35
Shark: SQL and Rich Analytics at Scale Reynold Xin, Josh Rosen, Matei Zaharia, Michael Franklin, Scott Shenker, Ion Stoica AMPLab, UC Berkeley June 25 @ SIGMOD 2013

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 1/35
Shark: SQL and RichAnalytics at Scale
Reynold Xin, Josh Rosen, Matei Zaharia, Michael Franklin, ScottShenker, Ion Stoica
AMPLab, UC Berkeley
June 25 @ SIGMOD 2013

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 2/35
Challenges
Data size growing » Processing has to scale out over large
clusters » Faults and stragglers complicate DB design
Complexity of analysis increasing
» Massive ETL (web crawling) » Machine learning, graph processing » Leads to long running jobs

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 3/35
The Rise of MapReduce

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 4/35
What’s good about
MapReduce?1. Scales out to thousands of nodes in a fault-
tolerant manner
2. Good for analyzing semi-structured data andcomplex analytics
3. Elasticity (cloud computing) 4. Dynamic, multi-tenant resource sharing

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 5/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 6/35
“parallel relational database systems aresignicantly faster than those that rely on the
use of MapReduce for their query engines”
“I totally agree.”

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 7/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 8/35
This Research
1. Shows MapReduce model can be extended tosupport SQL efciently
» Started from a powerful MR-like engine (Spark) » Extended the engine in various ways
2. The artifact: Shark, a fast engine on top of MR » Performant SQL » Complex analytics in the same engine » Maintains MR benets, e.g. fault-tolerance

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 9/35
MapReduce Fundamental Properties?
Data-parallel operations » Apply the same operations on a dened set of data
Fine-grained, deterministic tasks » Enables fault-tolerance & straggler mitigation

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 10/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 11/35
Why Were Databases Faster?
Data representation » Schema-aware, column-oriented, etc »
Co-partition & co-location of data Execution strategies
» Scheduling/task launching overhead (~20s in Hadoop) »
Cost-based optimization
» Indexing
Lack of mid-query fault tolerance »
MR’s pull model costly compared to DBMS “push”
See Pavlo 2009, Xin 2013.

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 12/35
Why Were Databases Faster?
Data representation » Schema-aware, column-oriented, etc »
Co-partition & co-location of data
Execution strategies » Scheduling/task launching overhead (~20s in Hadoop) »
Cost-based optimization
» Indexing
Lack of mid-query fault tolerance »
MR’s pull model costly compared to DBMS “push”
See Pavlo 2009, Xin 2013.
Not fundamental to
“MapReduce”
Can besurprisingly
cheap

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 13/35
Introducing Shark
MapReduce-based architecture » Uses Spark as the underlying execution engine »
Scales out and tolerate worker failures
Performant » Low-latency, interactive queries »
(Optionally) in-memory query processing
Expressive and exible » Supports ot SQL and complex analytics » Hive compatible (storage, UDFs, types, metadata, etc)

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 14/35
Spark Engine
Fast MapReduce-like engine » In-memory storage for fast iterative computations »
General execution graphs
» Designed for low latency (~100ms jobs)
Compatible with Hadoop storage APIs »
Read/write to any Hadoop-supported systems, includingHDFS, Hbase, SequenceFiles, etc
Growing open source platform » 17 companies contributing code

