processing Systems of Layered and Heterogeneous Events withSPARQL
Published in:JOURNAL ON DATA SEMANTICS
DOI:10.1007/s13740-016-0073-4
Published: 01/06/2017
Document VersionPeer reviewed version
Please cite the original version:Rinne, M., & Nuutila, E. (2017). Constructing Event Processing Systems of Layered and Heterogeneous Eventswith SPARQL. JOURNAL ON DATA SEMANTICS, 6(2), 57-69. https://doi.org/10.1007/s13740-016-0073-4
Journal on Data Semantics manuscript No.(will be inserted by the editor)
Constructing Event Processing Systems of Layered and HeterogeneousEvents with SPARQL
Mikko Rinne · Esko Nuutila
Received: 28 January 2016 / Accepted: 12 September 2016
Abstract SPARQL was originally developed to processqueries over finite-length datasets encoded as RDF graphs.Processing of infinite data streams can be enabled throughcontinuous incremental evaluation of an incoming eventstream. SPARQL Update provides tools for interconnectingqueries, enabling event processing applications to be con-structed out of multiple incrementally processed collabo-rating rules. These rule networks can perform event pro-cessing on heterogeneous event structures. Heterogeneousevent support combined with the capability to synthesisenew events enables the creation of layered event process-ing networks. In this paper we review the different types ofcomplex event processing building blocks presented in liter-ature and show their translations to SPARQL Update rulesthrough examples, supporting a modular and layered ap-proach. The interconnected examples demonstrate the cre-ation of an elaborate network for solving event processingtasks. The performance of the example event processing net-work is verified on the INSTANS platform.
Complex event processing, as pioneered by David Luck-ham [Luckham(2002)], takes a layered approach to eventprocessing systems. Using the core definitions from theEvent Processing Glossary [Luckham and Schulte(2011)],an event is broadly defined as “anything that happens, oris contemplated as happening” and a complex event is “an
M. Rinne and E. NuutilaAalto University School of Science,PO Box 15400, FI-00076 AALTO, FINLANDE-mail: [email protected]
event that summarises, represents, or denotes a set of otherevents”. Event objects, representations of events for com-puter processing, may carry a variable number of parame-ters to describe an event with the accuracy provided by theavailable sensor equipment [Rinne et al(2013)]. In large het-erogeneous systems such as smart cities incorporating hard-ware and software components from multiple suppliers andoperated by independent private, corporate and public actorsthere can be a lot of variation between the data supplied bydifferent sensors, requiring a flexible representation of eventdata. The need for flexibility is further supported by con-cepts like a composite event [Luckham and Schulte(2011)],which is created by combining a set of simple or complexevents, always encapsulating the components from whichthe composite event is derived.
Semantic web standards RDF [W3C(2014)] andSPARQL [W3C(2013a)] offer a good set of tools to copewith distributed heterogeneous environments. RDF is builtwith an open-world assumption and together with OWL itoffers tools to manage both disjoint and overlapping on-tologies and datasets from different sources. The inclusionof blank nodes in RDF and the support for querying overproperty paths in SPARQL provide flexible means to en-code and match event objects using variable numbers of el-ements and layers. TriG [Bizer and Cyganiak(2014)] addsfurther structure by supporting the transfer of RDF datasetsin Turtle format [Beckett et al(2014)]. SPARQL, with sup-port for federated queries, offers a natural way to enrichevents with static background data available in the web e.g.as linked open data. SPARQL Update [W3C(2013b)] withquery-based conditional INSERT and DELETE commandsprovides a SPARQL-compliant framework, which can beused to build networks of rules and store information dur-ing runtime.
The benefits of using SPARQL for event processing in-clude all the benefits of semantic web in general, e.g. agreed
The final publication is available at Springer via http://dx.doi.org/10.1007/s13740-016-0073-4
2 Mikko Rinne, Esko Nuutila
specifications, conceptual compatibility through shared on-tologies, compatibility with the current tool base, supportfor loosely coupled heterogeneous systems, straightforwardconnectivity to linked open data for enriching event infor-mation and a solid base of inference mechanisms to performreasoning over events.
The contribution of the present document is to demon-strate how the eight types of event processing buildingblocks listed in [Etzion et al(2010)] can be encoded inSPARQL to create an event processing network capable ofhandling heterogeneous events using standard unextendedsemantic web technologies. This document is based on aconference paper [Rinne and Nuutila(2014)], revised andextended by the addition of the performance evaluation.
The background of stream processing with SPARQL isexplained in Section 2. Structured representations of het-erogeneous events using RDF are reviewed in Section 3.SPARQL representations for different types of event pro-cessing agents are shown in Section 4 and their performanceevaluated in Section 5. The results are analysed in Section 6.Conclusions and future areas of study are outlined in Section7.
2 Stream Processing in SPARQL
Stream processing in the context of databases originatesfrom the observation that for an append-only database it ismore efficient to process a standing query against the newlyarriving data than to execute periodical queries against thewhole database [Terry et al(1992)]. Queries calculating ag-gregate values need to be computed over a finite partition ofan event stream known as stream windows to be solvable infinite time. These systems are commonly referred to as datastream management systems (DSMS) [Babcock et al(2002),Arasu et al(2006)].
Another approach to stream processing is to incre-mentally and asynchronously process each incoming eventagainst a pre-defined set of queries. Instead of windowsbased on time or number of streamed elements, the first stepof processing is based on events and event patterns, whichcontribute new input to the queries. When all the requiredinputs of a query are present, the result is immediatelyavailable. Complex event processing (CEP), pioneered by[Luckham(2002)], emphasises the hierarchical processingof events and event patterns, where higher level abstractionscalled complex events are derived to summarise the meaningof simple events. A more detailed survey of DSMS and CEPsystems can be found in [Cugola and Margara(2012)].
