Параллельные вычислительные технологии Осень 2014 (Parallel Computing Technologies, PCT 14) Лекция 2. Архитектура вычислительных систем с общей памятью Пазников Алексей Александрович Кафедра вычислительных систем СибГУТИ Сайт курса: http://cpct.sibsutis.ru/~apaznikov/teaching/ Вопросы: https://piazza.com/sibsutis.ru/fall2014/pct14/home
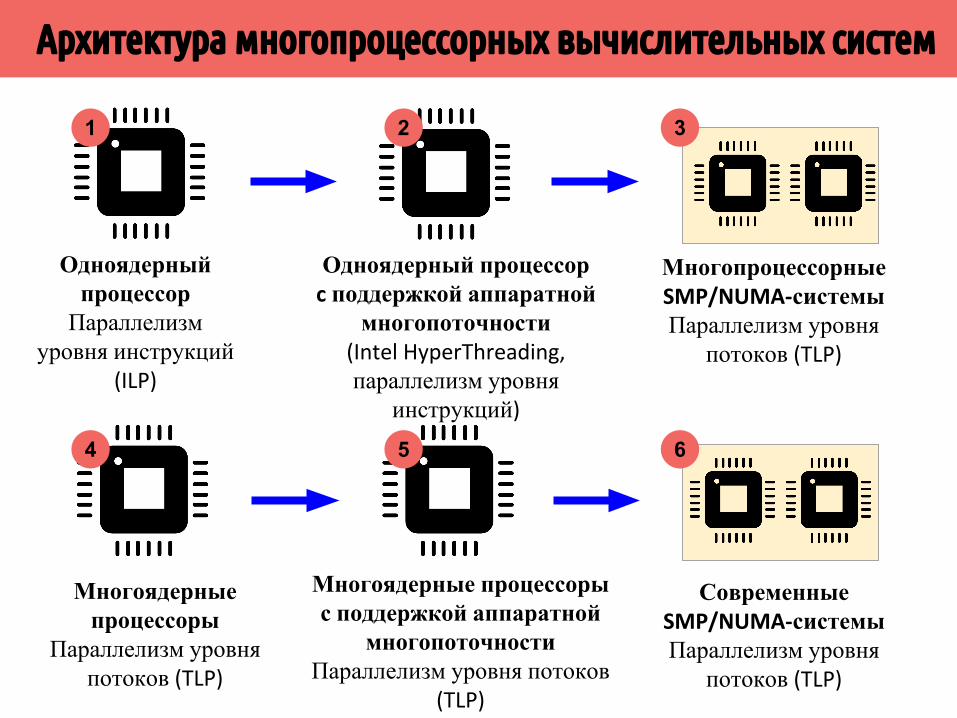
Параллелизм уровня инструкций (Instruction level parallelism – ILP)
▪ Архитектурные решения для обеспечения параллельного выполнения инструкций▫ Суперскалярный конвейер (Superscalar pipeline) – исполняющие
модули конвейера присутствуют в нескольких экземплярах (несколько ALU, FPU, Load/Store-модулей)
▫ Внеочередное исполнение команд (Out-of-order execution) – переупорядочивание команд для максимально загрузки ALU, FPU, Load/Store (минимизация зависимости по данным между инструкциями, выполнение инструкций по готовности их данных)
▫ SIMD-инструкции – модули ALU, FPU, Load/Store поддерживают операции над векторами (инструкции SSE, AVX, AltiVec, NEON SIMD)
▫ VLIW-архитектура (Very Long Instruction Word) – процессор с широким командным словом оперирует с инструкциями, содержащими в себе несколько команд, которые можно выполнять параллельно на ALU/FPU/Load-Store (Intel Itanium, Transmeta Efficeon, Texas Instruments TMS320C6x, ЗАО “МЦСТ” Эльбрус)
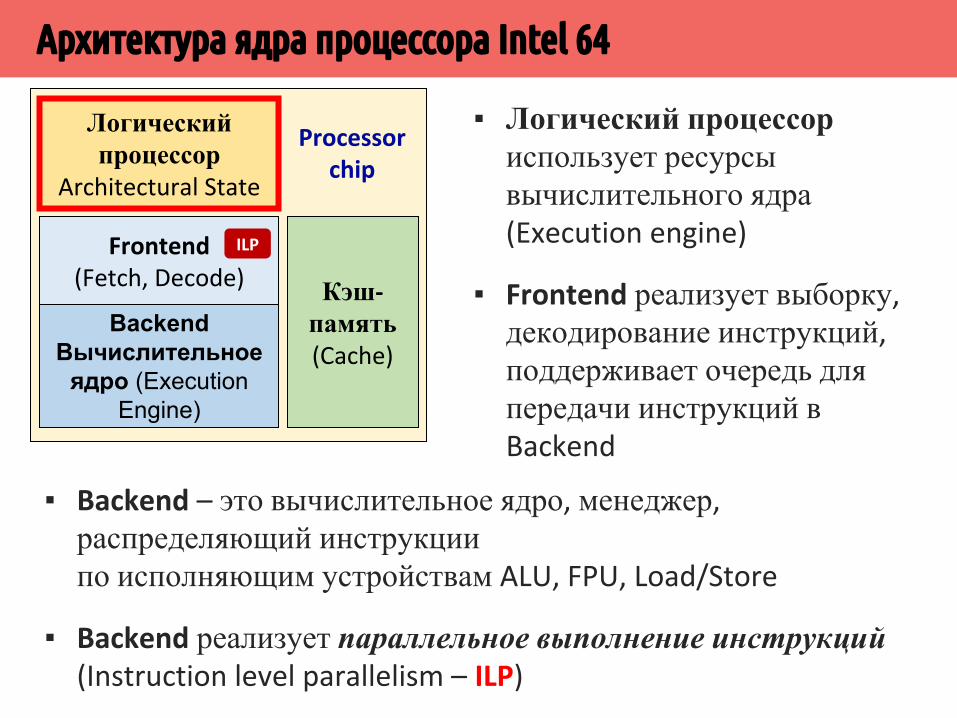
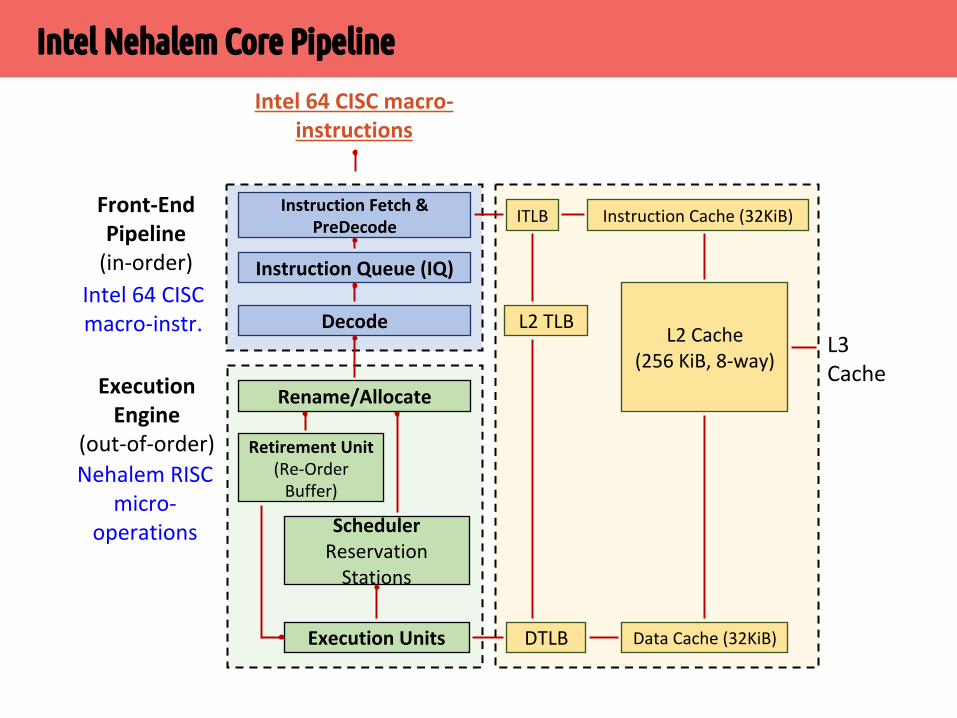
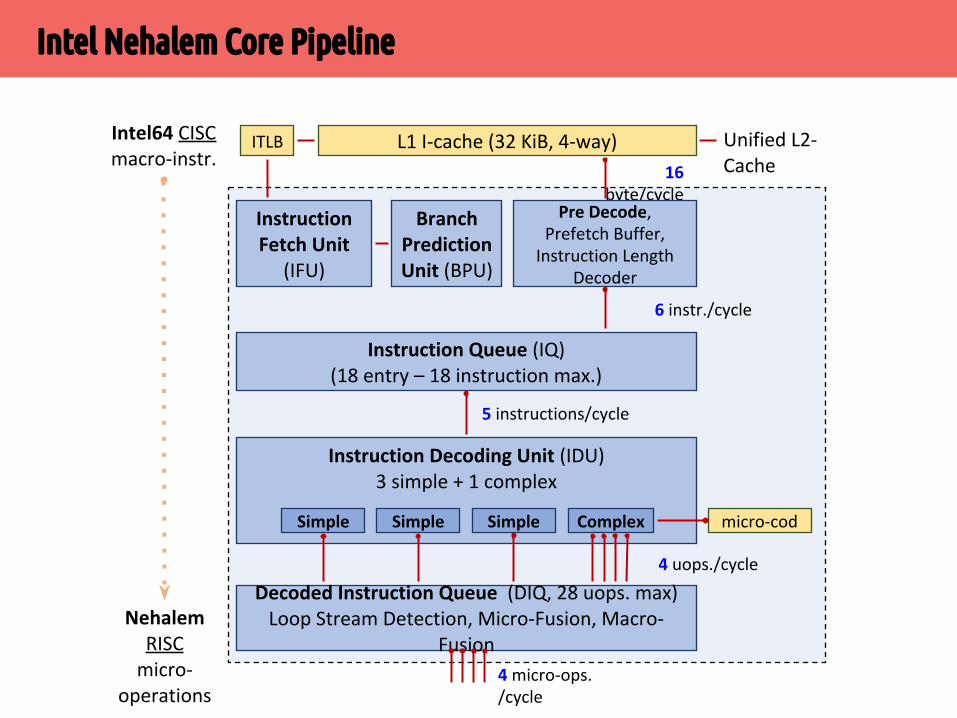
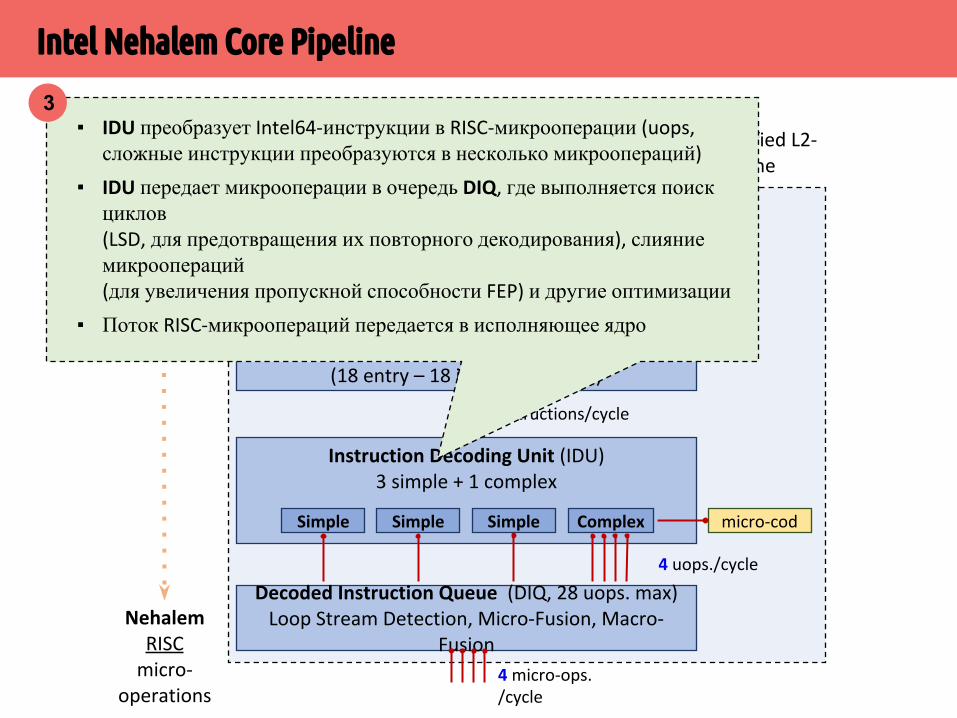
▪ IDU преобразует Intel64-инструкции в RISC-микрооперации (uops, сложные инструкции преобразуются в несколько микроопераций)
▪ IDU передает микрооперации в очередь DIQ, где выполняется поиск циклов (LSD, для предотвращения их повторного декодирования), слияние микроопераций (для увеличения пропускной способности FEP) и другие оптимизации
▪ Поток RISC-микроопераций передается в исполняющее ядро
