153
www.cineca.i t The basic of parallel programming Carlo Cavazzoni, HPC department, CINECA
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | hubert-obrien |
| View: | 226 times |
| Download: | 1 times |

www.cineca.it
The basic of parallel programming
Carlo Cavazzoni, HPC department, CINECA

www.cineca.it
Message Passing
Cooperation between two process
DataProcesso 0
Processo 1
May I Send?
Yes
Data
Data
Time
Two fundamental function: send(message) e receive(message)
Listening…
Listening…
Listening…

www.cineca.it 3
MPIMessage Passing Interface

www.cineca.it
Goals of the MPI standard
To provide source-code portability
To allow efficient implementation

www.cineca.it
Domain decompositionData are divided into pieces of approximately the same size and mapped to different processors. Each processors work only on its local data. The resulting code has a single flow.
Functional decompositionThe problem is decompose into a large number of smaller tasks and then the tasks are assigned to processors as they become available, Client-Server / Master-Slave paradigm.
two basic models

www.cineca.it
Basic Features of MPI Programs
An MPI program consists of multiple instances of a serial program that communicate by library call.
Calls may be roughly divided into four classes:
Calls used to initialize, manage, and terminate communications
Calls used to communicate between pairs of processors. (Pair communication)
Calls used to communicate among groups of processors. (Collective communication)
Calls to create data types.

www.cineca.it
A First Program: Hello World!Fortran
PROGRAM hello
INCLUDE ‘mpif.h‘
INTEGER err
CALL MPI_INIT(err)
PRINT *, “hello world!”
CALL MPI_FINALIZE(err)
END
C
#include <stdio.h>
#include <mpi.h>
void main (int argc, char * argv[])
{
int err;
err = MPI_Init(&argc, &argv);
printf(“Hello world!\n”);
err = MPI_Finalize();
}

www.cineca.it
Header filesAll Subprogram that contains calls to MPI subroutine must include the MPI header file
C:
#include<mpi.h>
Fortran:
include ‘mpif.h’
The header file contains definitions of MPI constants, MPI
types and functions

www.cineca.it
MPI CommunicatorIn MPI it is possible divide the total number of processes into groups, called communicators. The Communicator is a variable identifying a group of processes that are allowed to communicate with each other.The communicator that includes all processes is called MPI_COMM_WORLD MPI_COMM_WORLD is the default
communicator (automatically defined):
All MPI communication subroutines have a communicator argument. The Programmer could define many communicator at the same time
1
6
4
3
2
7
0
5
MPI_COMM_WORLD

www.cineca.it
MPI function format
C:
Error = MPI_Xxxxx(parameter,...);MPI_Xxxxx(parameter,...);
Fortran:
CALL MPI_XXXXX(parameter, IERROR)

www.cineca.it
Initialising MPI
C:int MPI-Init(int*argc, char***argv)
Fortran:INTEGER IERRORCALL MPI_INIT(IERROR)
Must be the first MPI call, Initializes the message passing routines

www.cineca.it
Communicator SizeHow many processors are associated with a communicator?
C:MPI_Comm_size(MPI_Comm comm, int *size)
Fortran:INTEGER COMM, SIZE, IERRCALL MPI_COMM_SIZE(COMM, SIZE, IERR)
OUTPUT: SIZE

www.cineca.it
Process RankHow do you identify different processes?
What is the ID of a processor in a group?
C:MPI_Comm_rank(MPI_Comm comm, int *rank)
Fortran:
INTEGER COMM, RANK, IERRCALL MPI_COMM_RANK(COMM, RANK, IERR)
OUTPUT: RANK
rank is an integer that identifies the Process inside the communicator comm
MPI_COMM_RANK is used to find the rank (the name or identifier) of the Process running the code

www.cineca.it
Communicator Size and Process Rank / 1
P0 P1 P2 P3 P4 P5 P6 P7
RANK = 2
SIZE = 8
Size is the number of processors associated to the communicator
rank is the index of the process within a group associated to a communicator (rank = 0,1,...,N-1). The rank is used to identify the source and destination process in a communication
How many processes are contained within a communicator?

www.cineca.it
Initializing and Exiting MPIInitializing the MPI environmentC:
int MPI_Init(int *argc, char ***argv);Fortran:
INTEGER IERRCALL MPI_INIT(IERR)
Finalizing MPI environmentC:
int MPI_Finalize()Fortran:
INTEGER IERRCALL MPI_FINALIZE(IERR)
This two subprograms should be called by all process, and no other MPI calls are allowed before mpi_init and after mpi_finalize

www.cineca.it
A Template for Fortran MPI Programs
PROGRAM template
INCLUDE ‘mpif.h‘INTEGER ierr, myid, nproc
CALL MPI_INIT(ierr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
!!! INSERT YOUR PARALLEL CODE HERE !!!
CALL MPI_FINALIZE(ierr)
END

www.cineca.it
A Template for C MPI programs
#include <stdio.h>#include <mpi.h>
void main (int argc, char * argv[]){ int err, nproc, myid;
err = MPI_Init(&argc, &argv); err = MPI_Comm_size(MPI_COMM_WORLD, &nproc); err = MPI_Comm_rank(MPI_COMM_WORLD, &myid);
/*** INSERT YOUR PARALLEL CODE HERE ***/
err = MPI_Finalize();}

www.cineca.it
ExamplePROGRAM helloIMPLICIT NONEINCLUDE ‘mpif.h’INTEGER:: myPE, totPEs, i, ierr CALL MPI_INIT(ierr)CALL MPI_COMM_RANK( MPI_COMM_WORLD, myPE, ierr )CALL MPI_COMM_SIZE( MPI_COMM_WORLD, totPEs, ierr )PRINT *, “myPE is “, myPE, “of total ”, totPEs, “ PEs”CALL MPI_FINALIZE(ierr)END PROGRAM hello
MyPE is 1 of total 4 PEs MyPE is 0 of total 4 PEs MyPE is 3 of total 4 PEs MyPE is 2 of total 4 PEs
Output (4 Procs)

www.cineca.it
Point to Point Communication
Is the fundamental communication facility provided by MPI library. Communication between 2 processesIs conceptually simple: source process A sends a message to destination process B, B receive the message from A. Communication take places within a communicatorSource and Destination are identified by their rank in the communicator
Communicator
1
6
4
3
2
7
05
Source
Dest

www.cineca.it
The MessageMPI Data types
Basic types Derived types
Derived type can be build up from basic typesUser-defined data types allows MPI to automatically scatter and gather data to and from non-contiguous buffers Messages are identified by their envelopes,
a message could be received only if the receiver specify the correct envelope
envelope body
source destination communicator tag buffer datatypecount
Message Structure

www.cineca.it
Fortran - MPI Basic Datatypes
DOUBLE COMPLEXMPI_DOUBLE_COMPLEX
MPI_PACKED
MPI_BYTE
CHARACTER(1)MPI_CHARACTER
LOGICALMPI_LOGICAL
COMPLEXMPI_COMPLEX
DOUBLE PRECISIONMPI_DOUBLE_PRECISION
REALMPI_REAL
INTEGERMPI_INTEGER
Fortran Data typeMPI Data type

www.cineca.it
C - MPI Basic Datatypes
MPI_PACKED
MPI_BYTE
long doubleMPI_LONG_DOUBLE
doubleMPI_DOUBLE
floatMPI_FLOAT
unsigned long intMPI_UNSIGNED_LONG
unsigned intMPI_UNSIGNED
unsigned short intMPI_UNSIGNED_SHORT
unsigned charMPI_UNSIGNED_CHAR
Signed log intMPI_LONG
signed intMPI_INT
signed short intMPI_SHORT
signed charMPI_CHAR
C Data typeMPI Data type

www.cineca.it
Blocking and non-Blocking
“Completion” of the communication means that memory locations used in the message transfer can be safely accessed
Send: variable sent can be reused after completion Receive: variable received can now be used
MPI communication modes differ in what conditions are needed for completion
Communication modes can be blocking or non-blocking Blocking: return from routine implies completion Non-blocking: routine returns immediately, user must
test for completion

www.cineca.it
Communication ModesFive different communication modes are allowed:· Synchronous Send· Buffered Send· Standard Send· Ready Send· ReceiveAll of them can be Blocking or Non-Blocking
– Blocking Send will not return until the message data is sent out or buffered in system buffer and the array containing the message is ready for re-use.
– Unblocking Send will return immediately after the send and then test if the send activity has been sucessful

