46
SAS Efficiency Techniques and Methods By Kelley Weston Sr. Statistical Programmer Quintiles
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | allan-quinn |
| View: | 222 times |
| Download: | 0 times |

SAS Efficiency Techniques and Methods
By Kelley WestonSr. Statistical Programmer
Quintiles

Efficiency can be measured in many ways – e.g.:
• CPU time• Disk space required• Memory • Input / Output• Original Programmer time• Maintenance Programmer time

Outline•Copying a data set•Changing attributes•Appending data sets•Procedures•Rename variables•Alternatives to logical OR constructs•Formats•Indexing•Disk Space•Views•Proc Sort and disk space•Hashing – merging data sets

Avoid reading the dataset multiple timesData work.data1 work.data2 work.data3; Set lib1.master; If substr(x, 1, 1) EQ 'A' then output work.data1; Else if substr(x, 1, 1) EQ 'B' then output work.data2; Else if substr(x, 1, 1) EQ 'C' then output work.data3;Run;
Data work.data1 work.data2 work.data3; Set lib1.master; Type = substr(x, 1, 1); If type EQ 'A' then output work.data1; Else if type EQ 'B' then output work.data2; Else if type EQ 'C' then output work.data3; Drop type;Run;

Copying a dataset:
/* inefficient */data work.data; set lib1.data;run;
/* efficient */proc datasets lib = work nolist; copy in = lib1 out = work; select data; quit;

Changing Attributes:
/* inefficient *//* reads & writes one observation at a time */data work.data; set lib1.data; label age = 'Years'; format salary dollar10.; rename cars = autos; Run;

Changing Attributes:
/* efficient */proc datasets lib = work nolist; copy in = lib1 out = work; select data; modify data (label = "Demographic Data"); label age = 'Years'; format salary dollar10.; rename cars = autos; change data = demograph; contents data = demograph;quit;

Appending datasets:
/* inefficient *//* reads and writes one observation at a time */data work.data1; set work.data1 work.data2;run;

Appending datasets:
/* efficient */proc datasets nolist; append base = work.data1 data = work.data2;quit;

Give procedures what they need – but no more:
/* inefficient */Proc sort data = lib1.data Out = work.data; By var1 var2 var3;Run;

Give procedures what they need – but no more:
/* still inefficient, but less so */Proc sort data = lib1.data Out = work.data (drop = var4); By var1 var2 var3;Run;

Give procedures what they need – but no more:
/* Efficient */Proc sort data = lib1.data (drop = var4) Out = work.data; By var1 var2 var3;Run;

Give procedures what they need – but no more:
Tools to limit datasets:•Drop / keep•Subsetting if•Where•Firstobs / Obs
Use these on the input dataset as much as possible
NOTE 1: Where has its affect after the Drop / Keep
NOTE 2: You can now use Firstobs / Obs along with Where; Where has its affect first, then Firstobs / Obs

Use rename rather than reassign:
Reassign:•Creates another variable (probably needlessly)•Takes up more space in the data set•Executes needlessly each execution of the data step•Is slower
Rename:•Occurs just once, at compile time, not execution time•Might be able to avoid reading the data one observation at a time

Use rename rather than reassign:
/* inefficient */Data work.data; Set lib1.data; Var2 = var1;Run;

Use rename rather than reassign:
/* still inefficient, but less so */Data work.data; Set lib1.data; Rename Var1 = var2;Run;

Use rename rather than reassign:
/* Efficient */Proc datasets lib = work Nolist; Copy in = lib1 Out = work; Select data;
Modify data; Rename var1 = var2;quit;

Avoid using logical OR constructs
•Can use IN() or Select/when – much faster, easier to code and understand (consider the order of the choices listed)
data work.data1;set lib1.data1; length msg $20; select (category); when ('A') msg = 'Category A'; when ('B') msg = 'Category B'; when ('C') msg = 'Category C'; otherwise msg = 'Category unknown'; end;run;

Use formats to make coding shorter and more to the point:
proc format ; value $status 'M','SEP' = 'A' 'S', 'D', 'W' = 'B';run;
data work.data;set lib1.data; where put(status, $status.) = 'A';run;ORdata work.data; set lib1.data (where = (put(status, $status.) = 'A'));Run;

