53
Who are we? what is it? what can I do with it? – and why does it matter? Some thoughts on identity and identification in an increasingly complex environment
| Date post: | 18-Jul-2015 |
| Category: |
Education |
| Upload: | charleston-conference |
| View: | 364 times |
| Download: | 0 times |

Who are we? what is it? what can I
do with it? – and why does it matter?
Some thoughts on identity and identification in an increasingly complex environment

Agenda
Introduction
Mark Bide (EDItEUR)
Identifying people, places and organizations
Helen Henderson (Ringgold)
Identifying resources
Brian Green (International ISBN Agency)
Identifying deals
Mark Bide (EDItEUR)

Introduction
Mark Bide

The things we need to identify: the <indecs>
model of commerce
Peoplemake
Stuffis used by
Deals
do
about

What are identifiers?
An identifier is a unique expression in a written format either by a code, by numbers or by the combination of both to distinguish variations from one to another among a class of substances, items, or objects….
In computer science, identifiers are lexical tokens (that is, “nouns”) that name entities (or “things”). The concept is analogous to that of a "name." Identifiers are used extensively in virtually all information processing systems.
Naming entities makes it possible to refer to them, which is essential for any kind of symbolic processing.
[Based on Wikipedia]

Why do we need identifiers?
Identifiers are “just” a special class of name
Unique within a given context
Why do we assign identifiers?
Collocation – to bring together instances of the same thing
Disambiguation – to distinguish things that are not the same
What does “the same” mean?
Whether things are or are not the same is always contextual
For example, an ISBN identifies a class of individual instances as
being “the same” for particular purposes – meaning is not
universal
Why does this matter?
Unambiguous communication…
…particularly from machine to machine (people don’t often use
unique identifiers in discourse – “that one over there” is usually
enough)

Why do we need standard identifiers?
When there is a need to communicate across
organizational boundaries – within any sort of
“supply chain”…
…particularly where anyone in the supply chain
needs to manage and aggregate information from
multiple sources
That means nearly everyone, particularly in a digital
supply chain
What matters about standard identifiers?
That their semantic should be clear to everyone…
…in other words, everyone in the chain knows what type
of thing they are identifying

Why do we need identifiers?
“The Web was designed as an information space, with the
goal that it should be useful not only for human–human
communication, but that also machines would be able to
participate… One of the major obstacles to this has been
the fact that most information on the Web was designed
for human consumption.”
Tim Berners-Lee The Semantic Web (1998)

So, if we are to make the semantic web a
reality…
We need to establish “chains of identifiers”
Identifiers with explicit and well understood semantics
We need to link them together with “relators” which
have well-defined semantics
We need to establish and manage the relationships that
are important to us
We need to be careful about trivializing the task
Everything is related to everything else at some level
Saying that two things “are the same” is complex,
because it is always contextual [an ISBN does not identify
“a book”]

Identifying people, places and
organizations
Helen Henderson

Types of Identifiers (in our space)
o Organizations
o D-U-N-S
o …. and many tax related identifiers
o ISIL
o ISNI
o MARC Org Code
o OCLC Symbol
o People
o ISNI
o Researcher ID
o Scopus Author Identifier
o ORCID
o Places
o GLN
o SAN
o UN LOC

What is the need?o Places
o Delivery of physical objects
o Tax regime
o People
o Rights payments
o Author affiliation (ownership)
o Disambiguation
o Organizations
o Delivery and entitlements
o Access rights
o Hierarchy
o Usually comes down to …… MONEY

Placeso GLN (Global Locator Number)
o Physical location
o Legal entity
o Maintained by GS1 (formerly EAN International)
o SAN (Standard Address Number)
o Specific street address
o ANSI/NISO standard
o Maintained by Bowker
o UN LOC (United Nations Code for Trade and Transport Locations)
o Trade locations (e.g. airports, ports)
o Coordinates
o Maintained by UN Economic Commission for Europe

Peopleo ISNI (International Standard Name Identifier)
o “Names” include people and organizations
o Initial emphasis rights holders
o Maintained by International ISNI Agency (consortium of national libraries and bibliographic utilities)
o Virtual International Authority File
o Jointly run by LC, BnF, DNB and OCLC
o Implemented and hosted by OCLC
o ~20 files from around the world
o 13 million name records
o 10 million clusters
o Plan to include other names
• Corporations, works, geographics, families, imaginary characters, etc.
• Not topical subject headings