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 15/35
More Powerful MR EngineGeneral task DAG
Pipelines functionswithin a stage
Cache-aware data locality & reuse
Partitioning-aware to avoid shufes
!"#$
&$#"$
'("&)*+
,-)
./-'0 1
./-'0 2
./-'0 3
45 *5
65 75
85
95
:5
; )(0<#"&=>+ ?",)&/0@ )-(/#/#"$
8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 16/35
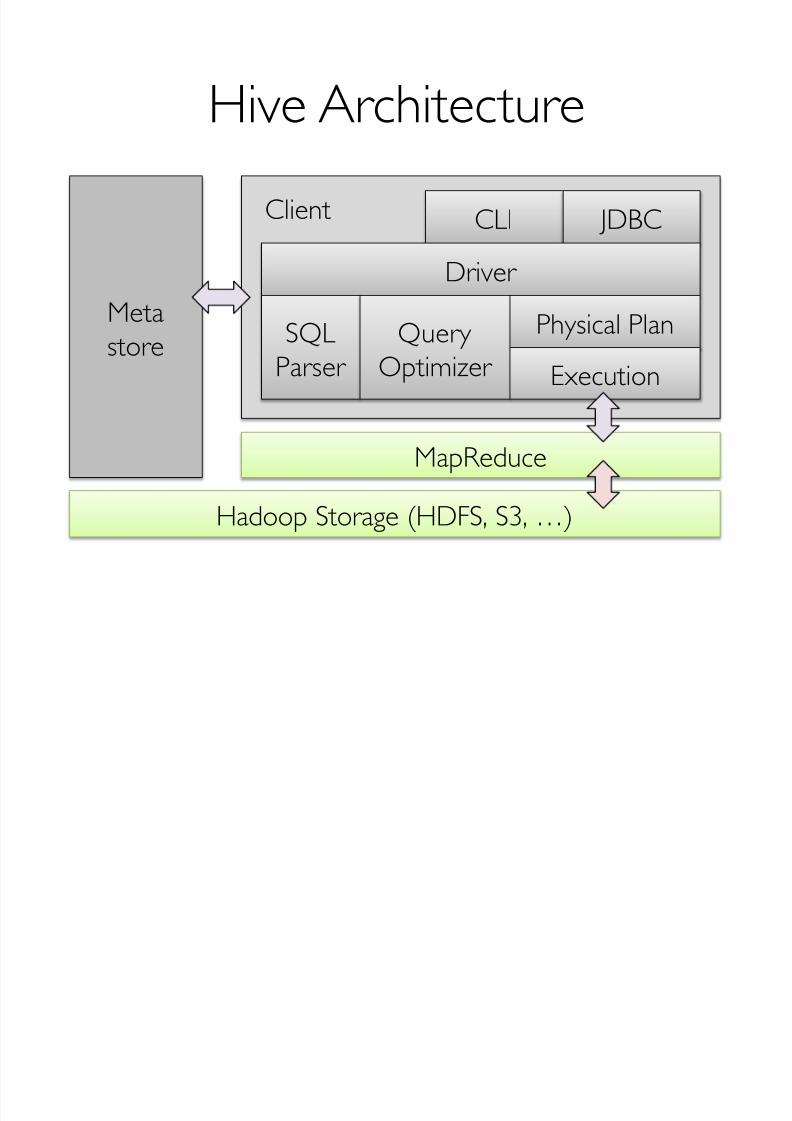
Client CLI JDBC
Hive Architecture
Metastore
Hadoop Storage (HDFS, S3, …)
Driver SQL
Parser Query
Optimizer Physical Plan
Execution
MapReduce
8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 17/35
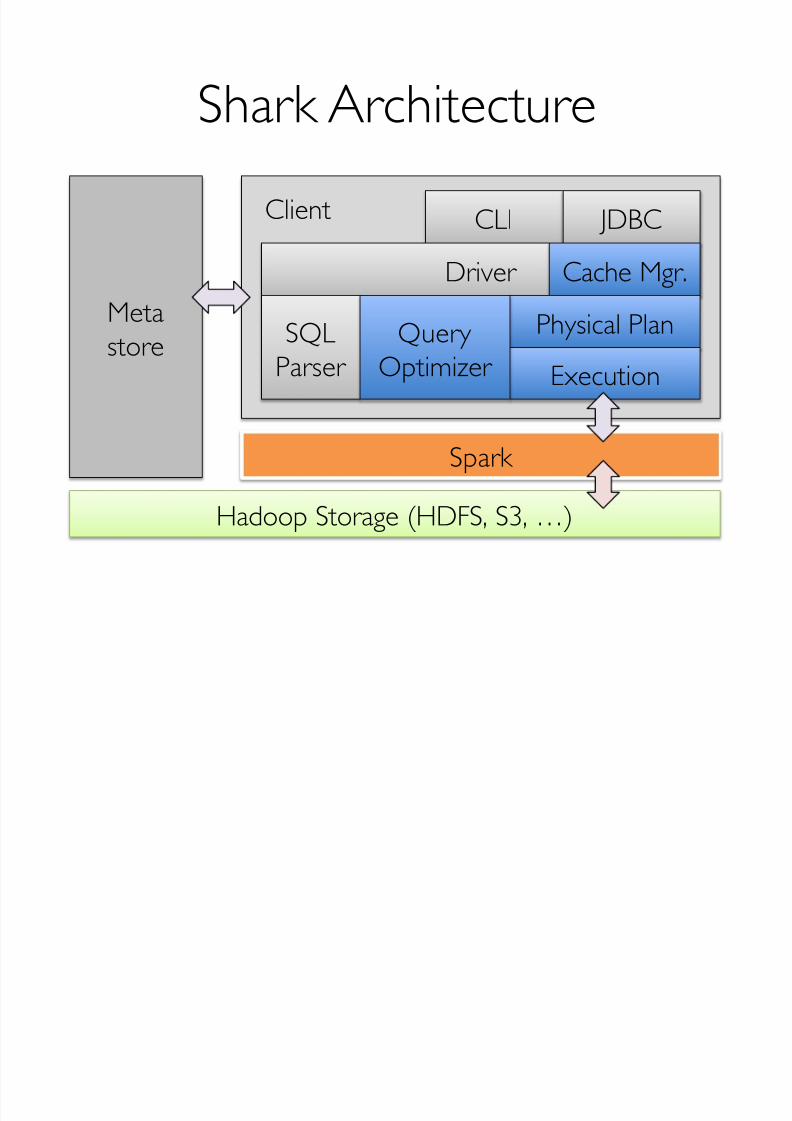
Client CLI JDBC
Shark Architecture
Metastore
Hadoop Storage (HDFS, S3, …)
Driver SQL
Parser
Spark
Cache Mgr. Physical Plan
Execution Query
Optimizer