Consider using an index instead of sorting the dataset
When to consider using an index:•When you can subset the dataset using a where option/statement•When the dataset will be involved in a merge / joinTip: Use “options msglevel = I” (for Info) when using indexes; gives INFO: message in log when used
/* 3 Ways of Creating an Index: */•Data Step•Proc Datasets •Proc SQL

Indices and the Data Step
data work.data1 (index = (var1 = (var1) composite = (var1 var2 ))); set lib1.data1;run;
/* Review index */proc contents data = work.data1;run;
/* Delete index – not preferred method */data work.data1; set lib1.data1;run;

Alphabetic List of Indexes and Attributes
# of Unique# Index Values Variables
1 composite 50 var1 var22 var1 50

Create index with proc datasets
proc datasets lib = work nolist; Modify data1; /* do not include missing values in the index */ Index create var1 / nomiss; /* insure that index values are unique */ Index create composite = (var1 var2) / unique;Quit;
/* delete index */proc datasets lib = work nolist; Modify data1; Index delete var1 composite;Quit;

Create index with proc sql
Proc sql; /* simple index */ Create index <index name> on <dataset>(variables(s));
Create index prodno on work.products(prodno);
/* composite index */ /* notice the commas */ Create index ordno on work.orders(custno, prodno, orderno);quit;
/* Delete index */proc sql; drop index ordno, orderno from work.orders; drop index prodno from work.products;quit;

DISK SPACE CONSIDERATIONS
•Consider putting long memo fields into a separate, associated dataset
•Use _NULL_ as the data set name when you do not need to create a dataset (e.g., when creating macro variables)
•Use the KEEP &/or DROP data set options (on input &/or output) or statements to limit the variables.
•Use the WHERE data set option (on input &/or output) or statement to limit the observations.

DISK SPACE CONSIDERATIONS
•Use data set compression (data set options COMPRESS = YES REUSE = YES). This is primarily useful with character data, or numeric data where the numbers are small.
data work.new2 (compress = yes reuse = yes); set work.new;run;
•Use a data set view, rather than creating a SAS data set – essentially a “pointer” to the data. •Use SQL to merge, summarize, sort, etc. instead of a combination of DATA steps and procs.

DISK SPACE CONSIDERATIONS
•Store the data in the order in which it is usually required. This saves the disk space used to re-sort the data.
•Create only the indexes that are needed - delete any unneeded ones.
•Delete old work libraries (use Windows Explorer)
•Delete old autosaved programs (use Windows Explorer)
•Delete datasets in current programs as soon as possible (proc datasets)

DISK SPACE CONSIDERATIONS
•Use appropriate length of variables-Find length of current character values, then make length current + 15% in new dataset to allow for longer lengths
oRemember that character variables get their length from their first use, if not explicitly defined (e.g., scan, repeat, symget functions have default length of 200)
-For numerics, can make length as low as 3 (default of 8) – good for ages (length of 3), dates (length of 4)

SAS DATA VIEWS
•Can be created with either a data step or proc sql.•Does not contain any data – only instructions on how to access the data•When the original data changes, it is immediately reflected in the view.

Data set View
data work.class / view = class; set sashelp.class; where weight LE 125; drop height;run;
title 'Printing View work.class';proc print data = work.class heading = h n;run;

Data set View
/* retrieve the source of a view *//* prints the source in the log */data view = work.class; describe;run;



Create view in sql
title 'View Created with SQL';proc sql; create view work.subview as select * from sashelp.class where height GT 50 order by name; select * from work.subview;quit;
/* print source statements in log */proc sql; describe view work.subview;quit;

Source stmts of SQL View
76 proc sql;77 describe view work.subview;NOTE: SQL view WORK.SUBVIEW is defined as: select * from SASHELP.CLASS where height>50 order by name asc;78 quit;

Saving Disk Space when using Proc Sort
proc sort data = sashelp.class out = work.class1 tagsort; by name; run;

Tagsort:
• Stores only the BY variables and the obs # in temp. files • Uses tags to retrieve the records from the input data set in sorted order • Not supported by the multi-threaded sort. • Best used when the total length of BY variables is small compared to length of entire observation. • Can increase processing time.

