MDPF For Search Appl ications In Mobil e Adhoc Networks Chapter 1 INTRODUCTION In a Mobile Ad Hoc Network (MANET), mobile devices (nodes) may be spread over a large area where access to external data is achieved through one or more access points(APs). However, not all nodes have a direct link with these APs. Instead, they rely on other nodes that act as routers to reach them. In certain situations, the APs may be located at the extremities of the MANET, where reaching them could be costly in terms of delay, power consumption, and bandwidth utilization. Additionally, the access point may connect to a costly resource (e.g., a satellite link), or an external network that is susceptible to intrusion. For such reasons and others that concern data availability and response time, MANET applications should check for the existence of the desired data inside the network before attempting to connect to the external data source. An example would be a node that is searching for data that have been requested before by othernodes and are now cached and available to the rest of the nodes. Another example is where there is a group of nodes that have data which may be of interest to other nodes and are willing to share them. These scenarios and o thers suggest that efficient data search techniques be d eveloped for allowing mobile nodes to find the desired data if it exists in the MANET quickly and with mi ni mum power con sumpti on. Gi ven how ad hoc wi re less networ ks work, sear ching performance relies on the efficiency of employed routing strategies. Actually, one of the biggest challenges in MANETS lies in the creation of efficient routing techniques [5]. Routing protocols are responsible for finding an efficient path between any two nodes in the network that wish to communicate, and for routing data messages along this path. The path must be cho sen so that networ k through put is maxi mi zed and me ss age delay and ot her undesirable events are minimized. Two main types of routing protocols exist: source routing and destination routing. Destination routing itself is classified into two types: distance-vector routing, used in the RIP Internet protocol [11], and link-state routing, used in the OSPF Internet protocol [12]. Relevant to our work are the Destination-Sequenced Distance Vector (DSDV) and the Ad hoc On-demand Distance Vector (AODV) protocols, which are distance-vector routing protocols designed for MANET environments. With such protocols, a node maintains a routing table and a distance vector. The table contains the neighbor along the shortest path to each destination in the Dept Of C.S.E, A.P.S.C.E 2010-11 Page 1
Transcript
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 1/30
MDPF For Search Applications In Mobile Adhoc Networks
Chapter 1
INTRODUCTION
In a Mobile Ad Hoc Network (MANET), mobile devices (nodes) may be spread over a large area
where access to external data is achieved through one or more access points(APs). However, not
all nodes have a direct link with these APs. Instead, they rely on other nodes that act as routers to
reach them. In certain situations, the APs may be located at the extremities of the MANET,
where reaching them could be costly in terms of delay, power consumption, and bandwidth
utilization. Additionally, the access point may connect to a costly resource (e.g., a satellite link),
or an external network that is susceptible to intrusion. For such reasons and others that concern
data availability and response time, MANET applications should check for the existence of the
desired data inside the network before attempting to connect to the external data source. An
example would be a node that is searching for data that have been requested before by other
nodes and are now cached and available to the rest of the nodes. Another example is where there
is a group of nodes that have data which may be of interest to other nodes and are willing to
share them. These scenarios and others suggest that efficient data search techniques be developed
for allowing mobile nodes to find the desired data if it exists in the MANET quickly and with
minimum power consumption. Given how ad hoc wireless networks work, searching
performance relies on the efficiency of employed routing strategies. Actually, one of the biggest
challenges in MANETS lies in the creation of efficient routing techniques [5].
Routing protocols are responsible for finding an efficient path between any two nodes in
the network that wish to communicate, and for routing data messages along this path. The path
must be chosen so that network throughput is maximized and message delay and other
undesirable events are minimized. Two main types of routing protocols exist: source routing and
destination routing. Destination routing itself is classified into two types: distance-vector routing,used in the RIP Internet protocol [11], and link-state routing, used in the OSPF Internet protocol
[12]. Relevant to our work are the Destination-Sequenced Distance Vector (DSDV) and the Ad
hoc On-demand Distance Vector (AODV) protocols, which are distance-vector routing protocols
designed for MANET environments. With such protocols, a node maintains a routing table and a
distance vector. The table contains the neighbor along the shortest path to each destination in the
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 1
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 2/30
MDPF For Search Applications In Mobile Adhoc Networks
network, while the vector has the distance (number of hops) of this path. In high mobility
scenarios, the paths from sources to destinations will become nonoptimal (i.e., not the shortest
paths) until the routing tables are updated. With DSDV, each node periodically updates its
shortest paths by sending its distance vector to its neighbors to inform them about possible
distance changes to destinations in the network, while with AODV, a node computes/updates the
shortest path to a destination only when it needs to communicate with it (i.e., on demand).
Our proposed Minimum Distance Packet Forwarding (MDPF) algorithm is based on the
same basic concept employed by distance-vector routing protocols in that it forwards the search
message to the nearest node that potentially stores the desired data item. Actually, MDPF maybe
regarded as a high-level routing protocol operating on top of a distance-vector routing protocol,
and thus, together they form a two-layer protocol that works to minimize the response time of a
search application by following the consecutive shortest paths. The given analysis focuses on
providing confidence intervals for the mean distance to reach the node with the desired data and
the distance to traverse all the search nodes. Moreover, it will be demonstrated that MDPF
distributes the average load caused by search traffic among the visited nodes nearly uniformly in
spite of their possibly nonuniform caching capacities.
