38


SQL Server's Big Red ButtonsPublished Friday, January 06, 2012 12:24 PM
One of the most reassuring aspects of watching a vintage James Bond film is the comfort of knowing that, just when there seems no further hopethat the villain's plans for world domination will be thwarted, Bond will glance up at the wall and notice a big red button. Instantly, he knows that all hehas to do is press it and the villain's lair will self-destruct messily, with plenty of pyrotechnics, and armed men being tossed into the air like rag dolls.
Of course, you have to wonder why the technologists who built the lair put that big red button on the wall. It seems to be an irresistible urge, and oneto which the creators of SQL Server are not immune, as @SQLPoolBoy noted last week in one of his tweets...
       "Looking at a database that has 99% fragmentation across the board. The cause, AutoShrink"
...a database brought to its knees by some poor soul who had accidentally hit one of SQL Server's big red buttons.
You have to feel sorry for anyone who accidentally accepts the default database sizing and auto-growth settings, or turns on AutoShrink, oraccidentally creates a collation conflict, or falls foul of any other of a host of 'Red Button' actions that can eventually lead to metaphoricalpyrotechnics and DBAs being tossed in the air like dolls.
SQL Server makes it very easy to tweak its various database- and server-level settings and so it's easy for inconsistency to creep in betweendatabase and servers, and it's easy for someone to unwittingly hit one of the red buttons. However, for the DBA managing tens of servers, it's notnecessarily easy to find out which buttons have been pressed where, or to find best practice advice on how some of these settings really should beconfigured for each environment.
However, help in various forms is slowly emerging. Brent Ozar has made publicly available his SQL Server Blitz script, which helps you verify someof the absolute fundamentals (Are backups being taken? Are DBCC checks being run?), and then seeks out a few of the more common redbuttons, which may need deactivating.
Then there is also SQLCop, a free community tool for "detecting common problems with database configurations and TSQL code". Named aftera similar .NET tool (FxCop), it's broader in scope than the Blitz script, checking everything from configuration settings, to fragmented indexes, tomissing Foreign Keys, to "code smells" in stored procedures. Red Gate has done some work with the makers of this tool, in incorporating some oftheir tests into the SQLTest tool, the idea being that the final step to resolving such problems may be automated testing.
However, there is still much work to be done. What are your favorite "Red Button" actions in SQL Server? What is the best way to find anddeactivate them before they cause havoc in your Server and databases?
Cheers,
Tony.
by Tony Davis

D
Unit Testing Myths and Practices05 January 2012by Tom Fischer
We all understand the value of Unit Testing, but how come so few organisations maintain unit tests for their in-house applications?We can no longer pretend that unit testing is a universal panacea for ensuring less-buggy applications. Instead, we should beprepared to actively justify the use of unit tests, and be more savvy about where in the development cycle the unit test resourcesshould be most effectively used.
espite the pervasive dictum within software engineering that unit tests must exist for all code, such tests are little-used for the development ofenterprise applications. In over fifteen years of consulting, I can count on the fingers of my hand the number of organizations maintaining unit
tests for their applications. Why is it that so many organizations ignore such a popular software practice? In order to answer this question we firstneed to explore the myths and real world practices of unit testing, and then go on to describe the points within development where their value iswell-established.
Myths
Two of the more generally-held myths that prop up the dogma of unit testing concern the professed benefits. The first myth, and most loudly claimed,states that unit testing inevitably saves money. The second myth, and zealously professed by many developers and engineers, promises areduction in the bug count.
The Saving Money Myth
The idea that unit testing inevitably lowers the cost of application development rests on the reasonable assumption that fixing a bug as soon aspossible saves money. Graphs such as the one below typically compare two application’s costs to support this claim. Each solid black linerepresents an application’s total cost over time.
The application labeled “No Unit Tests” starts out with lower expenses than that labeled “Unit Tests” as shown by the red line. Not a surprising factsince someone either coded or didn’t code unit tests. Over time though the “No Unit Tests” application costs more money because of increasedsupport, bug fixes, deployment, lost customers, etc. According to this assumption about cost-savings, organizations can even calculate the“Breakeven” point at which their unit testing pays off. And at any time past this point they can find the total savings earned from writing unit tests asshown by the green line on the far right.
There’s a problem with the underlying assumptions supporting the above cost profiles. They do not factor in the financial repercussions of a delay inthe delivery of today’s enterprise applications.
The first problem stems from the increasing importance of enterprise applications to an organization’s profitability. For example, it is not unusual fora company to build some widget that’ll save identifiable staff several hours a day. Delaying the widget’s release in order to write unit tests causesnot only angst but measurable, lost productivity. I have rarely seen a developer convince an end user that adding unit tests justifies delaying a much-anticipated feature just to prevent of a few potential bugs.
The second problem is the cost associated with the consequences of writing tests. Time expended coding unit tests keeps other features un-builtand idling on backlog. It disrupts the development process. The process of implementing unit tests cannot be readily scaled up to prevent backlogbecause, for most organizations, there are only one or two folks possessing the domain knowledge to add new or enhanced features to a specificapplication. When these developers code unit tests they are not coding new stuff.
When we update our cost assumptions for Unit Tests with only these two omissions, our graph alters as shown below. The “Unit Tests” application’stotal cost over time line shifts up with dramatic implications.
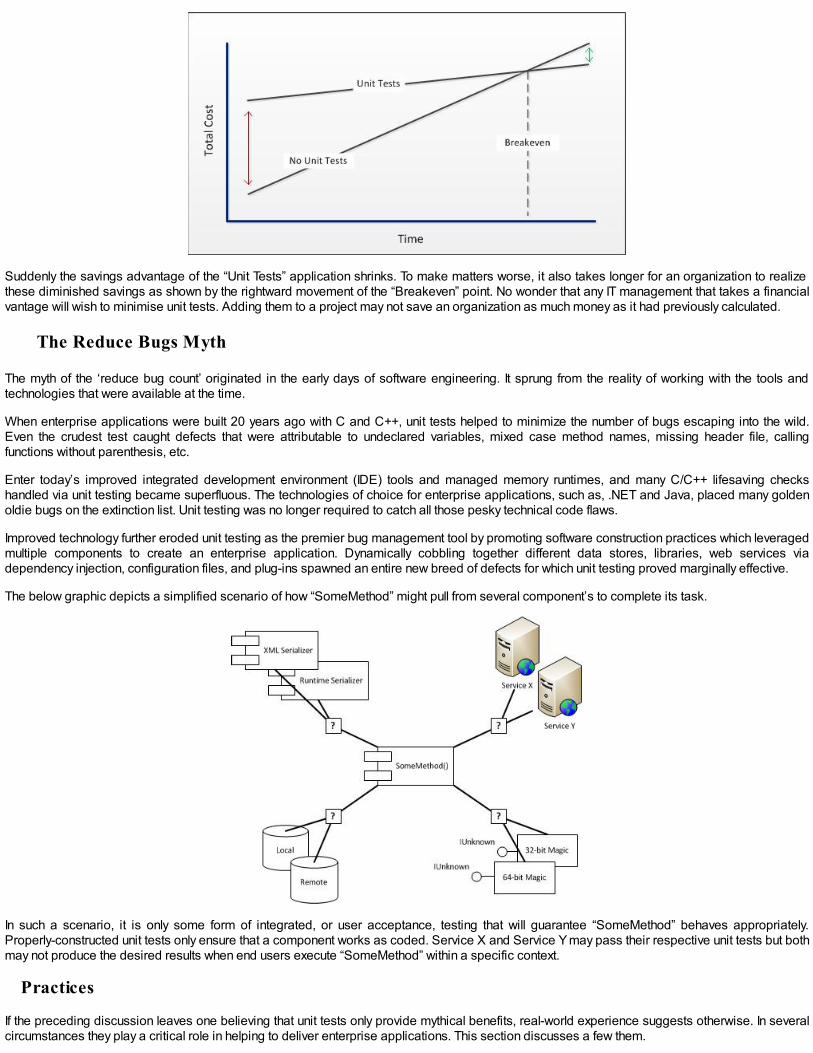
Suddenly the savings advantage of the “Unit Tests” application shrinks. To make matters worse, it also takes longer for an organization to realizethese diminished savings as shown by the rightward movement of the “Breakeven” point. No wonder that any IT management that takes a financialvantage will wish to minimise unit tests. Adding them to a project may not save an organization as much money as it had previously calculated.
The Reduce Bugs Myth
The myth of the ‘reduce bug count’ originated in the early days of software engineering. It sprung from the reality of working with the tools andtechnologies that were available at the time.
When enterprise applications were built 20 years ago with C and C++, unit tests helped to minimize the number of bugs escaping into the wild.Even the crudest test caught defects that were attributable to undeclared variables, mixed case method names, missing header file, callingfunctions without parenthesis, etc.
Enter today’s improved integrated development environment (IDE) tools and managed memory runtimes, and many C/C++ lifesaving checkshandled via unit testing became superfluous. The technologies of choice for enterprise applications, such as, .NET and Java, placed many goldenoldie bugs on the extinction list. Unit testing was no longer required to catch all those pesky technical code flaws.
Improved technology further eroded unit testing as the premier bug management tool by promoting software construction practices which leveragedmultiple components to create an enterprise application. Dynamically cobbling together different data stores, libraries, web services viadependency injection, configuration files, and plug-ins spawned an entire new breed of defects for which unit testing proved marginally effective.
The below graphic depicts a simplified scenario of how “SomeMethod” might pull from several component’s to complete its task.
In such a scenario, it is only some form of integrated, or user acceptance, testing that will guarantee “SomeMethod” behaves appropriately.Properly-constructed unit tests only ensure that a component works as coded. Service X and Service Y may pass their respective unit tests but bothmay not produce the desired results when end users execute “SomeMethod” within a specific context.
Practices
If the preceding discussion leaves one believing that unit tests only provide mythical benefits, real-world experience suggests otherwise. In severalcircumstances they play a critical role in helping to deliver enterprise applications. This section discusses a few them.

Building Libraries
Even the most powerful frameworks and runtimes omit features that are required by an organization. Because of this, organizations wisely createtheir own custom libraries for all their developers. As these libraries change of over time, whether via refactoring or feature updates, unit testing isessential to quickly validate the change and can save an organization a great deal of time and money.
Enhancing Technology
Sometimes the required technology cannot work its magic alone. Unaided it allows developers to write buggy code all too easily. In such situationsenhancing the technology with unit testing comes to the rescue.
Developing browser-based User-interfaces is an example of this situation. Despite the existence of such powerful plug-ins for building Web-BasedUser-Interfaces as Flex and Silverlight, it is HTML and JavaScript that remain the tools of choice for responsive web applications. AlthoughJavaScript is powerful, it looks more like C++ than C#. This means developers will need unit tests to avoid the classic pitfalls of type checking,improperly cased names, overwritten functions, etc.
Helping Startup Projects
When a new project with several engineers starts from scratch it will initially generate much code that will ultimately require synchronization. But untilreconciling all of the project’s components each engineer usually needs a way to execute their code without the other components. Unit testing toolsand products can provide such services.
As an aside, I find test driven development (TDD) demonstrates this value proposition. It too does not require developers to have all of theircomponents’ dependencies lined up and running. TDD allows engineers and developers to productively and safely write a lot code courtesy of unittesting. Developers only require the scantiest knowledge of the project’s other components.
Implementing Smoke Tests
Regularly deploying code to any environment can be a risky proposition for even the smallest fix or feature. We repeatedly relearn this fact.(Remember that little tweak that broke the entire application and left the testing staff without work?) In order to combat this problem manyorganizations write a few key unit tests which are automatically executed immediately after a build and before deployment. These few “smoke tests”provide enough coverage to ensure the basic functionality of the application.
If smoke testing sounds like continuous integration (CI), there’s a reason. They share similar objectives, albeit with vastly different scope. CItypically demands organizational commitment and resources; incorporating smoke tests typically requires a few commands by the build manager.
Writing Clearer Code
By having to Craft unit tests, developers are forced to think as consumers of their code. This gives them an extra motivation to build an applicationprogramming interface (API) that is clear, and easy to implement.
The drive to write better unit tests generally motivates better design, too. By incorporating unit tests into their components, Developers areencouraged to follow many good software design tenets, such as, avoiding hidden dependencies, and coding functions with a well-definedmission.
Note: Bug Management Practices
If unit testing provides less than ideal bug management support, what options exist for software developers and engineers? After all theintegrated and UAT tests are completed prevailing practices suggest two broad strategies for better managing bugs, one passive andone active.
The passive policy amounts to organizations providing a full featured help desk. In such an environment end users report bugs which gettriaged until resolved. While an effective practice from a managerial perspective, it tends to frustrate end users and place developers in areactive mode.
Actively managing bugs is an alternative strategy of growing popularity. It requires applications to self-report exceptions and such. Thiscan happen via home grown or 3rd party tools, such as, Red Gate’s SmartAssembly. This strategy acknowledges the difficulty ofpreventing bugs with the belief that knowing about them as soon as possible without explicit user complaints mitigates pain.
Conclusion
Forgive me if I have left any readers thinking ill of unit testing. Nothing could be further from my intent! The goal was to challenge the premise thatwriting unit tests is always a wise practice in all contexts. Because the IT culture within the enterprise application space is no longer so uncriticallyaccepting of the value of unit testing it is up to software engineers and developers to actively justify the cost of building unit tests in terms of benefits

to the enterprise. I’ve noted in this article several circumstances where unit testing is vital for the timely delivery of robust applications, and I stronglysuspect that many enterprise application engineers and developers who read this will think of more.
We can no longer rely on a general acceptance of the myth that unit testing is a universal panacea, but need to focus unit testing on aspects ofdevelopment where it is most effective, and be prepared to actively justify its use.
© Simple-Talk.com