www.cineca.it
Communication Modes
MPI_IRSENDMPI_RSENDAlways completes, irrespective of whether the receive has completed
Ready send
MPI_IBSENDMPI_BSENDAlways completes,irrespective of receiverGuarantees the message being buffered
Buffered send
MPI_ISSENDMPI_SSENDOnly completes after a matching recv() is posted ad the receive operation is started.
Synchronous send
MPI_IRECVMPI_RECVCompletes when a matching message has arrived
receive
MPI_ISENDMPI_SENDMessage sent (receive state unknown)
Standard send
Non-blocking subroutine
Blocking subroutine
Completion ConditionMode

www.cineca.it
Basic blocking point-to-point communication routine in MPI.
Fortran: MPI_SEND(buf, count, type, dest, tag, comm, ierr)MPI_RECV(buf, count, type, dest, tag, comm, status, ierr)
Bufarray of type type see table.Count (INTEGER) number of element of buf to be sentType (INTEGER) MPI type of bufDest (INTEGER) rank of the destination processTag(INTEGER) number identifying the messageComm (INTEGER) communicator of the sender and receiverStatus (INTEGER) array of size MPI_STATUS_SIZE containing
communication status informationIerr (INTEGER) error code (if ierr=0 no error occurs)
Standard Send and Receive
Message body envelope

www.cineca.it
Standard Send and Receive
C:int MPI_Send(void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm);
int MPI_Recv (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Status *status);

www.cineca.it
HandlesMPI controls its own internal data structuresMPI releases ‘handles’ to allow programmers to refer to these
C handles are defined typedefs Fortran handles are INTEGER

www.cineca.it
Wildcards
Both in Fortran and C MPI_RECV accept wildcard: To receive from any source: MPI_ANY_SOURCE To receive with any tag: MPI_ANY_TAG Actual source and tag are returned in the receiver’s status parameter.

www.cineca.it
For a communication to succeed
Sender must specify a valid destination rank.
· Receiver must specify a valid source rank.· The communicator must be the same.· Tags must match.· Message types must match.· Receiver’s buffer must be large enough: larger-equal than sender's one.

www.cineca.it
Communication EnvelopeInformation includes, source, tag and count:C:status.MPI_SOURCE
status.MPI_TAGMPI_Get_count()
Fortran: status(MPI_SOURCE)status(MPI_TAG)MPI_GET_COUNT
C:int MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int *count)Fortran:MPI_GET_COUNT (status, datatype, count, ierror)INTEGER status(mpi_status_size), datatype, count,, ierror
Envelope information is returned from MPI_RECV as status
This information is useful because:• receive tag can be MPI_ANY_TAG• source can be MPI_ANY_SOURCE• count can be larger than the real message size

www.cineca.it
examplePROGRAM send_recv
INCLUDE ‘mpif.h‘INTEGER ierr, myid, nprocINTEGER status(MPI_STATUS_SIZE)REAL A(2)
CALL MPI_INIT(ierr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
IF( myid .EQ. 0 ) THEN A(1) = 3.0 A(2) = 5.0 CALL MPI_SEND(A, 2, MPI_REAL, 1, 10, MPI_COMM_WORLD, ierr)ELSE IF( myid .EQ. 1 ) THEN CALL MPI_RECV(A, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr) WRITE(6,*) myid,’: a(1)=’,a(1),’ a(2)=’,a(2)END IF
CALL MPI_FINALIZE(ierr)END

www.cineca.it
example#include <stdio.h>#include <mpi.h>
void main (int argc, char * argv[]){ int err, nproc, myid; MPI_Status status; float a[2];
err = MPI_Init(&argc, &argv); err = MPI_Comm_size(MPI_COMM_WORLD, &nproc); err = MPI_Comm_rank(MPI_COMM_WORLD, &myid);
if( myid == 0 ) { a[0] = 3.0, a[1] = 5.0; MPI_Send(a, 2, MPI_FLOAT, 1, 10, MPI_COMM_WORLD); } else if( myid == 1 ) { MPI_Recv(a, 2, MPI_FLOAT, 0, 10, MPI_COMM_WORLD, &status); printf(”%d: a[0]=%f a[1]=%f\n”, myid, a[0], a[1]); } err = MPI_Finalize();}

www.cineca.it
Again about completion
Standard MPI_RECV and MPI_SEND block the calling process until completion.For MPI_RECV completion: the message is arrived and the process could proceed using the received data.For MPI_SEND completion: the process could proceed and data could be overwritten without interfering with the message. But this does not mean that the message has already been sent. In many MPI implementation, depending on the message size, sending data are copied to MPI internal buffers.
If the message is not buffered a call to MPI_SEND implies a process synchronization, on the contrary this is not true if the message is buffered.
Don’t make any assumptions (implementation dependent)

www.cineca.it
DEADLOCKDeadlock occurs when 2 (or more) processes are blocked and each is waiting for
the other to make progress.
0
terminate
Action A
Proceed if 1 has taken
action B
1init
init
compute compute
Action B
terminate
Proceed if 0 has taken
action A

www.cineca.it
Simple DEADLOCKPROGRAM deadlockINCLUDE ‘mpif.h‘INTEGER ierr, myid, nprocINTEGER status(MPI_STATUS_SIZE)REAL A(2), B(2)
CALL MPI_INIT(ierr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
IF( myid .EQ. 0 ) THEN a(1) = 2.0 a(2) = 4.0 CALL MPI_RECV(b, 2, MPI_REAL, 1, 11, MPI_COMM_WORLD, status, ierr) CALL MPI_SEND(a, 2, MPI_REAL, 1, 10, MPI_COMM_WORLD, ierr)ELSE IF( myid .EQ. 1 ) THEN a(1) = 3.0 a(2) = 5.0 CALL MPI_RECV(b, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr) CALL MPI_SEND(a, 2, MPI_REAL, 0, 11, MPI_COMM_WORLD, ierr)END IFWRITE(6,*) myid, ’: a(1)=’, a(1), ’ a(2)=’, a(2)CALL MPI_FINALIZE(ierr)END

www.cineca.it
init
init
computecompute
Avoiding DEADLOCK
terminateterminate
0 1
Action BProceed
if 1 has taken action B
Proceed if 0 has taken
action AAction A

www.cineca.it
Avoiding DEADLOCKPROGRAM avoid_lockINCLUDE ‘mpif.h‘INTEGER ierr, myid, nprocINTEGER status(MPI_STATUS_SIZE)REAL A(2), B(2)
CALL MPI_INIT(ierr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
IF( myid .EQ. 0 ) THEN a(1) = 2.0 a(2) = 4.0 CALL MPI_RECV(b, 2, MPI_REAL, 1, 11, MPI_COMM_WORLD, status, ierr) CALL MPI_SEND(a, 2, MPI_REAL, 1, 10, MPI_COMM_WORLD, ierr)ELSE IF( myid .EQ. 1 ) THEN a(1) = 3.0 a(2) = 5.0 CALL MPI_SEND(a, 2, MPI_REAL, 0, 11, MPI_COMM_WORLD, ierr) CALL MPI_RECV(b, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr)END IFWRITE(6,*) myid, ’: a(1)=’, a(1), ’ a(2)=’, a(2)CALL MPI_FINALIZE(ierr)END

www.cineca.it
DEADLOCK: the most common error
PROGRAM error_lockINCLUDE ‘mpif.h‘INTEGER ierr, myid, nprocINTEGER status(MPI_STATUS_SIZE)REAL A(2), B(2)
CALL MPI_INIT(ierr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)IF( myid .EQ. 0 ) THEN a(1) = 2.0 a(2) = 4.0 CALL MPI_SEND(a, 2, MPI_REAL, 1, 10, MPI_COMM_WORLD, ierr) CALL MPI_RECV(b, 2, MPI_REAL, 1, 11, MPI_COMM_WORLD, status, ierr)ELSE IF( myid .EQ. 1 ) THEN a(1) = 3.0 a(2) = 5.0 CALL MPI_SEND(a, 2, MPI_REAL, 0, 11, MPI_COMM_WORLD, ierr) CALL MPI_RECV(b, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr)END IFWRITE(6,*) myid, ’: a(1)=’, a(1), ’ a(2)=’, a(2)CALL MPI_FINALIZE(ierr)END

www.cineca.it
Non-Blocking Send and Receive
Non-Blocking communications allows the separation between the initiation of the communication and the completion.
Advantages: between the initiation and completion the program could do other useful computation (latency hiding).
Disadvantages: the programmer has to insert code to check for completion.

