37
S ecure I ncremental M aintenance of D istributed A ssociation R ules
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | kenneth-mckenzie |
| View: | 220 times |
| Download: | 0 times |

Secure Incremental Maintenance of Distributed Association Rules

Agenda
Introduction Secure Technologies Problem Definition Our algorithm Experiments Conclusions

Introduction
Association Rules– A means to identify patterns and trends
Secure Distributed Association Rules– Privacy is concerned– Restricted usage of some information
Maintenance of environment– Association rules with more sites– Use past results to reduce workload

Secure Data Mining
Approach 1: Data Obfuscation– Association rules from modified data– Simple algorithms but may get false rules
Approach 2: Secure Protocols– Complex communication– Difficult and costly algorithms but get accurate
rules– Balance between cost and privacy

Secure Technologies
Secure Sum– There are n sites– Each site holds a private number– Compute the sum of a group of sites
Secure Union– There are n sites– Each site holds a private set of items– Compute the union of sets

Secure Sum Example
Site 1
Site 2 Site 3
10
811
17 – 28 mod 40 = 29
38
9
17
Upper Bound: 40
R = 28
38 + 11 mod 40 = 9

Secure Technologies
Secure Comparison– Two sites– A site holds a number a, another holds a number
b– Check if a >= b without letting anyone knows the
value of a and b

Problem Definition
There are n old sites– Knows the association rules in these sites
There are r new sites– Requires update of association rules in new
environment
Maintain the privacy as well

Privacy? What to protect?
Different requirements in different situation Basic requirements
– Protect individual transaction– Protect individual site information
Local large itemsets, counts for itemsets
Secure Multi-party computation– The process does not reveal any other useful
information except the information that can be derived from own input and the final result

Algorithms
Secure Incremental Maintenance of Distributed Association Rules (SIMDAR)– Mining association rules with basic privacy level
More Secure Incremental Maintenance of Distributed Association Rules (MSIMDAR)– Mining association rules under the definition of
Secure Multiparty computation

SIMDAR: What we know? (Assumption)
Original Large Itemset Lk is available Total count for each old large Itemset is known All sites follow a semi-honest model
– They follow the rules, but may try to guess other’s information based on the received data (intermediate messages)
No collusion among any sites– Sites do not exchange intermediate information

Algorithm - SIMDAR
To find the large itemsets– Generate the candidate sets– Count on the candidates– Summing counts– Check for large itemset
Check if an association rule holds– Easy with counts available

Generate the candidates
C1 = I For Ck,
– Each new site generates its own candidate set with own (k-1)th locally large and globally large itemsets
Secure Union to find the candidate sets from the new sites
Union with Lk

Summing on candidates
Partition into 2 groups– Pk: in Lk
– Qk: not in Lk
For Pk, we got the original count, just add up the count in new sites using secure sum (no scan on old sites)

Summing Count for Qk
First summed up in new sites, we get a count If the itemset is large in new sites, send to
old sites for scan Otherwise, prune away

Information Protected by SIMDAR
Individual transaction– We never access to individual transaction of
others
Large Itemset of specific site– They are input to Secure Union
Count of each Itemset on each site– They are input to Secure Sum

MSIMDAR: for Higher privacy level
Final result: global association rules Input: Site database Other information should be protected Cannot reveal large itemsets?
– Costly checking– We treat the large itemsets as part of the result

MSIMDAR
Target: Global large itemsets and association rules
Useful information revealed by SIMDAR– Total Counts of itemsets– Original results of large itemset to new sites– New Candidates at new sites to old sites
Add fake itemset to hide the actual supported itemsets

MSIMDAR
Hiding the total count of an itemset– Do we really need to find out the total count?
Protect the large itemsets of the original results– Use a more complex protocol

MSIMDAR – Adding
Total excess count:– X.excess = X.count – s% |DB|
Instead of summing X.counti, we sum the excess count X.excessi
– Even revealed, we cannot know the count and database size
Checking for large itemsets after Secure Sum– Sa (the first site) holds random key Rx– Sb (the last site) holds (X.count – s% |DB| + Rx)– Secure Comparison between Sa and Sb