3
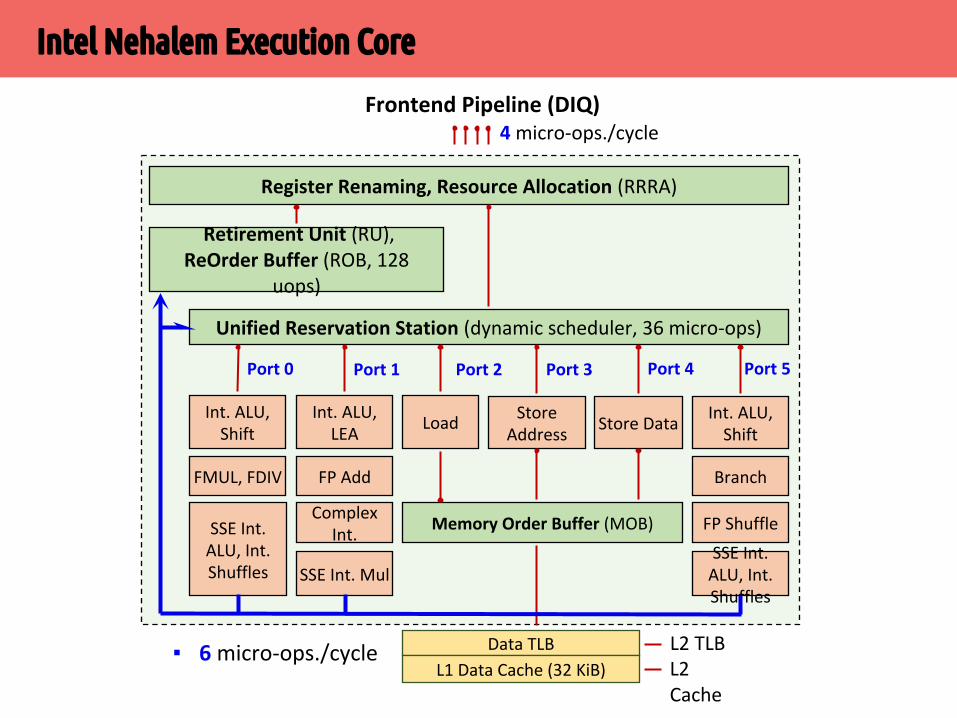
Intel Nehalem Execution Core
4 micro-ops./cycleFrontend Pipeline (DIQ)
Register Renaming, Resource Allocation (RRRA)
Retirement Unit (RU), ReOrder Buffer (ROB, 128
uops)
Unified Reservation Station (dynamic scheduler, 36 micro-ops)
Int. ALU,Shift
FMUL, FDIV
SSE Int. ALU, Int. Shuffles
Int. ALU,LEA
FP Add
Complex Int.
SSE Int. Mul
LoadStore
AddressStore Data
Int. ALU,Shift
Branch
FP Shuffle
SSE Int. ALU, Int. Shuffles
Memory Order Buffer (MOB)
Port 0 Port 1 Port 2 Port 3 Port 4 Port 5
Data TLB
L1 Data Cache (32 KiB) L2 Cache
L2 TLB▪ 6 micro-ops./cycle
Intel Nehalem Execution Core
4 micro-ops./cycleFrontend Pipeline (DIQ)
Register Renaming, Resource Allocation (RRRA)
Retirement Unit (RU), ReOrder Buffer (ROB, 128
uops)
Unified Reservation Station (dynamic scheduler, 36 micro-ops)
Int. ALU,Shift
FMUL, FDIV
SSE Int. ALU, Int. Shuffles
Int. ALU,LEA
FP Add
Complex Int.
SSE Int. Mul
LoadStore
AddressStore Data
Int. ALU,Shift
Branch
FP Shuffle
SSE Int. ALU, Int. Shuffles
Memory Order Buffer (MOB)
Port 0 Port 1 Port 2 Port 3 Port 4 Port 5
Data TLB
L1 Data Cache (32 KiB) L2 Cache
L2 TLB▪ 6 micro-ops./cycle
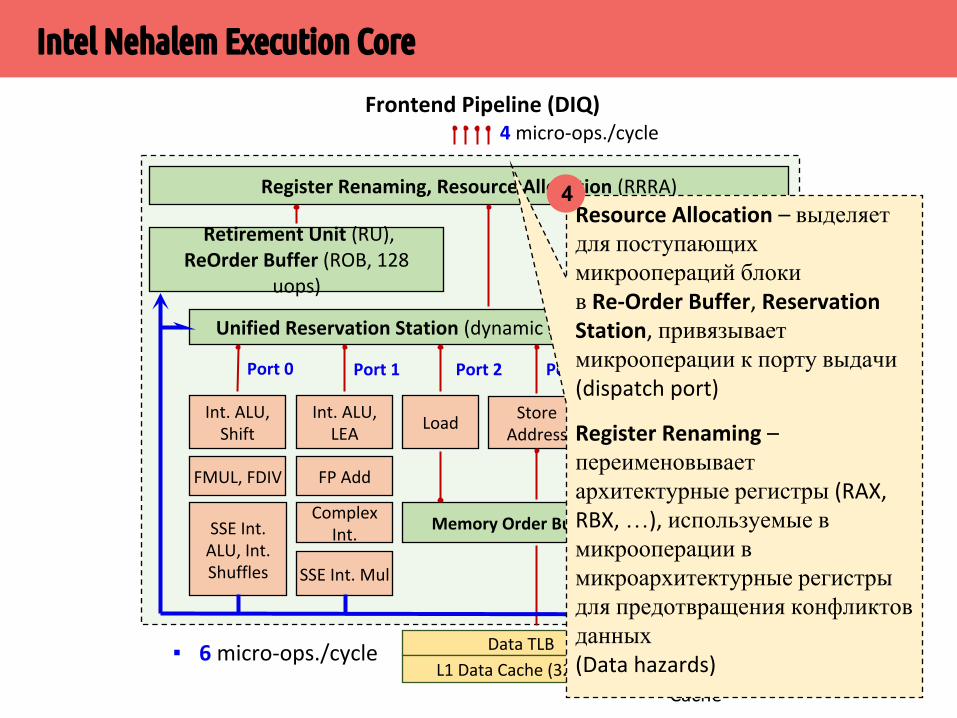
Resource Allocation – выделяет для поступающих микроопераций блоки в Re-Order Buffer, Reservation Station, привязывает микрооперации к порту выдачи (dispatch port)
Register Renaming – переименовывает архитектурные регистры (RAX, RBX, …), используемые в микрооперации в микроархитектурные регистры для предотвращения конфликтов данных (Data hazards)
4
Intel Nehalem Execution Core
4 micro-ops./cycleFrontend Pipeline (DIQ)
Register Renaming, Resource Allocation (RRRA)
Retirement Unit (RU), ReOrder Buffer (ROB, 128
uops)
Unified Reservation Station (dynamic scheduler, 36 micro-ops)
Int. ALU,Shift
FMUL, FDIV
SSE Int. ALU, Int. Shuffles
Int. ALU,LEA
FP Add
Complex Int.