www.cineca.it
Non-Blocking Send and Receive
Fortran: MPI_ISEND(buf, count, type, dest, tag, comm, req, ierr)MPI_IRECV(buf, count, type, dest, tag, comm, req, ierr)
buf array of type type see table.count (INTEGER) number of element of buf to be senttype (INTEGER) MPI type of bufdest (INTEGER) rank of the destination processtag (INTEGER) number identifying the messagecomm (INTEGER) communicator of the sender and receiverreq (INTEGER) output, identifier of the communications handleierr (INTEGER) output, error code (if ierr=0 no error occurs)

www.cineca.it
Non-Blocking Send and Receive
C:
int MPI_Isend(void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *req);
int MPI_Irecv (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *req);

www.cineca.it
Waiting and Testing for Completion
Fortran:MPI_WAIT(req, status, ierr)
A call to this subroutine cause the code to wait until the communication pointed by req is complete.
req (INTEGER) input/output, identifier associated to a communications event (initiated by MPI_ISEND or MPI_IRECV).Status (INTEGER) array of size MPI_STATUS_SIZE, if req was associated to a call to MPI_IRECV, status contains informations on the received message, otherwise status could contain an error code.ierr (INTEGER) output, error code (if ierr=0 no error occours).
C:int MPI_Wait(MPI_Request *req, MPI_Status *status);

www.cineca.it
Waiting and Testing for Completion
Fortran:MPI_TEST(req, flag, status, ierr)
A call to this subroutine sets flag to .true. if the communication pointed by req is complete, sets flag to .false. otherwise.
Req (INTEGER) input/output, identifier associated to a communications event (initiated by MPI_ISEND or MPI_IRECV).Flag(LOGICAL) output, .true. if communication req has completed .false. otherwiseStatus(INTEGER)array of size MPI_STATUS_SIZE, if req was associated to a call to MPI_IRECV, status contains informations on the received message, otherwise status could contain an error code.ierr(INTEGER) output, error code (if ierr=0 no error occours).
C:int MPI_Wait(MPI_Request *req, int *flag, MPI_Status *status);
www.cineca.it
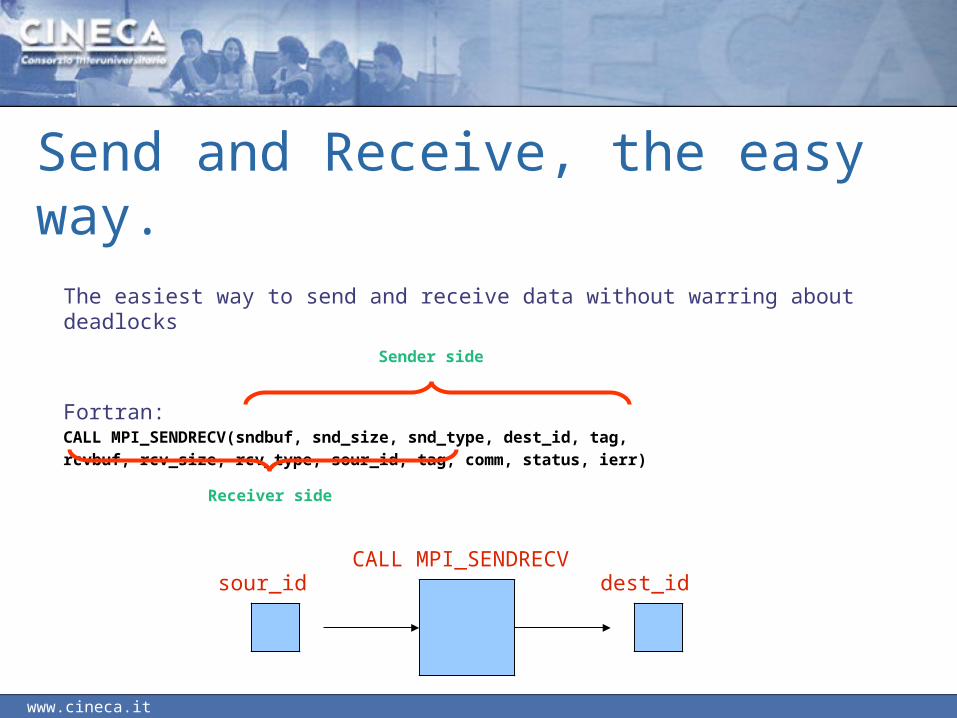
Send and Receive, the easy way.
The easiest way to send and receive data without warring about deadlocks
Fortran:CALL MPI_SENDRECV(sndbuf, snd_size, snd_type, dest_id, tag,rcvbuf, rcv_size, rcv_type, sour_id, tag, comm, status, ierr)
Sender side
Receiver side
CALL MPI_SENDRECVsour_id dest_id

www.cineca.it
Send and Receive, the easy way.
PROGRAM send_recvINCLUDE ‘mpif.h‘INTEGER ierr, myid, nprocINTEGER status(MPI_STATUS_SIZE)REAL A(2), B(2)CALL MPI_INIT(ierr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)IF( myid .EQ. 0 ) THEN a(1) = 2.0 a(2) = 4.0 CALL MPI_SENDRECV(a, 2, MPI_REAL, 1, 10, b, 2, MPI_REAL, 1, 11, MPI_COMM_WORLD, status, ierr)ELSE IF( myid .EQ. 1 ) THEN a(1) = 3.0 a(2) = 5.0 CALL MPI_SENDRECV(a, 2, MPI_REAL, 0, 11, b, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr)END IFWRITE(6,*) myid, ’: b(1)=’, b(1), ’ b(2)=’, b(2)CALL MPI_FINALIZE(ierr)END

www.cineca.it
Domain decomposition and MPI
MPI is particularly suited for a Domain decomposition approach, where there is a single program flow.
Parallel computation consist of a number of processes, each working on some local data. Each process has purely local variables (no access to remote memory).
Sharing of data takes place by message passing, by explicitly sending and receiving data between processes.

www.cineca.it
Collective Communications
Barrier Synchronization
Broadcast
Gather/Scatter
Reduction (sum, max, prod, … )
-Communications involving a group of process-Called by all processes in a communicator

www.cineca.it
Characteristics
Collective communications do not interfere with point-to-point
communication and vice-versa
All processes must call the collective routine
No non-blocking collective communication
No tags
Receive buffers must be exactly the right size
Safest communication mode

www.cineca.it
MPI_Barrier
Stop processes until all processes within a communicator reach
the barrier
Fortran:CALL MPI_BARRIER(comm, ierr)
C:int MPI_Barrier(MPI_Comm comm)

www.cineca.it
Barrier
P0 P1 P2 P3 P4
t1 t2 t3
P0 P1 P2 P3 P4
barrier
t
P0
P1
P2
P3
P4
barrier

www.cineca.it
Broadcast (MPI_BCAST)One-to-all communication: same data sent from root process to all others in the communicator
Fortran:INTEGER count, type, root, comm, ierr
CALL MPI_BCAST(buf, count, type, root, comm, ierr)
Buf array of type type
C:int MPI_Bcast(void *buf, int count, MPI_Datatype, datatypem int root,
MPI_Comm comm)
All processes must specify same root, rank and comm

www.cineca.it
Broadcast
P0P1
P2P3
a1
P0
a1
a1
a1
PROGRAM broad_cast INCLUDE 'mpif.h' INTEGER ierr, myid, nproc, root INTEGER status(MPI_STATUS_SIZE) REAL A(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) root = 0 IF( myid .EQ. 0 ) THEN a(1) = 2.0 a(2) = 4.0 END IF CALL MPI_BCAST(a, 2, MPI_REAL, 0,
MPI_COMM_WORLD, ierr) WRITE(6,*) myid, ': a(1)=', a(1), 'a(2)=', a(2) CALL MPI_FINALIZE(ierr) END
www.cineca.it
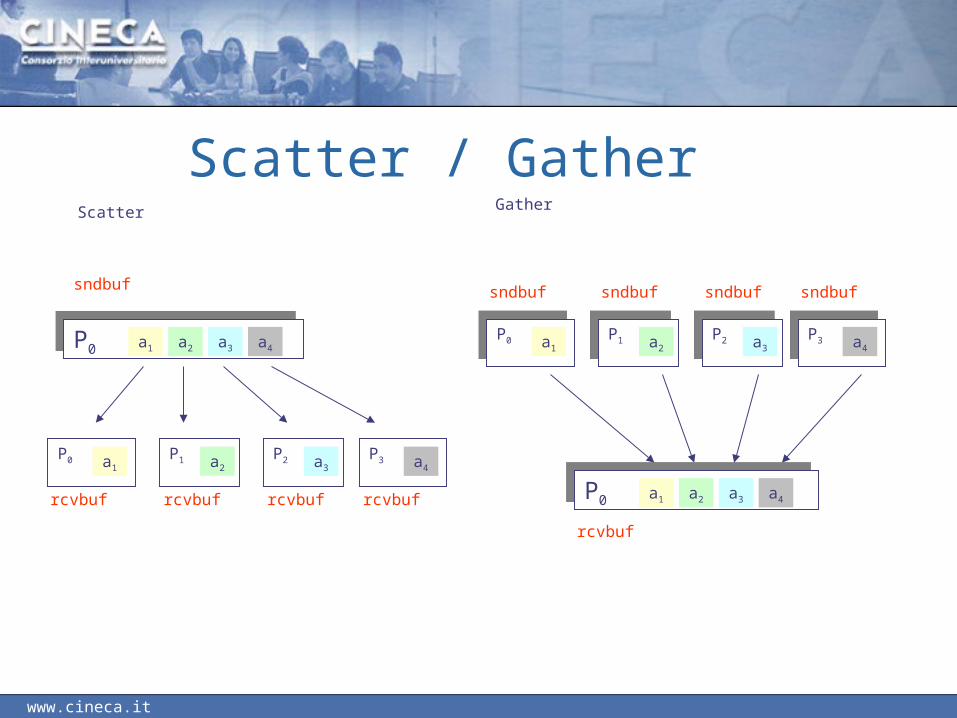
Scatter / GatherScatter
P0P0
rcvbuf
P0 a1
rcvbuf
P1 a2
rcvbuf
P2 a3
rcvbuf
P3 a4
rcvbuf
P1P1P2P2
P3P3P0P0 a1 a2 a3 a4
sndbuf sndbuf sndbuf sndbuf
Gather
P0P0 a2 a3a1 a4
sndbuf
a4a3a1 a2

