13
Streaming Data, Continuous Queries, and Adaptive Dataflow Michael Franklin UC Berkeley NRC June 2002 .
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 220 times |
| Download: | 0 times |

Streaming Data, Continuous Queries, and Adaptive Dataflow
Michael FranklinUC Berkeley
NRC June 2002
.

2
Data Stream ProcessingNetworked data streams central to current and
future computing.Existing data management and query processing
infrastructure is lacking:– Adaptability– Continuous and Incremental Processing– Work Sharing for large scale– Resource scalability: from “smart dust” up to
clusters to grids.XML provides additional opportunites.
3
Example 1: “Transactional Flows”
E-Commerce, clickstream, swipestream, logs…
Network Monitoring B2B and Enterprise apps
– Supply-Chain, CRM, ERP (Quasi) real-time flow of events and data Must manage these flows to drive business
processes. Mine flows to create and adjust business rules. Can also “tap into” flows for on-line analysis.
4
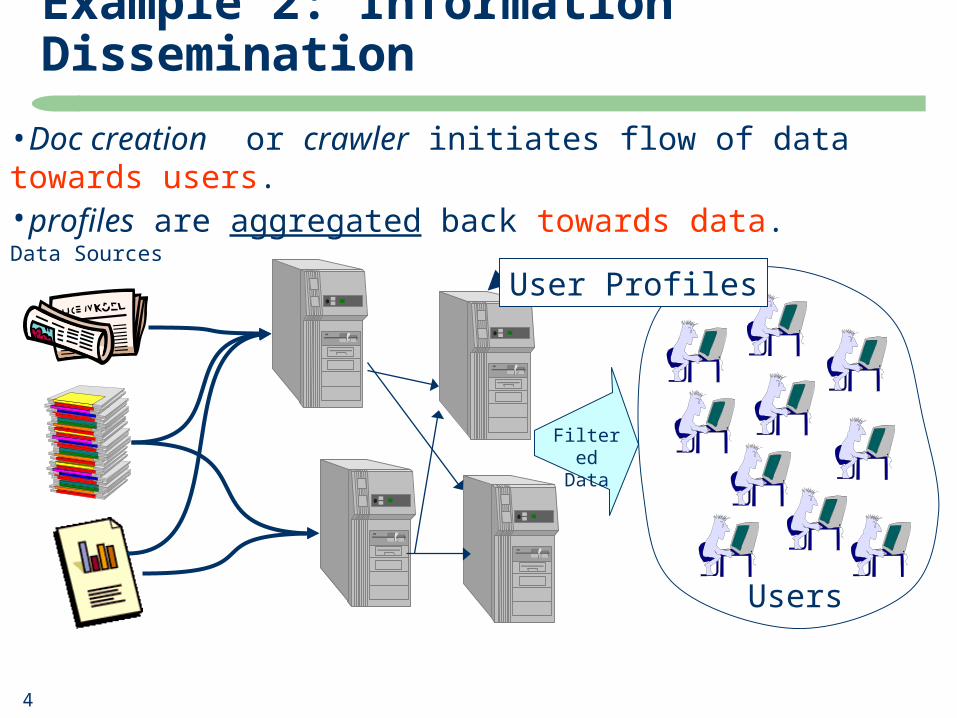
Example 2: Information Dissemination
User Profiles
Users
Filtered Data
Data Sources
•Doc creation or crawler initiates flow of data towards users.•profiles are aggregated back towards data.

5
Example 3: Sensor Nets
Tiny (or not so tiny) devices measure the physical world.
– Berkeley “motes”, Smart Dust, Smart Tags, … Many monitoring applications
– Transportation, Seismic, Energy, Military… Form dynamic ad hoc networks. Aggregate and communicate streams of values. Not one way – can actuate to effect or actively
monitor the environment

6
Common Features Centrality of Dataflow and Data Routing
– Architecture is focused on data movement– Moving streams of data through code in a network
Volatility of the environment– Dynamic resources & topology, partial failures– Long-running (never-ending?) tasks– Potential for user interaction during the flow– Large Scale: users, data, resources, …
Resource Constraints– Bandwidth, memory,processing,battery,…– Time and human attention