SSE Int. Mul
LoadStore
AddressStore Data
Int. ALU,Shift
Branch
FP Shuffle
SSE Int. ALU, Int. Shuffles
Memory Order Buffer (MOB)
Port 0 Port 1 Port 2 Port 3 Port 4 Port 5
Data TLB
L1 Data Cache (32 KiB) L2 Cache
L2 TLB▪ 6 micro-ops./cycle
▪ URS – пул из 36 микроопераций + динамический планировщик▪ Если операнды микрооперации готовы, она направляется на одно их исполняющих устройств – выполнение по готовности данных (максимум 6 микроопераций/такт – 6 портов)
▪ URS реализует разрешения некоторых конфликтов данных – передает результат выполненной операции напрямую на вход другой (если требуется, forwarding, bypass)
5
Intel Nehalem Execution Core
4 micro-ops./cycleFrontend Pipeline (DIQ)
Register Renaming, Resource Allocation (RRRA)
Retirement Unit (RU), ReOrder Buffer (ROB, 128
uops)
Unified Reservation Station (dynamic scheduler, 36 micro-ops)
Int. ALU,Shift
FMUL, FDIV
SSE Int. ALU, Int. Shuffles
Int. ALU,LEA
FP Add
Complex Int.
SSE Int. Mul
LoadStore
AddressStore Data
Int. ALU,Shift
Branch
FP Shuffle
SSE Int. ALU, Int. Shuffles
Memory Order Buffer (MOB)
Port 0 Port 1 Port 2 Port 3 Port 4 Port 5
Data TLB
L1 Data Cache (32 KiB) L2 Cache
L2 TLB▪ 6 micro-ops./cycle
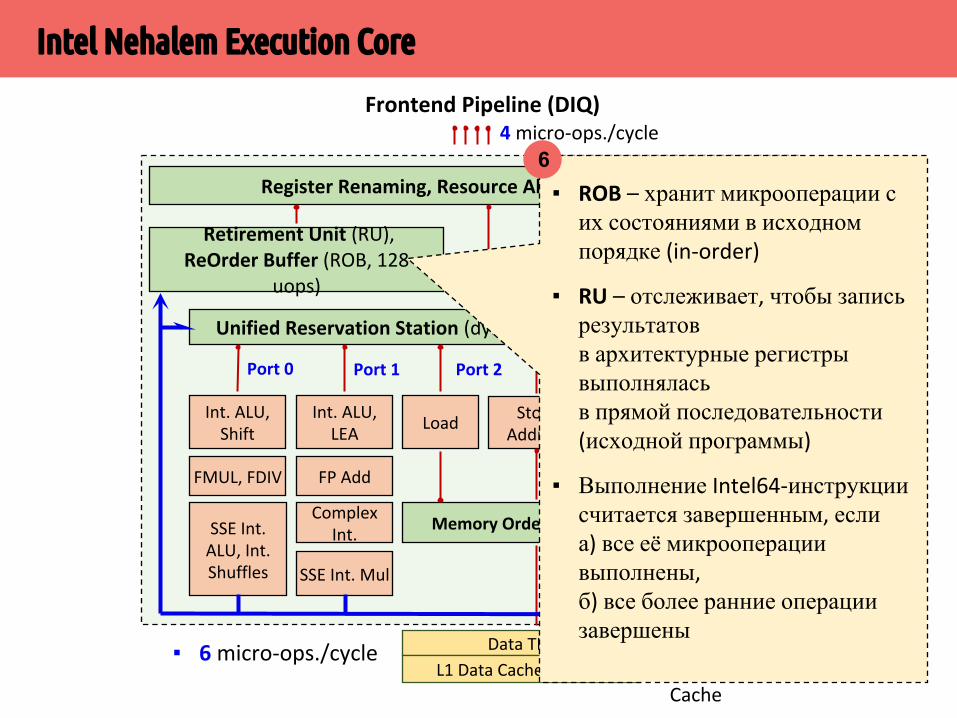
▪ ROB – хранит микрооперации с их состояниями в исходном порядке (in-order)
▪ RU – отслеживает, чтобы запись результатов в архитектурные регистры выполнялась в прямой последовательности (исходной программы)
