51
Searchable Encryption in Practice Paul Grubbs
| Date post: | 26-Dec-2015 |
| Category: |
Documents |
| Upload: | juliet-matthews |
| View: | 217 times |
| Download: | 3 times |

Searchable Encryption in Practice
Paul Grubbs

Who am I?
• Cryptography engineer in industry at Skyhigh Networks (hereafter SHN)
• Did undergrad at Indiana University
• In two months I’ll be starting my PhD at Cornell

What do I do?
• Design and write cryptography code– High-level architectural stuff
and low-level algorithms• Research (sometimes)– Interact with advisory board
• General infosec stuff– Key management
• Bakra

Why am I at this workshop?
• I fooled Sasha into thinking I know things about SE
• Reality

Alternate explanation
• SHN has unique perspective on searchable encryption
• First company to apply SE research as core of some real products– OPE and stateful variant – Index-based search (SSE)
• In a position to know where gaps in research/understanding are– Customers tell us, sometimes politely

What am I going to talk about?
• OPE• SSE use cases• SSE architecture• Open problems

Basic model
• Transparent encrypting proxy for cloud service providers (CSPs)
• “Bump in the wire” that encrypts data as it is loaded into CSP
• Decrypts data when user retrieves it• Changes to CSP application are difficult or
impossible

Basic model for storing data
Users of CSP
Proxy
CSP CSP
Users of CSP
Vs.
Store my plaintext.
Store my plaintext.
Store this ciphertext.
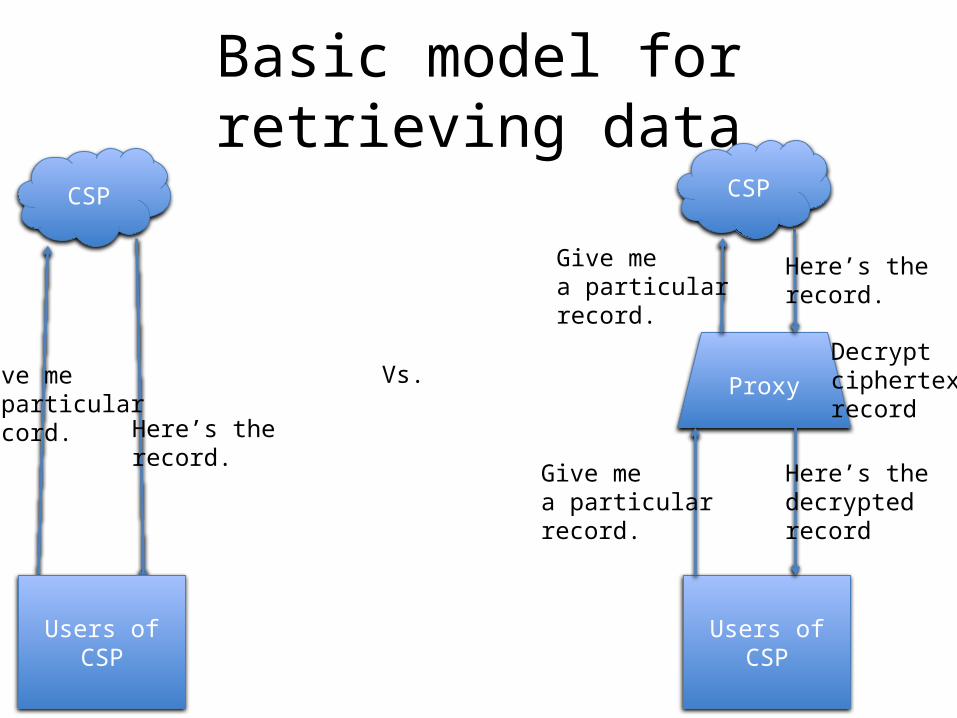
Basic model for retrieving data
CSP
Vs.
Users of CSP
Proxy
Here’s the record.
Give me a particular record.
Give me a particular record.
CSP
Users of CSP
Here’s the decrypted record
Here’s the record.
Decrypt ciphertext record
Give me a particular record.

Well, what do you mean by “changes”?
• How the application code works, e.g.:– How searches are executed– How reports are generated
• How data is stored in the database– Width of fields in DB schema
• How user input is verified– E.g. an encrypted phone number had better look
like a phone number.

What are some CSPs?
• Salesforce Dot Com• Service Now• Box• Jive• Office 365• Also sometimes
called “SaaS”• Market is big and
getting bigger

Who else does similar stuff?
• Ciphercloud• Perspecsys• Kryptnostic• Bitglass

Where’s the search?
• In this abstraction the CSP is basically just a file storage service
• Customers want other things from CSPs– Collaborative editing, report generation, filtering,
marketing automation, messaging…• Regular encryption breaks all these nice features• Using different kinds of SE, we can get back some
of these features– Provide acceptable security and application
functionality

Basic model for search
User
CSP CSP
User
Vs. ProxySearch(“Bob”)
All matching records
Search(“Bob”)
Rewrite(“Bob”)
Search(Rewrite(“Bob”))All matching records
Decrypt records
All matchingrecords

Functionality customers want
• Search• Sorting/range queries• Arithmetic• Format validation

Order-preserving Encryption (OPE)

What is OPE?
• Encryption that preserves some order on plaintexts
• BCLO ‘09• BCO ’11 “Revisited”
x < y
F(x) f(y)<

Why is OPE useful?
• Enables lots of functionality (encrypted DB)– Search– Sort– Range queries

Stateful variant
• Legal/regulatory requirement for data “residency” – Standard encryption
cannot be used• How do we construct
OPE in this alternate setting?

