

Compiler-Generated Compiler-Generated Staggered Staggered CheckpointingCheckpointing
Alison N. NormanDepartment of Computer SciencesThe University of Texas at Austin
Sung-Eun ChoiLos Alamos National Laboratory
Calvin LinDepartment of Computer SciencesThe University of Texas at Austin

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 22
The Importance of The Importance of ClustersClusters Scientific computation is increasingly Scientific computation is increasingly
performed on clustersperformed on clusters– Cost-effective: Created from commodity Cost-effective: Created from commodity
partsparts Scientists want more computational Scientists want more computational
power power Cluster computational power is easy to Cluster computational power is easy to
increase by adding processorsincrease by adding processors
Cluster size keeps increasing!Cluster size keeps increasing!

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 33
Clusters Are Not Clusters Are Not PerfectPerfect Failure rates are increasingFailure rates are increasing
– The number of moving parts is The number of moving parts is growing (processors, network growing (processors, network connections, disks, etc.)connections, disks, etc.)
Mean Time Between Failure (MTBF) Mean Time Between Failure (MTBF) is shrinking is shrinking
How can we deal with these failures?How can we deal with these failures?

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 44
Options forOptions forFault-ToleranceFault-Tolerance Redundancy in spaceRedundancy in space
– Each participating process has a Each participating process has a backup processbackup process
– Expensive!Expensive! Redundancy in timeRedundancy in time
– Processes save state and then Processes save state and then rollback for recoveryrollback for recovery
– Lighter-weight fault toleranceLighter-weight fault tolerance

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 55
Today’s AnswerToday’s Answer
Programmers place checkpointsProgrammers place checkpoints– Small checkpoint sizeSmall checkpoint size– SynchronousSynchronous
Every process checkpoints in the same Every process checkpoints in the same place in the codeplace in the code
Global synchronization before and Global synchronization before and after checkpointsafter checkpoints

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 66
What’s the Problem?What’s the Problem?
Future systems will be largerFuture systems will be larger Checkpointing will hurt program Checkpointing will hurt program
performanceperformance– Many processes checkpointing Many processes checkpointing
synchronously will result in network and file synchronously will result in network and file system contentionsystem contention
– Checkpointing to local disk not viableCheckpointing to local disk not viable Application programmers are only willing Application programmers are only willing
to pay 1% overhead for fault-toleranceto pay 1% overhead for fault-tolerance The solution:The solution:
– Avoid synchronous checkpointsAvoid synchronous checkpoints

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 77
Solution: Staggered Solution: Staggered CheckpointingCheckpointing Spread individual checkpoints in time to Spread individual checkpoints in time to
reduce network and file system reduce network and file system contentioncontention
Possible approaches existPossible approaches exist– Dynamic---Runtime overhead!Dynamic---Runtime overhead!– Do not guarantee reduced contentionDo not guarantee reduced contention
This talk is going to explain: This talk is going to explain: – Why staggered checkpointing is a good Why staggered checkpointing is a good
solutionsolution– Difficulties of staggered checkpointingDifficulties of staggered checkpointing– How a compiler can helpHow a compiler can help

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 88
ContributionsContributions
Show that synchronous checkpointing will Show that synchronous checkpointing will suffer significant contentionsuffer significant contention
Show that staggered checkpointing Show that staggered checkpointing improves performance:improves performance:– Reduces checkpoint latency up to a factor of 23Reduces checkpoint latency up to a factor of 23– Enables more frequent checkpoints Enables more frequent checkpoints
Describe a prototype compiler for identifying Describe a prototype compiler for identifying staggered checkpointsstaggered checkpoints
Show that there is great potential for Show that there is great potential for staggering checkpoints within applicationsstaggering checkpoints within applications

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 99
Talk OutlineTalk Outline
MotivationMotivation Our SolutionOur Solution
– Build communication graphBuild communication graph– Create vector clocksCreate vector clocks– Identify recovery linesIdentify recovery lines
ResultsResults Future WorkFuture Work Related WorkRelated Work ConclusionConclusion