▪ Выполнение Intel64-инструкции считается завершенным, если а) все её микрооперации выполнены,б) все более ранние операции завершены
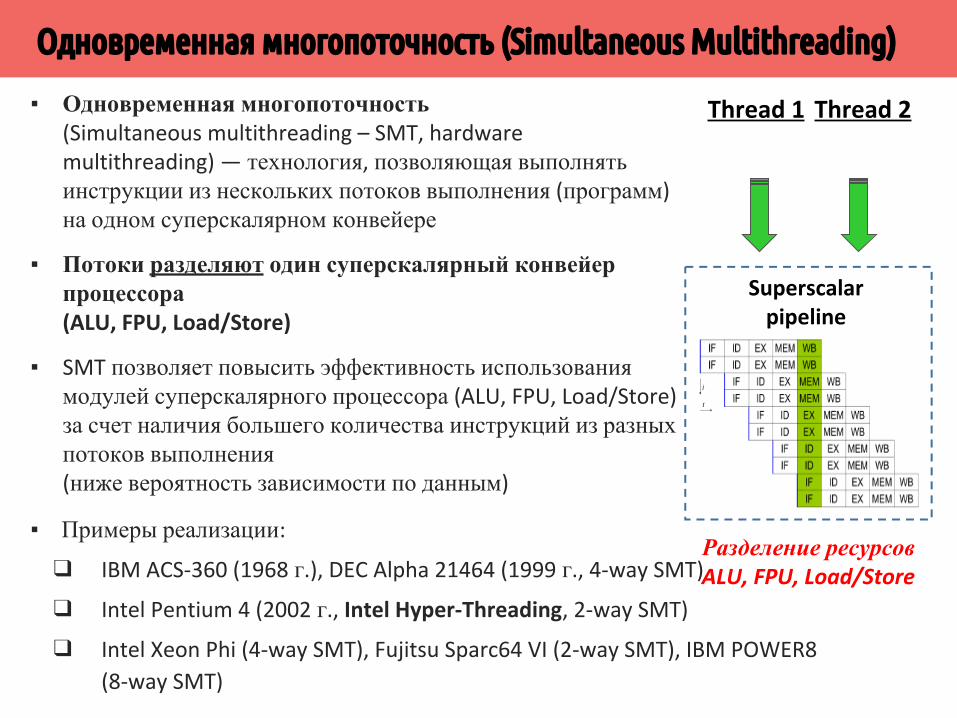
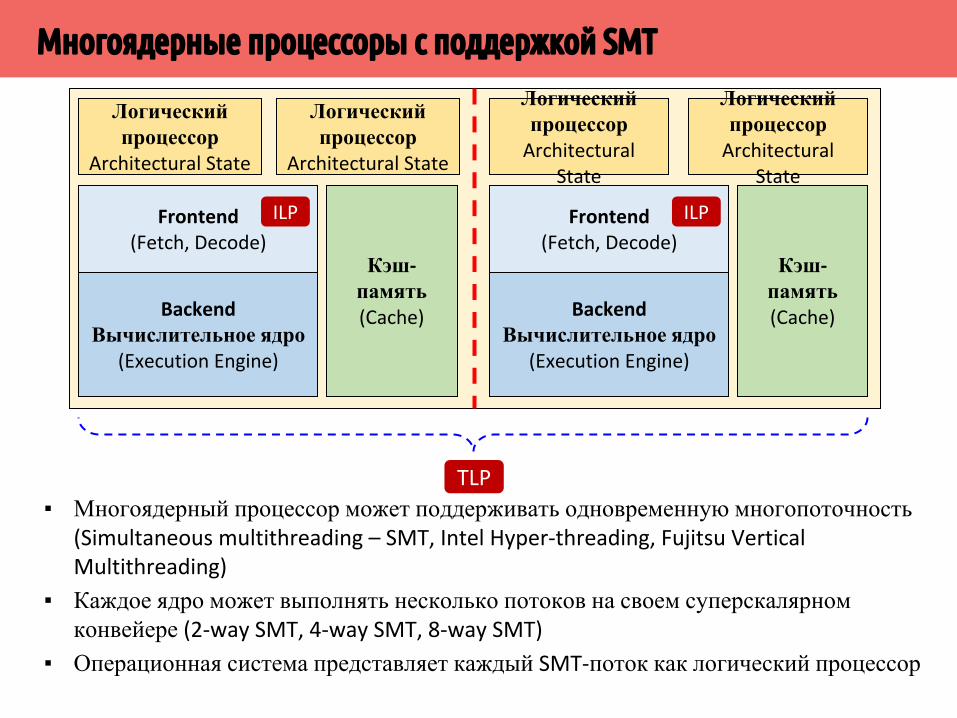
▪ Одновременная многопоточность (Simultaneous multithreading – SMT, hardware multithreading) — технология, позволяющая выполнять инструкции из нескольких потоков выполнения (программ) на одном суперскалярном конвейере
▪ Потоки разделяют один суперскалярный конвейер процессора (ALU, FPU, Load/Store)
▪ SMT позволяет повысить эффективность использования модулей суперскалярного процессора (ALU, FPU, Load/Store) за счет наличия большего количества инструкций из разных потоков выполнения (ниже вероятность зависимости по данным)
Superscalar pipeline
Thread 1 Thread 2
Разделение ресурсовALU, FPU, Load/Store
▪ Примеры реализации:
❑ IBM ACS-360 (1968 г.), DEC Alpha 21464 (1999 г., 4-way SMT)
❑ Intel Pentium 4 (2002 г., Intel Hyper-Threading, 2-way SMT)
❑ Intel Xeon Phi (4-way SMT), Fujitsu Sparc64 VI (2-way SMT), IBM POWER8
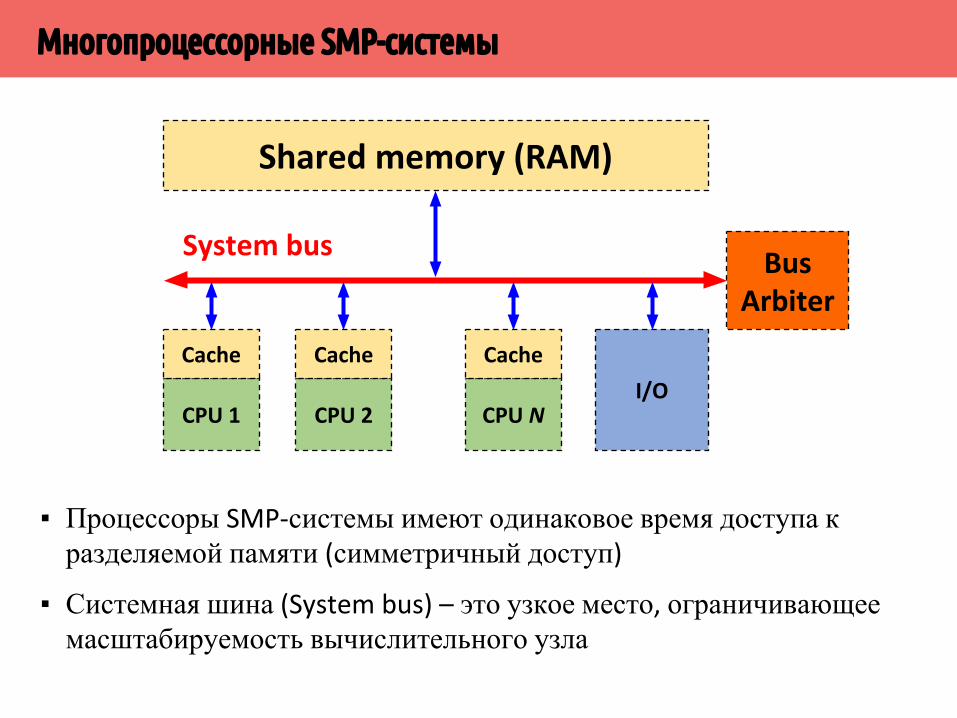
▪ Процессоры SMP-системы имеют одинаковое время доступа к разделяемой памяти (симметричный доступ)
▪ Системная шина (System bus) – это узкое место, ограничивающее масштабируемость вычислительного узла
Многопроцессорные NUMA-системы (AMD)
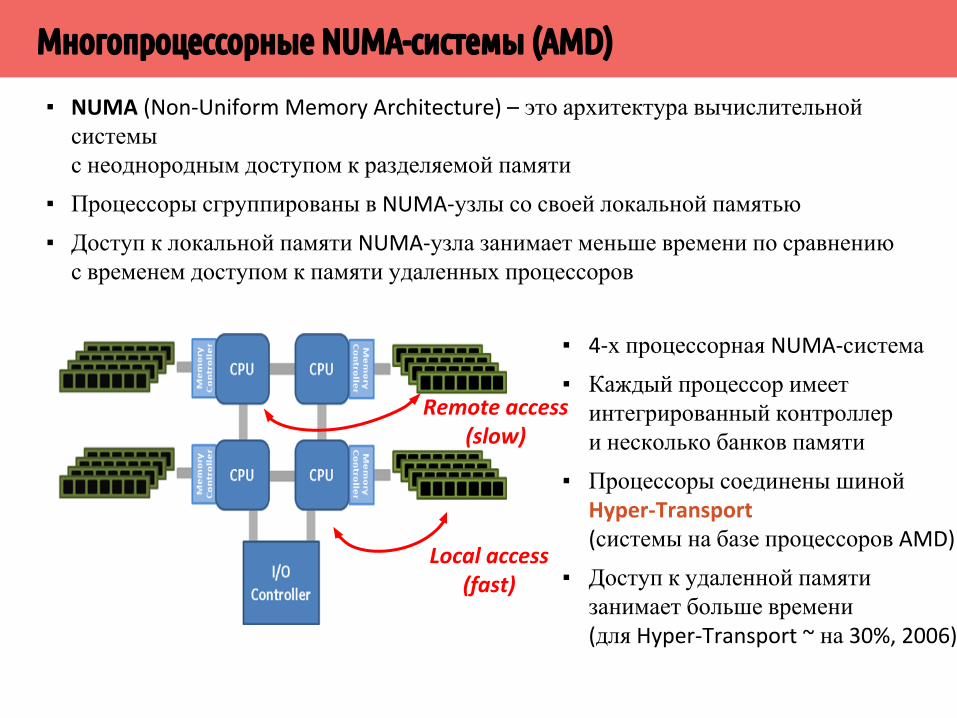
▪ NUMA (Non-Uniform Memory Architecture) – это архитектура вычислительной системы с неоднородным доступом к разделяемой памяти
