56
Text Mining IS698 Min Song
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 1 times |

Text Mining
IS698Min Song

The Needs:- Find people as well as documents that can
address my information need.- Promote collaboration and knowledge
sharing- Leverage existing information access
system- The Information Sources:
- Email, groupware, online reports, …
Example 1: KM People Finder
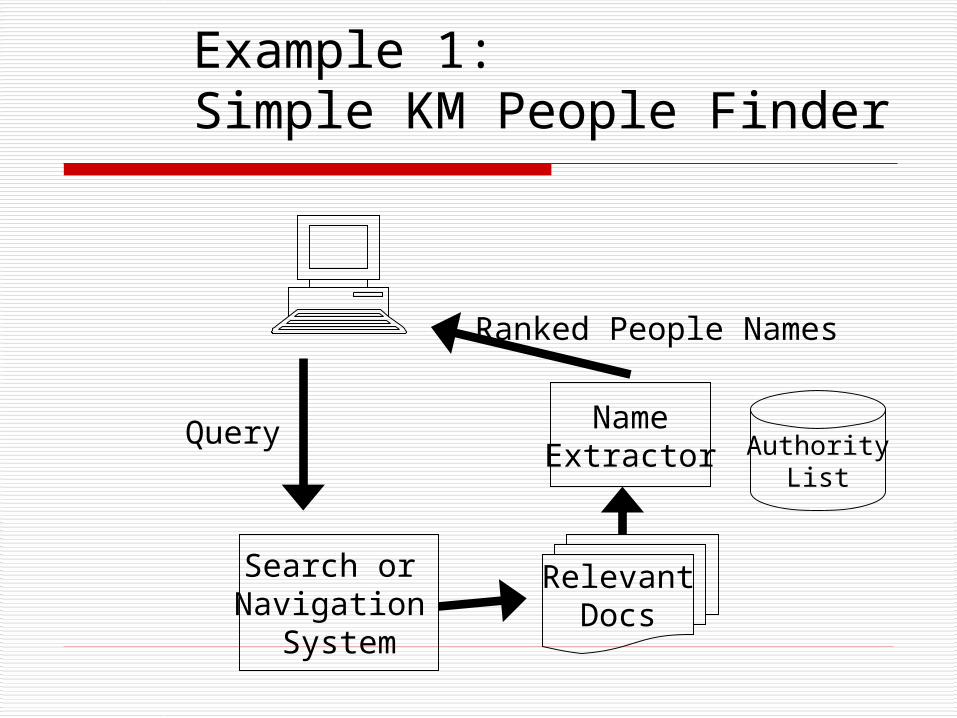
Example 1:Simple KM People Finder
RelevantDocs
Search or Navigation
System
NameExtractor Authority
List
Query
Ranked People Names
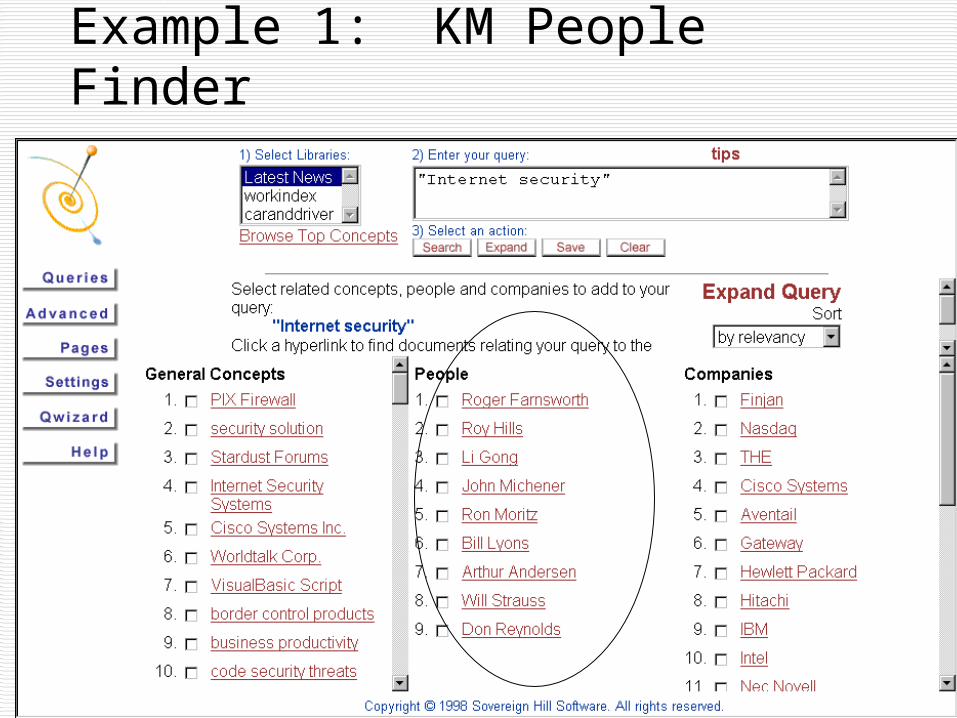
Example 1: KM People Finder