A
Window Functions in SQL Server: Part 3: Questions ofPerformance04 January 2012by Fabiano Amorim
A SQL expression may look elegant on the page but it is only valuable if its performance is good. Do window functions run quickerthan their conventional equivalent code? Fabiano gives a definitive answer.
re Window Functions as fast as the equivalent alternative SQL methods? In this article I’ll be exploring the performance of the window functions.After you read this article I hope you’ll be in a better position to decide whether it is really worth changing your application code to start using
window functions.
Before I start the tests, I would like to explain the most important factor that affects the performance of window functions. A window spool operatorhas two alternative ways of storing the frame data, with the in-memory worktable or with a disk-based worktable. You’ll have a huge difference onperformance according to the way that the query processor is executing the operator.
The in-memory worktable is used when you define the frame as ROWS and it is lower than 10000 rows. If the frame is greater than 10000 rows,then the window spool operator will work with the on-disk worktable.
The on-disk based worktable is used with the default frame, that is, “range…” and a frame with more than 10000 rows.
It’s possible to check whether the window spool operator is using the on-disk worktable by looking at the results of the SET STATISTICS IO. Let’ssee a small example of the window spool using the on-disk based worktable:
USE tempdbGOIF OBJECT_ID('tempdb.dbo.#TMP') IS NOT NULL DROP TABLE #TMPGOCREATE TABLE #TMP (ID INT, Col1 CHAR(1), Col2 INT)GOINSERT INTO #TMP VALUES(1,'A', 5), (2, 'A', 5), (3, 'B', 5), (4, 'C', 5), (5, 'D', 5)GOSET STATISTICS IO ONSELECT *, SUM(Col2) OVER(ORDER BY Col1 RANGE UNBOUNDED PRECEDING) "Range" FROM #TMPSET STATISTICS IO OFF
Table 'Worktable'. Scan count 5, logical reads 29, physical reads 0, read-ahead reads 0, loblogical reads 0, lob physical reads 0, lob read-ahead reads 0.Table 'Worktable'. Scan count 1, logical reads 1, physical reads 0, read-ahead reads 0, loblogical reads 0, lob physical reads 0, lob read-ahead reads 0.
SET STATISTICS IO ONSELECT *, SUM(Col2) OVER(ORDER BY Col1 ROWS UNBOUNDED PRECEDING) "Rows" FROM #TMPSET STATISTICS IO OFF
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, loblogical reads 0, lob physical reads 0, lob read-ahead reads 0.Table 'Worktable'. Scan count 1, logical reads 1, physical reads 0, read-ahead reads 0, loblogical reads 0, lob physical reads 0, lob read-ahead reads 0.
As you can see, the worktable has some reads when you use a “range”, but it doesn’t happen with the in-memory worktable which is used when youuse “Rows”.
Optionally you also can look at the xEvent called window_spool_ondisk_warning. Fortunately on SQL Server 2012 we’ve a very nice interface thatwe can use to deal with xEvents. In SSMS, you can easily capture an event, and then look at the live data captured. Here you can see a screen-capture of this interface:

There are many aspects of the window spool operator that could be improved, I just opened some connect items about this and I’d appreciate it ifyou could take a minute or so to vote on this items.
Window Spool worktable doesn't spill to tempdbDefault window spool worktable in memoryGranting memory to process window spool worktableUnnecessary Sort
For now, when the logic of the query allows it, it is a good practice to always define the window frame as ROWS in order to try to use the in-memory worktable.
Performance testsI’ll now show some performance tests that I did with the most-used windows functions such as LEAD, LAG, LAST_VALUE and the OVER clause.
To execute the tests, I used the free SQLQueryStress toll created by Adam Machanic ( blog | twitter), you can download it here, I also will use thesample database AdventureWorks2008R2.
Let’s start by testing the performance of the clause OVER with the running aggregation solution, let’s see how it would scale with many usersdemanding information from the server.
First let’s create a table with 453772 rows:
USE AdventureWorks2008R2GOSET NOCOUNT ON;IF OBJECT_ID('TestTransactionHistory') IS NOT NULL DROP TABLE TestTransactionHistoryGOSELECT IDENTITY(INT, 1,1) AS TransactionID, ProductID, ReferenceOrderID, ReferenceOrderLineID, TransactionDate, TransactionType, Quantity, ActualCost, ModifiedDate INTO TestTransactionHistory FROM Production.TransactionHistory CROSS JOIN (VALUES (1), (2), (3) , (4)) AS Tab(Col1)GOCREATE UNIQUE CLUSTERED INDEX ixClusterUnique ON TestTransactionHistory(TransactionID)GO
Running Aggregation, Clause OVER + Order ByNow let’s run the old solution to the running aggregation query:
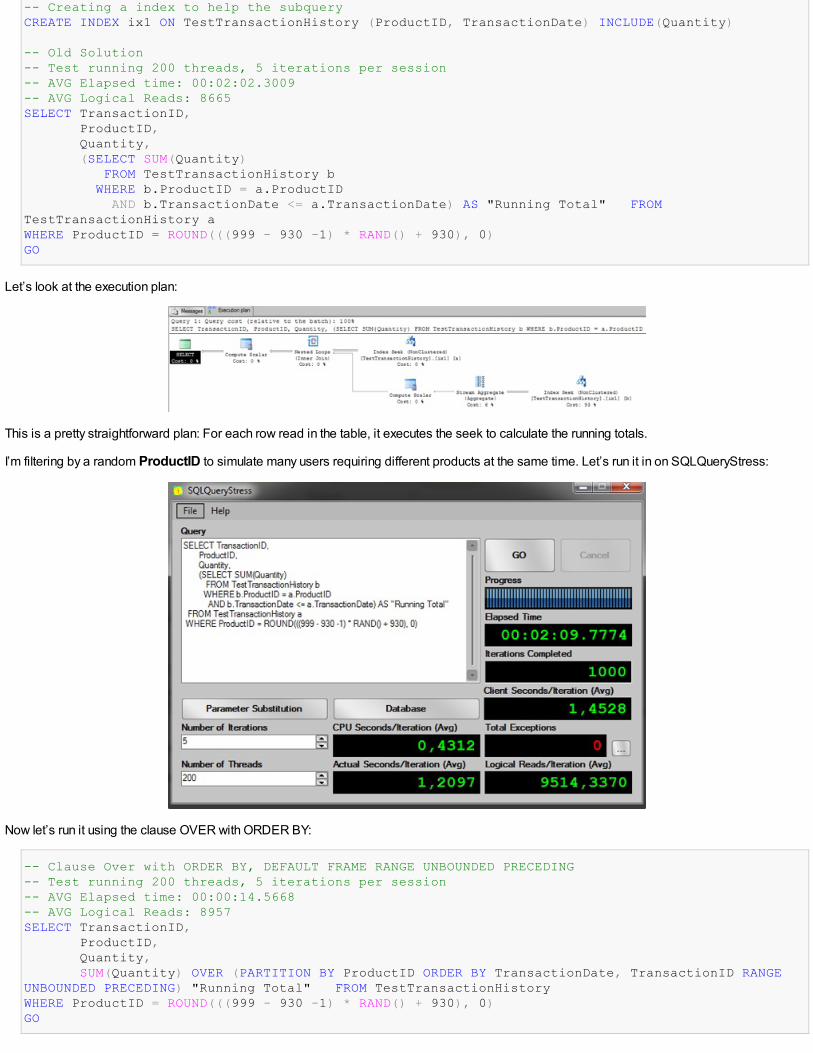
-- Creating a index to help the subqueryCREATE INDEX ix1 ON TestTransactionHistory (ProductID, TransactionDate) INCLUDE(Quantity)
-- Old Solution-- Test running 200 threads, 5 iterations per session-- AVG Elapsed time: 00:02:02.3009-- AVG Logical Reads: 8665SELECT TransactionID, ProductID, Quantity, (SELECT SUM(Quantity) FROM TestTransactionHistory b WHERE b.ProductID = a.ProductID AND b.TransactionDate <= a.TransactionDate) AS "Running Total" FROMTestTransactionHistory aWHERE ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)GO
Let’s look at the execution plan:
This is a pretty straightforward plan: For each row read in the table, it executes the seek to calculate the running totals.
I’m filtering by a random ProductID to simulate many users requiring different products at the same time. Let’s run it in on SQLQueryStress:
Now let’s run it using the clause OVER with ORDER BY:
-- Clause Over with ORDER BY, DEFAULT FRAME RANGE UNBOUNDED PRECEDING-- Test running 200 threads, 5 iterations per session-- AVG Elapsed time: 00:00:14.5668-- AVG Logical Reads: 8957SELECT TransactionID, ProductID, Quantity, SUM(Quantity) OVER (PARTITION BY ProductID ORDER BY TransactionDate, TransactionID RANGEUNBOUNDED PRECEDING) "Running Total" FROM TestTransactionHistoryWHERE ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)GO