▪ Процессоры сгруппированы в NUMA-узлы со своей локальной памятью▪ Доступ к локальной памяти NUMA-узла занимает меньше времени по сравнению с временем доступом к памяти удаленных процессоров
Local access (fast)
Remote access (slow)
▪ 4-х процессорная NUMA-система▪ Каждый процессор имеет интегрированный контроллери несколько банков памяти
▪ Процессоры соединены шиной Hyper-Transport (системы на базе процессоров AMD)
▪ Доступ к удаленной памяти занимает больше времени (для Hyper-Transport ~ на 30%, 2006)
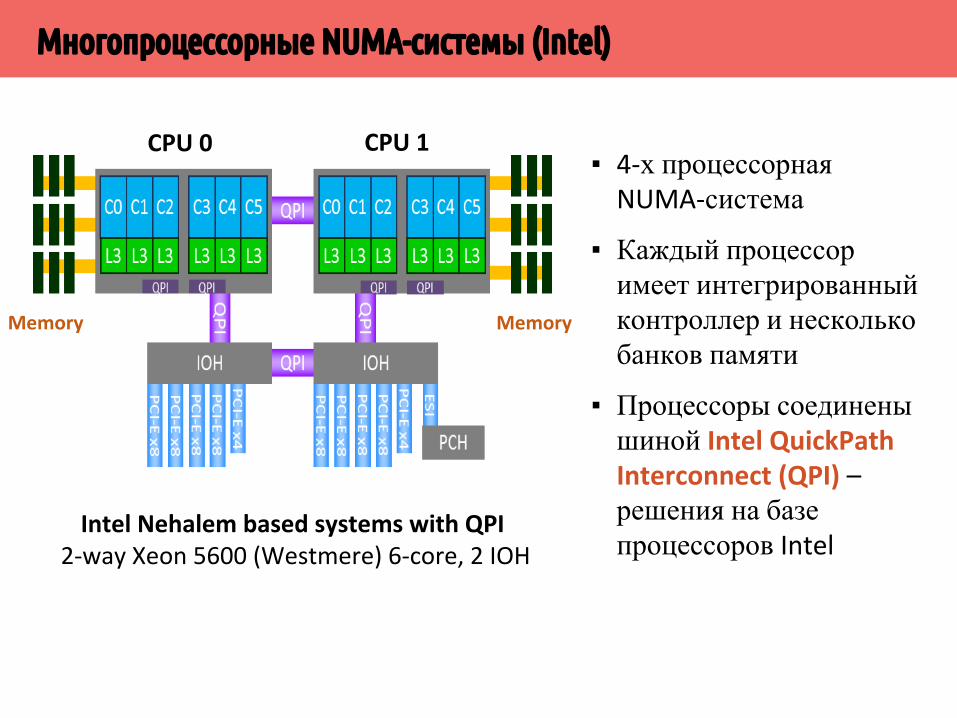
Многопроцессорные NUMA-системы (Intel)
▪ 4-х процессорная NUMA-система
▪ Каждый процессор имеет интегрированный контроллер и несколько банков памяти
▪ Процессоры соединены шиной Intel QuickPath Interconnect (QPI) – решения на базе процессоров Intel
Intel Nehalem based systems with QPI 2-way Xeon 5600 (Westmere) 6-core, 2 IOH
Memory Memory
CPU 0 CPU 1
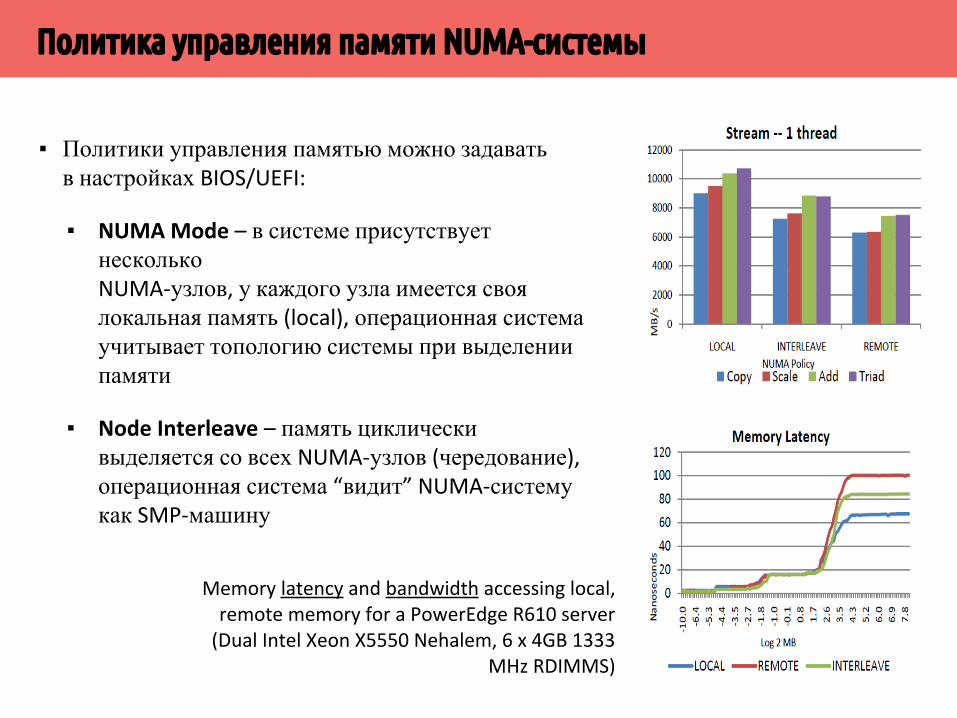
Политика управления памяти NUMA-системы
▪ Политики управления памятью можно задавать в настройках BIOS/UEFI:
▪ NUMA Mode – в системе присутствует несколько NUMA-узлов, у каждого узла имеется своя локальная память (local), операционная система учитывает топологию системы при выделении памяти
▪ Node Interleave – память циклически выделяется со всех NUMA-узлов (чередование), операционная система “видит” NUMA-систему как SMP-машину
Memory latency and bandwidth accessing local, remote memory for a PowerEdge R610 server
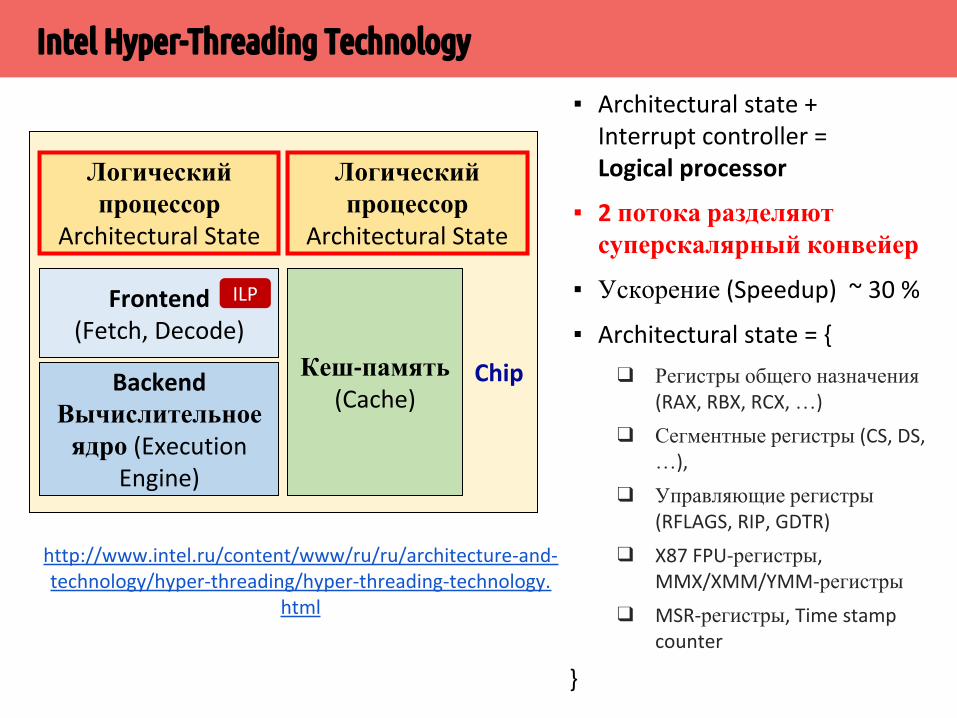
