1 Scalable Dynamic Formal Verifica3on and Correctness Checking of MPI Applica3ons Ganesh Gopalakrishnan 1 , Ma1hias Müller 2 , Bronis R. de Supinski 3 , Tobias Hilbrich 2 , Anh Vo 1 , Alan Humphrey 1 , and Christopher Derrick 1 University of Utah 1 Technische Universität Dresden 2 Lawrence Livermore NaMonal Laboratory 3
Transcript
1
Scalable Dynamic Formal Verifica3on and Correctness Checking of MPI Applica3ons
Ganesh Gopalakrishnan1, Ma1hias Müller2, Bronis R. de Supinski3, Tobias Hilbrich2, Anh Vo1, Alan Humphrey1, and Christopher Derrick1
University of Utah1
Technische Universität Dresden2
Lawrence Livermore NaMonal Laboratory3
2
Organiza3on • Overview of Erroneous Programming in MPI • MPI Run3me Error Detec3on with Marmot • ISP: A Run3me Checker Emphasizing Non-‐determinism • GEM: Graphical Explorer of MPI Programs • Improved Scalability Through Umpire BREAK • Verifica3on at Large Scale: DAMPI • Scalable MPI Error Detec3on with MUST • MPI Run3me Error Detec3on in Hybrid OpenMP/MPI
Ganesh Gopalakrishnan1, Ma1hias Müller2, Bronis R. de Supinski3, Tobias Hilbrich2, Anh Vo1, Alan Humphrey1, and Christopher Derrick1
University of Utah1
Technische Universität Dresden2
Lawrence Livermore NaMonal Laboratory3
4
MPI was designed to support performance
• Complex standard with many opera3ons – Includes non-‐blocking and collec3ve opera3ons – Can specify messaging choices precisely – Library not required to detect non-‐compliant usage
• Many erroneous or unsafe ac3ons – Incorrect arguments – Resource errors – Buffer usage – Type matching errors – Deadlock
• Includes concept of “unsafe” sends
5
Incorrect Arguments
• Incorrect arguments manifest during: – Compila3on (Type mismatch) – Run3me (Crash in MPI or unexpected behavior)
– During por3ng (Only manifests for some MPIs/Systems)
• Example (C): MPI_Send (buf, count, MPI_INTEGER,…);
6
Resource Tracking Errors
• Many MPI features require resource alloca3ons – Communicators – Data types – Requests – Groups, Error Handlers, Reduc3on Opera3ons
• Three kinds of MPI type matching – Send buffer type and MPI send data type – MPI send type and MPI receive type – MPI receive type and receive buffer type
• Similar requirements for collec3ve opera3ons
• Buffer type <=> MPI type matching – Requires compiler support – MPI_BOTTOM, MPI_LB & MPI_UB complicates – Not provided by our tools
10
Basic MPI Type Matching Example
• MPI standard provides support for heterogeneity – Endian-‐ness – Data formats – Limita3ons
• Simple cycle detec3on only sufficient for AND case • The more general AND-‐OR model is suitable, but: - Visualiza3on of deadlock unsa3sfactory - Too complex: each MPI call either uses AND or OR
• We developed a model specifically designed for MPI
Waits for all process (AND) Waits for any process (OR)
Consider Dependency Types in MPI Programs
17
Non-‐empty set of nodes N where: For all nodes x in N the set descendants(x) is equal to N
• Umpire uses enhanced wait for graph with: - AND seman3c arcs (drawn solid) - OR seman3c arcs (drawn dashed)
- Each node only uses one arc type • Deadlock Criterion ?
1
2
3 Example:
Best case reduction: 1
2
3
Cycle is not sufficient !
1
2
3
1
2
3
No knot !
Knot is not necessary !
The Either AND or OR Model
Each task executes the waited for calls
18
• OR-‐Knot is a relaxed knot: - Set of nodes N, each node can reach all nodes in N - Nodes may also reach further nodes
