

- Assume everybody here has heard of the project - The broad aim is to give Australia a world class broadband network for generations - NBN is a wholesaler of Ethernet layer two network – many, many retailers - Three different technologies in use: 93% Fibre, 4% Fixed Wireless, 3% Satellite - Look at our webpage – contains news updates well justified with factual data and
lots of interesting technical detail.

- Small part of the overall organization (approx 5% - 10%) - Internal development organizations founded with Agile principles in mind - Very much a DevOps style shop, responsible for the end to end delivery process
(all the way to PROD)
- We started with a virtual blank slate - We had an externally hosted basic website and a payrole system - Our brief was to build a exciting web presence and all the externally facing
applications needed to accept Orders and Tickets for a Telco - Build a classic three layer infrastructure with an external hosting provider - Multiple copies of the environment CI, Dev, Staging, Prod (80 machines) - Management pressure to build it really fast! - We felt the direction we where headed was towards ‘snowflake servers’ and we
wanted to avoid it

- Puppet to the rescue!
- I’m going to tell you about our journey with Puppet - The mistakes we made, the breakthroughs in understanding we had - This stuff is not an NBN competitive advantage, we’re happy to share and learn
from our mistakes

- Machine population is segregated into groups to provide isolation for your production environment
- Puppet agent installed as daemon and running with 30 minute period
- Method of segregation was initially by splitting the manifest top level directory per environment


- This process was working to a certain definition of ‘working’, but definitely not optimal
- Not DRY - A lot of time was spent copying information from one directory to another and
manually repeating processes - Analysis of what is different across environments using a diff tool
- Not building snowflake servers, our servers where closely related (fruit) - But not 100% confident that our lower layer environments closely reflect what’s in
production - The promotion process is reliant on a lot of manual processes

- We were better than we would have been than cowboying changes straight onto the box with SSH
- But we are still aren’t a well oiled machine
- At this point we decided that we needed to be better and kicked off a big refactor of our work

- Our operations team working very closely with our development team - Lots of exchange of ideas - Our Dev groups were very keen on implementing Continuous Delivery - We decided that we’d do this with our virtual machine setup too - Follow the same patterns as software development
- Multiple environments Dev, UAT, Staging, Prod - We were getting divergence between our different environments due to manual
merge processes - Change from distinct directories per environment to single manifest directory share
by all environments

- This is a big change that we wanted to do safely - We’ve still got infrastructure changes that need to be made each day - Need to establish a red/green refactor cycle with good test coverage
- Make good behaviour for your developers easy - Fast feedback loop - Single top level script that runs test suite locally - Spawns lots of parallel processes running the catalogue compile for every node

- Now using version control system the right way - Easy traceability of who changed a recipe, when and why - To change a recipe you don’t have to repeat yourself lots of time and do lots
manual steps
- Syntax checking is not enough! - More specific functional testing - Over time we added more tests to catch the repeated errors we were making - Extends the safety net so that you fail early (it breaks in Dev not in PROD)

- CI server runs our build system with every check in to source control - The team learns about a mistake as soon as it is made, not some indeterminate
time later
- Refactor safely completed - Celebration!

- Environment promotion pipeline - NB: version number is fastest changing in lower environments - Only ‘good’ versions are available for promotion to higher environments
- Invert the mode in which the Puppet agent is run - Instead of polling the Puppet agent is invoked only when instructed - We use Mcollective for this

- Different environments are pulling different versions of the same manifest directory structure
- Dev has the newest version, Prod has the oldest version
- There are class of errors that can only be detected by running directly on the server and testing the result
- The ‘—noop’ flag is the best way to ‘guessing’ what will really happen when you apply a manifest

- An agent to ‘kick’ the puppet daemon and run in –noop mode - Kick the puppet agent for real and run using the environment to which you belong


- Give strong visual and immediate feedback on the results of a change - Green banner == change passed tests - Provide centralized report that shows ‘what would change if I were to deploy this
version’
- Give strong visual and immediate feedback on the results of a change - This one not so good - Provide Puppet detailed output leading developer directly to the failing node and
failure reason.