Storage
We can reuse it in future and we need it in the future– Checking for association rules requires counting
information– Prepare for next update

Storage
Commonly used method– Each site holds their own information
Count for each itemset Database size
– need to calculate the total count each time

Storage
We first sum the total database size |DB| using Secure Sum– Su (first site) holds the key of secure sum Rt
– Sv (last site) get the sum |DB| + Rt
For each itemset X, we store also – The protecting key Rx
– The protected excess count X.excess + Rx

Reusing the count
Checking association rules– A.count – c% B.count > 0
Can be derived by six stored numbers– N1 + (-1)N2 + (-c%)N3 + (c%)N4 + (c%-1)s%N5 + (1-c%)N6
N1 = A.excess + Ra
N2 = Ra
N3 = B.excess + Rb
N4 = Rb
N5 = |DB| + Rt
N6 = Rt
Secure sum and secure comparison

Avoiding new sites knowing past results
Generating the candidates is similar except an old site will join to the Secure Union process
For counting, two old sites will join Define:
– Pk = Lk intersect Ck
– Qk = Ck – Pk
– Note that the new sites should not be able to distinguish Pk and Qk
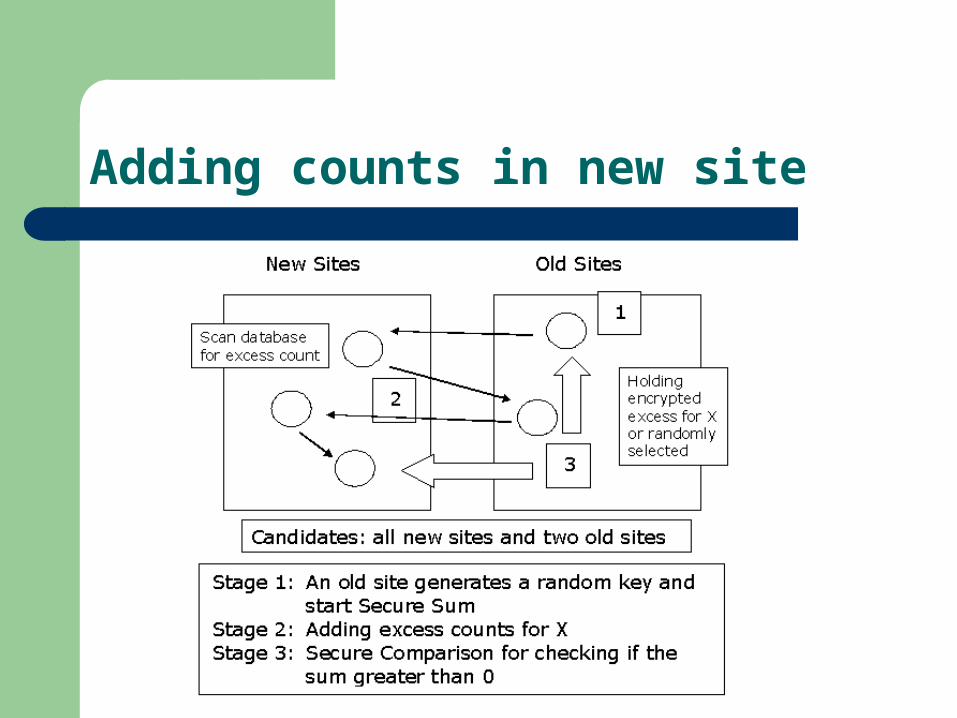
Adding counts in new site