The SPARQL query language, developed by W3Cas the semantic web counterpart to SQL from the re-lational database world, was first released as a recom-mendation in January 2008. SPARQL is built to pro-
cess queries over finite, possibly distributed datasets en-coded in RDF. Event streams, such as the flows of mea-surements from sensors, are intrinsically infinite. The firstplatform to demonstrate window-based stream process-ing in SPARQL was C-SPARQL1 [Barbieri et al(2010a),Barbieri et al(2010b),Barbieri et al(2010c)]. In C-SPARQLRDF streams are built out of time-annotated triples. C-SPARQL provides a mechanism, where the window size canbe based on either time or the number of triples. Aggregationoperators COUNT, MAX, MIN, SUM and AVG (later incor-porated into SPARQL 1.1 Query specification) are used tocompute aggregate values over the windows. There is alsoa timestamp() function to access the timestamp of a triplepattern. CQELS2 [Le-Phuoc et al(2011)] and SPARQLStream/ MorphStreams3 [Calbimonte et al(2010)] are later im-plementations of window-based streaming SPARQL. C-SPARQL, CQELS and SPARQLStream assume repeated pro-cessing of queries over windows based on either time ornumber of triples. As pointed out in [Rinne et al(2012a)],this approach has some challenges:
– Support for heterogeneous events: Delimiting win-dows by time (with timestamps assigned to individualtriples) or the number of triples carries an implicit as-sumption that each event is represented by a single triple.Event objects consisting of a variable number of triplescould either be split across window borders (there is noexplicit marker to indicate when an event is complete) orunintentionally merged, if the timestamps are identical.Objects consisting of a constant number of triples couldbe windowed based on the number of triples, but thisapproach easily gets out-of-sync. The RDF Stream Pro-cessing Community Group4 (RSP-CG) has lately beenconverging towards representing RDF streams as time-stamped graphs, which overcomes this problem.
– Window dimensioning: When a query involves multi-ple events in an event stream, a window has to be largeenough to capture all the related events. Since the timingof stream windows is not synchronised to event objects,the windows have to overlap to avoid missing event pat-terns due to window borders, resulting in duplicate pro-cessing and duplicate detections, which need to be fil-tered out. Faster window repetition helps to decreasedetection delay, but leads to more duplicate processingand detections. In an event processing system these con-flicting requirements lead to unwanted compromises be-tween duplicate processing, duplicate detections and no-tification delay.
– False positives: If an event pattern involves detectingthe absence of an event, the stream window approach
Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL 3
will produce false positive detections in cases, wherethe event required to be absent does exist, but falls out-side the current window boundaries. Such cases can besolved by e.g. persistence of state between windows andfiltering, but the complexity of the task increases consid-erably. Such mechanisms are also not commonly avail-able in stream processing platforms.
– Resource usage: Queries are processed repeatedly overthe defined windows, even when there are no new match-ing events.
EP-SPARQL [Anicic et al(2011)] is focusing on the de-tection of RDF triples in a specific temporal order. Thepublished examples also support heterogeneous event for-mats, create aggregation over sliding windows using sub-queries and expressions, and layer events by construct-ing new streams from the results of queries. The prolog-based ETALIS5 incorporates more functionality than theEP-SPARQL front-end. The ETALIS input stream is madeof triples with two timestamps (time interval semantics), buttimestamped graphs were not supported at the time of writ-ing.
Recent discussion on the RDF-processing DSMSplatforms has mostly concentrated on charting thedifferent operational semantics, and considerations onproper methods for benchmarking [Dell’Aglio et al(2013),Tommasini et al(2015),Kolchin et al(2016)]. At the sametime the RSP-CG is working towards a common specifica-tion for an RSP query language.
Algorithms familiar from production rule systems, suchas Rete [Forgy(1982),Forgy(1979)], can be adapted touse SPARQL to describe the rules. Streaming SPARQLwas first presented in [Groppe et al(2007)] using anetwork highly similar to Rete. Komazec and Cerri[Komazec and Cerri(2011)] apply SPARQL queries to RDFdata using an extended Rete-algorithm in a system calledSparkwave6. Their focus is on supporting selected RDF andRDFS inference rules through the use of a pre-processinge network and fast processing of data streams consistingof individual triples instead of multi-triple events. Rete hasalso been used for processing SPARQL queries by De-pena and Miranker in [Depena(2010),Miranker et al(2012)],where the focus is on nested access of dereferenced URIs,exploiting the constructive analogy with forward-chainingproduction systems.
In [Abdullah et al(2012)] it is shown that an enginebased on the Rete algorithm can incrementally processSPARQL queries offering competitive performance. Thecreation of an event processing application using multipleinterconnected SPARQL queries has been described andtested in [Rinne et al(2012a)], while use-cases in the do-
main of semantic sensor systems have been further elabo-rated in [Rinne et al(2012b)]. This approach is representedby the SPARQL-based event stream processing platformdenoted INSTANS7. The query language is SPARQL 1.1[W3C(2013a)], implementing also selected properties ofSPARQL 1.1 Update [W3C(2013b)], such as INSERT andDELETE. In [Rinne et al(2012a)] we have described thecreation of event processing applications using intercon-nected SPARQL update rules. The concept of collaboratingSPARQL queries for stream processing is discussed also in[Teymourian et al(2012)], with Teymourian et al preferringa backward-chaining algorithm over the forward-chainingtype used in Rete.
Outside the semantic web domain multiple stream andevent processing platforms are in active commercial use.A CEP market survey from 20168 lists 33 currently sup-ported platforms. None of these platforms support pro-cessing of RDF data with SPARQL queries9. The per-formance of INSTANS has been compared to Esper10 in[Rinne et al(2016)] by converting RDF data to XML and thequeries to Esper-proprietary EPL (Event Processing Lan-guage). Another platform with similar query functionality isWSO211, also with a proprietary query language (“Siddhi”)and no support for RDF.
