48
Safety, Reliability, and Robust Design in Embedded Systems
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 247 times |
| Download: | 6 times |

Safety, Reliability, and Robust Design
in Embedded Systems

Risk analysis: managing uncertainty
GOAL: be prepared for whatever happens
Risk analysis should be done for ALL PHASES of a project:---planning phase---development phase---the product itself
Identify risks: What could you have done during the planning stage to manage each of these “risks”?
How likely is it (what is probability) each one will occur?
How likely is it (what is probability) more than one will occur?
What actions will best manage the risk if it occurs?

During planning, a Risk Table can be generated: Risks Type* Probability Impact Plan (Pointer)
System not availableHardware failureColor printer unavailablePersonnel absent
(one meeting)Personnel unavailable
(several meetings)
Personnel have left project
*Type: Performance (product won’t meet requirements); Cost (budget overruns); Support (project can’t be maintained as
planned); Schedule (project will fall behind)
Probability: of this risk occurring
Impact: e.g., catastrophic, critical, marginal, negligible
risk management—identify, plan for risks
Then table is sorted by probability and impact and a “cutoff line” is defined. Everything above this line must be managed (with a management plan pointed to in the last column).
Useful reference: Embedded Syst. Prog. Nov. 00--examples:http://www.embedded.com/2000/0011/0011feat1.htm
Additional interesting reference: H. Petroski, To Engineer is Human: The Role of Failure in Successful Design, Vintage, 1992.
.
risk management—identify, plan for risks

professional risk analysis is proactive, not reactive

Important concepts for embedded systems::
Risk = Probability of failure * Severity
Increased risk decreased safety
Safety failures—possible causes:incorrect or incomplete specificationbad designimproper implementationfaulty componentimproper use
RELIABILITY: “what is the probability of failure?”

Some ways to determine reliability:
--product performs consistently as expected
--MTBF (mean time between failures) is long
--system behavior is DETERMINISTIC
--system responds or FAILS GRACEFULLY to out-of-bounds or unexpected conditions and recovers if possible

Definitions:
Fault: incorrect or unacceptable state or condition
Fault duration and frequency determines clasification:transient—from unexpected external condition-”soft”intermittent—unstable hardware or marginal design
periodic / aperiodicpermanent—failed component, e.g.—”hard”
Error: static, inherent characteristic of system
Failure: dynamic, occurs at specific time
Possible fault consequences:inappropriate actiontiming—event occurs too early or too latesequence of events incorrectquantity—wrong amount of energy or substance used

Achieving reliability:
safe design
fault detection
fault management
fault tolerant—system recovers, fault not detectede.g., packet transfers
Definition of reliability for embedded system: probability that a failure is detected by the user is less than a specified threshold

Examples—section 8.5—read these carefully!
Ariane 5 rocket: register overflow—64-bit word assigned to 16-bit register in a reused subsystem
Mars Pathfinder mission 1997—lower priority tasks were allowed to hog resources, higher priority tasks could not execute
2004 Mars mission—file management problems
Many more examples in articles at embedded.com, including some information on current Toyota problems

How do we define safety?
One criterion:
“single point”: failure of a single component will not lead to unsafe condition
“common-mode failure”: failure of multiple components due to a single failure event will not lead to an unsafe condition
Safety must be considered THROUGHOUT the project

fig_08_00
Embedded system design—project components
Development process (“waterfall model”):
Alternative process models: Need risk analysis AT EACH INCREMENT(A=analysis, D=design, I=implement, T=test, M=maintenance)Basic waterfall model: A-->D-->I-->T-->M
Prototyping: A-->D-->I-->T-->M Incremental: A-->D-->I-->T-->M-->A-->D-->I-->T--> ……-->M
Component based: A-->D-->Library-->Integrate-->T-->M I
Analysis Design Implement Test Maintain

Specifications:
Identify hazards
Calculate risk
Define safety measures
Specification document should include safety standards and guidelines which system complies with
e.g.: Underwriters Laboratory, FCC, FDA, FAA, AEC, NASA, ISO, etc.