o But: there must not be an AND arc from a node in N to a node not in N
• Examples: " An OR-Knot (in red): " Still an OR-Knot: " No OR-Knot:
A Necessary and Sufficient Deadlock Condi3on: The OR-‐Knot
19
• Uses best-‐case reduc3on of wait-‐for condi3ons • Sinks(fan-‐out=0) can sa3sfy wait-‐for condi3ons • Two reduc3on types: - AND: removes one incoming arc of a sink
- OR: removes all outgoing arcs of node connected to sink
• Example: OR AND
• Deadlock if resul3ng WFG has non-‐empty arc set
Signal Reduc3on Detec3on for the Either AND or OR Model
20
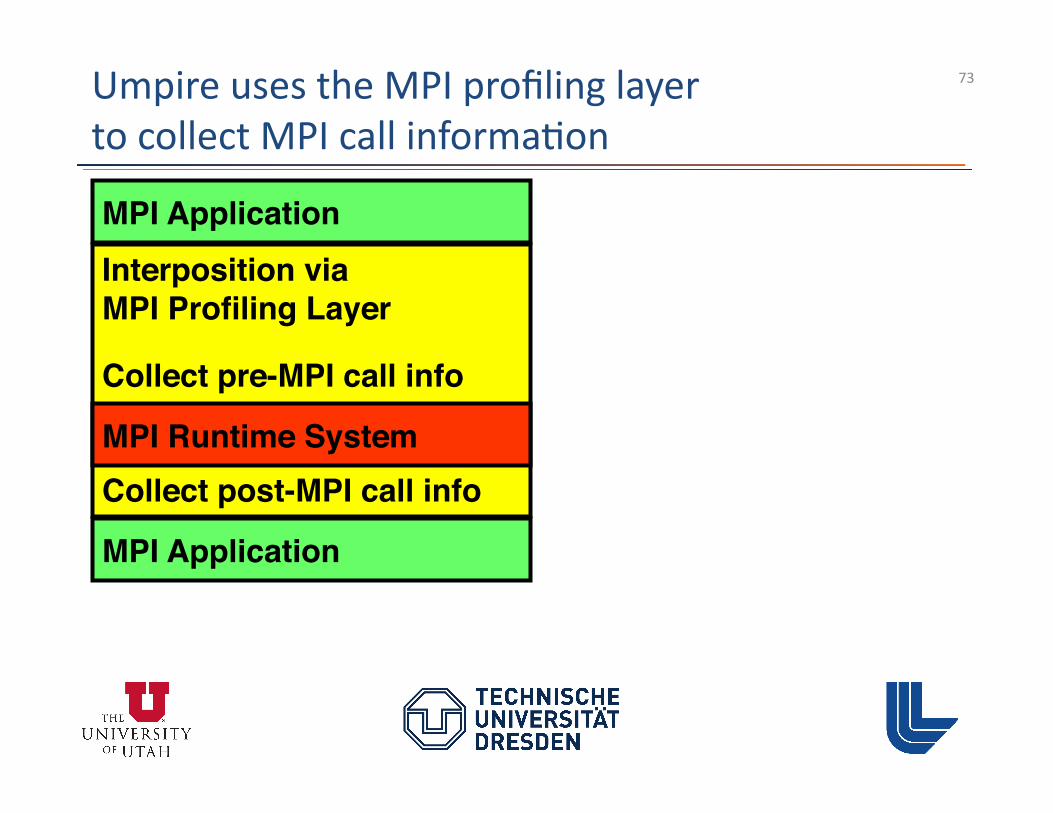
MPI Run3me Error Detec3on with Marmot
Ganesh Gopalakrishnan1, Ma1hias Müller2, Bronis R. de Supinski3, Tobias Hilbrich2, Anh Vo1, Alan Humphrey1, and Christopher Derrick1
– C++ library – Requires no source modifica3ons – MPI-‐1.2 support + some MPI-‐2 – Lots of usability
23
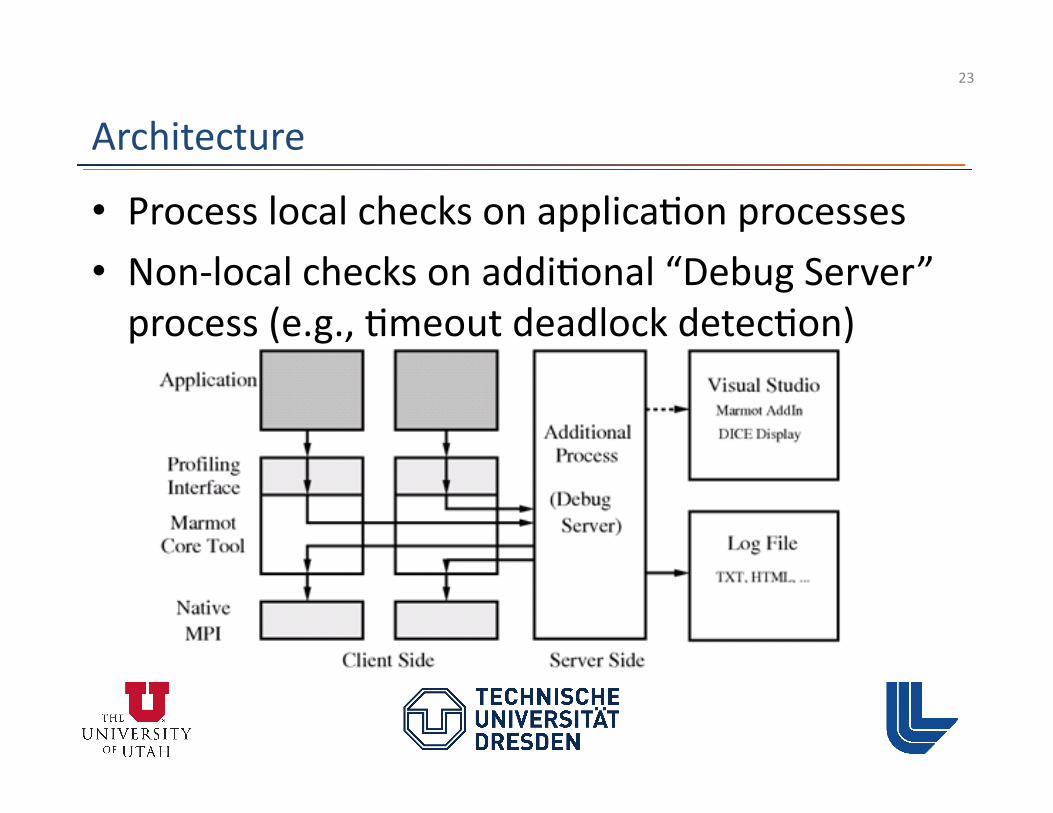
Architecture
• Process local checks on applica3on processes • Non-‐local checks on addi3onal “Debug Server” process (e.g., 3meout deadlock detec3on)
24
Usage
• Use Marmot compiler wrappers to compile and link: - Replace compiler calls by appropriate wrapper - For C/C++: marmotcc or marmotcxx
- For Fortran: marmoQ77 or marmoQ90 - Source code instrumenta3on added automa3cally
• Execu3on with Marmot requires one addi3onal process - Used for Debug Server - Instead of mpirun -‐np n call mpirun -‐np n+1 - Marmot's checks cause overhead
• Environmental variables control Marmots behaviour
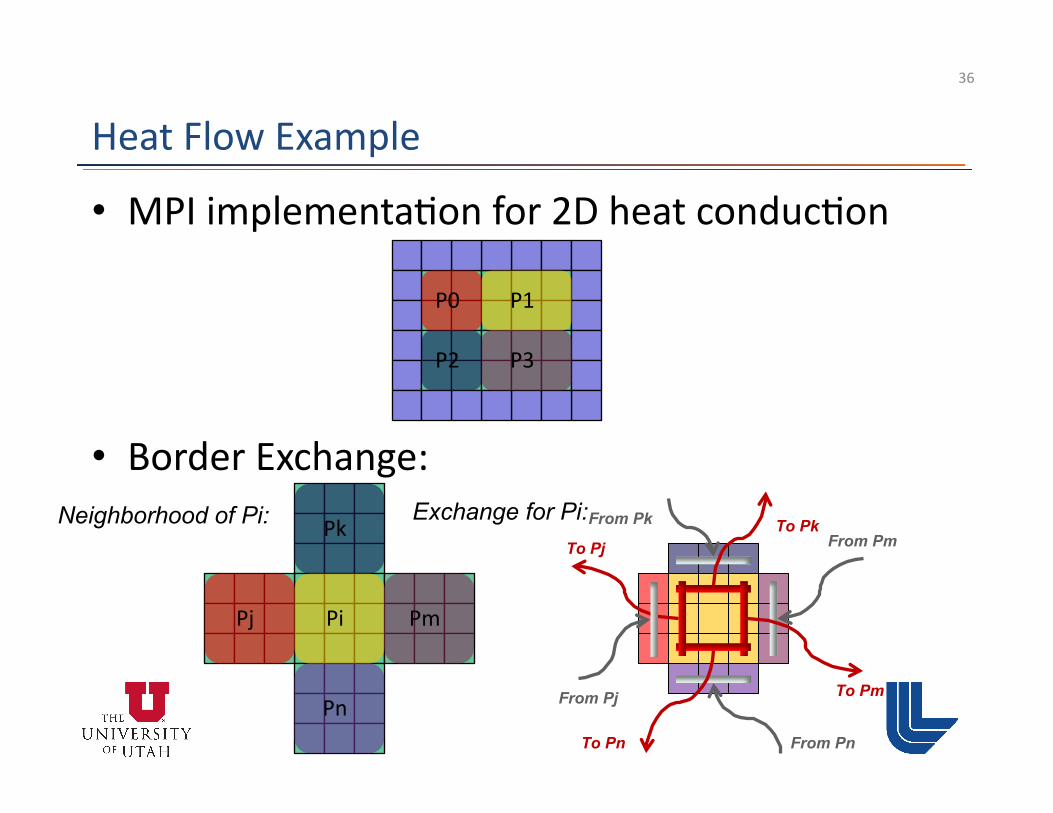
Neighborhood of Pi: Exchange for Pi: To Pk From Pk
To Pm
From Pm
To Pn From Pn
To Pj
From Pj
37
Live Demonstra3on
• Usage: – Replace compiler command with Marmot tool, e.g. mpicc -‐> marmotcc
– Run with 1 extra process • Examples:
– Datatype example – Heat conduc3on
38
ISP: A Dynamic MPI Checker Emphasizing Nondeterminism
Ganesh Gopalakrishnan1, Ma1hias Müller2, Bronis R. de Supinski3, Tobias Hilbrich2, Anh Vo1, Alan Humphrey1, and Christopher Derrick1
University of Utah1
Technische Universität Dresden2
Lawrence Livermore NaMonal Laboratory3
39
Descrip3on of an Idealized Tes3ng Tool
1. Eliminates redundant tests – Example: pos3ng a determinis3c send/receive in
both orders is wasteful (w.r.t. tes3ng priori3es)
2. De-‐bias from absolute speeds – Schedules must not be a vic3m of sequen3al
execu3on speed of individual processes
3. Force non-‐determinism coverage – Not only determine where non-‐determinism is,
but also force those cases to get tested
39
40
Descrip3on of an Idealized Tes3ng Tool
4. Force non-‐determinism coverage even around complex opera3ons (e.g., collec3ves)
– Tes3ng unbiased by collec3ve seman3cs
5. Tool based on a uniform underlying theory – Say a “happens-‐before” model
6. Be able to cover the input space 7. Provide intui3ve user interface within popular
frameworks
40
41
Mee3ng all these goals is difficult!
• ISP (In-‐situ Par3al Order) is our tool that meets all goals except Goal-‐6 for a reasonably large subset of MPI 2.0
• Goal-‐6 (input space coverage) typically requires symbolic analysis of program paths (not supported)
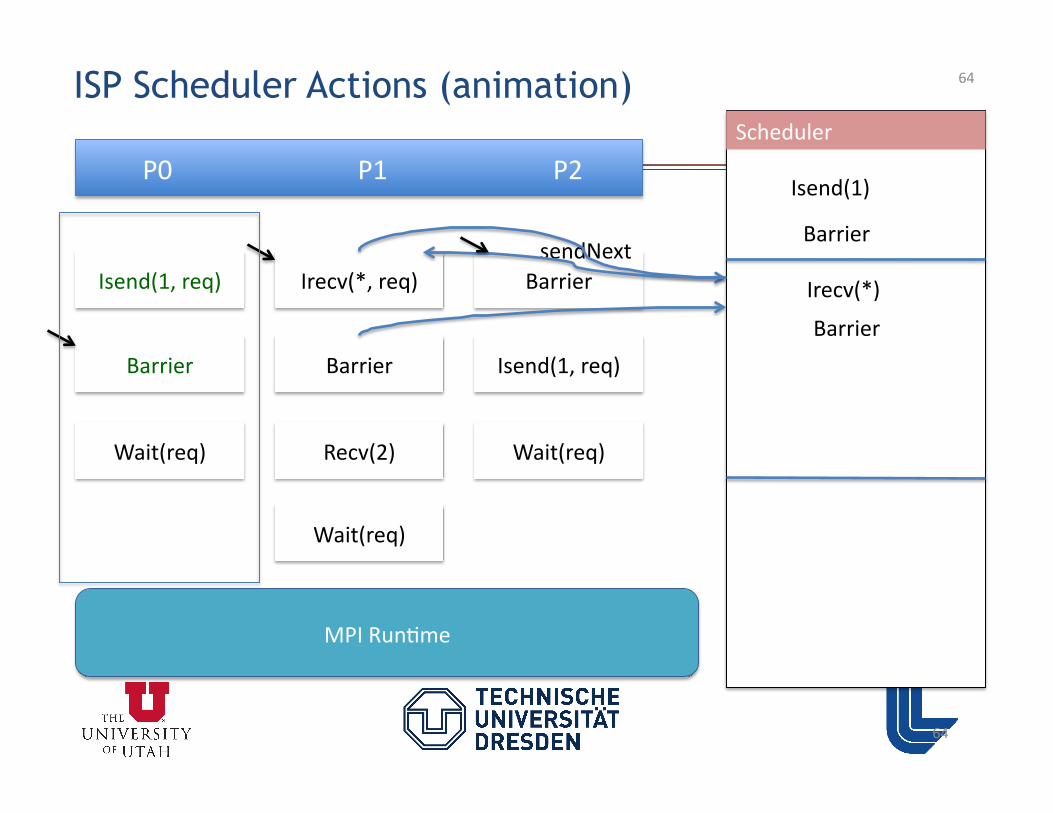
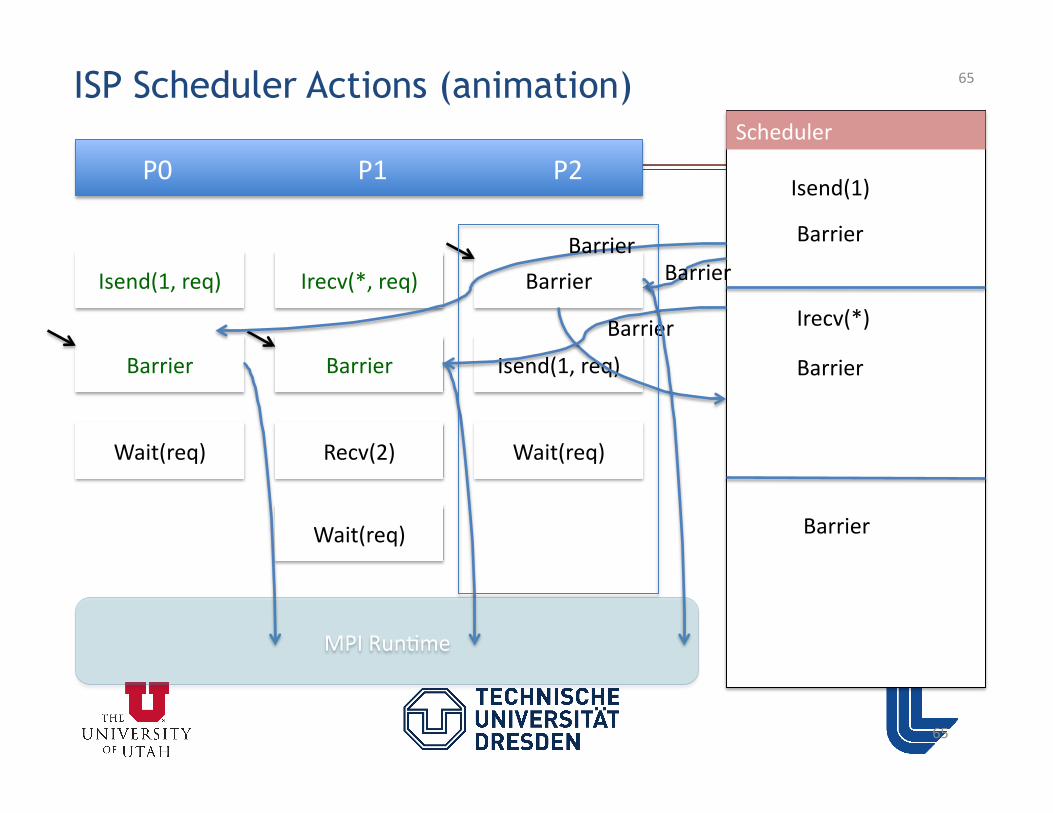
• Goals 1-‐5 met using special verifica3on Scheduler – ISP Scheduler AUTOMATICALLY Replays Given Program Enough Time Till Non-‐Determinism Space is Covered !!