3 Event Objects in RDF
In data stream processing applied to RDF it has initiallybeen assumed that each triple carries a standalone event.A suitable event could be the single reading of a temper-ature sensor or the license plate of a car from a tollgate.However, to minimise redundant data transfer and process-ing in the system, periodic measurements should be filteredas close to the source as possible, elevating to a higher levelof abstraction, where only sensor readings falling outside ofpreviously defined reporting thresholds or otherwise unex-pected results are forwarded upstream as events. This kindof filtering can be carried out in a “middle layer” sensorgateway node [Rinne et al(2012b)]. These filtered event ob-jects typically carry more information than a single sensorreading and timestamp. RDF is better motivated as the dataformat for heterogeneous asynchronously triggered eventsthan frequent periodic measurements of a single parameter,for which there are more compact representations. Differ-ent sensors, gateways or even different driver software ver-sions of the same sensor may include different types of aux-iliary data in addition to the base parameters used by the
7 Incremental eNgine for STANding Sparql, http://instans.org/8 http://www.complexevents.com/2016/05/12/cep-tooling-market-
Fig. 1 Example Event for Sensor Location Reporting
event processing application. Also in [Etzion et al(2010)]the assumed structure of an event includes a variable-lengthheader, which the event processing system can process,and a body, which is transported as unstructured payload.These structural requirements have been addressed by theevent processing ontology12 [Rinne et al(2013)]. To savespace and improve clarity, the event objects in this paperare simple events without separate header and body parts,but the extensions to support header, body and compos-ite events from the event processing ontology can be usedto extend the examples presented herein as demonstratedin [Rinne et al(2013)]. A sample event format for the pur-pose of updating the location of a sensor is illustrated inFigure 1. The dotted altitude field exemplifies an optionalfield, which may not be included by all sensors. The Turtleserialisation encapsulated in TriG is shown in Figure 2. Eventhough RDF triples can be used to build graphs of infinitelycomplex structures, there is no clear and reliable way to ex-press the boundaries of a “data record” such as an event ob-ject, as pointed out in [Keskisarkka and Blomqvist(2013)].This may cause problems when event objects in a streamcontain optional elements. A query often produces differentresults depending on whether some optional elements arepresent, but there is no general rule for how long the optionaltriples should be waited for in the case of an infinite stream.INSTANS can be configured to jointly process a “block” ofdata, which in the case of Turtle maps to all consecutivetriples connected by a common subject or blank nodes ac-cording to rule #6 (“triples”) of the Turtle grammar13. How-ever, something as simple as sending the latitude and lon-gitude coordinates of Figure 2 before the rest of the eventmay cause problems: A first block terminates already afterthe coordinates which, depending on the associated queries,
may trigger results different from the case where the coor-dinates are sent after the event. The issue is further empha-sised in a rule-based system like INSTANS, where the userhas no explicit control over the order in which simultane-ously matching rules are executed and therefore the order inwhich triples are output. TriG [Bizer and Cyganiak(2014)]
Fig. 2 Prefixes and an example location event encapsulated in TriG
defines a way of communicating datasets as Turtle by en-capsulating graphs. With this approach each event objectis a graph, and each graph can be processed as a blockwith no ambiguity. This has clear benefits in matching in-coming event objects having optional or unknown content.In [Rinne et al(2013)] unknown content is matched usingnested OPTIONAL clauses tracking triples connected byblank nodes. With TriG the situation is greatly simplified,because the entire incoming event object - independent ofstructural complexity or order of triples - can be matchedsimply with “?s ?p ?o”, as e.g. in Figure 5.
There are multiple different ways to use TriG in this con-text. The graph names for each event object could be thesame (all event objects belong to the same named graph) orthe name could be omitted entirely from the input stream (allevent objects are input via the main graph), but the delimita-tion property would still be maintained. The approach usedin this paper improves graph-level traceability, because allevents are uniquely identified on graph level, but the trade-off is that some of the granularity in using named graphs islost: Each event object is encapsulated into a named graphand since SPARQL doesn’t offer regular expression match-ing for graph names in one step, the incoming event objectshave to be matched to variables and filtered in two separatesteps, as shown in the examples of Section 4.
The only currently supported way of adding triples tonamed graphs is by using INSERT from SPARQL Update[W3C(2013b)], as is done extensively in our examples. Asthe SPARQL Update operations in INSTANS are memory-internal, INSTANS implements a small extension to add thenamed graph syntax from INSERT to CONSTRUCT to en-able output of event object datasets in TriG-format.
Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL 5
3.#Event#Processing#Agent#
1.#Event#Producer#
4.#Event#Consumer#
Event Processing Network
2.#Event#Channel#
2.#Event#Channel#
Fig. 3 Building Blocks of an Event Processing Network
Event&Processing&Agent&
Filter& Transforma5on& Pa6ern&Detect&
Translate& Aggregate& Split& Compose&
Enrich& Project&
Fig. 4 Types of Event Processing Agents (from [Etzion et al(2010)])
4 Event Processing Agents in SPARQL
Etzion et al. [Etzion et al(2010)] propose a set of eventprocessing agents (EPA) to be used as building blocks inconstructing event processing networks (EPN), shown inFigure 3. Event Processing Agents (3.) operate on events,which are transported between EPAs over Event Channels(2.). Two special types of EPA are Event Producer (1.),which is a source of events and has no inputs in this EPNand Event Consumer, which is an event sink and has nooutputs in this EPN. It should be noted, however, that ina system with multiple EPNs the Event Consumer of oneEPN can typically be an Event Producer in another. Whentranslated to SPARQL, EPAs are implemented as SPARQLUpdate rules or networks of rules. Event Channels can bemodelled as named graphs, providing isolated connectionpoints for event object transfer between EPAs. The types ofevent processing agents from [Etzion et al(2010)] are shownin Figure 4. In the following subsections the SPARQL im-plementation of each type, complemented by the set of filtertypes from [Taylor and Leidinger(2011)], are examined toshow the implementations as SPARQL Update rules.
4.1 Filters
Filters select interesting events or eliminate uninterestingones. A forwarding decision is made based on a test or setof tests. In a stateless filter the decision is fully based on the
current event object. An example (EPA 1) of a stateless filterto pass through all events generated during business hours isshown in Figure 5. Since only the time attribute is neededfor filtering, it is the only explicitly matched object. Other-wise the entire incoming event object is matched with “?s?p ?o” and copied in case it passes the filter. The str(<>)
function produces the BASE URI as a string. It is needed be-cause the graph and event names are prefixed with the BASEURI when read from a file. The BIND-statement is used toprefix the output graph name with “Poststateless”, separat-ing it from incoming event objects and thereby creating anew event channel.