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 18/35
Extending Spark for SQL
Columnar memory store
Dynamic query optimization
Miscellaneous other optimizations (distributed top-K, partition statistics & pruning a.k.a. coarse-
grained indexes, co-partitioned joins, …)

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 19/35
Columnar Memory Store
Simply caching records as JVM objects is inefcient(huge overhead in MR’s record-oriented model)
Shark employs column-oriented storage, apartition of columns is one MapReduce “record”.
2
!"#$%& ()"*+,-
3 1
!"A$ ,#B0 =->>+
CD2 1DE FDC
."/ ()"*+,-
2 !"A$ CD2
3 ,#B0 1DE
1 =->>+ FDCBenet: compact representation, CPU efcientcompression, cache locality.

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 20/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 21/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 22/35
Partial DAG Execution (PDE)
Lack of statistics for fresh data and the prevalentuse of UDFs necessitate dynamic approaches to
query optimization.
PDE allows dynamic alternation of query plans based on statistics collected at run-time.

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 23/35
Shufe Join
Stage 3Stage 2
Stage 1
Join
Result
Stage 1
Stage 2
JoinResult
Map Join (Broadcast Join)
minimizes network trafc

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 24/35
PDE Statistics
Gather customizable statistics at per-partitiongranularities while materializing map output.
» partition sizes, record counts (skew detection) » “heavy hitters” » approximate histograms
Can alter query plan based on such statistics » map join vs shufe join » symmetric vs non-symmetric hash join » skew handling

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 25/35
Complex Analytics IntegrationUnied system for SQL,machine learning
Both share the same setof workers and caches
def logRegress(points: RDD[Point] ): Vector {var w = Vector (D, _ => 2 * rand.nextDouble - 1)for (i <- 1 to ITERATIONS) {
val gradient = points.map { p =>val denom = 1 + exp(-p.y * (w dot p.x))(1 / denom - 1) * p.y * p.x
}.reduce(_ + _) w -= gradient
} w
}
val users = sql2rdd( "SELECT * FROM user u
JOIN comment c ON c.uid=u.uid" )
val features = users.mapRows { row =>new Vector (extractFeature1(row.getInt( "age" )),
extractFeature2(row.getStr( "country" )),...)}
val trainedVector = logRegress(features.cache())