7
In The Beginning
Data
Query
Index
Result
8
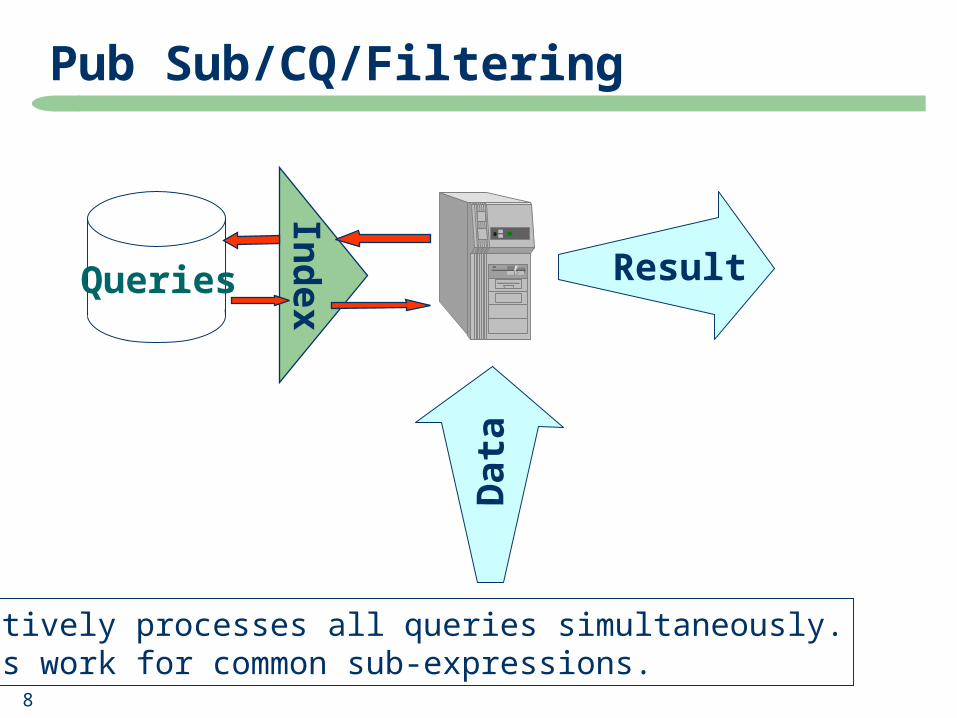
Pub Sub/CQ/Filtering
Queries
Dat
a
Ind
ex
Result
•Effectively processes all queries simultaneously.•Shares work for common sub-expressions.
9
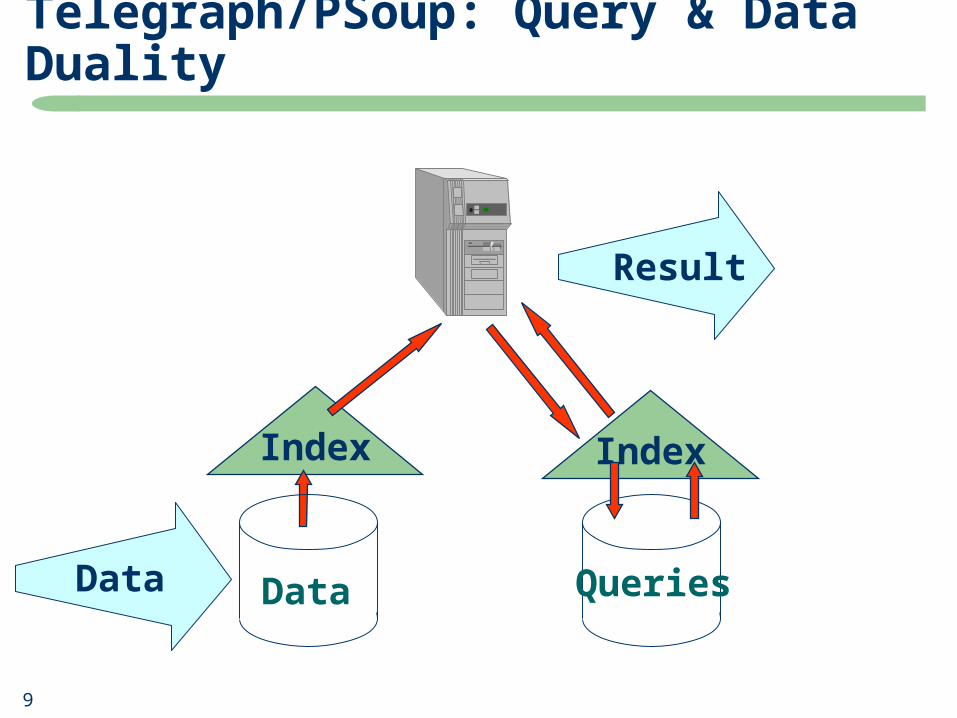
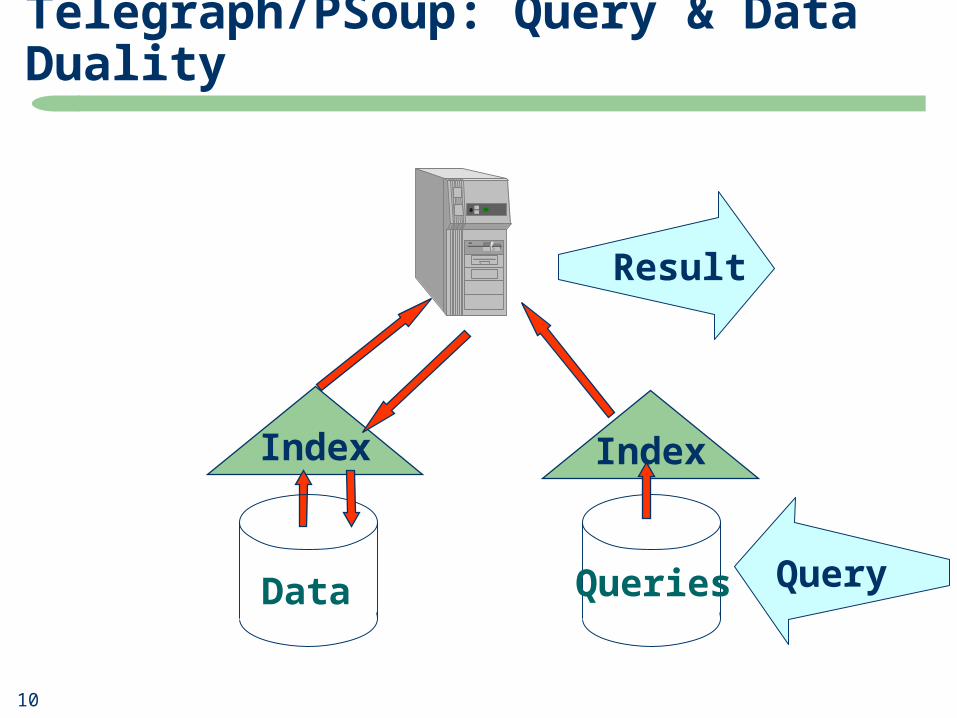
Telegraph/PSoup: Query & Data Duality
Queries
Index
Result
DataData
Index
10
Telegraph/PSoup: Query & Data Duality
Queries
Index
Result
Data
Index
Query

11
PSoup – Query Invocation
PSoup continuously maintains materialized views over streaming data and queries.
Data is returned to user when query is invoked.– Invocation requires applying “windows” to precomputed
results. Adaptive approach allows system to continuously
absorb new data and new queries without recompilation.
Lots of issues to study: – Query indexing, Spilling to disk, bulk processing– Other semantics and interaction models (e.g., alerts)

12
Stream Processing Research Agenda Need continuously-adaptive processing. Need appropriate data model & query lang.
– Window semantics: input and output– Notification semantics & thresholds
Approximation, satisficing, and QoS– must be driven by user needs and context– adapt to available resources & time constraints
Integration & interaction with “pooled” data.– time travel, archiving, “normal” databases
Structured, semi-, and un- data; XML etc. Sensor-sensitive processing. Metrics and Benchmarks (challenge problems).

13
Conclusions Dataflow and streaming are central to many
emerging application areas.– Solutions require a mixture of database and
networking approaches:adaptivity and tolerance of partial failureexploitation of user, app, and data semantics
A new infrastructure is needed for solving these problems. – Duality of Data and Queries
Currently a topic of major interest in the research community.

