Fig. 5 EPA 1: A stateless filter passing through events generated dur-ing business hours.
A stateful filter utilises information external to the in-coming event, e.g. information based on previously pro-cessed events or an external source. A stateful filter (EPA2) to pass through one location update per hour is shownin Figure 6. This filter, implemented as three SPARQL Up-date rules, demonstrates how a graph is used as memoryto save the hour of the previous event for comparison. Ex-plicit memory initialisation in EPA2-1 is used to avoid OP-TIONAL statements in the other queries. It can be observedthat implementing a stateful filter with a SPARQL systembased on stream windows would be practically impossiblein scenarios where one window should incorporate multipleevents. Because all the events in a window are processedjointly as a batch, results of processing one event cannot in-fluence the processing of the next one. Therefore statefulfilters such as the example in Figure 6 typically require acontinuous engine, which processes each event as it arrivesin a stream.
In principle a SPARQL-based event processing networkcan support all types of filters, which can be computedwith the available arithmetic operators, taking into accountthat multiple filter stages can be chained like any otherEPA:s. One clear limitation is the absence of square rootin SPARQL, causing the calculation of geographical dis-tances to be usually processed with extension functions. Asa collection of filter types Table 1 shows the filters listed in[Taylor and Leidinger(2011)] as “input specifiers” togetherwith the corresponding SPARQL FILTER statements. Thefirst four filters are clearly stateless. The last one, change,does stateful comparison, but it would also be simpler to
6 Mikko Rinne, Esko Nuutila
# EPA2-1 Initialize
INSERT DATA { GRAPH <memory> { :stateful :hour -1 ;
:passEvent [] } };# EPA2-2 Update memory, mark passing events
Fig. 6 EPA 2: A stateful filter passing one event per hour.
implement as a combination of an aggregate block (EPA6below) to compute a sliding aggregate value (e.g. min, max,average) over the n previous readings and compare the out-put of that block to the latest value using a stateless filter.
4.2 Transformation
Transformation agents modify the content of received eventobjects. Subtypes are:
– Translate: Operate on each event object independentlyof preceding or subsequent objects using a single in- single out model. A special case is Enrich, whichattaches additional information to an event object.SPARQL is particularly well suited for this purpose be-cause any data from a SPARQL endpoint can be queriedas a federated query. An example is given as EPA 3(Figure 7), where our location events are enriched withpreferred geographical labels from FactForge14.
– Project: Remove information from the incoming event.An example of this (EPA 4) would be e.g. the removal ofthe recently added location names, as shown in Figure 8.
– Split: Split a single incoming event into multiple outgo-ing events. In EPA 5 (Figure 9) incoming events are splitto two types, SensorEvents and GeoEvents, transmittedover separate channels.
– Aggregate: Output a function of incoming events ina multiple-in single-out model. Typical examples arecount, min, max, average and sum. The example in EPA6 (Figure 10) counts the number of incoming events
14 http://factforge.net
per hour using a combination of five rules. EPA6-1 ini-tialises the memory graph. EPA6-2 compacts SPARQLcode lines by extracting the hour of the incoming event,used by all three subsequent queries. EPA6-3 increasesthe event counter, 6-4 outputs the event counts when thehour changes and 6-5 resets the counter. Since the out-put is triggered by an object of the next hour, the lastcounter result is never produced. This may not be criti-cal in an infinite stream setting, but for completeness onrecorded streams the final output should be triggered e.g.by a special end marker triple at the end of the file. Alter-natively the count could be updated after every event ob-ject, which would be a more typical approach for streamprocessing.
– Compose: Combine two or more incoming streams toa single output stream. An example is given as EPA 7in Figure 11, a very straightforward reversal of EPA5with the contents of the INSERT and WHERE clausesreversed.
Fig. 7 EPA 3: Enriches incoming events with location labels.
Many streaming SPARQL platforms [Barbieri et al(2010a),Le-Phuoc et al(2011)] implement proprietary SPARQL ex-tensions for computation of aggregate values over timewindows. These tailor-made solutions result in compactqueries, but currently suffer from problems in support-ing heterogeneous events due to the window size defi-nitions outlined in Section 2 and different timecodes instreams. There is currently no specified way to use e.g.ep:hasEventObjectSamplingTime from the sample events ofthis paper as the time base for these window operators, re-quiring an additional conversion step. With the manuallygenerated aggregate calculation rules used by INSTANS win-dowing can be based on any parameter (e.g. location), notjust time, from the incoming RDF stream. Multiple aggre-gate values can also be computed jointly. In the exampleabove the sum of latitude and longitude coordinates could
Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL 7
Description: SPARQL filterEqual: Check for equality FILTER (?value1 = ?value2)About: Equality within a defined tolerancevalue FILTER (abs(?value1 - ?value2) < tolerance)
Area: Interval between two values FILTER ((?value > lower bound) &&(?value < upper bound))
Greater / Less: Check if the value is greateror less than a defined value.
FILTER (?value > limit) orFILTER (?value < limit)
Change: Tracks changes compared to n previ-ous readings. “Decrease” and “Increase” canbe used to specify the direction of change.
Two rules recommended: An aggregate to compute “nprevious readings” and a stateless filter to compare.
Table 1 SPARQL implementations of the filter types listed in [Taylor and Leidinger(2011)]
Fig. 9 EPA 5: Event objects split to two channels.
also be recorded, after which it would be easy to averagelocations over time.
As INSTANS operates asynchronously, windowing basedon a real-time clock would require the use of timed events(“pulse” event objects triggered based on a clock, in this caseto trigger aggregate calculation). In many practical casesusing timestamps from the incoming stream is a better ap-proach, because it works on both live and recorded streamsand produces more predictable and repeatable results thanreferencing the clock of the computer. The downside is thatthe absence of an out-of-window trigger event may leave thelast result in an infinite wait state, if not explicitly handled.