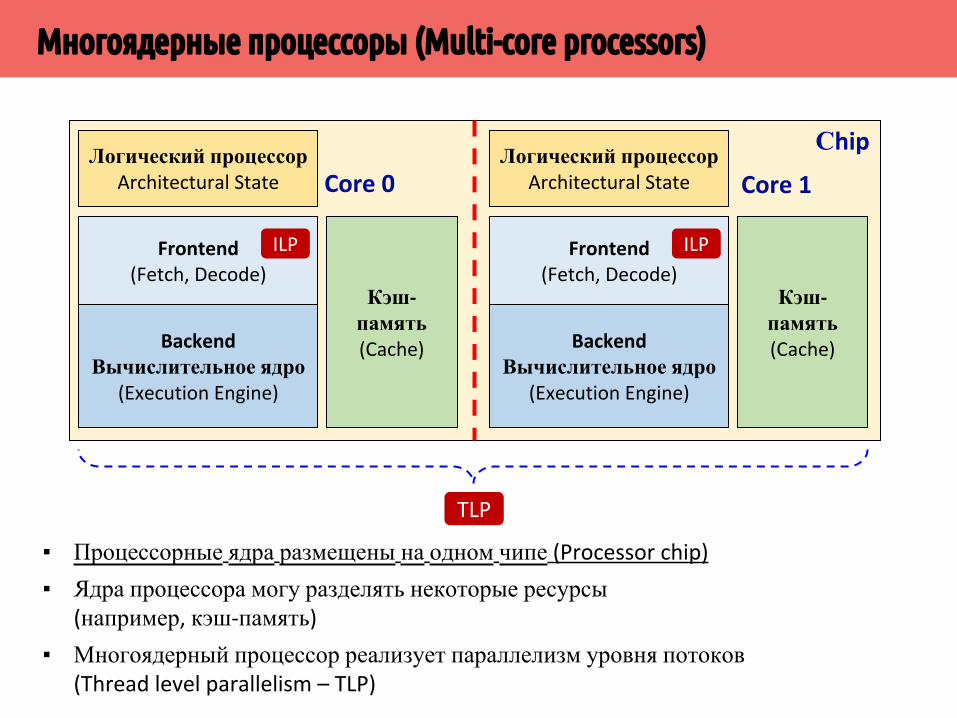
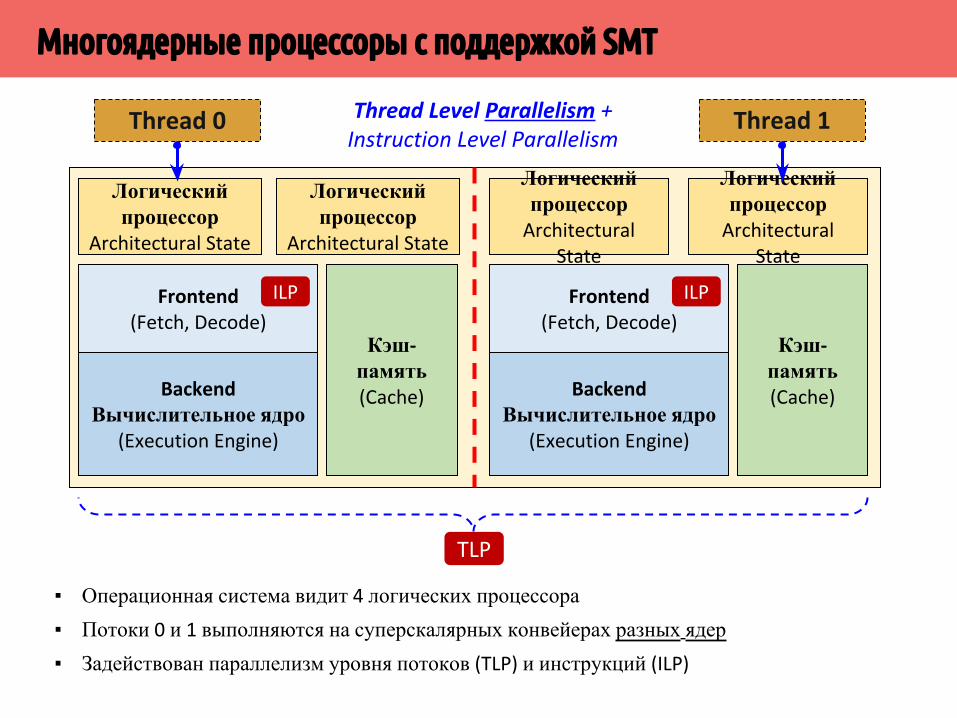
▪ Операционная система видит 4 логических процессора▪ Потоки 0 и 1 выполняются на суперскалярных конвейерах разных ядер▪ Задействован параллелизм уровня потоков (TLP) и инструкций (ILP)
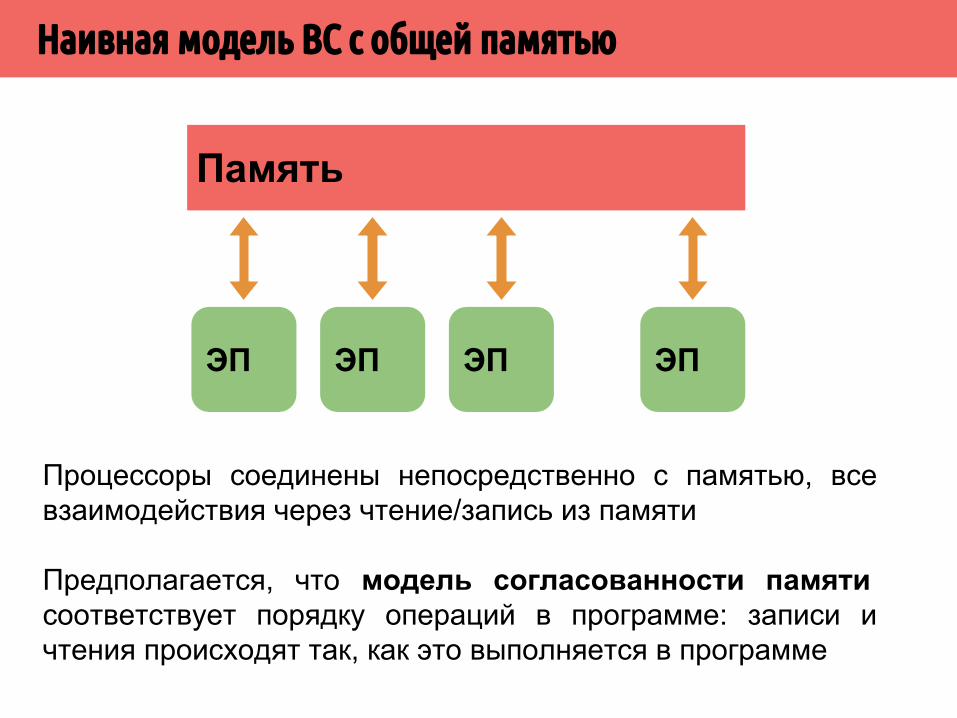
Процессоры соединены непосредственно с памятью, все взаимодействия через чтение/запись из памяти
Предполагается, что модель согласованности памяти соответствует порядку операций в программе: записи и чтения происходят так, как это выполняется в программе
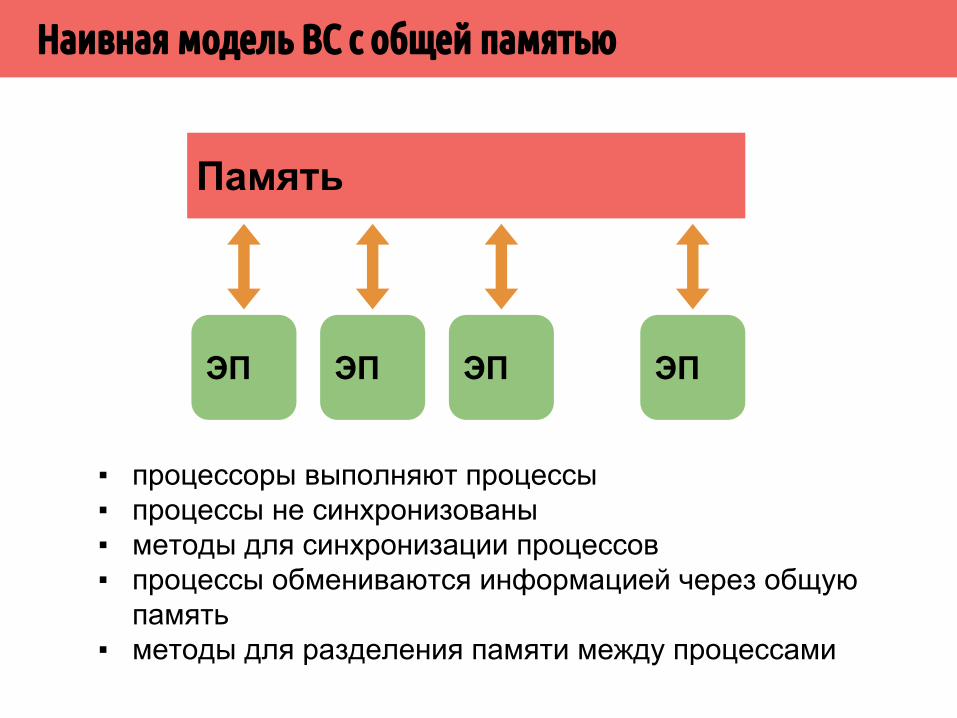
Наивная модель ВС с общей памятью
▪ процессоры выполняют процессы▪ процессы не синхронизованы▪ методы для синхронизации процессов▪ процессы обмениваются информацией через общую
память▪ методы для разделения памяти между процессами
Память
ЭП ЭП ЭП ЭП
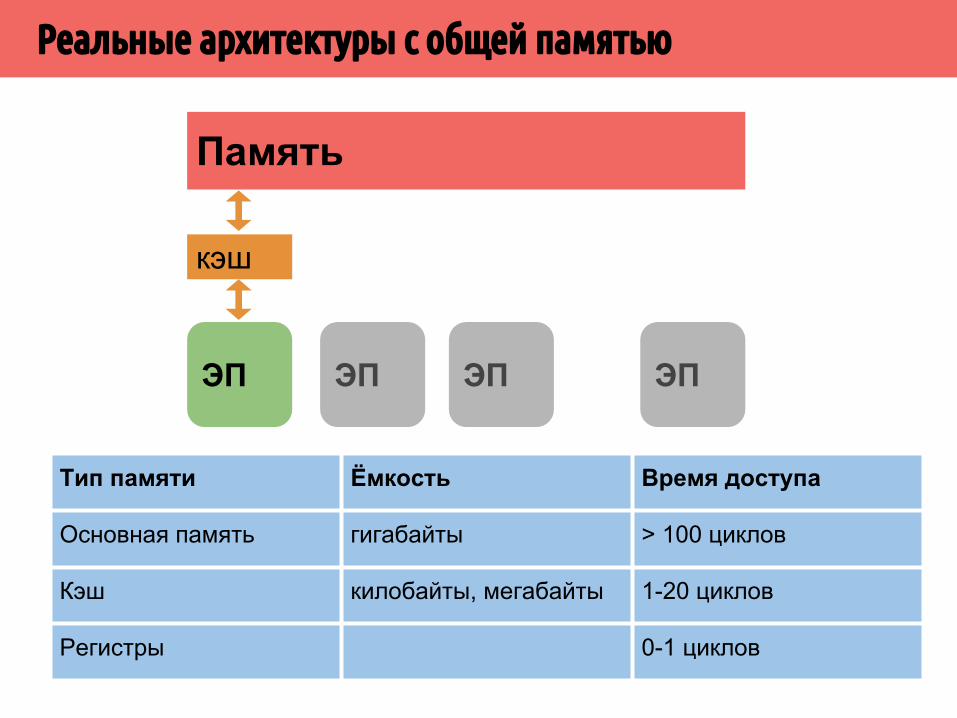
Реальные архитектуры с общей памятью
Память
ЭП ЭП ЭПЭП
кэш
Кэш: небольшая, быстрая память, расположенная близко к процессору. Сохраняет из основной памяти блоки, которые затем используются при вычислениях.Буфер между процессором и основной памятью.
Реальные архитектуры с общей памятью
Память
ЭП ЭП ЭПЭП
кэш
Тип памяти Ёмкость Время доступа
Основная память гигабайты > 100 циклов
Кэш килобайты, мегабайты 1-20 циклов
Регистры 0-1 циклов
Многоуровневная система кэша
Память
ЭП ЭП ЭПЭП
кэш
кэш
Д И
Уровень 3
Уровень 2
Уровень 1
2-3 уровня + специализированные кэши, TLB, кэш инструкций и т.д.