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1010
Understanding Understanding Staggered Staggered CheckpointingCheckpointingTodayToday::
0
2
1
X
X
X
Pro
cess
es
Time
…
64K
Tomorrow:Tomorrow:
checkpointcheckpointcheckpoint checkpoint
with with contentioncontention
No problem!No problem!More processes, more data, More processes, more data, synchronous checkpoints synchronous checkpoints Contention!
That’s easy! That’s easy! We’ll stagger the We’ll stagger the
checkpoints….checkpoints….
Not so fast… There Not so fast… There is communication!is communication!
Recovery Recovery lineline [Randall
75]
VALID VALID Recovery Recovery
lineline
Send Send not not savedsaved
Receive Receive is is savedsaved
Send Send is is savedsaved
Receive Receive not savednot saved
State is State is inconsistentinconsistent------it could it could notnot have existed have existed
State is State is consistentconsistent---it could have ---it could have existedexisted

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1111
Complications with Complications with Staggered Staggered CheckpointingCheckpointingCheckpoints must be placed Checkpoints must be placed
carefully:carefully:– Want valid recovery linesWant valid recovery lines– Want low contentionWant low contention– Want small stateWant small state
This is difficult!This is difficult!

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1212
Our SolutionOur Solution
Compiler places staggered Compiler places staggered checkpointscheckpoints– Builds communication graphBuilds communication graph– Calculates vector clocksCalculates vector clocks– Identifies valid recovery linesIdentifies valid recovery lines

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1313
Assumptions in our Assumptions in our Prototype CompilerPrototype Compiler Number of nodes known at compile-Number of nodes known at compile-
timetime Communication only dependent on:Communication only dependent on:
– Node rankNode rank– Number of nodes in the systemNumber of nodes in the system– Other constantsOther constants
Explicit communicationExplicit communication– Implementation assumes MPIImplementation assumes MPI

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1414
First Step:First Step:Build Communication Build Communication GraphGraph
Find Find neighbor neighbor at each communication callat each communication call– Symbolic expression analysis Symbolic expression analysis – Constant propagation and foldingConstant propagation and folding
MPI_irecv(x, x, x, from_process, …)
from_process = from_process = node_ranknode_rank % sqrt( % sqrt(no_nodesno_nodes) - 1) - 1
– Instantiate each processInstantiate each process Control-dependence analysisControl-dependence analysis
– Not all communication calls are executed every Not all communication calls are executed every time time
Match sends with receives, etc.Match sends with receives, etc.

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1515
Example:Example:Communication GraphCommunication Graph
0
2
1
Time
Pro
cess
es

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1616
Second Step: Second Step: Calculate Vector Calculate Vector ClocksClocks Use communication graphUse communication graph Create vector clocks (we will review!)Create vector clocks (we will review!)
– Iterate through callsIterate through calls– Track dependencesTrack dependences– Keep current clocks with each callKeep current clocks with each call

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1717
Example:Example:Calculate Vector Calculate Vector ClocksClocks
0
2
1
[1,0,0]
[2,3,2]
[2,0,2]
[1,2,0]
[2,0,0]
[2,0,1]
[1,1,0]
[2,4,2]
[3,2,0]
[2,5,2]
[4,5,2]
[2,4,3]
Time
[3][2][1]
[5]
[4][3]
[2][1]
[4][3][1] [2]
Pro
cess
es
[1,1,0]
[1,0,0]
[Lamport 78]
Vector Clocks: capture inter-process Vector Clocks: capture inter-process dependencesdependences
Track events within a processTrack events within a process[P0,P1,P2]

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1818
Next Step:Next Step:Identify All PossibleIdentify All PossibleValid Recovery LinesValid Recovery Lines
0
2
1
Time
Pro
cess
es
There are so many!There are so many!
[2,4,2]
[3,2,0]
[2,5,2]
[4,5,2]
[2,4,3]
[1,0,0]
[2,3,2]
[2,0,2]
[1,2,0]
[2,0,0]
[2,0,1]
[1,1,0]
Final Step: Choose Final Step: Choose some! And then place some! And then place
them in the code…them in the code…