The execution plan is:
As you can see, there is no double access to the table here. There is just a window spool doing the magic of keeping the rows to be aggregated.
The results from SQLQueryStress:
Now let’s specify the ROWS frame in the query and run again:
-- Clause Over with ORDER BY, ROWS WINDOW FRAME, ROWS UNBOUNDED PRECEDING-- Test running 200 threads, 5 iterations per session-- AVG Elapsed time: 00:00:02.7381-- AVG Logical Reads: 8SELECT TransactionID, ProductID, Quantity, SUM(Quantity) OVER (PARTITION BY ProductID ORDER BY TransactionDate, TransactionID ROWSUNBOUNDED PRECEDING) "Running Total" FROM TestTransactionHistoryWHERE ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)GO
The results from SQLQueryStress:
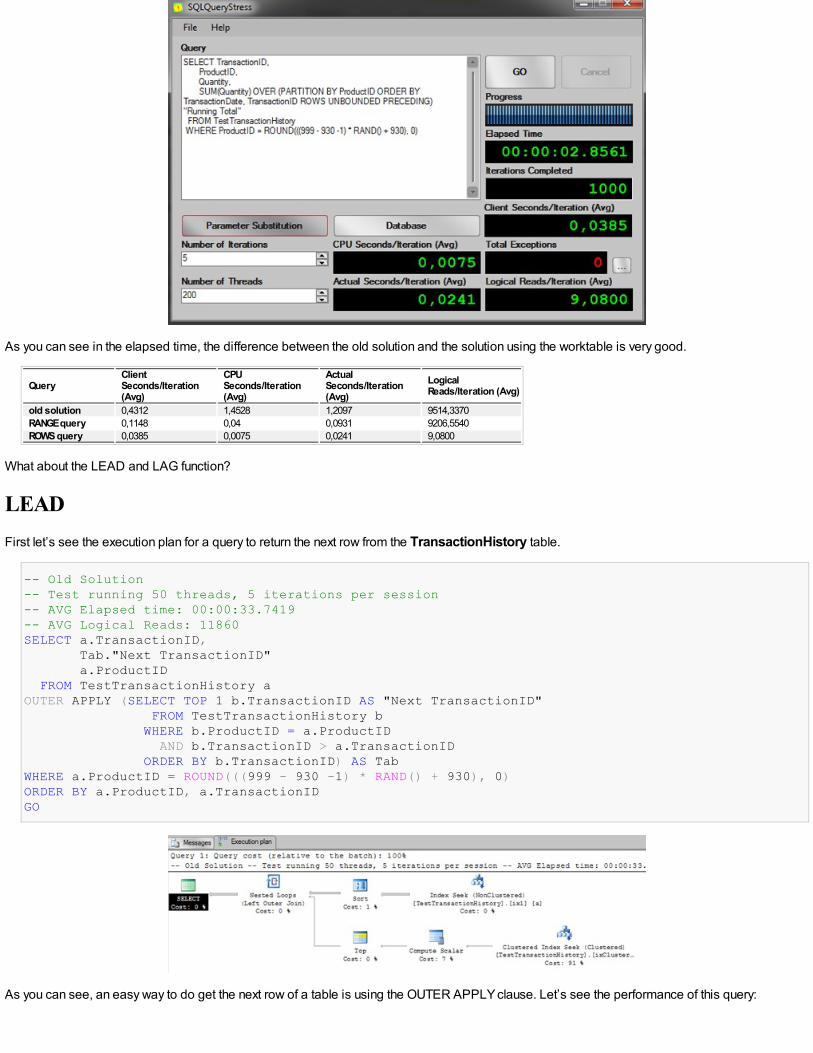
As you can see in the elapsed time, the difference between the old solution and the solution using the worktable is very good.
QueryClientSeconds/Iteration(Avg)
CPUSeconds/Iteration(Avg)
ActualSeconds/Iteration(Avg)
LogicalReads/Iteration (Avg)
old solution 0,4312 1,4528 1,2097 9514,3370RANGE query 0,1148 0,04 0,0931 9206,5540ROWS query 0,0385 0,0075 0,0241 9,0800
What about the LEAD and LAG function?
LEADFirst let’s see the execution plan for a query to return the next row from the TransactionHistory table.
-- Old Solution-- Test running 50 threads, 5 iterations per session-- AVG Elapsed time: 00:00:33.7419-- AVG Logical Reads: 11860SELECT a.TransactionID, Tab."Next TransactionID" a.ProductID FROM TestTransactionHistory aOUTER APPLY (SELECT TOP 1 b.TransactionID AS "Next TransactionID" FROM TestTransactionHistory b WHERE b.ProductID = a.ProductID AND b.TransactionID > a.TransactionID ORDER BY b.TransactionID) AS TabWHERE a.ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)ORDER BY a.ProductID, a.TransactionIDGO
As you can see, an easy way to do get the next row of a table is using the OUTER APPLY clause. Let’s see the performance of this query:

Now let’s see the same query but now using the LEAD function to get the next row.
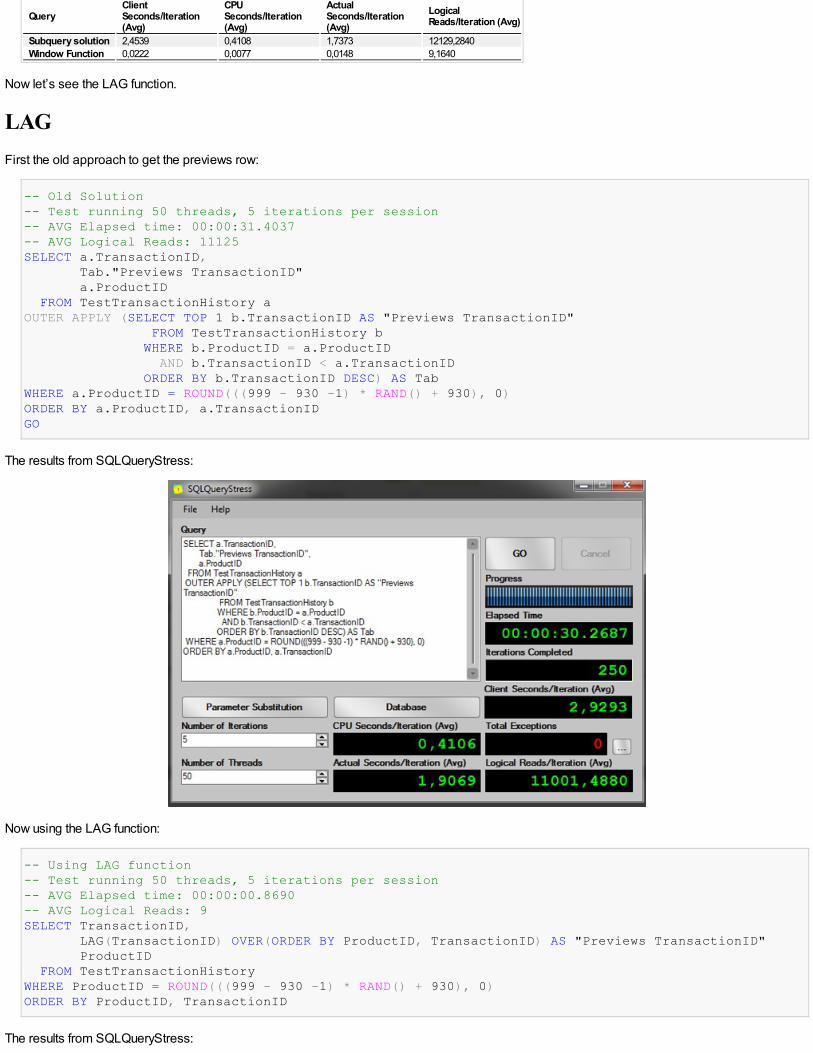
-- Using LEAD function-- Test running 50 threads, 5 iterations per session-- AVG Elapsed time: 00:00:00.9020-- AVG Logical Reads: 9SELECT TransactionID, LEAD(TransactionID) OVER(ORDER BY ProductID, TransactionID) AS "Next TransactionID", ProductID FROM TestTransactionHistoryWHERE ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)ORDER BY ProductID, TransactionID
Execution Plan:
As you can see from the execution plan, we could improve the query by creating an index on the columns ProductID and TransactionID toremove the sort operator, but in order to compare the performance, let’s see the results of the execution on this query:
Again, the window function is much better than the old subquery solution.
QueryClientSeconds/Iteration(Avg)
CPUSeconds/Iteration(Avg)
ActualSeconds/Iteration(Avg)
LogicalReads/Iteration (Avg)
Subquery solution 2,4539 0,4108 1,7373 12129,2840Window Function 0,0222 0,0077 0,0148 9,1640
Now let’s see the LAG function.
LAGFirst the old approach to get the previews row:
-- Old Solution-- Test running 50 threads, 5 iterations per session-- AVG Elapsed time: 00:00:31.4037-- AVG Logical Reads: 11125SELECT a.TransactionID, Tab."Previews TransactionID" a.ProductID FROM TestTransactionHistory aOUTER APPLY (SELECT TOP 1 b.TransactionID AS "Previews TransactionID" FROM TestTransactionHistory b WHERE b.ProductID = a.ProductID AND b.TransactionID < a.TransactionID ORDER BY b.TransactionID DESC) AS TabWHERE a.ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)ORDER BY a.ProductID, a.TransactionIDGO
The results from SQLQueryStress:
Now using the LAG function:
-- Using LAG function-- Test running 50 threads, 5 iterations per session-- AVG Elapsed time: 00:00:00.8690-- AVG Logical Reads: 9SELECT TransactionID, LAG(TransactionID) OVER(ORDER BY ProductID, TransactionID) AS "Previews TransactionID" ProductID FROM TestTransactionHistoryWHERE ProductID = ROUND(((999 - 930 -1) * RAND() + 930), 0)ORDER BY ProductID, TransactionID
The results from SQLQueryStress:

Once again, the performance on windowing functions is much better.
QueryClientSeconds/Iteration(Avg)
CPUSeconds/Iteration(Avg)
ActualSeconds/Iteration(Avg)
LogicalReads/Iteration (Avg)
Subquery solution 2,9293 0,4106 1,9069 11001,4880Lag Windowfunction 0.0193 0,0062 0,0117 8,2160
Note: The LEAD and LAG functions doesn’t accept a frame, in this case the default of window spool is to use the in memory worktable.
First_Value and Last_ValueLet’s suppose I want to return all the employees from a specific department. I also want to know which employee had the largest number of hoursnot working because he/she was sick and who that employee was.
To write it without window functions, I could use subqueries to return the data of most hours sick and who was the employee; something like thefollowing query:
-- Old Solution-- Test running 200 threads, 100 iterations per session-- AVG Elapsed time: 00:00:14.7488-- AVG Logical Reads: 391DECLARE @i INT = ROUND(((16 - 1 -1) * RAND() + 1), 0);WITH CTE_1AS( SELECT Person.FirstName + ' ' + Person.LastName AS EmployeeName, Employee.JobTitle, Employee.SickLeaveHours, Employee.HireDate, Department.Name AS DepartmentName FROM HumanResources.Employee INNER JOIN HumanResources.EmployeeDepartmentHistory ON Employee.BusinessEntityID = EmployeeDepartmentHistory.BusinessEntityID INNER JOIN HumanResources.Department ON EmployeeDepartmentHistory.DepartmentID = Department.DepartmentID INNER JOIN Person.Person ON Employee.BusinessEntityID = Person.BusinessEntityID WHERE EmployeeDepartmentHistory.EndDate IS NULL AND Department.DepartmentID = @i)SELECT a.*, (SELECT TOP 1 b.SickLeaveHours FROM CTE_1 b

WHERE a.DepartmentName = b.DepartmentName ORDER BY b.SickLeaveHours DESC) AS MostSickEmployee, (SELECT TOP 1 c.EmployeeName FROM CTE_1 c WHERE a.DepartmentName = c.DepartmentName ORDER BY c.SickLeaveHours DESC, c.HireDate DESC) AS MostSickEmployeeName FROM CTE_1 aORDER BY a.DepartmentName, a.EmployeeNameGO
This is the result:
The employee that had the most time off-sick was “Brian LaMee”. I had to use a CTE to make the query a little easier to understand, and I wrote twosubqueries on this CTE.
Let’s see the performance:
Now how it would be with window functions?
When you first try the functions FIRST_VALUE and LAST_VALUE, it may seem confusing and you might wonder if the functions MAX and MINwouldn’t return the same values of FIRST_VALUE and LAST_VALUE, let’s see an example.
-- New Solution-- Test running 200 threads, 100 iterations per session-- AVG Elapsed time: 00:00:11.9196-- AVG Logical Reads: 189SELECT Person.FirstName + ' ' + Person.LastName AS EmployeeName, Employee.JobTitle, Employee.SickLeaveHours, Employee.HireDate, Department.Name AS DepartmentName, MAX(Employee.SickLeaveHours) OVER(PARTITION BY Department.Name ORDER BYEmployee.SickLeaveHours ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) ASMostSickEmployee, LAST_VALUE(Person.FirstName + ' ' + Person.LastName) OVER(PARTITION BY Department.NameORDER BY Employee.SickLeaveHours, Employee.HireDate ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDEDFOLLOWING) AS MostSickEmployeeName FROM HumanResources.EmployeeINNER JOIN HumanResources.EmployeeDepartmentHistory ON Employee.BusinessEntityID = EmployeeDepartmentHistory.BusinessEntityID

INNER JOIN HumanResources.Department ON EmployeeDepartmentHistory.DepartmentID = Department.DepartmentIDINNER JOIN Person.Person ON Employee.BusinessEntityID = Person.BusinessEntityIDWHERE EmployeeDepartmentHistory.EndDate IS NULL AND Department.DepartmentID = ROUND(((16 - 1 -1) * RAND() + 1), 0)ORDER BY Department.Name, Person.FirstName + ' ' + Person.LastName
And the results:
The same results were returned, and the in fact the function MAX can be used to return the LAST_VALUE of the value in a partition, in this case thepartition is the department, so the MAX of a window partitioned by department with a frame that goes from UNBOUNDED PRECEDING ANDUNBOUNDED FOLLOWING will return the last value based on the ORDER BY of the column specified in the MAX function.
The LAST_VALUE function will return the last value based on the ORDER BY clause specified in the OVER clause. If you didn’t understand, then tryto change the LAST_VALUE for the MAX and see that the results will not be the ones you might expect.
Now let’s see the performance:
This time we can’t see a big difference between the queries, but that’s probably because the tables I used are very small.
QueryClientSeconds/Iteration(Avg)
CPUSeconds/Iteration(Avg)
ActualSeconds/Iteration(Avg)
LogicalReads/Iteration (Avg)
CTE solution 0,0268 0,0017 0,0029 411,3282Window function 0,0253 0,0011 0,0024 209,5995
Note: The performance will vary in your SQL Server environment since the codes are all random.
ConclusionIn general the window functions will perform better than the old solutions using subqueries that we are used to writing.
I recommend you to always test both solutions the old and the new using the window function, if the new solution is not performing better than the oldone you should always check whether the window spool operator is working with the worktable on-disk.
That’s all folks.