More Peopleo Proprietary Author Identifiers
o Scopus (Elsevier)
o Scholar Universe (COS)
o Researcher ID (Thomson Reuters)
o RePEc (Research Paper in Economics)
o ORCID (Open Researcher and Contributor ID)
o Open version of Thomson Reuter’s Researcher ID
o Most ‘social’
• Claiming IDs
• Interactive verification of associated works
• Pulling together several current initiatives
o Driven by STM, university communities
o Primarily interested in researchers
o Large number of participants
o Mostly concerned with present and future names

Organizations
o OCLC Symbol
o Library identifier
o Maintained by OCLC
o ISNI (International Standard Name Identifier – ISO 27729)
o Recently adopted
o Emphasis on individuals
o Central registry
o Registration agencies
o D-U-N-S …. and many tax related identifiers
o Related to corporate entities
o ISIL (International Standard Identifier for Libraries - ISO 15511)
o Libraries only
o National agencies
o MARC Org Code
o Library identifier
o Maintained by LC

More organizationso OCLC WorldCat Registry ID
o Library identifier
o Voluntary registration and maintenance
o NISO I2
o International Institutional Identifier
o Hierarchical structure with relationships
o Identifies “licensing units”
o May be a sub-registry of ISNI, still to be decided
o Ringgold Identifier
o 200,000 institutions or institutional entities
o Worldwide, all categories
o Used by over 40 publishers and agents

Existing Identifiers Investigated for use with I2
Identifier Name Current Status
ISIL (ISO 15511) International Standard
OCLC symbol OCLC specific
OCLC WorldCat Registry ID OCLC specific
MARC organization code MARC standard
ISNI (ISO 27729) Final Committee draft
SAN Standard address number NISO standard Z39.43-1993
GLN Global location number GS1 (formerly EAN international)
DUNS Data Universal Numbering Dun and Bradstreet
International Standard for Describing Institutions with Archival Holdings Information (ISDIAH) New standard 2008 – International Council on Archives

What is next for I2?o NISO Working Group
o Publishers
o Agents
o Distributors
o Libraries
o Hosting services
o Institutional Repositories
o Scenarios
o Electronic supply chain
o Consortia
o Research funding
o Inter-library loan
o Implementation

Identifying resources
Brian Green

… e-books in particular
Brian Green
International ISBN Agency

“What matters is that everyone in the chain
knows what type of thing they are identifying”
FRBR: Endeavour
ITEM
WORK
EXPRESSION
MANIFESTATIO
N
realization
embodimen
t
exemplar
realizationO
f
embodiment
Of
exemplarOf
Book Industry
concept: e.g.
Moby-Dick
e.g. author’s
original text
both concept and
content

ISTC/ISBN
ACCESSIO
N Number
ISTC
ISBN
embodimen
t
exemplar
embodiment
Of
exemplarOf
“What matters is that everyone in the chain
knows what type of thing they are identifying”

“Collocation – to bring together instances of
the same thing”
The International Standard Text Code
Unambiguously identifies a textual work, even though it
may be published in many different forms (One ISTC
may link to many ISBNs)
For use in improved discovery services, collocation,
rights and royalties etc.
Identifies content separately from the products which
contain it
Also identifies the relationships between items of content
(ONIX for ISTC registration)
e.g. Abridged, Annotated, Compilation, Critical, Excerpt,
Expurgated, Non-text material added or revised, Revised,
Translated
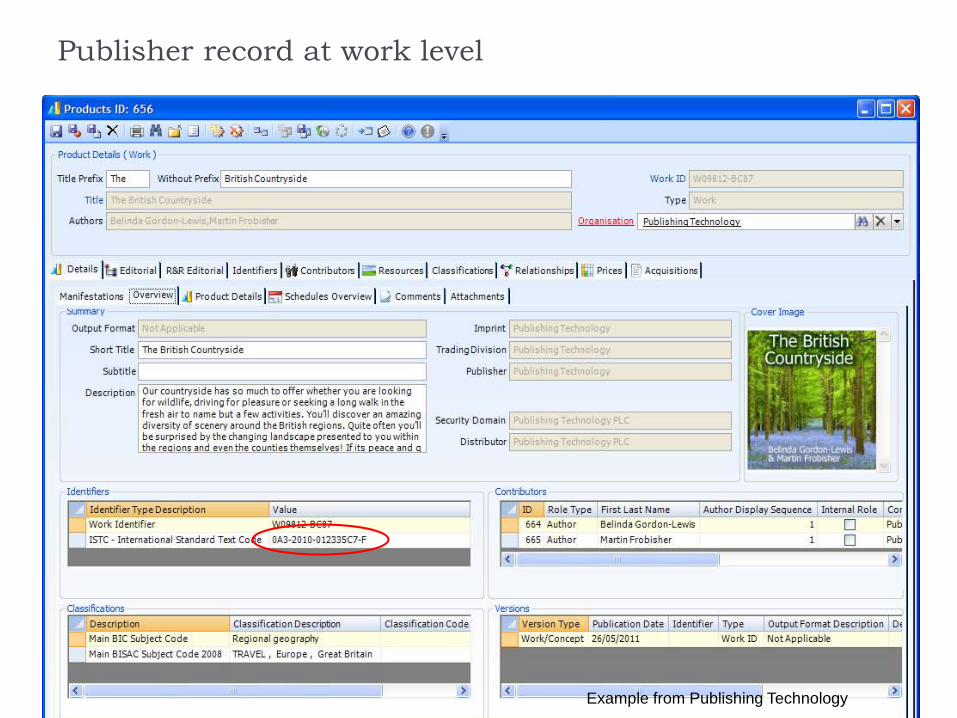
Publisher record at work level
Example from Publishing Technology