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 1919
Talk OutlineTalk Outline
MotivationMotivation Our SolutionOur Solution ResultsResults
– MethodologyMethodology– Contention EffectsContention Effects– Benchmark ResultsBenchmark Results
Future WorkFuture Work Related WorkRelated Work ConclusionConclusion

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2020
Event-driven SimulatorEvent-driven Simulator– Models computation events, communication Models computation events, communication
events, and checkpointing eventsevents, and checkpointing events– Network, file system modeled optimisticallyNetwork, file system modeled optimistically– Cluster characteristics are modeled after an Cluster characteristics are modeled after an
actual clusteractual cluster
MethodologyMethodology
Compiler ImplementationCompiler Implementation– Implemented in Broadway Compiler Implemented in Broadway Compiler [Guyer & Lin 2000][Guyer & Lin 2000]
– Accepts C code, generates C code Accepts C code, generates C code with checkpoints with checkpoints
Trace GeneratorTrace Generator– Generates traces from Generates traces from
pre-existing benchmarkspre-existing benchmarks– Uses static analysis and profilingUses static analysis and profiling
CompilerCompiler
SimulatorSimulator
FSFSTrace Trace
GeneratorGenerator

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2121
Synthetic BenchmarkSynthetic Benchmark
Large number of sequential instructionsLarge number of sequential instructions 2 checkpoint locations per process2 checkpoint locations per process Simulated with 2 checkpointing policiesSimulated with 2 checkpointing policies
Policy 1: Policy 1: Synchronous– Every process checkpoints simultaneouslyEvery process checkpoints simultaneously– Barrier before, barrier afterBarrier before, barrier after
Policy 2: Policy 2: Staggered– Processes checkpoint in groups of fourProcesses checkpoint in groups of four– Spread evenly throughout the sequential instructionsSpread evenly throughout the sequential instructions
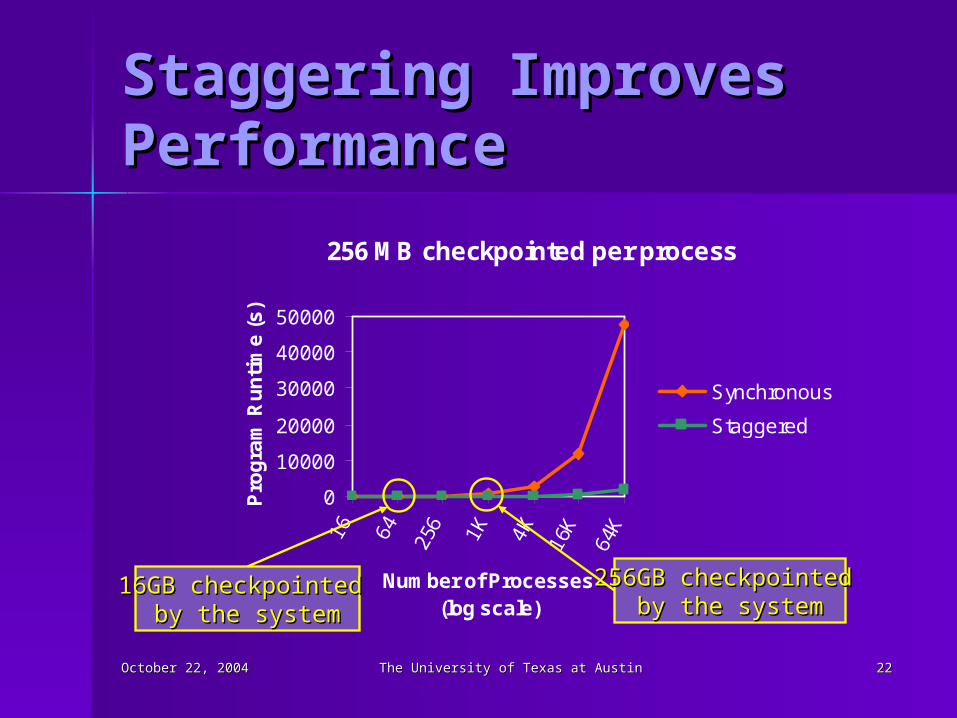
October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2222
Staggering Improves Staggering Improves PerformancePerformance
256 MB checkpointed per process
0
10000
20000
30000
40000
5000016 64 256 1K 4K 16K
64K
Number of Processes (log scale)
Pro
gra
m R
un
tim
e (
s)
Synchronous
Staggered
256GB checkpointed 256GB checkpointed by the systemby the system
16GB checkpointed 16GB checkpointed by the systemby the system