© Simple-Talk.com
Inside the Concurrent CollectionsPublished Thursday, January 05, 2012 2:41 PM
The concurrent collections, located in the System.Collections.Concurrent namespace, were introduced in .NET 4 as thread-safe collections thatcould be used without locking, and there are plenty of posts and articles out on the interwebs giving an overview of the collections and how to usethem.
Instead, I'll be focusing these posts on how the concurrent collections are implemented; how they achieve thread-safety and the principles behindtheir implementation. Not only because I find that sort of thing quite interesting, but also to give you ideas about how you might use these principlesin your own code.
Note however, that writing bulletproof thread-safe collections is hard. Really hard. Think carefully about somehow using one of the existingcollections before trying to write or adapt your own.
What is a 'thread-safe' collection?
First of all, we need to understand what we mean by 'thread-safe'. Well, let's start with the repository of all human knowledge - wikipedia:
A piece of code is thread-safe if it only manipulates shared data structures in a manner that guarantees safe execution bymultiple threads at the same time
OK, well, as an example, if m_Collection is some sort of 'thread-safe' ICollection, what will the result of these two threads running concurrentlydo?
Thread 1 Thread 2
m_Collection.Add(m_Item); bool removed = m_Collection.Remove(m_Item);
The answer depends on exactly which order Thread 1 and Thread 2 run with respect to each other. So, whether m_Item is in m_Collection afterthese two threads have run depends entirely on the whim of the operating system. Thread 2 could try and remove an item that's not in the collection,setting removed to false, then Thread 1 adds the item to the collection. Or Thread 1 could run first, adding the item, which is then immediatelyremoved by Thread 2, setting removed to true. Thread 1 could then merrily carry on executing, assuming m_Item is in m_Collection, not knowing it'sbeen immediately removed by Thread 2.
That, however, is an implementation detail of whoever wrote the code for Thread 1 and Thread 2. The important thing is that, after these two threadshave run the above code in some order, m_Collection will either have the item in it, or not; it won't be in some corrupted half-state where someinternal datastructures think it has the item and some don't, so that (for example) m_Collection.Contains(m_Item) returns false but the enumeratorstill returns the item. So, I propose that this is what is meant by a thread-safe collection:
A thread-safe collection is one that can be modified by multiple threads at the same time without corrupting itself.
Achieving concurrency
There is a very simple way of writing a thread-safe collection - implement ICollection<T> by wrapping a List<T> that locks the backing list objecton every method call (if you're unclear about what locks are, I'll be covering them below). This means that only one thread can access and modifythe backing list at once; thread-safety is therefore maintained. However, this isn't a very good solution; many threads could be blocked by onecostly list resize operation. This solution doesn't have very good concurrency.
Ideally, we want collections that don't keep threads waiting. As we'll see, two of the collections (ConcurrentStack and ConcurrentQueue) achievethread-safety using no locks at all, and the other collections minimise the chances of two threads blocking on the same lock.
Locking and synchronization primitives
You can't just create a lockless thread-safe datastructure out of nowhere, you need some underlying support from the hardware, operating systemand runtime to achieve this. Before we look at the collections themselves, we need to understand these primitives and what guarantees theyprovide.
1. Atomic types
Some types in .NET are specified as being 'atomic'. That is, if you change the value of a variable of an atomic type, it is guaranteed toappear to change value instantaneously; another thread won't be able to see the variable 'half-changed'. Object references andprimitive types of 4 bytes or shorter are always atomic (ints, chars, booleans, floats etc), but 8-byte primitives are only atomic whenrunning on a 64-bit process. The atomicity of object references is especially important to lockless collections, as we'll see in later posts.
2. Volatile variables

I discussed volatility in a previous post. To recap, marking a variable as volatile means that:
The JIT compiler won't cache the variable in a cpu register; it will always read and write to it using the original memory location.This is important when multiple threads are changing a variable at the same time, so that any changes made to the variable in onethread are immediately picked up by other threads.A read or write to a volatile location introduces a memory barrier at that point, so that other reads and writes won't be reorderedwith respect to each other. This is important later on, as we'll see.
3. Locks
Mutual-exclusion locks are one of the more basic synchronization primitives. Each object has a lock associated with it, and by lockingon an object you only allow one thread to have 'ownership' of that lock at a time. This allows only one thread to execute the section ofcode protected by that lock at a time.
When the currently executing thread 'releases' the lock, another thread (and only one other thread) is then allowed to take control of thelock and execute the protected code. Any other threads waiting to take the lock are blocked and cannot continue executing until it istheir turn to take the lock.
C# has special syntax for locking on an object:
private readonly object m_LockObj = new object();public void SynchronizedMethod() { lock (m_LockObj) { // protected code }}
C# actually compiles this method to something like this:
public void SynchronizedMethod() { bool lockTaken = false; object lockObj = m_LockObj; try { System.Threading.Monitor.Enter(lockObj, ref lockTaken); // protected code } finally { if (lockTaken) System.Threading.Monitor.Exit(lockObj); }}
This uses the System.Threading.Monitor class to implement the lock. The call to Monitor.Enter blocks the thread until it can takecontrol of the lock, and the lock is released by Monitor.Exit.
4. System.Threading.Interlocked
Interlocked provides various methods for performing operations that wouldn't normally be atomic in an atomic fashion. For example,Interlocked.Read allows an 8-byte long to be read as an atomic operation (remember, 8-byte primitives are only atomic on 64-bitprocesses), Interlocked.Add allows you to perform a = a + b (aka a+=b) atomically, Interlocked.Decrement performs a = a - 1(aka --a) atomically, etc.
The most important of these is Interlocked.CompareExchange. This family of methods performs the following operation atomically(using the generic overload as an example):
public static T CompareExchange<T>(ref T location, T value, T comparand) where T : class { T originalValue = location; if (location == comparand) location = value; return originalValue;}
This might not seem like a particularly useful atomic operation, but it is crucial to the lockless collections, as we'll see.
5. System.Threading.SpinWait
Introduced in .NET 4, this structure encapsulates the idea of a 'spinwait':
while (!variableThatShouldBeTrueToContinue) {}
This keeps the thread continually spinning round the while loop, repeatedly checking whether another thread has setvariableThatShouldBeTrueToContinue to true. However, performing such a spinwait gives no guarantees that the thread that is meantto set variableThatShouldBeTrueToContinue will be given the chance to execute; the operating system could, if it wishes, simply keepon executing the spinwait and not switch to other threads that actually change this variable.
System.Threading.SpinWait gets round this problem by, as well as simply spinning, occasionally calling Thread.Sleep andThread.Yield. This will respectively encourage and force the operating system to execute other threads, giving a chance for thespinning condition to be satisfied.
Using the concurrent collections
At this point it's also worth pointing out that using a thread-safe collection will not make the rest of your code thread-safe and free of raceconditions; it is not a panacea. As in the example at the top of this post, using a thread-safe collection does not stop a race condition betweenadding and removing the same item from the collection. Using a thread-safe collection simply means you have one less thing to worry about whenwriting threaded code. You still have the rest of your code to worry about!
That's it for introductions; in the next post, we'll look at the simplest of the concurrent collections, ConcurrentStack.
by Simon CooperFiled Under: Inside the Concurrent Collections

N
A SQL howler monkey
Tom LaRock's SQL Server Howlers05 January 2012by Thomas LaRock
In this next article in our series where well-known SQL Server people write about their favorite SQL Server Howlers, we asked TomLarock for his top five common misunderstandings about how SQL Server works that end in tears, and plaintive forum questions.
You need to fix the database server, because we're getting a lot of deadlocks.o: We need to fix the application or alter the database schema, but not the database server itself. There's no button for me to press that will stopdeadlocks from happening. They happen as a result of application code, database design, and user activity. The database engine does not
suddenly seize up and start deadlocking transactions arbitrarily because it is tired one day. No, certain conditions must exist in order for adeadlock to happen, and all of those conditions require someone, somewhere, to be using the database.
Deadlocking is not equivalent to blocking. Deadlocks do involve blocking, but that does not meanthe terms are interchangeable. While blocking and locking are normal database operations that arenecessary for transaction to be atomic, consistent, independent, and durable (ACID), a deadlock isa very special case where circular blocking has occurred so the processes are blocked by eachother and are therefore set to wait pointlessly and eternally. SQL Server has a background processcalled the 'Deadlock Monitor' that does nothing other than to look for deadlocks. Once detected, theDeadlock Monitor chooses one of the sessions as a victim (the one with the least estimated cost torollback) so that the other session(s) can continue with their processing.
So how do you avoid deadlocks? Well, you really can't, but you can minimize the chances of themhappening. The first thing you must do is to identify those queries and objects that are involved in thedeadlock, which you can do by following the details here: Detecting and Ending Deadlocks. I preferusing just trace flag 1222, but some people like to use 1204 as well.
Once you know the queries and objects involved in the deadlock you can go about taking steps toreduce their impact and/or minimize them from happening altogether. Here's a few things that I liketo recommend, in no particular order:
1. Retry the transaction. If your sessions gets an error returned (number 1205, to be exact),then you should trap for the error and simply retry the transaction. You can use theTRY/CATCH syntax to trap for errors.
2. Keep your transactions short. I've never met anyone that deliberately codes for theirtransactions to be long, but for whatever reason they just seem to end up that way. This isoften a result of an increase in data over time, or the need for updated statistics, orimproper indexing that leads to deteriorated performance. Stay on top of your maintenance and you can stay on top of the vigil of keepingyour transactions short.
3. Use the READ COMMITTED SNAPSHOT isolation level. This level uses fewer locks and can therefore reduce the chance of deadlocks.4. Access your database objects in the same order. This is likely not something that is a part of any code review, but should be. It is quite
possible that there could be a need for the same two tables to be updated by two different processes. And it is also possible that thepeople building the code for those updates perform them in a different order. If both sections of code update the tables in the same order,then it is unlikely a deadlock will be the result.
Next time someone comes running over to tell you that there is a "problem with the database server" because of deadlocks, do your best toeducate them as to what really causes deadlocks, and what work needs to be done in order to minimize them.
Testing against 10, 100, and then 1000 rows is most likely not an accurate test of aproduction workload.I've seen this many times in my career. A developer spends months building code. With each iteration they push a button and get back results. Thisseems to make them sufficiently happy with what they have built; they are happy with the results, and they are ready to deploy to production. Andabout five minutes after their code is deployed everything comes to a grinding halt. And then they do the logical thing: they blame the database.
After a few minutes of troubleshooting and listening to the developer insist about how "everything ran fine against the test server", any decent DBAis going to think of the following:
1. The test database (and server) is likely not an exact copy of production (i.e., different data, different hardware)2. The test database (and server) is likely not an exact copy of the production workload (i.e., different number of concurrent sessions)