4.3 Pattern Detect
Pattern detect agents are searching for patterns in incomingevents. They may either describe the pattern, pass throughqualifying patterns of incoming event objects or both. Sim-ple patterns could be detected e.g. with slightly augmentedstateful filters. A pattern detect example (EPA 8) to detecta pattern of movement directions from consecutive locationupdates is shown here as an example:
1. Transform location updates to a stream of directions:Auxiliary query creating a stream of compass events(e.g. “NW”) out of an incoming stream of location up-dates, Figure 12.
2. Advance pattern index with a positive match: Com-pare incoming direction events with a pattern in a graph,advance an index when they match, Figure 13.
3. Reset pattern index when not matching: If a directionevent does not match the next item in the pattern, resetthe index, Figure 14.
4. Detect completed pattern: When the pattern is com-plete, output detection and reset the index, Figure 15.
It is worth noting that the WHERE-clauses in the two queriesof Figure 15 are completely identical. The only reason whythey cannot be merged is that SPARQL syntax currentlydoes not allow DELETE and CONSTRUCT in the samequery.
5 Performance
The performance of the presented SPARQL-based eventprocessing agents was evaluated on the INSTANS v. 0.3.0.0
8 Mikko Rinne, Esko Nuutila
# EPA6-1 Initialize
INSERT DATA { GRAPH <memory> { :aggrHour :hour -1 ;
Fig. 11 EPA 7: Combine the streams, which were earlier split to Geo-Events and SensorEvents
platform. All tests were executed on a MacBook Pro 2.7GHz Intel Core i5 with 16 GB 1867 MHz DDR3 memoryrunning OS X 10.10.5. The measurements were done aftera clean reboot with no network connection, no antivirus andno virtual drives running. System idle was confirmed to be>99% before starting execution. In speed measurements theoutput was constructed but printed to “/dev/null” to mitigate
# Initialize memory with 1st incoming point from ?sensor
BIND ( IF ( !bound(?tdir) || strlen(?tdir)=0, "0", ?tdir )
as ?dir ) }
Fig. 12 Transform: Generate direction events out of subsequent loca-tions
any impacts of I/O processing. The event processing agentswere tested for batches of 100, 1,000 and 10,000 recordedsimulated location events from 5 sensors, each event con-sisting of six triples [Rinne et al(2012b)]. Each test was ex-ecuted four times, ignoring the first result and using the me-dian of the remaining three as the recorded result. The com-plete code for execution as well as the full results are avail-able in github15.
At the time of writing no other platforms capable ofrunning these examples with RDF data were known to theauthors. The combination of heterogeneous events, layeredasynchronous query networks and event pattern handlingwithout stream windows is not available in the referencedRDF stream processing engines. Similar query functionalitywould be available in Esper and WSO2, but without supportfor either RDF or SPARQL.
15 https://github.com/aaltodsg/instans-cep2sparql
Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL 9
# Initialize memory with 1st direction entry from sensor
INSERT { GRAPH <memory> { # Initialize a new entry to memory
Fig. 14 EPA 8-2: Reset index if the latest direction does not matchwith the pattern
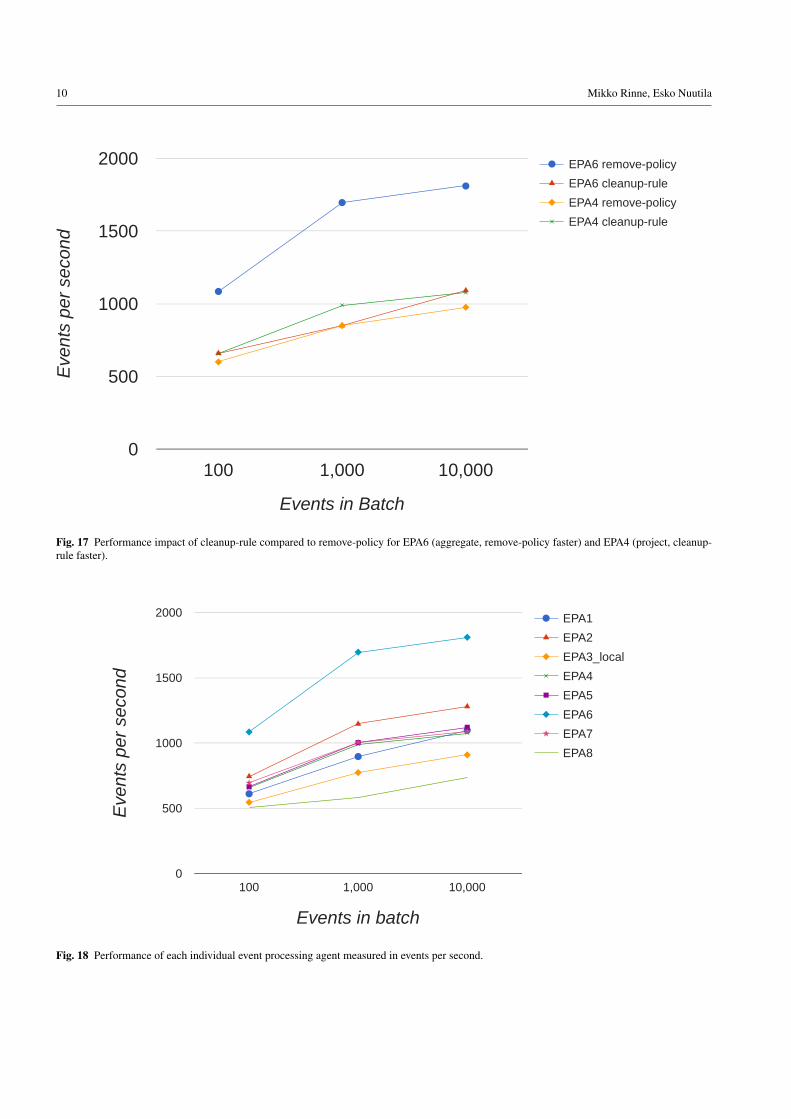
In stream processing it is important to prevent accumu-lation of data into the system. INSTANS offers an operationalremove-policy, which can be used to delete incoming eventsafter all the queries, which reference elements of the incom-ing data, have been processed. Alternatively old events canbe removed by using an explicit cleanup-rule (Figure 16).Both approaches were tested for EPAs 1-6, with the cleanup-rule removing any event older than the most recent one.The remove-policy does not work correctly with EPA7 whendirectly connected to the input events, because both typesof input events need to be available simultaneously for thecombined output to be created. Therefore for stand-alonetesting of EPA7 the cleanup-rule needs to be applied. Theremove-policy was faster than the cleanup-rule in all other
# Reset index when pattern is complete
DELETE { GRAPH <memory> { # Remove last index from memory
Fig. 16 Cleanup-rule to DELETE input events older than the most re-cent one.