The rest of this paper is organized as follows: Section 2 describes the proposed approach
and illustrates it using an example application. Section 3 derives expressions for the system
parameters plus key performance measures and presents the analysis results. Section 4 presents
the simulations done using the ns2 software. Section 5 provides a short survey of related work,
while finally, Section 6 ends the paper with concluding remarks and ideas for future work.
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 2
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 3/30
MDPF For Search Applications In Mobile Adhoc Networks
Chapter 2
FRAMEWORK OVERVIEW
The idea behind MDPF is to use routing table information for visiting nodes in the order of
shortest distance (hop counts). As implied, this requires valid routing information, which could
be handled through a proactive routing protocol such as the DSDV protocol or an on-demand
reactive routing protocol, like AODV. We make the assumption that the set of nodes that hold
the search information is known to all nodes in the wireless network, and we refer to these nodes
as the search nodes, or SNs. We emphasize though that a requesting node which is interested in a
particular data item does not usually know which specific SN holds the location of the data item,
and therefore, it must search for it in the SNs.
2.1 Basic Operation
According to MDPF, the client uses the information in the routing tables to send its request
to the nearest SN. If an SN does not have the requested data, it also uses MDPF and forwards the
request to the nearest unvisited SN. Fig. 1 shows two example scenarios. Nodes request database
data, which may be cached in any of the caching nodes (CNs). The search nodes (SNs) cache
previously submitted requests (queries), and for each such query, an SN maintains a reference to
the result that resides on a CN. In the first scenario, the client submits its request to the nearest
SN (SN3), which does not have a matching query. The request is then forwarded in accordance
with MDPF through SN1 and SN4 before it arrives to SN2, where a match is found. Using the
reference that is stored along with the cached query, the request of the client is forwarded to the
CN that stores the result. This CN sends the result to the client whose address is found in the
forwarded packet. In the second scenario, no match is found in the SNs, and so, the last visited
SN (SN5) forwards the request to the data server via the access point. The server retrieves the
result and sends it directly to the client, which, in turn, asks SN3 (being its nearest SN) to cache
the query. It is noted that the node at which the client requested the data item that was retrieved
from the outside data server becomes a CN for this particular item.
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 3
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 4/30
MDPF For Search Applications In Mobile Adhoc Networks
Fig. 2.1 Two scenarios for request forwarding: Scenario 1 corresponds to a hit and Scenario 2
describes a miss
When a proactive routing protocol is employed, MDPF can readily use the routing
information to choose the SN that requires the minimum number of hops from the set of
unchecked SNs. However, when an on-demand routing protocol, such as the AODV or Dynamic
Source Routing (DSR) protocols, is in place, the routing information to the nearest unvisited SN
must be discovered on demand if necessary (i.e., if its is not cached, or if it is cached but not
fresh) and kept in the routing table for a certain period of time before it expires. More
specifically, when a reactive routing protocol is employed, MDPF works as follows. Each node
examines its routing table to find if the routing information to the unchecked SNs is present and
valid. If yes, the node acts as in the proactive case and chooses the SN with the minimum
number of hops to reach. If the node finds that its routing table does not contain the routing
information for one or more unchecked SNs, it broadcasts an SN Discovery Packet (SNDP)
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 4
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 5/30
MDPF For Search Applications In Mobile Adhoc Networks
containing the list of unchecked SNs and a sequence number to all its neighbors.When a
neighbor receives an SNDP the first time, it checks its routing table for the presence of one or
more unchecked SNs. If it knows of such SNs, the neighbor sends the routing information of
these SNs to the requesting node. Else, the neighbor broadcasts (forwards) the SNDP to its own
neighbors. In order to prevent the possibility of flooding the network with packets, the SNDP
contains a hop limit k that denotes the maximum number of hops away from the source that the
SNDP can be sent to. The value of k depends on the network size, the total number of nodes, the
transmission range, and the number of current unchecked SNs. For example, for a 1;000 _ 1;000
m2 network containing 100 nodes, and when the number of unchecked SNs is 7, the network
diameter is approximately 14 hops and k could be set to 14=7 ¼ 2 hops (assuming that the SNs
are uniformly spread throughout the network).
As the number of uncheckedSNs decreases, k increases, and vice versa. When this number is
1, k will be equal to the network diameter. Finally, the SNDP source node waits for time _ (e.g.,
0.1 sec), examines the routing information to the SNs it received, then chooses the SN with
minimum number of hops to reach, and forwards the search packet to it. It also adds the routing
information to its routing table for future use.
2.2 Evaluation Methodology
The objective of this paper is to propose a message forwarding algorithm for search applications
and analyze its performance. We focus on the analysis of the hop count to reach the SN having
the desired data, and to traverse all the SNs. We also consider an important metric that concerns
fairness, namely, the average traffic load experienced by the different SNs. In addition to the
experimental evaluation using the ns2 simulation software, we analyze the system’s performance
using analytical derivations in the case of traffic load and numerical analysis in the case of hop
count. The reason for this is that simulation by itself does not always yield completely reliable
results, and this fact has been shown in published papers, such as [21].