Link to various manifestations
Example from Publishing Technology

Link to various manifestations
Example from Publishing Technology
One metadata
record – multiple
ISBNS

“Disambiguation – to distinguish things that
are not the same”
Under “Rules of assignment”, the 2005 revision of
the ISBN standard (ISO 2108) says:
Different product forms (e.g. hardcover, paperback,
Braille, audio-book, video, online electronic publication)
shall be assigned separate ISBNs
Each different format of an electronic publication (e.g.
‘.lit’, ‘.pdf’, ‘.html’, ‘.pdb’) that is published and made
separately available shall be given a separate ISBN.
Seemed adequate at the time but file format not
really an appropriate indicator of different products

What differentiates e-book products?
Ability to render book
Does it work on my device/platform/software?
User’s experience and usage rights
What can I do with it?
File format only part of the story. DRM is what really
differentiates e-book products and platforms

Why identify separate e-book products?
To ensure that the e-book ordered is the correct one
for the user’s e-reader device and/or software
platform
To enable bibliographic databases to provide
information about the different available versions of
an e-book
To facilitate electronic trading of e-books, particularly
where multiple formats are sold through the same
channel
To facilitate product level reporting of sales and
usage and facilitate management of e-book products

The e-book supply chain
For printed books, publishers assign ISBNs to each
format, and that product and it’s ISBN remains
constant throughout the supply chain
For e-books, there is an additional layer of
intermediaries providing conversion services to
publishers and producing new e-book products
Many publishers only produce a single generic file
format (e.g. “.epub” or “PDF”), and intermediaries or
Internet retailers add technical rights protection
(DRM) and create different formats/products

Publisher
Library
platformConversion
Random,
HarperCollins,
Faber...
Libre Digital,
Ingram,
PubDim, VCI...
XML
Disassemble
Markup
Convert
Master
format
.epub
.epub/PDF
.epub
MyiLibrary, Overdrive etc.
NetLibrary
Add DRM
Library
EDI order
EDI order
Library
ebrary
Add DRM
Convert
Add DRM
Acct No
epub+DRMOPAC
Library ID
Consumer
Overdrive “white label”...
Jobber
YBP, Ingram etc

New ISBN rule introduced 2008
Since some publishers do not provide separate
ISBNs for each version and some customers,
including libraries, need unique identification of
products from different platforms with different
functionality…
If a publisher does not identify each format with a
separate ISBN, intermediaries/re-sellers may do so
on their behalf
Not ideal but a necessary compromise until publishers
assign their own ISBNs
Requires central bibliographic agency to collect and list
ISBNs and related metadata

What’s actually happening?
Everything. It’s like the 1960’s before ISBN.
Some publishers assign separate ISBNs to each
version
Some assign the same ISBN to all versions
Some publishers assign an ISBN to the epub file and
let third parties assign their own ISBNs or proprietary
identifiers to their versions
Sometimes these proprietary “ISBN-like” identifiers
actually duplicate ISBNs assigned to books already
published elsewhere