• An exploration and analysis of textual (natural-language) datatextual (natural-language) data by automatic and semi automatic means to discover new knowledge.
Text Mining Definition
Many definitions in the literature“The non trivial extraction of implicit, previously unknown, and potentially useful information from (large amount of) textual data”.

What is ““previously unknown”previously unknown” information ? Strict definition
Information that not even the writer knows. e.g., Discovering a new method for a hair growth
that is described as a side effect for a different procedure
Lenient definition Rediscover the information that the author
encoded in the text e.g., Automatically extracting a product’s name
from a web-page.
Text Mining Definition

Outline
Text mining applications Text characteristics Text mining process Learning methods

Text Mining Applications Marketing: Discover distinct
groups of potential buyers according to a user text based profile e.g. amazon
Industry: Identifying groups of competitors web pages e.g., competing products
and their prices Job seeking: Identify
parameters in searching for jobs e.g., www.flipdog.com

Information Retrieval Indexing and retrieval of textual documents
Information Extraction Extraction of partial knowledgepartial knowledge in the text
Web Mining Indexing and retrieval of textual documents and
extraction of partial knowledge using the web Clustering
Generating collections of similar text documents
Text Mining Methods

Information Retrieval
Given: A source of textual
documents A user query (text
based)
IRSystem
QueryE.g. Spam / Text
Documentssource
• Find:
• A set (ranked) of documents that are relevant to the query
RankedDocuments
Document
DocumentDocument

Intelligent Information Retrieval meaning of words
Synonyms “buy” / “purchase” Ambiguity “bat” (baseball vs. mammal)
order of words in the query hot dog stand in the amusement park hot amusement stand in the dog park
user dependency for the data direct feedback indirect feedback
authority of the source IBM is more likely to be an authorized source then my
second far cousin

Given: A source of textual documents A well defined limited query (text based)
Find: Sentences with relevantrelevant information Extract the relevant information and ignore non-relevant information (important!) Link related information and output in a
predetermined format
What is Information Extraction?

Information Extraction: Example
Salvadoran President-elect Alfredo Cristiania condemned the terrorist killing of Attorney General Roberto Garcia Alvarado and accused the Farabundo Marti Natinal Liberation Front (FMLN) of the crime. … Garcia Alvarado, 56, was killed when a bomb placed by urban guerillas on his vehicle exploded as it came to a halt at an intersection in downtown San Salvador. … According to the police and Garcia Alvarado’s driver, who escaped unscathed, the attorney general was traveling with two bodyguards. One of them was injured.
Incident Date: 19 Apr 89 Incident Type: Bombing Perpetrator Individual ID: “urban guerillas” Human Target Name: “Roberto Garcia Alvarado” ...

What is Information Extraction?
ExtractionSystem
Documentssource
RankedDocuments
Relevant Info 1
Relevant Info 2
Relevant Info 3
Query 1 (E.g. job title)Query 2 (E.g. salary)
CombineQuery Results

Why Mine the Web? Enormous wealth of textual information on the
Web. Book/CD/Video stores (e.g., Amazon) Restaurant information (e.g., Zagats) Car prices (e.g., Carpoint)
Lots of data on user access patterns Web logs contain sequence of URLs accessed by users
Possible to retrieve “previously unknown” information People who ski also frequently break their leg. Restaurants that serve sea food in California are likely
to be outside San-Francisco

Mining the Web
IR / IESystem
Query
Documentssource
RankedDocuments
1. Doc12. Doc2
3. Doc3 . .
Web Spider