- Surprise, the new DC is ready – we need you to move in before Christmas!
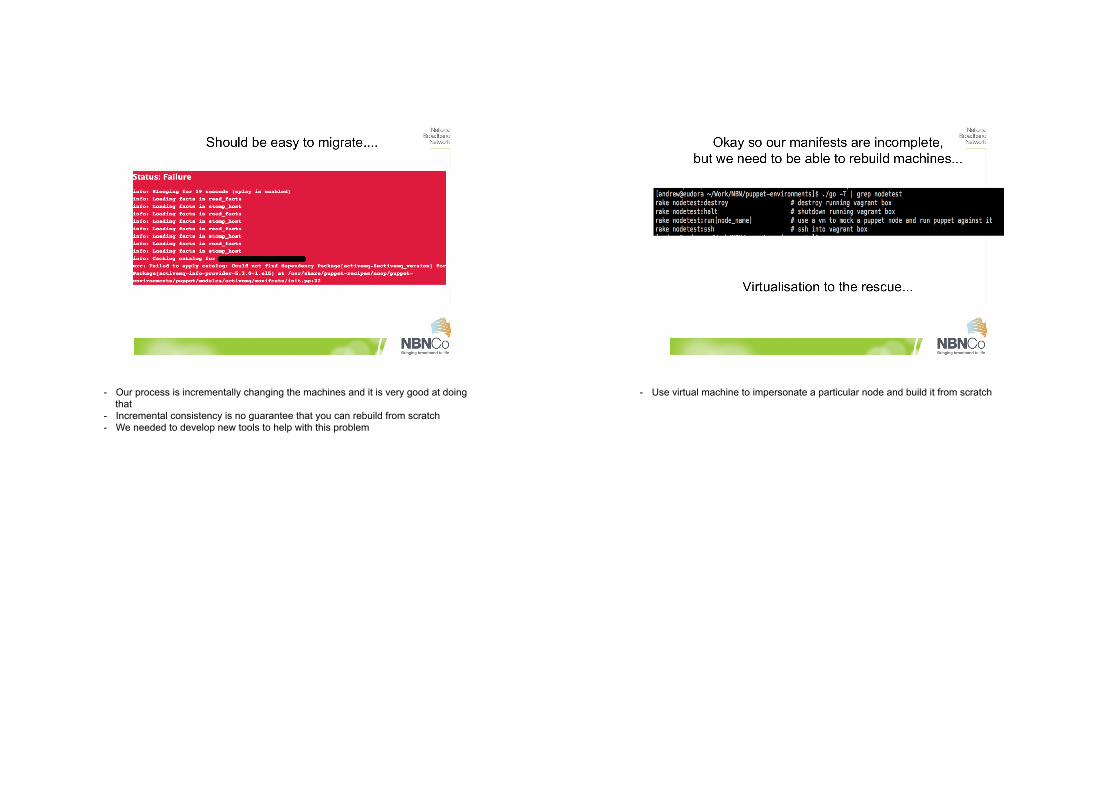
- Our process is incrementally changing the machines and it is very good at doing that
- Incremental consistency is no guarantee that you can rebuild from scratch - We needed to develop new tools to help with this problem
- Use virtual machine to impersonate a particular node and build it from scratch

- Vagrant + VirtualBox + Puppet is a great combination for learning! - Provides new team members a safe environment to learn about the PROD
manifests in detail - Is an essential part of building great team with knowledge shared broadly across
memebers

- Its your safety net, make sure you use it all the time - Sometimes ‘urgent’ changes that you think can ‘easily’ be cowboyed straight onto
the box aren’t as easy as you thought
- 5 minutes delay (the time to run through a well configured pipeline) isn’t an inefficiency worth working without a safety net