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 5
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 6/30
MDPF For Search Applications In Mobile Adhoc Networks
2.2.1 Results Reliability
Simulation approaches usually suffer from a lack of reliability because it is difficult to
prove that the samples taken out of a certain probability distribution are indeed typical, or thatthe sampling distribution of their mean closely follows a Gaussian law. For example, probability
distributions with a high kurtosis may have sample means which are not close to the actual mean
of the distribution. All these problems and others affect the reliability of simulation in general,
while the analytical solution is usually reliable. Since the MDPF algorithm (or a very close
variant thereof) has, in fact, already been studied in Computer Science under the name of
“Nearest Neighbor” heuristic for the traveling salesperson problem, several papers can be found
in the literature on the subject. Unfortunately, the problems in this area turned out to be so
difficult that researchers who attempted to tackle similar problems analytically did so under
unrealistic simplifying assumptions such as considering all distances between pair of points
statistically independent from each other (i.e., even ignoring the triangular inequality) [13], while
some other researchers obtained analytical solutions on much simpler problems, for example, by
restricting themselves to the one-dimensional case, leaving the two-dimensional problem
unsolved due to its difficulty [17].
In contrast, the probabilistic results for similar problems, which are considered the most
reliable, have been obtained through simulation [10]. Still, however, we do not give up on the
analytical solution of the nearest SN search problem. In this regard, it might be useful to point
out the main challenge that makes the problem a difficult one, even under the infinite node
density assumption. First, it is not hard to obtain an expression for the probability distribution of
the closest SN to a given random SN: as derived in [2]. We assume that the SNs are randomly,
uniformly, and independently distributed on the considered area, and therefore, the probability
distribution function of the distance to the closest SN is simply the same as the distance sample
minimum. The sample minimum has a closed-form formula [18] which could be applied. But the
difficulties start to appear when we wish to determine the probability distribution of the distance
between the second and the third SN. The main problem here is that the distribution of available
SNs around the second SN is not independent from the position of the first SN.
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 6
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 7/30
MDPF For Search Applications In Mobile Adhoc Networks
Indeed, since the second SN was the closest one to the first, it means that the second SN is on the
boundary of a disk centered at the first SN which is empty of any SN. As one reaches the third,
fourth, and nth SN, the empty area becomes an ever more complicated union of disks, making it
difficult to obtain a provably accurate analysis.
2.2.2 Implemented Methodology
To avoid the lack of reliability often associated with results obtained through simulations,
we will derive confidence intervals for the obtained results. For the numerical analysis, we will
be able to obtain results at the 0.0001 confidence level (meaning a probability inferior to
1/10,000 of being wrong), while maintaining an acceptable precision (between 10 and 30
percent). For the experimental evaluation, we will follow the lead of Andrel and Yasinsac [1]
and derive a sample size necessary to obtain a 90 percent confidence in the computed averages.
The next section describes two methods for implementing the numerical analysis for the hop
count measure, followed by a section that treats the analytical derivation of the average load
experienced by the SNs. Finally, a third section is dedicated to presenting the results of the
experimental evaluation.
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 7
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 8/30
MDPF For Search Applications In Mobile Adhoc Networks
Chapter 3
HOP COUNT ANALYSIS
The average number of hops between two successively traversed SNs is different than averagenumber of hops between two random nodes because the latter represents the expected number of
hops when only one destination choice is available, while with MDPF, a client or SN picks the
nearest unchecked SN, and hence, the expected number of hops is anticipated to be lower. That
is, when there are more choices, it is more likely for a client or SN to find an unchecked SN that
is closer to it than when having fewer choices. Equivalently, as the number of choices decreases,
the average number of hops to get to the next SN increases. Like [2], we assume a rectangular
topology with area a x b and uniform distribution of nodes. Two nodes can form a direct link if
the distance x between them is less or equal to the maximum node transmission range r0. In this
analysis, we are interested in computing the average number of hops to get to the SN that holds
the desired data. Moreover, and for reference, we also derive the average number of hops to
reach the last SN from a requesting node. We do this by computing the upper and lower bounds
of the number of hops using numerical analysis. However, before describing our approach in
details, we mention two important theorems, which we refer to later. First, [15, Theorem 1] states
that for all graphs where the triangular inequality holds, the length of the nearest neighbor path
obeys the following equality:
where NN(i) is the length of the Traveling Salesperson Tour obtained using the Nearest
Neighbor heuristic on a problem instance i, Opt(i) is the length of the optimal tour of the problem
instance, and n is the number of nodes. Here, the term “optimal tour” was borrowed from [9] and
refers to the simple cycle of the shortest length containing all the nodes. Next, [16, Theorem 2]
specifies that if n points are in a unit square, the optimal path length is at most:
Dept Of C.S.E, A.P.S.C.E 2010-11 Page 8
8/3/2019 Seminar Pavi
http://slidepdf.com/reader/full/seminar-pavi 9/30
MDPF For Search Applications In Mobile Adhoc Networks
So, we can deduce a worst case bound on the length of the nearest neighbor path in a unit square:
However, it is often the average case which is the most relevant in practice. So, we are
now faced with a standard statistical problem: estimating the mean of an unknown probability
distribution using sampling. In our case, the probability distribution of the total path length is not
known to belong to a well-known family (e.g., Binomial, Poisson, Geometric, Gaussian, etc.). It
might be argued that since we will be looking at the distribution of the sample mean, we could
infer that it would tend to be a Gaussian law using the central limit theorem. But if we simply
rely on this, we would disregard the conditions of validity of the theorem, which would be a
rather risky thing to do: there are probability distributions which do not even have a mean, such
as defined on And, even for the distributions that do have a mean,
it is difficult to determine the sample size that would guarantee a sample mean distribution
acceptably close to the normal.