• Goal 7 met by embedding within Eclipse PTP (GEM, an officially released PTP 4.0 component)
41
42
Flow of ISP
42
Executable
Proc1 Proc2 …… Procn
Scheduler Run
MPI Run?me
Hijack MPI Calls Scheduler decides how they are sent to the MPI run3me Scheduler plays out only the RELEVANT interleavings
MPI Program
Interposi3on Layer
43
Example Illustra3ng Goals 1 and 2
43
Process P0
R(from:*, r1) ;
R(from:2, r2);
S(to:2, r3);
R(from:*, r4);
All the Ws…
Process P1
Sleep(rand());
S(to:0, r1);
All the Ws…
Process P2
Sleep(rand());
S(to:0, r1);
R(from:0, r2);
S(to:0, r3);
All the Ws…
44
Example (contd.): Cover this case
44
Process P0
R(from:*, r1) ;
R(from:2, r2);
S(to:2, r3);
R(from:*, r4);
All the Ws…
Process P1
Sleep(rand());
S(to:0, r1);
All the Ws…
Process P2
Sleep(rand());
S(to:0, r1);
R(from:0, r2);
S(to:0, r3);
All the Ws… No deadlock
45
Example (contd.): … and also this case (no more)
45
Process P0
R(from:*, r1) ;
R(from:2, r2);
S(to:2, r3);
R(from:*, r4);
All the Ws…
Process P1
Sleep(rand());
S(to:0, r1);
All the Ws…
Process P2
Sleep(rand());
S(to:0, r1);
R(from:0, r2);
S(to:0, r3);
All the Ws…
deadlock
46
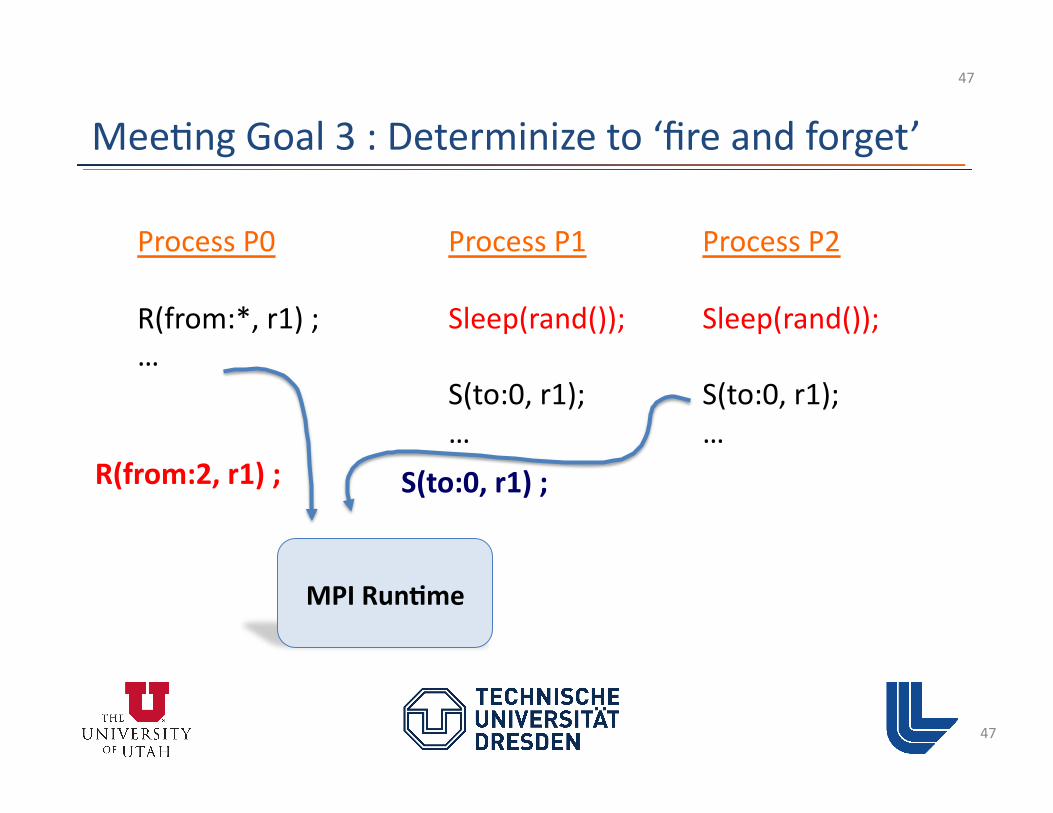
Mee3ng Goal 3 : Determinize to ‘fire and forget’
46
Process P0
R(from:*, r1) ; …
Process P1
Sleep(rand());
S(to:0, r1); …
Process P2
Sleep(rand());
S(to:0, r1); …
MPI Run?me
R(from:1, r1) ; S(to:0, r1) ;
47
Mee3ng Goal 3 : Determinize to ‘fire and forget’
47
Process P0
R(from:*, r1) ; …
Process P1
Sleep(rand());
S(to:0, r1); …
Process P2
Sleep(rand());
S(to:0, r1); …
MPI Run?me
R(from:2, r1) ; S(to:0, r1) ;
48
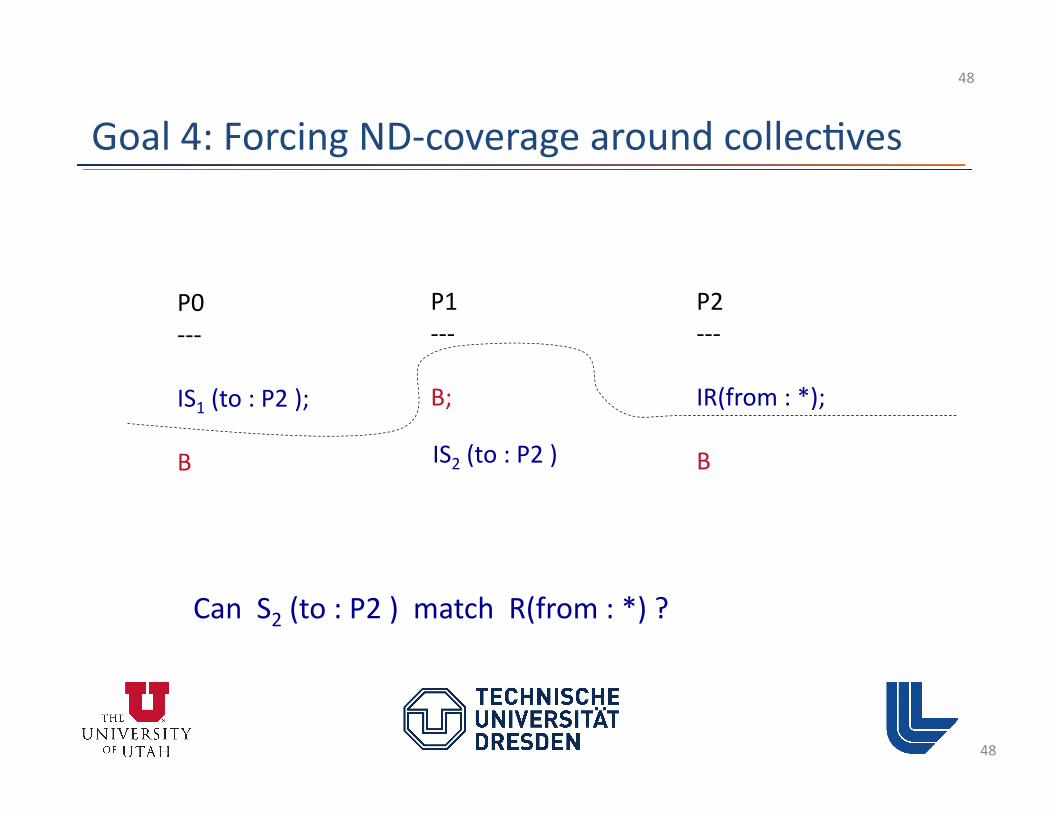
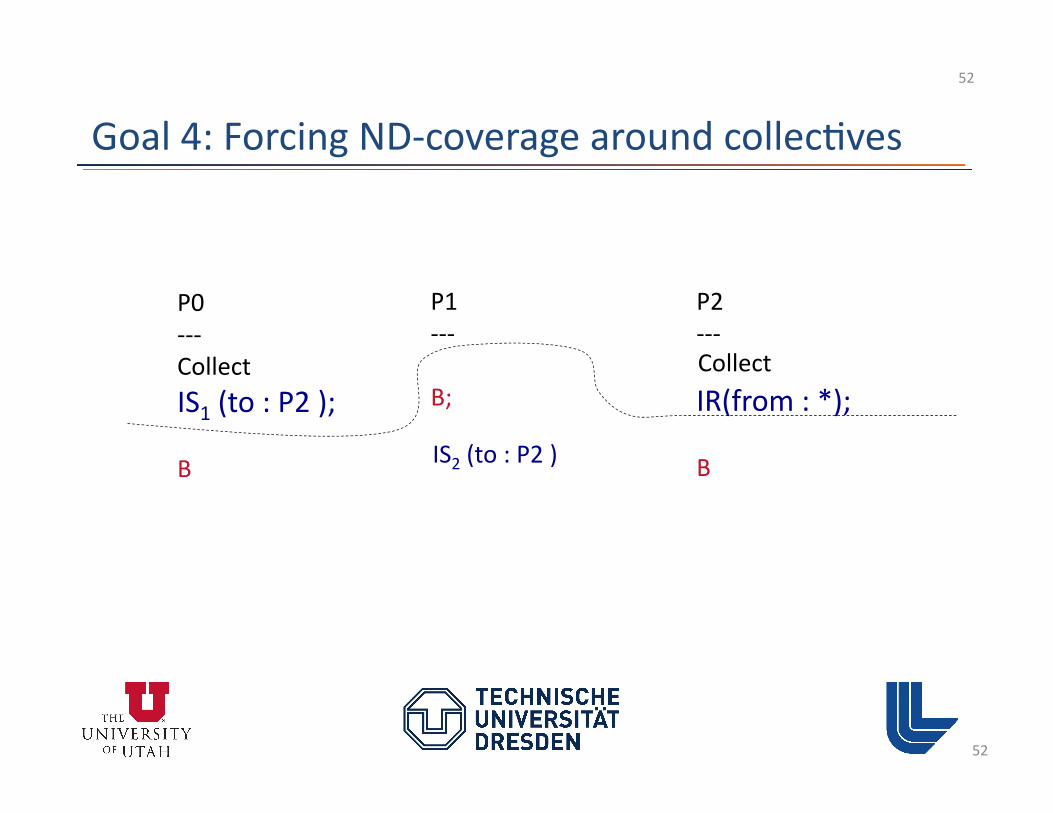
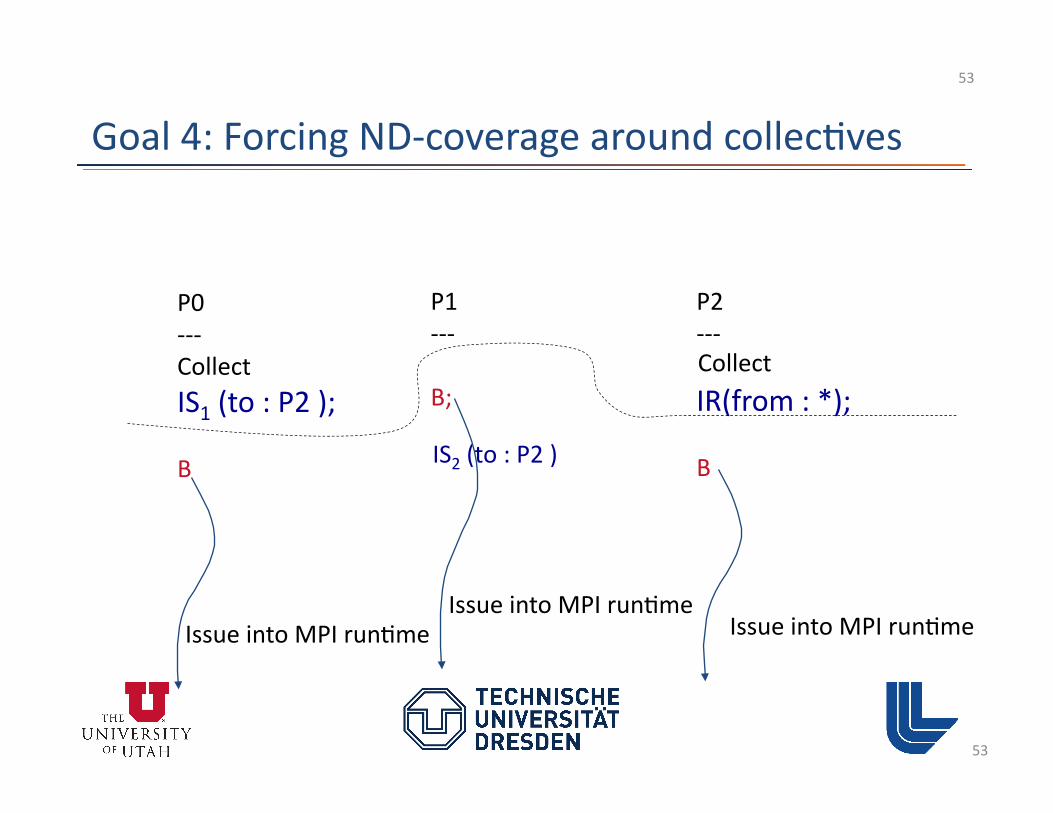
Goal 4: Forcing ND-‐coverage around collec3ves
48
P0 -‐-‐-‐
IS1 (to : P2 );
B
P1 -‐-‐-‐
B;
P2 -‐-‐-‐
IR(from : *);
B IS2 (to : P2 )
Can S2 (to : P2 ) match R(from : *) ?