cases than EPA4 (project), in which case the cleanup-rulewas 1.1 times faster with the 10,000 event batch. In other testcases slowdown factors of 1.29-1.66 were measured. Thelargest performance penalty was observed for EPA6 (aggre-gate), shown with EPA4 in Figure 17.
To measure the performance of each EPA separately, weused the best-performing option, i.e. cleanup-rule for EPAs4 and 7 and remove-policy for everything else. EPA6 (ag-gregate) and EPA8 (pattern recognition) produce a relativelylow amount of output, which was not separately cleared. Theoutput from other EPAs was cleared with cleanup-rules. Theresults are shown in Figure 18. The performance for the 10kevent batch varied from 736 events per second (EPA8 - pat-tern recognition) to 1810 eps (EPA6 - aggregation). EPA3(enrich) performance was tested locally, i.e. the name of thelocation was bound to a variable with a SPARQL BIND-command. One execution of 100 events was also tested withthe real SERVICE query against factforge with the test com-puter connected to our university network, resulting in per-formance of 3.7 events per second (the comparable EPA3 lo-cal result without federated SERVICE queries was 545 eps).
Fig. 17 Performance impact of cleanup-rule compared to remove-policy for EPA6 (aggregate, remove-policy faster) and EPA4 (project, cleanup-rule faster).
EPA1EPA2EPA3_localEPA4EPA5EPA6EPA7EPA8
100 1,000 10,0000
500
1000
1500
2000
Events in batch
Eve
nts
per s
econ
d
Fig. 18 Performance of each individual event processing agent measured in events per second.
Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL 11
The individual EPAs can be connected to each other,forming the event processing network shown in Figure 19.When running the whole network, stateless and stateful fil-ters effectively reduce the amount of events which need tobe processed by EPAs 3-5 and 7 further down the chain. InFigure 20 the performance of the complete interconnectedEPN (EPA-All) is compared with the sum of the executiontimes of EPAs 1-8 (EPA-Total). For 10k events INSTANSprocessed 176 input events per second, compared with 134eps calculated from the sum of the time of all individualagents processing every event separately.
6 Discussion
The described experiment reveals some structural shortcom-ings, which could be addressed in future releases of theSPARQL specification set:
1. Generating dataset output from a query: Even thoughTriG is specified as a format to convey datasets andSPARQL can query TriG input, the only specified way towrite datasets is using INSERT from SPARQL Update.In INSTANS CONSTRUCT has been extended with thecapability to generate graphs as TriG output. We haveobserved no negative impacts either to the coherence ofthe syntax or the implementation.
2. Combination of output and update: As seen inFigure 15, SPARQL code could be made more compactby allowing multiple result processing operators (e.g.CONSTRUCT and INSERT) in the same query. Evenmore importantly, it is currently very difficult to chainany operation to take place after output processing, be-cause SELECT or CONSTRUCT queries cannot produceany changes detectable by other queries or rules.
In the aggregation example (EPA6, Figure 10) some codelines were reduced by adding an extra query to extract a pa-rameter used by three other queries. INSTANS automaticallymerges identical parts of queries in the internal Rete rep-resentation. Therefore this reduction is only significant interms of SPARQL text for the end-user; the compiled ruleprocessing network is the same. Due to limits in the capa-bilities of a single query, similar parts often need to be usedin multiple queries. A macro mechanism would reduce theneed to replicate the same SPARQL code to multiple places,compacting the source code and reducing the risk of incon-sistency.
While putting all of the tested rules into a single Rete en-gine demonstrates readiness to process complex networks, itis not the most efficient solution. This is manifested by theperformance of the complete EPN, where despite the factthat EPAs deeper in the EPN handle only a fraction of theinput events, the complete EPN is only slightly faster thanthe total sum over all EPAs (176 vs. 134 events per second).
No EPA in the trial is exchanging any other information thanevent objects with other EPAs, in which case it would bemore efficient to run each EPA in a separate instance ofINSTANS. This would modularise the approach and ensurethat there will not be any unwanted side effects due to un-planned matching of rules between different agents. Whenstream processors are created in a modular way, using RDFboth for input and output, multiple RDF-based stream pro-cessors can be interconnected to solve more complex taskswhile helping to keep the size of each EPN manageable.
The challenges of applying synchronous query repeti-tion over stream windows in event processing tasks were dis-cussed in [Rinne et al(2012a)]. In this document it was ad-ditionally observed that the creation of stateful filters facesfurther challenges in windowed environments because con-ventional SPARQL matches graph patterns over the com-plete addressable dataset, in this case window, before act-ing on the results. Unless it can be guaranteed that a win-dow contains precisely one event object (thereby precludingcases using multiple event objects from the same stream asinput), the results of processing one event cannot impact theprocessing of the next. The results of stateful filtering canalso be sensitive to repeated processing, causing symptomswith overlapping windows.