The only tool we have in this regard is the Berry-Esse´en theorem [19], which requires
knowing at least some bounds on the third moment and on the standard deviation to
be applied. We do not know either of these two values in our case. It would be possible to derive
some bounds on them, but if these bounds are too imprecise, the required sample size would
become enormous. That is why we finally opted for more direct methods that allow us to derive
confidence intervals without making any further assumption. We start by describing a naı¨ve
approach: we run, say, 1,000,000 experiments and record the smallest and highest values of
obtained path length. Wechoose two bounds which are, respectively, much below the minimum
and much above the maximum. We run 1,000,000 experiments a few times again. It is quite
probable that all the values we obtain will be within our bounds. So, we could obtain a result
such as 99.9 percent of all path length values falling within bounds x and y at the 0.0001
confidence level or even better (a chance in 10,000 of being wrong). We then can obtain a bound
on the mean by using the fact that the remaining paths have a bounded length (by Theorems 1
and 2 that were mentioned above) and that there are only few of them.
MDPF For Search Applications In Mobile Adhoc Networks
3.2 Method 2 for Computing the Confidence Intervals
Our second method is based on the theorem that the sample mean is an unbiased estimator of
the mean, meaning that the probability distribution of the sample mean and the sampled
probability distribution have the same expectation. This theorem holds for all probability
distributions which have a finite mean. The motivation behind the use of the sample mean is that
as a consequence of the Central Limit Theorem, the sample means usually tend to be much more