www.cineca.it
MPI_ScatterOne-to-all communication: different data sent from root process to all others in the
communicator
Fortran:
CALL MPI_SCATTER(sndbuf, sndcount, sndtype, rcvbuf, rcvcount, rcvtype,
root, comm, ierr)
Arguments definition are like other MPI subroutine
sndcount is the number of elements sent to each process, not the size of sndbuf, that
should be sndcount times the number of process in the communicator
The sender arguments are meaningful only for root

www.cineca.it

www.cineca.it
MPI_SCATTERVUsage
int MPI_Scatterv( void* sendbuf, /* in */
int* sendcounts, /* in */
int* displs, /* in */
MPI_Datatype sendtype, /* in */
void* recvbuf, /* in */
int recvcount, /* in */
MPI_Datatype recvtype, /* in */
int root, /* in */
MPI_Comm comm); /* in */
DescriptionDistributes individual messages from root to each process in communicator
Messages can have different sizes and displacements

www.cineca.it

www.cineca.it
MPI_Gather
One-to-all communication: different data collected by the root process, from all others
processes in the communicator. Is the opposite of Scatter
Fortran:
CALL MPI_GATHER(sndbuf, sndcount, sndtype, rcvbuf, rcvcount,
rcvtype, root, comm, ierr)
Arguments definition are like other MPI subroutine
rcvcount is the number of elements collected from each process, not the size of rcvbuf,
that should be rcvcount times the number of process in the communicator
The receiver arguments are meaningful only for root

www.cineca.it

www.cineca.it
MPI_GATHERVUsage
int MPI_Gatherv( void* sendbuf, /* in */ int sendcount, /* in */ MPI_Datatype sendtype, /* in */ void* recvbuf, /* out */ int* recvcount, /* in */ int* displs, /* in */ MPI_Datatype recvtype,/* in */ int root, /* in */ MPI_Comm comm ); /* in */
DescriptionCollects individual messages from each process in communicator to the root
process and store them in rank orderMessages can have different sizes and displacements

www.cineca.it

www.cineca.it
Scatter example PROGRAM scatter
INCLUDE 'mpif.h'
INTEGER ierr, myid, nproc, nsnd, I, root
INTEGER status(MPI_STATUS_SIZE)
REAL A(16), B(2)
CALL MPI_INIT(ierr)
CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
root = 0
IF( myid .eq. root ) THEN
DO i = 1, 16
a(i) = REAL(i)
END DO
END IF
nsnd = 2
CALL MPI_SCATTER(a, nsnd, MPI_REAL, b, nsnd,
& MPI_REAL, root, MPI_COMM_WORLD, ierr)
WRITE(6,*) myid, ': b(1)=', b(1), 'b(2)=', b(2)
CALL MPI_FINALIZE(ierr)

www.cineca.it
Gather example
PROGRAM gather
INCLUDE 'mpif.h'
INTEGER ierr, myid, nproc, nsnd, I, root
INTEGER status(MPI_STATUS_SIZE)
REAL A(16), B(2)
CALL MPI_INIT(ierr)
CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
root = 0
b(1) = REAL( myid )
b(2) = REAL( myid )
nsnd = 2
CALL MPI_GATHER(b, nsnd, MPI_REAL, a, nsnd,
& MPI_REAL, root MPI_COMM_WORLD, ierr)
IF( myid .eq. root ) THEN
DO i = 1, (nsnd*nproc)
WRITE(6,*) myid, ': a(i)=', a(i)
END DO
END IF
CALL MPI_FINALIZE(ierr)

www.cineca.it
MPI_Alltoall
P0
P0
P0
P0
P0
P0
P0
P0
a4
b4
c4
d4 a4 b4 c4 d4
a3
b3
c3
d3
a3 b3 c3 d3
a2
b2
c2
d2
a2 b2 c2 d2
a1
b1
c1
d1
a1 b1 c1 d1
Fortran:
CALL MPI_ALLTOALL(sndbuf, sndcount, sndtype, rcvbuf, rcvcount, rcvtype, comm, ierr)
Very useful to implement data transposition
rcvbuf
sndbuf

www.cineca.it
Reduction
The reduction operation allow to:
•Collect data from each process
•Reduce the data to a single value
•Store the result on the root processes
•Store the result on all processes
•Overlap of communication and computing

www.cineca.it
Reduce, Parallel Sum
P0
P1
P2
P3
P0 a1
a2
a3
a4
Sa=a1+a2+a3+a4
Sa
Reduction function works with arrays
other operation: product, min, max, and, ….
b1
b2
b3
b4
Sb=b1+b2+b3+b4
Sb
P2 Sa Sb
P3 Sa Sb
P1 Sa Sb

www.cineca.it
MPI_REDUCE and MPI_ALLREDUCEFortran:
MPI_REDUCE( snd_buf, rcv_buf, count, type, op, root, comm, ierr)
snd_buf input array of type type containing local values.rcv_buf output array of type type containing global resultsCount (INTEGER) number of element of snd_buf and rcv_buftype (INTEGER) MPI type of snd_buf and rcv_bufop (INTEGER) parallel operation to be performedroot (INTEGER) MPI id of the process storing the resultcomm (INTEGER) communicator of processes involved in the operationierr (INTEGER) output, error code (if ierr=0 no error occours)
MPI_ALLREDUCE( snd_buf, rcv_buf, count, type, op, comm, ierr)
The argument root is missing, the result is stored to all processes.
www.cineca.it
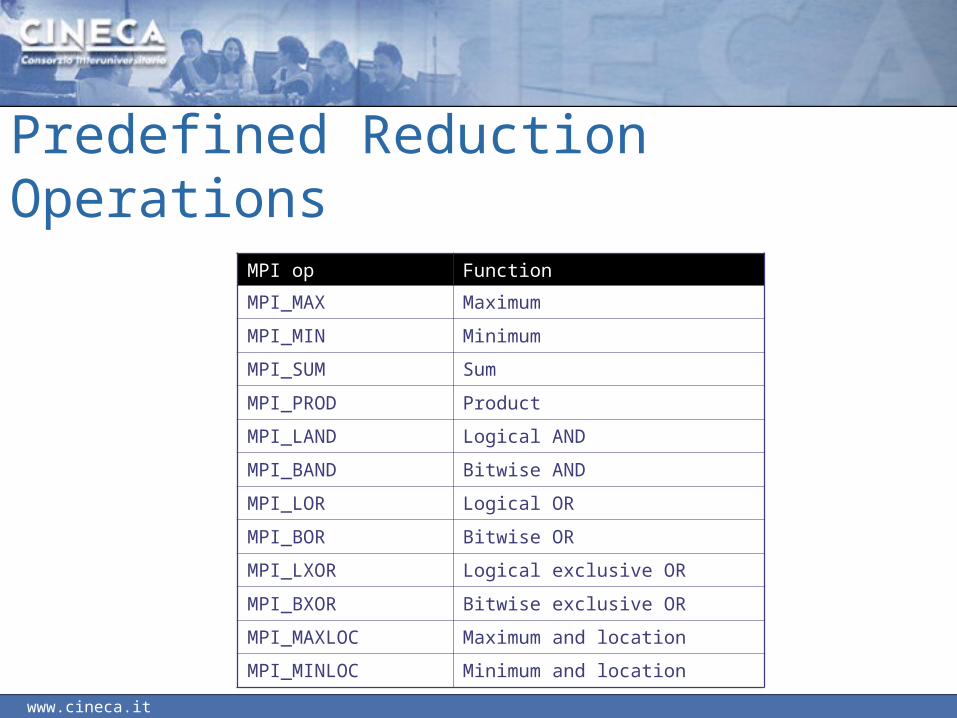
Predefined Reduction Operations
MPI op Function
MPI_MAX Maximum
MPI_MIN Minimum
MPI_SUM Sum
MPI_PROD Product
MPI_LAND Logical AND
MPI_BAND Bitwise AND
MPI_LOR Logical OR
MPI_BOR Bitwise OR
MPI_LXOR Logical exclusive OR
MPI_BXOR Bitwise exclusive OR
MPI_MAXLOC Maximum and location
MPI_MINLOC Minimum and location