All
different

All the
same

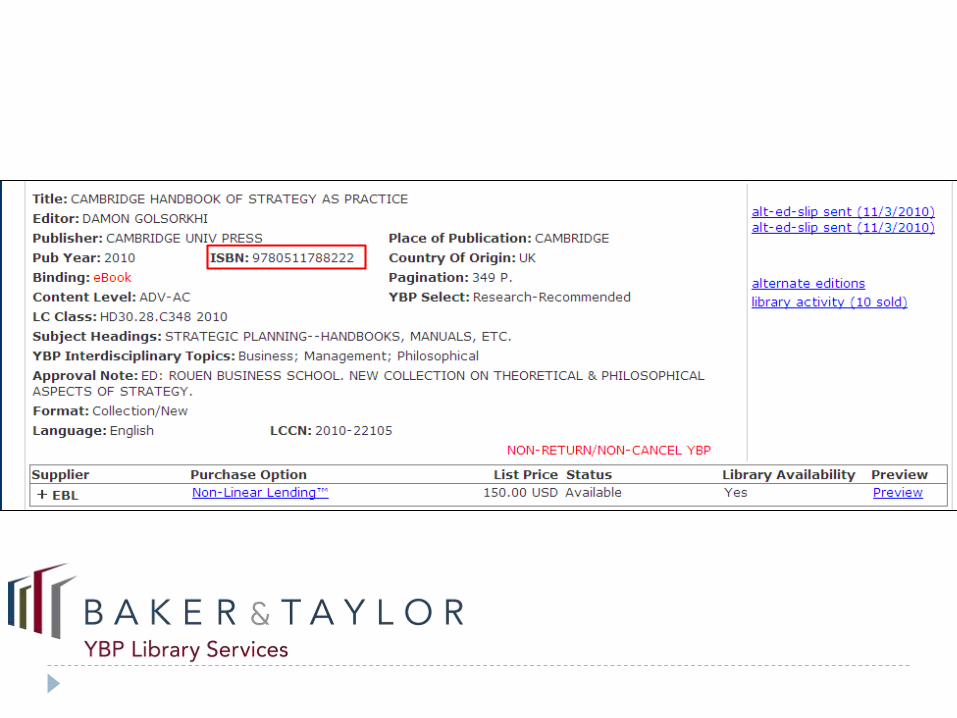





“Whether things are or are not the same is
always contextual”
Results of ISBN survey 2009/2010:
There is a need for each digital format to be
separately identified at various points in the supply
chain
However there seems to be a need for a more
abstract generic identifier to collocate different
versions of the same books
ISTC identifies underlying textual works and is a
potentially useful way of aggregating different
manifestations and their ISBNs regardless of media

“The use of a single ISBN would enable provider-neutral records and
act similarly to eISSNs. Open link resolution, federated search, and
unified discovery platforms would also benefit from the use of a single
eISBN.
It is also useful to have some sort of identifier by platform, particularly
for back-end vendor operations.”
Library comments from ISBNsurvey
“Essential to have a single 'matching point' to compare collections, pull-
in usage data, exclude already-purchased titles from lists, etc.
Useful to have a second ISBN for each platform as different platforms
have different DRM etc. Combined with a single ISBN for all formats,
would help to identify where we have purchased the same title from
more than one platform.”

In summary
The use of a single ISBN to identify multiple e-book formats is confusing and potentially unsafe
If two things are given the same identifier it becomes very hard to distinguish between them if/when we need to
The International ISBN Agency continues to recommend that publishers should assign ISBNs to each e-book version separately available (n.b.“version” needs defining)
…but we also need to use identifiers at higher levels of abstraction (ISTC?)
Consistent application of standard identifiers is essential
“particularly where anyone in the supply chain needs to manage and aggregate information from multiple sources”

Identifying “deals”
Mark Bide

We are getting better at automating license
communication
48
Creative Commons: http://creativecommons.org –standard licences most appropriate for noncommercial content [?] machine and human readable – and related approaches such as the UK’s “Open Government Licence”
ONIX-PL: www.editeur.org – a standard for the communication of publishers licenses to libraries, to make complex information human readable
ACAP: www.the-acap.org – a standard machine to machine communication of permissions, developed mainly in support of the news sector
PLUS Coalition: http://www.useplus.com – standards for licensing photographs and other visual images, machine and human readable
ODRL: http://odrl.net/ Open Digital Rights Language –“machine decidable permissions” – v2.0 in development

Related infrastructural developments
49
The Book Rights Registry (“the Google Settlement”):
http://books.google.com/googlebooks/agreement/
Global Repertoire Database (GRD)
http://globalrepertoiredatabase.com/faq.html
The ARROW project:
http://www.arrow-net.eu/
PLUS seeking to establish registries for visual
images

Standards for license identification
Musical Works License Identifier (MWLI)
There appears to be work to do here…..

Conclusions and discussion

Some questions for discussion
At what level would you like to see manifestations
separately identified?
By channel?
By DRM / usage features?
Should 2 e-book versions from different channels but with
the same usage features share an ISBN
At what level would you like to see them collocated?
All manifestations regardless of media?
All e-books (but excluding print and audio)?
What can libraries do about it?

Helen Henderson [email protected] Green [email protected]
Mark Bide [email protected]
ISBN: www.isbn-international.org
ISTC: www.istc-international.org
53
Thanks for coming


