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2323
0
50
100
150
200
16 64 256 1K 4K 16K 64K
What About a Fixed What About a Fixed Problem Size?Problem Size?
Average Checkpoint Time Per Average Checkpoint Time Per ProcessProcess
Number of Number of ProcessesProcesses
Synchronous, 16GB, 16GBStaggered, 16GB, 16GB
Staggered checkpointing Staggered checkpointing improves performanceimproves performance
Staggered checkpointing Staggered checkpointing becomes more helpful asbecomes more helpful as– Number of processes Number of processes
increasesincreases– Amount of data Amount of data
checkpointed increasescheckpointed increases
Amount of data Amount of data checkpointedcheckpointed
by the by the systemsystem
Average Checkpoint Time Per Average Checkpoint Time Per ProcessProcess
Tim
e
Tim
e
(s)
(s)
Number of Number of ProcessesProcesses
Numbers represented Numbers represented in previous graphin previous graph

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2424
What About a Fixed What About a Fixed Problem Size?Problem Size?
0
50
100
150
200
16 64 256 1K 4K 16K 64K
700
750
800
Average Checkpoint Time Per Average Checkpoint Time Per ProcessProcess
Tim
e
Tim
e
(s)
(s)
Number of Number of ProcessesProcesses
23x improvement23x improvement
Synchronous, 16GB, 16GBStaggered, 16GB, 16GB
Staggered, 256GB, 256GB
Staggered checkpointing Staggered checkpointing improves performanceimproves performance
Staggered checkpointing Staggered checkpointing becomes more helpful asbecomes more helpful as– Number of processes Number of processes
increasesincreases– Amount of data Amount of data
checkpointed increasescheckpointed increases
Synchronous, , 256GB256GB
Numbers represented Numbers represented in previous graphin previous graph

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2525
Staggering Allows Staggering Allows More CheckpointsMore Checkpoints Staggered Staggered
checkpointing checkpointing allows allows processes to processes to checkpoint checkpoint more oftenmore often
Can checkpoint Can checkpoint 9.3x more 9.3x more frequently for frequently for 4K processes4K processes
1% allowed checkpoint overhead, 16 GB checkpointed by the system
0
100
200
300
400
500
600
700
800
900
1000
1K 4K 16K 64KNumber of Processes in the System
Nu
mb
er
of P
oss
ible
Ch
eck
po
ints
Synchronous Staggered

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2626
Benchmark Benchmark CharacteristicsCharacteristics
IS, , BT are versions of the NAS Parallel are versions of the NAS Parallel BenchmarksBenchmarks
ek-simple is CFD benchmark is CFD benchmark
BenchmarBenchmarkk
Collective Collective CommunicatiCommunicati
onon
Point-to-Point Point-to-Point CommunicatiCommunicati
onon
IS 1414 22
BT 88 2424
ek-simple 66 5252

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2727
Unique ValidUnique ValidRecovery LinesRecovery Lines
BenchmarkBenchmark4 4
processeprocessess
9 9 processeprocesse
ss
16 16 processeprocesse
ss
IS 55 55 55
BT 3030 7373 191191
ek-simple 9898 57,20657,206 >2>22424
Lots of point-to-point communication means many Lots of point-to-point communication means many unique valid recovery linesunique valid recovery lines
ek-simple is most representative of real applications is most representative of real applications These recovery lines differ These recovery lines differ onlyonly with respect to with respect to
dependence-creating communication dependence-creating communication
Number of statically unique valid recovery Number of statically unique valid recovery lineslines