49
49
P0 -‐-‐-‐
IS1 (to : P2 );
B
P1 -‐-‐-‐
B;
P2 -‐-‐-‐
IR(from : *);
B IS2 (to : P2 )
Can S2 (to : P2 ) match R(from : *) ? YES!
Goal 4: Forcing ND-‐coverage around collec3ves
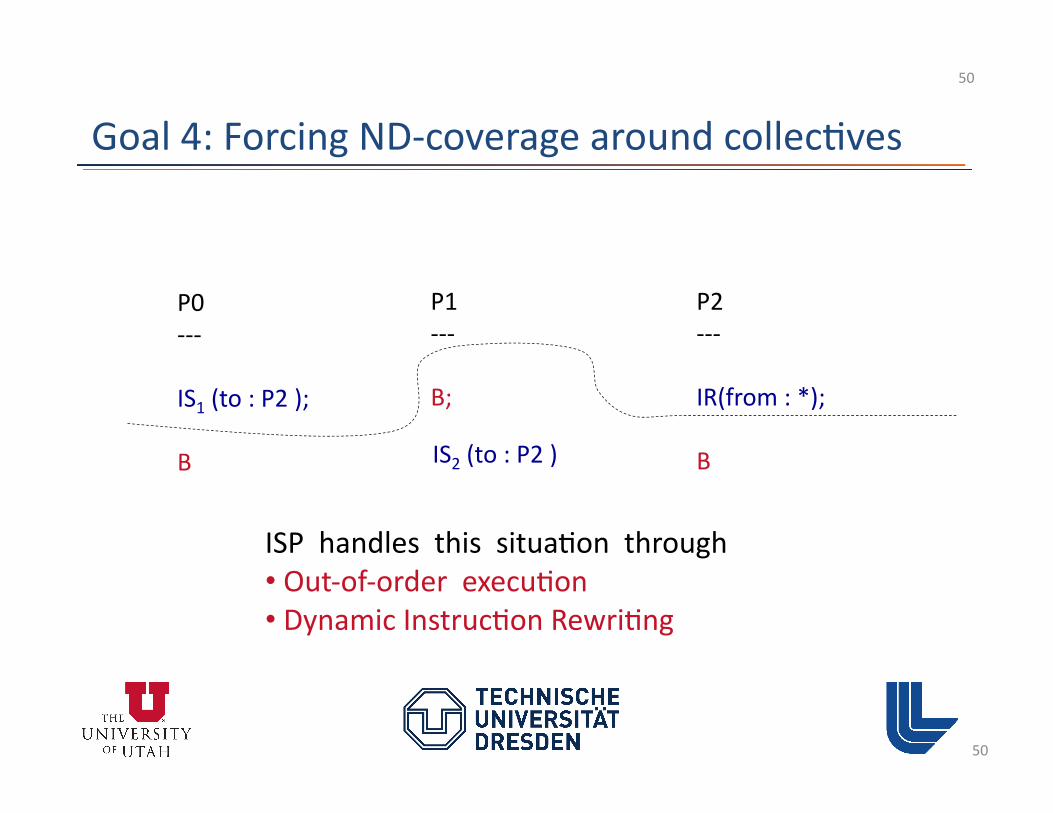
50
50
P0 -‐-‐-‐
IS1 (to : P2 );
B
P1 -‐-‐-‐
B;
P2 -‐-‐-‐
IR(from : *);
B IS2 (to : P2 )
ISP handles this situa3on through • Out-‐of-‐order execu3on • Dynamic Instruc3on Rewri3ng
--------------- End of Umpire Outfielder Report ---------------
79
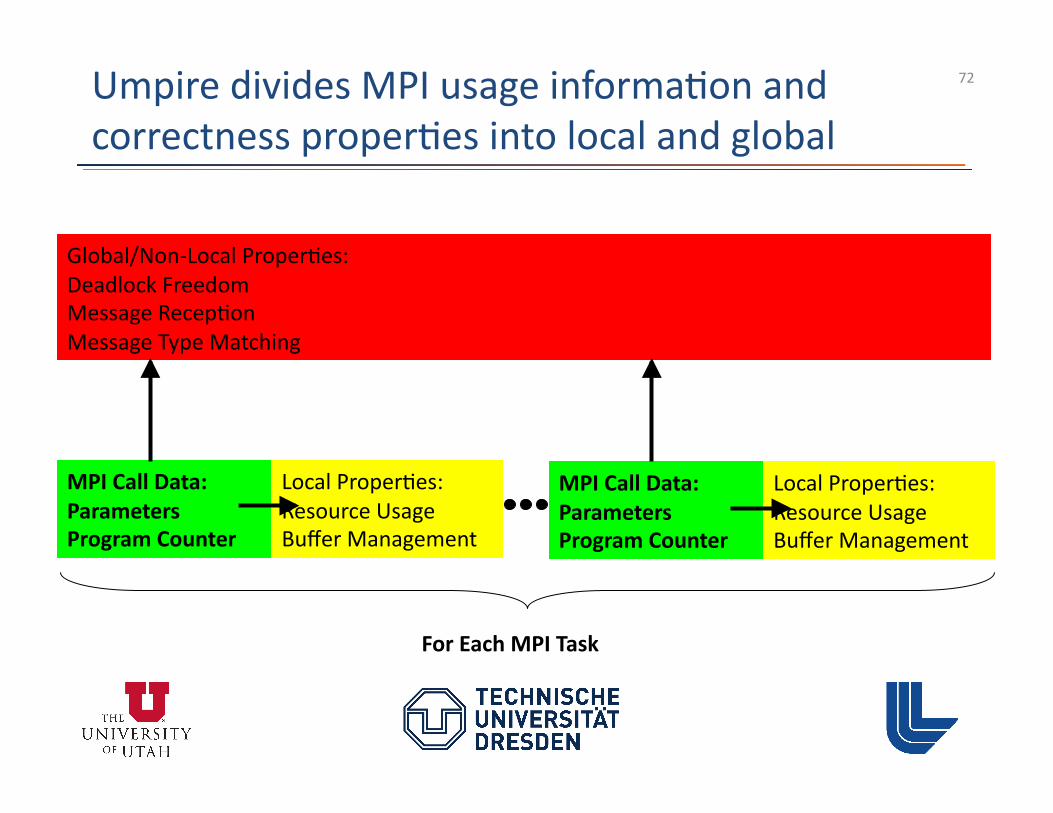
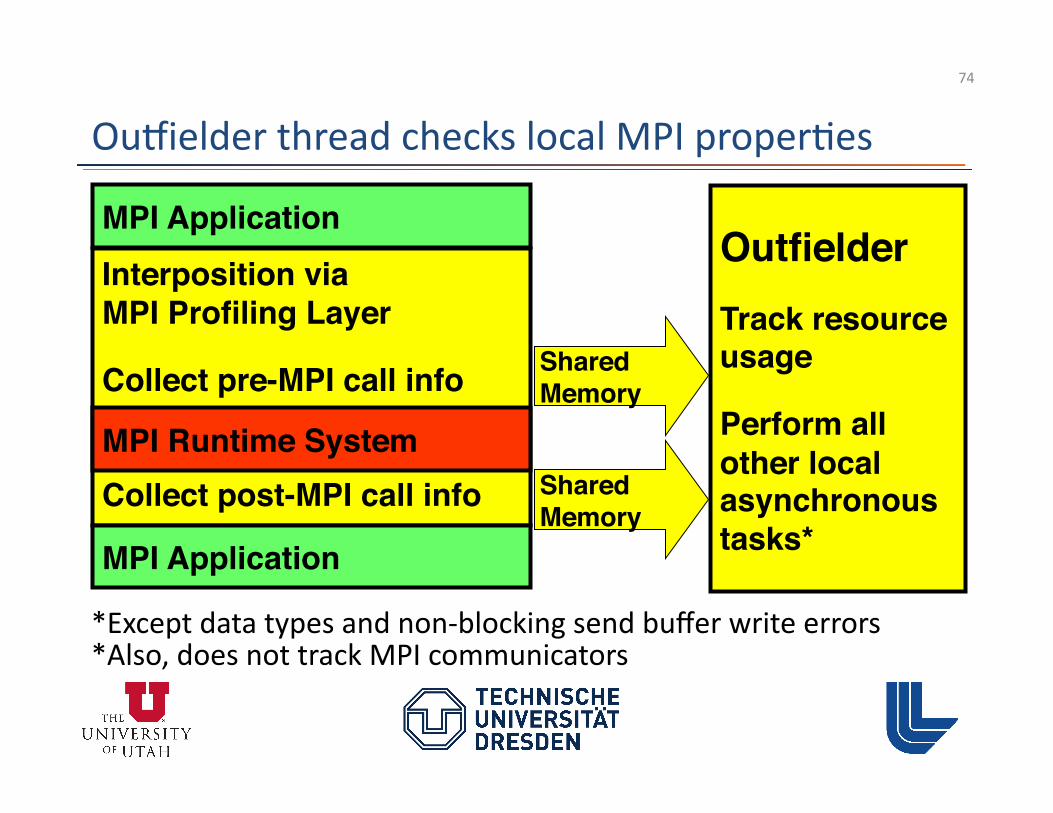
Umpire detects resource tracking errors
• Track most resources in ou�ielder – Track MPI assigned handle (follows PMPI call) – Variable may change without leak
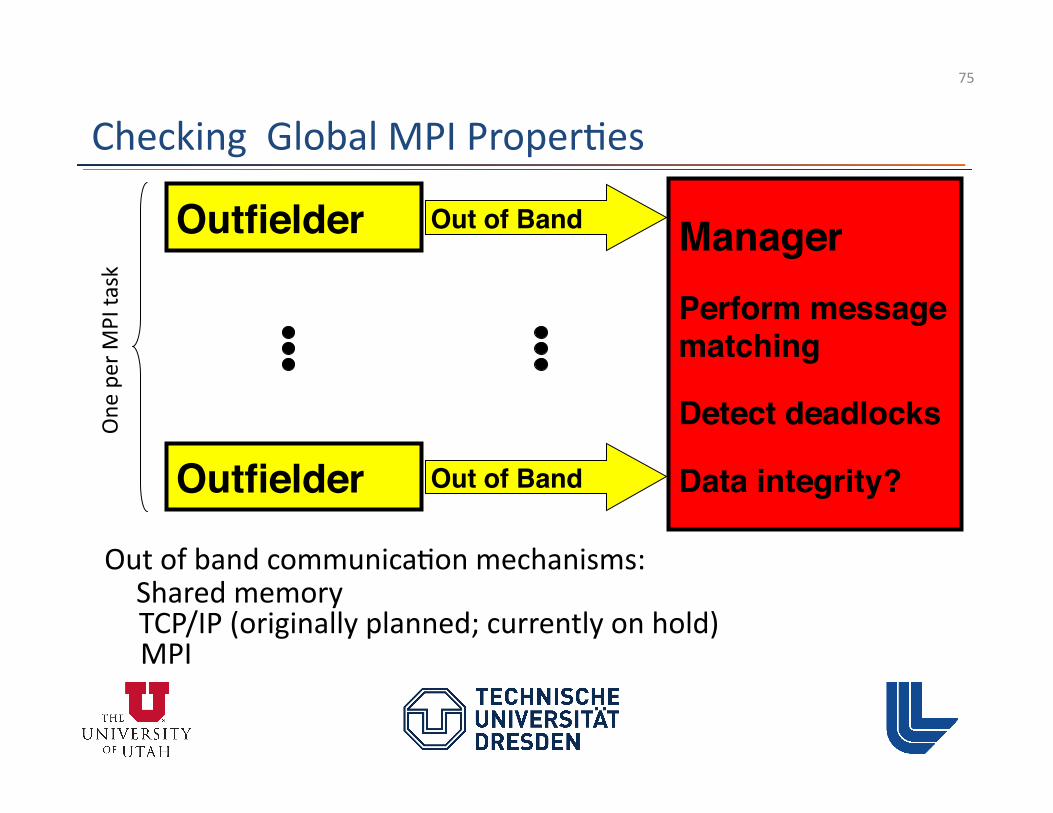
• Requests and communicators tracked by manager – Needed to perform MPI message matching
• Used to detect dropped requests • Also needed for type matching and deadlock detec3on
– Avoid duplicate storage by not tracking in ou�ielder
• Detect lost requests similarly to other resource tracking errors
• Also ensure proper use of persistent requests – Init (Start Complete)* Free
80
MPI Type Matching in Umpire • Represent types as regular expressions
– Determined in user process when commieed – Factor using “smallest first” canonical order
• e.g., {(c2(dc)3)3}, not {(c(cd)3c)3} • e.g., {((dc)2dc3)5}, not {((dc)3c2)5}
• Compare “greatest contained” factors – In manager, “on demand” – Ignore outermost count – Can match exactly or par3ally one-‐way or both – Compute and store “par3al count” – Both implies count at most one for one type – Remember results and combine exact matches
• Compare using send/recv count * outermost count
81
Umpire MPI Type Mismatch Output
--- Type Mismatches
57 type mismatch errors found: 1 occurence at 10001938 (MPI_COMM_WORLD rank 1)
• However, at scale: – Debug Server is a boeleneck – (Processes are no3fying – blocking – the server before calling the actual MPI call)
• MPI correctness checking needs to scale, e.g. a case from Sabine Roller and Harald Klimach (GRS-‐Sim, Aachen)
:: 1 ::
Runable Job
Smallest configuration providing usable results
needs 1680 cores and at least 4 days
103
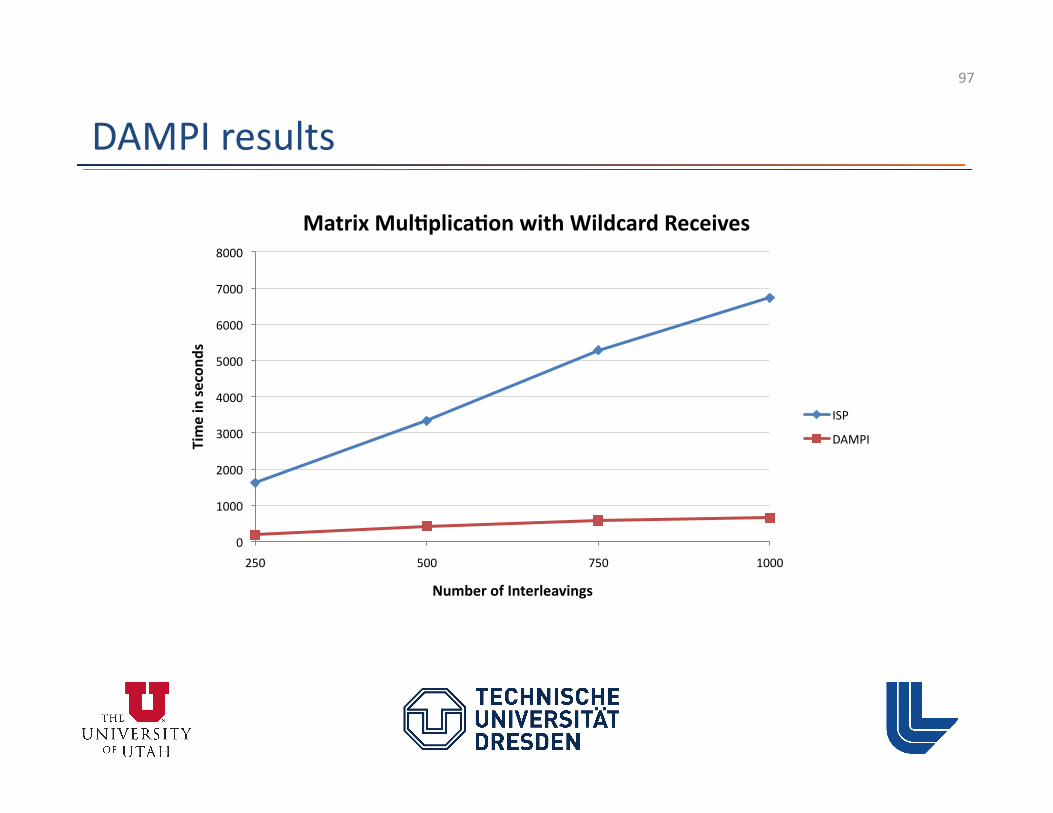
Correctness Checking at Scale
• Marmot performance test with SPEC MPI2007 – Combina3on with VampirTrace, only local checks
104
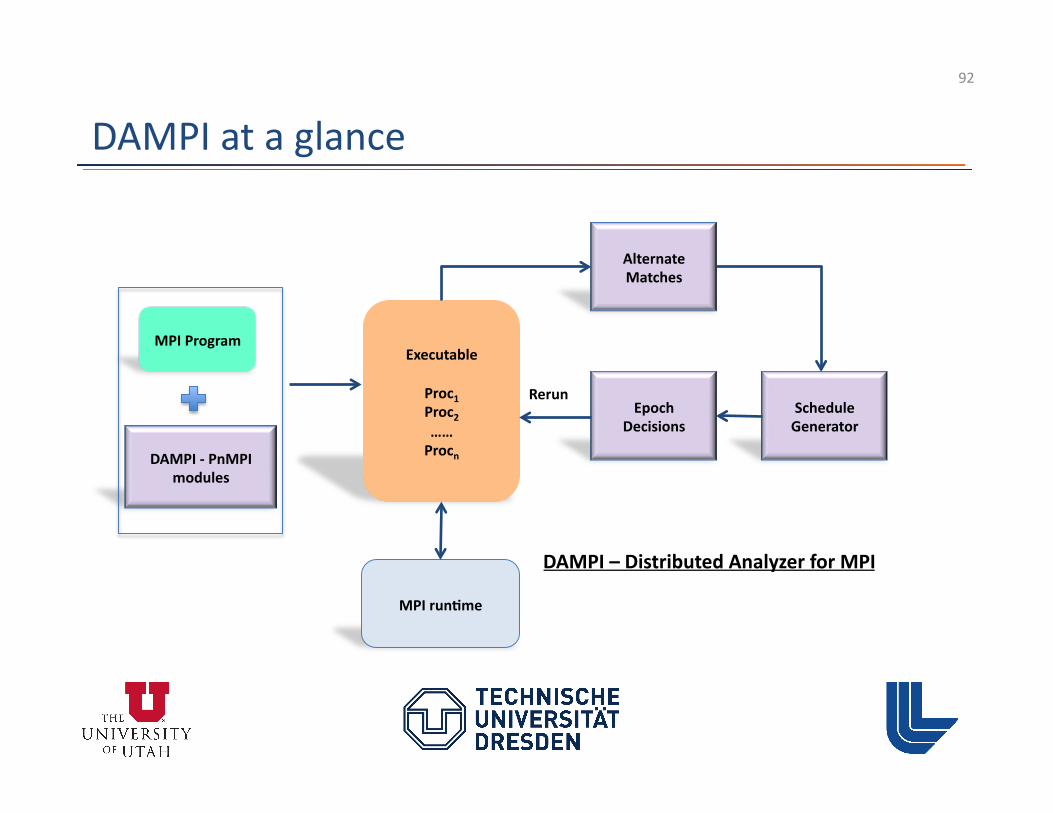
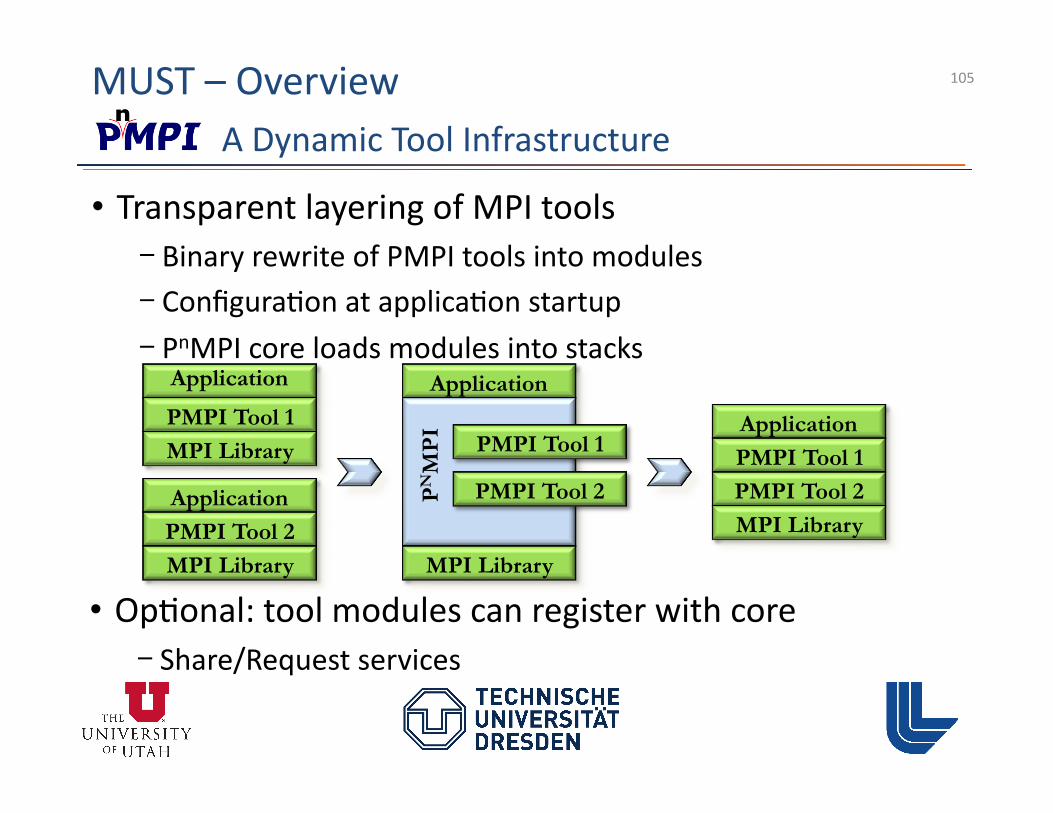
MUST – Overview
• MUST (Marmot Umpire Scalable Tool) = Umpire + Marmot + PnMPI – Local checks from Marmot – Non-‐Local checks from Umpire (e.g. Deadlock det.) – PnMPI as Infrastructure – Ongoing project, s3ll in development