fig_08_01
Design and review process:steps

fig_08_02
Primitive C error-handling: May not be sufficient for embedded system
Assert:

fig_08_03
Example:
Good for debugging stage, allows “controlled crash”
Not robust enough for final code

fig_08_04
Jump statements: consequences may not be acceptable

fig_08_05
Example:
Better: high compiler warning level, variable typing, e.g.

fig_08_06
Example system:
Control
Memory
Data / comm
Power / reset
Peripherals
Clock

fig_08_07
Basic method: redundancy (triple):

fig_08_08
Higher redundancy:

fig_08_09
Reduced capability in case of failure / error:

fig_08_10
Alternative: monitor only

fig_08_11
Bussing; interconnection architectures

fig_08_12
Sequential: still can fail at one point

fig_08_13
Better: ring

fig_08_14
Even better: ring with redundancy

fig_08_15
Signal values: magnitude & duration:ignoredetect / warnreact

fig_08_16
Data errors: detect / correct
Example: errors in 3 bits

fig_08_17
Error detection example

fig_08_18
Hamming code (review):

fig_08_22
Block codes: exampleLateral & longitudinal parity
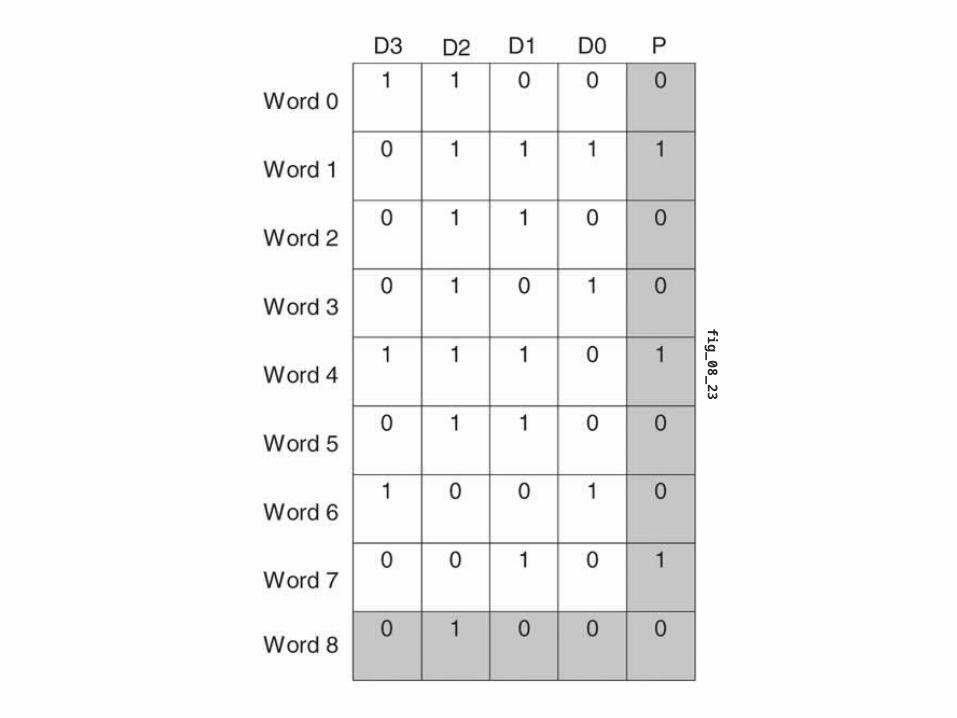
fig_08_23

fig_08_24
More complex codes: use the field Z2

fig_08_25
Shift register for encoding, decoding:

fig_08_26
Checking data:

fig_08_27
“syndrome” calculator:

fig_08_28
Encoding:

fig_08_29
Some polynomials: must choose correct one

fig_08_30
Power system:

fig_08_31
Redundancy and power monitoring:

fig_08_32
Potential actions:

fig_08_33
Using backups:

fig_08_34
Backups: short-term fix:

fig_08_35
Bus faults: buffering

fig_08_36
Bus testing:

fig_08_37
Interface system monitoring and testing:

table_08_00
Example: common fault analysis

