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2828
Future WorkFuture Work
Develop heuristic to identify good Develop heuristic to identify good recovery linesrecovery lines– Determining optimal is NP complete Determining optimal is NP complete [Li et al [Li et al
94]94]
Scalable simulationScalable simulation– Develop more realistic contention modelsDevelop more realistic contention models
Relax assumptions in compilerRelax assumptions in compiler– Dynamically changing communication Dynamically changing communication
patternspatterns

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 2929
Related WorkRelated Work
Checkpointing with compilersCheckpointing with compilers– Compiler-Assisted Compiler-Assisted [Beck et al 1994][Beck et al 1994]
– Automatic Checkpointing Automatic Checkpointing [Choi & Deitz 2002][Choi & Deitz 2002]
– Application-Level Non-Blocking Application-Level Non-Blocking [Bronevetsky et al [Bronevetsky et al 2003]2003]
Dynamic fault-tolerant protocolsDynamic fault-tolerant protocols– Message logging Message logging [Elnozahy et al 2002][Elnozahy et al 2002]

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3030
ConclusionsConclusions
Synchronous checkpointing suffers from Synchronous checkpointing suffers from contentioncontention
Staggered checkpoints reduce contentionStaggered checkpoints reduce contention– Reduces checkpoint latency up to a factor of 23 Reduces checkpoint latency up to a factor of 23 – Allows the application to tolerate more failures Allows the application to tolerate more failures
without a corresponding increase in overheadwithout a corresponding increase in overhead A compiler can identify where to A compiler can identify where to
stagger checkpointsstagger checkpoints Unique valid recovery lines are numerous in Unique valid recovery lines are numerous in
applications with point-to-point applications with point-to-point communicationcommunication

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3131
Thank Thank you!you!

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3232
Dynamic ValidDynamic ValidRecovery LinesRecovery Lines
BenchmarkBenchmark 4 4 processeprocesse
ss
9 9 processeprocesse
ss
16 16 processesprocesses
IS 8 8 (5)(5) 8 8 (5)(5) 8 8 (5)(5)
BT 53 53 (30)(30) 139 139 (73)(73) 375 375 (191)(191)
ek-simple 113 113 (98)(98) 65,586 65,586 (57,206)(57,206)
641,568,40641,568,404 4 (>2(>22424))
Number of dynamically unique valid Number of dynamically unique valid recovery linesrecovery lines

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3333
Fault ModelFault Model
Crash
Receive OmissionSend Omission
General Omission
Arbitrary failureswith message authentication
Arbitrary (Byzantine) failures

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3434
Vector Clock FormulaVector Clock Formula

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3535
Message LoggingMessage Logging
Saves all messages sent to stable Saves all messages sent to stable storagestorage
In the future, storing this data will be In the future, storing this data will be untenableuntenable
Message logging relies on Message logging relies on checkpointing so that logs can be checkpointing so that logs can be clearedcleared

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3636
In-flight messages:In-flight messages:Why we don’t careWhy we don’t care We reason about them at the We reason about them at the
application level so…application level so…– Messages are assumed received at actual Messages are assumed received at actual
receive call or at waitreceive call or at wait– We will know if any messages crossed the We will know if any messages crossed the
recovery line. We can prepare for recovery line. We can prepare for recovery by checkpointing that recovery by checkpointing that information.information.