Stateful OPE
• Store plaintext/ciphertext mapping• Generate HGD samples using PRNG
(/dev/urandom)• Can take advantage of HGD tail bound to make
accurate guess during recursive search– 10x speedup
• Not concurrent in a straightforward way (Why?)

Prefix search
• Range query prefix search• Ciphertext padded to
common length anyway
E(Apple)
E(Berry)
E(Quick)
E(Quark)
E(Zebra)
Give me records of the form “qu*”
P = Common prefix of E(quaaa), E(quzzz)
“P*”

Challenges and open problems
• What “order” is preserved?
• Security of padding for lexicographic order– Also affects usability
• Length of inputs must be fixed in advance, no “cipher mode” for OPE
7 < 10 “7” > “10”vs.

cont’d
• Efficiency– HGD sampling
• Security for non-uniform plaintext distributions– Modular OPE (?)
• Can we get better security for fuzzy orderings?

Searchable Symmetric Encryption

Information Retrieval
• Lucene, Solr, ElasticSearch


Functionality
• Exact-match queries – ‘paul’
• Wildcard/substring search – ‘pau*’ or ‘*aul’ or “cry*phy” or “*bob*”
• Phrase queries – ‘big red’ matches ‘big red dog’ but not ‘big dog’ or ‘red dog’
• Boolean queries– “paul AND hani”
• Error-tolerant queries– Query for “pohne” returns “phone”

What have companies been doing?
• CipherCloud– Two types of SE
• Use CSP index for search (EDESE-esque)– Multi-IV
• “Local” plaintext index
• Kryptnostic– Indexed-based SSE w/ de
novo construction– Multivariate quadratic
hardness assumption

“Local” indexes
User
“On-prem” proxy
CSP
User
UserNetwork edge
df
Index

Cont’d
User
“On-prem” proxy
UserUserNetwork edge
df
CSP
Plaintext

“Multi-IV”
• CipherCloud’s technique for countering frequency analysis
• Tweakable deterministic encryption with small # tweaks (e.g. 10)
• Open problem: How much better than deterministic encryption? Worth tradeoff?
Query “bob”Ek(“bob”, T1) OR … OR Ek(“bob”, Tn)



Kryptnostic
Running Kryptnostic client
Kr(“Bob”)
CSPKryptnostic
cloud
Kr

SSE at SHN

Architecture, high-level
User
Proxy
CSP
Add new record containing “bob”
Index “bob”
Store encryption of “bob”
SSE Encrypt “bob”

Searching
CSP
Proxy
User
SSE
Give me recordsContaining “bob”
Return records matchingToken for “bob”
CiphertextsOf “bob”
Search ciphertextOf “bob”
Records containing Ciphertext of “bob”
Decrypted records containing ”Bob”

CSP support
• “Structured” apps– “Documents” are collections of specific fields– Not often free-text– E.g. SFDC
• “Unstructured” apps– “Documents” are actual free-text documents– E.g. Box, Dropbox

Our SSE functionality
• Single-wildcard queries (not substring)– Preprocess keywords,
generate prefixes and suffixes
• Short phrase queries– Similar brute-force
approach• Exact match (top-k)• Boolean queries
Take-home message: naïve approach is sometimes fine

Generic Workflow• Bulk data load
– Initial preprocessing of data to produce static index• Updates on-the-fly
– Additions are loaded into index as they come. No support for deletions currently.• Searches
– Searches are encrypted and rewritten in the proxy– Sent to SSE server, results come back to proxy– Results fetched from CSP
• “Cache flush”– Partial re-index of new values– Happens at regular intervals– Counters for updates
• Full re-index– We will want to re-index all the data, for security and efficiency of searches. Longer
interval than cache flush. (maybe 3-4 months)

Cache flush

SSE is actually two separate things
• Encrypted index server– Inserts encrypted updates.– Responds to search queries.– Talks to backend DB
• Update agent– Receives updates– Synchronizes counters for dynamic writes
• Both are multi-tenant– Per-tenant cache in update agent– DB tables are tagged with tenant info

Multi-POP
• Current plan is to have one POP be the master and all other search POPs are replicated slaves
• Not very fault-tolerant but simple• Could be changed to multi-master if need be– Every search POP can receive updates– Instead of one dynamic table, each search POP
gets its own which is replicated to others– Search all dynamic tables in a query

Technologies
• Cassandra– Underlying DB– Eventually-consistent distributed data store
• Redis– In-memory cache– Used in update agent and for search result caching
• Thrift– Generic interface description language for creating services– Write a kind of interface definition in pseudocode,
generate bindings for different languages

Why Cassandra?
• Scale, fault-tolerance, replication• On-disk implementations hard to do multi-
tenant• Open problem in implementation: Use low-
level IO implementation for single machine storage and C* distributed database framework on top

Possible extensions and optimizations
• Range scans on Cassandra row keys instead of randomized lookups
• Top-K queries using OPE-encrypted TF-IDF• (more) Efficient wildcard search with
permuterm index

Cassandra row keys
• Sequential lookups are generally better than random ones
• Especially true in distributed DB w/ consistent hash
• Two-stage static search• Stage one: use trapdoor to find
range of row key values• Stage two: fetch values, decrypt
doc IDs

Ranked searches
• Term frequency-inverse document frequency
• Only need to compare
• Does this affect security?

Permuterm + MOPE = ?
• Space-efficient wildcard queries on encrypted keywords
• Modular OPE = OPE with random secret offset
• Trade some security for space/query time• Composite index, two-
stage search protocol• Fetch words
matching wildcard query, then do regular search protocol for each word
• How much security is too much?

Summary
• Setting for cloud cryptography• OPE• Deterministic encryption• Index-based SSE• Open problems

Open problems
• Other space-efficient wildcard queries?– Maybe some like Chase/Shen but for regular SSE
setting

