7 Conclusions
The principle of processing heterogeneous events using anetwork of SPARQL queries and update rules was first pre-sented in [Rinne et al(2012a)] through a practical event pro-cessing example solved by three interconnected rules anda result output query. This paper takes a more systematicapproach by showing working examples of every type ofevent processing agent found in [Etzion et al(2010)]. TheSPARQL implementation of the “input modifiers” (filtertypes) mentioned in [Taylor and Leidinger(2011)] is alsoreviewed. Building on top of the principles introduced in[Rinne et al(2013)], the benefits of TriG input over plainTurtle in encapsulating events objects are explained anddemonstrated.
Based on the examples it is observed that every type ofevent processing agent found in the referenced literature canbe expressed using a SPARQL Update rule or network ofrules. While the examples do not extend to prove that ev-ery event processing task would have a corresponding so-lution in SPARQL, they serve to demonstrate a systematicapproach up to a level of complexity, which would be suf-ficient for many real-life scenarios. SPARQL is observed tobe capable of serving as the foundation for event processingsystems and the current INSTANS implementation demon-strated speeds from approximately 1,000 to 11,000 triplesper second, depending on the complexity of the task. Using
12 Mikko Rinne, Esko Nuutila
Source' 1:#Stateless# Post,stateless#
2:#Stateful# Post,stateful#
3:#Translate#
Memory#
4:#Project#
5:#Split#
Geo,Events#
Time,Events#
6:#Aggregate# Event,Counts#
7:#Compose#
Combined#
Transform#
DirecHons#
Compare#
PaIern#Reset#
Detect#
PaIern,detect#
8: Pattern Detect
Translated#Projected#
Fig. 19 The example event processing network created in the paper.
100 1,000 10,0000
50
100
150
200
142142154154
176176
8282
116116
134134
EPA AllEPA All EPA TotalEPA Total
Events in batch
Eve
nts
per s
econ
d
Fig. 20 Performance comparison of the complete event processing net-work (EPA All) against the sum of times executing each individualagent against the whole batch (EPA Total).
a reporting interval of 10 seconds, the complete event pro-cessing network (176 events per second) could serve a pop-ulation of 1760 sensors with the off-the-shelf laptop usedfor performance tests. If the reporting interval can be fur-ther reduced by filtering in a sensor gateway node, a largerpopulation of sensors can be supported.
While the query examples in this paper have been pre-pared manually, it would also be possible to create end-usertools to synthesise the rules and queries. Higher-level rep-resentations for event processing networks and their transla-tion to SPARQL is a potential topic for future studies. Theaspects of synchronised aggregate calculation and process-ing of timed events (especially in cases requiring detectionof missing events) also need to be elaborated further.
Acknowledgements This work has been carried out in Spaceify,SPIRE and TrafficSense projects funded by European Commissionthrough the SSRA (Smart Space Research and Applications) activityof EIT ICT Labs16, Tekes and Aalto University.
References
[Abdullah et al(2012)] Abdullah H, Rinne M, Torma S, Nuutila E(2012) Efficient matching of SPARQL subscriptions using Rete. In:Proceedings of the 27th Symposium On Applied Computing, Rivadel Garda, Italy
[Anicic et al(2011)] Anicic D, Fodor P, Rudolph S, Stojanovic N(2011) EP-SPARQL: a unified language for event processing andstream reasoning. In: Proceedings of the 20th international con-ference on World wide web (WWW’11), ACM, pp 635–644, DOI10.1145/1963405.1963495
[Arasu et al(2006)] Arasu A, Babu S, Widom J (2006) The CQL con-tinuous query language: Semantic foundations and query execution.VLDB Journal 15:121–142, DOI 10.1007/s00778-004-0147-z
Constructing Event Processing Systems of Layered and Heterogeneous Events with SPARQL 13
[Babcock et al(2002)] Babcock B, Babu S, Datar M, Motwani R,Widom J (2002) Models and issues in data stream systems. In: Pro-ceedings of the twenty-first ACM SIGMOD-SIGACT-SIGART sym-posium on Principles of database systems - PODS ’02, ACM Press,New York, New York, USA, p 1, DOI 10.1145/543614.543615
[Barbieri et al(2010a)] Barbieri DF, Braga D, Ceri S, GrossniklausM (2010a) An execution environment for C-SPARQL queries. In:Proceedings of the 13th International Conference on ExtendingDatabase Technology - EDBT ’10, Lausanne, Switzerland, p 441,DOI 10.1145/1739041.1739095
[Barbieri et al(2010b)] Barbieri DF, Braga D, Ceri S, Valle ED, Gross-niklaus M (2010b) C-SPARQL: A Continuous query language forRDF data streams. International Journal of Semantic Computing04:3, DOI 10.1142/S1793351X10000936
[Barbieri et al(2010c)] Barbieri DF, Braga D, Ceri S, Valle ED, Gross-niklaus M (2010c) Querying RDF streams with C-SPARQL. ACMSIGMOD Record 39:20, DOI 10.1145/1860702.1860705
[Beckett et al(2014)] Beckett D, Berners-Lee T, Prud’hommeauxE, Carothers G (2014) RDF 1.1 Turtle - Terse RDF TripleLanguage. W3C Recommendation 25 Feb 2014. URLhttp://www.w3.org/TR/turtle/
[Bizer and Cyganiak(2014)] Bizer C, Cyganiak R (2014) RDF1.1 TriG W3C Recommendation 25 February 2014. URLhttp://www.w3.org/TR/trig/
[Calbimonte et al(2010)] Calbimonte Jp, Corcho O, Gray AJG (2010)Enabling Ontology-based Access to Streaming Data Sources. In: 9thInternational Semantic Web Conference (ISWC 2010), Shanghai,China, pp 96–111, DOI 10.1007/978-3-642-17746-0 7