• Goals: – Combine checks into one tool – Overcome scalability limita3ons – Maintainable and extendable checks (e.g. MPI-‐3)
105
A Dynamic Tool Infrastructure
Application
PMPI Tool 1 MPI Library
Application PMPI Tool 2 MPI Library
Application
MPI Library
PN
MP
I Application PMPI Tool 1 PMPI Tool 2 MPI Library
PMPI Tool 2
PMPI Tool 1
• Transparent layering of MPI tools - Binary rewrite of PMPI tools into modules - Configura3on at applica3on startup - PnMPI core loads modules into stacks
• Op3onal: tool modules can register with core - Share/Request services
MUST – Overview
106
MUST – Design
• Uses PnMPI and fine grained modules • Each correctness check is a module: - Needs specified input data - Can run anywhere - May use other modules for collabora3on
• Checks run on a place: - Applica3on thread or, - Extra thread/process
• Places connected with a communica3on network (TBON)
107
MUST – Required Tool Infrastructure (1/2)
• Example configura3on for 8 applica3on processes: - Layout for places - Communica3on system - Distribu3on of correctness checks
Tree network 0
2
4
6
1
3
5
7
108
MUST – Required Tool Infrastructure (2/2)
• MUST needs an infrastructure that provides: - Genera3on of MPI wrappers, - Spawning of extra tool threads/processes - Records to communicate MPI trace data, - A (flexible + scalable) communica3on system, - Forwarding of trace data to the checks, - Handling of applica3on crashes
• Exis3ng approaches: - MRNet is close, but: - No wrappers, No records, No data forwarding to checks, (No crash handling)
109
MUST – Marmot & Umpire
• MUST re-‐uses checks: – Local checks from Marmot – Non-‐Local checks from Umpire
0
2
4
6
1
3
5
7
Local checks: • Invalid arguments • Resource errors • Buffer errors • Call order errors …
Non-‐local checks: • Deadlock detec3on • Type matching • Collec3ve valida3on … (Umpire checks currently centralized)
110
MUST – Scalable Correctness Checks
• MUST uses a reduction network – Well suited to verify collective calls, e.g.: – E.g.: MPI_Bcast(buf, count, type, root, comm)
p1
• root must match on all tasks • Signature spawned by (count, type) must match on all tasks
• MUST uses a reduction network – Less suited for message matching
p1
p2
p3
q1
q2
p1
• N tasks • N2 possible matches exist
• M places • Each receives from N/M tasks • Each place can detect (N/M)2
matches • Total matches detected: M*(N/M)2 = N2/M E.g.: M=100 (N=1000) => first layer only detects 1% of the matches
N+((N-‐1)*N)/2 In fact …