tightly grouped than the sample values and this phenomenon increases with sample size.
While this is the reason why the confidence intervals we have obtained through this method
are relatively narrow, we do not rely on this fact to derive them. So, we proceed as follows:
1. First, decide the total number of experiments that we are going to perform, say N.2. Choose two numbers n1 and n2 such that n1× n2= N. The value of n1 will be the size of a
single sample and n2 will be the number of samples.
3. We run the N experiments, considering them to be n2 samples of n1 size each. We compute
the mean of each of the n2 samples. We get the smallest mean and the largest mean. We then
choose two bounds which are, respectively, say 5 percent smaller than the smallest mean and 5
percent larger than the largest mean.
4. We run the N experiments again. Hopefully, all the means will be within the bounds chosen in
step 3. If not, we keep widening the interval until all means are within it for several more runs of
the N experiments.
5. We are now able to obtain a good lower bound on the proportion of path lengths that lie within
the interval, with a high-level confidence, using the same basic principles as the Clopper Pearson
method.
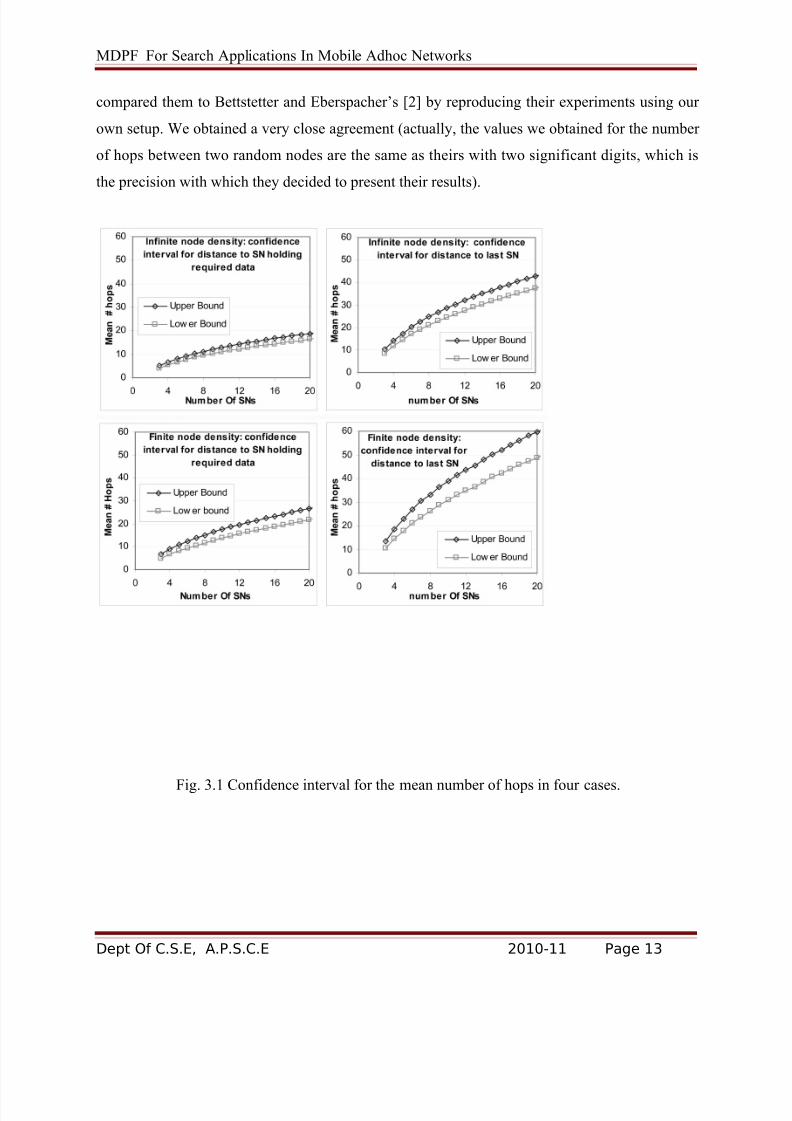
3.3 Confidence Intervals Computation Results
Using the two above methods, we obtained the confidence intervals for the path lengths, as
shown in Fig. 2. For each of these intervals, we are 99.9 percent sure that the mean falls within
them. In the infinite node density case, the sample size was 10,000, while for the finite density
case, the sample size was 3,000. All the corresponding bounds on the original distribution mean
are the 0.001 confidence level. To test the correctness and reproducibility of our results, we