Using Hashing to Merge Data Sets
data <output data set(s)>;* Set up input and lookup datasets;* Set up hash info;* Read input dataset;* Check if key value is stored in hash;* Get value of data variable;* Write obs to the output data set(s);run;

Using Hashing to Merge Data Sets
data <output data set>;* Set up input and lookup datasets; if 0 then do; set <input data set>; set <lookup data set>(keep = <lookup var(s)>); end;...run;

Using Hashing to Merge Data Sets
data <output data set>;* Set up input and lookup datasets;
* Set up hash info; retain rc 0; if _n_ EQ 1 then do; declare hash h(dataset: "<lookup data set>"); h.definekey("<key var 1>", "<key var 2>"); h.definedata("<data var 1>", "<data var 2>"); h.definedone(); * all definitions are complete; * assign missing values to vars; call missing(<key vars>, <lookup vars>); end;...run;

Using Hashing to Merge Data Sets
data <output data set(s)>;* Set up input and lookup datasets;* Set up hash info;
* Read input dataset;
set <input data set>;...run;

Using Hashing to Merge Data Sets
data <output data set(s)>;* Set up input and lookup datasets;* Set up hash info;* Read input dataset;
* Check if key value is stored in hash;
rc = h.check(); ...Run;

Using Hashing to Merge Data Sets
data <output data set(s)>;* Set up input and lookup datasets;* Set up hash info;* Read input dataset;* Check if key value is stored in hash;
* Get value of data variable;
if rc EQ 0 then do; rc = h.find(); end;...run;
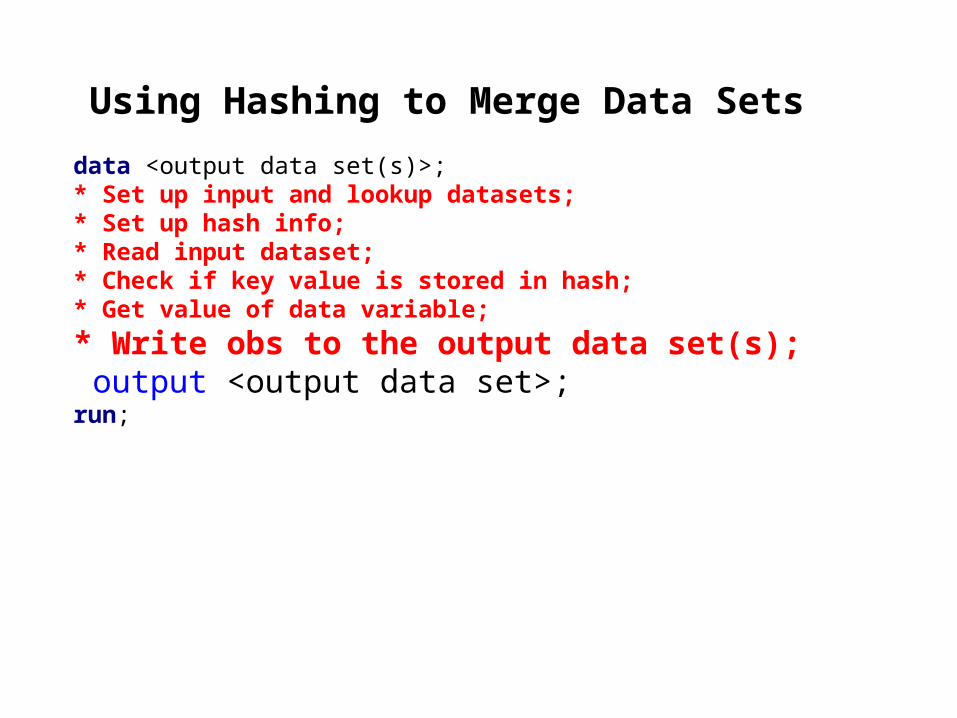
Using Hashing to Merge Data Sets
data <output data set(s)>;* Set up input and lookup datasets;* Set up hash info;* Read input dataset;* Check if key value is stored in hash;* Get value of data variable;
* Write obs to the output data set(s); output <output data set>;run;

Using Hashing to Merge Data Setsdata <output data set>; if 0 then do; set <input data set>; set <lookup data set>(keep = <lookup variable(s)>); end; retain rc 0; if _n_ EQ 1 then do; declare hash h(dataset: "<lookup data set>"); h.definekey("<key variable 1>", "<key variable 2>"); h.definedata("<data variable 1>", "<data variable 2>"); h.definedone(); * all definitions are complete; * assign missing values to vars; call missing(<key variables>, <lookup variables>); end; set <input data set>; rc = h.check(); * is key stored in hash?; if rc EQ 0 then do; rc = h.find(); * get value of data variable; end; output <output data set>; drop rc;run;

Questions ?

