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 26/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 27/35
Machine Learning Performance
!"#$%&' )*+',$-.&/
0 12 34 506 577 560
583
795
:;/.',.< =$/-$''.;&
0 47 76 34 >2 540
550
09>2
?@%-A B%C;;D
Runtime per iteration (secs)
8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 28/35
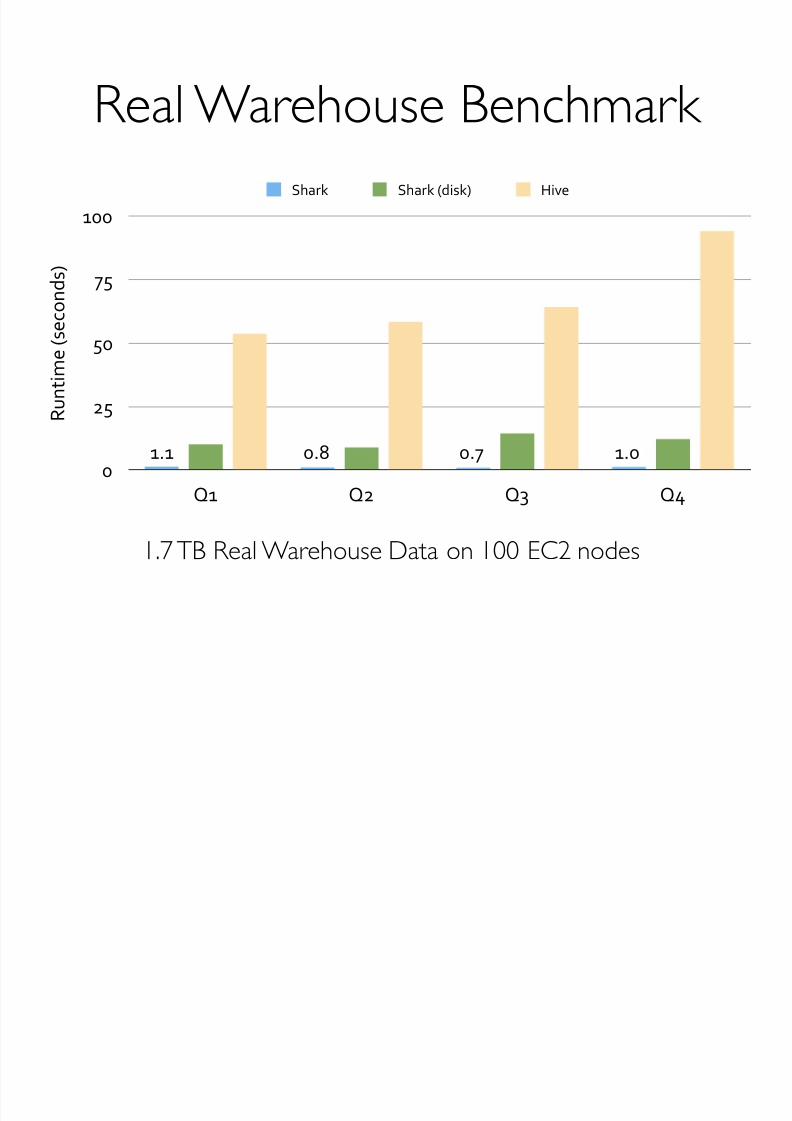
Real Warehouse Benchmark
!
"#
#!
$#
%!!
&% &" &' &(
) * + , - . /
1 2 / 3 4 + 5 2 6
789:; 789:; 15-2;6 <-=/
%>% !>? !>$ %>!
1.7 TB Real Warehouse Data on 100 EC2 nodes

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 29/35
New Benchmark
!"#$%$
!"#$%$ '"(")
*(+,-./0
1-$23 '+.,3)
1-$23 '"(")
4 5 64 65 74
*890."( ',(:;9+,)
http://tinyurl.com/bigdata-benchmark