[Cugola and Margara(2012)] Cugola G, Margara A (2012) Pro-cessing Flows of Information: From Data Stream to ComplexEvent Processing. ACM Comput Surv 44(i):15:1–15:62, DOI10.1145/2187671.2187677
[Dell’Aglio et al(2013)] Dell’Aglio D, Calbimonte JP, Balduini M,Corcho O, Della Valle E (2013) On correctness in RDF stream pro-cessor benchmarking. In: International Semantic Web Conference2013, vol 8219 LNCS, pp 326–342, DOI 10.1007/978-3-642-41338-4 21
[Depena(2010)] Depena RK (2010) Diamond : A Rete-Match LinkedData SPARQL Environment (M.Sc. Thesis). PhD thesis, Universityof Texas at Austin
[Etzion et al(2010)] Etzion O, Niblett P, Luckham D (2010) EventProcessing in Action. Manning Publications
[Forgy(1979)] Forgy CL (1979) On the efficient implementation ofproduction systems. PhD thesis, Carnegie Mellon University, Pitts-burgh, PA, USA, aAI7919143
[Forgy(1982)] Forgy CL (1982) Rete: A fast algorithm for the manypattern/many object pattern match problem. Artificial Intelligence19(1):17–37, DOI 10.1016/0004-3702(82)90020-0
[Groppe et al(2007)] Groppe S, Groppe J, Kukulenz D, Linne-mann V (2007) A SPARQL Engine for Streaming RDF Data.In: Third International IEEE Conference on Signal-Image Tech-nologies and Internet-Based System, IEEE, pp 167–174, DOI10.1109/SITIS.2007.22
[Keskisarkka and Blomqvist(2013)] Keskisarkka R, Blomqvist E(2013) Event Object Boundaries in RDF Streams - A Position Pa-per. In: OrdRing 2013 - 2nd International Workshop on Orderingand Reasoning, CEUR workshop proceedings
[Kolchin et al(2016)] Kolchin M, Wetz P, Kiesling E, Tjoa AM (2016)YABench: A Comprehensive Framework for RDF Stream Proces-sor Correctness and Performance Assessment. In: Bozzon A, Cudre-Mauroux P, Pautasso C (eds) 16th International Conference on WebEngineering, Springer International Publishing, Lugano, Switzer-land, vol 9671, pp 280–298, DOI 10.1007/978-3-319-38791-8 16
[Komazec and Cerri(2011)] Komazec S, Cerri D (2011) Towards Ef-ficient Schema-Enhanced Pattern Matching over RDF Data Streams.In: 10th ISWC, Springer, Bonn, Germany
[Le-Phuoc et al(2011)] Le-Phuoc D, Dao-Tran M, Parreira JX,Hauswirth M (2011) A native and adaptive approach for unified pro-cessing of linked streams and linked data. In: ISWC’11, Springer-Verlag Berlin, pp 370–388
[Luckham(2002)] Luckham D (2002) The Power of Events: An In-troduction to Complex Event Processing in Distributed EnterpriseSystems, 1st edn. Addison-Wesley Professional
[Luckham and Schulte(2011)] Luckham D, Schulte R(2011) Event Processing Glossary Version 2.0. URLhttp://www.complexevents.com/
[Miranker et al(2012)] Miranker DP, Depena RK, Hyunjoon J, Car-los R, Sequeda JF (2012) Diamond: A SPARQL Query Engine, forLinked Data Based on the Rete Match. In: Gueret C, Sharffle F, IencoD, Villata S (eds) 1st International Workshop on Artificial Intelli-gence meets the Web of Data (ECAI 2012), Montpellier, pp 12–17
[Rinne and Nuutila(2014)] Rinne M, Nuutila E (2014) ConstructingEvent Processing Systems of Layered and Heterogeneous Eventswith SPARQL. In: Meersman R, Panetto H, Dillon T, Missikoff M,Liu L, Pastor O, Cuzzocrea A, Sellis T (eds) On the Move to Mean-ingful Internet Systems: OTM 2014 Conferences, Springer BerlinHeidelberg, pp 682–699, DOI 10.1007/978-3-662-45563-0 42
[Rinne et al(2012a)] Rinne M, Abdullah H, Torma S, Nuutila E(2012a) Processing Heterogeneous RDF Events with StandingSPARQL Update Rules. In: Meersman R, Dillon T (eds) OTM 2012Conferences, Part II, Springer-Verlag, pp 793–802
[Rinne et al(2012b)] Rinne M, Torma S, Nuutila E (2012b) SPARQL-Based Applications for RDF-Encoded Sensor Data. In: 5th Interna-tional Workshop on Semantic Sensor Networks
[Rinne et al(2013)] Rinne M, Blomqvist E, Keskisarkka R, NuutilaE (2013) Event Processing in RDF. In: Proceedings of WOP2013,CEUR Workshop Proceedings, p 13
[Rinne et al(2016)] Rinne M, Solanki M, Nuutila E (2016) RFID-based Logistics Monitoring with Semantics-driven Event Pro-cessing. Proceedings of the 10th ACM International Confer-ence on Distributed and Event-based Systems pp 238–245, DOI10.1145/2933267.2933300
[Taylor and Leidinger(2011)] Taylor K, Leidinger L (2011)Ontology-Driven Complex Event Processing in HeterogeneousSensor Networks. In: 8th Extended Semantic Web Conference(ESWC), Springer Berlin Heidelberg, Heraklion, Crete, Greece, pp285–299, DOI 10.1007/978-3-642-21064-8 20
[Terry et al(1992)] Terry D, Goldberg D, Nichols D, Oki B (1992)Continuous queries over append-only databases. ACM SIGMODRecord 21(2):321–330, DOI 10.1145/141484.130333
[Teymourian et al(2012)] Teymourian K, Rohde M, Paschke A (2012)Fusion of background knowledge and streams of events. In: Proceed-ings of the 6th ACM International Conference on Distributed Event-Based Systems - DEBS ’12, ACM Press, New York, New York,USA, pp 302–313, DOI 10.1145/2335484.2335517
[Tommasini et al(2015)] Tommasini R, Valle ED, Balduini M, AglioDD (2015) Heaven Test Stand: towards comparative research on RSPengines. In: Joint Proceedings of the 1st Joint International Work-shop on Semantic Sensor Networks and Terra Cognita (SSN-TC2015) and the 4th International Workshop on Ordering and Reason-ing (OrdRing 2015), CEUR Workshop Proceedings, Bethlehem, PA,USA, pp 1–16, DOI urn:nbn:de:0074-1488-9