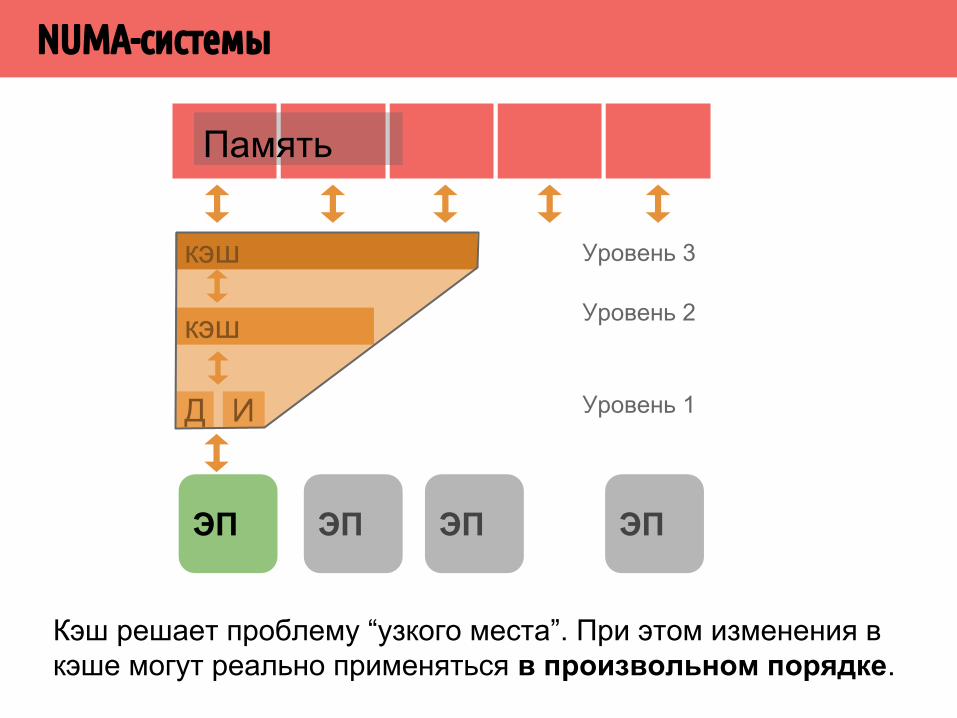
NUMA-системы
Память
ЭП ЭП ЭПЭП
кэш
кэш
Д И
Уровень 3
Уровень 2
Уровень 1
Кэш решает проблему “узкого места”. При этом изменения в кэше могут реально применяться в произвольном порядке.
Память
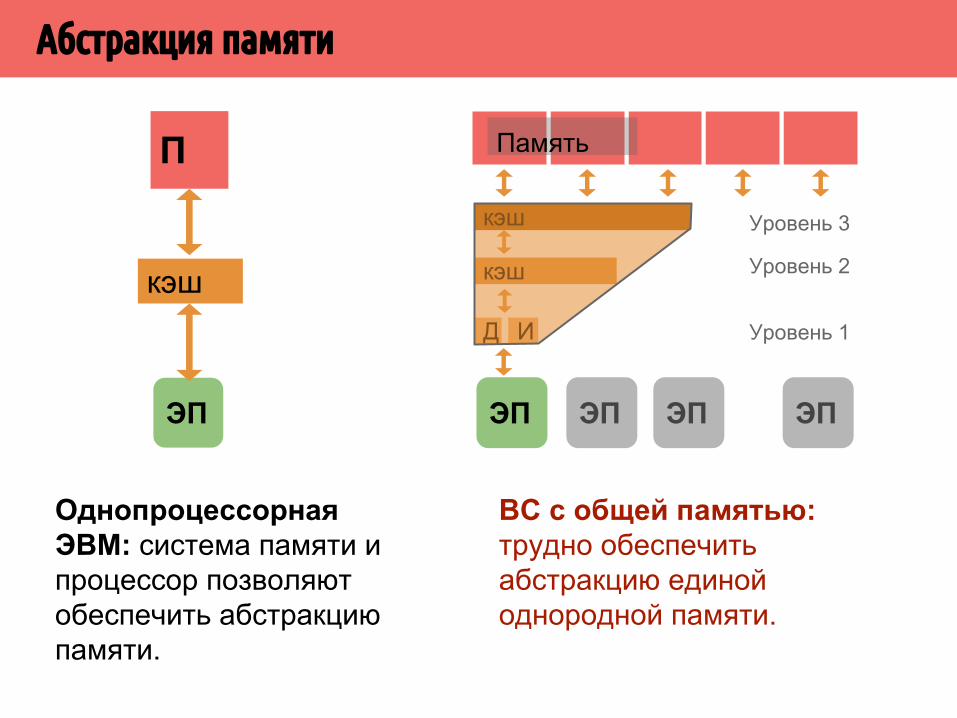
Абстракция памяти
Однопроцессорная ЭВМ: система памяти и процессор позволяют обеспечить абстракцию памяти.
Память
ЭП ЭП ЭПЭП
кэш
кэш
Д И
Уровень 3
Уровень 2
Уровень 1
ПамятьП
ЭП
кэш
ВС с общей памятью: трудно обеспечить абстракцию единой однородной памяти.
Абстракция памяти - проблемы
Память
ЭП ЭП ЭПЭП
кэш
кэш
Д И
Уровень 3
Уровень 2
Уровень 1
Память
▪ Что случится, если один и тот же адрес находится в разных кэшах?
▪ Что происходит при изменении записи в один из кэшей одним из процессоров?
▪ Несколько процессоров записывают или читают из одного адреса?
Абстракция памяти - проблемы
ЭП ЭП ЭПЭП
кэш
Д И
Память
Д И Д И Д И
кэш
Абстракция памяти - проблемы
Память
ЭП ЭП ЭПЭП
кэш
кэш
Д И
Уровень 3
Уровень 2
Уровень 1
Память
▪ Что случится, если один и тот же адрес находится в разных кэшах?
▪ Что происходит при изменении записи в один из кэшей одним из процессоров?
▪ Несколько процессоров записывают или читают из одного адреса?
Проблема когерентности кэша
Процессы и потоки
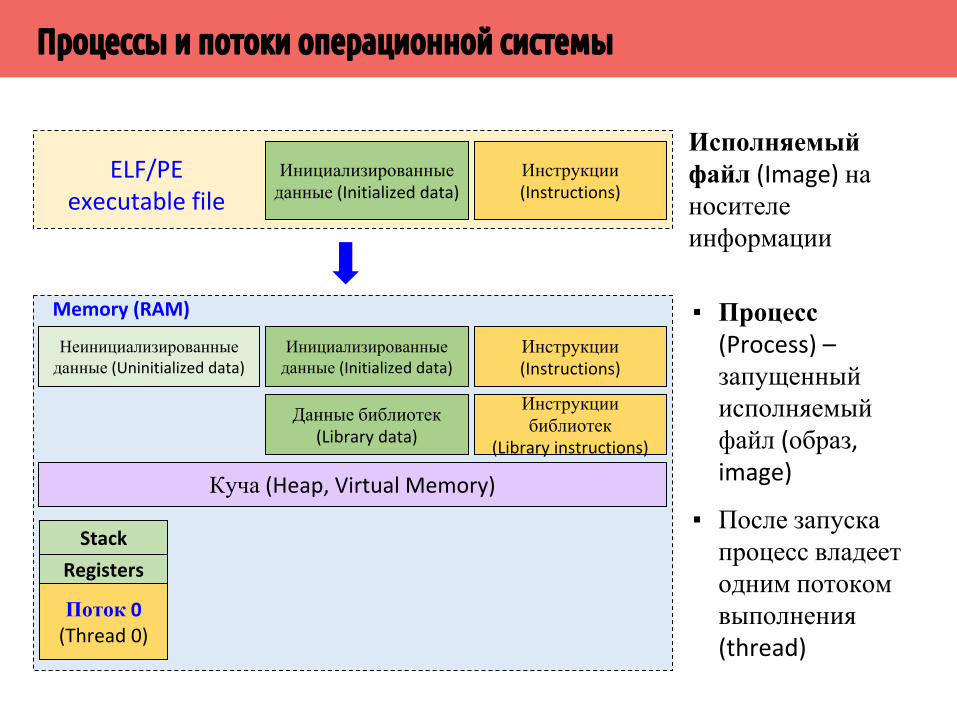
Процессы и потоки операционной системы
Инструкции(Instructions)
Инициализированные данные (Initialized data)
ELF/PE executable file
Исполняемый файл (Image) на носителе информации
Memory (RAM)
Инструкции(Instructions)
Инициализированные данные (Initialized data)
Неинициализированные данные (Uninitialized data)
Куча (Heap, Virtual Memory)
Данные библиотек (Library data)
Инструкции библиотек
(Library instructions)
Stack
Registers
Поток 0(Thread 0)
▪ Процесс (Process) – запущенный исполняемый файл (образ, image)
▪ После запуска процесс владеет одним потоком выполнения (thread)
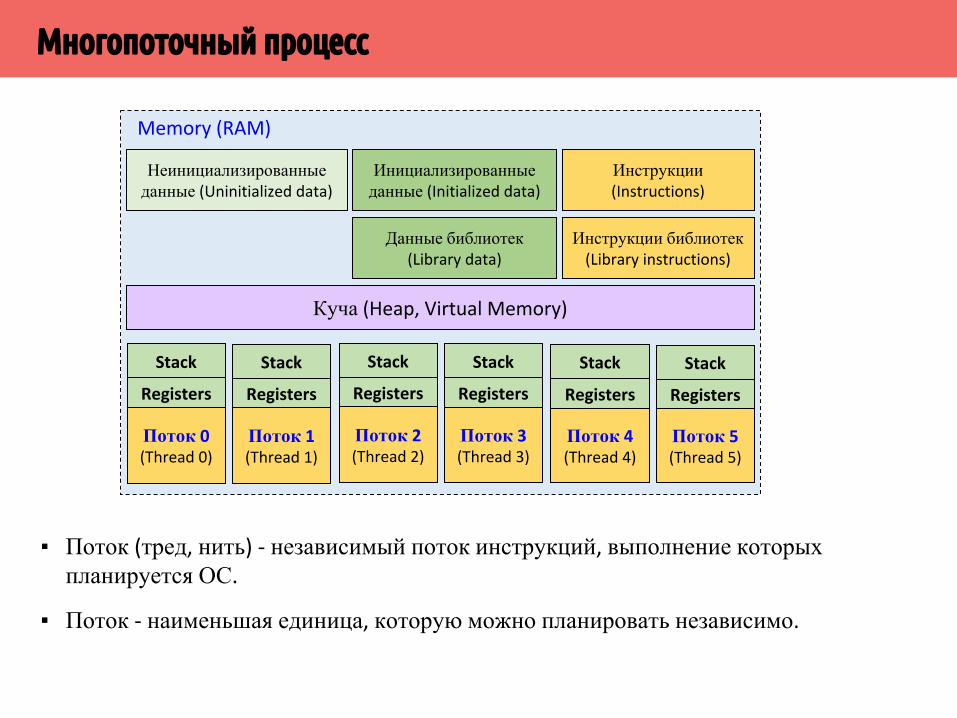
Многопоточный процесс
Memory (RAM)
Инструкции(Instructions)
Инициализированные данные (Initialized data)
Неинициализированные данные (Uninitialized data)
Куча (Heap, Virtual Memory)
Данные библиотек (Library data)
Инструкции библиотек(Library instructions)
Stack
Registers
Поток 0(Thread 0)
Stack
Registers
Поток 1(Thread 1)
Stack
Registers
Поток 2(Thread 2)
Stack
Registers
Поток 3(Thread 3)
Stack
Registers
Поток 4(Thread 4)
Stack
Registers
Поток 5(Thread 5)
