22
Search and Optimization Methods Based in part on Chapter 8 of Hand, Manilla, & Smyth David Madigan
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 217 times |
| Download: | 2 times |

Search and Optimization Methods
Based in part on Chapter 8 of Hand, Manilla, & Smyth
David Madigan

Introduction
•This chapter is about finding the models and parameters that minimize a general score function S
•Often have to conduct a parameter search for each visited model
•The number of possible structures can be immense. For example, there are 3.6 1013 undirected graphical models with 10 vertices

Greedy Search
1. Initialize. Chose an initial state Mk
2. Iterate. Evaluate the score function at all adjacent states and move to the best one
3. Stopping Criterion. Repeat step 2 until no further improvement can be made.
4. Multiple Restarts. Repeat 1-3 from different starting points and choose the best solution found.

Systematic Search Heuristics
Breadth-first, Depth-first, Beam-search, etc.

Parameter OptimizationFinding the parameters that minimize a score function S() is usually equivalent to the problem of minimizing a complicated function in a high-dimensional space
Define the gradient function is S as:
When closed form solutions to S()=0 exist, no need for numerical methods.
d
SSSg
)(,,
)()()(
1

Gradient-Based Methods
1. Initialize. Choose an initial value for = 0
2. Iterate. Starting with i=0, let i+1 = i +i vi where v is the direction of the next step and lambda is the distance. Generally choose v to be a direction that improves the score
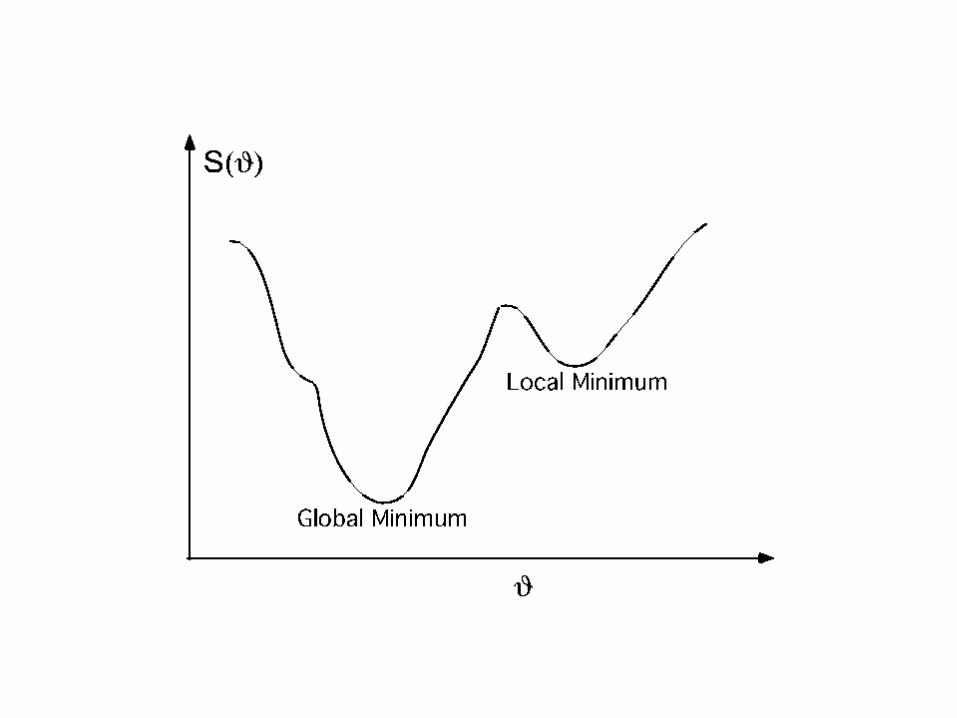
3. Convergence. Repeat step 2 until S appears to have reached a local minimum.
4. Multiple Restarts. Repeat steps 1-3 from different initial starting points and choose the best minimum found.

Univariate OptimizationLet g()=S’(). Newton-Raphson proceeds as follows. Suppose g(s)=0. Then:
)(
)(
:bygiven is stepth -i
)(
)(
)()()()(
1
*
**
***
i
iii
s
ss
g
g
g
g
ggg

1-D Gradient-Descent
)(1 iii g
usually chosen to be quite small
•Special case of NR where 1/g’(i) is replaced by a constant

Multivariate CaseCurse-of-Dimensionality again. For example, suppose S is defined on a d-dimensional unit hypercube. Suppose we know that all components of are less than 1/2 at the optimum.
if d=1, have eliminated half the parameter space
if d=2, have eliminated 1/4 of the parameter space
if d=20, have eliminated 1/1,000,000 of the parameter space!

Multivariate Gradient Descent
)(1 iii g
•-g(i) points in the direction of steepest descent
•Guaranteed to converge if small enough
•Essentially the same as the back-propagation method used in NNs
•Can replace with second-derivative information (“quasi-Newton” uses approx).

Simplex Search Method
Evaluates d+1 points arranged in a hyper-tetrahedron
For example, with d=2, evaluates S at the vertices of an equilateral triangle
Reflect the triangle in the side opposite the vertex with the highest value
Repeat until oscillation occurs, then half the sides of the triangle
No calculation of derivatives...

•


EM for two-component Gaussian mixture
Tricky to maximize…

EM for two-component Gaussian mixture, cont.
This is the “E-step.” Does a soft assignment of observations to mixture components

EM for two-component Gaussian mixture – Algorithm


EM with Missing Data
H
HDpDpl )|,(log)|(log)(
Let Q(H) denote a probability distribution for the missing data
),(
)(log)()|,(log)(
)(
)|,(log)(
)(
)|,()(log)|,(log
QF
HQHQHDpHQ
HQ
HDpHQ
HQ
HDpHQHDp
HH
H
HH
This is a lower bound on l()

EM (continued)
),(maxarg :Step-M
),(maxarg :Step-E
11
1
kkk
kk
Q
k
QF
QFQ
In the E-Step, Max is achieved when
In the M-Step, need to maximize:
),|(1 kk DHpQ
)|,(log),|(maxarg1 k
H
kk HDpDHp

EM Normal Mixture Example
)(
),;()|( :Step-E
),,,,,,(Let
),;()(
111
1
xf
xfxkp
pp
xfxf
kkkk
kkk
K
kkkkk

EM Normal Mixture Example
2
1
1
1
)ˆ)(())(|(ˆ
1ˆ
)())(|(ˆ
1ˆ
))(|(1
ˆ :Step-M
k
n
ikk
n
ikk
n
ik
ixixkpn
ixixkpn
ixkpn

