www.cineca.it
Reduce / 1
C:int MPI_Reduce(void * snd_buf, void * rcv_buf, int
count, MPI_Datatype type, MPI_Op op, int root, MPI_Comm comm)
int MPI_Allreduce(void * snd_buf, void * rcv_buf, int count, MPI_Datatype type, MPI_Op op, MPI_Comm comm)

www.cineca.it
Reduce, example PROGRAM reduce
INCLUDE 'mpif.h'
INTEGER ierr, myid, nproc, root
INTEGER status(MPI_STATUS_SIZE)
REAL A(2), res(2)
CALL MPI_INIT(ierr)
CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr)
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
root = 0
a(1) = 2.0*myid
a(2) = 4.0+myid
CALL MPI_REDUCE(a, res, 2, MPI_REAL, MPI_SUM, root,
& MPI_COMM_WORLD, ierr)
IF( myid .EQ. 0 ) THEN
WRITE(6,*) myid, ': res(1)=', res(1), 'res(2)=', res(2)
END IF
CALL MPI_FINALIZE(ierr)
END

www.cineca.it
Shared Memory System
• Shared memory refers to a large block of RAM that can be accessed by several different CPUs in a multiple-processor computer system.
• Usually the system is a Simmetric MultiProcessor (SMP). SMP involves a multiprocessor computer hardware architecture where two or more identical processors are connected to a single shared main memory.

www.cineca.it
• The OpenMP Application Program Interface (API) supports multi-platform shared-memory parallel programming in C/C++ and Fortran on all architectures, including Unix platforms and Windows NT platforms.
• OpenMP is a portable, scalable model that gives shared-memory parallel programmers a simple and flexible interface for developing parallel applications for platforms ranging from the desktop to the supercomputer.

www.cineca.it
Pros of OpenMP• easier to program and debug;• directives can be added incrementally;• gradual parallelization;• can still run the program as a serial code;
• serial code statements usually don't need modification.
Cons of OpenMP• can only be run in shared memory computers;
• Traffic between CPU and memory increases with the number of CPUs;

www.cineca.it
• The OpenMP API uses the fork-join model of parallel execution.• An OpenMP program begins as a single thread of execution, called the initial
thread. The initial thread executes sequentially until encounters a parallel construct.
• The initial thread creates a team of threads and becomes the master of the new team. Beyond the end of the parallel construct, only the master thread resume execution.

www.cineca.it
OpenMP consists of a set of:
• Compiler directives
• Runtime library routines
• Environment variables

www.cineca.it
OpenMP directives for C/C++ are specified with the pragma preprocessing directive.
The syntax of an OpenMP directive is formally specified as follows:
• C/C++:#pragma omp directive-name [clause[[,]clause]...]
• Fortran:!$omp directive-name [clause[[,]clause]...]

www.cineca.it
Parallel construct
• Start parallel execution;• A team of threads is created to execute the parallel region;• The thread that encountered the parallel construct becomes the
master thread of the new team with a thread number zero.• There is an implicit barrier at the end of the construct;• Any number of parallel constructs can be specified in a single
program;

www.cineca.it
A first program in Fortran:
PROGRAM HELLOINTEGER VAR1, VAR2, VAR3!Serial code!Beginning of parallel region. !Fork a team of threads.!Specify variable scoping.!$OMP PARALLEL Print *, “Hello World!!!”!$OMP END PARALLEL!Resume serial code
END

www.cineca.it
A first program in C:
#include <omp.h>int main (){ int var1, var2, var3; Serial code! Beginning of parallel region. Fork a team of threads.! Specify variable scoping#pragma omp parallel {Parallel section executed by all threadsAll threads join master thread and disband }!Resume serial code}

www.cineca.it
Worksharing construct
• A worksharing construct distributes the execution of the associated region among the members of the team that encounters it.
• A worksharing region has no barrier on entry; however, an implied barrier exists at the end of the worksharing region.
• If a nowait clause is present, an implementation may omit the barrier at the end of the worksharing region.
→ Loop , Sections, Single, Workshare

www.cineca.it
Loop construct (DO/for)The loop construct specifies that the iterations of one or more
associated loops will be executed in parallel by threads in the team in the context of their implicit tasks. The iterations are distributed across threads that already exist in the team executing the parallel region to which the loop region binds.

www.cineca.it
Loop construct (DO/for)
Fortran:integer :: i,n=200real :: a(n),b(n),c(n)
do i=1, n a(i) = b(i) + c(i)enddo

www.cineca.it
Loop construct (DO/for)
Fortran:integer :: i,n=200real :: a(n),b(n),c(n)!$OMP PARALLEL!$OMP DOdo i=1, n a(i) = b(i) + c(i)enddo!$OMP END DO!$OMP END PARALLEL

www.cineca.it
Loop construct (DO/for)
C/C++:
#pragma omp parallel{…#pragma omp forfor (i=0;i<n;++i) a[i] = b[i] + c[i]…}

www.cineca.it
Scheduling
Specifies how iterations of the associated loops are divided into contiguous non-empty subsets, called chunks, and how these chunks are distributed among threads of the team.
• Static: iterations are divided into chunks of size chunk_size, and the chunks are assigned to the threads in the team in a round-robin fashion in the order of the thread number.
• Dynamic: iterations are distributed to threads in the team in chunks as the threads request them. Each thread executes a chunk of iterations, then requests another chunk, until no chunks remain to be distributed.

www.cineca.it
Scheduling
• Guided: the iterations are assigned to threads in the team in chunks as the executing threads request them. Each thread executes a chunk of iterations, then requests another chunk, until no chunks remain to be assigned. The chunk decrease with time.
• Runtime: the decision regarding scheduling is deferred until run time.• Auto: the decision regarding scheduling is delegated to the compiler and/or runtime
system.

www.cineca.it
Schedule clauses

www.cineca.it
Sections construct
The sections construct is a noniterative worksharing construct that contains a set of structured blocks that are to be distributed among and executed by the threads in a team.

www.cineca.it
Workshare: Sections construct
Fortran:!$OMP PARALLEL…!$OMP SECTIONS!$OMP SECTIONcall subr_A(c,d)!$OMP SECTIONcall subr_B(e,f)!$OMP SECTIONcall subr_c(g,h,i)!$OMP END SECTIONS…!$OMP END PARALLEL

www.cineca.it
Workshare: Sections constructC/C++:#pragma omp parallel{…#pragma omp sections{#pragma omp sectionA=subr_A(c,d)#pragma omp sectionB=subr_B(e,f)#pragma omp sectionC=subr_c(g,h,i)}…}

