27
1/27 SP Study Paper Reading NAIST, AHC-Lab, SP-GROUP Mori Takuma(M1) 10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
| Date post: | 22-Mar-2017 |
| Category: |
Engineering |
| Upload: | mori-takuma |
| View: | 70 times |
| Download: | 0 times |

1/27
SP StudyPaper Reading
NAIST, AHC-Lab, SP-GROUP
Mori Takuma(M1)
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST

2/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
1. Towards End-to-End Speech Recognition with Deep Convolutional NeuralNetworks
2. Deep Speech 2: End-to-End Speech Recognition inEnglish and Mandarin
Outline

3/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
1. Towards End-to-End Speech Recognition with Deep Convolutional NeuralNetworks
2. Deep Speech 2: End-to-End Speech Recognition inEnglish and Mandarin
Outline

4/27
Towards End-to-End Speech Recognition with Deep Convolutional Neural
NetworksYing Zhang, Mohammad Pezeshki, Phil emon Brakel, Saizheng
Zhang, C esar Laurent,
Yoshua Bengio, Aaron Courville
Universit e de Montr eal, INTERSPEECH 2016
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST

5/27
Background• Convolutional Neural Networks (CNNs) are effective models for reducing spectral variations and modeling spectral correlations in acoustic features for automatic speech recognition.
• Connectionist Temporal Classification (CTC) with Recurrent Neural Networks (RNNs), which is proposed for labeling unsegmented sequences, makes it feasible to train an ‘end-to-end’ speech recognition system instead of hybrid settings.
Problem• RNNs are computationally expensive and sometimes difficult to train.
Solve• We propose an end-to-end speech framework for sequence labeling, by combining hierarchical CNNs with CTC directly without recurrent connections.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Overview
6/27
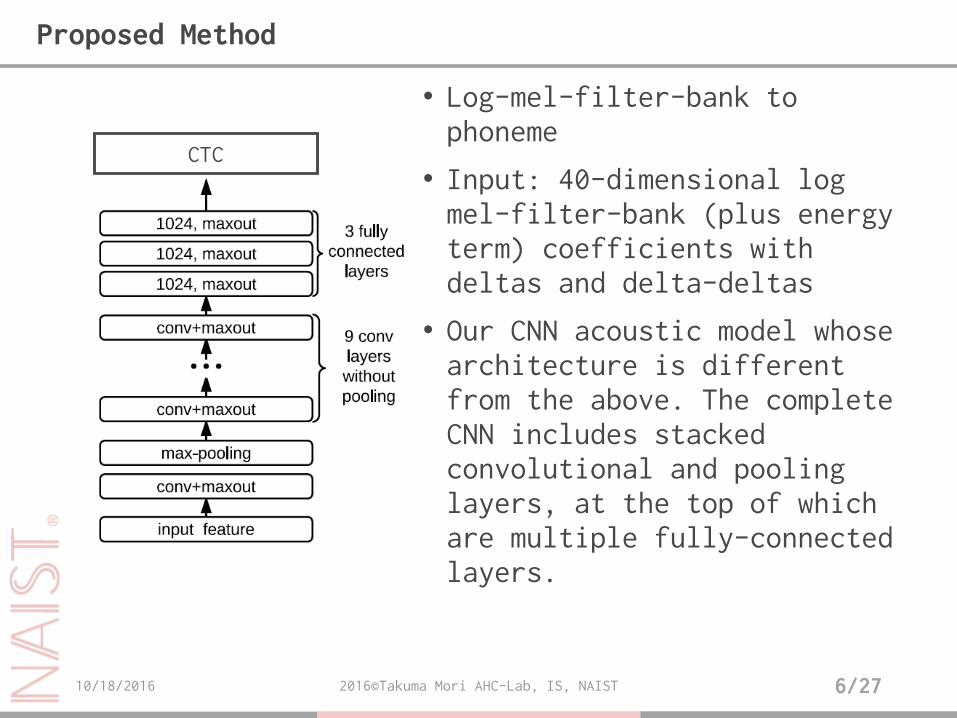
• Log-mel-filter-bank to phoneme
• Input: 40-dimensional log mel-filter-bank (plus energy term) coefficients with deltas and delta-deltas
• Our CNN acoustic model whose architecture is different from the above. The complete CNN includes stacked convolutional and pooling layers, at the top of which are multiple fully-connected layers.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Proposed Method
CTC
7/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Convolution

