19
Concept introduction series Anand, 26-Feb-2015
| Date post: | 07-Aug-2015 |
| Category: |
Software |
| Upload: | anand-srinivasan |
| View: | 189 times |
| Download: | 1 times |

Concept introduction series
Anand, 26-Feb-2015

What this deck aims to convey and what it doesn’t?

3
Captures some attributes of RDBMS (SQL DB!) with the intent of providing the context behind non-relational database models
Does not attempt to capture the pro-s or con-s of RDBMS. Does not attempt to explain RDBMS’ role in modern server architectures etc.

Some attributes and their implications

5
{
id: 223091
job: “test.feature_x”
status: “complete”
events:{
{id: 220923232, type: started, time: 13:20:21, date: 03-06-2016}
{id: 220923439, type: restarted, time: 13:20:30, date: 03-06-2016}
{id: 220923439, type: finished, time: 12:24:31, date: 03-06-2016}}
{description: {console_output: {blah blah}}}
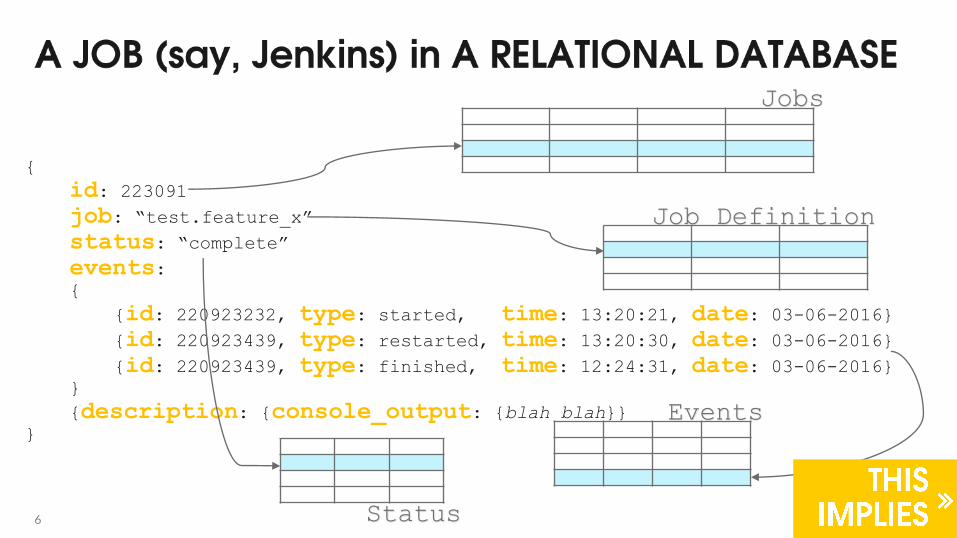
6
{
id: 223091
job: “test.feature_x”
status: “complete”
events:{
{id: 220923232, type: started, time: 13:20:21, date: 03-06-2016}
{id: 220923439, type: restarted, time: 13:20:30, date: 03-06-2016}
{id: 220923439, type: finished, time: 12:24:31, date: 03-06-2016}}
{description: {console_output: {blah blah}}}
Jobs
Job Definition
Events
Status
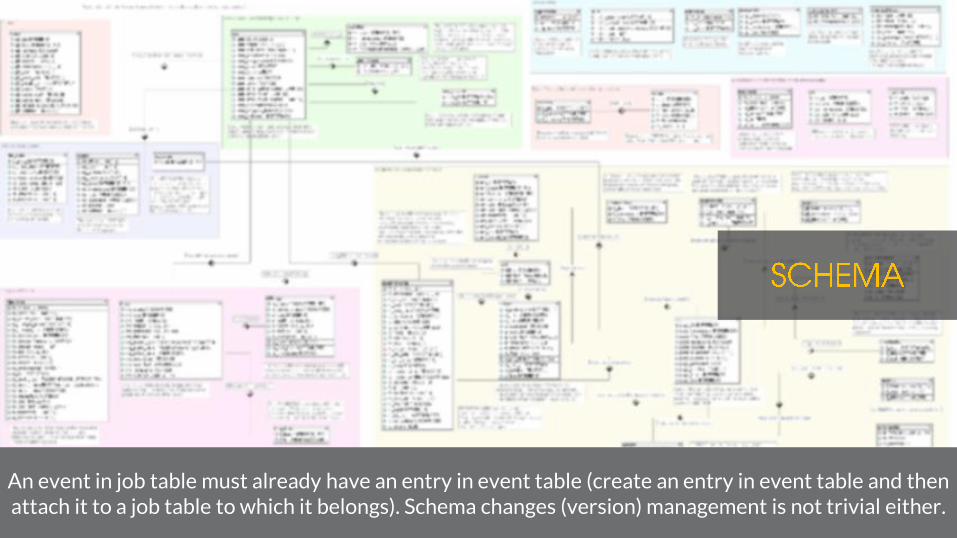
7
An event in job table must already have an entry in event table (create an entry in event table and then attach it to a job table to which it belongs). Schema changes (version) management is not trivial either.

8
Thinking in tables needs a different skillset than creating a Job class. In other words, memory data structures (classes/objects in your heap or in a in-mem db) rarely resemble relational tables. Keeping
them in-synch while rapid development/ prototyping is costly.
Jobs
Job Definition
Events
Status
=

9
Clustering (sharding,
replicating etc.) data is a necessity
with constantly evolving
relationships (=schema) and exponentially
increasing volumes. Doing
that in RDBMS is complicated to say
the least

TYPES

11
SELECT db_name_text
FROM db_table
WHERE data_relationship_model <>
‘TABULAR’;

12
KEY VALUE
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
DOCUMENT
GRAPH
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{Event Id: <id>Event:{
Lat: 12.952772Long: 77.644305Type: <location alert>
}}
COLUMN FAMILY
a
c
b
x
z
y

13
= A Key to a value mapping storage
Think of java.util.Map<K,V>
The DB knows only about the keys
Values could be anything; they are just stored and retrieved, never processed
Use cases:– User -> Profile Data– User -> Preference Data– User -> Session Data

{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{User Id: <id>User:{
Call Name: XAddress: YGenres: [“action”, “noir”]
}}
{Event Id: <id>Event:{
Lat: 12.952772Long: 77.644305Type: <location alert>
}}
= A (implicit) Key (id) to a document (value) mapping storage
Think of filing a document in a folder
Values are supplied in readable formats – json, bson, XML
Values are visible to the database and typically indexed
Use cases:– Rapidly evolving data (application of schema like thing can
be delayed till maturity)– Event processing (self contained documents for future
computation; mostly ‘read’ or ‘created’ and rarely ‘updated’)

= Column is the unit of data; Stores columns as groups (‘families’)
Think of it as a ‘sparse matrix’
Every row (key) may have data only against a sub-set of columns
Use cases:– Live analytics, Iteratively computed outcomes
{column family
‘likes’
user1
user2
userX
userY

= Graphs with data in both nodes and edges
Think of it as a, well, just graph!
Node data represent what we normally think as ‘data’
Edge data represent the ‘relationship’ between the connected nodes
Use cases:– Recommendations, Relationship traversal & analytics
a
c
b
x
z
y


18
No SQL Distilled
The Definitive Guide to MongoDB
Plenty of references in WWW

19
DB Schema: http://commons.wikimedia.org/wiki/File:Mediawiki-database-schema.png
Internet per Minute: http://upload.wikimedia.org/wikipedia/commons/5/54/Internet_Minute_Infographic.jpg
NoSQL Boom: From Ramana under CC2.0

