MDPF For Search Applications In Mobile Adhoc Networks
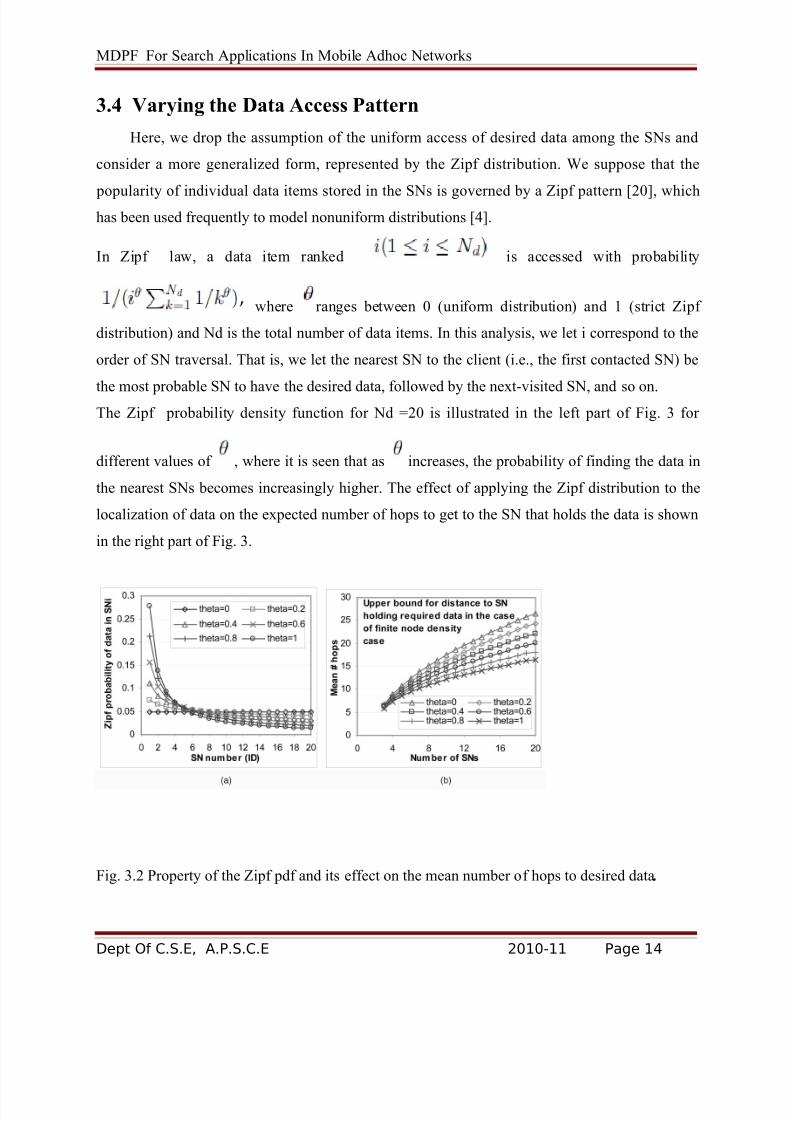
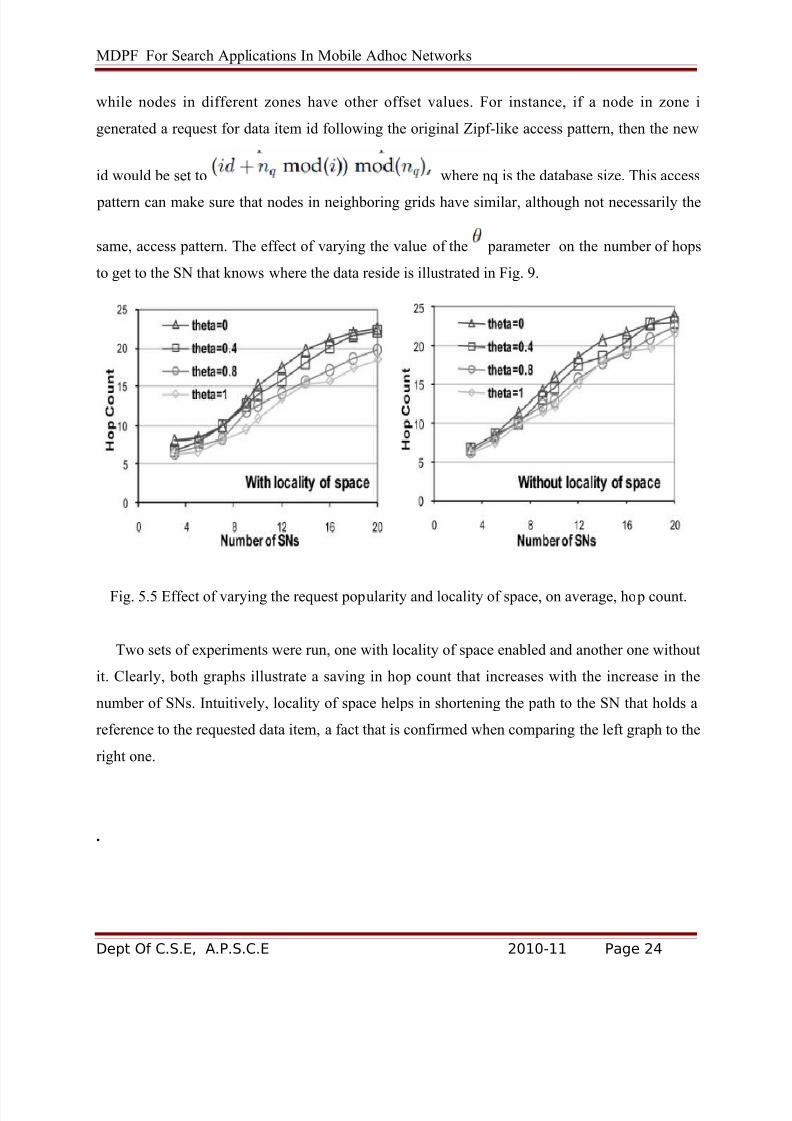
3.4 Varying the Data Access Pattern
Here, we drop the assumption of the uniform access of desired data among the SNs and
consider a more generalized form, represented by the Zipf distribution. We suppose that the
popularity of individual data items stored in the SNs is governed by a Zipf pattern [20], whichhas been used frequently to model nonuniform distributions [4].
In Zipf law, a data item ranked is accessed with probability
where ranges between 0 (uniform distribution) and 1 (strict Zipf
distribution) and Nd is the total number of data items. In this analysis, we let i correspond to the
order of SN traversal. That is, we let the nearest SN to the client (i.e., the first contacted SN) be
the most probable SN to have the desired data, followed by the next-visited SN, and so on.The Zipf probability density function for Nd =20 is illustrated in the left part of Fig. 3 for
different values of , where it is seen that as increases, the probability of finding the data in
the nearest SNs becomes increasingly higher. The effect of applying the Zipf distribution to the
localization of data on the expected number of hops to get to the SN that holds the data is shown
in the right part of Fig. 3.
Fig. 3.2 Property of the Zipf pdf and its effect on the mean number of hops to desired data.
MDPF For Search Applications In Mobile Adhoc Networks
Chapter 4
AVERAGE SEARCH NODE LOAD
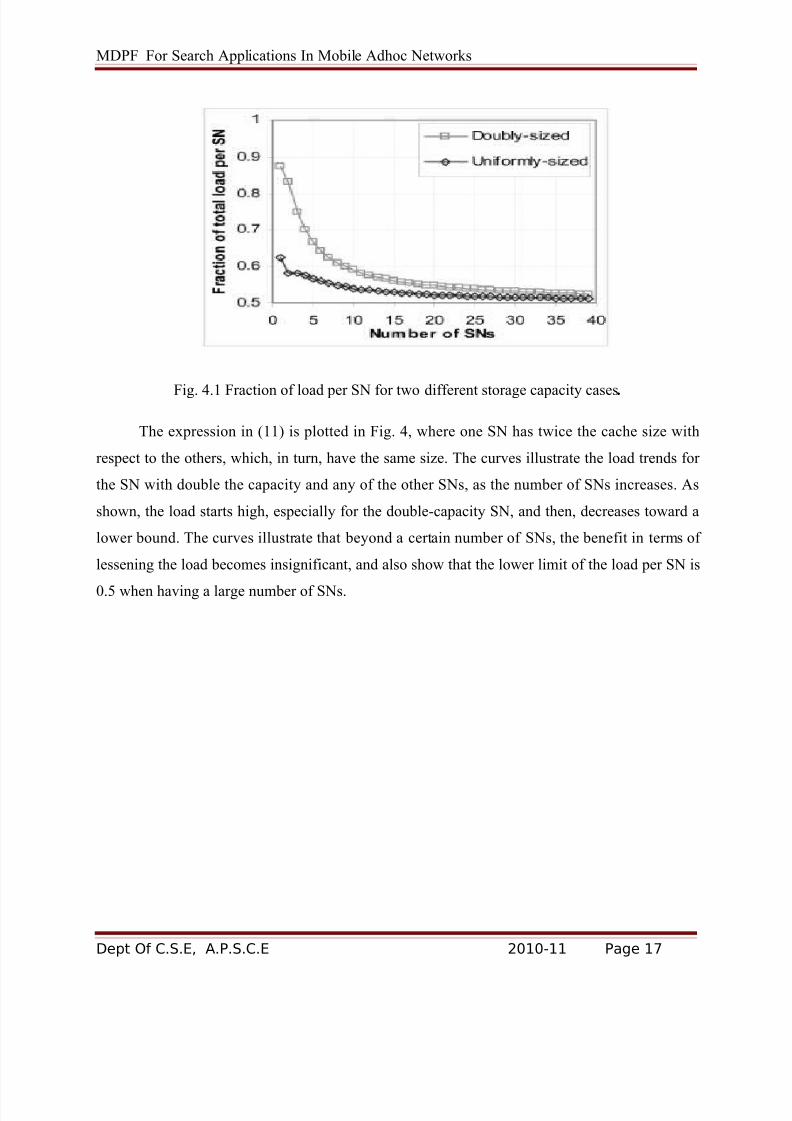
Since SNs are ordinary nodes themselves, an objective would be to minimize the number of requests handled by each node without degrading the system’s performance. Given that MDPF