8/27
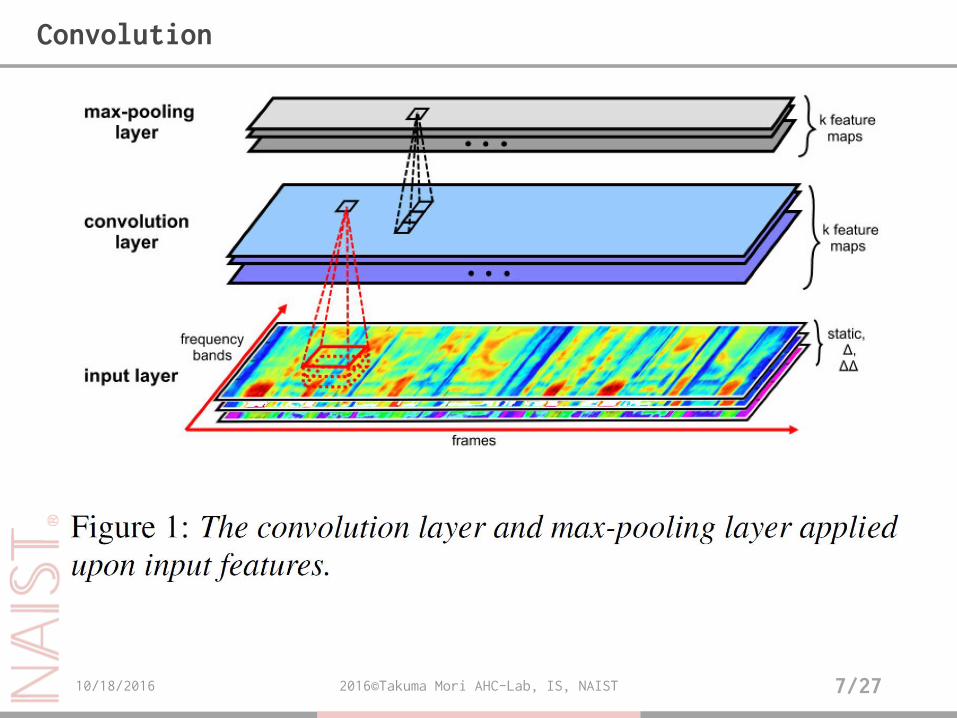
• Sequence of acoustic feature values:𝑋 ∈ ℝ𝑐×𝑏×𝑓
• channels 𝑐, frequency bandwidth 𝑏, time length 𝑓
• convolutional layer convolves 𝑋 with 𝑘 filters {𝑊𝑖}𝑘:
𝑊𝑖 ∈ ℝ𝑐×𝑚×𝑛
• Frequency axis = m, length along frame axis = n
• The resulting 𝑘 preactivation feature maps consist of a 3D tensor:
𝐻 ∈ ℝ𝑘×𝑏𝐻×𝑓𝐻
• 𝐻𝑖 is computed as follows:
𝐻𝑖 = 𝑊𝑖 ∗ 𝑋 + 𝑏𝑖, 𝑖 = 1,… , 𝑘.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Convolution

9/27
• We take the number of piece-wise linear functions as 2 for example
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Maxout

10/27
• Before ෩𝐻𝑖 and After 𝐻𝑖 pooling:[𝐻𝑖]𝑟,𝑡= 𝑚𝑎𝑥𝑗=1
𝑝{[෩𝐻𝑖]𝑟×𝑠+𝑗,𝑡}
• the step size s, pooling size p, all the [ ෩𝐻𝑖]𝑟×𝑠+𝑗,𝑡 values inside the max have the same time index t.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Pooling