The Web is a huge collection of documents where many contain: Hyper-linkHyper-link information Access and usage information
The Web is very dynamic Web pages are constantly being
generated (removed)
Unique Features of the Web
Challenge: Develop new Web mining algorithms to . . .• Exploit hyper-links and access patterns.• Be adaptable to its documents source

Combine the intelligent IR tools meaningmeaning of words orderorder of words in the query user dependencyuser dependency for the data authorityauthority of the source
With the unique web features retrieve Hyper-link information utilize Hyper-link as input
Intelligent Web Search

What is Clustering ? Given:
A source of textual documents
Similarity measure e.g., how many
words are common in these documents
ClusteringSystem
Similarity measure
Documentssource
DocDo
cDoc
Doc
Doc
DocDoc
Doc
DocDoc
• Find:• Several clusters of
documents that are relevant to each other

Outline
Text mining applications Text characteristics Text mining process Learning methods

Text characteristics: Outline
Large textual data base High dimensionality Several input modes Dependency Ambiguity Noisy data Not well structured text

Text characteristics Large textual data base
Efficiency consideration over 2,000,000,000 web pages almost all publications are also in electronic form
High dimensionality (Sparse input) Consider each word/phrase as a dimension
Several input modes e.g., Web mining: information about user is
generated by semantics, browse pattern and outside knowledgebase.

Text characteristics Dependency
relevant information is a complex conjunction of words/phrases e.g., Document categorization. Pronoun disambiguation.
Ambiguity Word ambiguity
Pronouns (he, she …) “buy”, “purchase”
Semantic ambiguity The king saw the rabbit with his glasses.

Text characteristics
Noisy data Example: Spelling mistakes
Not well structured text Chat rooms
“r u available ?” “Hey whazzzzzz up”
Speech

Outline
Text mining applications Text characteristics Text mining process Learning methods

Text mining process

Text mining process Text preprocessing
Syntactic/Semantic text analysis
Features Generation Bag of words
Features Selection Simple counting Statistics
Text/Data Mining Classification-
Supervised learning Clustering-
Unsupervised learning Analyzing results

Part Of Speech (pos) tagging Find the corresponding pos for each word e.g., John (noun) gave (verb) the (det) ball (noun) ~98% accurate.
Word sense disambiguation Context basedContext based or proximity basedproximity based Very accurate
Parsing Generates a parse treeparse tree (graph) for each sentence Each sentence is a stand alone graph
Syntactic / Semantic text analysis

Given: a collection of labeled records (training settraining set) Each record contains a set of features (attributesattributes),
and the true class (labellabel) Find: a modelmodel for the class as a function of the values
of the features Goal: previously unseen records should be assigned a
class as accurately as possible A test settest set is used to determine the accuracy of the
model. Usually, the given data set is divided into training and test sets, with training set used to build the model and test set used to validate it
Text Mining: Classification definition

Similarity Measures:• Euclidean DistanceEuclidean Distance if attributes are continuous• Other Problem-specific Measures
• e.g., how many words are common in these documents
Given: a set of documents and a similarity measuresimilarity measure among documents
Find: clusters such that: Documents in one cluster are more similar to one
another Documents in separate clusters are less similar to
one another Goal:
Finding a correctcorrect set of documents
Text Mining: Clustering definition

Supervised learning (classification) Supervision: The training data (observations,
measurements, etc.) are accompanied by labelslabels indicating the class of the observations
New data is classified based on the training set Unsupervised learning (clustering)
The class labels of training data is unknown Given a set of measurements, observations, etc.
with the aim of establishing the existence of classes or clusters in the data
Supervised vs. Unsupervised Learning

Correct classification: The known label of test sample is identical with the class resultclass result from the classification model
Accuracy ratio: the percentage of test set samples that are correctly classified by the model
A distance measuredistance measure between classes can be used e.g., classifying “football” document as a
“basketball” document is not as bad as classifying it as “crime”.
Evaluation:What Is Good Classification?

Good clustering method: produce high quality clusters with . . . high intra-classintra-class similarity low inter-classinter-class similarity
The qualityquality of a clustering method is also measured by its ability to discover some or all of the hiddenhidden patterns
Evaluation: What Is Good Clustering?