Frank:Me:Frank:Me:Frank:
Me:
3. The developer never tested the test database (and server) to match the production data and workload (assuming they are aware that testdidn't match production, of course).
I could never quite figure out how I could have a person debate with me on a Monday regarding how the test servers didn't match the productionone, and then when their production deployment fails they immediately blame the server, the data, or worse yet, me! If they knew that the serverswere different, why not take steps to stage a test against a simulated workload?
Bottom line: if you want to know how your code will hold up against a production workload, you need to run it against something close to aproduction workload. If production has a forty million row table and the test database only has forty row table, you can bet your test will not be all thataccurate. And if you start blaming the DBA and database server when the real issue is proper testing, then you can bet you won't be winning anyfriends, either.
Table variables are in memory only.No, they are not "in memory only". At first I thought that was the case as well, but my mentor (Frank) led me through a thought experiment that wentlike this:
"Think Tom, just stop and think about it...how much memory is on that server?""Eight gigabytes.""OK, let's go create a table variable and shove sixteen gigabytes of data into it, we can do that, right?""Um...I don't know.""Of course we can do it, because the table variable isn't storing the data in memory, it is storing it on disk, just like aregular temp table is stored.""Um, yeah...OK then."
The data for table variables are not stored in memory. That makes no sense, really, because you could chew through all of your server memory in avery short amount of time, leaving nothing for the server itself. The data has to spill to disk, and it does, by going right into the tempdb database.
And yet I still see people making the mistake of thinking that table variables are in memory objects only, despite having people (UnderstandingTempDB, table variables v. temp tables and Improving throughput for TempDB ) tell them again (TempDB:: Table variable vs local temporary table ),and again (SQL SERVER – Difference TempTable and Table Variable – TempTable in Memory a Myth)
So, to recap:
1. Table variables do not reside in memory only2. Table variables are not always better than using temporary tables3. Always restrain from using the word "always" when talking about database performance
Now that you know a little bit more about table variables, it should help you make an informed decision with some of your T-SQL coding options.
Please restore that stored procedure from yesterday.This question is almost always followed by another question: "Aren't you using some type of source control for your code?" Sadly the answer iseither "no" or "something happened". So why is this an issue? It is because SQL Server doesn't make any distinction about database objects whendoing a backup. The backup is just a dump of everything, there is no such thing as a "logical dump" native to SQL Server.
In order to restore a stored procedure from a database backup you need to perform a full restore of the database and then extract the storedprocedure. For small databases this is really not as much of an issue as it can be just a laborious process. But what if you have a database that isterabytes in size? Now you don't just have a pain in the neck, but you likely also have an issue of where you can restore that large database in orderto extract something so tiny...like pulling a needle from a haystack.
The easy solution to all of this is to be using source control. At this point in software development it is almost criminal to not be using something tohelp track your code and revisions. If you do have to restore a database in order to get an object (or two) then you are doing it wrong.
I've also seen requests come in to restore a particular table from a backup. This can be problematic when foreign keys are involved as you willneed to recover more than just the one table. I am always wary of recovering just one table because it always seems to lead to more work thananyone expects. I even had a developer tell me that they didn't need the entire database (200GB in size) restored, they just needed one table(which was 196GB in size), as if that was supposed to make things easier! (Their manager sure seemed to think they were doing us a favor by onlyasking for the one table).
Database backups are meant to recover the entire database to a point in time. They were not designed to recover just parts.
Using 'SELECT *' as your production process.If I could go back in time and find the person who built every beginning training manual with this example I would kick them in the junk.
Relying on this statement is a very bad idea. Why? Because things change. That's what things do, they change. All the time. Let's look at an

‘Hmmm.. Looks like there is moreto SQL Programming than havingopposable thumbs'
example.
There is a table in a database, say with 100 columns. You decide that you want to take a copy of a subset of that data (say, the orders for theprevious day only) and insert it into a different table. You don't want to write out all 100 column names, so you decide to use SELECT * because,well, it works, right?
Now, some point later in time, someone (let's call them a 'manager') decides that the original tableneeds more columns. Guess what will happen to your insert statement the next time it tries to run? It fails,that's what happens. You are expecting 100 columns and you get back more. Your process failsbecause a change was made upstream and you had no idea, and your code was not dynamic enough toadjust for the change.
Other issues with SELECT * include the extra network bandwidth you consume by draggingunnecessary data back and forth across the wire. You should only ever move the data that is necessary,not grab everything just because you can. All the extra I/O drains network resources, increases memoryconsumption, and disk activity. If you have systems that are relying heavily on the use of SELECT * youcan see in increase in overall performance just by taking steps to use explicit column names, which is avery simple step to take.
© Simple-Talk.com
Using XML to pass lists as parameters in SQL ServerPublished Thursday, January 05, 2012 2:32 AM
Every so often, the question comes up on forums of how to pass a list as a parameter to a SQL procedure or function. There was a time that I usedto love this question because one could spread so much happiness and gratitude by showing how to parse a comma-delimited list into a table. JeffModen has probably won the laurels for the ultimate list-parsing TSQL function, the amazing ‘DelimitedSplit8K’. Erland Sommarskog haspermanently nailed the topic with a very complete coverage of the various methods for using lists in SQL Server on his website.. With Table-Valuedparameters, of course, the necessity for having any lists in SQL Server is enormously reduced, though it still crops up.
XML seems, on the surface, to provide a built-in way of handling lists as parameters. No need for all those ancillary functions for splitting lists intotables, one might think. I’m not so sure that one can, in all conscience, give advice to use XML without qualification. It is fine for short lists, andI've never used the technique for anything else, but lists have a habit of not staying short as applications develop and other hands take over whoaren't aware of potential problems of abusing the common idea of a list. Let’s just take the very simplest example of taking a list of integersand turning it into a table of integers. One can a simple XML list based on a fragment like this… DECLARE @XMLlist XML SELECT @XMLList = '<list><i>2</i><i>4</i><i>6</i><i>8</i><i>10</i><i>15</i><i>17</i><i>21</i></list>'
…to give a table like this ..
IDs-----------246810151721 (8 row(s) affected)
..by using this TSQL expression
SELECT x.y.value('.','int') AS IDs FROM @XMLList.nodes('/list/i') AS x ( y )
It isn’t as intuitive as a simple comma-delimited list to be sure, but it is bearable. In small doses, this shredding of XML lists works fine, but onesoon notices the sigh from the server as the length of the list starts to increases into four figures. Try it on a list of a hundred thousand integers andyou’ll have time to eat a sandwich.
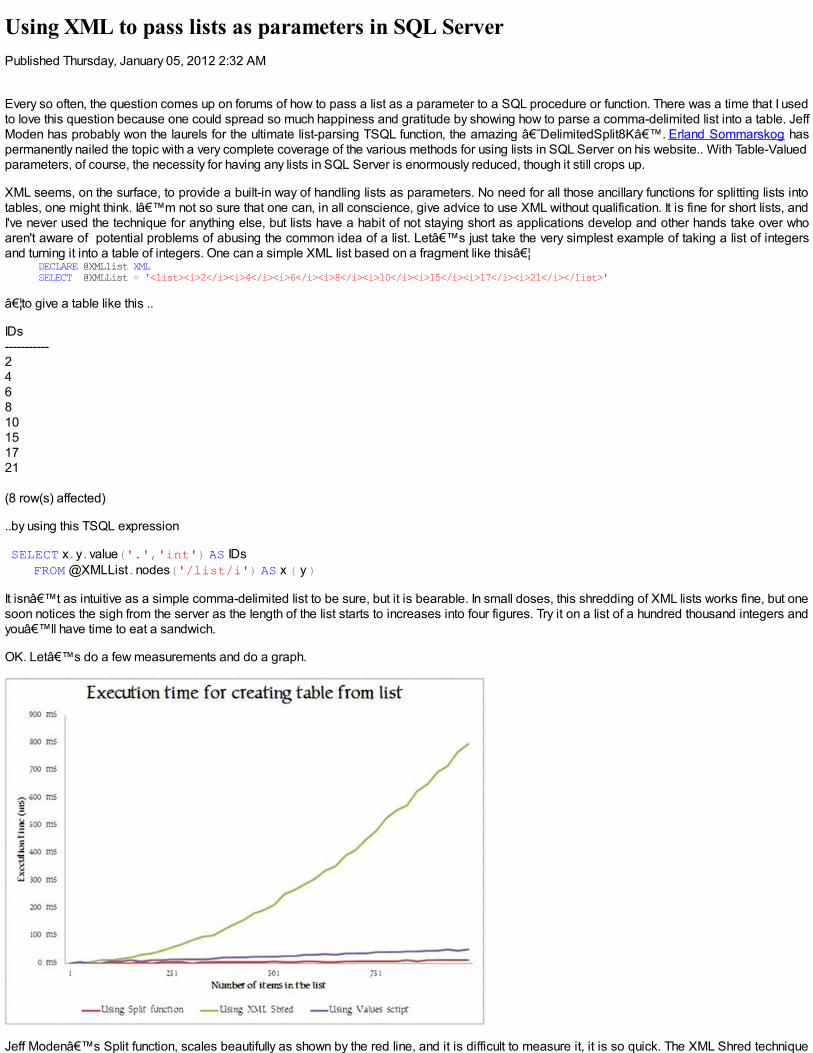
OK. Let’s do a few measurements and do a graph.
Jeff Moden’s Split function, scales beautifully as shown by the red line, and it is difficult to measure it, it is so quick. The XML Shred technique
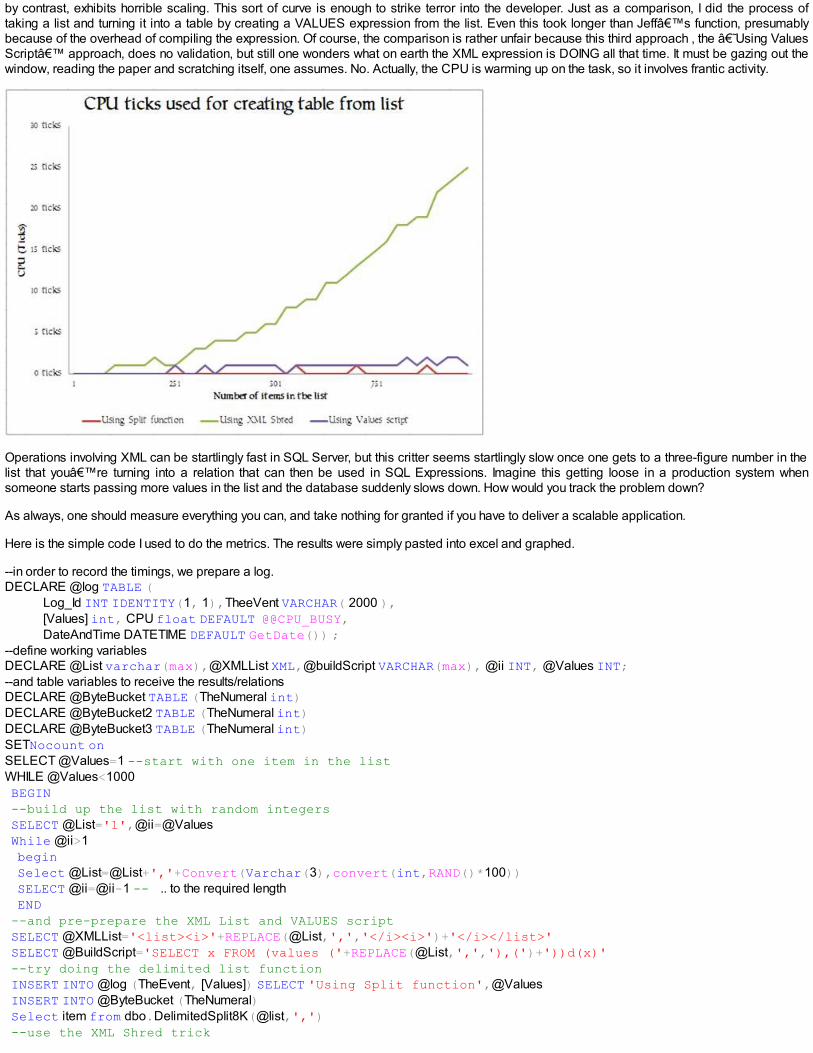
by contrast, exhibits horrible scaling. This sort of curve is enough to strike terror into the developer. Just as a comparison, I did the process oftaking a list and turning it into a table by creating a VALUES expression from the list. Even this took longer than Jeff’s function, presumablybecause of the overhead of compiling the expression. Of course, the comparison is rather unfair because this third approach , the ‘Using ValuesScript’ approach, does no validation, but still one wonders what on earth the XML expression is DOING all that time. It must be gazing out thewindow, reading the paper and scratching itself, one assumes. No. Actually, the CPU is warming up on the task, so it involves frantic activity.
Operations involving XML can be startlingly fast in SQL Server, but this critter seems startlingly slow once one gets to a three-figure number in thelist that you’re turning into a relation that can then be used in SQL Expressions. Imagine this getting loose in a production system whensomeone starts passing more values in the list and the database suddenly slows down. How would you track the problem down?
As always, one should measure everything you can, and take nothing for granted if you have to deliver a scalable application.
Here is the simple code I used to do the metrics. The results were simply pasted into excel and graphed.
--in order to record the timings, we prepare a log.DECLARE @log TABLE ( Log_Id INT IDENTITY(1, 1),TheeVent VARCHAR( 2000 ), [Values] int, CPU float DEFAULT @@CPU_BUSY, DateAndTime DATETIME DEFAULT GetDate()) ;--define working variablesDECLARE @List varchar(max),@XMLList XML,@buildScript VARCHAR(max), @ii INT, @Values INT;--and table variables to receive the results/relationsDECLARE @ByteBucket TABLE (TheNumeral int)DECLARE @ByteBucket2 TABLE (TheNumeral int)DECLARE @ByteBucket3 TABLE (TheNumeral int)SETNocount onSELECT @Values=1 --start with one item in the listWHILE @Values<1000 BEGIN --build up the list with random integers SELECT @List='1',@ii=@Values While @ii>1 begin Select @List=@List+','+Convert(Varchar(3),convert(int,RAND()*100)) SELECT @ii=@ii-1 -- .. to the required length END --and pre-prepare the XML List and VALUES script SELECT @XMLList='<list><i>'+REPLACE(@List,',','</i><i>')+'</i></list>' SELECT @BuildScript='SELECT x FROM (values ('+REPLACE(@List,',','),(')+'))d(x)' --try doing the delimited list function INSERT INTO @log (TheEvent, [Values]) SELECT 'Using Split function',@Values INSERT INTO @ByteBucket (TheNumeral) Select item from dbo.DelimitedSplit8K(@list,',') --use the XML Shred trick

