12
SpaceX Interview Code Overview and Analysis Josh Sulkin Sep. 12, 2011
| Date post: | 13-Dec-2015 |
| Category: |
Documents |
| Upload: | mitchell-sharp |
| View: | 217 times |
| Download: | 0 times |

SpaceX Interview Code Overview and Analysis
Josh SulkinSep. 12, 2011
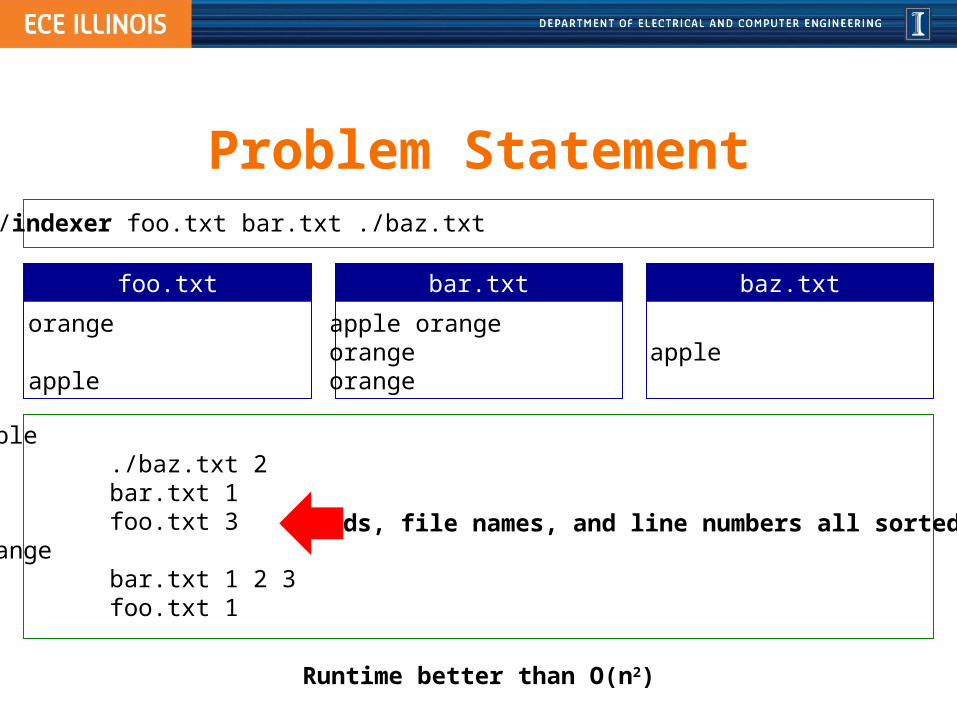
Problem Statement> ./indexer foo.txt bar.txt ./baz.txt
orange
apple
foo.txt
apple orangeorangeorange
bar.txt
apple
baz.txt
apple ./baz.txt 2 bar.txt 1 foo.txt 3orange bar.txt 1 2 3 foo.txt 1
Words, file names, and line numbers all sorted.
Runtime better than O(n2)

Proposed Solution
Step 1:
Step 2:
Worst-Case Runtime: O(n*k)n: number of words
k: length of longest word
• Sort the file names in place• Insert each word into a Trie
- the word is the key- the value is a vector of line numbers for each file
• Do a pre-order traversal of the Trie
- For each stored value print the key and the list of line numbers for each file
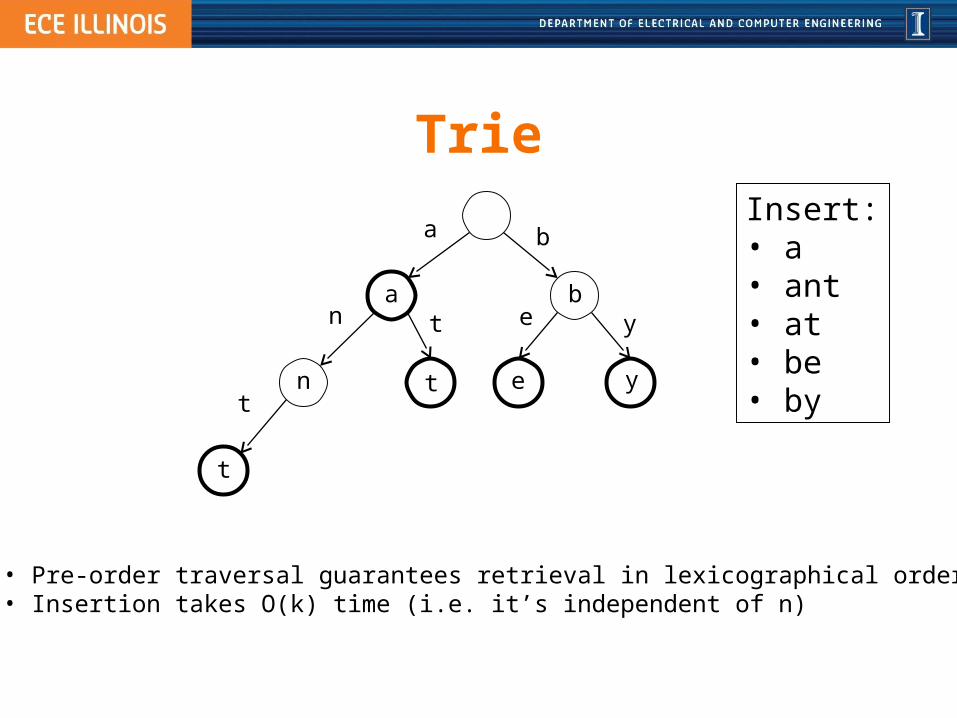
Trie
a
n
t
at
n
t
t
b
e yb
e y
Insert:• a• ant• at• be• by
• Pre-order traversal guarantees retrieval in lexicographical order• Insertion takes O(k) time (i.e. it’s independent of n)

Trie.h

Trie.h

MultiCount.h and SpaceXVector.h

SpaceXVector.h

Main.cpp

Modifications

Modifications
• Simplified interface to Trie• Made duplicate line number
detection more efficient– Used fact that line numbers are inserted
in order
• Added more input parameter checks– Throw exceptions if parameters are bad
(i.e. initializing MultiCount with negative numbers)

Runtime Tests
Use
r S
pace
Run
time
[s]
Number of Words (n) Length of Words (k)
k = 5 n = 1E+05
