Solu3on: Usage of a layer with inter-‐communica3on for matching
112
• MUST uses a 3-‐Layer sotware stack:
MUST
Generic Tool Infrastructure
PnMPI Module infrastructure, basic modules
Trace records, communication, places, ...
Checks
MUST – Sotware Layers
113
GTI – Overview
• GTI (Generic Tool Infrastructure) consists of: - Interfaces for modules with different tasks - Implementa3ons for these interface - A complex generator for wrapper genera3on, trace record genera3on, and instan3a3on
• MPI and MUST Agnos3c: - Basically an infrastructure for execu3ng analyses in a parallel environment - For MUST: “analysis” = “correctness check” - The API being used is an input for the GTI genera3on, e.g. For MUST this is an MPI descrip3on
114
GTI – Communica3on System (1/4)
• An instance of the tool has mul3ple layers • Pairs of layers may be connected (no cycles) • E.g.:
Layer 1 Layer 2 Layer 3
115
Layer 3
Layer 3
Layer 2 Layer 1
GTI – Communica3on System (2/4)
Layer 1 Layer 2
0
2
1
3
4
6
5
7
a
c
b d
• Each layer may contain mul3ple places • For MPI: first layer would contain all MPI tasks • E.g.:
116
Layer 3 Layer 1 Layer 2
GTI – Communica3on System (3/4)
0
2
1
3
4
6
5
7
a
c
b d
Reduc3on network
• A connec3on between layers i and j means that each process in i is connected to exactly one process of j
• E.g.:
117
Layer 3 Layer 1 Layer 2
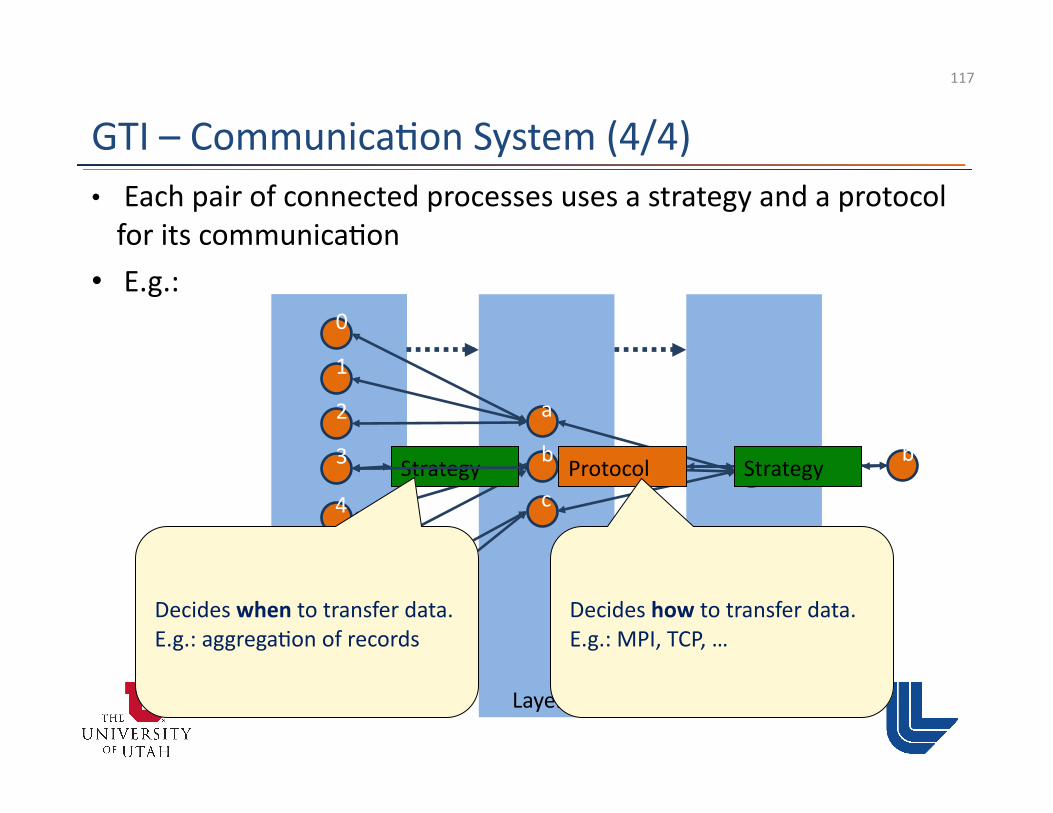
GTI – Communica3on System (4/4)
0
2
1
4
6
5
7
a
c
dStrategy 3 b bProtocol Strategy
Decides when to transfer data. E.g.: aggrega3on of records
Decides how to transfer data. E.g.: MPI, TCP, …
• Each pair of connected processes uses a strategy and a protocol for its communica3on
• E.g.:
118
GTI – Genera3on and Instan3a3on
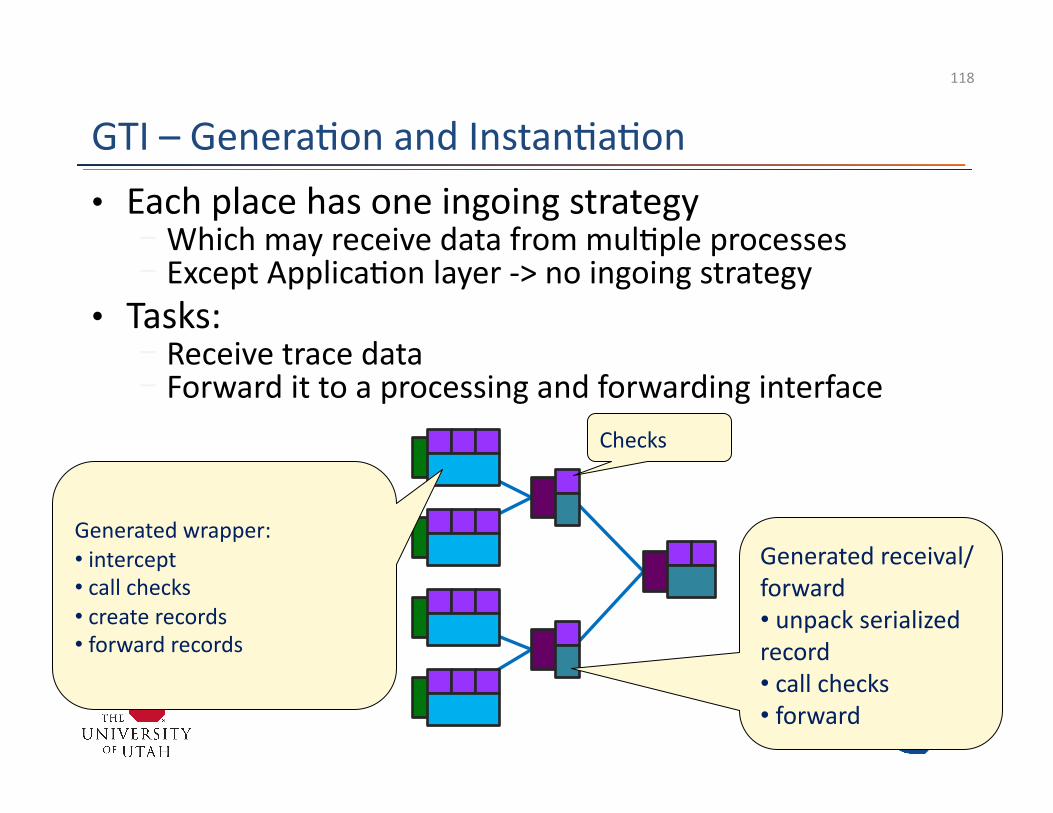
• Each place has one ingoing strategy - Which may receive data from mul3ple processes - Except Applica3on layer -‐> no ingoing strategy
• Tasks: - Receive trace data - Forward it to a processing and forwarding interface
Generated wrapper: • intercept • call checks • create records • forward records
119
GTI – Genera3on and Instan3a3on
• Modules for wrappers, records, and data forwarding need to be generated to instan3ate MUST
• The following things need to be specified: - What calls exist, what data do they provide - What checks exist, what data do they require - What tool layers are used, how are they connected, what checks do they run - What communica3on modules should be used
• This is specified in XML files • The “System Builder” (part of GTI) processes these
120
GTI – Genera3on and Instan3a3on GTI Spec. API
Spec.