INSERT INTO @log (TheEvent, [Values]) SELECT 'Using XML Shred',@Values INSERT INTO @ByteBucket2 (TheNumeral) SELECT x.y.value('.','int') AS IDs FROM @XMLList.nodes('/list/i') AS x ( y ) --try the VALUES method INSERT INTO @log (TheEvent, [Values]) SELECT 'Using Values script',@Values INSERT INTO @ByteBucket3 (TheNumeral) EXECUTE (@BuildScript) INSERT INTO @log (TheEvent, [Values]) SELECT 'finished',@Values SELECT @Values=@Values+25end SELECT TheStart.[Values], MAX(CASE WHEN TheStart.TheeVent ='Using Split function' THEN DatedIff( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Using Split function], MAX(CASE WHEN TheStart.TheeVent ='Using XML Shred' THEN DatedIff( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Using XML Shred], MAX(CASE WHEN TheStart.TheeVent ='Using Values script' THEN DatedIff( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Using Values script]FROM @log TheStart INNER JOIN @log Theend ON Theend.Log_Id = TheStart.Log_Id + 1WHERE TheStart.TheEvent<>'finished'GROUPBY TheStart.[Values]; SELECT TheStart.[Values], MAX(CASE WHEN TheStart.TheeVent ='Using Split function' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Using Split function], MAX(CASE WHEN TheStart.TheeVent ='Using XML Shred' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Using XML Shred], MAX(CASE WHEN TheStart.TheeVent ='Using Values script' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Using Values script]FROM @log TheStart INNER JOIN @log Theend ON Theend.Log_Id = TheStart.Log_Id + 1WHERE TheStart.TheEvent<>'finished'GROUPBY TheStart.[Values];
by Phil Factor

I
Incorporating XML into your Database Objects04 January 2012by Robert Sheldon
XML data can become a full participant in a SQL Server Database, and can be used in views, functions, check constraints,computed columns and defaults. Views and table-valued functions can be used to provide a tabular view of XML data that can beused in SQL Expressions. Robert Sheldon explains how.
n my last two articles, “Working with the XML Data Type in SQL Server ” and “The XML Methods in SQL Server ,” I discussed how to use the XMLdata type and its methods to store and access XML data. This article takes these topics a step further and explains ways in which you can
implement XML within various database objects, including views, functions, computed columns, check constraints, and defaults. If you’re notfamiliar with how the XML data type and its methods are implemented in SQL Server, you should review the first two articles before starting in onthis one. Once you have the basic information, you’ll find that incorporating XML within these other database objects is a relatively straightforwardprocess.
Creating ViewsWhen you create a view, you can include an XML column just like you would a column configured with another data type. For example, theSales.Store table in the AdventureWorks2008R2 sample database includes the Demographics column, which is configured with theXML type. For each row in the table, the column stores an XML document that contains details about the store described in that row of data.
In the following example, I create a view that retrieves data from the Sales.Store table, including the Demographics column:
USE AdventureWorks2008R2;
IF OBJECT_ID('StoreSurvey') IS NOT NULLDROP VIEW StoreSurvey;GO
CREATE VIEW StoreSurveyAS SELECT BusinessEntityID AS StoreID, Demographics AS Survey FROM Sales.Store;GO
SELECT SurveyFROM StoreSurveyWHERE StoreID = 292;
There should be no surprises here. I simply specified the name of the XML column as I would other columns and assigned the alias Survey to thecolumn name. The SELECT statement I tagged onto the view definition returns the following results:
<StoreSurvey xmlns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey" <AnnualSales>800000</AnnualSales> <AnnualRevenue>80000</AnnualRevenue> <BankName>United Security</BankName> <BusinessType>BM</BusinessType> <YearOpened>1996</YearOpened> <Specialty>Mountain</Specialty> <SquareFeet>21000</SquareFeet> <Brands>2</Brands> <Internet>ISDN</Internet> <NumberEmployees>13</NumberEmployees></StoreSurvey>
The SELECT statement returns the full XML document, as it’s stored in the Demographics column (for the row with a StoreID value of 292).Although this all fine enough, it’s not particularly noteworthy. Where things get interesting is when you use an XML method within a view to retrieveonly part of the XML data. For example, in the following view definition, I use the value() method to retrieve a single value from the XML

document in the Demographics column:
USE AdventureWorks2008R2;
IF OBJECT_ID('StoreSales') IS NOT NULLDROP VIEW StoreSales;GO
CREATE VIEW StoreSalesAS SELECT BusinessEntityID AS StoreID, Demographics.value('declare namespace ns= "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"; (/ns:StoreSurvey/ns:AnnualSales)[1]', 'int') AS AnnualSales FROM Sales.Store;GO
SELECT AnnualSalesFROM StoreSalesWHERE StoreID = 292;
The value() method retrieves the value stored in the <AnnualSales> child element of the <StoreSurvey> element. Because theDemographics column is a typed XML column, the value() method’s first argument includes the namespace reference, along with a referenceto the actual element. And the method’s second argument specifies that the value be returned as type int. The SELECT statement I’ve taggedonto the view definition now returns only a single value, 800000.
Because XQuery expressions can get somewhat complex, particularly when they include the namespace reference, views provide a handy way ofstoring those expressions in your database. For instance, if you want to retrieve annual sales information regularly, a view such as the one abovecan make the process quite easy.
Creating FunctionsAs is the case with views, you can also work with XML data within functions. For example, in the following function definition, I return the contents ofthe Demographics column based on an inputted store ID value (which is equivalent to the table’s BusinessEntityID value):
USE AdventureWorks2008R2;
IF OBJECT_ID('Survey') IS NOT NULLDROP FUNCTION Survey;GO
CREATE FUNCTION Survey(@StoreID INT)RETURNS XMLAS BEGINRETURN( SELECT Demographics FROM Sales.Store WHERE BusinessEntityID = @StoreID)END;GO
SELECT dbo.Survey(292);
Once again, no surprises here. When I call the function and store ID (292) in a SELECT statement, the function returns the full XML document fromthe Demographics column for that store. However, notice that I specified XML as the return type. Because XML is being returned, you can evenuse the XML methods when you call the function. For instance, in the following example, I again call the Survey function, passing in the store ID(292), but this time I also include the value() method:
SELECT dbo.Survey(292).value('declare namespace ns= "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"; (/ns:StoreSurvey/ns:AnnualSales)[1]', 'int');

Notice that I simply add the period and method name when I call the function, followed by the necessary arguments. As you would expect, thefunction now returns only a single value, in this case, 800000.
I could have just as easily specified the query() method, as in the following example:
SELECT dbo.Survey(292).query('declare namespace ns= "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"; /ns:StoreSurvey/ns:AnnualSales');
Now the SELECT statement returns the entire <AnnualSales> element, along with the namespace information, as shown in the following results:
<ns:AnnualSales xmlns:ns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey">800000</ns:AnnualSales>
So far, working with XML data within a function has been pretty straightforward, but suppose you don’t want to retrieve the entire XML document.You can instead use XML methods within the function to return specific information from the document. In the following example, I create a functionthat returns only the value from the <AnnualSales> child element, just like I did earlier in my view definition:
USE AdventureWorks2008R2;
IF OBJECT_ID('AnnualSales') IS NOT NULLDROP FUNCTION AnnualSales;GO
CREATE FUNCTION AnnualSales(@survey XML)RETURNS INTAS BEGINRETURN @survey.value('declare namespace ns= "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"; (/ns:StoreSurvey/ns:AnnualSales)[1]', 'int')END;GO
SELECT dbo.AnnualSales(Demographics) AS AnnualSalesFROM Sales.StoreWHERE BusinessEntityID = 292;
There are a couple things worth noting about this function definition. First, unlike the preceding example, I specified INT as the return type (ratherthan XML) because INT is the value type returned by the value() method. In addition, I specified XML as the type for the input parameter(@survey). I then used that parameter to call the value() method. That way, I can pass in the column name as the argument to the function, andthe value() method will return the specific value from the XML document in the column.
To verify this, I created a SELECT statement that calls the function and passes in the Demographics column as its input argument. Now thefunction returns a value of 800000, without having to specify an XML method when calling the function itself, as in the preceding example.
Being able to use XQuery expressions within functions provides the same advantages as being able to use them in views. You can save complexexpressions to the database that you can call as often as necessary, without having to reconstruct those expressions each time you need them.
Creating Computed ColumnsThere might be times when you want to use XML data to construct a computed column. One simple way to do that is to convert an entire XML valueto a string, as I do in the following example:
USE AdventureWorks2008R2;
IF OBJECT_ID('Stores') IS NOT NULLDROP TABLE Stores;GO
CREATE TABLE Stores( StoreID INT PRIMARY KEY, SurveyXml XML, SurveyChar AS CAST(SurveyXml AS NVARCHAR(MAX))