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3737
C-BreezeC-Breeze
In-house compilerIn-house compiler Allows us to reason about code at Allows us to reason about code at
various phases of compilationvarious phases of compilation Allows us to add our own phasesAllows us to add our own phases

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3838
In the future…In the future…
Systems will be more complexSystems will be more complex Programs will be more complexPrograms will be more complex Checkpointing will be more complexCheckpointing will be more complex Programmer should not waste time Programmer should not waste time
and talent handling fault-toleranceand talent handling fault-tolerance
Algorithm
FORTRAN/C/C++
MPI
Checkpointing
October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 3939

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4040
Solution GoalsSolution Goals
Transparent checkpointingTransparent checkpointing– Use the compiler to place checkpointsUse the compiler to place checkpoints
Low failure-free execution overheadLow failure-free execution overhead– Stagger checkpointsStagger checkpoints– Minimize checkpoint stateMinimize checkpoint state
Support legacy codeSupport legacy code

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4141
The IntuitionThe Intuition
Fault-tolerance requires valid recovery Fault-tolerance requires valid recovery lineslines
Many possible valid recovery linesMany possible valid recovery lines– Find themFind them– Automatically choose a good oneAutomatically choose a good one
Small state, low contentionSmall state, low contention Flexibility is keyFlexibility is key

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4242
Our SolutionOur Solution
Where is the set of valid recovery Where is the set of valid recovery lines?lines?– Determine communication patternDetermine communication pattern– Use vector clocksUse vector clocks
Which recovery line should we use?Which recovery line should we use?– Develop heuristics based on cluster Develop heuristics based on cluster
architecture and application (not done yet)architecture and application (not done yet)

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4343
Overview: StatusOverview: Status
Discover communication patternDiscover communication pattern Create vector clocksCreate vector clocks Identify possible recovery linesIdentify possible recovery lines Select recovery lineSelect recovery line
– ExperimentationExperimentation– Performance model and heuristicPerformance model and heuristic

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4444
Finding neighborsFinding neighbors
Find the neighbors for each process:Find the neighbors for each process:p = sqrt(no_nodes) cell_coord[0][0] = node % pcell_coord[1][0] = node / p;j = cell_coord[0][0] - 1i = cell_coord[1][0] - 1from_process = (i – 1 + p) % p + p * jMPI_irecv(x, x, x, from_process, …)
(taken from NAS benchmark bt)(taken from NAS benchmark bt)
from_process = (from_process = (nodenode / (sqrt( / (sqrt(no_nodesno_nodes)) - 1 – 1 + )) - 1 – 1 + sqrt(sqrt(no_nodesno_nodes)) % sqrt()) % sqrt(no_nodesno_nodes) + ) +
sqrt(sqrt(no_nodesno_nodes) * ) * nodenode % sqrt( % sqrt(no_nodesno_nodes) - 1) - 1

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4545
Final Step: Final Step: Recovery LinesRecovery Lines Discover possible recovery linesDiscover possible recovery lines Choose a good oneChoose a good one Determining optimal is NP complete Determining optimal is NP complete [Li 94][Li 94]
– Develop heuristicDevelop heuristic Rough performance model for staggeringRough performance model for staggering
GoalsGoals– Valid recovery lineValid recovery line– Reduce bandwidth contentionReduce bandwidth contention– Reduce storage spaceReduce storage space

October 22, 2004October 22, 2004 The University of Texas at AustinThe University of Texas at Austin 4646
What about a fixed What about a fixed problem size?problem size?
Staggered checkpointing improves performanceStaggered checkpointing improves performance Staggered checkpointing becomes more helpful asStaggered checkpointing becomes more helpful as
– number of processes increasesnumber of processes increases– amount of data checkpointed increasesamount of data checkpointed increases
1616 6464 256256 1K1K 4K4K 16K16K 64K64K
16 GB16 GB 3.83.8 7.677.67 9.29.2 11.511.5 9.29.2 9.29.2 9.29.2
256 256 GBGB
3.983.98 15.915.911
22.122.188
22.922.944
22.922.944
23.323.311
23.323.311
Average checkpoint speedup (x faster) per process :Average checkpoint speedup (x faster) per process :StaggeredStaggered over over Synchronous. Synchronous.
Number of Number of ProcessesProcesses
Data
D
ata
ch
eck
poin
ted b
y
check
poin
ted b
y
the s
yst
em
the s
yst
em
Numbers represented Numbers represented in previous graphin previous graph