Outline
Text mining applications Text characteristics Text mining process Learning methods
Classification Clustering
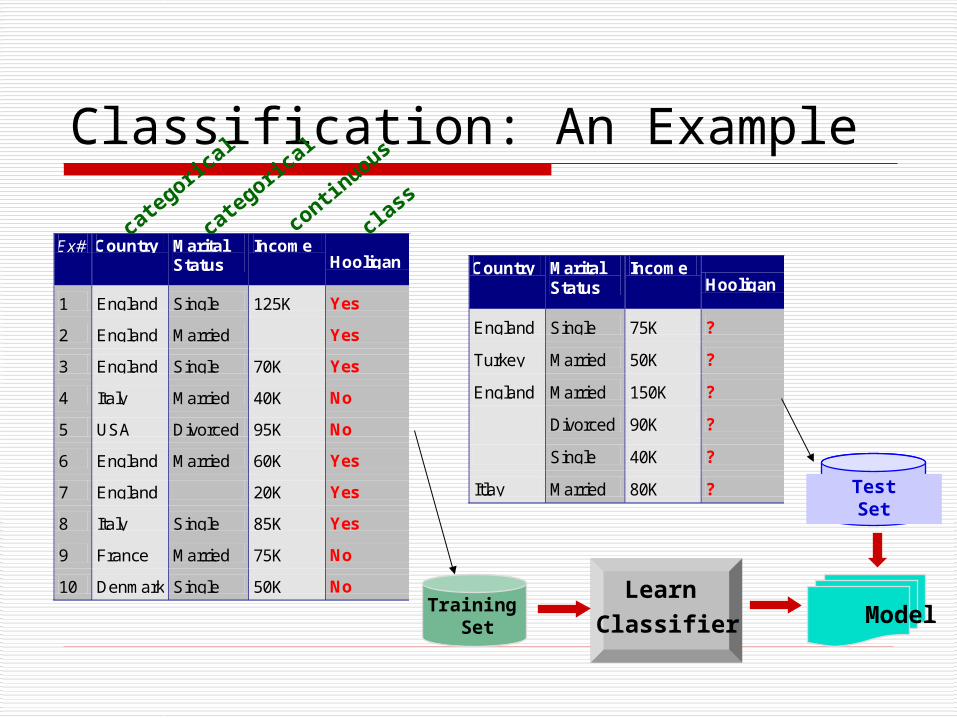
Classification: An Example
Ex# Country Marital Status
Income Hooligan
1 England Single 125K Yes
2 England Married Yes
3 England Single 70K Yes
4 Italy Married 40K No
5 USA Divorced 95K No
6 England Married 60K Yes
7 England 20K Yes
8 Italy Single 85K Yes
9 France Married 75K No
10 Denmark Single 50K No 10
categoric
al
categoric
al
continuous
class
Training Set
ModelLearn
Classifier
Country Marital Status
Income Hooligan
England Single 75K ?
Turkey Married 50K ?
England Married 150K ?
Divorced 90K ?
Single 40K ?
Itlay Married 80K ? 10
TestSet

Text Classification: An Example
Ex# Hooligan
1 An English football fan …
Yes
2 During a game in Italy …
Yes
3 England has been beating France …
Yes
4 Italian football fans were cheering …
No
5 An average USA salesman earns 75K
No
6 The game in London was horrific
Yes
7 Manchester city is likely to win the championship
Yes
8 Rome is taking the lead in the football league
Yes 10
class
Training Set
ModelLearn
Classifier
text
TestSet
Hooligan
A Danish football fan ?
Turkey is playing vs. France. The Turkish fans …
? 10

Classification Techniques
Instance-Based Methods Decision trees Neural networks Bayesian classification

Instance-based (memory based) learning Store training examples and delay the
processing (“lazy evaluation”) until a new instance must be classified
k-nearest neighbor approach InstancesInstances (Examples) are represented
as points in a Euclidean spacepoints in a Euclidean space
Instance-based Methods

foot
ball
Italian
The English footballfootball fan is a hooligan. . .
foot
ball
Italian
Similar to his English equivalent, the ItalianItalianfootballfootball fan is a hooligan. . .
Text Examples in Euclidean Space

All instances correspond to points in the nn-D space The nearest neighbor are defined in terms of
Euclidean distance
.
_+
+ ?
+
_ _+
_
_
+
_+
+ +
+
_ _+
_
_
+
• The kk-NN-NN returns the most common value among the kk nearest training examples
• Voronoi diagram: the decision surface induced by 11-NN-NN for a typical set of training examples
K-Nearest Neighbor Algorithm