Adding for Pk
Old sites
A
B
New SitesRandom Key
Sum
Protected excess
Secure Compare
A
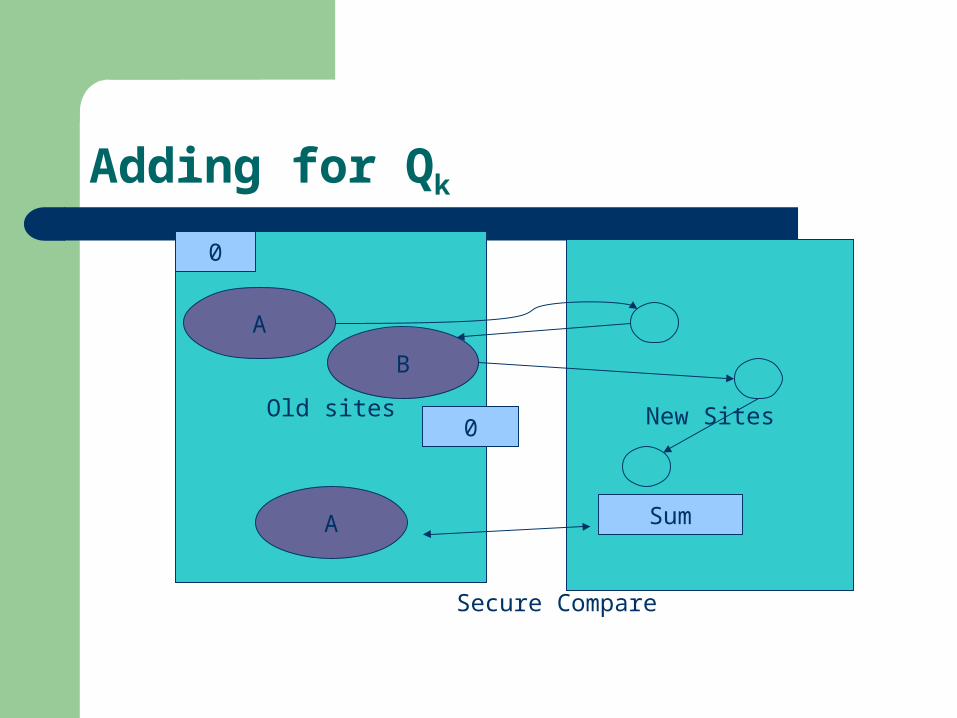
Adding for Qk
Old sites
A
B
New Sites0
Sum
0
Secure Compare
A

New site pruning
New sites sends the count to an old site to continue
We got final excess count for Pk
– Comparison means if the itemset is large in all sites
We got excess count in new sites for Qk
– Comparison means if the itemset is large in new sites

Experiments
3 programs– With privacy but no maintenance (SEC)– No Privacy but maintenance (MAN)– With privacy and maintenance (MSIDMAR)
Environment– P4 1.7GHz under Linux– Each site is simulated by an individual computer
Measure– CPU time

DB size
0
1000
2000
3000
0 400 800 1200Database size (in thousands)
CP
U T
ime
(in
sec
on
ds)
SEC MAN(old)MAN(new ) MSIMDAR(old)MSIMDAR(new )