11/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Connectionist Temporal Classification
12/27
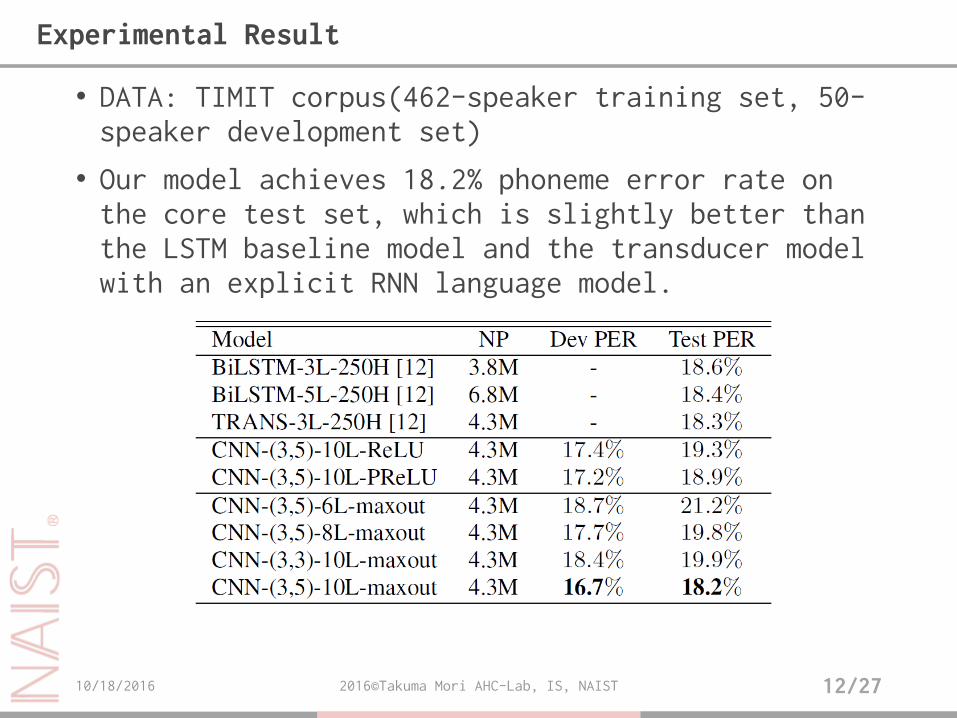
• DATA: TIMIT corpus(462-speaker training set, 50-speaker development set)
• Our model achieves 18.2% phoneme error rate on the core test set, which is slightly better than the LSTM baseline model and the transducer model with an explicit RNN language model.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Experimental Result

13/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
1. Towards End-to-End Speech Recognition with Deep Convolutional NeuralNetworks
2. Deep Speech 2: End-to-End Speech Recognition inEnglish and Mandarin
Outline

14/27
Deep Speech 2: End-to-End Speech Recognition inEnglish and Mandarin
Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Jingdong Chen, Mike Chrzanowski, Adam
Coates, Greg Diamos, Erich Elsen, Jesse Engel, Linxi Fan, Christopher Fougner, Tony Han, Awni Hannun, Billy Jun, Patrick LeGresley, Libby Lin, Sharan Narang, Andrew Ng, Sherjil Ozair, Ryan Prenger, Jonathan Raiman, Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Yi Wang, Zhiqian Wang, Chong Wang, Bo Xiao, Dani
Yogatama, Jun Zhan, Zhenyao Zhu
Baidu Research – Silicon Valley AI Lab, ICML 2016
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST

15/27
Background
• This “end to end” vision of training simplyfiesthe training process.
Effort
• We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech–two vastly different languages.
• In several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets.
• Finally, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Overview
16/27
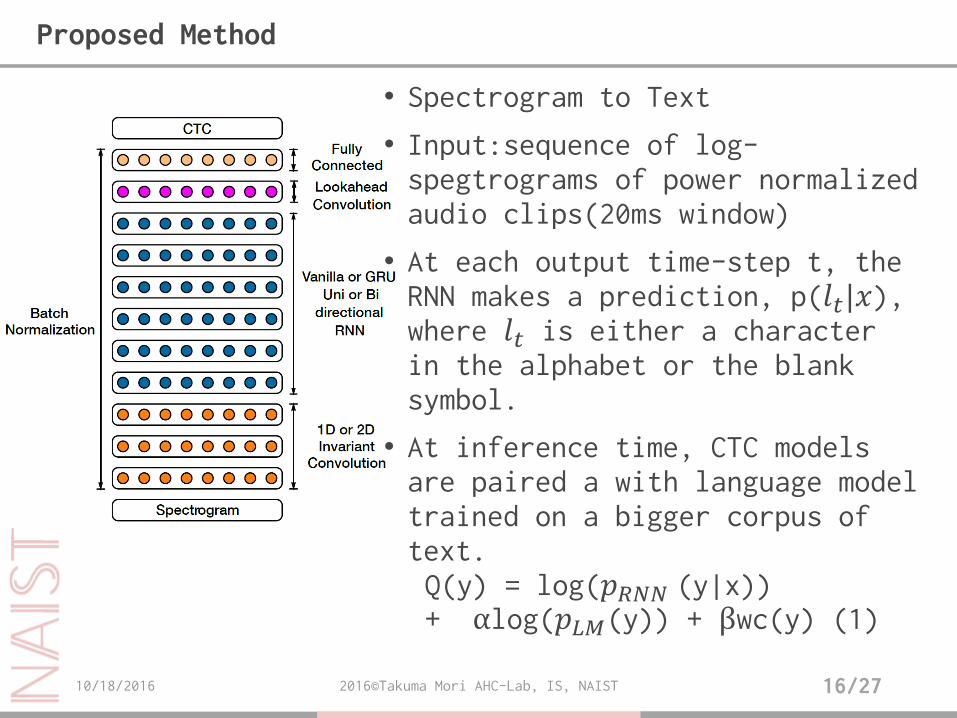
• Spectrogram to Text
• Input:sequence of log-spegtrograms of power normalized audio clips(20ms window)
• At each output time-step t, the RNN makes a prediction, p(𝑙𝑡|𝑥), where 𝑙𝑡 is either a character in the alphabet or the blank symbol.
• At inference time, CTC models are paired a with language model trained on a bigger corpus of text.Q(y) = log(𝑝𝑅𝑁𝑁 (y|x))+ αlog(𝑝𝐿𝑀(y)) + βwc(y) (1)
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Proposed Method