API Spec.
Analysis Spec.
Analysis Spec.
Layout Spec.
Analysis Spec.
API Spec.
• What comm. Modules available • What types of places available
• What checks exist • What are their collabora3ons, inputs, …
• How many layers • Layer connec3ons • What checks(analyses) on each layer
• What calls can be wrapped • What are their arguments • What analyses use the arguments
121
GTI Spec. API
Spec.
API Spec.
Analysis Spec.
Analysis Spec.
Layout Spec.
Analysis Spec.
API Spec.
Layout GUI
GTI – Genera3on and Instan3a3on
122
GTI Spec. API
Spec.
API Spec.
Analysis Spec.
Analysis Spec.
Layout Spec.
Analysis Spec.
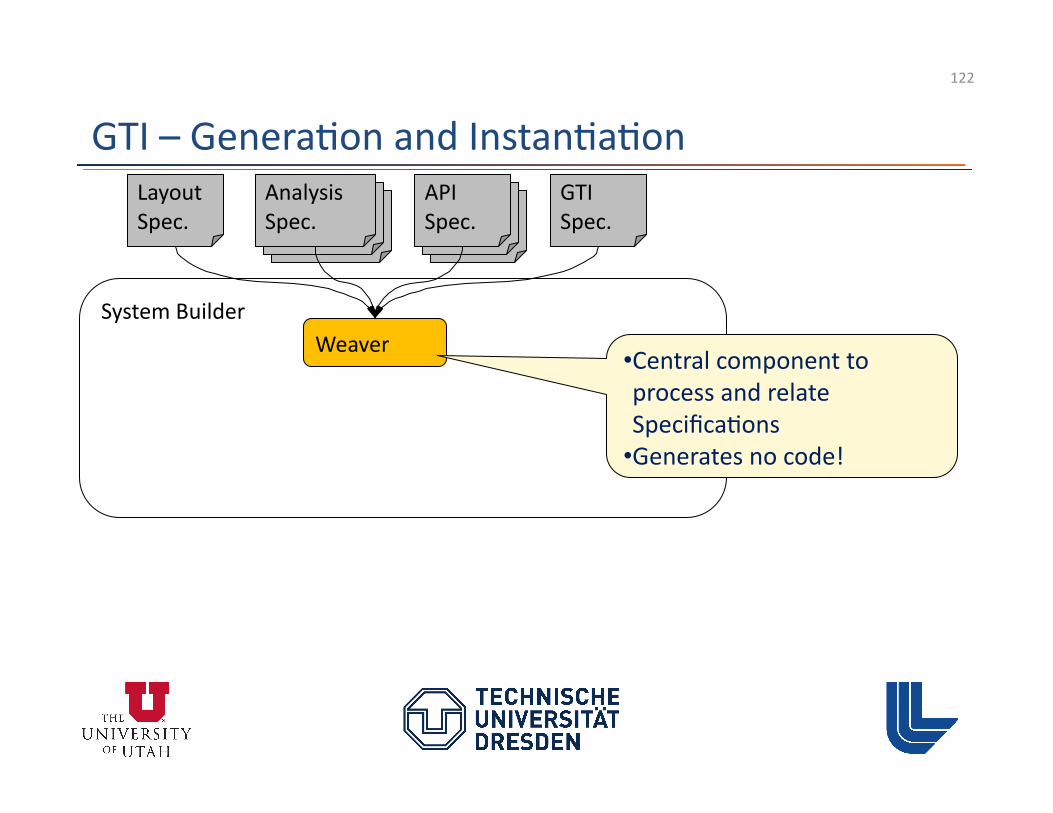
API Spec.
System Builder Weaver • Central component to
process and relate Specifica3ons
• Generates no code!
GTI – Genera3on and Instan3a3on
123
Receival/ Forward Gen Input Receival/ Forward Gen Input Wrapper Gen Input Wrapper Gen Input
GTI Spec. API
Spec.
API Spec.
Analysis Spec.
Analysis Spec.
Layout Spec.
Analysis Spec.
API Spec.
System Builder Weaver
Wrapper Gen Input Receival/ Forward Gen Input
• Specifica3on for wrapper and receival/forward genera3on
• XML files • One for each layer
• Specifica3on for wrapper and receival/forward genera3on
• XML files • One for each layer
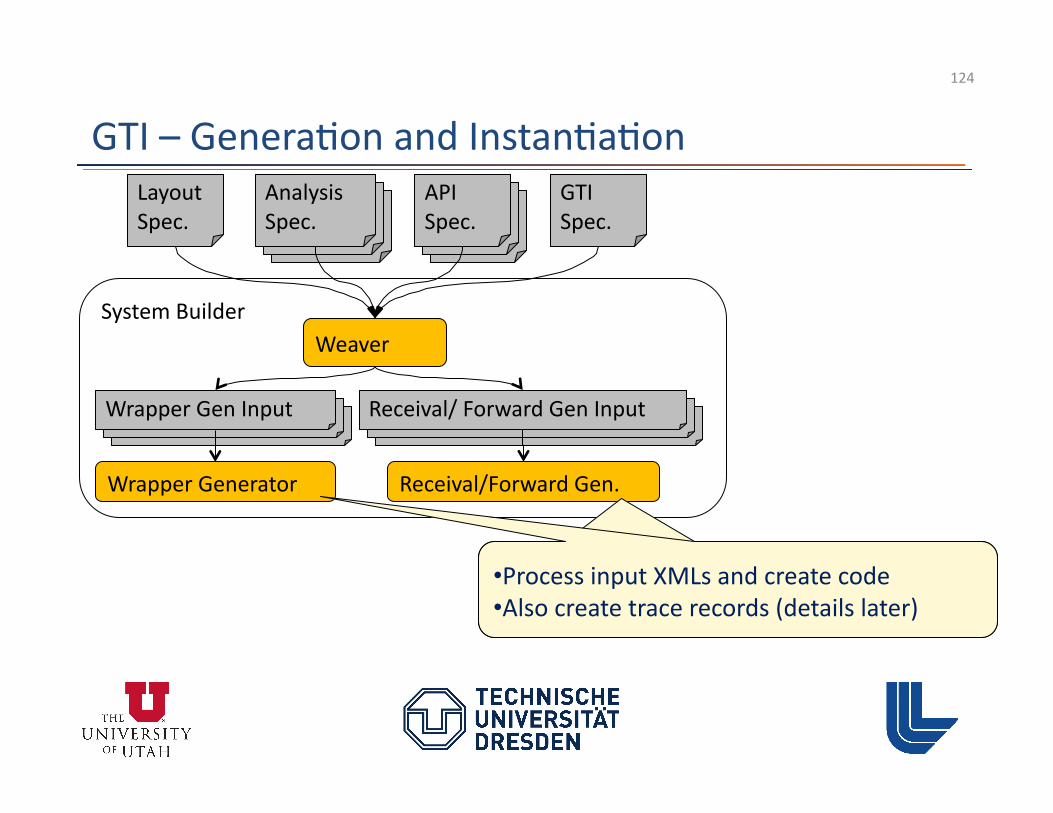
GTI – Genera3on and Instan3a3on
124
Receival/ Forward Gen Input Receival/ Forward Gen Input Wrapper Gen Input Wrapper Gen Input
GTI Spec. API
Spec.
API Spec.
Analysis Spec.
Analysis Spec.
Layout Spec.
Analysis Spec.
API Spec.
System Builder Weaver
Wrapper Gen Input Receival/ Forward Gen Input
Wrapper Generator Receival/Forward Gen.
• Process input XMLs and create code • Also create trace records (details later) • Process input XMLs and create code • Also create trace records (details later)
Receival/ Forward Gen Input Receival/ Forward Gen Input Wrapper Gen Input Wrapper Gen Input
GTI Spec. API
Spec.
API Spec.
Analysis Spec.
Analysis Spec.
Layout Spec.
Analysis Spec.
API Spec.
System Builder Weaver
Wrapper Gen Input Receival/ Forward Gen Input
Wrapper Generator Receival/Forward Gen.
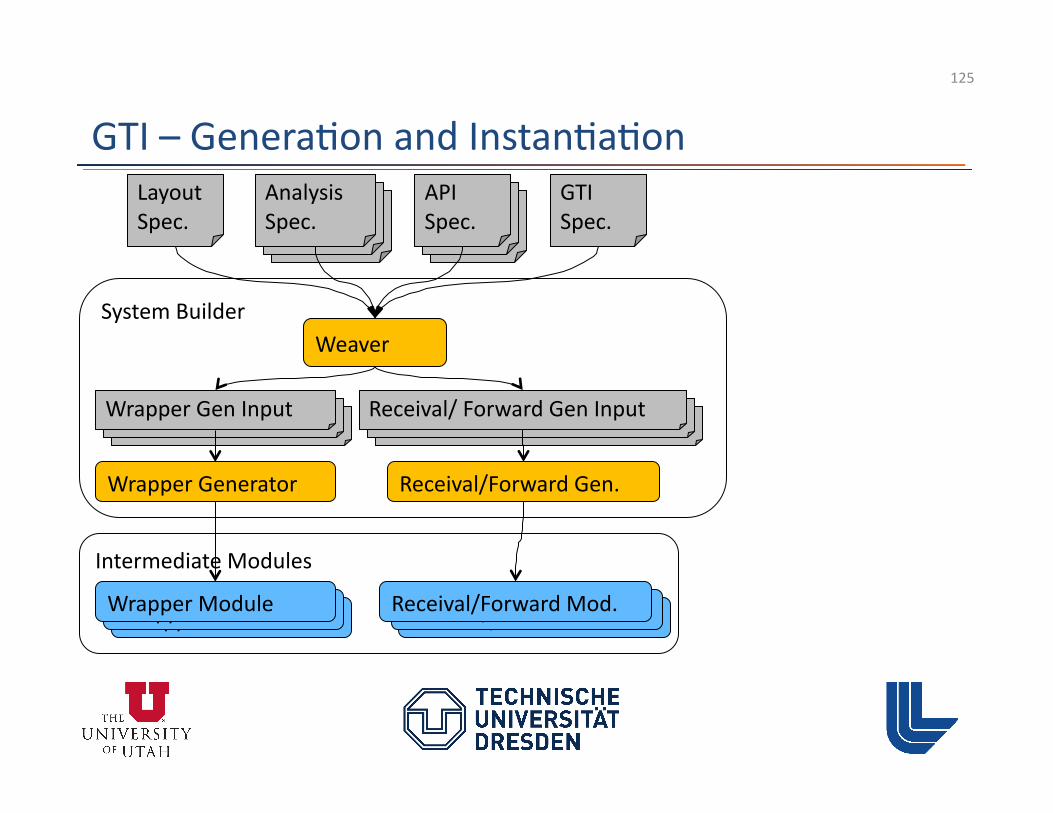
Intermediate Modules Module Library
Executable
Instance
Wrapper Module Receival/Forward Mod. PnMPI Conf.