Support
0
10000
20000
30000
40000
0% 1% 2% 3% 4%
Support Threshold
old sitesnew sites
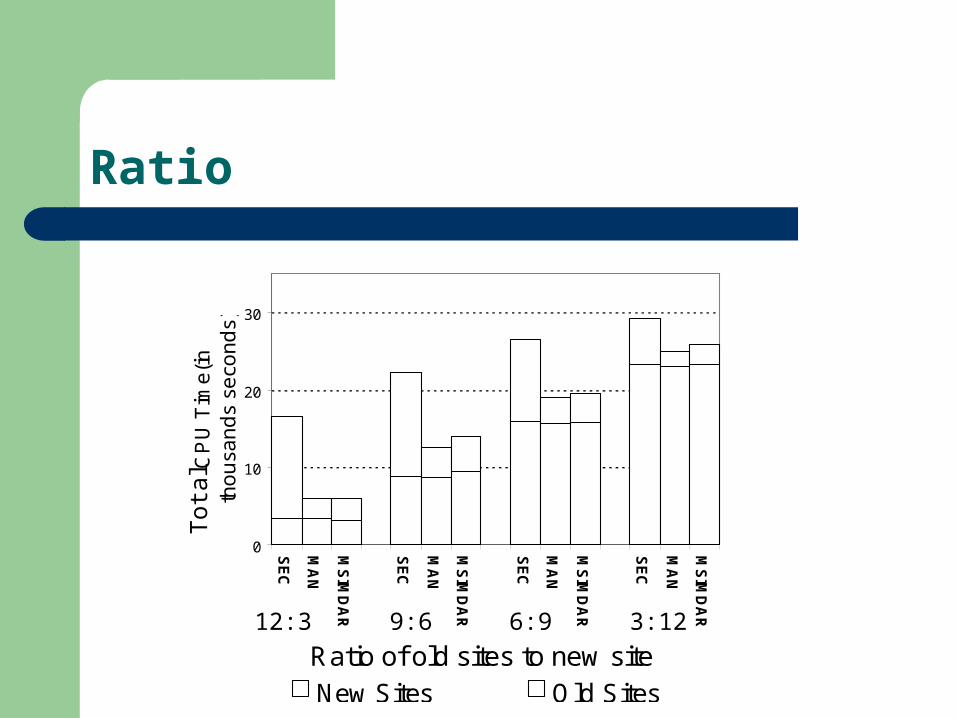
Ratio
0
10
20
30
SE
C
MA
N
MS
IMD
AR
SE
C
MA
N
MS
IMD
AR
SE
C
MA
N
MS
IMD
AR
SE
C
MA
N
MS
IMD
AR
Ratio of old sites to new site
CP
U T
ime
(in
tho
usa
nd
s se
con
ds)
New Sites Old Sites
Tot
al
12:3 9:6 6:9 3:12
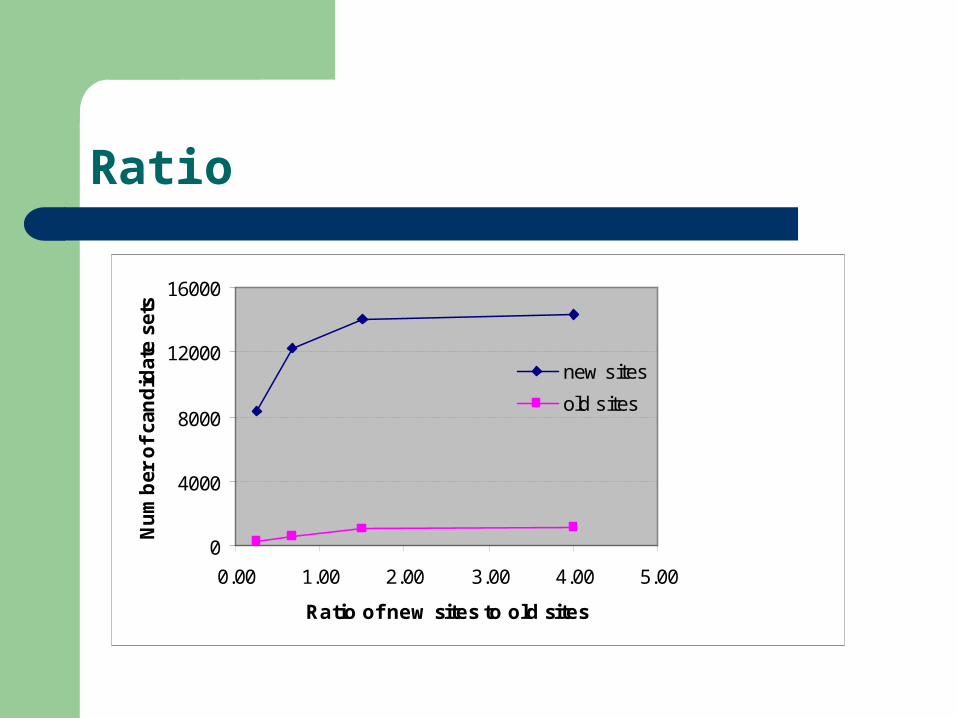
Ratio
0
4000
8000
12000
16000
0.00 1.00 2.00 3.00 4.00 5.00
Ratio of new sites to old sites
Nu
mb
er o
f ca
nd
idat
e se
ts
new sites
old sites

Analysis
Process time at new sites takes much longer– About 3 time to 5 times of that of old sites
Cost overhead due to secure algorithm– At old sites, average 10% of total cost– At new sites, average 6% of total cost– Both decrease in proportion with increase in db
size

Conclusion
We have proposed algorithms to solve the maintenance problem at different privacy level
– All can give a more efficient solution than simply ignoring the past results
As the number of sites are most likely to increase– The load on old sites will be low relatively to new sites– High entrance cost but low maintenance cost

End

