);GO
INSERT INTO Stores(StoreID, SurveyXml)SELECT BusinessEntityID, DemographicsFROM Sales.Store;
SELECT * FROM StoresWHERE StoreID = 292;
First, I create the Stores table, which includes one XML column and one calculated column. The calculated column is simply a recasting of theXML column to an NVARCHAR(MAX) column. Notice in the INSERT statement, I retrieve data from the Sales.Store column, including theDemographics column. The Demographics data is converted to NVARCHAR(MAX) when inserted into the SURVEYCHAR column. As youwould expect, the SELECT statement returns the full XML document for the SurveyXml column and returns the same document as character datafor the SurveyChar column.
This is all well and good if all you want to do is play around with the entire XML document. But suppose instead you want to create a calculatedcolumn based on only a portion of that document. That’s where things get a bit sticky.
It turns out that you can’t use XML methods to define a calculated column. However, there is a work-around. You can define a function that retrievesthe data you need and then use that function within the column definition, as I do in the following example:
USE AdventureWorks2008R2;
IF OBJECT_ID('Stores') IS NOT NULLDROP TABLE Stores;GO
IF OBJECT_ID('AnnualSales') IS NOT NULLDROP FUNCTION AnnualSales;GO
CREATE FUNCTION AnnualSales(@survey XML)RETURNS INTAS BEGINRETURN @survey.value('declare namespace ns= "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"; (/ns:StoreSurvey/ns:AnnualSales)[1]', 'int')END;GO
CREATE TABLE Stores( StoreID INT PRIMARY KEY, Survey XML, SalesAmount AS dbo.AnnualSales(Survey));GO
INSERT INTO Stores(StoreID, Survey)SELECT BusinessEntityID, DemographicsFROM Sales.Store;
SELECT * FROM StoresWHERE StoreID = 292;
First, I create a function (AnnualSales) that uses the value() method to retrieve the <AnnualSales> value from the inputted XMLdocument, as you saw in a previous example. I then create a table that includes an XML column (Survey) and a calculated column(SalesAmount). Within the SalesAmount column definition, I call the AnnualSales function and pass in the Survey column as its argument.Next, I populate the table with data from the Sales.Store table and then use a SELECT statement to retrieve a row from that table. As to beexpected, the Survey column returns the full XML document, and the SalesAmount column returns a value of 800000.
This is, of course, a roundabout way to use XML methods to create a calculated column, but it’s an effective approach nonetheless. The keyis making sure that the function targets the XML data that will provide the source for the calculated column. That means any schema and elementreferences must be consistent with the source data.

Creating Check ConstraintsAnother way you can work with XML in your database is to create check constraints on an XML column. However, chances are, if you decide to dothat, you’ll want to use one of the XML methods to create the constraint. The problem with this is that, like calculated columns, you can’t use thesemethods within the constraint definition. Once again, you must first create a function, as I’ve done in the following example:
USE AdventureWorks2008R2;
IF OBJECT_ID('Stores') IS NOT NULLDROP TABLE Stores;GO
IF OBJECT_ID('SpecialtyExists') IS NOT NULLDROP FUNCTION SpecialtyExists;GO
CREATE FUNCTION SpecialtyExists(@survey XML)RETURNS BITAS BEGINRETURN @survey.exist('declare namespace ns= "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"; /ns:StoreSurvey/ns:Specialty')END;GO
CREATE TABLE Stores( StoreID INT PRIMARY KEY, Survey XML CHECK(dbo.SpecialtyExists(Survey) = 1));GO
INSERT INTO Stores(StoreID, Survey)SELECT BusinessEntityID, DemographicsFROM Sales.Store;
SELECT * FROM StoresWHERE StoreID = 292;
In this case, the function (SpecialtyExists) uses the exist() method to determine whether the inputted XML document contains the<Specialty> child element within the <StoreSurvey> parent element. The EXIST() method will return 1 if the child element exists within theparent element and will return a 0 if the two elements don’t exist as specified. Consequently, the return type used for the function is BIT. As for theEXIST() method itself, it takes only one argument, the namespace reference and the parent and child elements.
After I defined the function, I created a table (Stores), which includes an XML column (Survey). I’ve also defined a check constraint on thecolumn. The constraint uses the SpecialtyExists function to determine if the data to be inserted into the Survey column contains thespecified child and parent elements. If the data contains the elements, the rows are inserted into the table; otherwise the insertion fails.
For instance, when I inserted the data from the Sales.Store table, the Demographics data was added to the store data because that dataincludes the required child and parent elements. However, if the function had specified a different child element, such as <MainType>, no rowswould have been inserted because the check constraint would have evaluated to False in each case.
As you saw with calculated columns, functions provide a workaround for using XML methods to create check constraints on XML columns. In theexample above, I used the EXIST() method to verify the existence of an element. However, I could have also used that method to check theexistence of an attribute, or I could have used another XML method, although the EXIST() method will probably prove to be the handiest one inthis case.
Creating DefaultsIf you create a table that includes an XML column, you can create a DEFAULT constraint on that column, as you would other column types. The maindifference with the XML column, however, is that if that column is typed XML, your constraint can’t violate the schema associated with that column.
You can create a DEFAULT constraint on an XML column in one of two ways: by implicitly converting the string value to XML or explicitly convertingthe value. In the following example, I use both approaches:

USE AdventureWorks2008R2;
IF OBJECT_ID('Stores') IS NOT NULLDROP TABLE Stores;GO
CREATE TABLE Stores( StoreID INT PRIMARY KEY, Survey_implicit1 XML DEFAULT '<Survey>Survey to follow</Survey>', Survey_implicit2 XML DEFAULT '<Survey>Survey to follow</Survey>', Survey_explicit1 XML DEFAULT CAST('<Survey>Survey to follow</Survey>' AS XML), Survey_explicit2 XML DEFAULT CAST('<Survey>Survey to follow</Survey>' AS XML));GO
INSERT INTO Stores (StoreID, Survey_implicit1, Survey_explicit1)SELECT BusinessEntityID, Demographics, DemographicsFROM Sales.Store;
SELECT * FROM StoresWHERE StoreID = 292;
Notice that I created four XML columns in the table. I did this to verify how the defaults work when I don’t add data to the columns. The first two XMLcolumns (Survey_implicit1 and Survey_implicit2) each include default definitions that specify an XML value as a string without trying toconvert that value to the XML type. For the third and fourth columns (Survey_explicit1 and Survey_explicit2), I specifically cast thecolumns to the XML type. Because SQL Server automatically converts the string values, you can take either approach.
After I defined the table, I inserted data into the Survey_implicit1 and Survey_explicit1 columns. I then retrieved a row from the table.As to be expected, the Survey_implicit1 and Survey_explicit1 columns returned the entire XML documents and theSurvey_implicit2 and Survey_explicit2 columns each returned the value defined in the DEFAULT constraint.
Working with XMLAs you saw with the DEFAULT constraints shown in the example above, you can convert non-XML data into XML. You can also convert XML datainto other types. In my next article, I’ll provide more specifics on how those conversions work. In the meantime, this article should have provided youwith the details you need to work with XML data when creating views, functions, computed columns, check constraints, and defaults. Of course, theXML methods, and the XQuery expressions you can create by using those methods, often play an important role in how you incorporate XML in yourdatabase objects, so knowing those methods and the XQuery language can be pivotal in effectively using that XML.
© Simple-Talk.com

Retrieving Passwords from Managed Accounts in SharePoint 2010 for C#Published Friday, January 06, 2012 9:17 AM
I was looking for a way to retrieve a password from a managed account when I ran into a post titled How to: Get Your Managed Account PasswordsWhen They are Changed Automatically by SharePoint 2010 by Jason Himmelstein. It was written for PowerShell and I needed in C#, so I figured Iwould post the converted code in case anyone was looking for the same thing. You will need to have the following using statements:
using System.Runtime.InteropServices;using Microsoft.SharePoint.Administration;Then you can use the following code to retrieve the managed password:
var managedAccounts = new SPFarmManagedAccountCollection(SPFarm.Local);foreach (SPManagedAccount managedAccount in managedAccounts){  var securePassword = (SPEncryptedString)managedAccount   .GetType()   .GetField("m_Password",      System.Reflection.BindingFlags.GetField |     System.Reflection.BindingFlags.Instance |     System.Reflection.BindingFlags.NonPublic)   .GetValue(managedAccount); var intptr = System.IntPtr.Zero; var unmanagedString = Marshal.   SecureStringToGlobalAllocUnicode(securePassword.SecureStringValue); var unsecureString = Marshal.PtrToStringUni(unmanagedString); Marshal.ZeroFreeGlobalAllocUnicode(unmanagedString);  //Do something with unsecureString}
One caveat to this is that you must be running as a Farm Administrator for the code to succeed. Otherwise you will get an error about accessingthe registry. It is also relying on reflection to retrieve a non-public internal field, so as my friend Jeff Burt was quick to point out, Microsoft couldchange it at any time and break this code. Probably not good for production code.
by DamonFiled Under: .NET Development, SharePoint

B
RM:
BS:
RM:
BS:
"It is easy for a programmerto outsmart himself (herself)"
The Marmite or Miracle Whip of Computer Languages03 January 2012by Richard Morris
What is it about C++ that makes it one of the most important computer languages for systems work, yet so reviled by so many? LikeMarmite, or Miracle Whip, nobody seems to take a neutral opinion of it. We asked the languages' creator, the great BjarneStroustrup.
jarne Strostrup's contribution to programming languages might as well be re-named C++ Marmite for all the grimaces that the language attracts.People either hate it with predictable snarls and loathing, or they affect not to like it very much, but use it nonetheless.
There are those who dislike it intensely. Linus Torvalds called it a horrible language, Don Knuth said it was too‘baroque' for him to use. There are, of course, the many who use it as the obvious choice for developingdemanding Windows system drivers and utilities. C++ is the main development language used by many ofGoogle's open-source projects and last year the company released a research paper which suggested that thelanguage is the best-performing programming language in the market after it had implemented a compactalgorithm in four languages – C++, Java, Scala and its own programming language Go – and then benchmarkedresults to find "factors of difference".
Who, we wondered, would be the best person to explain themysteries of the difference between the public perception and
actual usage. It was obvious who that person was, so we asked Bjarne about the issues hewrestled with when he developed the language, the problem he has had with explaining whatC++ was developed for, how he practices his craft and how language features can help peopleto be more productive.
Bjarne, was there something with C++ that made you think something along the lines of ‘Well, there are lots of things that could beusefully looked at as an infinite series of computations from which we want to draw answers until we are tired of it? As opposed tothinking something such as ‘Oh, that's an interesting technique for problems but not the basis of everything.'
I tend to design language facilities to be general, rather than as specific solutions to specific problems. For example, I did not say"Concurrency is important, so let's build in a notion of a process." Instead, I considered what would be sufficiently general to allowprogrammers to define their own notions of concurrency using classes. Constructors and destructors were part of that. Today, threadsand locks are library features in C++11 – as intended in 1980.
When I designed templates, I again aimed for generality – and of course efficiency because if your elegant systems code isn'tefficient, people will use a hack instead. I took a lot of flak from a variety of people: "templates are too complicated, why don't yourestrict them to make them less general and safer?" and "but templates make the type system Turing complete! Your compiler mightnever complete!" My thought was that you should not stop good programmers from writing good code out of fear that badprogrammers might misuse features. Incompetent programmers will write bad code in any language. The people who worry aboutinfinite compilations seem not to have thought of translation limits.
I don't see language design as an exercise in applied mathematics.
C++ is one of Google's four official languages so if use is a sign of popularity there should be little grumbling but as you know peoplecriticise C++ as a bad language yet continue to use it.
Has it been a problem getting people to understand what C++ was supposed to be and how to use it? Do you feel that programmersfail to learn how some of the language's features can be used in combination to serve some ideal of programming, such as object-oriented programming and generic programming?
I once had a Google manager say apologetically "we use C++ for all critical applications, but only because there is nothing else thatcan do those jobs." I responded "Thanks!" C++ was designed for demanding tasks, not as a "me too" language. If C++ is the onlylanguage that can do the job for a worthwhile task, I have succeeded. It is sad, though, when people can't see such success as a resultof rational and effective design choices. Instead, many see the essential features they critically rely on as failings because the featuresdon't meet the dictates of fashion.
And yes, I have a lot of trouble getting my ideas of programming styles and programming techniques across. It seems that just abouteverybody else is more certain of their opinions. Many people seem comfortable with explanations I consider unhelpfuloversimplifications: "Everything is an object!" or "Type errors must be impossible!" or "Strong typing is for weak minds!" Simpleideas, strongly stated, win converts.
I'm still optimistic, though. Good ideas often take a long time to become appreciated – sometimes decades later. Programminglanguages today look very different from languages when I started with "C with Classes." Many look a bit like C++. I take that as avalidation of the fundamental ideas I built into the language. Many of those ideas were of course borrowed (with frequentacknowledgements), but I think I helped make significant positive changes.