www.cineca.it
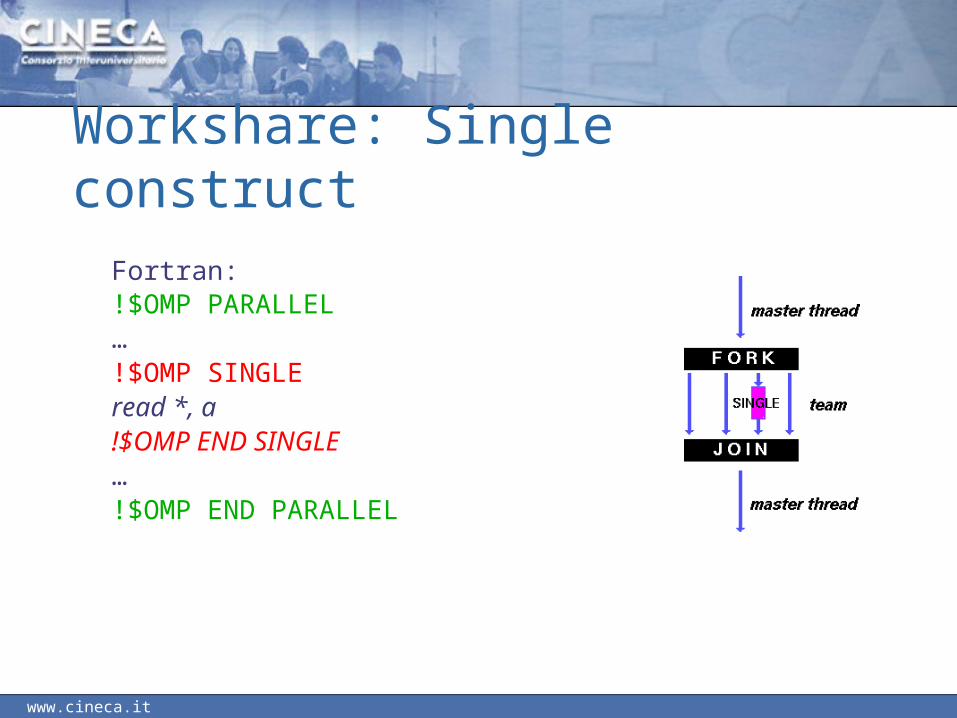
Workshare: Single constructThe single construct specifies that the associated structured block
is executed by only one of the threads in the team (not necessarily the master thread).
The other threads in the team, which do not execute the block, wait at an
implicit barrier at the end of the single construct unless a nowait clause is specified.
www.cineca.it
Workshare: Single construct
Fortran:!$OMP PARALLEL…!$OMP SINGLEread *, a!$OMP END SINGLE…!$OMP END PARALLEL

www.cineca.it
Workshare: Single construct
C/C++:#pragma omp parallel{…#pragma omp singleprintf(“Beginning work”);…}

www.cineca.it
Workshare
Costrutto Parallel combinato con costrutti Workshare!$omp parallel do...!$omp end parallel do
!$omp parallel workshare...!$omp end parallel workshare
!$omp parallel sections...!$omp end parallel sections

www.cineca.it
Workshare: Single construct
C/C++:#pragma omp parallel{…#pragma omp singleprintf(“Beginning work”);…}

www.cineca.it
Master & Sinchronization constructs
• Master• Critical• Atomic• Barrier
• Ordered

www.cineca.it
Master construct
The master construct specifies a structured block that is executed by the master thread of the team.
There is no implied barrier either on entry to, or exit from, the master construct.
Fortran:!$OMP PARALLEL…!$OMP MASTERread *, a!$OMP END MASTER…!$OMP END PARALLEL

www.cineca.it
Master construct
C/C++:#pragma omp parallel{…#pragma omp masterprintf(“Beginning work”);…}

www.cineca.it
Critical construct
The critical construct restricts execution of the associated structured block to a single thread at a time. An optional name may be used to identify the critical construct.
Fortran:!$OMP PARALLEL…!$OMP CRITICAL [NAME]X=FUNC_A(X)!$OMP END CRITICAL…!$OMP END PARALLEL

www.cineca.it
Critical construct
C/C++:#pragma omp parallel{…#pragma omp critical [name]x=subr_A(x)…}

www.cineca.it
Barrier construct
The barrier construct specifies an explicit barrier at the point at which the construct appears.
Fortran:!$OMP PARALLEL…X=FUNC_A(X)!$OMP BARRIER…!$OMP END PARALLEL

www.cineca.it
Barrier construct
The barrier construct specifies an explicit barrier at the point at which the construct appears.
C/C++:#pragma omp parallel{…x=subr_A(x)#pragma omp barrier…}

www.cineca.it
Atomic construct
The atomic construct ensures that a specific storage location is updated atomically, rather than exposing it to the possibility of multiple, simultaneous writing threads.
Fortran:!$OMP PARALLEL…!$OMP ATOMICX=X+1…!$OMP END PARALLEL

www.cineca.it
Atomic construct
The atomic construct ensures that a specific storage location is updated atomically, rather than exposing it to the possibility of multiple, simultaneous writing threads.
C/C++:#pragma omp parallel{…#pragma omp atomicx++;…}

www.cineca.it
Ordered construct
The ordered construct specifies a structured block in a loop region that will be executed in the order of the loop iterations. This sequentializes and orders the code within an ordered region while allowing code outside the region to run in parallel.

www.cineca.it
Ordered construct
Fortran:!$OMP PARALLEL !$OMP DO ORDEREDDO i=1,N A(i)=...!$OMP ORDERED PRINT *,a(i)!$OMP END ORDEREDENDDO!$OMP END DO ORDERED!$OMP END PARALLEL

www.cineca.it
Ordered construct
C/C++:#pragma omp parallel{…#pragma omp for ordered for (i=0;i<n;++i) { a[i] = b[i] + 1.0;#pragma omp ordered { printf(“%f\n”,a[i]); } }}

www.cineca.it
OpenMP Memory Model
Fortran:integer :: i=5,n=200real :: tmp=7!$OMP PARALLEL!$OMP DOdo i=1, n tmp = func(b(i)) a(i) = b(i) + tmpenddo!$OMP END DO!$OMP END PARALLEL

www.cineca.it
OpenMP Memory ModelFortran:integer :: i=5,n=200real :: tmp=7!$OMP PARALLEL!$OMP DO PRIVATE(tmp)do i=1, n tmp = func(b(i)) a(i) = b(i) + tmpenddo!$OMP END DO!$OMP END PARALLEL

www.cineca.it
OpenMP Memory Model
OpenMP provides a consistent shared-memory model. All threads have access to the main memory to retrieve shared variables.
Each thread also has access to another type of memory that cannot be accessed by another threads, called thread private memory.
A directive that accepts data-sharing attribute clauses determines two kinds of access to variables used in the directive’s associated structured block: shared and private.

www.cineca.it
Data-Sharing Attribute Clauses
• Shared:declares a list of one or more items to be shared by threads generated by a parallel construct.
• Private: declares one or more list items to be private to a task.No other thread can access this data.Changes can only visible to the thread owning the data.• Firstprivate: declares one or more list items to be private to a task, and
initializes each of them with the value that the corresponding original item has when the construct is encountered.

www.cineca.it
Data-Sharing Attribute Clauses
Lastprivate: declares one or more list items to be private to an implicit task, and causes the corresponding original list item to be updated after the end of the region.
!$omp do lastprivate (i)do i = 1,n-1 a(i) = b(i+1)enddo!$omp end doa(i) = b(0)

www.cineca.it
Data-Sharing Attribute Clauses
do i = 1,n x = x + a(i)Enddo

www.cineca.it
Data-Sharing Attribute Clauses
Reduction: The reduction clause specifies an operator and one or more list items. For each list item, a private copy is created in each implicit task, and is initialized appropriately for the operator. After the end of the region, the original list item is updated with the values of the private copies using the specified operator.
!$omp do reduction (+:x)do i = 1,n x = x + a(i)enddo!$omp end doSupport for most arithmetic and logical operators+, *, -, .MIN., .MAX., . AND., .OR., ...

www.cineca.it
Runtime Libraries Routines
OpenMP provides several user-callable functions to control and query parallel environment.
• The Runtime Libraries take precedence over the corrisponding environment variables;
• Recommended to use under control of conditional compilation (#ifdef _OPENMP);
• C/C++ programs need to include <omp.h>;• Fortran program may want to use “USE OMP_LIB” or include
“omp_lib.h”.

www.cineca.it
Runtime Libraries Routines• num_threads=omp_get_num_threads(): Gets number of threads in team;
• thread_id=omp_get_thread_num(): Gets thread ID;
• time=omp_get_wtime(): Return elapsed wall clock time in seconds.
START = omp_get_wtime()... work to be timed ...END = omp_get_wtime()PRINT *, "Work took", END – START, “seconds”

www.cineca.it
Conditional Compilation
With OpenMP compilation, the _OPENMP macro is defined.C:
#ifdef _OPENMPprintf("Compiled with OpenMP support);#elseprintf("Compiled for serial execution.");#endif
Fortran:!$ print *,”Compiled with OpenMP support”

www.cineca.it
Environment Variables
• OMP_NUM_THREADS: sets the number of threads to use for parallel regions;
• OMP_SCHEDULE: controls the schedule type and chunk size of all loop directives that have the schedule type runtime.
• OMP_STACKSIZE: specifies the size of the stack for threads created by the OpenMP implementation.
csh:% setenv OMP_NUM_THREADS 8% setenv OMP_SCHEDULE "guided,4"sh:$ export OMP_NUM_THREADS=8$ export OMP_SCHEDULE=”guided,4”

www.cineca.it
OpenMP Compiler
GNU (Version >= 4.3.2) Compile with -fopenmp For Linux, Solaris, AIX, MacOSX, Windows:
IBM Compile with -qsmp=omp for Windows, AIX and Linux.
Sun Microsystems Compile with -xopenmp for Solaris and Linux.
IntelCompile with -Qopenmp on Windows, or just -openmp on Linux or Mac
Emit useful information to stderr. -openmp-report2
Portland Group Compilers Compile with -mp
Emit useful information to stderr. -Minfo=mp

www.cineca.it
Exercises
Write a serial “Hello World”.Add OpenMP directives to make each thread writing the same message.Add a new message stating whether the code has been compiled in serial or parallel mode.Using the environment variable OMP_NUM_THREADS, try to execute the code with different
numbers of threads.Implement a routine that provides the “thread_id” and the number of threads that are currently
executing the code without using OpenMP functions. The message has to look like“Hello World from thread_id 1 of 4 thread_tot”.
Afterwards, print this message according to the id order:“Hello World from thread_id 0 of 4 thread_tot”.“Hello World from thread_id 1 of 4 thread_tot”.“Hello World from thread_id 2 of 4 thread_tot”.“Hello World from thread_id 3 of 4 thread_tot”.