17/27
• Recent research has shown that BatchNorm(Batch Normalization) can speed convergence of RNNs training, though not always improving generalization error.
• A recurrent layer is implemented asℎ𝑡𝑙 = 𝑓(𝐵 𝑊𝑙ℎ𝑡
𝑙−1 + 𝑈𝑙ℎ𝑡−1𝑙 )
• Two ways of applying BatchNorm
1. ℎ𝑡𝑙 = 𝑓(𝐵 𝑊𝑙ℎ𝑡
𝑙−1 +𝑈𝑙ℎ𝑡−1𝑙 )
2. ℎ𝑡𝑙 = 𝑓(𝐵 𝑊𝑙ℎ𝑡
𝑙−1 +𝑈𝑙ℎ𝑡−1𝑙 )
𝐵 :BatchNorm transformation
• 1 is not effective.
• 2 is good.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Batch Normalization for Deep RNNs

18/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Batch Normalization for Deep RNNs
19/27
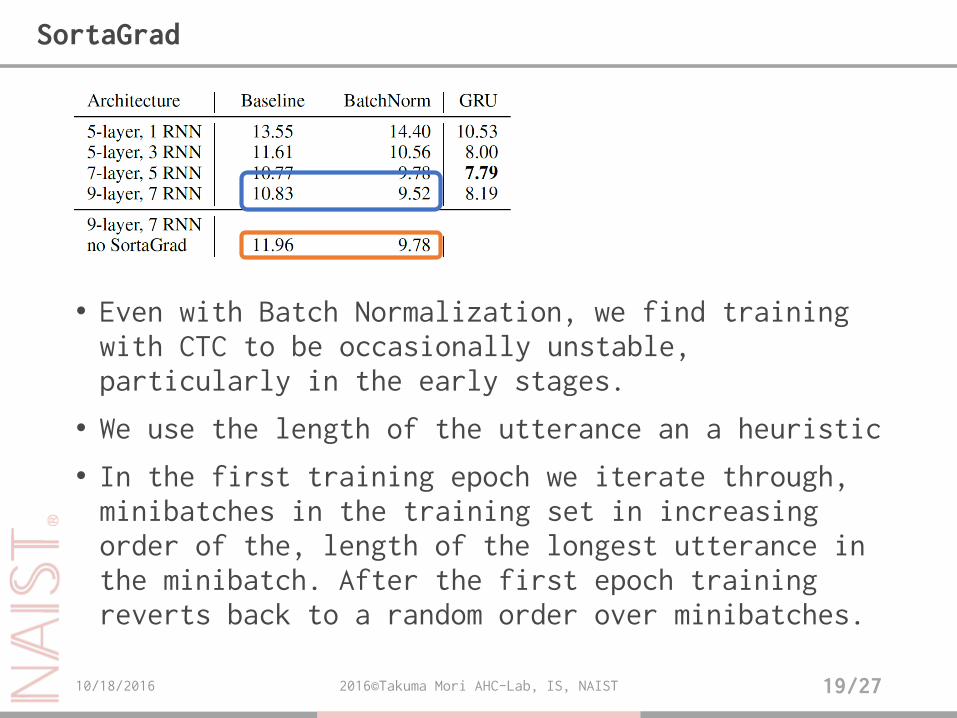
• Even with Batch Normalization, we find training with CTC to be occasionally unstable, particularly in the early stages.
• We use the length of the utterance an a heuristic
• In the first training epoch we iterate through, minibatches in the training set in increasing order of the, length of the longest utterance in the minibatch. After the first epoch training reverts back to a random order over minibatches.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
SortaGrad