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 30/35
Other benets of MapReduce
Elasticity » Query processing can scale up and down dynamically
Straggler Tolerance
Schema-on-read & Easier ETL
Engineering » MR handles task scheduling / dispatch / launch » Simpler query processing code base (~10k LOC)
8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 31/35
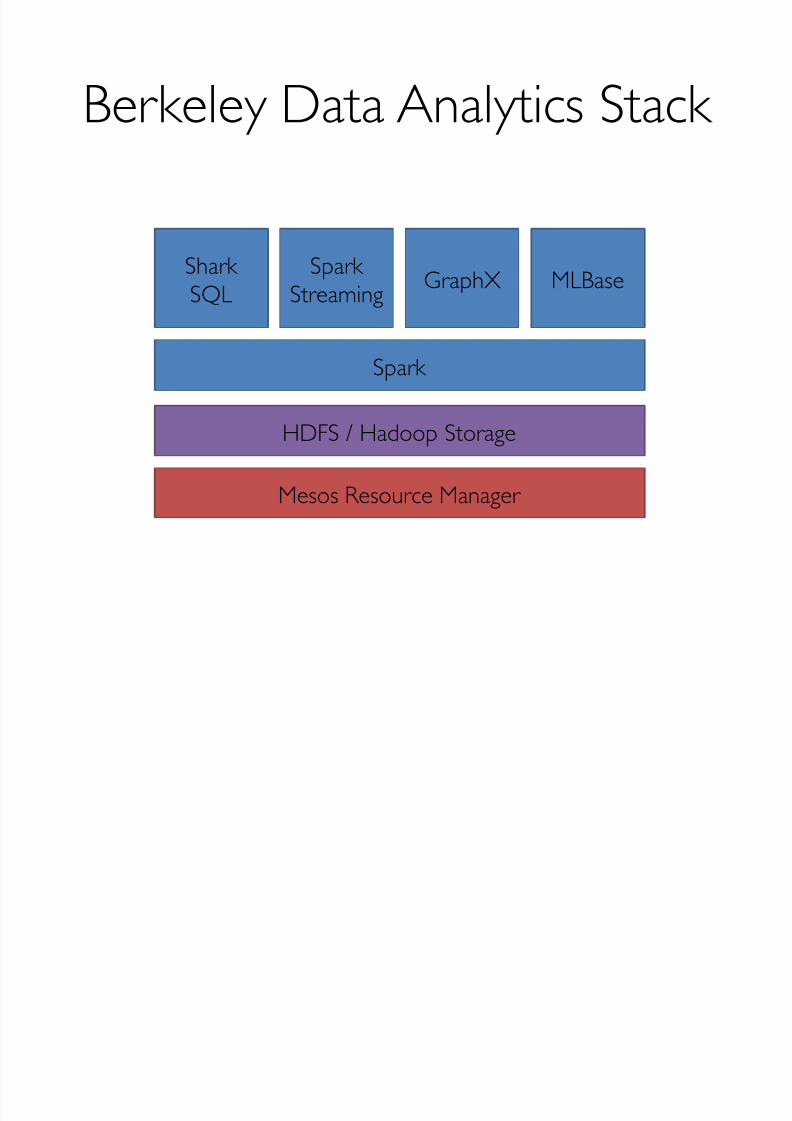
Berkeley Data Analytics Stack
Spark
Shark SQL
HDFS / Hadoop Storage
Mesos Resource Manager
SparkStreaming GraphX MLBase

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 32/35
Community
3000 people attendedonline training
800 meetup members 17 companies contributing

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 33/35
Conclusion
Leveraging a modern MapReduce engine and techniques from databases, Shark supports both
SQL and complex analytics efciently, whilemaintaining fault-tolerance.
Growing open source community » Users observe similar speedups in real use cases » http://shark.cs.berkeley.edu » http://www.spark-project.org

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 34/35

8/12/2019 xin-june27-425pm-room230c-130710131659-phpapp02 (1)
http://slidepdf.com/reader/full/xin-june27-425pm-room230c-130710131659-phpapp02-1 35/35
MapReduce MSs hark

