Classification Techniques
Instance-Based Methods Decision trees Neural networks Bayesian classification

Ex# Country Marital Status
Income Hooligan
1 England Single 125K Yes
2 England Married 100K Yes
3 England Single 70K Yes
4 Italy Married 40K No
5 USA Divorced 95K No
6 England Married 60K Yes
7 England Divorced 20K Yes
8 Italy Single 85K Yes
9 France Married 75K No
10 Denmark Single 50K No 10
categoric
al
categoric
al
continuous
class
Decision Tree: An Example
YesEnglish
Yes
No
MarSt
NO
Married Single, Divorced
Splitting Attributes
Income
YESNO
> 80K < 80K
The splitting attribute at a node is
determined based on a specific
Attribute selection algorithm

Ex# Hooligan
1 An English football fan …
Yes
2 During a game in Italy …
Yes
3 England has been beating France …
Yes
4 Italian football fans were cheering …
No
5 An average USA salesman earns 75K
No
6 The game in London was horrific
Yes
7 Manchester city is likely to win the championship
Yes
8 Rome is taking the lead in the football league
Yes 10
classte
xt
Decision Tree: A Text Example
YesEnglish
Yes
No
MarSt
NO
Married Single, Divorced
Splitting Attributes
Income
YESNO
> 80K < 80K
The splitting attribute at a node is
determined based on a specific
Attribute selection algorithm

Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes represent class labels or class distribution
Decision tree generation consists of two phases: Tree construction Tree pruning
Identify and remove branches that reflect noisenoise or outliersoutliers
Use of decision tree: Classifying an unknown sample Test the attribute of the sample against the decision
tree
Classification by DT Induction

Partitioning Methods Hierarchical Methods
Clustering Techniques

Partitioning method: Construct a partition of n documents into a set of k clusters
Given: a set of documents and the number k Find: a partition of k clusters that optimizes the
chosen partitioning criterion Global optimalGlobal optimal: exhaustively enumerate all
partitions Heuristic methods: k-means and k-medoids
algorithms k-meansk-means: Each cluster is represented by the center
of the cluster
Partitioning Algorithms

k-means algorithm is implemented in 4 steps:
1. Partition objects into kk nonempty subsets.2. Compute seed points as the centroidscentroids of the
clusters of the current partition. The centroid is the center (mean point) of the cluster.
3. Assign each object to the cluster with the nearest seed point.
4. Go back to Step 2, stop when no more new assignment.
The K-means Clustering Method

0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
The K-means Clustering: Example

Partitioning Methods Hierarchical Methods
Clustering Techniques

Agglomerative: Start with each document being a single cluster. Eventually all document belong to the same
cluster.
Divisive: Start with all document belong to the same cluster. Eventually each node forms a cluster on its own.
Does not require the number of clusters k in advance
Needs a termination condition
The final mode in both Agglomerative and Divisive in of no use.
Hierarchical Clustering

Step 0
b
d
c
e
a a b
Step 1 Step 2
d e
Step 3
c d e
Step 4
a b c d e
agglomerative
Step 4 Step 3 Step 2 Step 1 Step 0
divisive
Hierarchical Clustering: Example

• Dendrogram: Decomposes data objects into a several levels of nested partitioning (tree of clusters).
• Clustering of the data objects is obtained by cutting the dendrogram at the desired level, then each connectedconnected component forms a cluster.
A Dendogram: Hierarchical Clustering

Demo

Commercial Tools
IBM Intelligent Miner for Text Semio Map InXight LinguistX / ThingFinder LexiQuest ClearForest Teragram SRA NetOwl Extractor Autonomy

Text is tricky to process, but “ok” results are easily
achieved
There exist several text mining systemstext mining systems
e.g., D2K - Data to Knowledge
http://www.ncsa.uiuc.edu/Divisions/DMV/ALG/
Additional IntelligenceIntelligence can be integrated with text
mining
One may play with any phase of the text mining
process
Summary

Summary
There are many other scientific and statistical text mining scientific and statistical text mining
methodsmethods developed but not covered in this talk.
http://www.cs.utexas.edu/users/pebronia/text-mining/
http://filebox.vt.edu/users/wfan/text_mining.html
Also, it is important to study theoretical foundationstheoretical foundations of data
mining.
Data Mining Concepts and Techniques / J.Han &
M.Kamber
Machine Learning, / T.Mitchell

