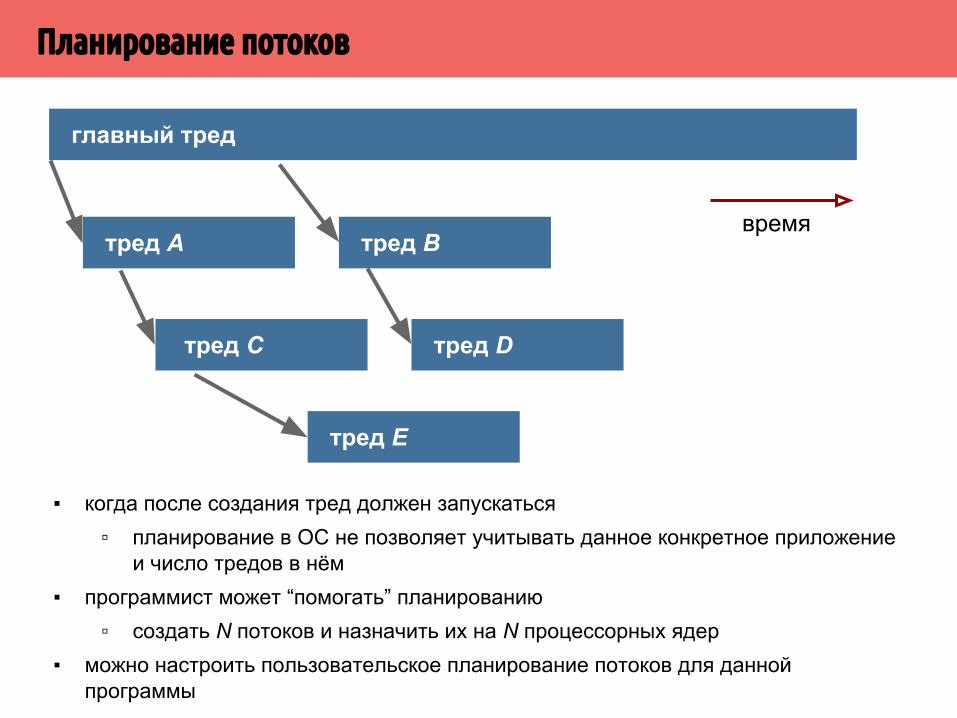
▪ Поток (тред, нить) - независимый поток инструкций, выполнение которых планируется ОС.
▪ Поток - наименьшая единица, которую можно планировать независимо.
Многопоточный процесс
Memory (RAM)
Инструкции(Instructions)
Инициализированные данные (Initialized data)
Неинициализированные данные (Uninitialized data)
Куча (Heap, Virtual Memory)
Данные библиотек (Library data)
Инструкции библиотек(Library instructions)
Stack
Registers
Поток 0(Thread 0)
Stack
Registers
Поток 1(Thread 1)
Stack
Registers
Поток 2(Thread 2)
Stack
Registers
Поток 3(Thread 3)
Stack
Registers
Поток 4(Thread 4)
Stack
Registers
Поток 5(Thread 5)
▪ Каждый поток имеет свой стек и контекст (context) – память для хранения значения архитектурных регистров при переключении контекстов (context switching) операционной системой
▪ Куча процесса (heap), инструкции, статические данные (инициализированные) являются общими для всех потоков
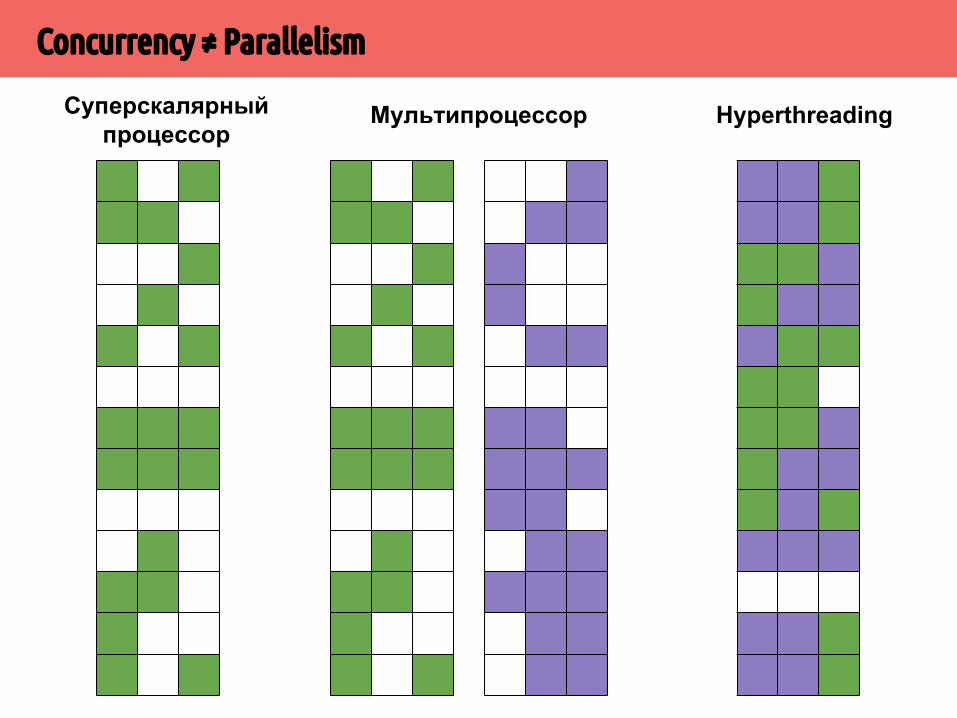
Concurrency ≠ Parallelism
18 февраля 2014 г.
▪ Concurrency (одновременность) – два и более потоков выполняются разделяя одно процессорное ядро
▪ Операционная система реализует режим разделения времени ядра процессора (time sharing)
▪ Ускорение вычислений отсутствует
▪ Зачем?
▪ Обеспечение отзывчивости интерфейса, совмещение ввода-вывода и вычислений, ...
▪ Parallelism (параллелизм) – каждый поток выполняется на отдельном ядре процессора (нет конкуренции за вычислительные ресурсы)
▪ Вычисления выполняются быстрее
Concurrency ≠ Parallelism
Суперскалярный процессор
Мультипроцессор Hyperthreading
Обзор библиотеки POSIX Threads
POSIX Threads (Pthreads)
▪ Pthreads - интерфейс для потоков семейства стандартов POSIX
▫ в основе - системные вызовы для создания и синхронизации потоков
▫ поддерживаются UNIX-подобные операционные системы
▫ IEEE POSIX 1003.1c
▪ Pthreads поддерживает:
▫ реализация параллелизма
▫ синхронизация потоков
▫ нет явной поддержки коммуникаций между потоками: поскольку общая память неявная, а указатель на общие данные передаётся в поток
Пример вызова: errcode = pthread_create(&thread_id, &thread_attr, &thread_func, &fun_arg);
thread_id - идентификатор потока (для завершения, синхронизации и т.д.)thread_attr - параметры потока (например, минимальный размер стека)thread_func - функция для запуска (принимает и возвращает указатель void*)errcode - код ошибки, ≠ 0, если операция завершилась неудачно