20/27
• GRU and LSTM reach similar accuracy
• GRUs are faster to train and less likely to diverge.
• GRU architecture achieves better WER for all network depths.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Comparison of vanilla RNNs and GRUs
21/27
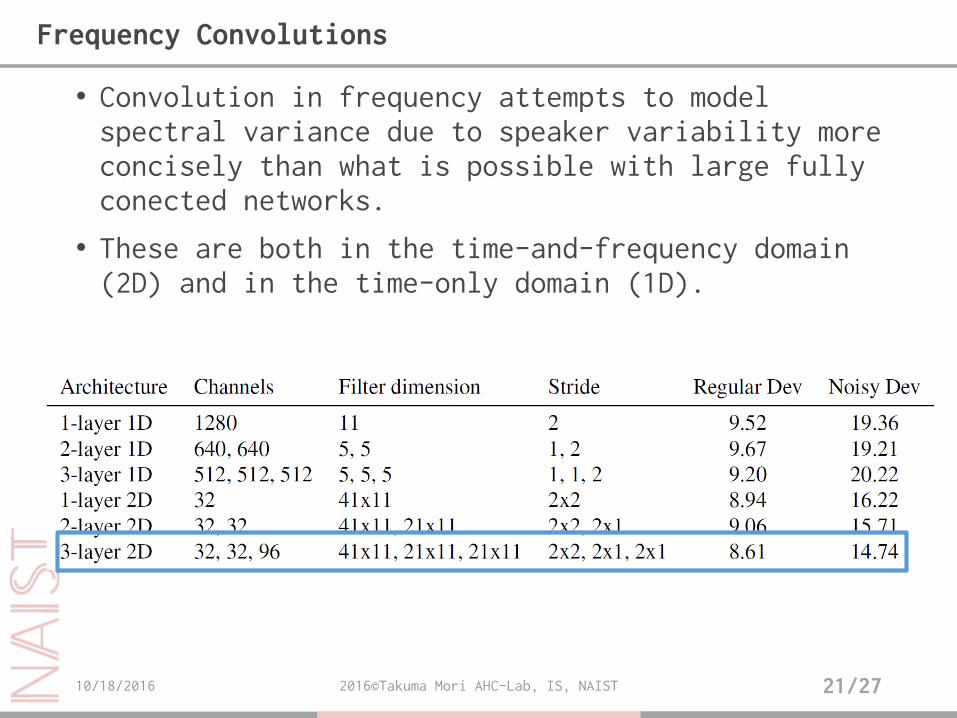
• Convolution in frequency attempts to model spectral variance due to speaker variability more concisely than what is possible with large fully conected networks.
• These are both in the time-and-frequency domain (2D) and in the time-only domain (1D).
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Frequency Convolutions
22/27
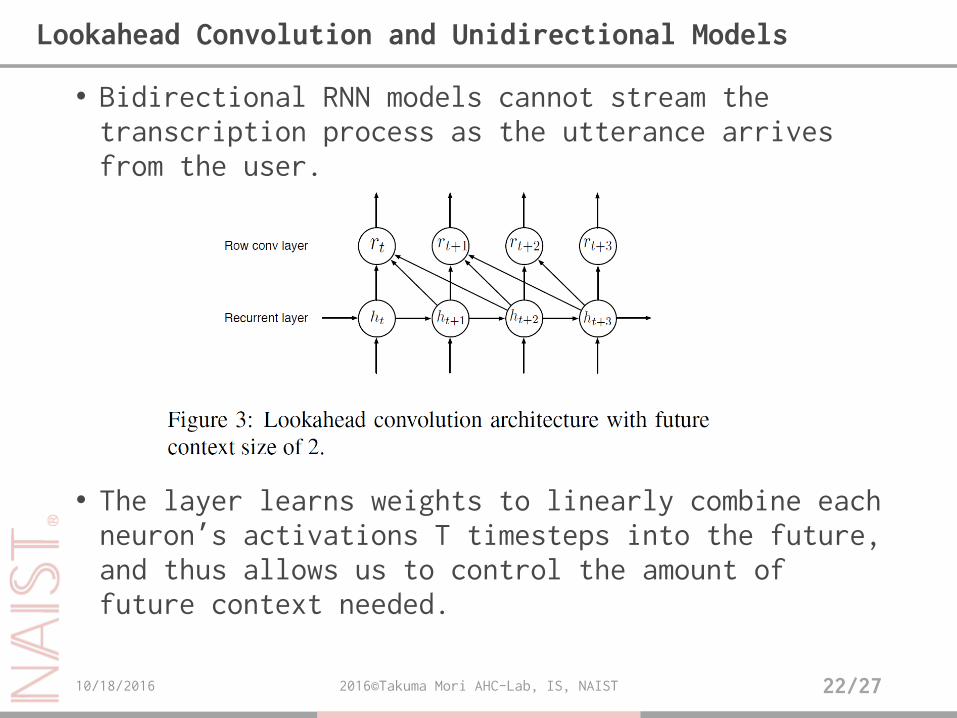
• Bidirectional RNN models cannot stream the transcription process as the utterance arrives from the user.
• The layer learns weights to linearly combine each neuron’s activations T timesteps into the future, and thus allows us to control the amount of future context needed.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Lookahead Convolution and Unidirectional Models