RM:BS:
RM:
BS:RM:BS:
RM:BS:
RM:
BS:
RM:
BS:
That said, most of my non-academic writings have something to do with explaining programming style. For example, my latest paper(IEEE Computer, January 2012) is about programming techniques for infrastructure and my latest book ("Programming: Principlesand Practice Using C++") is focussed on technique and style. My academic writings often describe experiments that might eventuallylead to more effective programming styles.
Do you think that backwards compatible with C is a fatal flaw given that C has a corrupt type system?
One of my favourite Dennis Ritchie quotes is "C is a strongly typed, weakly checked language." I don't think that C's type system is"corrupt." At least it wasn't, as it came from Dennis. I built on C because I thought it provided the best model of the machine with thefewest artificial limitations.
That said, keeping up with the incompatible changes to ISO C and the lack of concern for C++ in some of the C community (to say itpolitely) has made maintaining compatibility surprisingly hard. Also, people seem to insist using pointers and arrays in error-proneways even though C++ provides safer and easier to use alternatives (e.g. the standard-library containers and algorithms) that are justas efficient.
In your career you've straddled both academic research and working in the industry. Functional programming is popular with theresearch community but a lot of people outside that community see functional programming as being driven by ideas that, while clever,can be very mathematical and divorced from day-to-day programming. Is that a fair characterisation?
Yes.
Is there a lot of interaction between research and actual programming?
I guess your answer will depend on where you think widely used ideas originated. Object-oriented programming: A mix of industry andacademia in the Norwegian Computer Centre. C: Bell Labs, with origins in the University of Cambridge. Generic Programming:Various industrial labs and a few academic departments. Many of the "greats" of computer science, such as Dijkstra, Hoare, andNygaard straddled the industry/academia divide and their work was much better for it. I could go on with examples of languages,systems, and individuals. I think that industry/academia interaction is essential for progress. Delivering the next release of acommercial system is not in itself significant progress, nor is a stream of papers written for academic insiders.
I fear that academic language research has become further removed from the industrial reality than it was decades ago. However, Icould be falling into the trap of seeing the "good old days" through rose-tinted glasses. Maybe most of academia was always off innever-never land and all we remember is who wasn't?
Are the best of the good ideas from research labs and universities percolating into practice fast enough?
The problem is how to decide which ideas a good. Often the most popular ideas – in both academia and industry – are ineffective oreven counterproductive. Once in wide industrial use, ideas can have major impact, for good and bad. Ideally, there is a slow filteringprocess from the lab to industry that separate fads from genuine progress.
As our languages get better, or at least more programmer-friendly, compared to the days of assembly language on punch cards, itseems as it's easier to write correct programs – you get a lot of help from compilers that flag errors for you. But is it possible to allowthe focus on readability to come first, if only slightly ahead of correctness? After all some, programmers are fond of saying ‘If yourHaskell program type checks, it can't go wrong.'
What is ``programmer friendly'' depends critically of the programmer's skills and what the programmer is trying to accomplish. C++ isexpert friendly and that's fine as long as that does not imply that it is hostile to non-experts – and modern C++ isn't. C++11 provideslanguage features and standard library components that makes writing quality code simpler, but it is not a language optimized forcomplete novices.
If a Haskell program checks, it won't crash the computer, but that doesn't mean it does what it was meant to do or does so withreasonable efficiency. Nor does it imply maintainability. Anyone who thinks that Haskell is programmer friendly hasn't tried teaching itto a large class of average budding programmers. Haskell is in its own way beautiful, but it does not appear to be easily accessible toprogrammers needing to do "average tasks."
The languages that appears to be ``novice friendly'' are the dynamically typed languages where most tasks has already been done forthe programmer in the form of language facilities and massive application libraries. JavaScript, PHP, Python, and Ruby are examplesof that, but relying on a dynamically-typed language implies a major run-time cost (typically 4-to-50 times compared to C++) andconcerns about correctness for larger programs ("duck typing" postpones error detection). Whether such a trade-off betweendevelopment time and run-time costs is acceptable depends of the application. There is little gain from a statically typed language ifyou are mostly doing something that requires run-time interpretation, such as regular expression matching. On the other hand, if youraim is to respond to a stimulus respond in a few microseconds or render millions of pixels, overheads imposed for the convenience ofthe programmer easily become intolerable.
Let's talk about concurrency a little. Is Software Transactional Memory (STM) the world-saver that many people say it is? Is it right tosay that if you use one programming paradigm for writing concurrent programs and implement it really well and that's it; people shouldlearn how to write concurrent programs using that paradigm?
STM seems to have been the up-and-coming thing for over a decade. It would obviously be a boon if it really worked at the efficienciesand scale needed for near-universal use. I do not know if it does. I have not seen evidence that it does and such evidence would behard to get. I particularly worry about one aspect of STM: it's not inherently local: I designate some data to be in a TM and then anyother part of the system can affect the performance of my code by also using that data. My inclination is always to try to encapsulateaccess to help local reasoning. Global/shared resources are poison to reasoning about concurrent systems and to the performance ofsuch systems. STM localizes correctness issues, but not performance issues. If performance wasn't an issue, concurrency wouldn't be

RM:
BS:
RM:
BS:
such a hot topic.
Are there language features that make programmers more productive? You've designed the most widely used language so you'veobviously got an opinion on this.
This is a tricky question. The features that make bad programmers more productive don't seem to be the same as the ones thatmakes good programmers more productive.
To make a poor/struggling programmer productive you make language features as "familiar" as possible to current popularlanguages, minimize the efforts required for first use (no installation and interpretation can be key) , focus on common cases, improvedebuggers, avoid features that is not easily taught through online documentation, and provide an immense mass of libraries for free.
To make an expert productive you provide more control and better abstraction mechanisms and improve analysis and testing tools.Precise specification is essential. Built-in limitations (to safe and common cases) can be serious problems. Unavoidable overheadscan be fatal flaws.
Consider C's for statement and C++'s standard-library algorithms:
for (p = &a, p<(a+max); ++p) // …sort(v.begin(),v.end());
In the loop, the initialization, termination condition, and increment operations are separate. That way, arbitrary traversals over a linearsequence can be expressed, and more. Similarly, listing the beginning and the end of the sequence of elements to be sorted providesgenerality. For example, we can sort half a container or a C-style array. If you don't need this generality, simplification is easy:
for (auto x : a) // …sort(v);
These alternatives are also valid C++11. They are obviously simpler to learn, simpler to use, and – importantly – eliminates severalopportunities for making mistakes. That makes them better for novice, but the former alternatives are in a significant number of casesessential for experts. Thus, for a major language, we need both. A language for experts must not just be "expert friendly" it must alsobe approachable by novices. Also, the "novice friendly" features can – assuming that they don't impose avoidable overheads - simplifythe life of experts in the many cases where they are appropriate.
The tradeoffs are not always simply safe vs. unsafe or efficient vs. inefficient. However, the more general version always requires adeeper understanding and the added flexibility always opens more opportunities for confusion and algorithmic errors. For a specificapplication area, we can sometimes dodge this dilemma by raising the level of abstraction and leaving the mapping of very-high-levelconstructs to the language and run-time support, but for a general-purpose language, especially in the systems programming andinfrastructure areas that interests me most, that is not an option (instead, we can use such techniques in the design of libraries).
How much does choice of language really matter? Are there good reasons to choose one language over another or does it all justcomes down to taste?
The choice obviously matters, but how much and how? What matters for productivity, performance, and maintainability are theabstractions that a language presents to a programmer. These abstractions can be built into the language or as part of a library. Andagain, we come back to the questions "for what kind of application? and "for what kind of programmer?"
Imagine writing everything in assembler. That's obviously absurd; who would want to write a web service or even a full-scale operatingsystem in assembler. Unix settled that. On the other hand, imagine writing everything in JavaScript. That's equally absurd; how wouldyou write a high-speed network driver in JavaScript? How well would a JavaScript engine run if implemented in JavaScript? I think it isclear that we need a multiplicity of languages and that one (for infrastructure applications) will be something like C or C++ and that one(for web services) will be something like JavaScript, Python, and Ruby. If we agree so far, the exercise will no longer be "whichlanguage is the best?" but "which languages are suitable for a given kind of application; and which of those will be best for thisparticular set of constraints and programmers?"
People who claim that the language choice is not important are as wrong as those who claim that their favourite language is thesolution to all problems. A language is a tool, not a solution. People who genuinely consider languages unimportant are condemned towrite in the common subset of C and COBOL. Anything else would be an admission that some language features are actually useful,and that some are better and more important than others.
I'm an optimist, so I hope to see something better than C++ for infrastructure applications – even though I think that for that C++ is thecurrent best choice by far. Similarly, I hope to see something better than JavaScript, Python, Ruby, and PHP for web applications. Ialso expect to see a further specialization beyond the two areas I mention here.
I think we need work on characterizing application areas and their needs from languages. We are groping in the dark and not learningfrom current successes and failures. A major part of the problem is that proponents of a language are unwilling to admit weaknessesbecause such admissions are immediately broadcast as proof of their favourite language's fundamental inferiority. Too many stillbelieve that one language is best and that history moves from one dominant language (for everything) to another; that we move fromone (exclusive) paradigm to the next. I consider that absurd and in disagreement with any non-revisionist history. Another problem is

RM:BS:
RM:BS:
RM:BS:
that thorough and impartial analysis of existing systems is hard and typically ill rewarded by both industry and academia.
I have already used too many words, so I will dodge your question beyond pointing to the two application areas mentioned. Languagechoice is important and we need better rational criteria for choice. I think some of those criteria must be empirical. Language choiceis not a purely mathematical or philosophical exercise. We do not need another discussion based on comparisons of individuallanguage features.
What languages have you used seriously? It must be a long list for you?
Define "serious." I don't ship software for the non-educational use of others any more, and haven't done so for years. Similarly, Ihaven't done much maintenance recently. I had tried on the order of 25 languages when I started on C with Classes and I haveexperimented with a similar number since. Of the early languages, microcode assemblers, assemblers, Algol60, Algol68, Simula,Snobol, and BCPL were my main tools. Later, C++, C, and various scripting languages dominate. I think I have learned a lot frommany languages, but that my experiences with modern language make me better suited for writing a textbook in comparativeprogramming languages than for delivering quality code at a commercially viable rate. I have tried most modern languages currentlyused to deliver code and a few experimental languages. Listening to people who use languages non-experimentally is as important asmy personal experiments.
Are there programming languages which you don't enjoy using?
Yes, but I refuse to name languages. That wouldn't be fair. I might simply have misunderstood something or applied the languageoutside its intended problem domain.
Since you started programming what's changed about the way you think about it?
I'm much more concerned with correctness and far more suspicious about my own observations. Everything needs to be doublechecked and validated – preferably with the aid of tools. Maintainability has been a steadily growing concern.
I value simple, easy-to-read code, well specified algorithms, and simple, compact, data structures. I am increasingly suspicious ofclever code and clever data structures. It is easy for a programmer to outsmart himself (herself) so that the resulting code is hard tomaintain and often end up performing poorly as hardware architectures and input sets change over time. The best optimizations aresimplifications. One reason for my concerns about "cleverness" is that modern architectures make predictions about performancehazardous. Similarly, the size and longevity of modern systems makes assumptions about what programmers understand hazardous.Think "pipelines and caches" and "Java programmers trying to write C++ or Ada programmers trying to write C."
© Simple-Talk.com
