www.cineca.it
Exercises
optional:Compute the area below the plot of a function using computational methods for integration such as
Simpson, ect. For simplicity you can choose a linear function whose plot defines a rectangular triangle.Split the computational kernel among the threads.

www.cineca.it
Hybrid programming MPI+OpenMP

www.cineca.it
Multi-node SMP (Symmetric Multiprocessor) connected by and interconnection network.
Each node is mapped (at least) one process MPI and OpenMP threads more.
The hybrid model

www.cineca.it
MPI vs. OpenMP Pure MPI Pro:
High scalabilityHigh portabilityNo false sharingScalability out-of-node
Pure MPI Con:Hard to develop and
debug.Explicit communicationsCoarse granularityHard to ensure load
balancing
Pure OpenMP Pro:Easy do deploy (often)Low latencyImplicit communicationsCoarse and fine granularityDynamic Load balancing
Pure OpenMP Con:Only on shared memory machinesIntranode scalability Possible long waits for unlocking
dataNo order specific thread

www.cineca.it
Why hybrid? MPI+OpenMP hybrid paradigm is the trend for clusters with SMP
architecture.
Elegant in concept: use OpenMP within the node and MPI between nodes, in order to have a good use of shared resources.
Avoid additional communication within the MPI node. OpenMP introduces fine-granularity. Two-level parallelism introduces other problems Some problems can be reduced by lowering MPI procs number If the problem is suitable, the hybrid approach can have better
performance than pure MPI or OpenMP codes.

www.cineca.it
Why mixing MPI and OpenMP code can be slower?
OpenMP has lower scalability because of locking resources while MPI has not potential scalability limits.
All threads are idle except ones during an MPI communication Need overlap computation and communication to improve
performance Critical section for shared variables
Overhead of thread creation Cache coherency and false sharing. Pure OpenMP code is generally slower than pure MPI code Few optimizations by OpenMP compilers compared to MPI

www.cineca.it
Pseudo hybrid code
call MPI_INIT (ierr) call MPI_COMM_RANK (…) call MPI_COMM_SIZE (…) … some computation and MPI communication call OMP_SET_NUM_THREADS(4) !$OMP PARALLEL !$OMP DO
do i=1,n … computation enddo !$OMP END DO !$OMP END PARALLEL … some computation and MPI communication call MPI_FINALIZE (ierr)

www.cineca.it
MPI_INIT_Thread support ( MPI-2)
MPI_INIT_THREAD (required, provided, ierr) IN: required, desider level of thread support (integer). OUT: provided, provided level (integer). provided may be less than required.
Four levels are supported: MPI_THREAD_SINGLE: Only one thread will runs. Equals to MPI_INIT. MPI_THREAD_FUNNELED: processes may be multithreaded, but only the
main thread can make MPI calls (MPI calls are delegated to main thread) MPI_THREAD_SERIALIZED: processes could be multithreaded. More than one
thread can make MPI calls, but only one at a time. MPI_THREAD_MULTIPLE: multiple threads can make MPI calls, with no
restrictions.

www.cineca.it
MPI_THREAD_SINGLEHot to implement:
!$OMP PARALLEL DO do i=1,10000 a(i)=b(i)+f*d(i) enddo!$OMP END PARALLEL DO call MPI_Xxx(...)!$OMP PARALLEL DO do i=1,10000 x(i)=a(i)+f*b(i) enddo!$OMP END PARALLEL DO
#pragma omp parallel for for (i=0; i<10000; i++) { a[i]=b[i]+f*d[i]; }/* end omp parallel for */ MPI_Xxx(...);#pragma omp parallel for for (i=0; i<10000; i++) { x[i]=a[i]+f*b[i]; }/* end omp parallel for */

www.cineca.it
MPI_THREAD_FUNNELEDOnly the main thread can do MPI communications. Obviously,
there is a main thread for each node

www.cineca.it
MPI_THREAD_FUNNELED MPI calls outside the parallel region.
Inside the parallel region with “omp master”.
!$OMP BARRIER!$OMP MASTER call MPI_Xxx(...)!$OMP END MASTER!$OMP BARRIER
There are no synchronizations with “omp master”, thus needs a barrier before and after, to ensure that data and buffers are availabe before and/or after MPI calls
#pragma omp barrier#pragma omp master MPI_Xxx(...);#pragma omp barrier

www.cineca.it
MPI_THREAD_SERIALIZED MPI calls are made concurrently by two (or more) different threads
(all MPI calls are serialized)

www.cineca.it
MPI_THREAD_SERIALIZED Outside the parallel region
Inside the parallel region with ”omp master”
Inside the parallel region with “omp single”
!$OMP BARRIER!$OMP SINGLE call MPI_Xxx(...)!$OMP END SINGLE
#pragma omp barrier#pragma omp single MPI_Xxx(...);

www.cineca.it
MPI_THREAD_MULTIPLEAny thread can make communications at all times. Less restrictive
and very flexible, but the application becomes very hard to manage

www.cineca.it
A little example#include <mpi.h>#include <omp.h>#include <stdio.h>
int main(int argc, char *argv[]){ int rank,omp_rank,mpisupport; MPI_Init_thread(&argc,&argv,MPI_THREAD_FUNNELED, &mpisupport); MPI_Comm_rank(MPI_COMM_WORLD,&rank); omp_set_num_threads(atoi(argv[1])); #pragma omp parallel private(omp_rank) { omp_rank=omp_get_thread_num(); printf("%d %d \n",rank,omp_rank); } MPI_Finalize();}
0 0 0 2 0 1 0 3 1 0 1 2 1 1 1 3
Output-->

www.cineca.it
Overlap communications and computation
Need at least MPI_THREAD_FUNNELED. While the master or the single thread is making MPI calls,
other threads are doing computations. It's difficult to separate code that can run before or after the
exchanged data are available
!$OMP PARALLEL if (thread_id==0) then call MPI_xxx(…) else do some computation endif !$OMP END PARALLEL

www.cineca.it
THREAD FUNNELED/SERIALIZED vs. Pure MPI
FUNNELED/SERIALIZED: All other threads are sleeping while just one thread is
communicating. Only one thread may not be able to lead up max internode
bandwidth
Pure MPI: Each CPU communication can lead up max internode
bandwidth
Overlap communications and computations.

www.cineca.it
The various implementations differs in levels of thread-safety If your application allow multiple threads to make MPI calls If your application allow multiple threads to make MPI calls
simultaneously, whitout MPI_THREAD_MULTIPLE, is not simultaneously, whitout MPI_THREAD_MULTIPLE, is not thread-safethread-safe
In OpenMPI, you have to use –enable-mpi-threads at compile In OpenMPI, you have to use –enable-mpi-threads at compile time to activate all levels.time to activate all levels.
Higher level corresponds higher thread-safety. Use the required Higher level corresponds higher thread-safety. Use the required safety needs.safety needs.

www.cineca.it
Collective operations are often bottlenecks
All-to-all communications Point-to-point can be faster Hybrid implementation: For all-to-all communications, the
number of transfers decrease by a factor #threads^2
The length of messages increases by a factor #threads
Allow to overlap communication and computation.

www.cineca.it
Collective operations are often bottlenecks
All-to-all communications Point-to-point can be faster
Hybrid implementation: For all-to-all communications, the
number of transfers decrease by a factor #threads^2
The length of messages increases by a factor #threads
Allow to overlap communication and computation.

www.cineca.it
Collective operations are often bottlenecks
All-to-all communications Point-to-point can be faster
Hybrid implementation: For all-to-all communications, the
number of transfers decrease by a factor #threads^2
The length of messages increases by a factor #threads
Allow to overlap communication and computation.