23/27
• The only architectural changes we make to our networks are due to the characteristics of the Chinese character set.
• The network outputs probabilities for about 6000 characters, which includes the Roman alphabet, since hybrid Chinese-English transcripts are common.
• We use a character level language model in Mandarin as words are not usually segmented in text.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Adaptation to Mandarin

24/27
• Optimizer: Synchronous SGD.
• Our training distributes work over multiple GPUs in a dataparallel fashion with synchronous SGD.
• Each GPU uses a local copy of the model to work on a portion of the current minibatch and then exchanges computed gradients with all other GPUs.
• It is reproducible, which facilitates discovering and fixing regressions.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
System Optimizations

25/27
• Training Data: 11,940 hours of labeled speech containing 8 million utterances
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Experimental Result
26/27
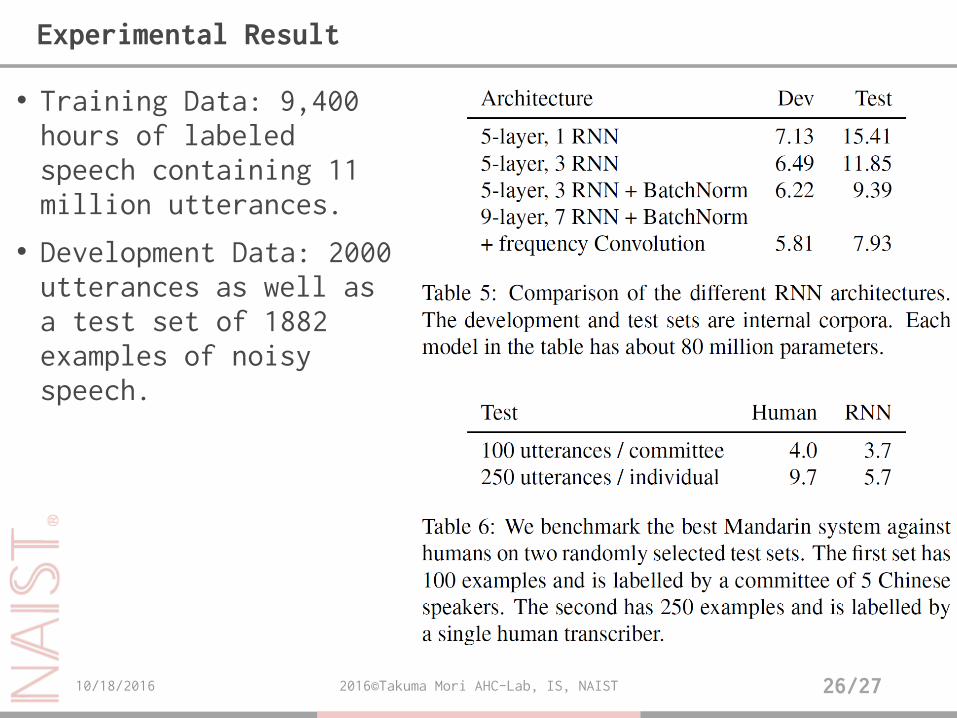
• Training Data: 9,400 hours of labeled speech containing 11 million utterances.
• Development Data: 2000 utterances as well as a test set of 1882 examples of noisy speech.
10/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
Experimental Result

27/2710/18/2016 2016©Takuma Mori AHC-Lab, IS, NAIST
End Slide.

