GTI – Genera3on and Instan3a3on
127
Summary
• MUST: Scalable MPI correctness checking • Checks are modules, can run anywhere
– PnMPI as base infrastructure • Based on Generic Tool Infrastructure
– Very flexible (MPI agnostic) – Uses reduction networks – Instantiation uses generated code – Generation work on XML descriptions
128
MPI Run3me Error Detec3on in Hybrid OpenMP/MPI Applica3ons
Ganesh Gopalakrishnan1, Ma1hias Müller2, Bronis R. de Supinski3, Tobias Hilbrich2, Anh Vo1, Alan Humphrey1, and Christopher Derrick1
University of Utah1
Technische Universität Dresden2
Lawrence Livermore NaMonal Laboratory3
129
Overview
• OpenMP – Parallel threads, shared memory
• MPI – Parallel processes – No shared memory, messages used for exchange
... Process Thread
Memory
... MPI
130
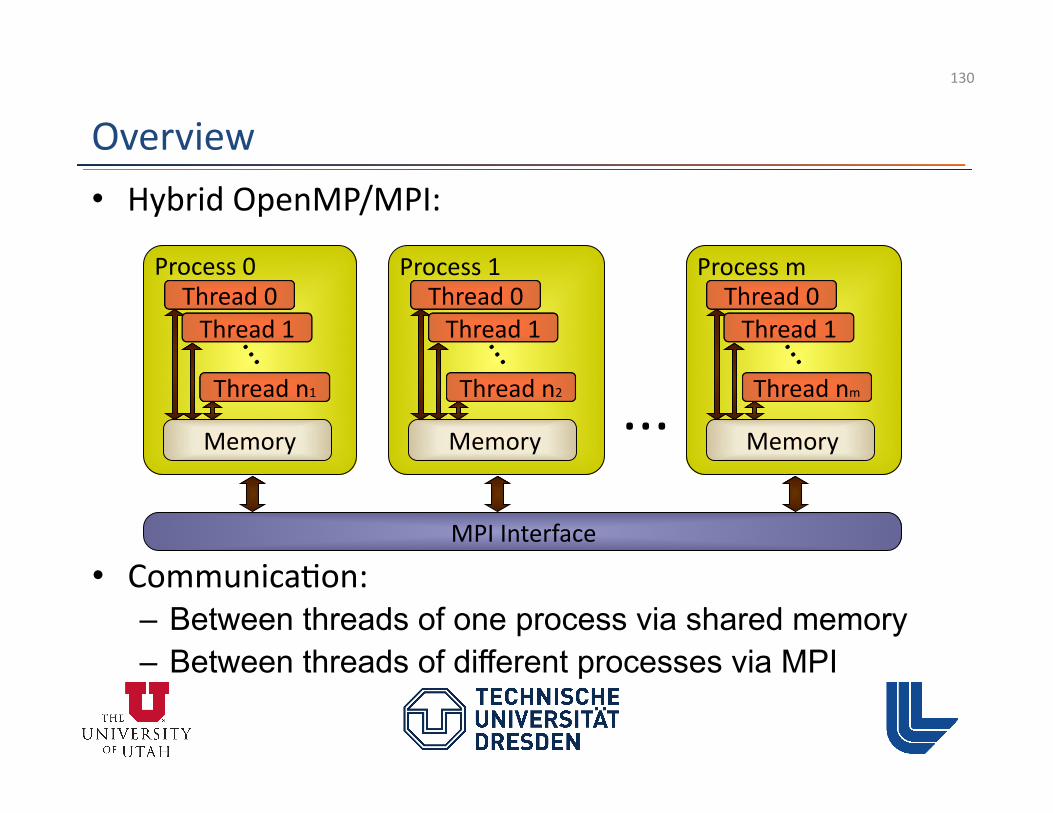
Overview • Hybrid OpenMP/MPI:
Process 0 Thread 0
Memory ...
Process 1
Memory
Process m
Memory
Thread 1
Thread n1
Thread 0 Thread 1
Thread n2
Thread 0 Thread 1
Thread nm
MPI Interface
• Communica3on: – Between threads of one process via shared memory – Between threads of different processes via MPI
131
Overview
• MPI-‐2 standard defines level of thread support: – MPI_THREAD_SINGLE: there is only one thread – MPI_THREAD_FUNNELED: only main thread performs MPI calls
– MPI_THREAD_SERIALIZED: only one thread is in MPI at a 3me
– MPI_THREAD_MULTIPLE: threads may call MPI simultaneously
• MPI_Init_thread used to request a certain level • Further restric3ons in the MPI Standard
– E.g.: A communicator, file handle or window must not be used in mul3ple collec3ve calls simultaneous
132
Marmot Support for Hybrid OpenMP/MPI
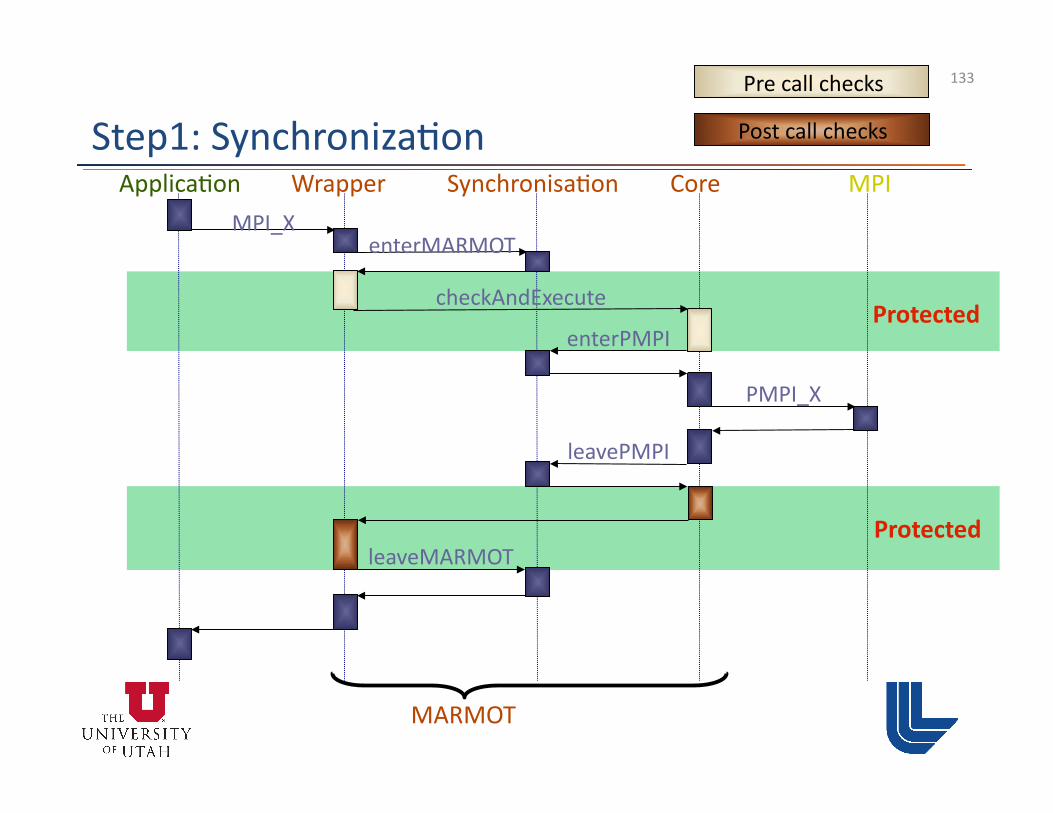
• Three steps: (1) Marmot extensions to operate in hybrid mode - Synchroniza3on
(2) Marmot checks for hybrid OpenMP/MPI errors - Usage errors of MPI that result from OpenMP usage - Detect errors that appear in a run with Marmot
(3) Advanced checks that detect errors in alterna3ve execu3on orders - Uses Intel Thread Checker
Step2: Marmot Checks (Example) • “Finally, in mulMthreaded implementaMons, one can have
more than one, concurrently execuMng, collecMve communicaMon call at a process. In these situaMons, it is the user’s responsibility to ensure that the same communicator is not used concurrently by two different collecMve communicaMon calls at the same process.” [MPI-‐1 p 130 lines 37-‐41]
• Implementa3on pseudo code: Pre execu?on code for all collec?ves: If check_is_comm_in_use (comm) == TRUE Then print_error() register_comm_as_used(comm)
Post execu?on code for all collec?ves: unregister_comm(comm)
135
Example – Code 25) //init MPI 26) MPI_Init_thread(&argc,&argv,MPI_THREAD_MULTIPLE,&provided); 27) MPI_Comm_rank(MPI_COMM_WORLD,&rank); 28) MPI_Comm_size(MPI_COMM_WORLD,&size); 29) 30) if ((rank == 0) && (provided != MPI_THREAD_MULTIPLE)) 31) prin� ("WARNING MPI_THREAD_MULTIPLE not supported\n"); 32) 33) //set num threads 34) omp_set_num_threads(4); 35) 36) #pragma omp parallel 37) { 38) MPI_Barrier(MPI_COMM_WORLD); //this is erroneous ! 39) }
/* The counter example given by PUG is : TRY HITTING THIS VIA RANDOM TESTING! t1.x = 2, t2.x = 10, i@t1 = 1, i@t2 = 0, that is, d_out[threadIdx.x+8*i]+=d_out[threadIdx.x+8*i+1]; d_out[2+8*1]+=d_out[10+8*0+1]; d_out[10]+=d_out[10] a race!!! */
150
Real __syncthreads() error
150
__global__ void computeKernel(int *d_in,int *d_out, int *d_sum) { // *d_sum=0;
// PUG found this synchroniza3on error if(threadIdx.x%2==0) { for(int i=0; i<SIZE/BLOCKSIZE; i++) { d_out[threadIdx.x+SIZE/BLOCKSIZE*i]+=d_out[threadIdx.x+SIZE/BLOCKSIZE*i+1];
__syncthreads(); } } …
151
Combined MPI + CUDA / OpenCL verifica3on • Separately verify kernels using PUG (e.g.) • Put kernel codes within MPI and verify using one of the tools described here
• PUG can generate input sets that MPI tes3ng must ‘hit’ when invoking kernels
• Many open issues:
– Mul3ple concurrent kernel launches – Data sharings between kernels and MPI
• Much more research is needed
152
Concluding Remarks and Live-‐DVD Distribu3on
Ganesh Gopalakrishnan1, Ma1hias Müller2, Bronis R. de Supinski3, Tobias Hilbrich2, Anh Vo1, Alan Humphrey1, and Christopher Derrick1