www.cineca.it
Domain decomposition In MPI implementation, each process
has to exchange ghost-cell
This even two different processes are within the same node. This is because two different process do not share the
same memory

www.cineca.it
Hybrid approach allows you to share the memory area where ghost-cell are stored
Each thread has not to do communication within the node, since it already has
available data.
Communication decreases, and as in the previous case, increases MPI message
size.
Domain decomposition

www.cineca.it
Space Integrals: Electrostatic potentialsimple loop parallelization
!$omp parallel do default(shared), private(rp,is,rhet,rhog,fpibg), reduction(+:eh,ehte,ehti) DO ig = gstart, ngm rp = (0.D0,0.D0) DO is = 1, nsp rp = rp + sfac( ig, is ) * rhops( ig, is ) END DO rhet = rhoeg( ig ) rhog = rhet + rp IF( tscreen ) THEN fpibg = fpi / ( g(ig) * tpiba2 ) + screen_coul(ig) ELSE fpibg = fpi / ( g(ig) * tpiba2 ) END IF vloc(ig) = vloc(ig) + fpibg * rhog eh = eh + fpibg * rhog * CONJG(rhog) ehte = ehte + fpibg * DBLE(rhet * CONJG(rhet)) ehti = ehti + fpibg * DBLE( rp * CONJG(rp)) END DO
Hartree potentialHatree EnergyIonic contributionElectronic contribution
Electronic density (reciprocal space)
Ionic density (reciprocal space)
! IBM xlf compiler does not like name of function used for OpenMP reduction

www.cineca.it
Space Integral: Non local energyless simple loop parallelization
!$omp do do ia = 1, na(is) inl = ish(is)+(iv-1)*na(is)+ia jnl = ish(is)+(jv-1)*na(is)+ia isa = isa+1 sums = 0.d0 do i = 1, n iss = ispin(i) sums(iss) = sums(iss) + f(i) * bec(inl,i) * bec(jnl,i) end do sumt = 0.d0 do iss = 1, nspin rhovan( ijv, isa, iss ) = sums( iss ) sumt = sumt + sums( iss ) end do if( iv .ne. jv ) sumt = 2.d0 * sumt ennl = ennl + sumt * dvan( jv, iv, is) end do!$omp end do
!$omp parallel default(shared), &!$omp private(is,iv,ijv,isa,ism,ia,inl,jnl,sums,i,iss,sumt), reduction(+:ennl) do is = 1, nsp do iv = 1, nh(is) do jv = iv, nh(is) ijv = (jv-1)*jv/2 + iv isa = 0 do ism = 1, is - 1 isa = isa + na(ism) end do!$omp do ...!$omp end do
end do end do end do!$omp end parallel
Larger parallel region to reduceThe fork/join overhead

www.cineca.it
Point Function evaluation: Exchange and Correlation energy
!$omp parallel do private( rhox, arhox, ex, ec, vx, vc ), reduction(+:etxc) do ir = 1, nnr rhox = rhor (ir, nspin) arhox = abs (rhox) if (arhox.gt.1.d-30) then CALL xc( arhox, ex, ec, vx(1), vc(1) ) v(ir,nspin) = e2 * (vx(1) + vc(1) ) etxc = etxc + e2 * (ex + ec) * rhox endif enddo!$omp end parallel do
Real space electronic charge density
XC functional (external subroutine)XC PotentialXC Energy

www.cineca.it
Gram-Schmidt kernel: dealing with thread private allocatable array
!$omp parallel default(shared), private( temp, k, ig )
ALLOCATE( temp( ngw ) )
!$omp do DO k = 1, kmax csc(k) = 0.0d0 IF ( ispin(i) .EQ. ispin(k) ) THEN DO ig = 1, ngw temp(ig) = cp(1,ig,k) * cp(1,ig,i) + cp(2,ig,k) * cp(2,ig,i) END DO csc(k) = 2.0d0 * SUM(temp) IF (gstart == 2) csc(k) = csc(k) - temp(1) ENDIF END DO!$omp end do
DEALLOCATE( temp )
!$omp end parallel

www.cineca.it
Example of non trivial loop parallelization
DO nt = 1, ntyp IF ( upf(nt)%tvanp ) THEN ! DO ih = 1, nh(nt) ! DO jh = ih, nh(nt)! CALL qvan2( ngm, ih, jh, nt, qmod, qgm, ylmk0 ) !!$omp parallel default(shared), private(na,qgm_na,is,dtmp,ig,mytid,ntids)#ifdef __OPENMP mytid = omp_get_thread_num() ntids = omp_get_num_threads() #endif ALLOCATE( qgm_na( ngm ) ) ! DO na = 1, nat !#ifdef __OPENMP IF( MOD( na, ntids ) /= mytid ) CYCLE #endif IF ( ityp(na) == nt ) THEN qgm_na(1:ngm) = qgm(1:ngm)*eigts1(ig1(1:ngm),na)*eigts2(ig2(1:ngm),na)*eigts3(ig3(1:ngm),na) DO is = 1, nspin_mag dtmp = 0.0d0 DO ig = 1, ngm dtmp = dtmp + aux( ig, is ) * CONJG( qgm_na( ig ) ) END DO deeq(ih,jh,na,is) = fact * omega * DBLE( dtmp ) deeq(jh,ih,na,is) = deeq(ih,jh,na,is) END DO END IF END DO DEALLOCATE( qgm_na )!$omp end parallel END DO END DO END IF END DO
take the thread ID
take the number of threads
distribute atoms round-robin to threads

www.cineca.it
Logical Machine Organization
The logical organization, seen by the programmer, could be different from the hardware architecture.
Its quite easy to logically partition a Shared Memory computer to reproduce a Distributed memory Computers.
The opposite is not true.

www.cineca.it
Parallel Programming Paradigms
The two architectures determine two basic scheme for parallel programming
Message Passing (distributed memory)
all processes could directly access only their local memory
Data Parallel (shared memory)
Single memory view, all processes (usually threads) could directly access the whole memory

www.cineca.it
Programming Environments
Message Passing Data Parallel
Standard compilers Ad hoc compilers
Communication Libraries Source code Directive
Ad hoc commands to run the program Standard Unix shell to run the program
Standards: MPI, PVM Standards: OpenMP, HPF
www.cineca.it
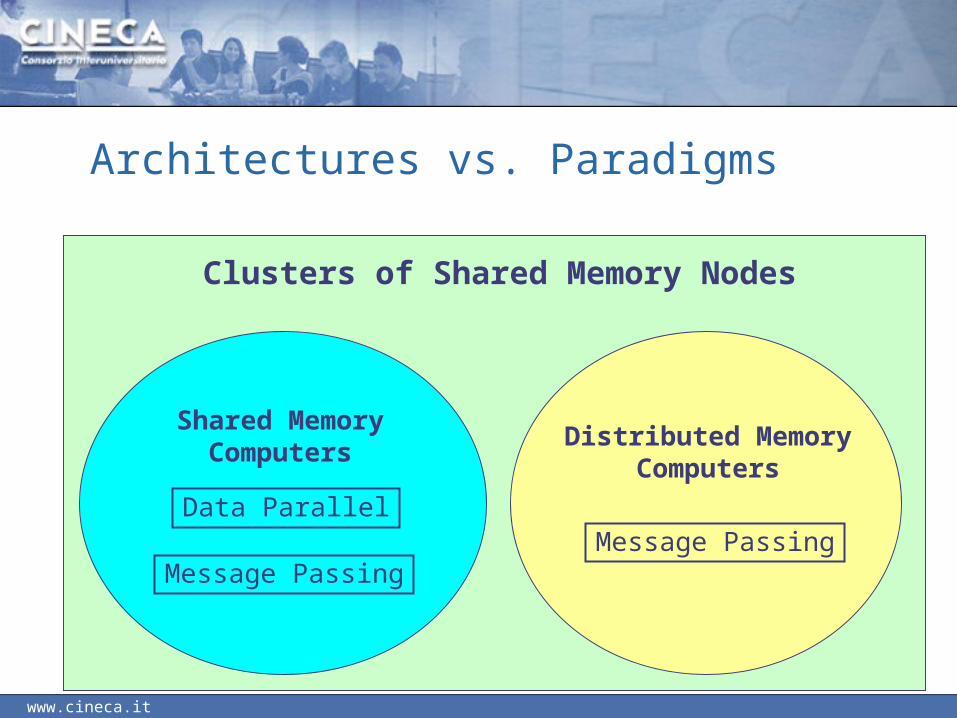
Architectures vs. Paradigms
Shared MemoryComputers
Distributed MemoryComputers
Message Passing
Data ParallelMessage Passing
Clusters of Shared Memory Nodes

