calls for forwarding the request to the nearest SN and the requesting node may be any one in the
network, the initial SN may then be any of the SNs. Similarly, the second SN may be any of the
remaining SNs, and so on. Hence, the order in which the SNs are accessed will be uniformly
random. We define the load ratio on SNi, λi, as the ratio of number of accesses to SNi to the total
number of requests issued, and assume that the SNs have varying cache sizes. Having a cache
size Ci for SNi with no replication, the probability of finding a random data item in SNi is
However, when calculating all possible positions of SNi should be taken into account,
since the list of SNs may be accessed in any order. For this purpose, we define the function
which is the probability that SNi will be accessed (or have a request forwarded to)
given that it is in position n As explained earlier, this probability
depends on the cache size of all nodes that follow SNi. However, since the next nodes are
considered to be random, an expected total cache size must be determined. Now, since there is
no a priori knowledge of the positions of each of the other nodes in the sequence, their size is
estimated using the expected cache size of other nodes. This is determined as follows (N stands
MDPF For Search Applications In Mobile Adhoc Networks
SN5, SN4, then SN2) until the request reaches an SN that has a path to one of the remaining
unvisited SNs. Note that the reverse path can be determined by the order of visited SNs in the
request packet. In MSTF, even though an MST builds a tree that links all its nodes with the least
number of total hops hMST , the total number of hops traversed by the packet, however, could be
greater than hMST due to the aforementioned condition, and as illustrated in the example of Fig.
5. However, we will illustrate later in this section that MSTF might produce better average
search times when the time to search for the data item at an SN is significantly high.
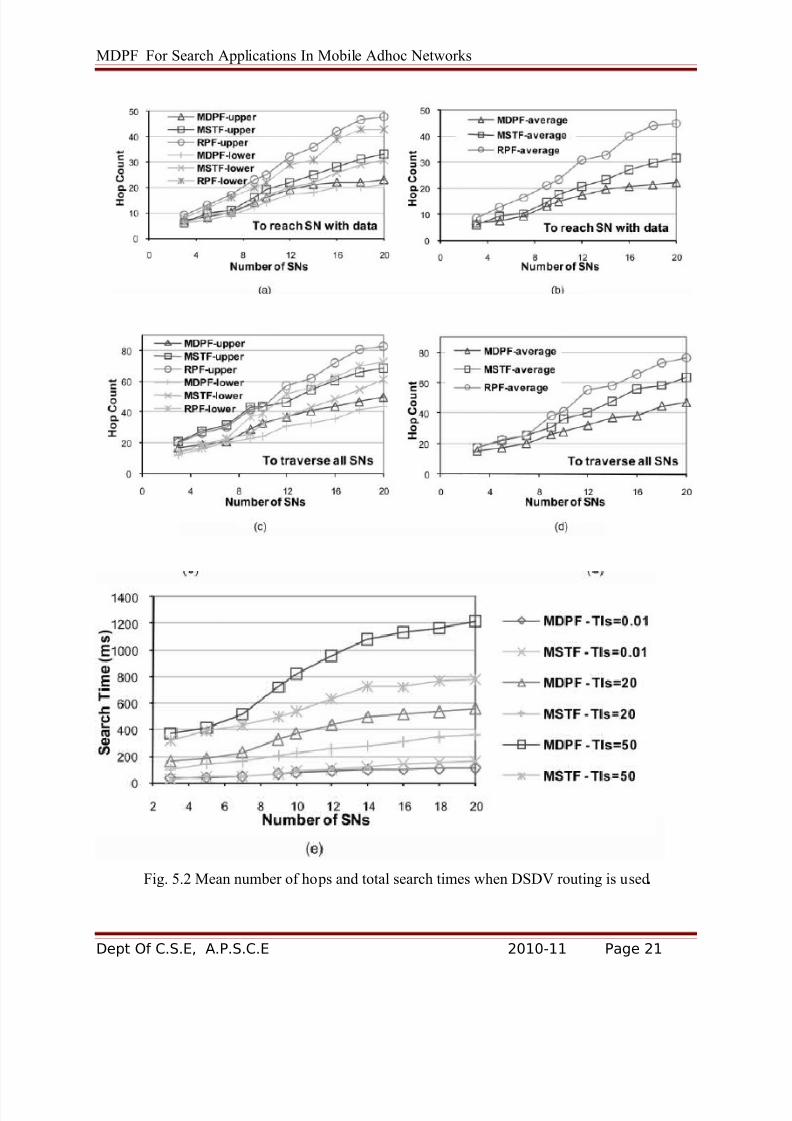
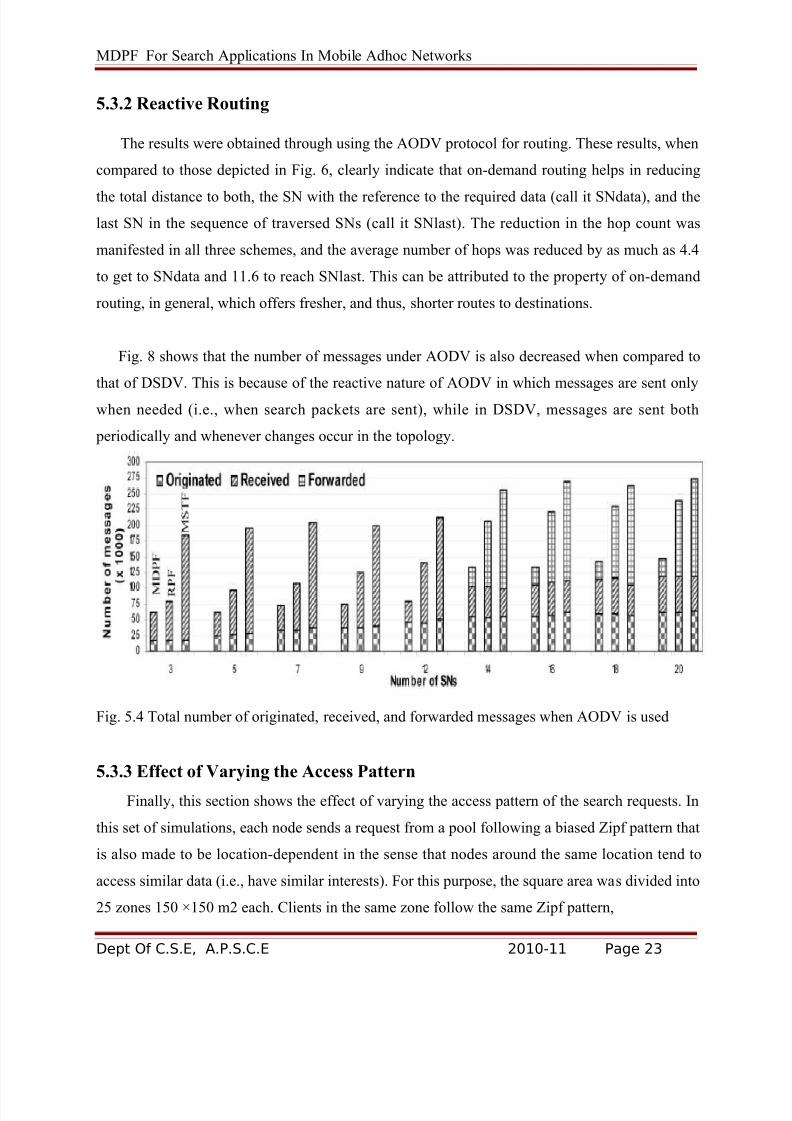
5.3 Results
To be consistent with the results presented in Section 3.5, we computed the lower and upper
bounds of the mean hop count for each scenario, in addition to the average taken over all sample
values. As was described above, each experiment comprised at least 27,000 points. To compute
the bounds, we used a procedure that is similar in principle to Method 2 (see Section 3.1.2) by
dividing the sample space into 54 groups, each consisting of about 500 samples. For each group,
the average value was computed, and then, the lower and upper bounds were taken as the lowest
and highest means, respectively, across all groups. In addition to the bounds, the overall average
was taken over all 27,000 points.
5.3.1 Proactive Routing
In this and the next sections, we examine the effect of the routing scheme on the performance
of all three systems, and in this section, we consider the DSDV protocol. The top-left and
middle-left graphs of Fig. 6 show the confidence interval of the mean hop count to reach the SN
with the data reference and to traverse all SNs, respectively. First, we remark that the results
shown in the two graphs are in line with the results presented in Section 3. In this regard, we
should indicate that the experimental results correspond to the finite number of nodes case
discussed in Section 3. With regard to comparing MDPF to MSTF and RPF, the top two rows of the graphs in Fig. 6 confirm that MDPF achieves minimum distance packet forwarding (in terms
of number of hops) to traverse all the SNs and reach the node that holds the reference to the